mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-22 17:31:03 +01:00
updated README-zh.md
This commit is contained in:
113
README-zh.md
113
README-zh.md
@@ -6,50 +6,93 @@
|
||||
<img src="https://img.shields.io/badge/License-BSD-blue.svg">
|
||||
</a>
|
||||
|
||||
中文 | [English](https://github.com/tikazyq/crawlab/blob/master/README.md)
|
||||
中文 | [English](https://github.com/tikazyq/crawlab)
|
||||
|
||||
基于Golang的分布式爬虫管理平台,支持Python、NodeJS、Go、Java、PHP等多种编程语言以及多种爬虫框架。
|
||||
|
||||
[查看演示 Demo](http://114.67.75.98:8080) | [文档](https://tikazyq.github.io/crawlab-docs)
|
||||
|
||||
## 要求
|
||||
- Go 1.12+
|
||||
- Node.js 8.12+
|
||||
- MongoDB 3.6+
|
||||
- Redis
|
||||
|
||||
## 安装
|
||||
|
||||
三种方式:
|
||||
1. [Docker](https://tikazyq.github.io/crawlab/Installation/Docker.md)(推荐)
|
||||
2. [直接部署](https://tikazyq.github.io/crawlab/Installation/Direct.md)
|
||||
3. [预览模式](https://tikazyq.github.io/crawlab/Installation/Direct.md)(快速体验)
|
||||
2. [直接部署](https://tikazyq.github.io/crawlab/Installation/Direct.md)(了解内核)
|
||||
|
||||
### 要求(Docker)
|
||||
- Docker
|
||||
- Redis
|
||||
- MongoDB 3.6+
|
||||
|
||||
### 要求(直接部署)
|
||||
- Go 1.12+
|
||||
- Node 8.12+
|
||||
- Redis
|
||||
- MongoDB 3.6+
|
||||
|
||||
## 运行
|
||||
|
||||
### Docker
|
||||
|
||||
运行主节点示例。`192.168.99.1`是在Docker Machine网络中的宿主机IP地址。`192.168.99.100`是Docker主节点的IP地址。
|
||||
|
||||
```bash
|
||||
docker run -d --rm --name crawlab \
|
||||
-e CRAWLAB_REDIS_ADDRESS=192.168.99.1:6379 \
|
||||
-e CRAWLAB_MONGO_HOST=192.168.99.1 \
