mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-22 17:31:03 +01:00
145 lines
5.4 KiB
Markdown
145 lines
5.4 KiB
Markdown
# Crawlab
|
||
|
||

|
||

|
||
<a href="https://github.com/tikazyq/crawlab/blob/master/LICENSE" target="_blank">
|
||
<img src="https://img.shields.io/badge/License-BSD-blue.svg">
|
||
</a>
|
||
|
||
中文 | [English](https://github.com/tikazyq/crawlab/blob/master/README.md)
|
||
|
||
基于Celery的爬虫分布式爬虫管理平台,支持多种编程语言以及多种爬虫框架.
|
||
|
||
[查看演示 Demo](http://114.67.75.98:8080) | [文档](https://tikazyq.github.io/crawlab-docs)
|
||
|
||
## 要求
|
||
- Python 3.6+
|
||
- Node.js 8.12+
|
||
- MongoDB
|
||
- Redis
|
||
|
||
## 安装
|
||
|
||
三种方式:
|
||
1. [Docker](https://tikazyq.github.io/crawlab/Installation/Docker.md)(推荐)
|
||
2. [直接部署](https://tikazyq.github.io/crawlab/Installation/Direct.md)
|
||
3. [预览模式](https://tikazyq.github.io/crawlab/Installation/Direct.md)(快速体验)
|
||
|
||
## 截图
|
||
|
||
#### 首页
|
||
|
||
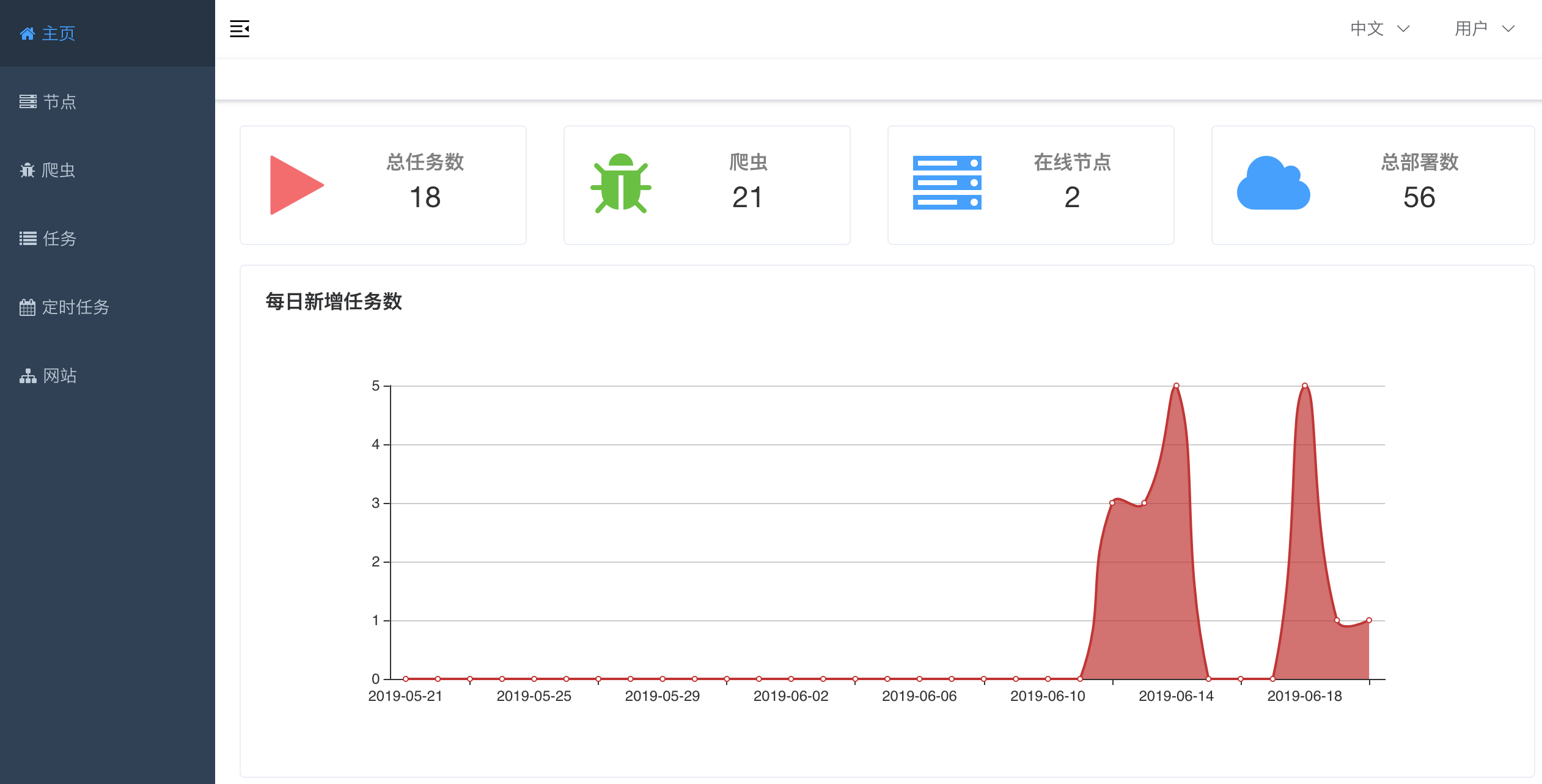
|
||
|
||
#### 爬虫列表
|
||
|
||
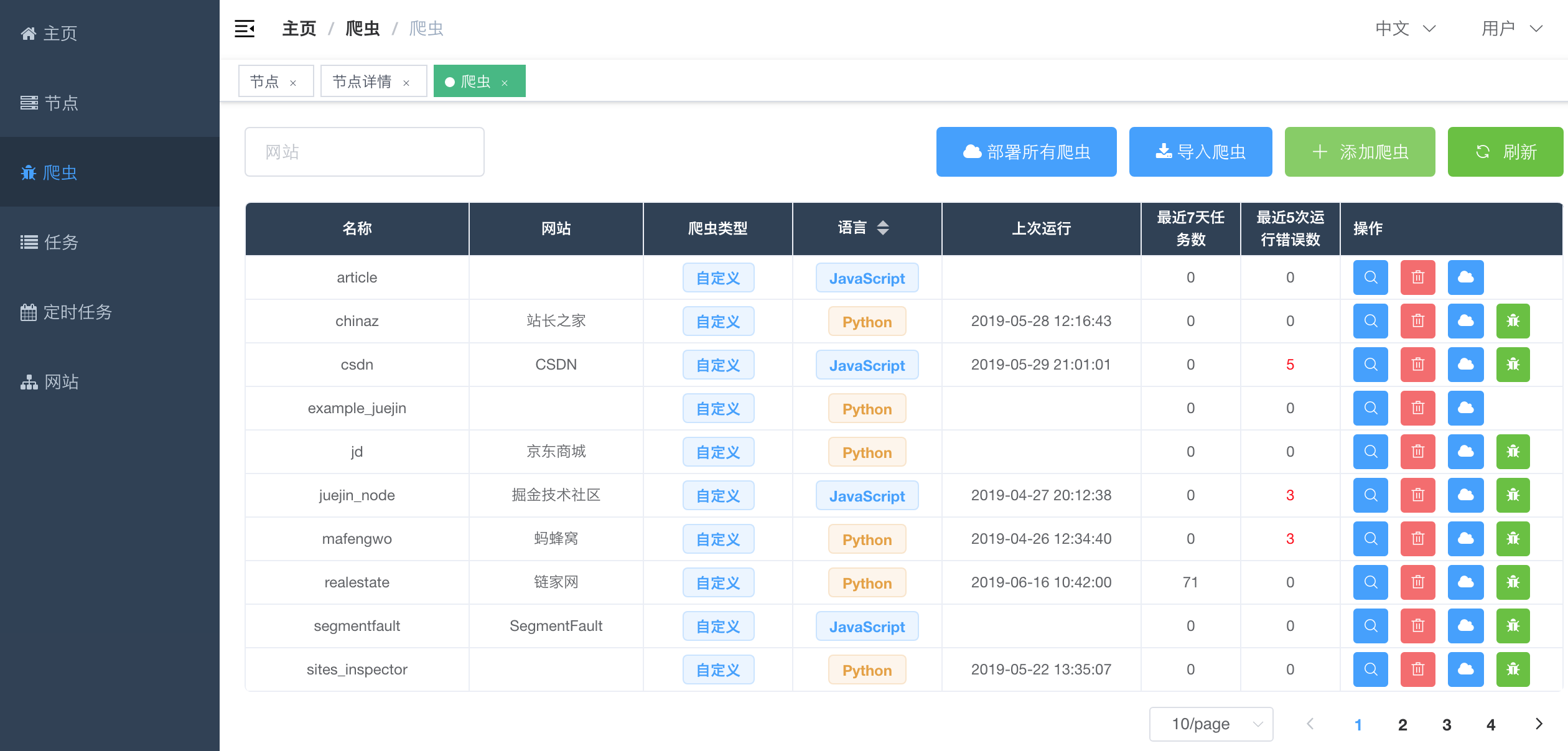
|
||
|
||
#### 爬虫详情 - 概览
|
||
|
||
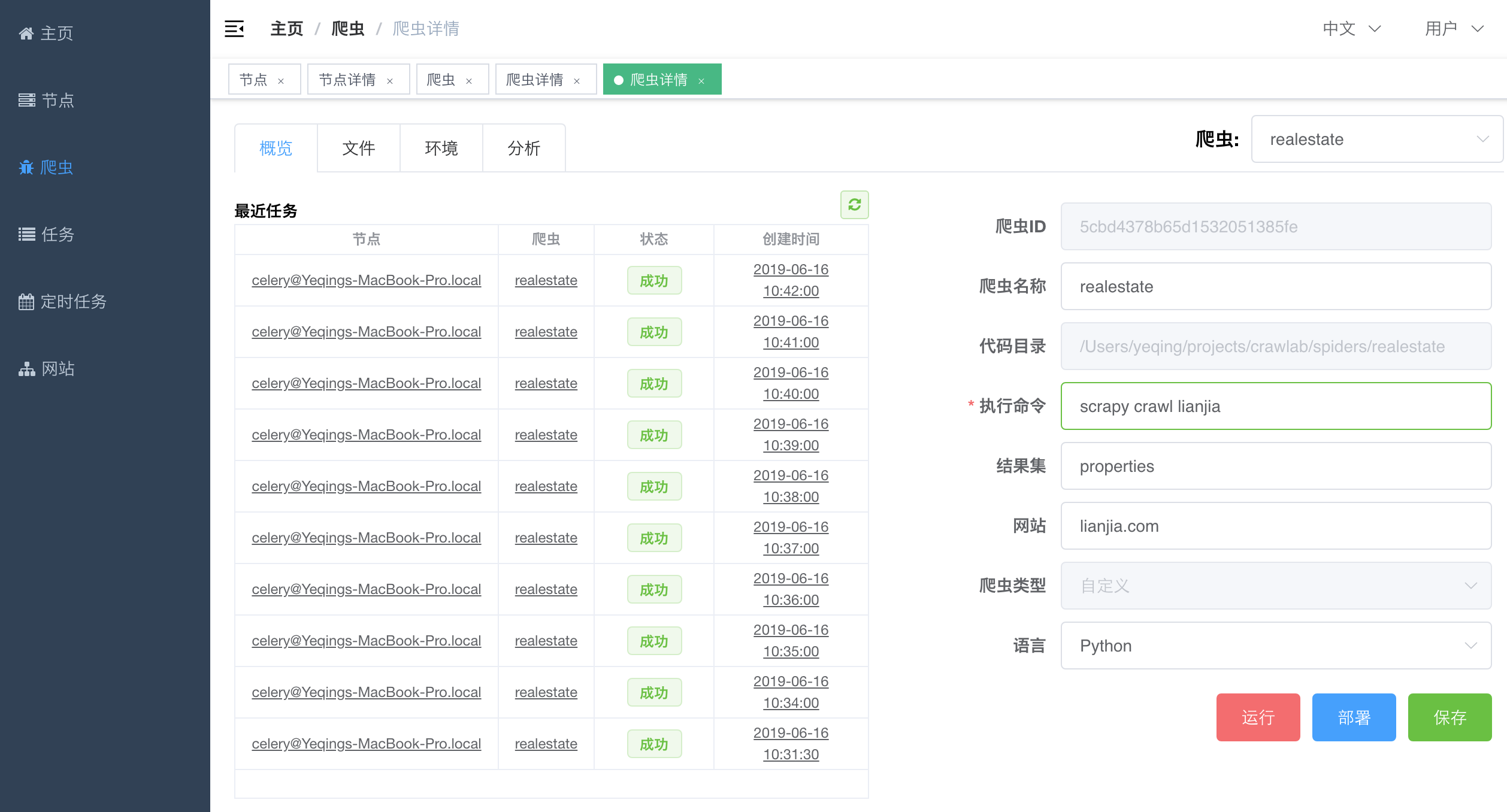
|
||
|
||
#### 爬虫详情 - 分析
|
||
|
||
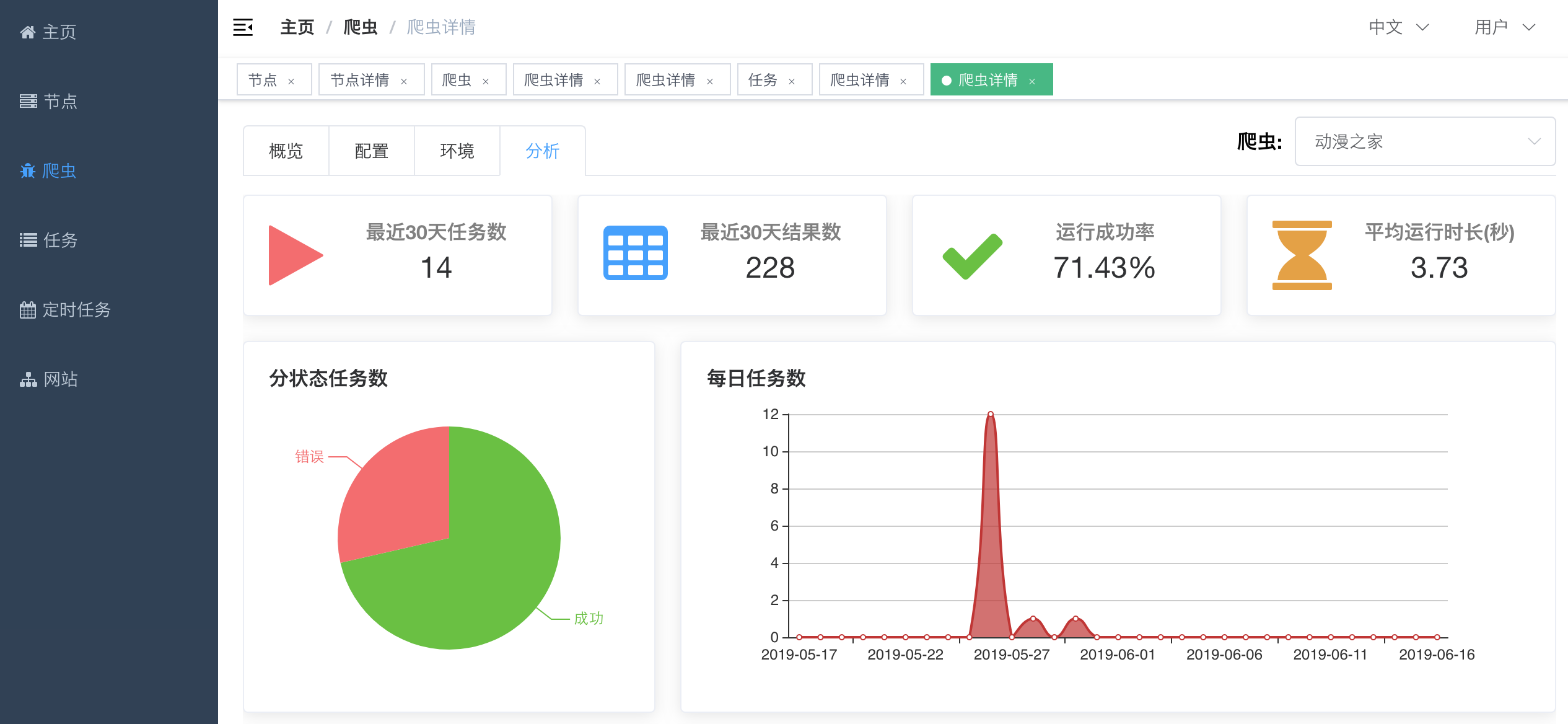
|
||
