mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-22 17:31:03 +01:00
20
CHANGELOG.md
20
CHANGELOG.md
@@ -1,4 +1,22 @@
|
||||
# 0.2.4 (unreleased)
|
||||
# 0.3.0 (2019-07-31)
|
||||
### Features / Enhancement
|
||||
- **Golang Backend**: Refactored code from Python backend to Golang, much more stability and performance.
|
||||
- **Node Network Graph**: Visualization of node typology.
|
||||
- **Node System Info**: Available to see system info including OS, CPUs and executables.
|
||||
- **Node Monitoring Enhancement**: Nodes are monitored and registered through Redis.
|
||||
- **File Management**: Available to edit spider files online, including code highlight.
|
||||
- **Login/Regiser/User Management**: Require users to login to use Crawlab, allow user registration and user management, some role-based authorization.
|
||||
- **Automatic Spider Deployment**: Spiders are deployed/synchronized to all online nodes automatically.
|
||||
- **Smaller Docker Image**: Slimmed Docker image and reduced Docker image size from 1.3G to \~700M by applying Multi-Stage Build.
|
||||
|
||||
### Bug Fixes
|
||||
- **Node Status**. Node status does not change even though it goes offline actually. [#87](https://github.com/tikazyq/crawlab/issues/87)
|
||||
- **Spider Deployment Error**. Fixed through Automatic Spider Deployment [#83](https://github.com/tikazyq/crawlab/issues/83)
|
||||
- **Node not showing**. Node not able to show online [#81](https://github.com/tikazyq/crawlab/issues/81)
|
||||
- **Cron Job not working**. Fixed through new Golang backend [#64](https://github.com/tikazyq/crawlab/issues/64)
|
||||
- **Flower Error**. Fixed through new Golang backend [#57](https://github.com/tikazyq/crawlab/issues/57)
|
||||
|
||||
# 0.2.4 (2019-07-07)
|
||||
### Features / Enhancement
|
||||
- **Documentation**: Better and much more detailed documentation.
|
||||
- **Better Crontab**: Make crontab expression through crontab UI.
|
||||
|
||||
123
README-zh.md
123
README-zh.md
@@ -6,50 +6,101 @@
|
||||
<img src="https://img.shields.io/badge/License-BSD-blue.svg">
|
||||
</a>
|
||||
|
||||
中文 | [English](https://github.com/tikazyq/crawlab/blob/master/README.md)
|
||||
中文 | [English](https://github.com/tikazyq/crawlab)
|
||||
|
||||
基于Golang的分布式爬虫管理平台,支持Python、NodeJS、Go、Java、PHP等多种编程语言以及多种爬虫框架。
|
||||
|
||||
[查看演示 Demo](http://114.67.75.98:8080) | [文档](https://tikazyq.github.io/crawlab-docs)
|
||||
|
||||
## 要求
|
||||
- Go 1.12+
|
||||
- Node.js 8.12+
|
||||
- MongoDB 3.6+
|
||||
- Redis
|
||||
|
||||
## 安装
|
||||
|
||||
三种方式:
|
||||
1. [Docker](https://tikazyq.github.io/crawlab/Installation/Docker.md)(推荐)
|
||||
2. [直接部署](https://tikazyq.github.io/crawlab/Installation/Direct.md)
|
||||
3. [预览模式](https://tikazyq.github.io/crawlab/Installation/Direct.md)(快速体验)
|
||||
2. [直接部署](https://tikazyq.github.io/crawlab/Installation/Direct.md)(了解内核)
|
||||
|
||||
### 要求(Docker)
|
||||
- Docker 18.03+
|
||||
- Redis
|
||||
- MongoDB 3.6+
|
||||
|
||||
### 要求(直接部署)
|
||||
- Go 1.12+
|
||||
- Node 8.12+
|
||||
- Redis
|
||||
- MongoDB 3.6+
|
||||
|
||||
## 运行
|
||||
|
||||
### Docker
|
||||
|
||||
运行主节点示例。`192.168.99.1`是在Docker Machine网络中的宿主机IP地址。`192.168.99.100`是Docker主节点的IP地址。
|
||||
|
||||
```bash
|
||||
docker run -d --rm --name crawlab \
|
||||
-e CRAWLAB_REDIS_ADDRESS=192.168.99.1:6379 \
|
||||
-e CRAWLAB_MONGO_HOST=192.168.99.1 \
|
||||
-e CRAWLAB_SERVER_MASTER=Y \
|
||||
-e CRAWLAB_API_ADDRESS=192.168.99.100:8000 \
|
||||
-e CRAWLAB_SPIDER_PATH=/app/spiders \
|
||||
-p 8080:8080 \
|
||||
-p 8000:8000 \
|
||||
-v /var/logs/crawlab:/var/logs/crawlab \
|
||||
tikazyq/crawlab:0.3.0
|
||||
```
|
||||
|
||||
当然也可以用`docker-compose`来一键启动,甚至不用配置MongoDB和Redis数据库。
|
||||
|
||||
```bash
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
Docker部署的详情,请见[相关文档](https://tikazyq.github.io/crawlab/Installation/Docker.md)。
|
||||
|
||||
### 直接部署
|
||||
|
||||
请参考[相关文档](https://tikazyq.github.io/crawlab/Installation/Direct.md)。