|
||||
-e CRAWLAB_SERVER_MASTER=Y \
|
||||
-e CRAWLAB_API_ADDRESS=192.168.99.100:8000 \
|
||||
-e CRAWLAB_SPIDER_PATH=/app/spiders \
|
||||
-p 8080:8080 \
|
||||
-p 8000:8000 \
|
||||
-v /var/logs/crawlab:/var/logs/crawlab \
|
||||
tikazyq/crawlab:0.3.0
|
||||
```
|
||||
|
||||
### 直接部署
|
||||
|
||||
请参考文档。
|
||||
|
||||
## 截图
|
||||
|
||||
#### 登录
|
||||
|
||||

|
||||
|
||||
#### 首页
|
||||
|
||||
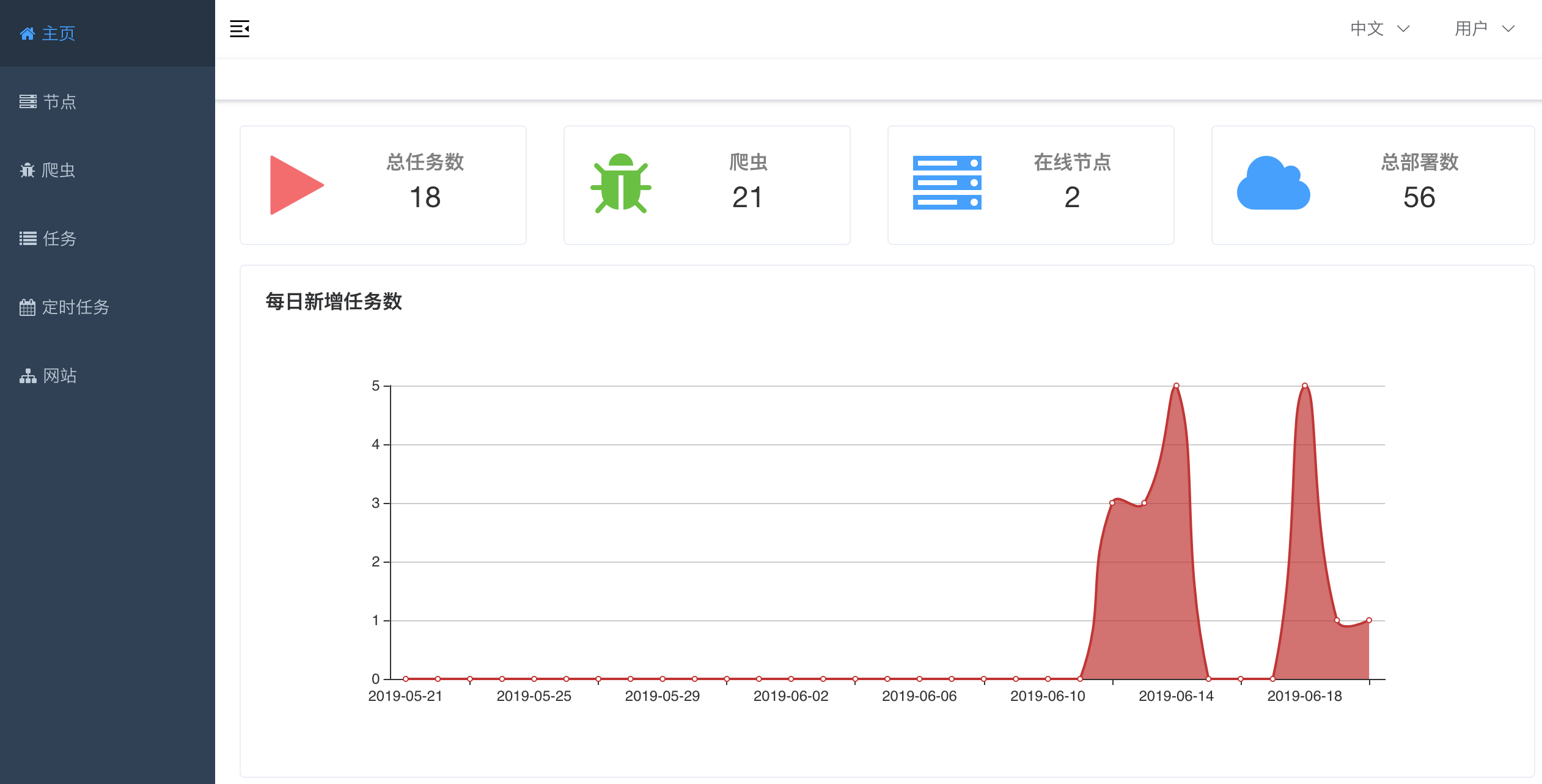
|
||||
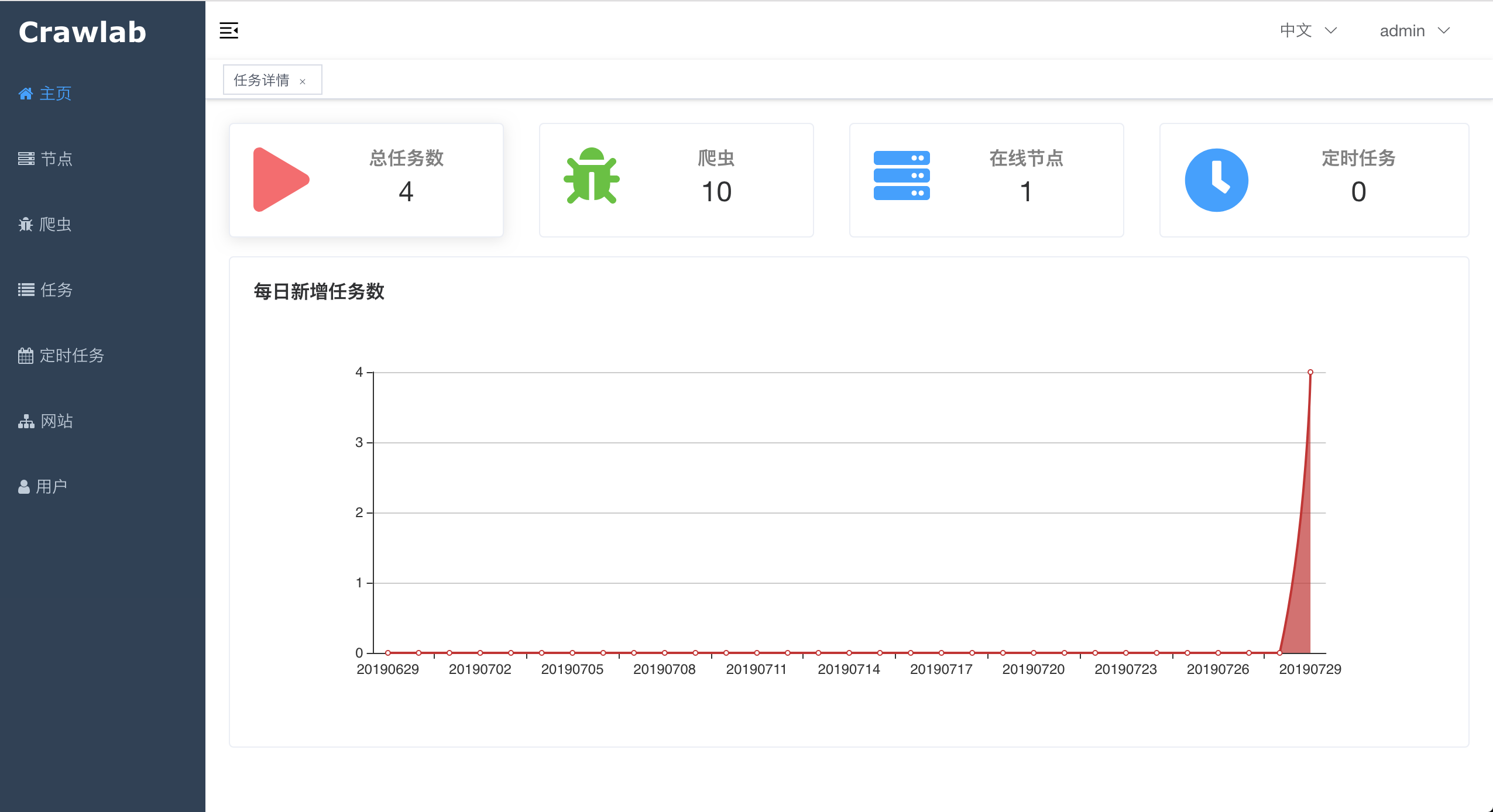
|
||||
|
||||
#### 节点列表
|
||||
|
||||
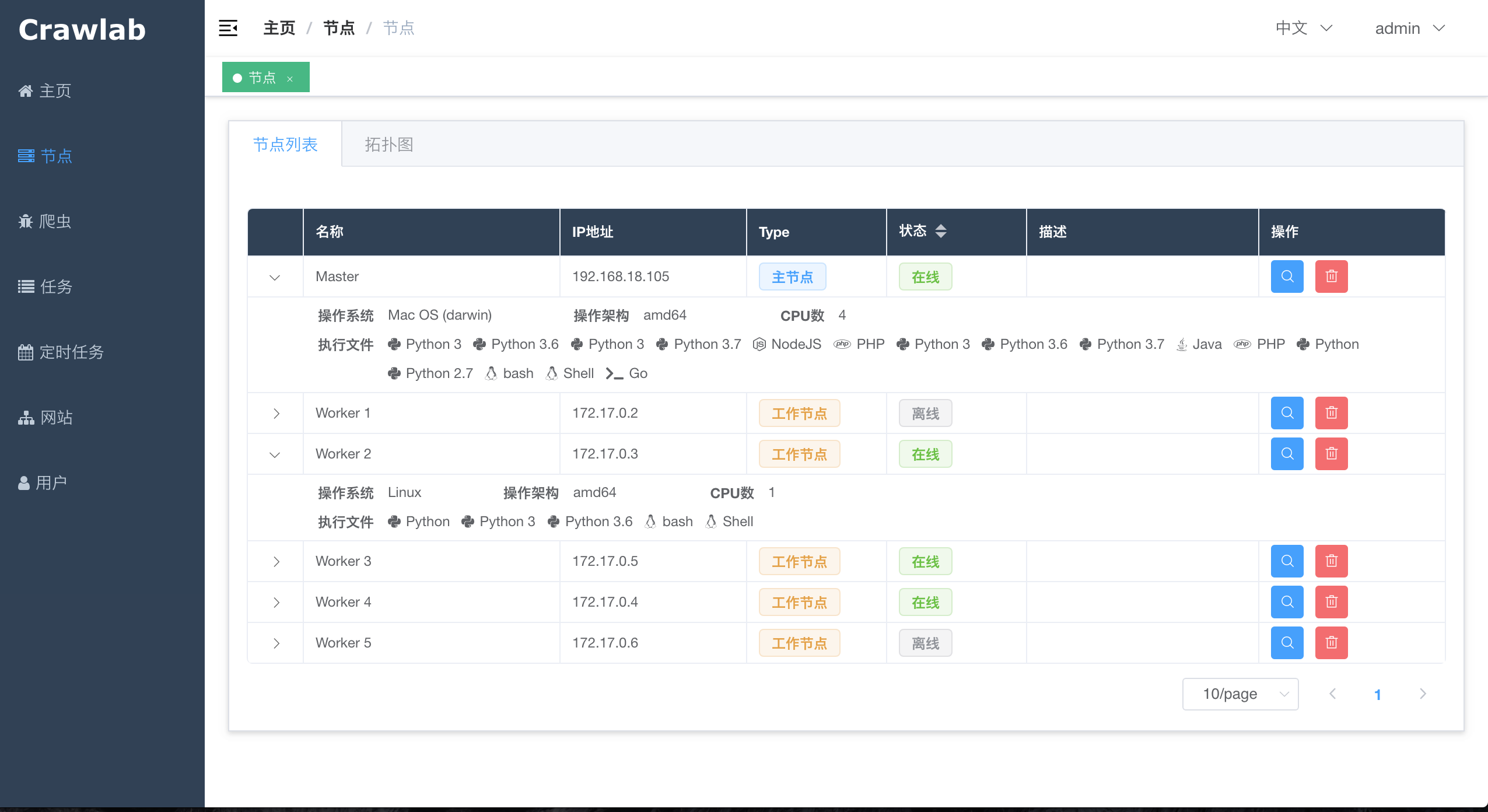
|
||||
|
||||
#### 节点拓扑图
|
||||
|
||||
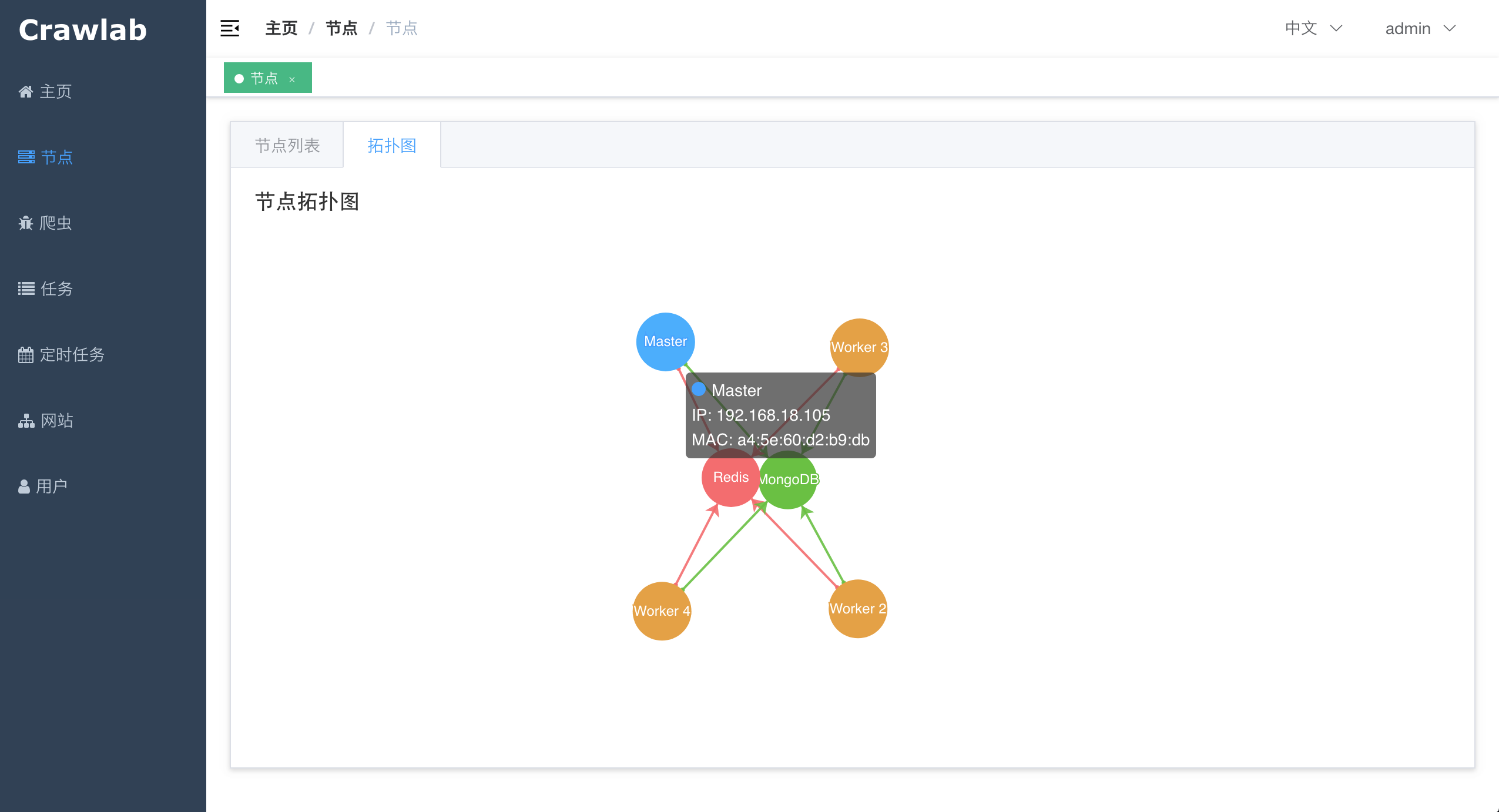
|
||||
|
||||
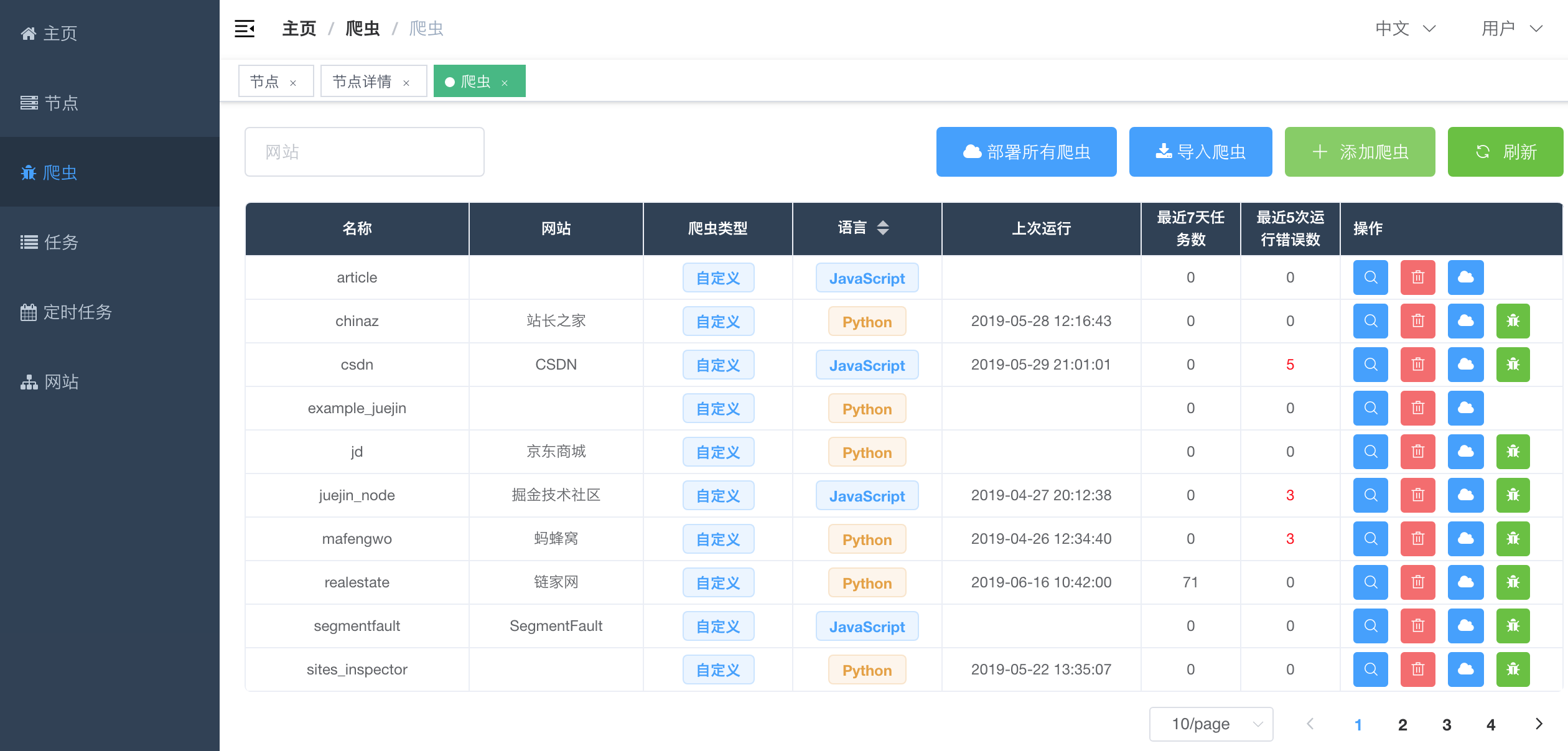
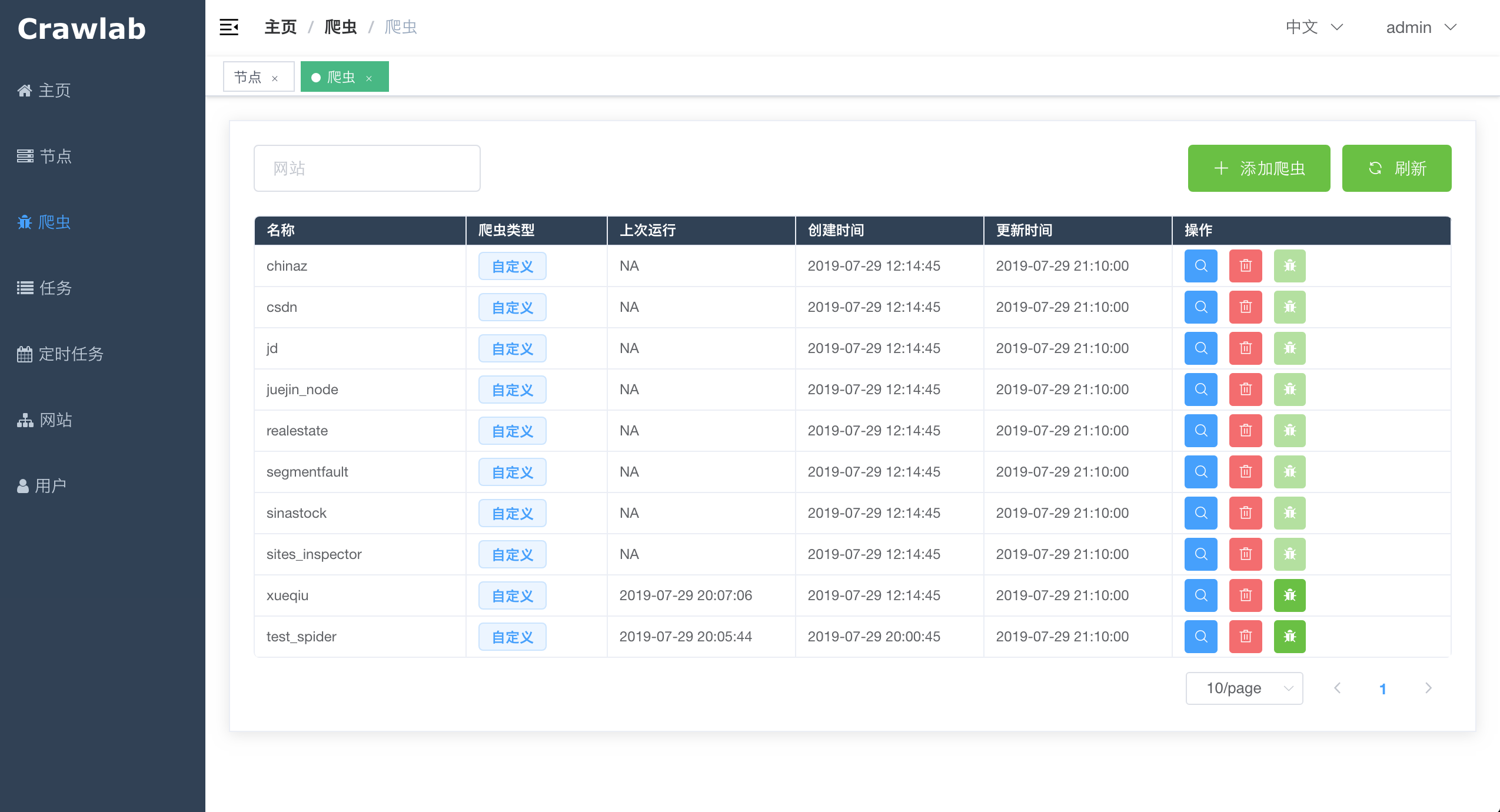