|
||
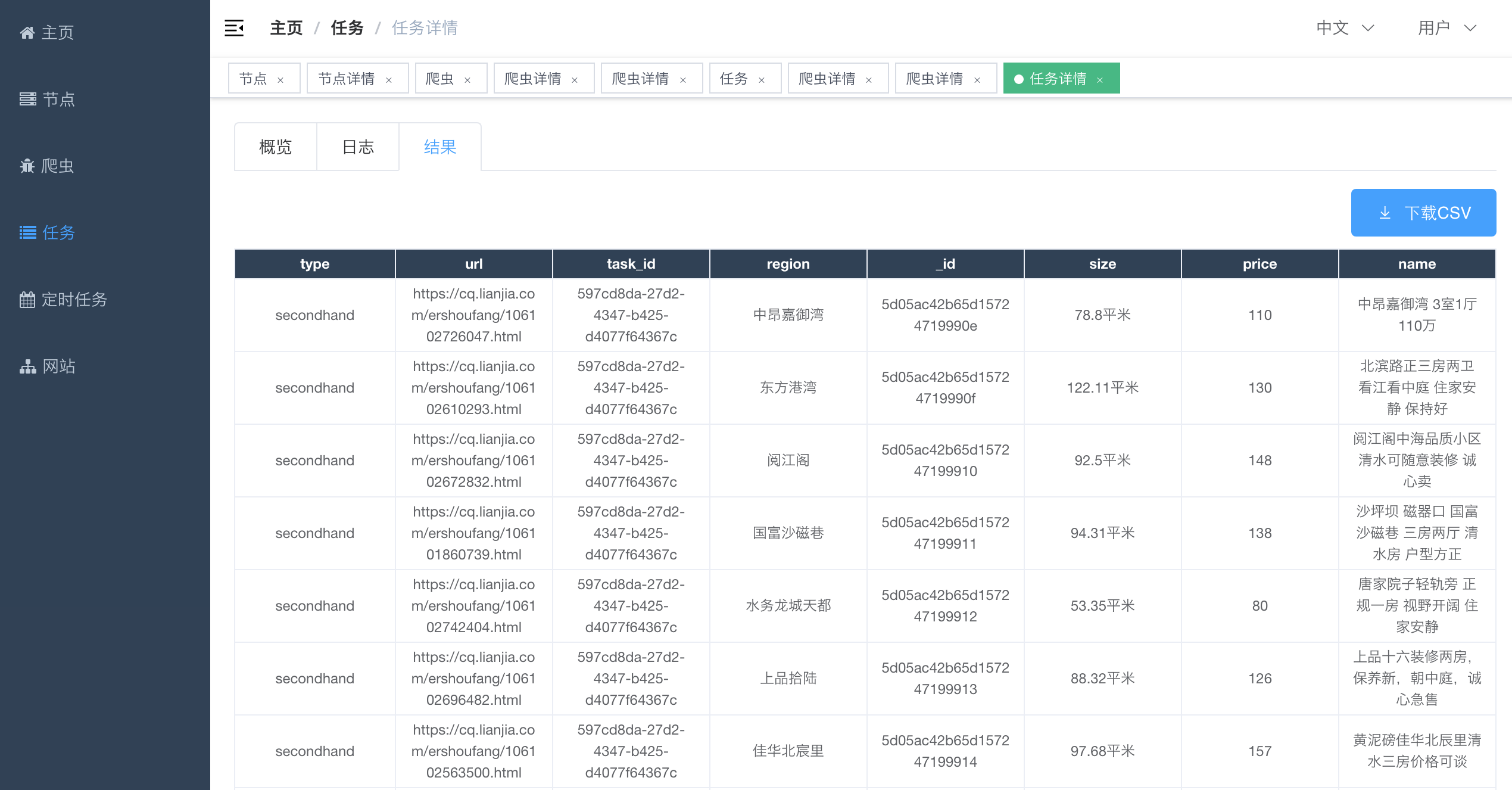
#### 任务详情 - 抓取结果
|
||
|
||
|
||
|
||
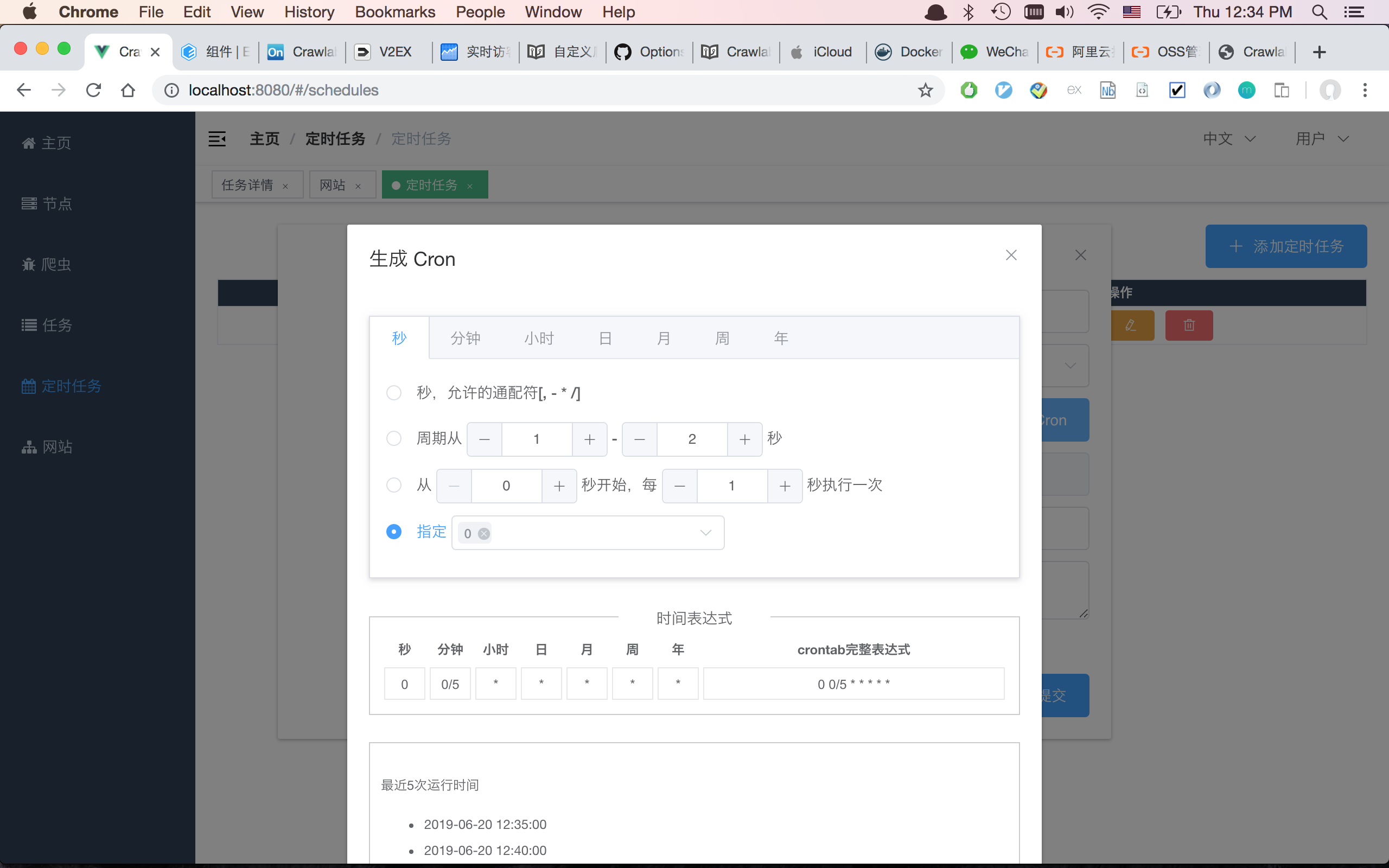
#### 定时任务
|
||
|
||
|
||
|
||
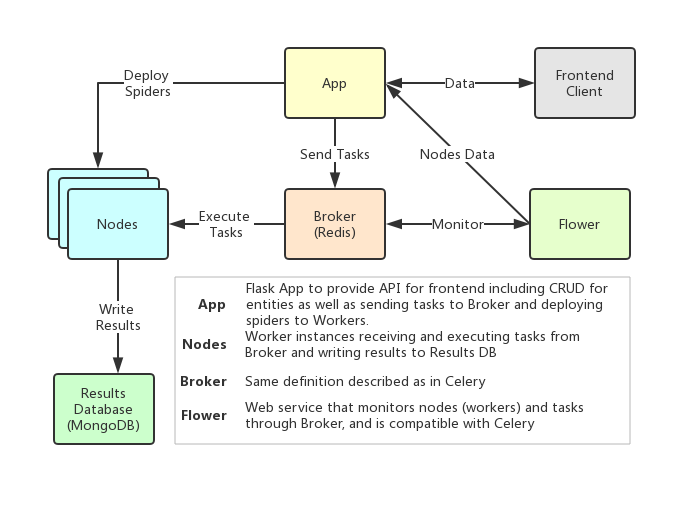
## 架构
|
||
|
||
Crawlab的架构跟Celery非常相似,但是加入了包括前端、爬虫、Flower在内的额外模块,以支持爬虫管理的功能。架构图如下。
|
||
|
||
|
||
|
||
### 节点 Node
|
||
|
||
节点其实就是Celery中的`worker`。一个节点运行时会连接到一个任务队列(例如`Redis`)来接收和运行任务。所有爬虫需要在运行时被部署到节点上,用户在部署前需要定义节点的IP地址和端口。
|
||
|
||
### 后台应用 Backend App
|
||
|
||
这是一个Flask应用,提供了必要的API来支持常规操作,例如CRUD、爬虫部署以及任务运行。每一个节点需要启动Flask应用来支持爬虫部署。运行`python app.py`来启动应用。
|
||
|
||
### 爬虫 Spider
|
||
|
||