|
||||
|
||||
## 截图
|
||||
|
||||
#### 登录
|
||||
|
||||

|
||||
|
||||
#### 首页
|
||||
|
||||
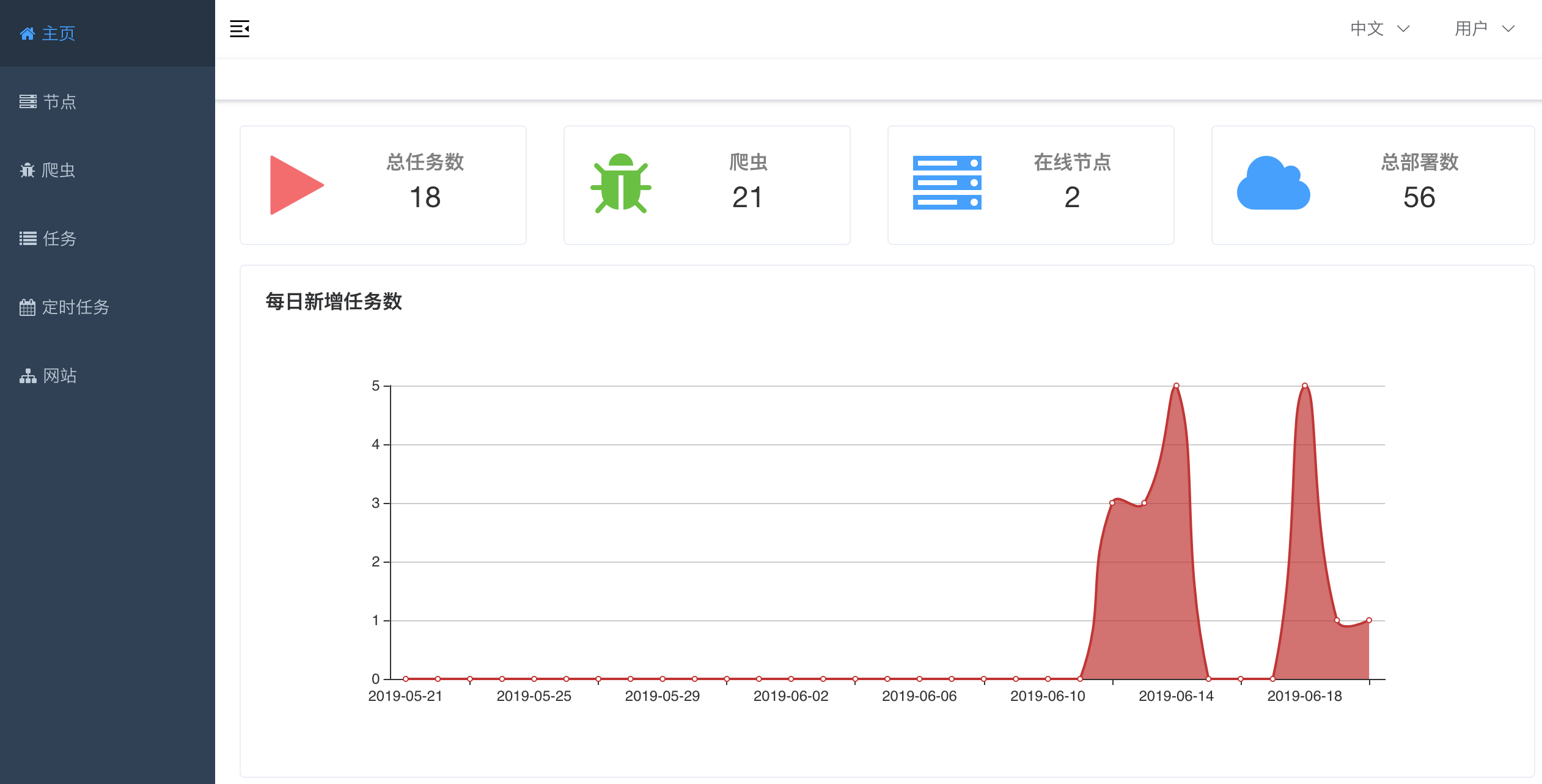
|
||||
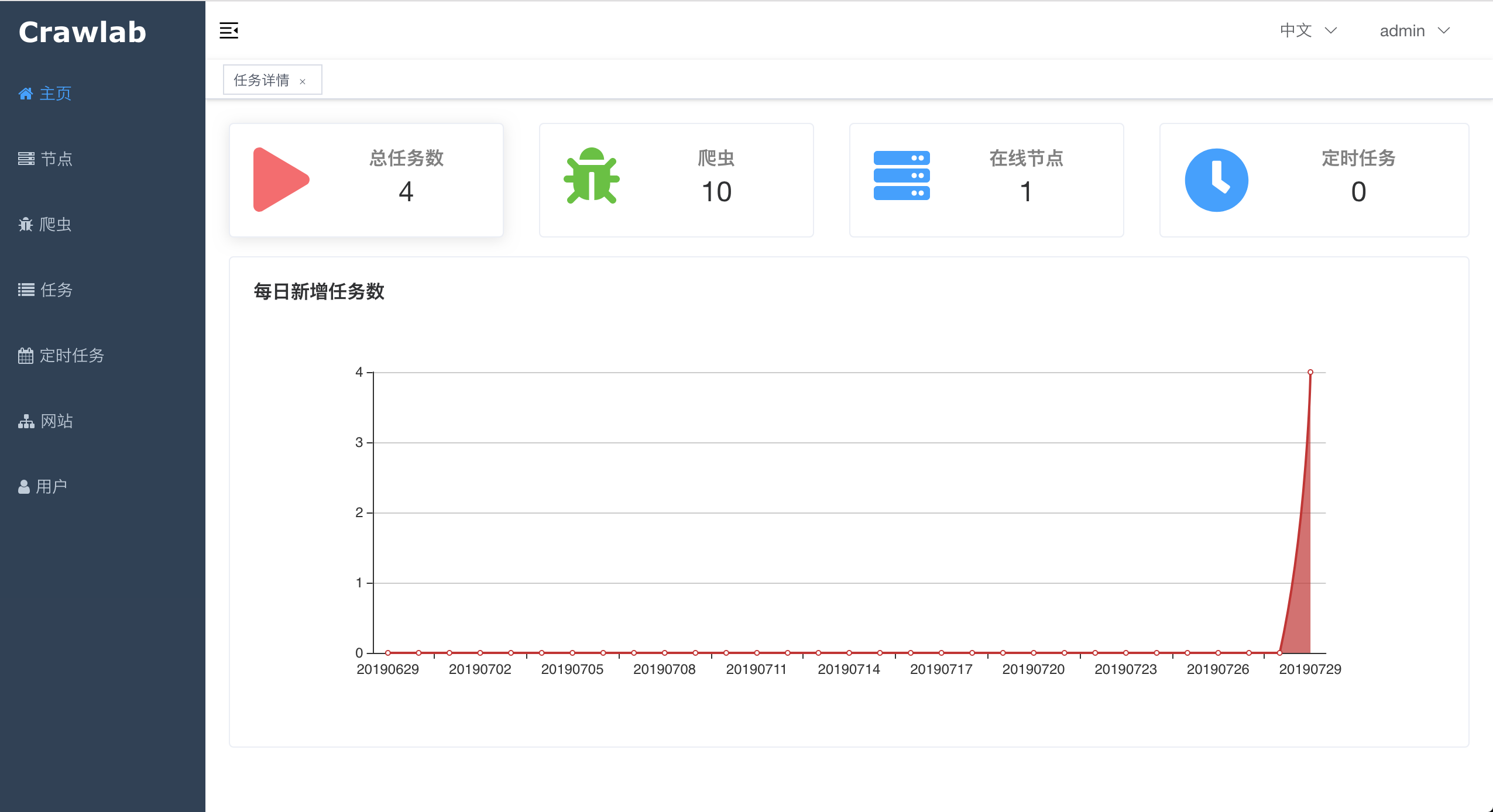
|
||||
|
||||
#### 节点列表
|
||||
|
||||
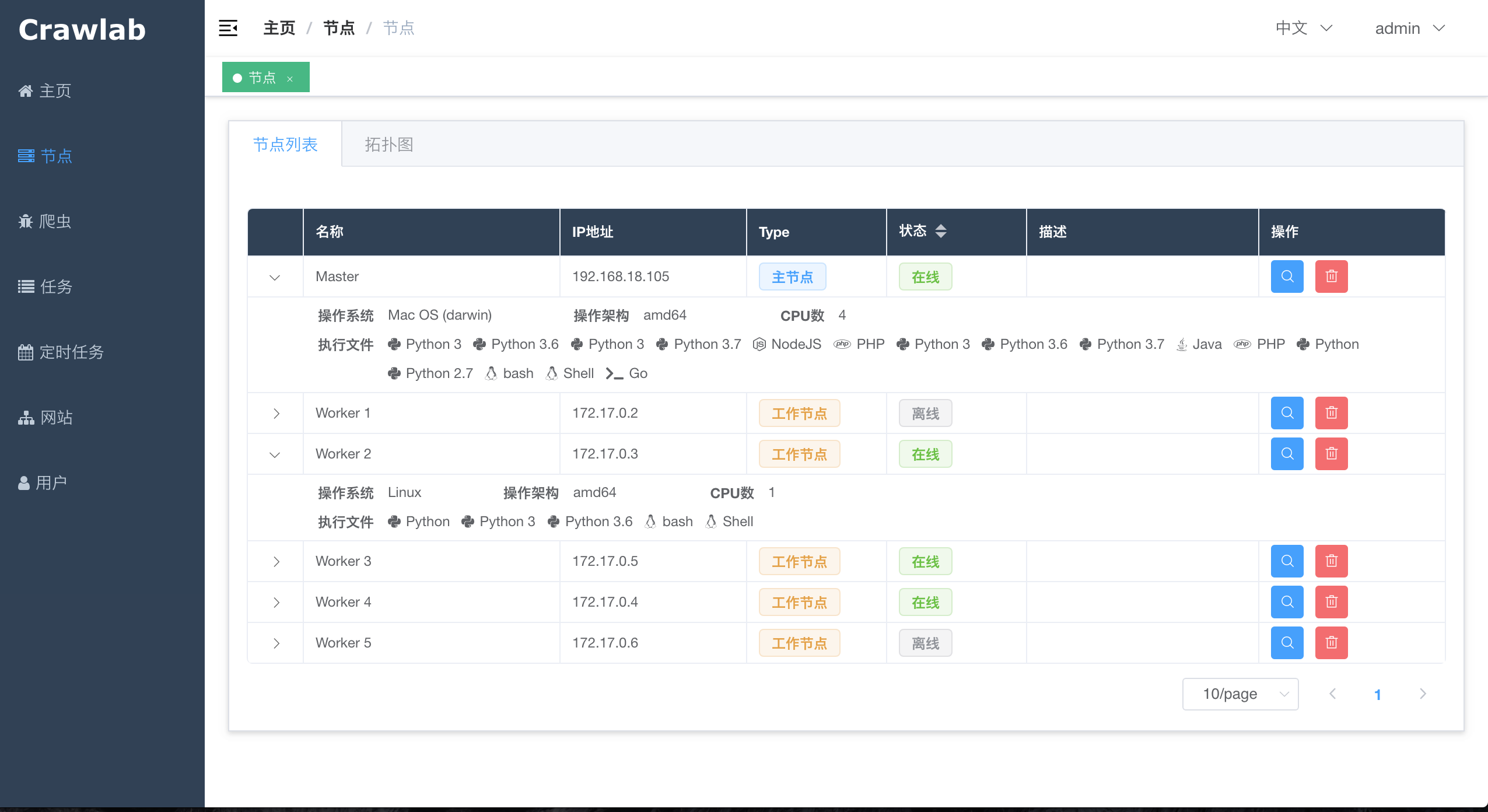
|
||||
|
||||
#### 节点拓扑图
|
||||
|
||||
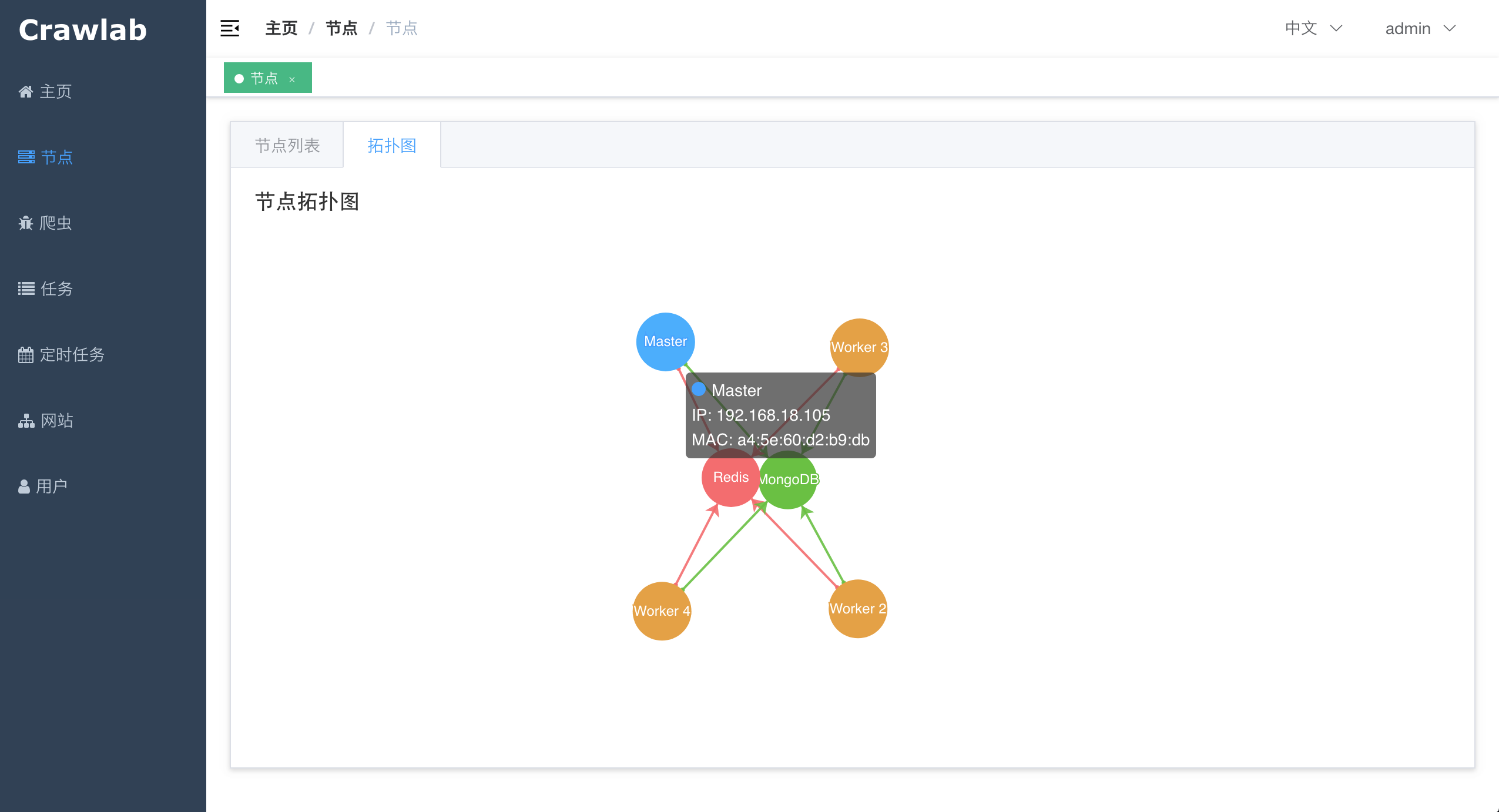
|
||||
|
||||
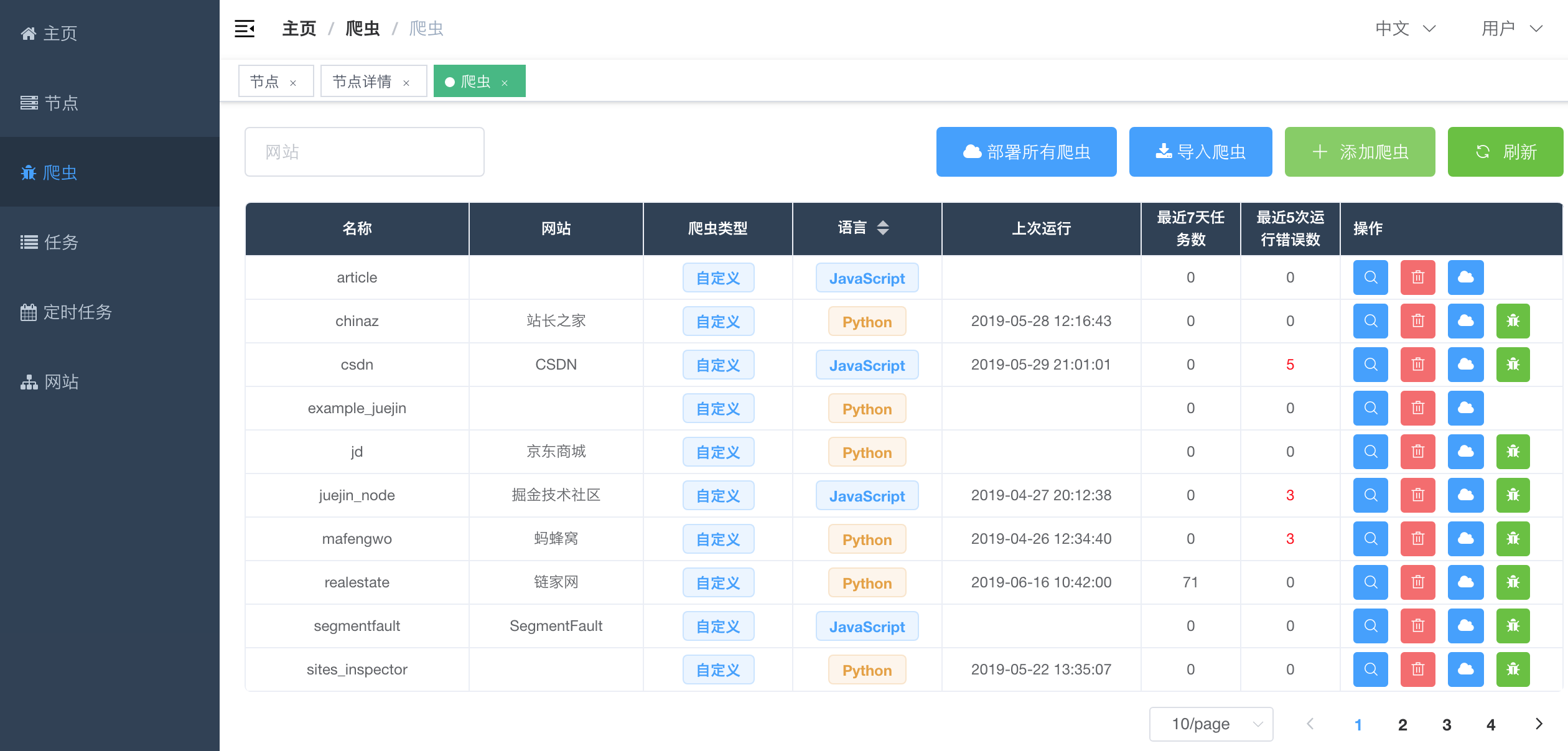
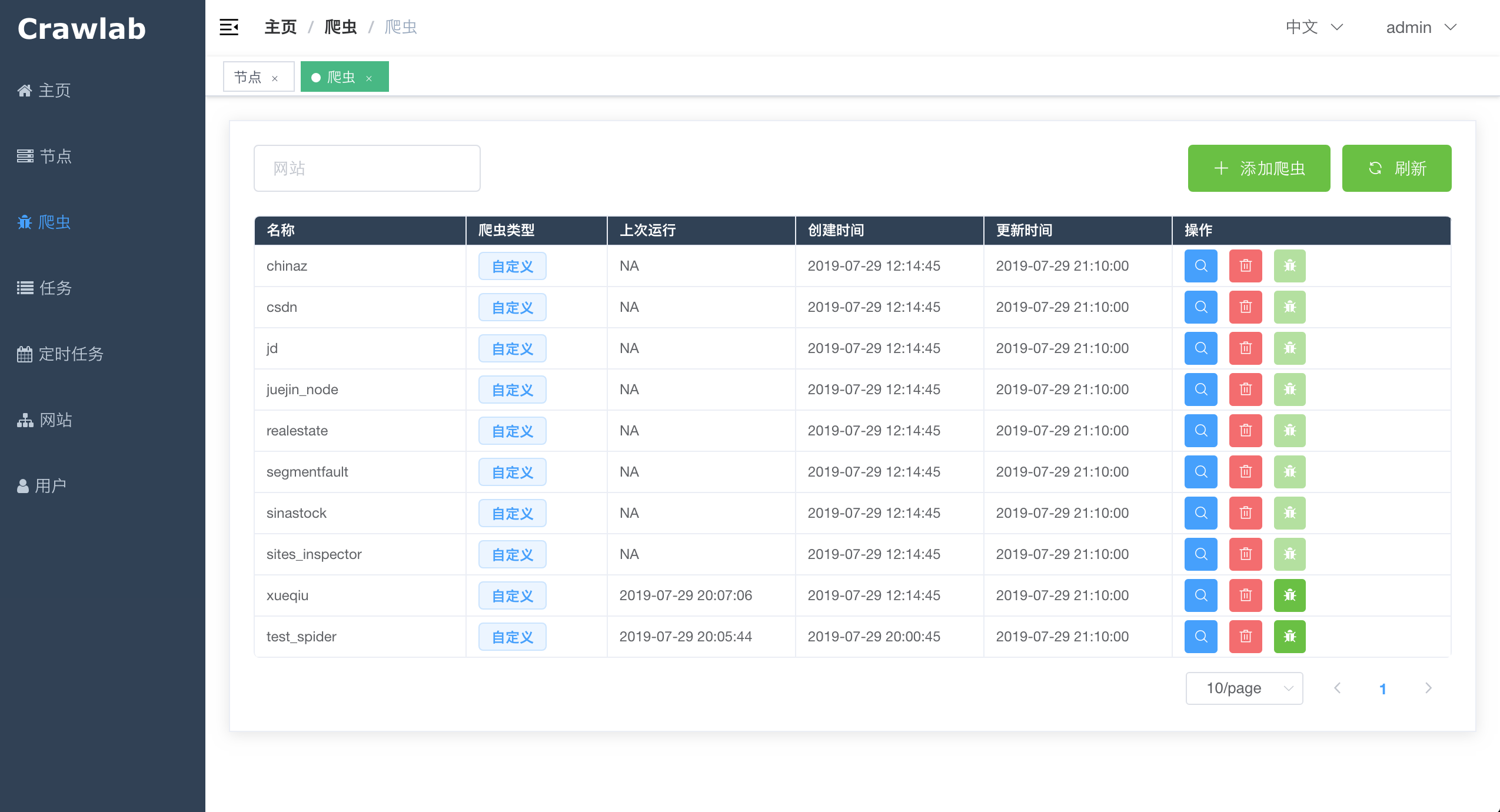
#### 爬虫列表
|
||||
|
||||
|
||||
|
||||
|
||||
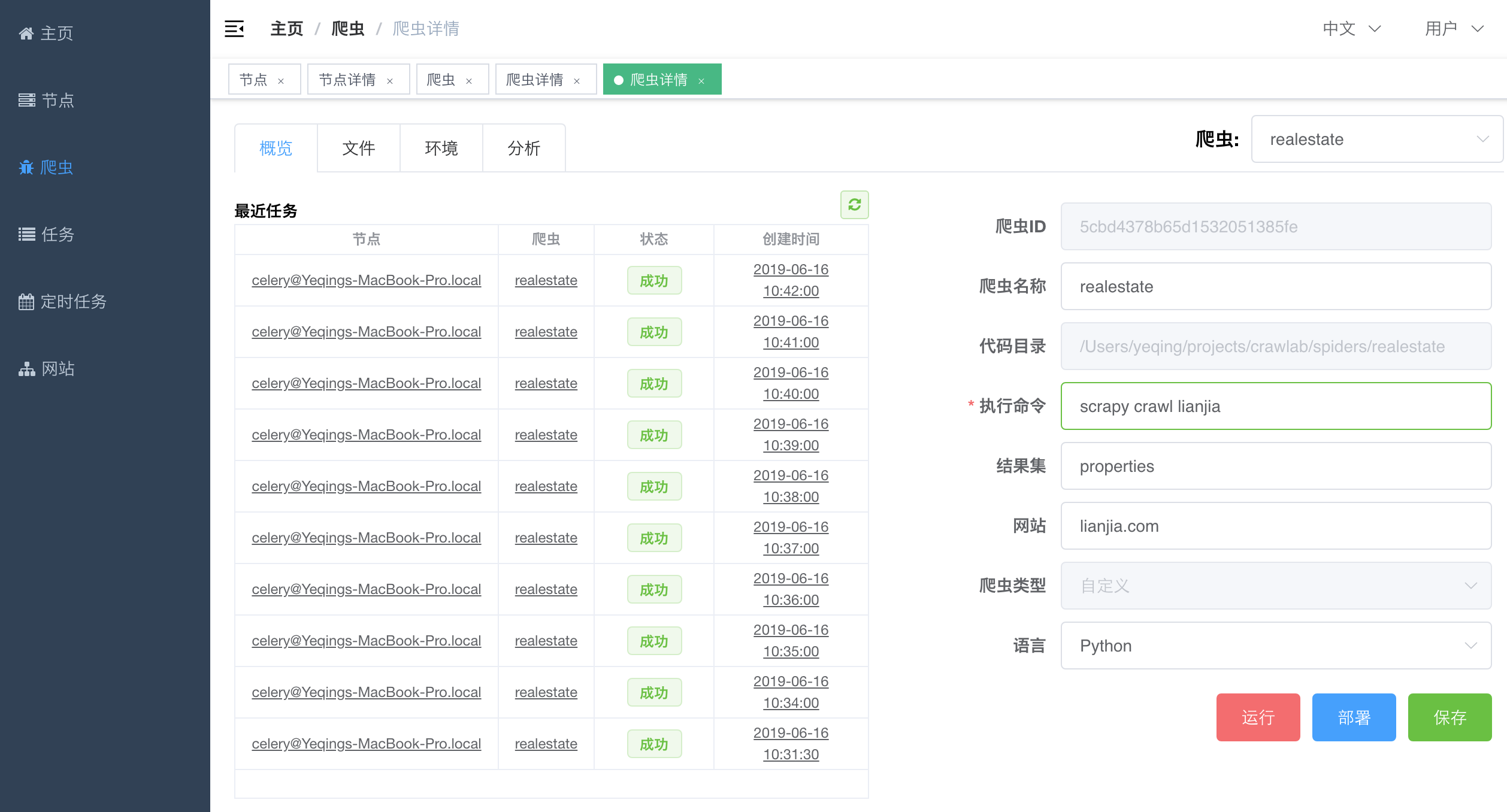
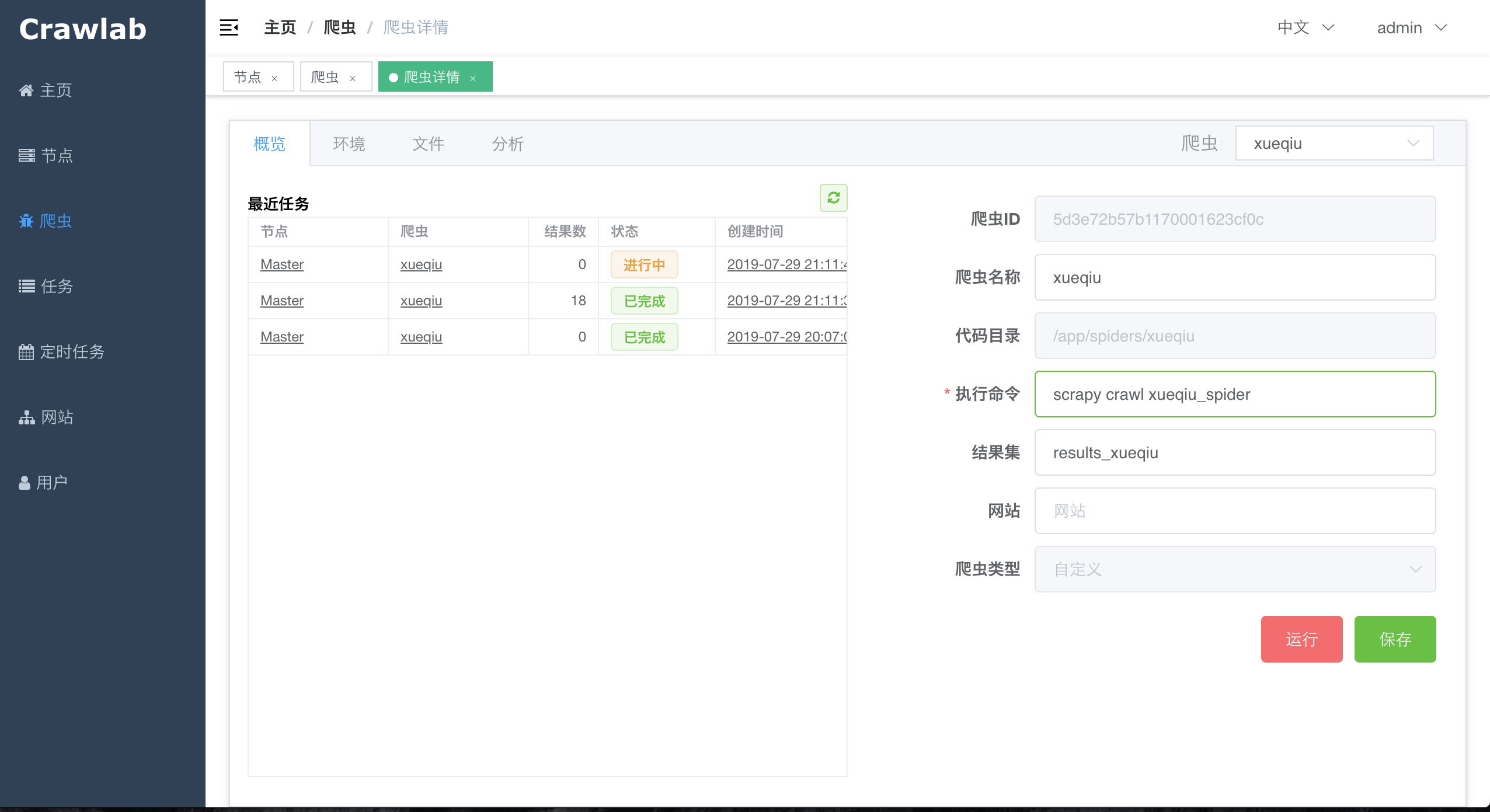
#### 爬虫详情 - 概览
|
||||
#### 爬虫概览
|
||||
|
||||
|
||||
|
||||
|
||||
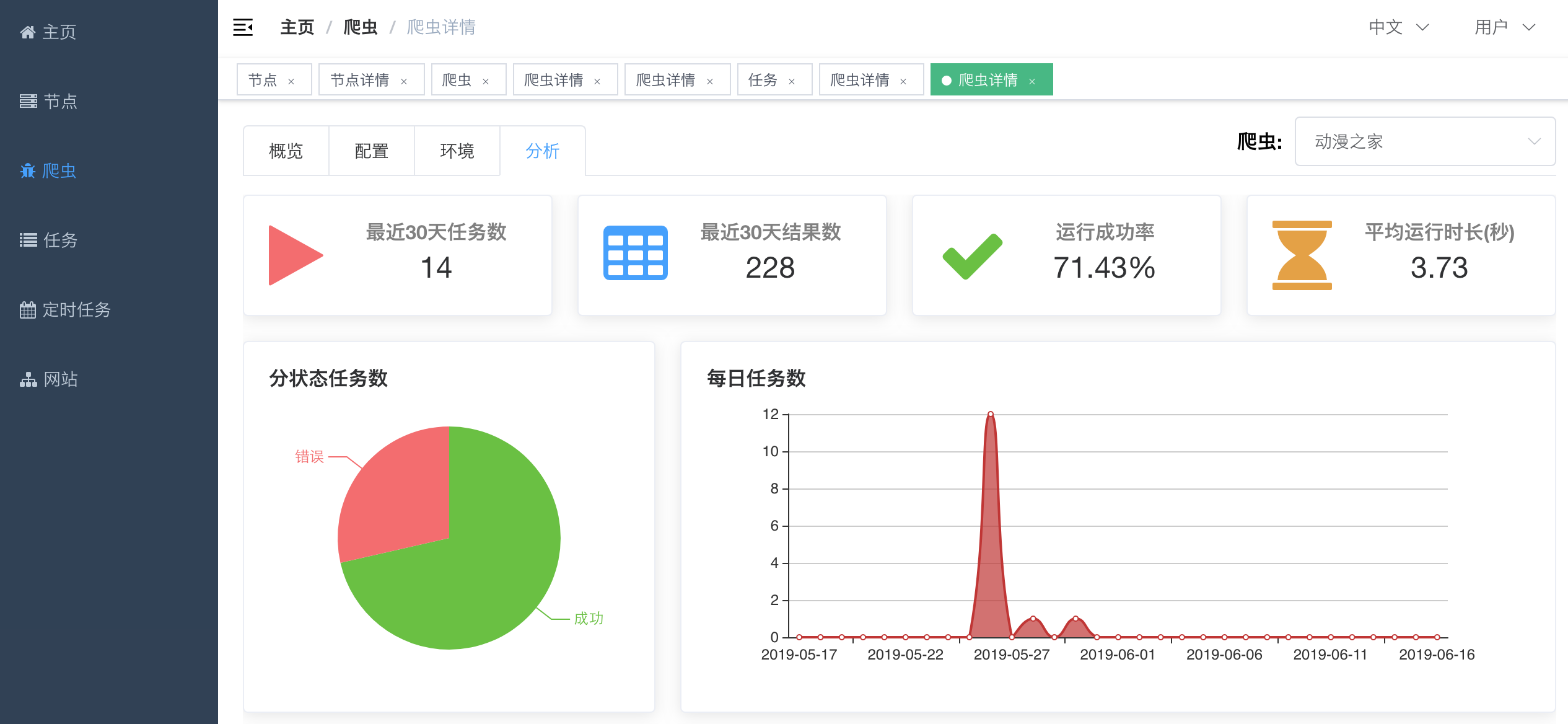
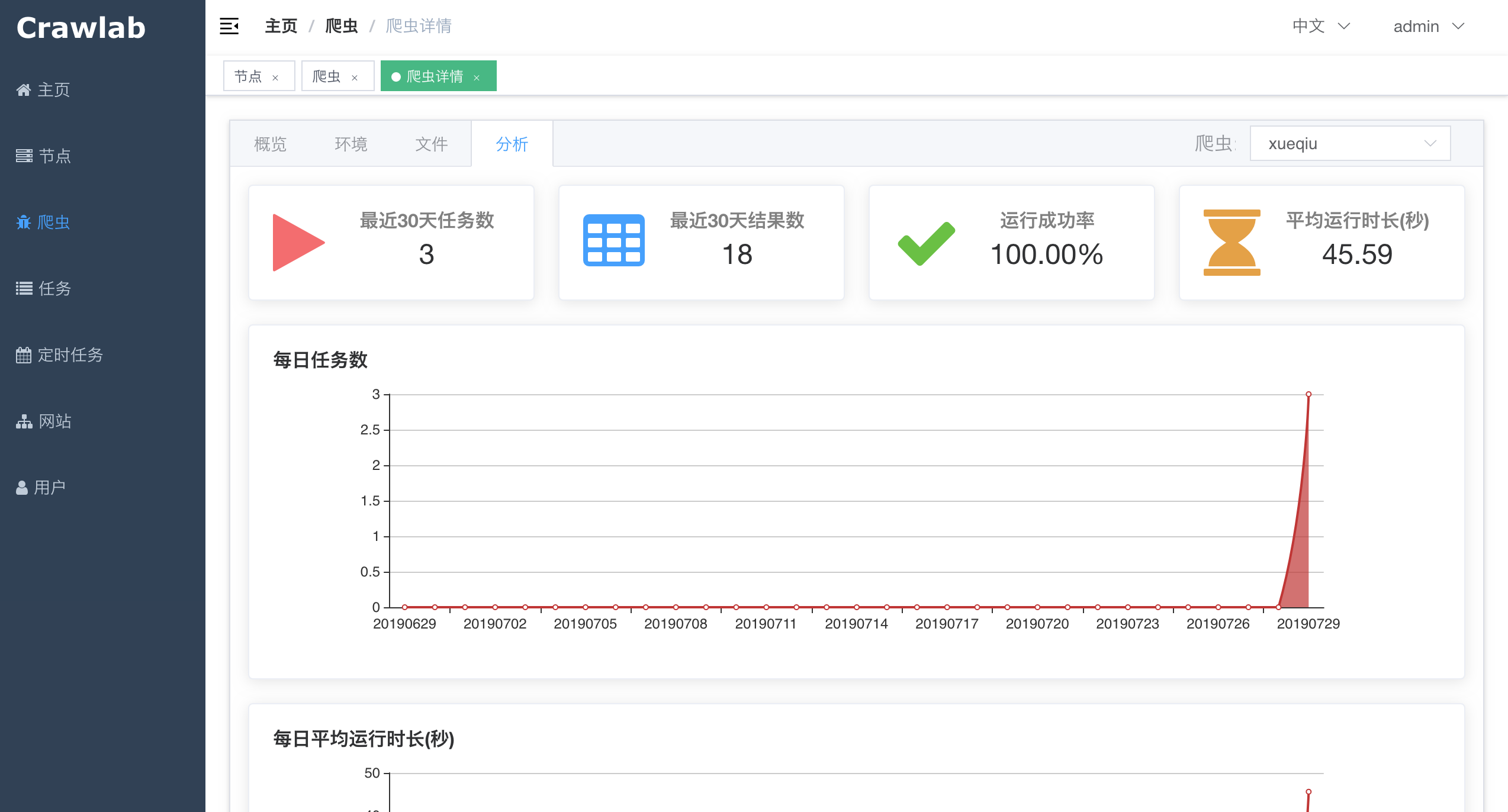
#### 爬虫详情 - 分析
|
||||
#### 爬虫分析
|
||||
|
||||
|
||||
|
||||
|
||||
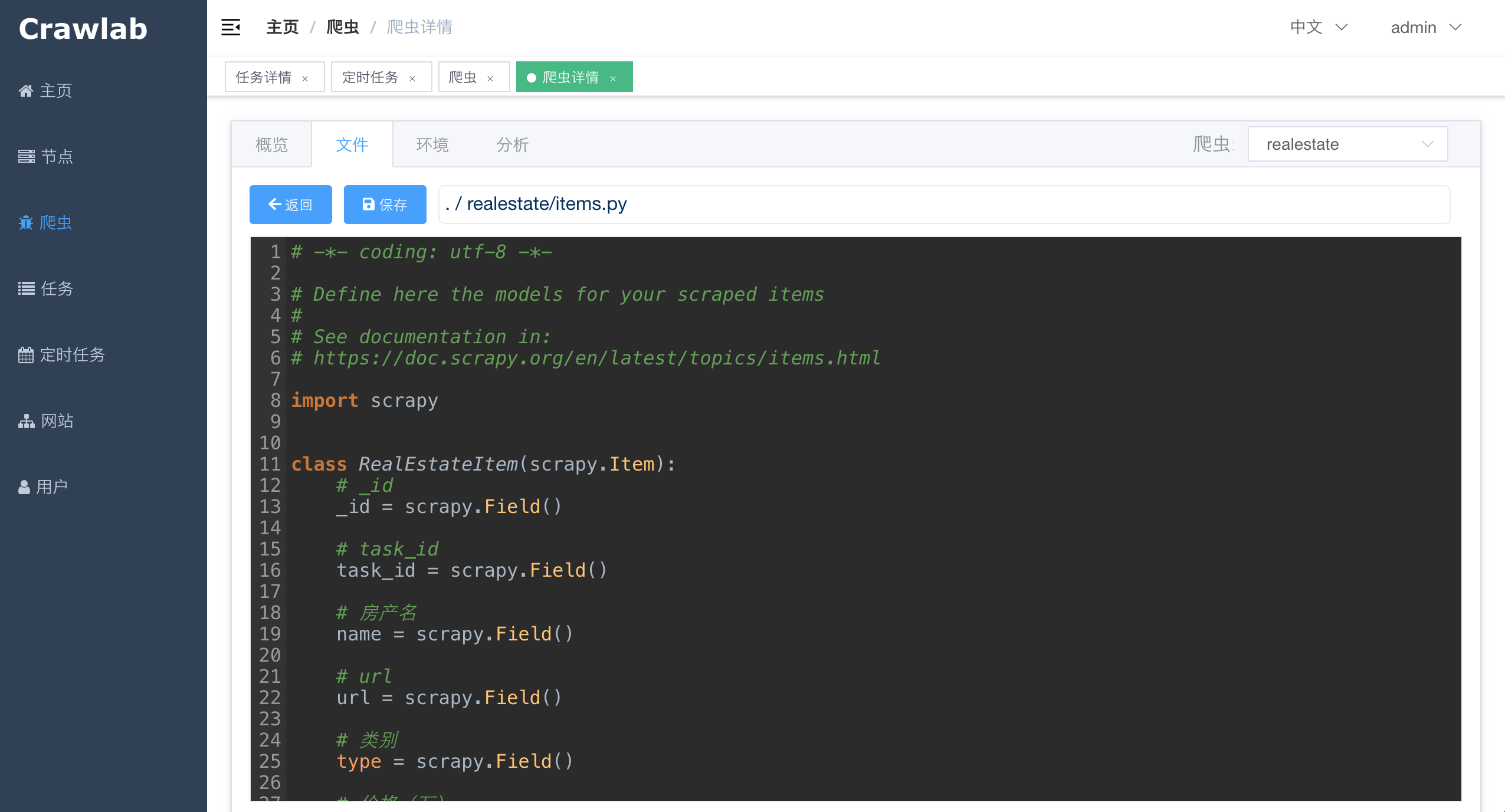
#### 爬虫文件
|
||||
|
||||
|
||||
|
||||
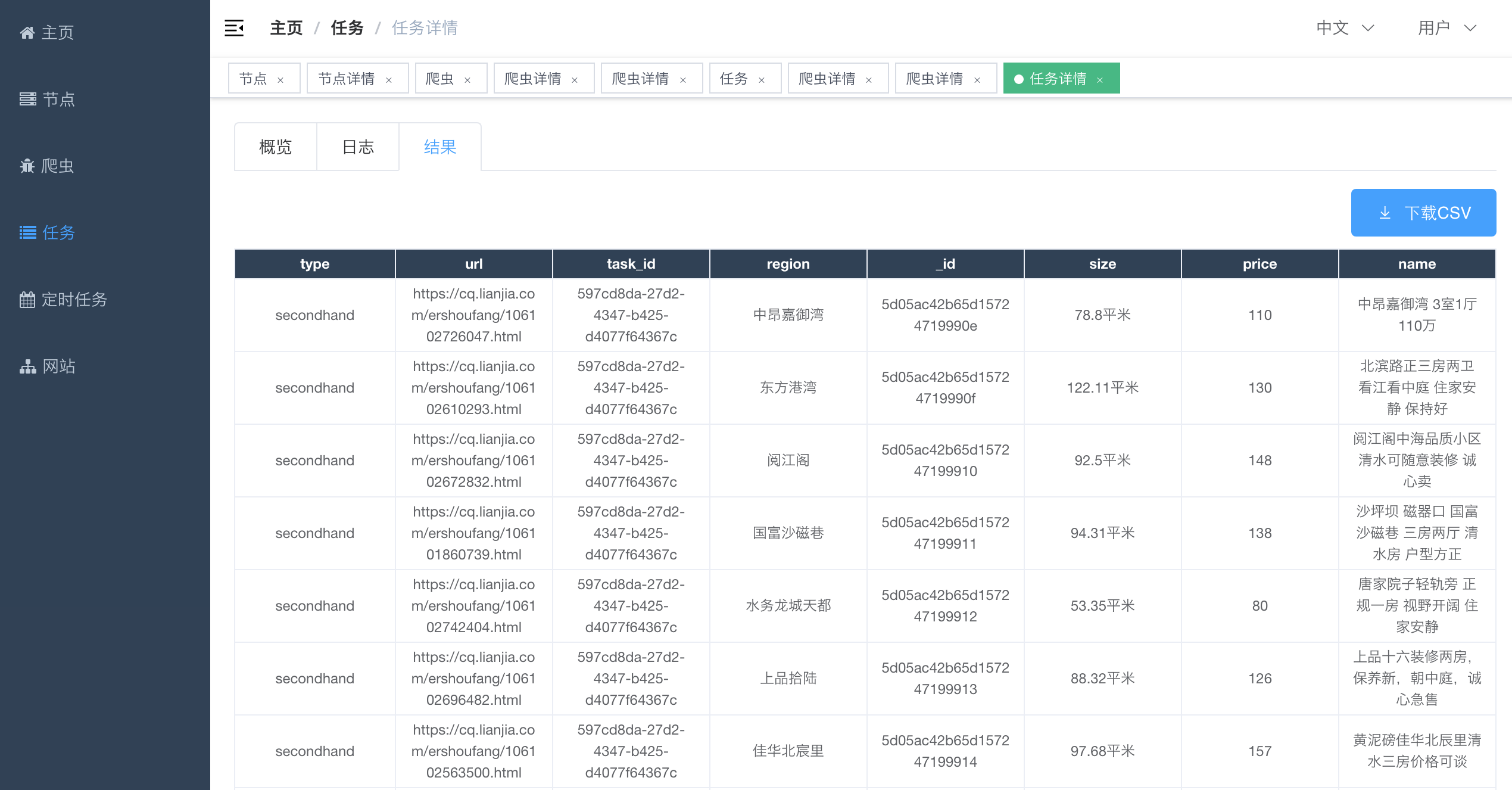
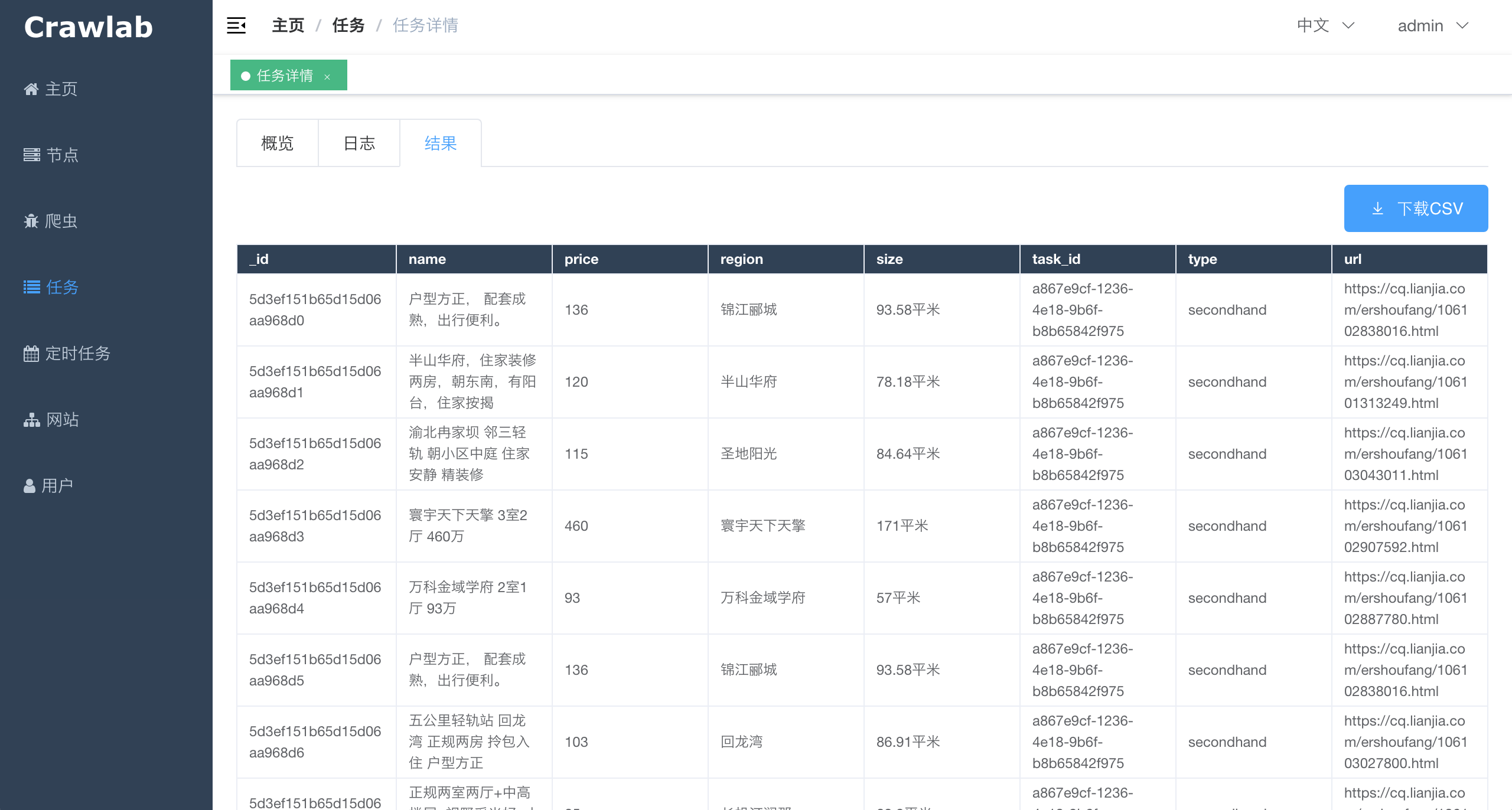
#### 任务详情 - 抓取结果
|
||||
|
||||
|
||||
|
||||
|
||||
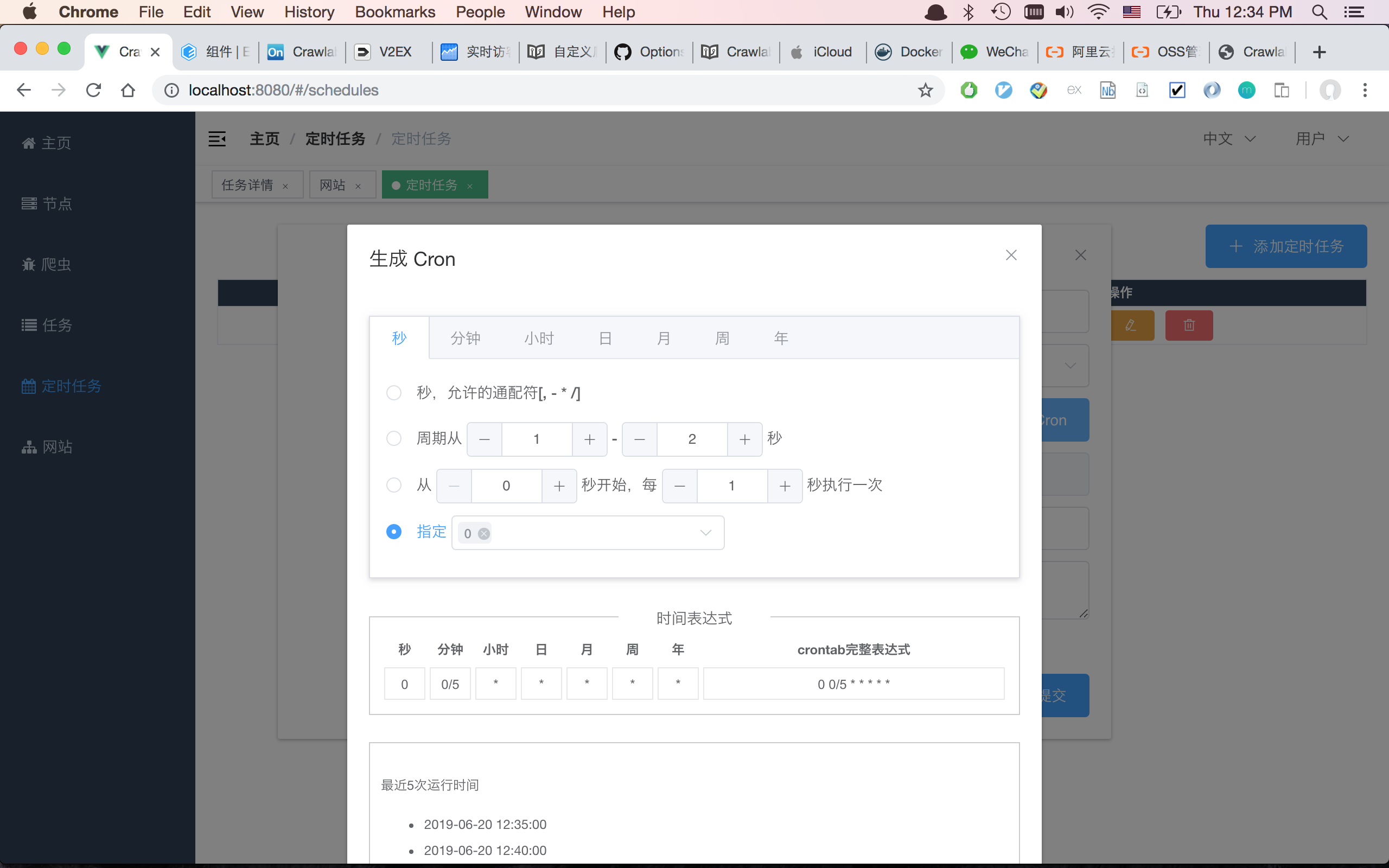
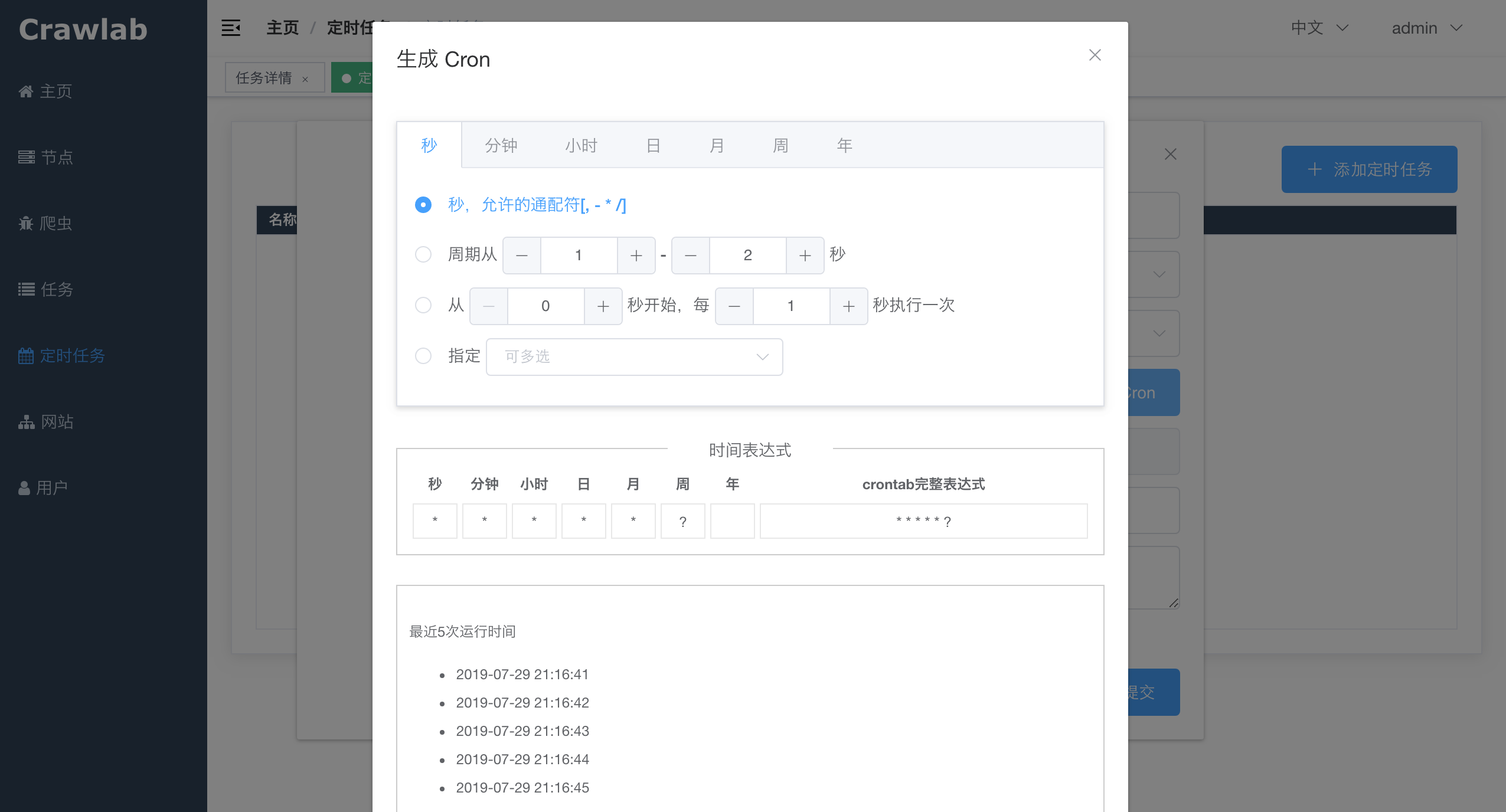
#### 定时任务
|
||||
|
||||
|
||||
|
||||
|
||||
## 架构
|
||||
|
||||
@@ -59,7 +110,7 @@ Crawlab的架构包括了一个主节点(Master Node)和多个工作节点
|
||||
|
||||
前端应用向主节点请求数据,主节点通过MongoDB和Redis来执行任务派发调度以及部署,工作节点收到任务之后,开始执行爬虫任务,并将任务结果储存到MongoDB。架构相对于`v0.3.0`之前的Celery版本有所精简,去除了不必要的节点监控模块Flower,节点监控主要由Redis完成。
|
||||
|
||||
### 主节点 Master Node
|
||||
### 主节点
|
||||
|
||||
主节点是整个Crawlab架构的核心,属于Crawlab的中控系统。
|
||||
|
||||
@@ -68,36 +119,33 @@ Crawlab的架构包括了一个主节点(Master Node)和多个工作节点
|
||||
2. 工作节点管理和通信
|
||||
3. 爬虫部署
|
||||
4. 前端以及API服务
|
||||
5. 执行任务(可以将主节点当成工作节点)
|
||||
|
||||
主节点负责与前端应用进行通信,并通过Redis将爬虫任务派发给工作节点。同时,主节点会同步(部署)爬虫给工作节点,通过Redis和MongoDB的GridFS。
|
||||
|
||||
### 工作节点
|
||||
|
||||
工作节点的主要功能是执行爬虫任务和储存抓取数据与日志,并且通过Redis的PubSub跟主节点通信。
|
||||
工作节点的主要功能是执行爬虫任务和储存抓取数据与日志,并且通过Redis的`PubSub`跟主节点通信。通过增加工作节点数量,Crawlab可以做到横向扩展,不同的爬虫任务可以分配到不同的节点上执行。
|
||||
|
||||
### 爬虫 Spider
|
||||
### MongoDB
|
||||
|
||||
爬虫源代码或配置规则储存在`App`上,需要被部署到各个`worker`节点中。
|
||||
MongoDB是Crawlab的运行数据库,储存有节点、爬虫、任务、定时任务等数据,另外GridFS文件储存方式是主节点储存爬虫文件并同步到工作节点的中间媒介。
|
||||
|
||||
### 任务 Task
|
||||
### Redis
|
||||
|
||||
任务被触发并被节点执行。用户可以在任务详情页面中看到任务到状态、日志和抓取结果。
|
||||
Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点间数据通信的功能。例如,节点会将自己信息通过`HSET`储存在Redis的`nodes`哈希列表中,主节点根据哈希列表来判断在线节点。
|
||||
|
||||
### 前端 Frontend
|
||||
### 前端
|
||||
|
||||
前端是一个基于[Vue-Element-Admin](https://github.com/PanJiaChen/vue-element-admin)的单页应用。其中重用了很多Element-UI的控件来支持相应的展示。
|
||||
|
||||
### Flower
|
||||
|
||||
一个Celery的插件,用于监控Celery节点。
|
||||
|
||||
## 与其他框架的集成
|
||||
|
||||
任务是利用python的`subprocess`模块中的`Popen`来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。
|
||||
爬虫任务本质上是由一个shell命令来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。另外,`CRAWLAB_COLLECTION`是Crawlab传过来的所存放collection的名称。
|
||||
|
||||
在你的爬虫程序中,你需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
|
||||
在爬虫程序中,需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中`CRAWLAB_COLLECTION`的collection中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
|
||||
|
||||
### Scrapy
|
||||
### 集成Scrapy
|
||||
|
||||
以下是Crawlab跟Scrapy集成的例子,利用了Crawlab传过来的task_id和collection_name。
|
||||
|
||||
@@ -135,11 +183,20 @@ Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流
|
||||
|框架 | 类型 | 分布式 | 前端 | 依赖于Scrapyd |
|
||||
|:---:|:---:|:---:|:---:|:---:|
|
||||
| [Crawlab](https://github.com/tikazyq/crawlab) | 管理平台 | Y | Y | N
|
||||
| [Gerapy](https://github.com/Gerapy/Gerapy) | 管理平台 | Y | Y | Y
|
||||
| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | 管理平台 | Y | Y | Y
|
||||
| [ScrapydWeb](https://github.com/my8100/scrapydweb) | 管理平台 | Y | Y | Y
|
||||
| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | 管理平台 | Y | Y | Y
|
||||
| [Gerapy](https://github.com/Gerapy/Gerapy) | 管理平台 | Y | Y | Y
|
||||
| [Scrapyd](https://github.com/scrapy/scrapyd) | 网络服务 | Y | N | N/A
|
||||
|
||||
## 相关文章
|
||||
|
||||