#### 爬虫列表
|
||||
|
||||
|
||||
|
||||
|
||||
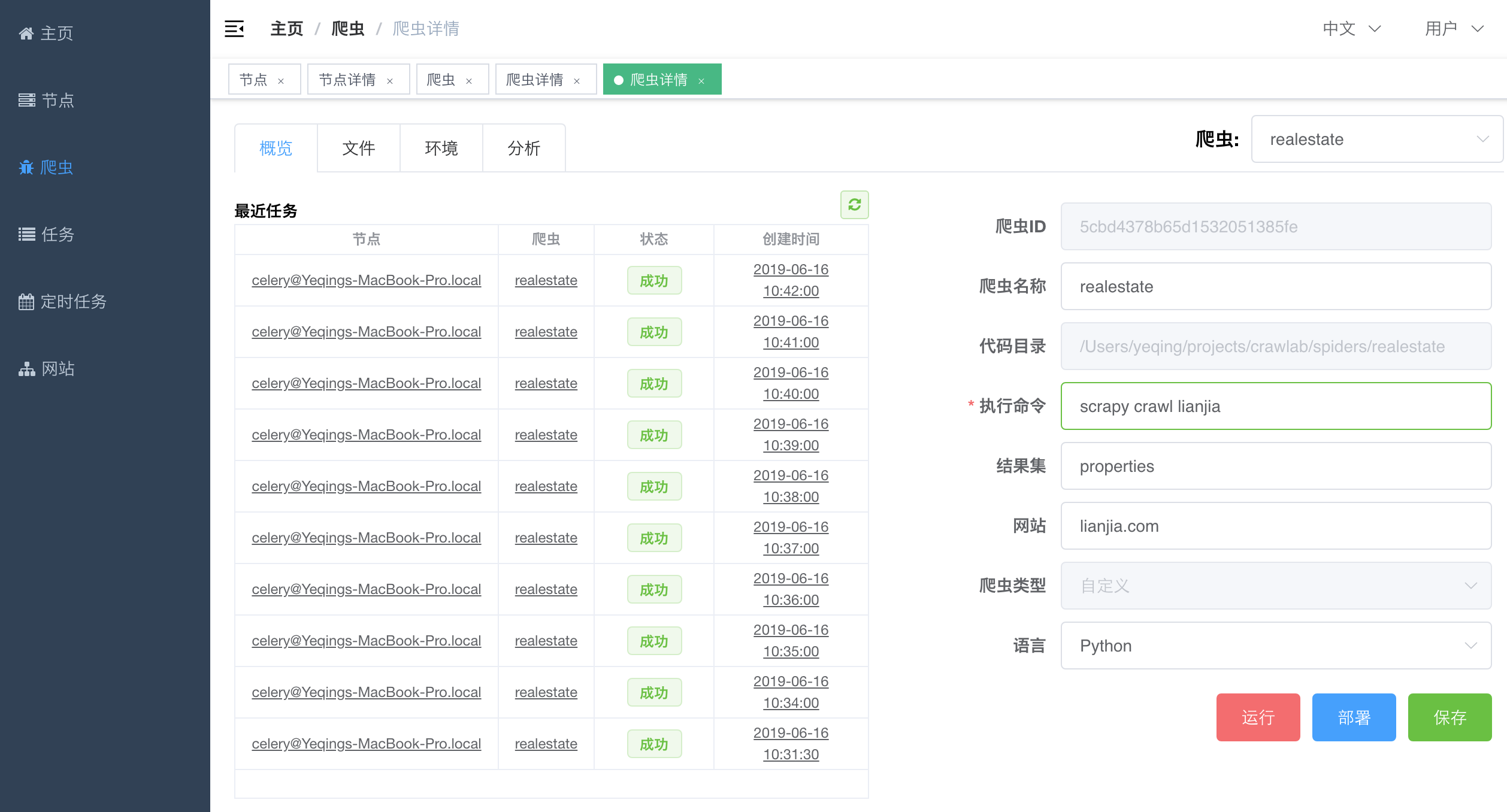
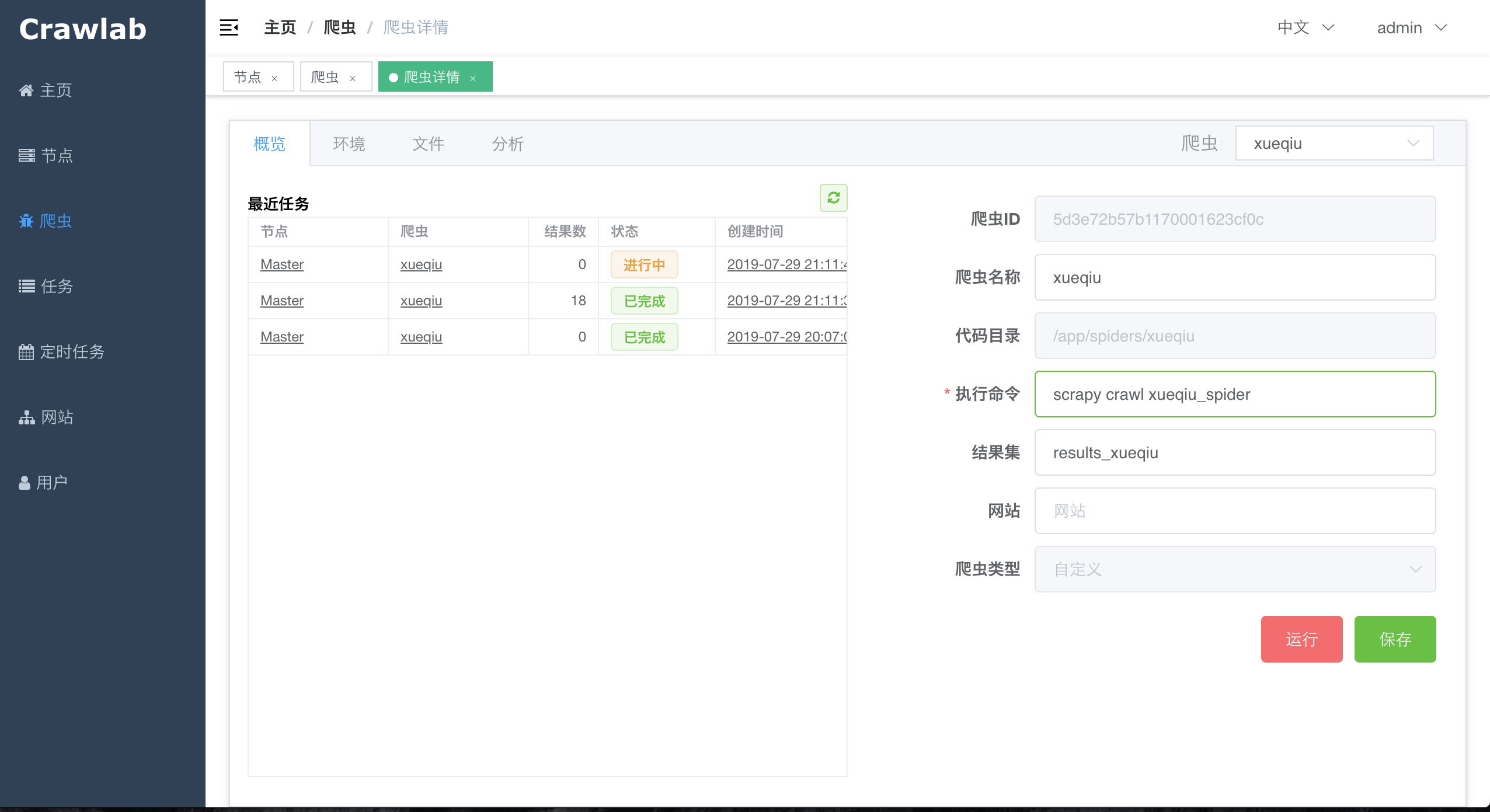
#### 爬虫详情 - 概览
|
||||
#### 爬虫概览
|
||||
|
||||
|
||||
|
||||
|
||||
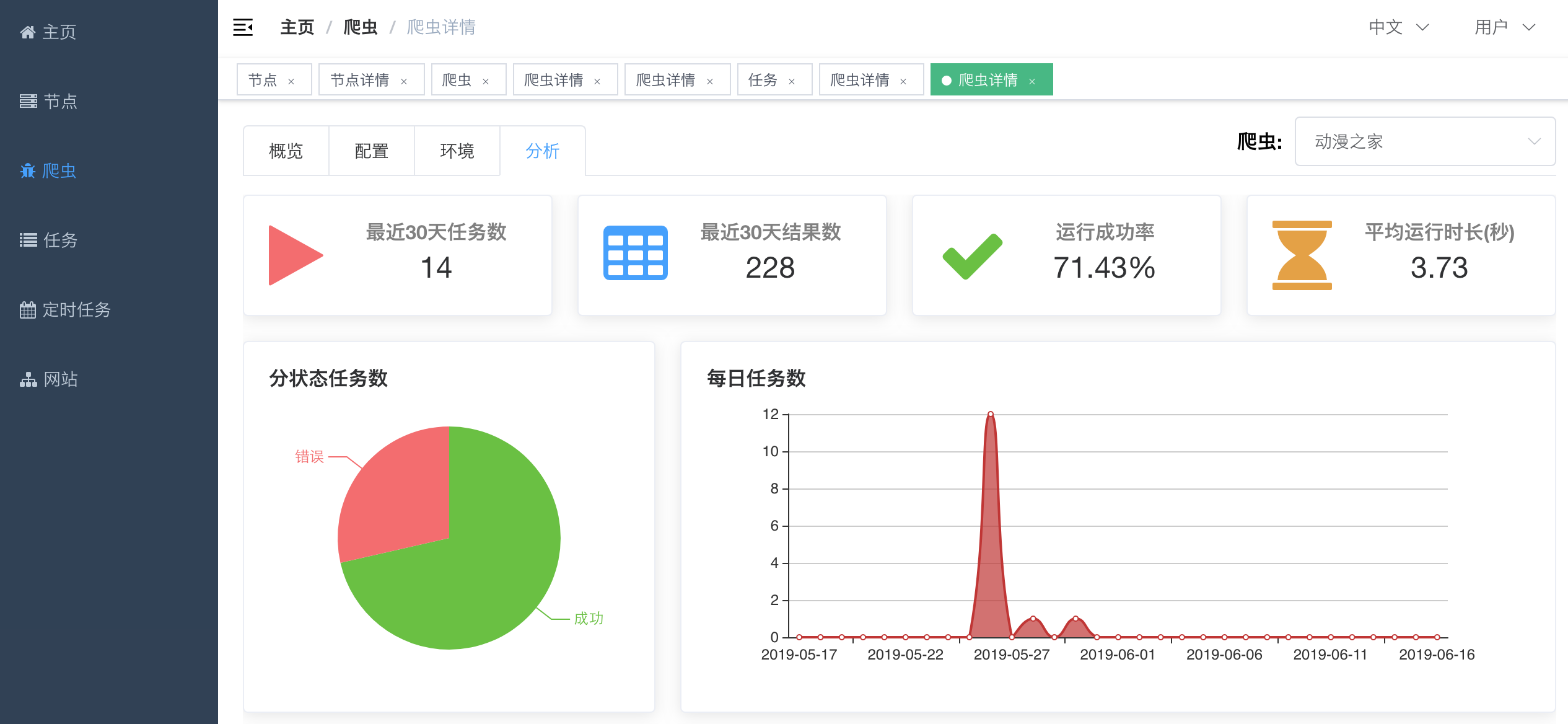
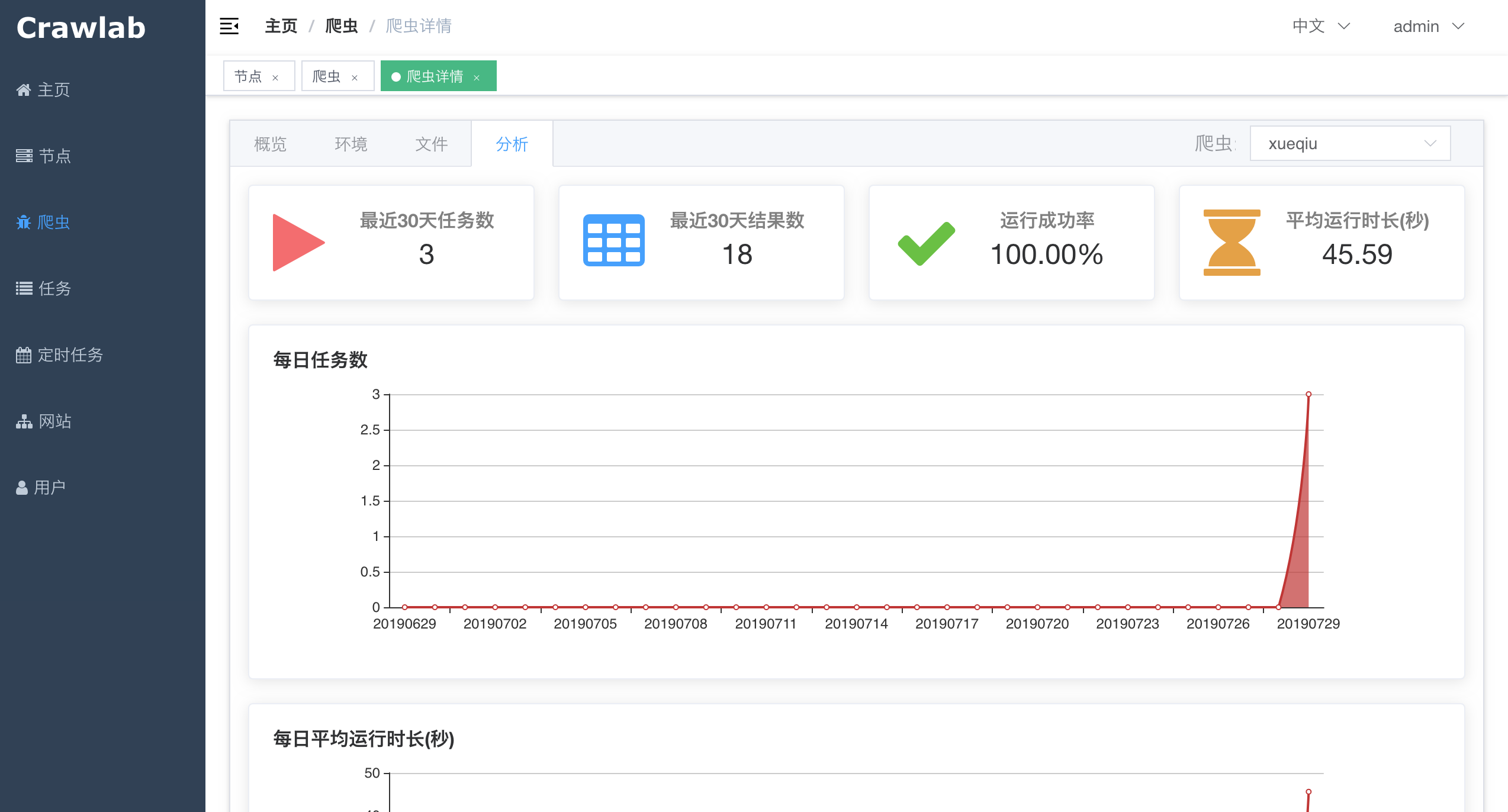
#### 爬虫详情 - 分析
|
||||
#### 爬虫分析
|
||||
|
||||
|
||||
|
||||
|
||||
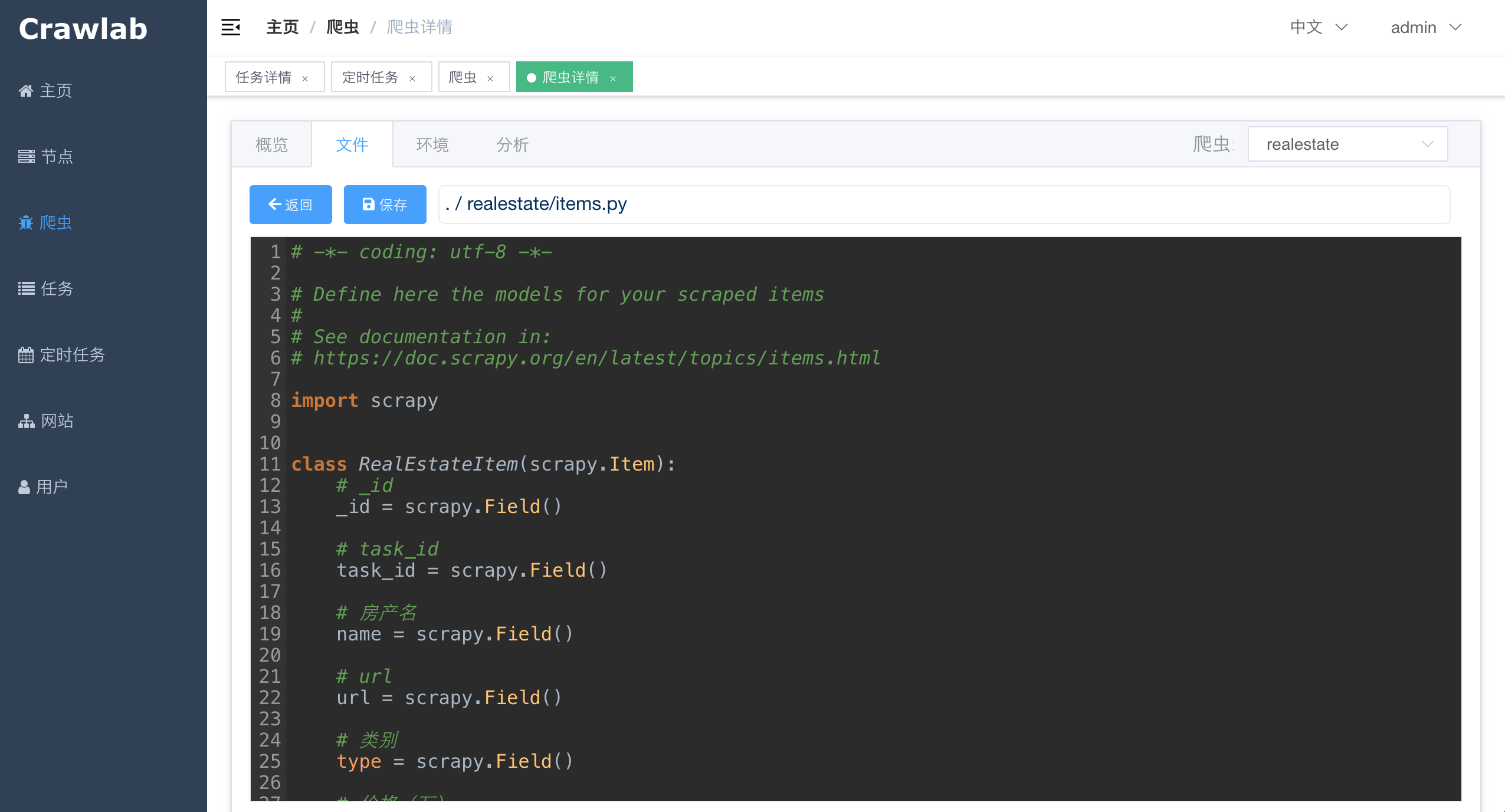
#### 爬虫文件
|
||||
|
||||
|
||||
|
||||
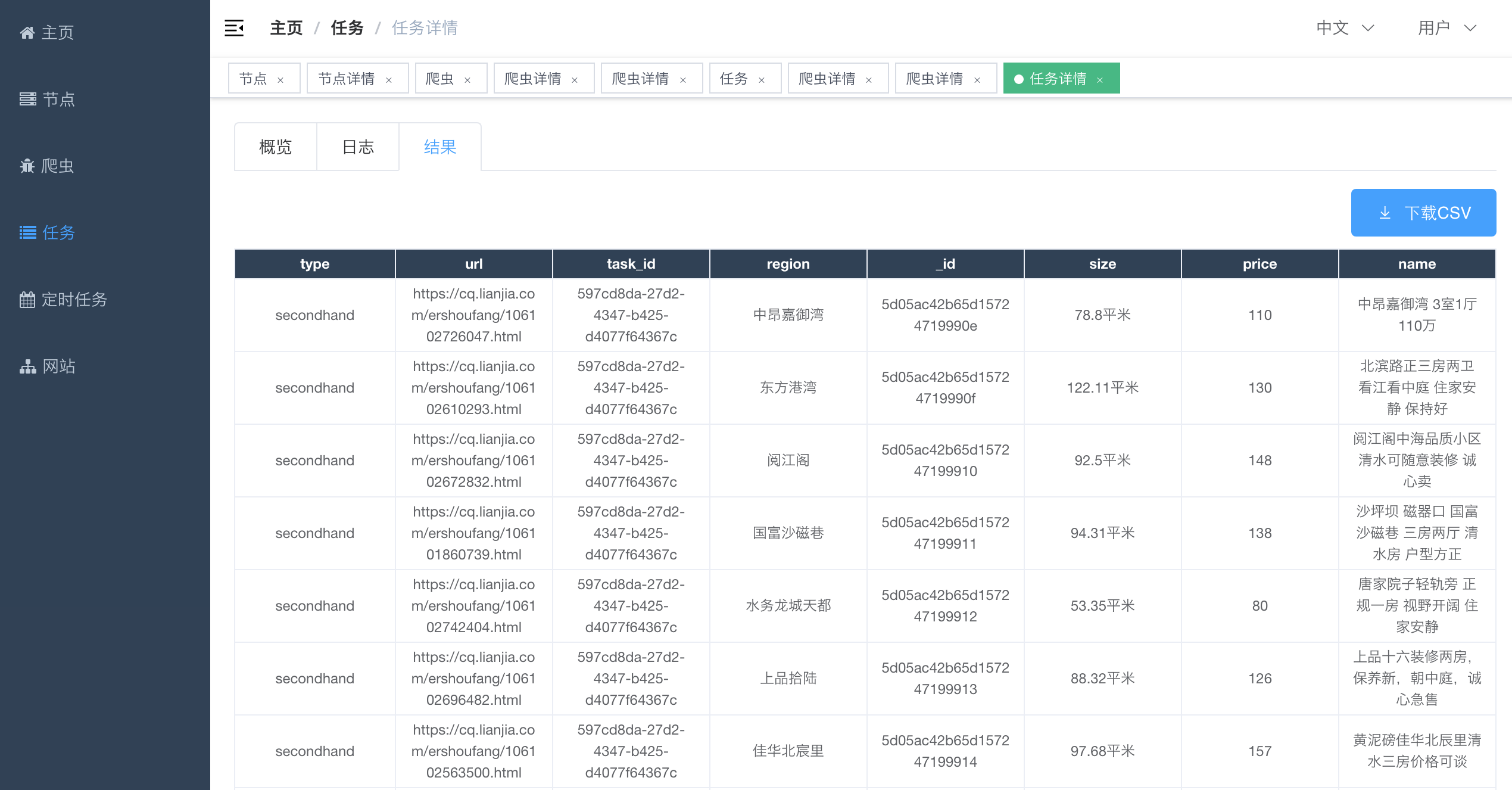
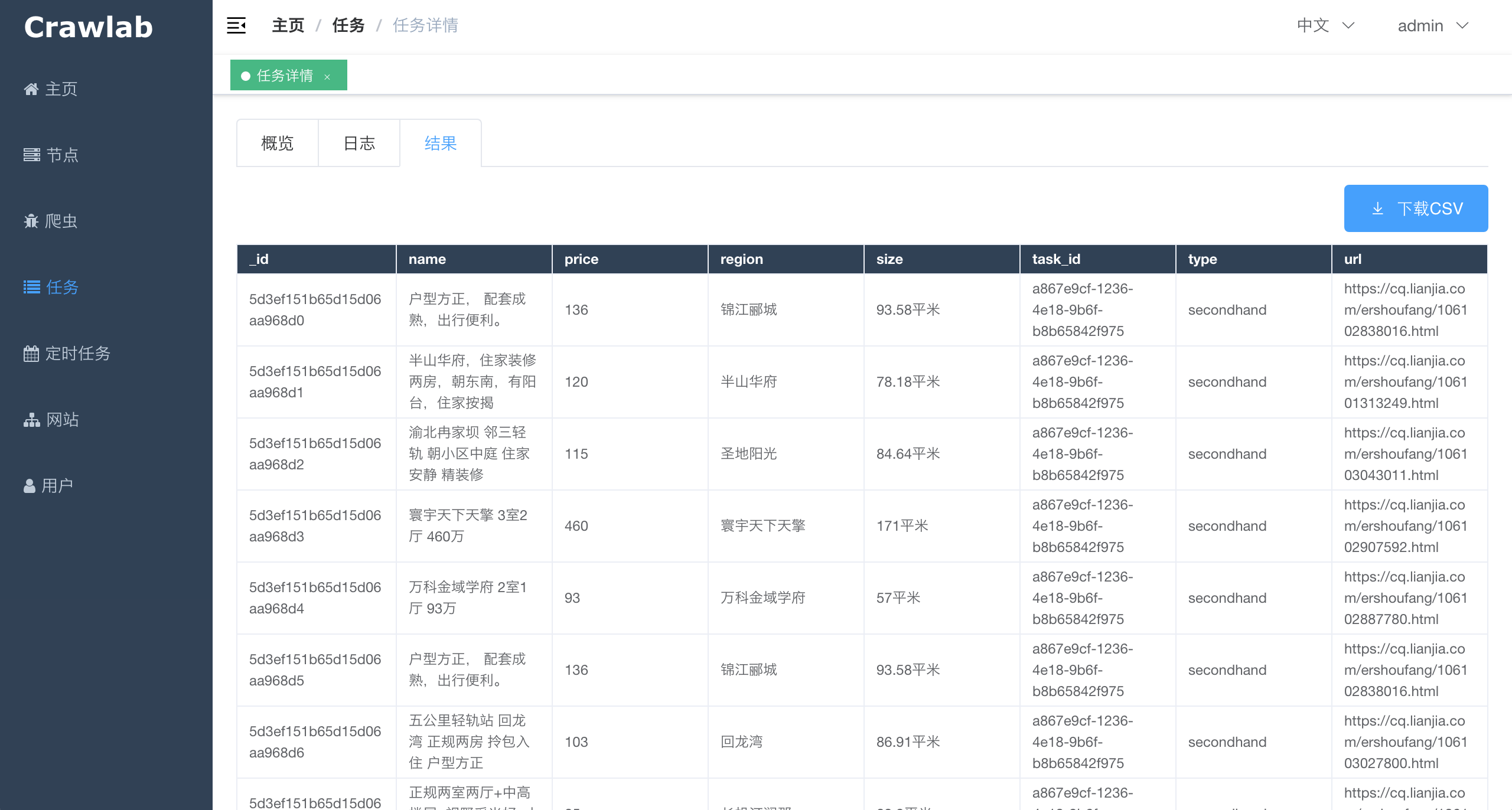
#### 任务详情 - 抓取结果
|
||||
|
||||
|
||||
|
||||
|
||||
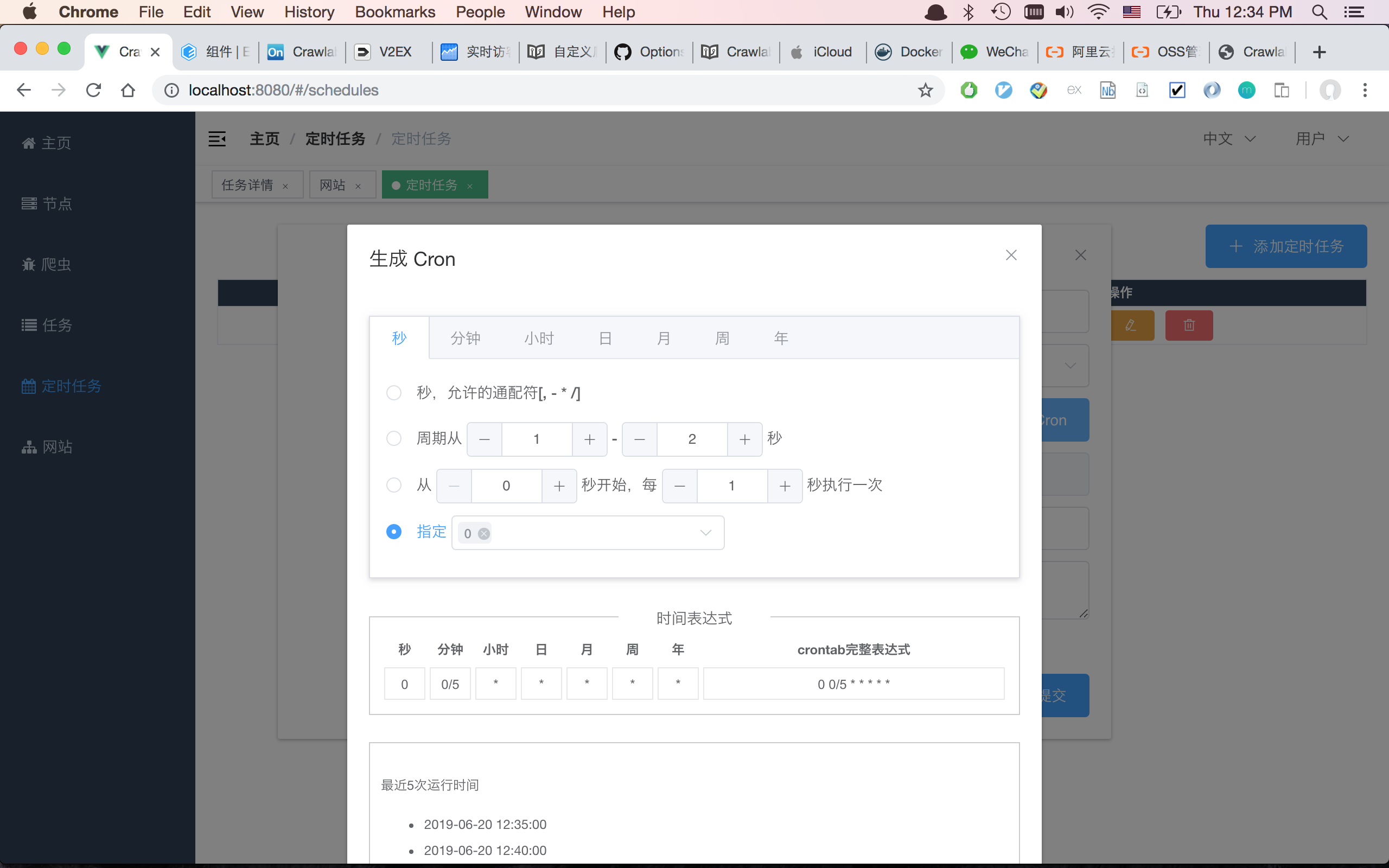
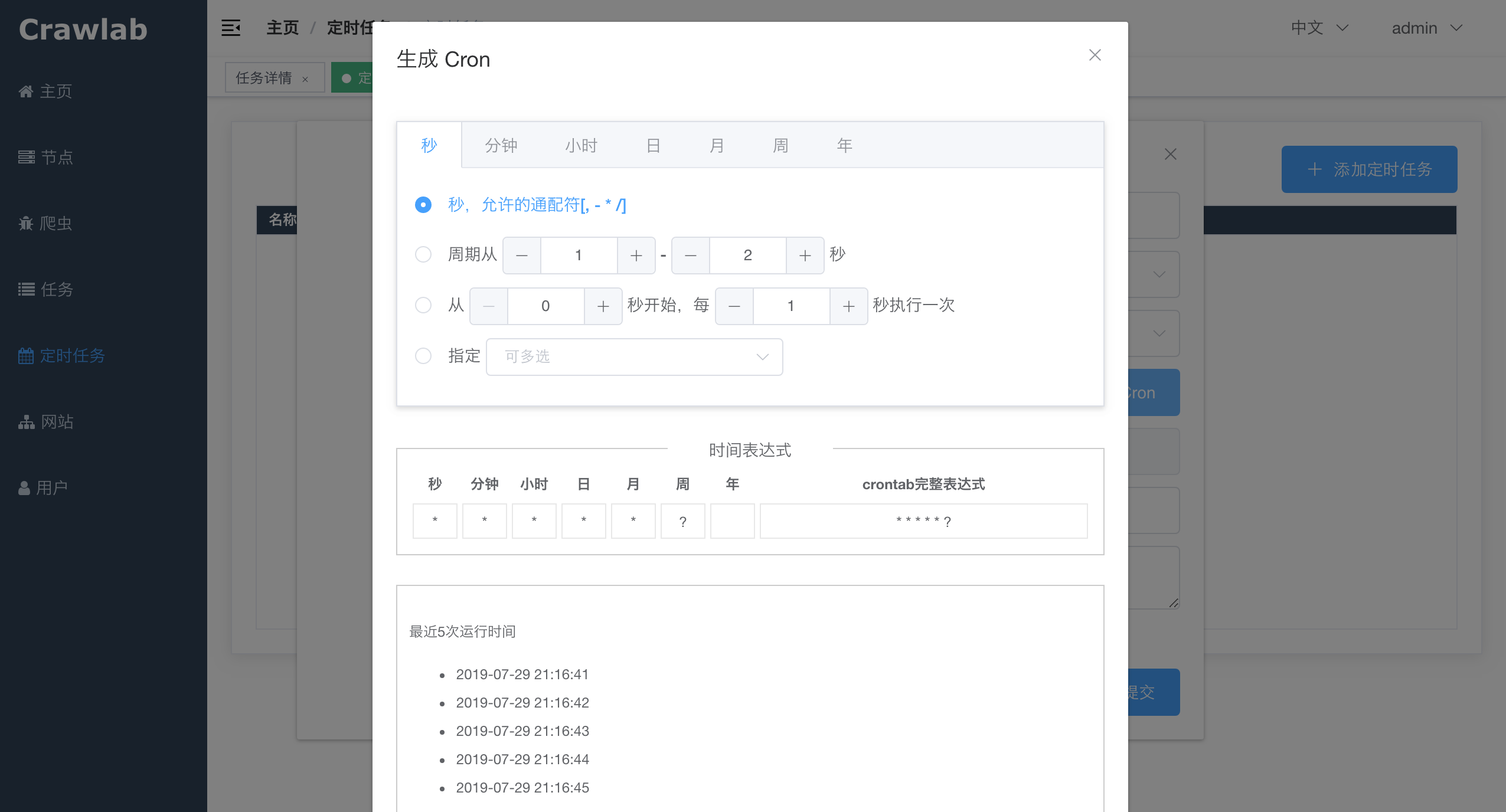
#### 定时任务
|
||||
|
||||
|
||||
|
||||
|
||||
## 架构
|
||||
|
||||
@@ -68,36 +111,33 @@ Crawlab的架构包括了一个主节点(Master Node)和多个工作节点