爬虫源代码或配置规则储存在`App`上,需要被部署到各个`worker`节点中。
|
||
|
||
### 任务 Task
|
||
|
||
任务被触发并被节点执行。用户可以在任务详情页面中看到任务到状态、日志和抓取结果。
|
||
|
||
### 中间者 Broker
|
||
|
||
中间者跟Celery中定义的一样,作为运行异步任务的队列。
|
||
|
||
### 前端 Frontend
|
||
|
||
前端其实就是一个基于[Vue-Element-Admin](https://github.com/PanJiaChen/vue-element-admin)的单页应用。其中重用了很多Element-UI的控件来支持相应的展示。
|
||
|
||
### Flower
|
||
|
||
一个Celery的插件,用于监控Celery节点。
|
||
|
||
## 与其他框架的集成
|
||
|
||
任务是利用python的`subprocess`模块中的`Popen`来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。
|
||
|
||
在你的爬虫程序中,你需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中。这样Crawlab就直到如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
|
||
|
||
### Scrapy
|
||
|
||
以下是Crawlab跟Scrapy集成的例子,利用了Crawlab传过来的task_id和collection_name。
|
||
|
||
```python
|
||
import os
|
||
from pymongo import MongoClient
|
||
|
||
MONGO_HOST = '192.168.99.100'
|
||
MONGO_PORT = 27017
|
||
MONGO_DB = 'crawlab_test'
|
||
|
||
# scrapy example in the pipeline
|
||
class JuejinPipeline(object):
|
||
mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT)
|
||
db = mongo[MONGO_DB]
|
||
col_name = os.environ.get('CRAWLAB_COLLECTION')
|
||
if not col_name:
|
||
col_name = 'test'
|
||
col = db[col_name]
|
||
|
||