- [爬虫管理平台Crawlab部署指南(Docker and more)](https://juejin.im/post/5d01027a518825142939320f)
|
||||
- [[爬虫手记] 我是如何在3分钟内开发完一个爬虫的](https://juejin.im/post/5ceb4342f265da1bc8540660)
|
||||
- [手把手教你如何用Crawlab构建技术文章聚合平台(二)](https://juejin.im/post/5c92365d6fb9a070c5510e71)
|
||||
- [手把手教你如何用Crawlab构建技术文章聚合平台(一)](https://juejin.im/user/5a1ba6def265da430b7af463/posts)
|
||||
|
||||
**注意: v0.3.0版本已将基于Celery的Python版本切换为了Golang版本,如何部署请参照文档**
|
||||
|
||||
## 社区 & 赞助
|
||||
|
||||
如果您觉得Crawlab对您的日常开发或公司有帮助,请加作者微信 tikazyq1 并注明"Crawlab",作者会将你拉入群。或者,您可以扫下方支付宝二维码给作者打赏去升级团队协作软件或买一杯咖啡。
|
||||
|
||||
@@ -33,9 +33,17 @@ func InitMongo() error {
|
||||
var mongoHost = viper.GetString("mongo.host")
|
||||
var mongoPort = viper.GetString("mongo.port")
|
||||
var mongoDb = viper.GetString("mongo.db")
|
||||
var mongoUsername = viper.GetString("mongo.username")
|
||||
var mongoPassword = viper.GetString("mongo.password")
|
||||
|
||||
if Session == nil {
|
||||
sess, err := mgo.Dial("mongodb://" + mongoHost + ":" + mongoPort + "/" + mongoDb)
|
||||
var uri string
|
||||
if mongoUsername == "" {
|
||||
uri = "mongodb://" + mongoHost + ":" + mongoPort + "/" + mongoDb
|
||||
} else {
|
||||
uri = "mongodb://" + mongoUsername + ":" + mongoPassword + "@" + mongoHost + ":" + mongoPort + "/" + mongoDb
|
||||
}
|
||||
sess, err := mgo.Dial(uri)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
|
||||
@@ -95,8 +95,7 @@ func main() {
|
||||
// 爬虫
|
||||
app.GET("/spiders", routes.GetSpiderList) // 爬虫列表
|
||||
app.GET("/spiders/:id", routes.GetSpider) // 爬虫详情
|
||||
app.PUT("/spiders", routes.PutSpider) // 上传爬虫
|
||||
app.POST("/spiders", routes.PublishAllSpiders) // 发布所有爬虫
|
||||
app.POST("/spiders", routes.PutSpider) // 上传爬虫
|
||||
app.POST("/spiders/:id", routes.PostSpider) // 修改爬虫
|
||||
app.POST("/spiders/:id/publish", routes.PublishSpider) // 发布爬虫
|
||||
app.DELETE("/spiders/:id", routes.DeleteSpider) // 删除爬虫
|
||||
|
||||
@@ -130,7 +130,7 @@ func ExecuteShellCmd(cmdStr string, cwd string, t model.Task, s model.Spider) (e
|
||||
|
||||
// 添加任务环境变量
|
||||
for _, env := range s.Envs {
|
||||
cmd.Env = append(cmd.Env, env.Name + "=" + env.Value)
|
||||
cmd.Env = append(cmd.Env, env.Name+"="+env.Value)
|
||||
}
|
||||
|
||||
// 起一个goroutine来监控进程
|
||||
@@ -344,14 +344,16 @@ func ExecuteTask(id int) {
|
||||
}
|
||||
|
||||
// 起一个cron执行器来统计任务结果数
|
||||
cronExec := cron.New(cron.WithSeconds())
|
||||
_, err = cronExec.AddFunc("*/5 * * * * *", SaveTaskResultCount(t.Id))
|
||||
if err != nil {
|
||||
log.Errorf(GetWorkerPrefix(id) + err.Error())
|
||||
return
|
||||
if spider.Col != "" {
|
||||
cronExec := cron.New(cron.WithSeconds())
|
||||
_, err = cronExec.AddFunc("*/5 * * * * *", SaveTaskResultCount(t.Id))
|
||||
if err != nil {
|
||||
log.Errorf(GetWorkerPrefix(id) + err.Error())
|
||||
return
|
||||
}
|
||||
cronExec.Start()
|
||||
defer cronExec.Stop()
|
||||
}
|
||||
cronExec.Start()
|
||||
defer cronExec.Stop()
|
||||
|
||||
// 执行Shell命令
|
||||
if err := ExecuteShellCmd(cmd, cwd, t, spider); err != nil {
|
||||
@@ -360,9 +362,11 @@ func ExecuteTask(id int) {
|
||||
}
|
||||
|
||||
// 更新任务结果数
|
||||
if err := model.UpdateTaskResultCount(t.Id); err != nil {
|
||||
log.Errorf(GetWorkerPrefix(id) + err.Error())
|
||||
return
|
||||
if spider.Col != "" {
|
||||
if err := model.UpdateTaskResultCount(t.Id); err != nil {
|
||||
log.Errorf(GetWorkerPrefix(id) + err.Error())
|
||||
return
|
||||
}
|
||||
}
|
||||
|
||||
// 完成进程
|
||||
|
||||
114
crawlab/.gitignore
vendored
114
crawlab/.gitignore
vendored
@@ -1,114 +0,0 @@
|
||||
.idea/
|
||||
|
||||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
|
||||
# PyBuilder
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# pyenv
|
||||
.python-version
|
||||
|
||||
# celery beat schedule file
|
||||
celerybeat-schedule
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
|
||||
# node_modules
|
||||
node_modules/
|
||||
|
||||
# egg-info
|
||||
*.egg-info
|
||||
|
||||
tmp/
|
||||
106
crawlab/app.py
106