|
||||
2. 工作节点管理和通信
|
||||
3. 爬虫部署
|
||||
4. 前端以及API服务
|
||||
5. 执行任务(可以将主节点当成工作节点)
|
||||
|
||||
主节点负责与前端应用进行通信,并通过Redis将爬虫任务派发给工作节点。同时,主节点会同步(部署)爬虫给工作节点,通过Redis和MongoDB的GridFS。
|
||||
|
||||
### 工作节点
|
||||
|
||||
工作节点的主要功能是执行爬虫任务和储存抓取数据与日志,并且通过Redis的PubSub跟主节点通信。
|
||||
工作节点的主要功能是执行爬虫任务和储存抓取数据与日志,并且通过Redis的`PubSub`跟主节点通信。通过增加工作节点数量,Crawlab可以做到横向扩展,不同的爬虫任务可以分配到不同的节点上执行。
|
||||
|
||||
### 爬虫 Spider
|
||||
### MongoDB
|
||||
|
||||
爬虫源代码或配置规则储存在`App`上,需要被部署到各个`worker`节点中。
|
||||
MongoDB是Crawlab的运行数据库,储存有节点、爬虫、任务、定时任务等数据,另外GridFS文件储存方式是主节点储存爬虫文件并同步到工作节点的中间媒介。
|
||||
|
||||
### 任务 Task
|
||||
### Redis
|
||||
|
||||
任务被触发并被节点执行。用户可以在任务详情页面中看到任务到状态、日志和抓取结果。
|
||||
Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点间数据通信的功能。例如,节点会将自己信息通过`HSET`储存在Redis的`nodes`哈希列表中,主节点根据哈希列表来判断在线节点。