def process_item(self, item, spider):
|
||
item['task_id'] = os.environ.get('CRAWLAB_TASK_ID')
|
||
self.col.save(item)
|
||
return item
|
||
```
|
||
|
||
## 与其他框架比较
|
||
|
||
现在已经有一些爬虫管理框架了,因此为啥还要用Crawlab?
|
||
|
||
因为很多现有当平台都依赖于Scrapyd,限制了爬虫的编程语言以及框架,爬虫工程师只能用scrapy和python。当然,scrapy是非常优秀的爬虫框架,但是它不能做一切事情。
|
||
|
||
Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流语言和框架。它还有一个精美的前端界面,让用户可以方便的管理和运行爬虫。
|
||
|
||
|框架 | 类型 | 分布式 | 前端 | 依赖于Scrapyd |
|
||
|:---:|:---:|:---:|:---:|:---:|
|
||
| [Crawlab](https://github.com/tikazyq/crawlab) | 管理平台 | Y | Y | N
|
||
| [Gerapy](https://github.com/Gerapy/Gerapy) | 管理平台 | Y | Y | Y
|
||
| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | 管理平台 | Y | Y | Y
|
||
| [ScrapydWeb](https://github.com/my8100/scrapydweb) | 管理平台 | Y | Y | Y
|
||
| [Scrapyd](https://github.com/scrapy/scrapyd) | 网络服务 | Y | N | N/A
|
||
|
||
## 社区 & 赞助
|
||
|
||
如果您觉得Crawlab对您的日常开发或公司有帮助,请加作者微信 tikazyq1 并注明"Crawlab",作者会将你拉入群。或者,您可以扫下方支付宝二维码给作者打赏去升级团队协作软件或买一杯咖啡。
|
||
|
||
<p align="center">
|
||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/gitbook/qrcode.png" height="360">
|
||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/gitbook/payment.jpg" height="360">
|
||
</p>
|