crawlab/app.py
@@ -1,106 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
from multiprocessing import Process
|
||||
|
||||
from flask import Flask
|
||||
from flask_cors import CORS
|
||||
from flask_restful import Api
|
||||
# from flask_restplus import Api
|
||||
|
||||
file_dir = os.path.dirname(os.path.realpath(__file__))
|
||||
root_path = os.path.abspath(os.path.join(file_dir, '.'))
|
||||
sys.path.append(root_path)
|
||||
|
||||
from utils.log import other
|
||||
from constants.node import NodeStatus
|
||||
from db.manager import db_manager
|
||||
from routes.schedules import ScheduleApi
|
||||
from tasks.celery import celery_app
|
||||
from tasks.scheduler import scheduler
|
||||
from config import FLASK_HOST, FLASK_PORT, PROJECT_LOGS_FOLDER
|
||||
from routes.sites import SiteApi
|
||||
from routes.deploys import DeployApi
|
||||
from routes.files import FileApi
|
||||
from routes.nodes import NodeApi
|
||||
from routes.spiders import SpiderApi, SpiderImportApi, SpiderManageApi
|
||||
from routes.stats import StatsApi
|
||||
from routes.tasks import TaskApi
|
||||
|
||||
# flask app instance
|
||||
app = Flask(__name__)
|
||||
app.config.from_object('config')
|
||||
|
||||
# init flask api instance
|
||||
api = Api(app)
|
||||
|
||||
# cors support
|
||||
CORS(app, supports_credentials=True)
|
||||
|
||||
# reference api routes
|
||||
api.add_resource(NodeApi,
|
||||
'/api/nodes',
|
||||
'/api/nodes/<string:id>',
|
||||
'/api/nodes/<string:id>/<string:action>')
|
||||
api.add_resource(SpiderApi,
|
||||
'/api/spiders',
|
||||
'/api/spiders/<string:id>',
|
||||
'/api/spiders/<string:id>/<string:action>')
|
||||
api.add_resource(SpiderImportApi,
|
||||
'/api/spiders/import/<string:platform>')
|
||||
api.add_resource(SpiderManageApi,
|
||||
'/api/spiders/manage/<string:action>')
|
||||
api.add_resource(TaskApi,
|
||||
'/api/tasks',
|
||||
'/api/tasks/<string:id>',
|
||||
'/api/tasks/<string:id>/<string:action>')
|
||||
api.add_resource(DeployApi,
|
||||
'/api/deploys',
|
||||
'/api/deploys/<string:id>',
|
||||
'/api/deploys/<string:id>/<string:action>')
|
||||
api.add_resource(FileApi,
|
||||
'/api/files',
|
||||
'/api/files/<string:action>')
|
||||
api.add_resource(StatsApi,
|
||||
'/api/stats',
|
||||
'/api/stats/<string:action>')
|
||||
api.add_resource(ScheduleApi,
|
||||
'/api/schedules',
|
||||
'/api/schedules/<string:id>')
|
||||
api.add_resource(SiteApi,
|
||||
'/api/sites',
|
||||
'/api/sites/<string:id>',
|
||||
'/api/sites/get/<string:action>')
|
||||
|
||||
|
||||
def monitor_nodes_status(celery_app):
|
||||
def update_nodes_status(event):
|
||||
node_id = event.get('hostname')
|
||||
db_manager.update_one('nodes', id=node_id, values={
|
||||
'status': NodeStatus.ONLINE
|
||||
})
|
||||
|
||||
def update_nodes_status_online(event):
|
||||
other.info(f"{event}")
|
||||
|
||||
with celery_app.connection() as connection:
|
||||
recv = celery_app.events.Receiver(connection, handlers={
|
||||
'worker-heartbeat': update_nodes_status,
|
||||
# 'worker-online': update_nodes_status_online,
|
||||
})
|
||||
recv.capture(limit=None, timeout=None, wakeup=True)
|
||||
|
||||
|
||||
# run scheduler as a separate process
|
||||
scheduler.run()
|
||||
|
||||
# monitor node status
|
||||
p_monitor = Process(target=monitor_nodes_status, args=(celery_app,))
|
||||
p_monitor.start()
|
||||
|
||||
# create folder if it does not exist
|
||||
if not os.path.exists(PROJECT_LOGS_FOLDER):
|
||||
os.makedirs(PROJECT_LOGS_FOLDER)
|
||||
|
||||
if __name__ == '__main__':
|
||||
# run app instance
|
||||
app.run(host=FLASK_HOST, port=FLASK_PORT)
|
||||
@@ -1,3 +0,0 @@
|
||||
# encoding: utf-8
|
||||
|
||||
from config.config import *
|
||||
@@ -1,52 +0,0 @@
|
||||
import os
|
||||
|
||||
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
|
||||
|
||||
# 爬虫源码路径
|
||||
PROJECT_SOURCE_FILE_FOLDER = os.path.join(BASE_DIR, "spiders")
|
||||
|
||||
# 爬虫部署路径
|
||||
PROJECT_DEPLOY_FILE_FOLDER = '/var/crawlab'