|
||||
|
||||
### 前端 Frontend
|
||||
### 前端
|
||||
|
||||
前端是一个基于[Vue-Element-Admin](https://github.com/PanJiaChen/vue-element-admin)的单页应用。其中重用了很多Element-UI的控件来支持相应的展示。
|
||||
|
||||
### Flower
|
||||
|
||||
一个Celery的插件,用于监控Celery节点。
|
||||
|
||||
## 与其他框架的集成
|
||||
|
||||
任务是利用python的`subprocess`模块中的`Popen`来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。
|
||||
爬虫任务本质上是由一个shell命令来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。另外,`CRAWLAB_COLLECTION`是Crawlab传过来的所存放collection的名称。
|
||||
|
||||
在你的爬虫程序中,你需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
|
||||
在爬虫程序中,需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中`CRAWLAB_COLLECTION`的collection中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
|
||||
|
||||
### Scrapy
|
||||
### 集成Scrapy
|
||||
|
||||
以下是Crawlab跟Scrapy集成的例子,利用了Crawlab传过来的task_id和collection_name。
|
||||
|
||||
@@ -135,11 +175,20 @@ Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流
|
||||
|框架 | 类型 | 分布式 | 前端 | 依赖于Scrapyd |
|
||||
|:---:|:---:|:---:|:---:|:---:|
|
||||
| [Crawlab](https://github.com/tikazyq/crawlab) | 管理平台 | Y | Y | N
|
||||
| [Gerapy](https://github.com/Gerapy/Gerapy) | 管理平台 | Y | Y | Y
|
||||
| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | 管理平台 | Y | Y | Y
|
||||
| [ScrapydWeb](https://github.com/my8100/scrapydweb) | 管理平台 | Y | Y | Y
|
||||
| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | 管理平台 | Y | Y | Y
|
||||
| [Gerapy](https://github.com/Gerapy/Gerapy) | 管理平台 | Y | Y | Y