|
||||
|
||||
# 爬虫日志路径
|
||||
PROJECT_LOGS_FOLDER = '/var/log/crawlab'
|
||||
|
||||
# 打包临时文件夹
|
||||
PROJECT_TMP_FOLDER = '/tmp'
|
||||
|
||||
# MongoDB 变量
|
||||
MONGO_HOST = '127.0.0.1'
|
||||
MONGO_PORT = 27017
|
||||
MONGO_USERNAME = None
|
||||
MONGO_PASSWORD = None
|
||||
MONGO_DB = 'crawlab_test'
|
||||
MONGO_AUTH_DB = 'crawlab_test'
|
||||
|
||||
# Celery中间者URL
|
||||
BROKER_URL = 'redis://127.0.0.1:6379/0'
|
||||
|
||||
# Celery后台URL
|
||||
if MONGO_USERNAME is not None:
|
||||
CELERY_RESULT_BACKEND = f'mongodb://{MONGO_USERNAME}:{MONGO_PASSWORD}@{MONGO_HOST}:{MONGO_PORT}/'
|
||||
else:
|
||||
CELERY_RESULT_BACKEND = f'mongodb://{MONGO_HOST}:{MONGO_PORT}/'
|
||||
|
||||
# Celery MongoDB设置
|
||||
CELERY_MONGODB_BACKEND_SETTINGS = {
|
||||
'database': 'crawlab_test',
|
||||
'taskmeta_collection': 'tasks_celery',
|
||||
}
|
||||
|
||||
# Celery时区
|
||||
CELERY_TIMEZONE = 'Asia/Shanghai'
|
||||
|
||||
# 是否启用UTC
|
||||
CELERY_ENABLE_UTC = True
|
||||
|
||||
# flower variables
|
||||
FLOWER_API_ENDPOINT = 'http://localhost:5555/api'
|
||||
|
||||
# Flask 变量
|
||||
DEBUG = False
|
||||
FLASK_HOST = '0.0.0.0'
|
||||
FLASK_PORT = 8000
|
||||
@@ -1,3 +0,0 @@
|
||||
class FileType:
|
||||
FILE = 1
|
||||
FOLDER = 2
|
||||
@@ -1,4 +0,0 @@
|
||||
class LangType:
|
||||
PYTHON = 1
|
||||
NODE = 2
|
||||
GO = 3
|
||||
@@ -1,6 +0,0 @@
|
||||
class ActionType:
|
||||
APP = 'app'
|
||||
FLOWER = 'flower'
|
||||
WORKER = 'worker'
|
||||
SCHEDULER = 'scheduler'
|
||||
RUN_ALL = 'run_all'
|
||||
@@ -1,3 +0,0 @@
|
||||
class NodeStatus:
|
||||
ONLINE = 'online'
|
||||
OFFLINE = 'offline'
|
||||
@@ -1,44 +0,0 @@
|
||||
class SpiderType:
|
||||
CONFIGURABLE = 'configurable'
|
||||
CUSTOMIZED = 'customized'
|
||||
|
||||
|
||||
class LangType:
|
||||
PYTHON = 'python'
|
||||
JAVASCRIPT = 'javascript'
|
||||
JAVA = 'java'
|
||||
GO = 'go'
|
||||
OTHER = 'other'
|
||||
|
||||
|
||||
class CronEnabled:
|
||||
ON = 1
|
||||
OFF = 0
|
||||
|
||||
|
||||
class CrawlType:
|
||||
LIST = 'list'
|
||||
DETAIL = 'detail'
|
||||
LIST_DETAIL = 'list-detail'
|
||||
|
||||
|
||||
class QueryType:
|
||||
CSS = 'css'
|
||||
XPATH = 'xpath'
|
||||
|
||||
|
||||
class ExtractType:
|
||||
TEXT = 'text'
|
||||
ATTRIBUTE = 'attribute'
|
||||
|
||||
|
||||
SUFFIX_IGNORE = [
|
||||
'pyc'
|
||||
]
|
||||
|
||||
FILE_SUFFIX_LANG_MAPPING = {
|
||||
'py': LangType.PYTHON,
|
||||
'js': LangType.JAVASCRIPT,
|
||||
'java': LangType.JAVA,
|
||||
'go': LangType.GO,
|
||||
}
|
||||
@@ -1,8 +0,0 @@
|
||||
class TaskStatus:
|
||||
PENDING = 'PENDING'
|
||||
STARTED = 'STARTED'
|
||||
SUCCESS = 'SUCCESS'
|
||||
FAILURE = 'FAILURE'
|
||||
RETRY = 'RETRY'
|
||||
REVOKED = 'REVOKED'
|
||||
UNAVAILABLE = 'UNAVAILABLE'
|
||||
@@ -1,189 +0,0 @@
|
||||
from bson import ObjectId
|
||||
from pymongo import MongoClient, DESCENDING
|
||||
from config import MONGO_HOST, MONGO_PORT, MONGO_DB, MONGO_USERNAME, MONGO_PASSWORD, MONGO_AUTH_DB
|
||||
from utils import is_object_id
|
||||
|
||||
|
||||
class DbManager(object):
|
||||
__doc__ = """
|
||||
Database Manager class for handling database CRUD actions.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.mongo = MongoClient(host=MONGO_HOST,
|
||||
port=MONGO_PORT,
|
||||
username=MONGO_USERNAME,
|
||||
password=MONGO_PASSWORD,
|
||||
authSource=MONGO_AUTH_DB or MONGO_DB,
|
||||
connect=False)
|
||||
self.db = self.mongo[MONGO_DB]
|
||||
|
||||
def save(self, col_name: str, item: dict, **kwargs) -> None:
|
||||
"""
|
||||
Save the item in the specified collection
|
||||
:param col_name: collection name
|
||||
:param item: item object
|
||||
"""
|
||||
col = self.db[col_name]
|
||||
|
||||
# in case some fields cannot be saved in MongoDB
|
||||
if item.get('stats') is not None:
|
||||
item.pop('stats')
|
||||
|
||||
return col.save(item, **kwargs)
|
||||
|
||||
def remove(self, col_name: str, cond: dict, **kwargs) -> None:
|
||||
"""
|
||||
Remove items given specified condition.
|
||||
:param col_name: collection name
|
||||
:param cond: condition or filter
|
||||
"""
|
||||
col = self.db[col_name]
|
||||
col.remove(cond, **kwargs)
|
||||
|
||||
def update(self, col_name: str, cond: dict, values: dict, **kwargs):
|
||||
"""
|
||||
Update items given specified condition.
|
||||
:param col_name: collection name
|
||||
:param cond: condition or filter
|
||||
:param values: values to update
|
||||
"""
|
||||
col = self.db[col_name]
|
||||
col.update(cond, {'$set': values}, **kwargs)
|
||||
|
||||
def update_one(self, col_name: str, id: str, values: dict, **kwargs):
|
||||
"""
|
||||
Update an item given specified _id
|
||||
:param col_name: collection name
|
||||
:param id: _id
|
||||
:param values: values to update
|
||||
"""
|
||||
col = self.db[col_name]
|
||||
_id = id
|
||||
if is_object_id(id):
|
||||
_id = ObjectId(id)
|
||||
# print('UPDATE: _id = "%s", values = %s' % (str(_id), jsonify(values)))
|
||||
col.find_one_and_update({'_id': _id}, {'$set': values})
|
||||
|
||||
def remove_one(self, col_name: str, id: str, **kwargs):
|
||||
"""
|
||||
Remove an item given specified _id
|
||||
:param col_name: collection name
|
||||
:param id: _id
|
||||
"""
|
||||
col = self.db[col_name]
|
||||
_id = id
|
||||
if is_object_id(id):
|
||||
_id = ObjectId(id)
|
||||
col.remove({'_id': _id})
|
||||
|
||||
def list(self, col_name: str, cond: dict, sort_key=None, sort_direction=DESCENDING, skip: int = 0, limit: int = 100,
|
||||
**kwargs) -> list:
|
||||
"""
|
||||
Return a list of items given specified condition, sort_key, sort_direction, skip, and limit.
|
||||
:param col_name: collection name
|
||||
:param cond: condition or filter
|
||||
:param sort_key: key to sort
|
||||
:param sort_direction: sort direction
|
||||
:param skip: skip number
|
||||
:param limit: limit number
|
||||
"""
|
||||
if sort_key is None:
|
||||
sort_key = '_i'
|
||||
col = self.db[col_name]
|
||||
data = []
|
||||
for item in col.find(cond).sort(sort_key, sort_direction).skip(skip).limit(limit):
|
||||
data.append(item)
|
||||
return data
|
||||
|
||||
def _get(self, col_name: str, cond: dict) -> dict:
|
||||
"""
|
||||
Get an item given specified condition.
|
||||
:param col_name: collection name
|
||||
:param cond: condition or filter
|
||||
"""
|
||||
col = self.db[col_name]
|
||||
return col.find_one(cond)
|
||||
|
||||
def get(self, col_name: str, id: (ObjectId, str)) -> dict:
|
||||
"""
|
||||
Get an item given specified _id.
|
||||
:param col_name: collection name
|
||||
:param id: _id
|
||||
"""
|
||||
if type(id) == ObjectId:
|
||||
_id = id
|
||||
elif is_object_id(id):
|
||||
_id = ObjectId(id)
|
||||
else:
|
||||
_id = id
|
||||
return self._get(col_name=col_name, cond={'_id': _id})
|
||||
|
||||
def get_one_by_key(self, col_name: str, key, value) -> dict:
|
||||
"""
|
||||
Get an item given key/value condition.
|
||||
:param col_name: collection name
|
||||
:param key: key
|
||||
:param value: value
|
||||
"""
|
||||
return self._get(col_name=col_name, cond={key: value})
|
||||
|
||||
def count(self, col_name: str, cond) -> int:
|
||||
"""
|
||||
Get total count of a collection given specified condition
|
||||
:param col_name: collection name
|
||||
:param cond: condition or filter
|
||||
"""
|
||||
col = self.db[col_name]
|
||||
return col.count(cond)
|
||||
|
||||
def get_latest_version(self, spider_id, node_id):
|
||||
"""
|
||||
@deprecated
|
||||
"""
|
||||
col = self.db['deploys']
|
||||
for item in col.find({'spider_id': ObjectId(spider_id), 'node_id': node_id}) \
|
||||
.sort('version', DESCENDING):
|
||||
return item.get('version')
|
||||
return None
|
||||
|
||||
def get_last_deploy(self, spider_id):
|
||||
"""
|
||||
Get latest deploy for a given spider_id
|
||||
"""
|
||||
col = self.db['deploys']
|
||||
for item in col.find({'spider_id': ObjectId(spider_id)}) \
|
||||
.sort('finish_ts', DESCENDING):
|
||||
return item
|
||||
return None
|
||||
|
||||
def get_last_task(self, spider_id):
|
||||
"""
|
||||
Get latest deploy for a given spider_id
|
||||
"""
|
||||
col = self.db['tasks']
|
||||
for item in col.find({'spider_id': ObjectId(spider_id)}) \
|
||||
.sort('create_ts', DESCENDING):
|
||||
return item
|
||||
return None
|
||||
|
||||
def aggregate(self, col_name: str, pipelines, **kwargs):
|
||||
"""
|
||||
Perform MongoDB col.aggregate action to aggregate stats given collection name and pipelines.
|
||||
Reference: https://docs.mongodb.com/manual/reference/command/aggregate/
|
||||
:param col_name: collection name
|
||||
:param pipelines: pipelines
|
||||
"""
|
||||
col = self.db[col_name]
|
||||
return col.aggregate(pipelines, **kwargs)
|
||||
|
||||
def create_index(self, col_name: str, keys: dict, **kwargs):
|
||||
col = self.db[col_name]
|
||||
col.create_index(keys=keys, **kwargs)
|
||||
|
||||
def distinct(self, col_name: str, key: str, filter: dict):
|
||||
col = self.db[col_name]
|
||||
return sorted(col.distinct(key, filter))
|
||||
|
||||
|
||||
db_manager = DbManager()
|
||||
@@ -1,20 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
import subprocess
|
||||
|
||||
# make sure the working directory is in system path
|
||||
FILE_DIR = os.path.dirname(os.path.realpath(__file__))
|
||||
ROOT_PATH = os.path.abspath(os.path.join(FILE_DIR, '..'))
|
||||
sys.path.append(ROOT_PATH)
|
||||
|
||||
from utils.log import other
|
||||
from config import BROKER_URL
|
||||
|
||||
if __name__ == '__main__':
|
||||
p = subprocess.Popen([sys.executable, '-m', 'celery', 'flower', '-b', BROKER_URL],
|
||||
stdout=subprocess.PIPE,
|
||||
stderr=subprocess.STDOUT,
|
||||
cwd=ROOT_PATH)
|
||||
for line in iter(p.stdout.readline, 'b'):
|
||||
if line.decode('utf-8') != '':
|
||||
other.info(line.decode('utf-8'))
|
||||
@@ -1,17 +0,0 @@
|
||||
Flask_CSV==1.2.0
|
||||
gevent==1.4.0
|
||||
requests==2.21.0
|
||||
Scrapy==1.6.0
|
||||
pymongo==3.7.2
|
||||
APScheduler==3.6.0
|
||||
coloredlogs==10.0
|
||||
Flask_RESTful==0.3.7
|
||||
Flask==1.0.2
|
||||
lxml==4.3.3
|
||||
Flask_Cors==3.0.7
|
||||
Werkzeug==0.15.2
|
||||
eventlet
|
||||
Celery
|
||||
Flower
|
||||
redis
|
||||
gunicorn
|
||||
@@ -1,7 +0,0 @@
|
||||
# from app import api
|
||||
# from routes.deploys import DeployApi
|
||||
# from routes.files import FileApi
|
||||
# from routes.nodes import NodeApi
|
||||
# from routes.spiders import SpiderApi
|
||||
# from routes.tasks import TaskApi
|
||||
# print(api)
|
||||
@@ -1,189 +0,0 @@
|
||||
from flask_restful import reqparse, Resource
|
||||
# from flask_restplus import reqparse, Resource
|
||||
|
||||
from db.manager import db_manager
|
||||
from utils import jsonify
|
||||
|
||||
DEFAULT_ARGS = [
|
||||
'page_num',
|
||||
'page_size',
|
||||
'filter'
|
||||
]
|
||||
|
||||
|
||||
class BaseApi(Resource):
|
||||
"""
|
||||
Base class for API. All API classes should inherit this class.
|
||||
"""
|
||||
col_name = 'tmp'
|
||||
parser = reqparse.RequestParser()
|
||||
arguments = []
|
||||
|
||||
def __init__(self):
|
||||
super(BaseApi).__init__()
|
||||
self.parser.add_argument('page_num', type=int)
|
||||
self.parser.add_argument('page_size', type=int)
|
||||
self.parser.add_argument('filter', type=str)
|
||||
|
||||
for arg, type in self.arguments:
|
||||
self.parser.add_argument(arg, type=type)
|
||||
|
||||
def get(self, id: str = None, action: str = None) -> (dict, tuple):
|
||||
"""
|
||||
GET method for retrieving item information.
|
||||
If id is specified and action is not, return the object of the given id;
|
||||
If id and action are both specified, execute the given action results of the given id;
|
||||
If neither id nor action is specified, return the list of items given the page_size, page_num and filter
|
||||
:param id:
|
||||
:param action:
|
||||
:return:
|
||||
"""
|
||||
# import pdb
|
||||
# pdb.set_trace()
|
||||
args = self.parser.parse_args()
|
||||
|
||||
# action by id
|
||||
if action is not None:
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
return getattr(self, action)(id)
|
||||
|
||||
# list items
|
||||
elif id is None:
|
||||
# filter
|
||||
cond = {}
|
||||
if args.get('filter') is not None:
|
||||
cond = args.filter
|
||||
# cond = json.loads(args.filter)
|
||||
|
||||
# page number
|
||||
page = 1
|
||||
if args.get('page_num') is not None:
|
||||
page = args.page
|
||||
# page = int(args.page)
|
||||
|
||||
# page size
|
||||
page_size = 10
|
||||
if args.get('page_size') is not None:
|
||||
page_size = args.page_size
|
||||
# page = int(args.page_size)
|
||||
|
||||
# TODO: sort functionality
|
||||
|
||||
# total count
|
||||
total_count = db_manager.count(col_name=self.col_name, cond=cond)
|
||||
|
||||
# items
|
||||
items = db_manager.list(col_name=self.col_name,
|
||||
cond=cond,
|
||||
skip=(page - 1) * page_size,
|
||||
limit=page_size)
|
||||
|
||||
# TODO: getting status for node
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'total_count': total_count,
|
||||
'page_num': page,
|
||||
'page_size': page_size,
|
||||
'items': jsonify(items)
|
||||
}
|
||||
|
||||
# get item by id
|
||||
else:
|
||||
return jsonify(db_manager.get(col_name=self.col_name, id=id))
|
||||
|
||||
def put(self) -> (dict, tuple):
|
||||
"""
|
||||
PUT method for creating a new item.
|
||||
:return:
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
item = {}
|
||||
for k in args.keys():
|
||||
if k not in DEFAULT_ARGS:
|
||||
item[k] = args.get(k)
|
||||
id = db_manager.save(col_name=self.col_name, item=item)
|
||||
|
||||
# execute after_update hook
|
||||
self.after_update(id)
|
||||
|
||||
return jsonify(id)
|
||||
|
||||
def update(self, id: str = None) -> (dict, tuple):
|
||||
"""
|
||||
Helper function for update action given the id.
|
||||
:param id:
|
||||
:return:
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
item = db_manager.get(col_name=self.col_name, id=id)
|
||||
if item is None:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 401,
|
||||
'error': 'item not exists'
|
||||
}, 401
|
||||
values = {}
|
||||
for k in args.keys():
|
||||
if k not in DEFAULT_ARGS:
|
||||
if args.get(k) is not None:
|
||||
values[k] = args.get(k)
|
||||
item = db_manager.update_one(col_name=self.col_name, id=id, values=values)
|
||||
|
||||
# execute after_update hook
|
||||
self.after_update(id)
|
||||
|
||||
return jsonify(item)
|
||||
|
||||
def post(self, id: str = None, action: str = None):
|
||||
"""
|
||||
POST method of the given id for performing an action.
|
||||
:param id:
|
||||
:param action:
|
||||
:return:
|
||||
"""
|
||||
# perform update action if action is not specified
|
||||
if action is None:
|
||||
return self.update(id)
|
||||
|
||||
# if action is not defined in the attributes, return 400 error
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
|
||||
# perform specified action of given id
|
||||
return getattr(self, action)(id)
|
||||
|
||||
def delete(self, id: str = None) -> (dict, tuple):
|
||||
"""
|
||||
DELETE method of given id for deleting an item.