|
||||
| [Scrapyd](https://github.com/scrapy/scrapyd) | 网络服务 | Y | N | N/A
|
||||
|
||||
## 相关文章
|
||||
|
||||
- [爬虫管理平台Crawlab部署指南(Docker and more)](https://juejin.im/post/5d01027a518825142939320f)
|
||||
- [[爬虫手记] 我是如何在3分钟内开发完一个爬虫的](https://juejin.im/post/5ceb4342f265da1bc8540660)
|
||||
- [手把手教你如何用Crawlab构建技术文章聚合平台(二)](https://juejin.im/post/5c92365d6fb9a070c5510e71)
|
||||
- [手把手教你如何用Crawlab构建技术文章聚合平台(一)](https://juejin.im/user/5a1ba6def265da430b7af463/posts)
|
||||
|
||||
**注意: v0.3.0版本已将基于Celery的Python版本切换为了Golang版本,如何部署请参照文档**
|
||||
|
||||
## 社区 & 赞助
|
||||
|
||||
如果您觉得Crawlab对您的日常开发或公司有帮助,请加作者微信 tikazyq1 并注明"Crawlab",作者会将你拉入群。或者,您可以扫下方支付宝二维码给作者打赏去升级团队协作软件或买一杯咖啡。
|
||||
|
||||
Reference in New Issue
Block a user