|
||||
:param id:
|
||||
:return:
|
||||
"""
|
||||
# perform delete action
|
||||
db_manager.remove_one(col_name=self.col_name, id=id)
|
||||
|
||||
# execute after_update hook
|
||||
self.after_update(id)
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'message': 'deleted successfully',
|
||||
}
|
||||
|
||||
def after_update(self, id: str = None):
|
||||
"""
|
||||
This is the after update hook once the update method is performed.
|
||||
To be overridden.
|
||||
:param id:
|
||||
:return:
|
||||
"""
|
||||
pass
|
||||
@@ -1,46 +0,0 @@
|
||||
from db.manager import db_manager
|
||||
from routes.base import BaseApi
|
||||
from utils import jsonify
|
||||
|
||||
|
||||
class DeployApi(BaseApi):
|
||||
col_name = 'deploys'
|
||||
|
||||
arguments = (
|
||||
('spider_id', str),
|
||||
('node_id', str),
|
||||
)
|
||||
|
||||
def get(self, id: str = None, action: str = None) -> (dict, tuple):
|
||||
"""
|
||||
GET method of DeployAPI.
|
||||
:param id: deploy_id
|
||||
:param action: action
|
||||
"""
|
||||
# action by id
|
||||
if action is not None:
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
return getattr(self, action)(id)
|
||||
|
||||
# get one node
|
||||
elif id is not None:
|
||||
return jsonify(db_manager.get('deploys', id=id))
|
||||
|
||||
# get a list of items
|
||||
else:
|
||||
items = db_manager.list('deploys', {})
|
||||
deploys = []
|
||||
for item in items:
|
||||
spider_id = item['spider_id']
|
||||
spider = db_manager.get('spiders', id=str(spider_id))
|
||||
item['spider_name'] = spider['name']
|
||||
deploys.append(item)
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': jsonify(deploys)
|
||||
}
|
||||
@@ -1,50 +0,0 @@
|
||||
import os
|
||||
|
||||
from flask_restful import reqparse, Resource
|
||||
|
||||
from utils import jsonify
|
||||
from utils.file import get_file_content
|
||||
|
||||
|
||||
class FileApi(Resource):
|
||||
parser = reqparse.RequestParser()
|
||||
arguments = []
|
||||
|
||||
def __init__(self):
|
||||
super(FileApi).__init__()
|
||||
self.parser.add_argument('path', type=str)
|
||||
|
||||
def get(self, action=None):
|
||||
"""
|
||||
GET method of FileAPI.
|
||||
:param action: action
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
path = args.get('path')
|
||||
|
||||
if action is not None:
|
||||
if action == 'getDefaultPath':
|
||||
return jsonify({
|
||||
'defaultPath': os.path.abspath(os.path.join(os.path.curdir, 'spiders'))
|
||||
})
|
||||
|
||||
elif action == 'get_file':
|
||||
file_data = get_file_content(path)
|
||||
file_data['status'] = 'ok'
|
||||
return jsonify(file_data)
|
||||
|
||||
else:
|
||||
return {}
|
||||
|
||||
folders = []
|
||||
files = []
|
||||
for _path in os.listdir(path):
|
||||
if os.path.isfile(os.path.join(path, _path)):
|
||||
files.append(_path)
|
||||
elif os.path.isdir(os.path.join(path, _path)):
|
||||
folders.append(_path)
|
||||
return jsonify({
|
||||
'status': 'ok',
|
||||
'files': sorted(files),
|
||||
'folders': sorted(folders),
|
||||
})
|
||||
@@ -1,81 +0,0 @@
|
||||
from constants.task import TaskStatus
|
||||
from db.manager import db_manager
|
||||
from routes.base import BaseApi
|
||||
from utils import jsonify
|
||||
from utils.node import update_nodes_status
|
||||
|
||||
|
||||
class NodeApi(BaseApi):
|
||||
col_name = 'nodes'
|
||||
|
||||
arguments = (
|
||||
('name', str),
|
||||
('description', str),
|
||||
('ip', str),
|
||||
('port', str),
|
||||
)
|
||||
|
||||
def get(self, id: str = None, action: str = None) -> (dict, tuple):
|
||||
"""
|
||||
GET method of NodeAPI.
|
||||
:param id: item id
|
||||
:param action: action
|
||||
"""
|
||||
# action by id
|
||||
if action is not None:
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
return getattr(self, action)(id)
|
||||
|
||||
# get one node
|
||||
elif id is not None:
|
||||
return db_manager.get('nodes', id=id)
|
||||
|
||||
# get a list of items
|
||||
else:
|
||||
# get a list of active nodes from flower and save to db
|
||||
update_nodes_status()
|
||||
|
||||
# iterate db nodes to update status
|
||||
nodes = db_manager.list('nodes', {})
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': jsonify(nodes)
|
||||
}
|
||||
|
||||
def get_deploys(self, id: str) -> (dict, tuple):
|
||||
"""
|
||||
Get a list of latest deploys of given node_id
|
||||
:param id: node_id
|
||||
"""
|
||||
items = db_manager.list('deploys', {'node_id': id}, limit=10, sort_key='finish_ts')
|
||||
deploys = []
|
||||
for item in items:
|
||||
spider_id = item['spider_id']
|
||||
spider = db_manager.get('spiders', id=str(spider_id))
|
||||
item['spider_name'] = spider['name']
|
||||
deploys.append(item)
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': jsonify(deploys)
|
||||
}
|
||||
|
||||
def get_tasks(self, id):
|
||||
"""
|
||||
Get a list of latest tasks of given node_id
|
||||
:param id: node_id
|
||||
"""
|
||||
items = db_manager.list('tasks', {'node_id': id}, limit=10, sort_key='create_ts')
|
||||
for item in items:
|
||||
spider_id = item['spider_id']
|
||||
spider = db_manager.get('spiders', id=str(spider_id))
|
||||
item['spider_name'] = spider['name']
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': jsonify(items)
|
||||
}
|
||||
@@ -1,25 +0,0 @@
|
||||
import json
|
||||
|
||||
import requests
|
||||
|
||||
from constants.task import TaskStatus
|
||||
from db.manager import db_manager
|
||||
from routes.base import BaseApi
|
||||
from tasks.scheduler import scheduler
|
||||
from utils import jsonify
|
||||
from utils.spider import get_spider_col_fields
|
||||
|
||||
|
||||
class ScheduleApi(BaseApi):
|
||||
col_name = 'schedules'
|
||||
|
||||
arguments = (
|
||||
('name', str),
|
||||
('description', str),
|
||||
('cron', str),
|
||||
('spider_id', str),
|
||||
('params', str)
|
||||
)
|
||||
|
||||
def after_update(self, id: str = None):
|
||||
scheduler.update()
|
||||
@@ -1,90 +0,0 @@
|
||||
import json
|
||||
|
||||
from bson import ObjectId
|
||||
from pymongo import ASCENDING
|
||||
|
||||
from db.manager import db_manager
|
||||
from routes.base import BaseApi
|
||||
from utils import jsonify
|
||||
|
||||
|
||||
class SiteApi(BaseApi):
|
||||
col_name = 'sites'
|
||||
|
||||
arguments = (
|
||||
('keyword', str),
|
||||
('main_category', str),
|
||||
('category', str),
|
||||
)
|
||||
|
||||
def get(self, id: str = None, action: str = None):
|
||||
# action by id
|
||||
if action is not None:
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
return getattr(self, action)(id)
|
||||
|
||||
elif id is not None:
|
||||
site = db_manager.get(col_name=self.col_name, id=id)
|
||||
return jsonify(site)
|
||||
|
||||
# list tasks
|
||||
args = self.parser.parse_args()
|
||||
page_size = args.get('page_size') or 10
|
||||
page_num = args.get('page_num') or 1
|
||||
filter_str = args.get('filter')
|
||||
keyword = args.get('keyword')
|
||||
filter_ = {}
|
||||
if filter_str is not None:
|
||||
filter_ = json.loads(filter_str)
|
||||
if keyword is not None:
|
||||
filter_['$or'] = [
|
||||
{'description': {'$regex': keyword}},
|
||||
{'name': {'$regex': keyword}},
|
||||
{'domain': {'$regex': keyword}}
|
||||
]
|
||||
|
||||
items = db_manager.list(
|
||||
col_name=self.col_name,
|
||||
cond=filter_,
|
||||
limit=page_size,
|
||||
skip=page_size * (page_num - 1),
|
||||
sort_key='rank',
|
||||
sort_direction=ASCENDING
|
||||
)
|
||||
|
||||
sites = []
|
||||
for site in items:
|
||||
# get spider count
|
||||
site['spider_count'] = db_manager.count('spiders', {'site': site['_id']})
|
||||
|
||||
sites.append(site)
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'total_count': db_manager.count(self.col_name, filter_),
|
||||
'page_num': page_num,
|
||||
'page_size': page_size,
|
||||
'items': jsonify(sites)
|
||||
}
|
||||
|
||||
def get_main_category_list(self, id):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': db_manager.distinct(col_name=self.col_name, key='main_category', filter={})
|
||||
}
|
||||
|
||||
def get_category_list(self, id):
|
||||
args = self.parser.parse_args()
|
||||
filter_ = {}
|
||||
if args.get('main_category') is not None:
|
||||
filter_['main_category'] = args.get('main_category')
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': db_manager.distinct(col_name=self.col_name, key='category',
|
||||
filter=filter_)
|
||||
}
|
||||
@@ -1,937 +0,0 @@
|
||||
import json
|
||||
import os
|
||||
import shutil
|
||||
import subprocess
|
||||
from datetime import datetime
|
||||
from random import random
|
||||
from urllib.parse import urlparse
|
||||
|
||||
import gevent
|
||||
import requests
|
||||
from bson import ObjectId
|
||||
from flask import current_app, request
|
||||
from flask_restful import reqparse, Resource
|
||||
from lxml import etree
|
||||
from werkzeug.datastructures import FileStorage
|
||||
|
||||
from config import PROJECT_DEPLOY_FILE_FOLDER, PROJECT_SOURCE_FILE_FOLDER, PROJECT_TMP_FOLDER
|
||||
from constants.node import NodeStatus
|
||||
from constants.spider import SpiderType, CrawlType, QueryType, ExtractType
|
||||
from constants.task import TaskStatus
|
||||
from db.manager import db_manager
|
||||
from routes.base import BaseApi
|
||||
from tasks.scheduler import scheduler
|
||||
from tasks.spider import execute_spider, execute_config_spider
|
||||
from utils import jsonify
|
||||
from utils.deploy import zip_file, unzip_file
|
||||
from utils.file import get_file_suffix_stats, get_file_suffix
|
||||
from utils.spider import get_lang_by_stats, get_last_n_run_errors_count, get_last_n_day_tasks_count, get_list_page_data, \
|
||||
get_detail_page_data, generate_urls
|
||||
|
||||
parser = reqparse.RequestParser()
|
||||
parser.add_argument('file', type=FileStorage, location='files')
|
||||
|
||||
IGNORE_DIRS = [
|
||||
'.idea'
|
||||
]
|
||||
|
||||
|
||||
class SpiderApi(BaseApi):
|
||||
col_name = 'spiders'
|
||||
|
||||
arguments = (
|
||||
# name of spider
|
||||
('name', str),
|
||||
|
||||
# execute shell command
|
||||
('cmd', str),
|
||||
|
||||
# spider source folder
|
||||
('src', str),
|
||||
|
||||
# spider type
|
||||
('type', str),
|
||||
|
||||
# spider language
|
||||
('lang', str),
|
||||
|
||||
# spider results collection
|
||||
('col', str),
|
||||
|
||||
# spider schedule cron
|
||||
('cron', str),
|
||||
|
||||
# spider schedule cron enabled
|
||||
('cron_enabled', int),
|
||||
|
||||
# spider schedule cron enabled
|
||||
('envs', str),
|
||||
|
||||
# spider site
|
||||
('site', str),
|
||||
|
||||
########################
|
||||
# Configurable Spider
|
||||
########################
|
||||
|
||||
# spider crawl fields for list page
|
||||
('fields', str),
|
||||
|
||||
# spider crawl fields for detail page
|
||||
('detail_fields', str),
|
||||
|
||||
# spider crawl type
|
||||
('crawl_type', str),
|
||||
|
||||
# spider start url
|
||||
('start_url', str),
|
||||
|
||||
# url pattern: support generation of urls with patterns
|
||||
('url_pattern', str),
|
||||
|
||||
# spider item selector
|
||||
('item_selector', str),
|
||||
|
||||
# spider item selector type
|
||||
('item_selector_type', str),
|
||||
|
||||
# spider pagination selector
|
||||
('pagination_selector', str),
|
||||
|
||||
# spider pagination selector type
|
||||
('pagination_selector_type', str),
|
||||
|
||||
# whether to obey robots.txt
|
||||
('obey_robots_txt', bool),
|
||||
|
||||
# item threshold to filter out non-relevant list items
|
||||
('item_threshold', int),
|
||||
)
|
||||
|
||||
def get(self, id=None, action=None):
|
||||
"""
|
||||
GET method of SpiderAPI.
|
||||
:param id: spider_id
|
||||
:param action: action
|
||||
"""
|
||||
# action by id
|
||||
if action is not None:
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
return getattr(self, action)(id)
|
||||
|
||||
# get one node
|
||||
elif id is not None:
|
||||
spider = db_manager.get('spiders', id=id)
|
||||
|
||||
# get deploy
|
||||
last_deploy = db_manager.get_last_deploy(spider_id=spider['_id'])
|
||||
if last_deploy is not None:
|
||||
spider['deploy_ts'] = last_deploy['finish_ts']
|
||||
|
||||
return jsonify(spider)
|
||||
|
||||
# get a list of items
|
||||
else:
|
||||
items = []
|
||||
|
||||
# get customized spiders
|
||||
dirs = os.listdir(PROJECT_SOURCE_FILE_FOLDER)
|
||||
for _dir in dirs:
|
||||
if _dir in IGNORE_DIRS:
|
||||
continue
|
||||
|
||||
dir_path = os.path.join(PROJECT_SOURCE_FILE_FOLDER, _dir)
|
||||
dir_name = _dir
|
||||
spider = db_manager.get_one_by_key('spiders', key='src', value=dir_path)
|
||||
|
||||
# new spider
|
||||
if spider is None:
|
||||
stats = get_file_suffix_stats(dir_path)
|
||||
lang = get_lang_by_stats(stats)
|
||||
spider_id = db_manager.save('spiders', {
|
||||
'name': dir_name,
|
||||
'src': dir_path,
|
||||
'lang': lang,
|
||||
'suffix_stats': stats,
|
||||
'type': SpiderType.CUSTOMIZED
|
||||
})
|
||||
spider = db_manager.get('spiders', id=spider_id)
|
||||
|
||||
# existing spider
|
||||
else:
|
||||
# get last deploy
|
||||
last_deploy = db_manager.get_last_deploy(spider_id=spider['_id'])
|
||||
if last_deploy is not None:
|
||||
spider['deploy_ts'] = last_deploy['finish_ts']
|
||||
|
||||
# file stats
|
||||
stats = get_file_suffix_stats(dir_path)
|
||||
|
||||
# language
|
||||
lang = get_lang_by_stats(stats)
|
||||
|
||||
# spider type
|
||||
type_ = SpiderType.CUSTOMIZED
|
||||
|
||||
# update spider data
|
||||
db_manager.update_one('spiders', id=str(spider['_id']), values={
|
||||
'lang': lang,
|
||||
'type': type_,
|
||||
'suffix_stats': stats,
|
||||
})
|
||||
|
||||
# append spider
|
||||
items.append(spider)
|
||||
|
||||
# get configurable spiders
|
||||
for spider in db_manager.list('spiders', {'type': SpiderType.CONFIGURABLE}):
|
||||
# append spider
|
||||
items.append(spider)
|
||||
|
||||
# get other info
|
||||
for i in range(len(items)):
|
||||
spider = items[i]
|
||||
|
||||
# get site
|
||||
if spider.get('site') is not None:
|
||||
site = db_manager.get('sites', spider['site'])
|
||||
if site is not None:
|
||||
items[i]['site_name'] = site['name']
|
||||
|
||||
# get last task
|
||||
last_task = db_manager.get_last_task(spider_id=spider['_id'])
|
||||
if last_task is not None:
|
||||
items[i]['task_ts'] = last_task['create_ts']
|
||||
|
||||
# ---------
|
||||
# stats
|
||||
# ---------
|
||||
# last 5-run errors
|
||||
items[i]['last_5_errors'] = get_last_n_run_errors_count(spider_id=spider['_id'], n=5)
|
||||
items[i]['last_7d_tasks'] = get_last_n_day_tasks_count(spider_id=spider['_id'], n=5)
|
||||
|
||||
# sort spiders by _id descending
|
||||
items = reversed(sorted(items, key=lambda x: x['_id']))
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': jsonify(items)
|
||||
}
|
||||
|
||||
def delete(self, id: str = None) -> (dict, tuple):
|
||||
"""
|
||||
DELETE method of given id for deleting an spider.
|
||||
:param id:
|
||||
:return:
|
||||
"""
|
||||
# get spider from db
|
||||
spider = db_manager.get(col_name=self.col_name, id=id)
|
||||
|
||||
# delete spider folder
|
||||
if spider.get('type') == SpiderType.CUSTOMIZED:
|
||||
try:
|
||||
shutil.rmtree(os.path.abspath(os.path.join(PROJECT_SOURCE_FILE_FOLDER, spider['src'])))
|
||||
except Exception as err:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': str(err)
|
||||
}, 500
|
||||
|
||||
# perform delete action
|
||||
db_manager.remove_one(col_name=self.col_name, id=id)
|
||||
|
||||
# remove related tasks
|
||||
db_manager.remove(col_name='tasks', cond={'spider_id': spider['_id']})
|
||||
|
||||
# remove related schedules
|
||||
db_manager.remove(col_name='schedules', cond={'spider_id': spider['_id']})
|
||||
|
||||
# execute after_update hook
|
||||
self.after_update(id)
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'message': 'deleted successfully',
|
||||
}
|
||||
|
||||
def crawl(self, id: str) -> (dict, tuple):
|
||||
"""
|
||||
Submit an HTTP request to start a crawl task in the node of given spider_id.
|
||||
@deprecated
|
||||
:param id: spider_id
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
node_id = args.get('node_id')
|
||||
|
||||
if node_id is None:
|
||||
return {
|
||||
'code': 400,
|
||||
'status': 400,
|
||||
'error': 'node_id cannot be empty'
|
||||
}, 400
|
||||
|
||||
# get node from db
|
||||
node = db_manager.get('nodes', id=node_id)
|
||||
|
||||
# validate ip and port
|
||||
if node.get('ip') is None or node.get('port') is None:
|
||||
return {
|
||||
'code': 400,
|
||||
'status': 'ok',
|
||||
'error': 'node ip and port should not be empty'
|
||||
}, 400
|
||||
|
||||
# dispatch crawl task
|
||||
res = requests.get('http://%s:%s/api/spiders/%s/on_crawl?node_id=%s' % (
|
||||
node.get('ip'),
|
||||
node.get('port'),
|
||||
id,
|
||||
node_id
|
||||
))
|
||||
data = json.loads(res.content.decode('utf-8'))
|
||||
return {
|
||||
'code': res.status_code,
|
||||
'status': 'ok',
|
||||
'error': data.get('error'),
|
||||
'task': data.get('task')
|
||||
}
|
||||
|
||||
def on_crawl(self, id: str) -> (dict, tuple):
|
||||
"""
|
||||
Start a crawl task.
|
||||
:param id: spider_id
|
||||
:return:
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
params = args.get('params')
|
||||
|
||||
spider = db_manager.get('spiders', id=ObjectId(id))
|
||||
|
||||
# determine execute function
|
||||
if spider['type'] == SpiderType.CONFIGURABLE:
|
||||
# configurable spider
|
||||
exec_func = execute_config_spider
|
||||
else:
|
||||
# customized spider
|
||||
exec_func = execute_spider
|
||||
|
||||
# trigger an asynchronous job
|
||||
job = exec_func.delay(id, params)
|
||||
|
||||
# create a new task
|
||||
db_manager.save('tasks', {
|
||||
'_id': job.id,
|
||||
'spider_id': ObjectId(id),
|
||||
'cmd': spider.get('cmd'),
|
||||
'params': params,
|
||||
'create_ts': datetime.utcnow(),
|
||||
'status': TaskStatus.PENDING
|
||||
})
|
||||
|
||||
return {
|
||||
'code': 200,
|
||||
'status': 'ok',
|
||||
'task': {
|
||||
'id': job.id,
|
||||
'status': job.status
|
||||
}
|
||||
}
|
||||
|
||||
def deploy(self, id: str) -> (dict, tuple):
|
||||
"""
|
||||
Submit HTTP requests to deploy the given spider to all nodes.
|
||||
:param id:
|
||||
:return:
|
||||
"""
|
||||
spider = db_manager.get('spiders', id=id)
|
||||
nodes = db_manager.list('nodes', {'status': NodeStatus.ONLINE})
|
||||
|
||||
for node in nodes:
|
||||
node_id = node['_id']
|
||||
|
||||
output_file_name = '%s_%s.zip' % (
|
||||
datetime.now().strftime('%Y%m%d%H%M%S'),
|
||||
str(random())[2:12]
|
||||
)
|
||||
output_file_path = os.path.join(PROJECT_TMP_FOLDER, output_file_name)
|
||||
|
||||
# zip source folder to zip file
|
||||
zip_file(source_dir=spider['src'],
|
||||
output_filename=output_file_path)
|
||||
|
||||
# upload to api
|
||||
files = {'file': open(output_file_path, 'rb')}
|
||||
r = requests.post('http://%s:%s/api/spiders/%s/deploy_file?node_id=%s' % (
|
||||
node.get('ip'),
|
||||
node.get('port'),
|
||||
id,
|
||||
node_id,
|
||||
), files=files)
|
||||
|
||||
# TODO: checkpoint for errors
|
||||
|
||||
return {
|
||||
'code': 200,
|
||||
'status': 'ok',
|
||||
'message': 'deploy success'
|
||||
}
|
||||
|
||||
def deploy_file(self, id: str = None) -> (dict, tuple):
|
||||
"""
|
||||
Receive HTTP request of deploys and unzip zip files and copy to the destination directories.
|
||||
:param id: spider_id
|
||||
"""
|
||||
args = parser.parse_args()
|
||||
node_id = request.args.get('node_id')
|
||||
f = args.file
|
||||
|
||||
if get_file_suffix(f.filename) != 'zip':
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': 'file type mismatch'
|
||||
}, 400
|
||||
|
||||
# save zip file on temp folder
|
||||
file_path = '%s/%s' % (PROJECT_TMP_FOLDER, f.filename)
|
||||
with open(file_path, 'wb') as fw:
|
||||
fw.write(f.stream.read())
|
||||
|
||||
# unzip zip file
|
||||
dir_path = file_path.replace('.zip', '')
|
||||
if os.path.exists(dir_path):
|
||||
shutil.rmtree(dir_path)
|
||||
unzip_file(file_path, dir_path)
|
||||
|
||||
# get spider and version
|
||||
spider = db_manager.get(col_name=self.col_name, id=id)
|
||||
if spider is None:
|
||||
return None, 400
|
||||
|
||||
# make source / destination
|
||||
src = os.path.join(dir_path, os.listdir(dir_path)[0])
|
||||
dst = os.path.join(PROJECT_DEPLOY_FILE_FOLDER, str(spider.get('_id')))
|
||||
|
||||
# logging info
|
||||
current_app.logger.info('src: %s' % src)
|
||||
current_app.logger.info('dst: %s' % dst)
|
||||
|
||||
# remove if the target folder exists
|
||||
if os.path.exists(dst):
|
||||
shutil.rmtree(dst)
|
||||
|
||||
# copy from source to destination
|
||||
shutil.copytree(src=src, dst=dst)
|
||||
|
||||
# save to db
|
||||
# TODO: task management for deployment
|
||||
db_manager.save('deploys', {
|
||||
'spider_id': ObjectId(id),
|
||||
'node_id': node_id,
|
||||
'finish_ts': datetime.utcnow()
|
||||
})
|
||||
|
||||
return {
|
||||
'code': 200,
|
||||
'status': 'ok',
|
||||
'message': 'deploy success'
|
||||
}
|
||||
|
||||
def get_deploys(self, id: str) -> (dict, tuple):
|
||||
"""
|
||||
Get a list of latest deploys of given spider_id
|
||||
:param id: spider_id
|
||||
"""
|
||||
items = db_manager.list('deploys', cond={'spider_id': ObjectId(id)}, limit=10, sort_key='finish_ts')
|
||||
deploys = []
|
||||
for item in items:
|
||||
spider_id = item['spider_id']
|
||||
spider = db_manager.get('spiders', id=str(spider_id))
|
||||
item['spider_name'] = spider['name']
|
||||
deploys.append(item)
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': jsonify(deploys)
|
||||
}
|
||||
|
||||
def get_tasks(self, id: str) -> (dict, tuple):
|
||||
"""
|
||||
Get a list of latest tasks of given spider_id
|
||||
:param id:
|
||||
"""
|
||||
items = db_manager.list('tasks', cond={'spider_id': ObjectId(id)}, limit=10, sort_key='create_ts')
|
||||
for item in items:
|
||||
spider_id = item['spider_id']
|
||||
spider = db_manager.get('spiders', id=str(spider_id))
|
||||
item['spider_name'] = spider['name']
|
||||
if item.get('status') is None:
|
||||
item['status'] = TaskStatus.UNAVAILABLE
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': jsonify(items)
|
||||
}
|
||||
|
||||
def after_update(self, id: str = None) -> None:
|
||||
"""
|
||||
After each spider is updated, update the cron scheduler correspondingly.
|
||||
:param id: spider_id
|
||||
"""
|
||||
scheduler.update()
|
||||
|
||||
def update_envs(self, id: str):
|
||||
"""
|
||||
Update environment variables
|
||||
:param id: spider_id
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
envs = json.loads(args.envs)
|
||||
db_manager.update_one(col_name='spiders', id=id, values={'envs': envs})
|
||||
|
||||
def update_fields(self, id: str):
|
||||
"""
|
||||
Update list page fields variables for configurable spiders
|
||||
:param id: spider_id
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
fields = json.loads(args.fields)
|
||||
db_manager.update_one(col_name='spiders', id=id, values={'fields': fields})
|
||||
|
||||
def update_detail_fields(self, id: str):
|
||||
"""
|
||||
Update detail page fields variables for configurable spiders
|
||||
:param id: spider_id
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
detail_fields = json.loads(args.detail_fields)
|
||||
db_manager.update_one(col_name='spiders', id=id, values={'detail_fields': detail_fields})
|
||||
|
||||
@staticmethod
|
||||
def _get_html(spider) -> etree.Element:
|
||||
if spider['type'] != SpiderType.CONFIGURABLE:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': 'type %s is invalid' % spider['type']
|
||||
}, 400
|
||||
|
||||
if spider.get('start_url') is None:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': 'start_url should not be empty'
|
||||
}, 400
|
||||
|
||||
try:
|
||||
r = None
|
||||
for url in generate_urls(spider['start_url']):
|
||||
r = requests.get(url, headers={
|
||||
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
|
||||
})
|
||||
break
|
||||
except Exception as err:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': 'connection error'
|
||||
}, 500
|
||||
|
||||
if not r:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': 'response is not returned'
|
||||
}, 500
|
||||
|
||||
if r and r.status_code != 200:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': 'status code is not 200, but %s' % r.status_code
|
||||
}, r.status_code
|
||||
|
||||
# get html parse tree
|
||||
try:
|
||||
sel = etree.HTML(r.content.decode('utf-8'))
|
||||
except Exception as err:
|
||||
sel = etree.HTML(r.content)
|
||||
|
||||
# remove unnecessary tags
|
||||
unnecessary_tags = [
|
||||
'script'
|
||||
]
|
||||
for t in unnecessary_tags:
|
||||
etree.strip_tags(sel, t)
|
||||
|
||||
return sel
|
||||
|
||||
@staticmethod
|
||||
def _get_children(sel):
|
||||
return [tag for tag in sel.getchildren() if type(tag) != etree._Comment]
|
||||
|
||||
@staticmethod
|
||||
def _get_text_child_tags(sel):
|
||||
tags = []
|
||||
for tag in sel.iter():
|
||||
if type(tag) != etree._Comment and tag.text is not None and tag.text.strip() != '':
|
||||
tags.append(tag)
|
||||
return tags
|
||||
|
||||
@staticmethod
|
||||
def _get_a_child_tags(sel):
|
||||
tags = []
|
||||
for tag in sel.iter():
|
||||
if tag.tag == 'a':
|
||||
if tag.get('href') is not None and not tag.get('href').startswith('#') and not tag.get(
|
||||
'href').startswith('javascript'):
|
||||
tags.append(tag)
|
||||
|
||||
return tags
|
||||
|
||||
@staticmethod
|
||||
def _get_next_page_tag(sel):
|
||||
next_page_text_list = [
|
||||
'下一页',
|
||||
'下页',
|
||||
'next page',
|
||||
'next',
|
||||
'>'
|
||||
]
|
||||
for tag in sel.iter():
|
||||
if tag.text is not None and tag.text.lower().strip() in next_page_text_list:
|
||||
return tag
|
||||
return None
|
||||
|
||||
def preview_crawl(self, id: str):
|
||||
spider = db_manager.get(col_name='spiders', id=id)
|
||||
|
||||
# get html parse tree
|
||||
sel = self._get_html(spider)
|
||||
|
||||
# when error happens, return
|
||||
if type(sel) == type(tuple):
|
||||
return sel
|
||||
|
||||
# parse fields
|
||||
if spider['crawl_type'] == CrawlType.LIST:
|
||||
if spider.get('item_selector') is None:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': 'item_selector should not be empty'
|
||||
}, 400
|
||||
|
||||
data = get_list_page_data(spider, sel)[:10]
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': data
|
||||
}
|
||||
|
||||
elif spider['crawl_type'] == CrawlType.DETAIL:
|
||||
# TODO: 详情页预览
|
||||
pass
|
||||
|
||||
elif spider['crawl_type'] == CrawlType.LIST_DETAIL:
|
||||
data = get_list_page_data(spider, sel)[:10]
|
||||
|
||||
ev_list = []
|
||||
for idx, d in enumerate(data):
|
||||
for f in spider['fields']:
|
||||
if f.get('is_detail'):
|
||||
url = d.get(f['name'])
|
||||
if url is not None:
|
||||
if not url.startswith('http') and not url.startswith('//'):
|
||||
u = urlparse(spider['start_url'])
|
||||
url = f'{u.scheme}://{u.netloc}{url}'
|
||||
ev_list.append(gevent.spawn(get_detail_page_data, url, spider, idx, data))
|
||||
break
|
||||
|
||||
gevent.joinall(ev_list)
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'items': data
|
||||
}
|
||||
|
||||
def extract_fields(self, id: str):
|
||||
"""
|
||||
Extract list fields from a web page
|
||||
:param id:
|
||||
:return:
|
||||
"""
|
||||
spider = db_manager.get(col_name='spiders', id=id)
|
||||
|
||||
# get html parse tree
|
||||
sel = self._get_html(spider)
|
||||
|
||||
# when error happens, return
|
||||
if type(sel) == tuple:
|
||||
return sel
|
||||
|
||||
list_tag_list = []
|
||||
threshold = spider.get('item_threshold') or 10
|
||||
# iterate all child nodes in a top-down direction
|
||||
for tag in sel.iter():
|
||||
# get child tags
|
||||
child_tags = self._get_children(tag)
|
||||
|
||||
if len(child_tags) < threshold:
|
||||
# if number of child tags is below threshold, skip
|
||||
continue
|
||||
else:
|
||||
# have one or more child tags
|
||||
child_tags_set = set(map(lambda x: x.tag, child_tags))
|
||||
|
||||
# if there are more than 1 tag names, skip
|
||||
if len(child_tags_set) > 1:
|
||||
continue
|
||||
|
||||
# add as list tag
|
||||
list_tag_list.append(tag)
|
||||
|
||||
# find the list tag with the most child text tags
|
||||
max_tag = None
|
||||
max_num = 0
|
||||
for tag in list_tag_list:
|
||||
_child_text_tags = self._get_text_child_tags(self._get_children(tag)[0])
|
||||
if len(_child_text_tags) > max_num:
|
||||
max_tag = tag
|
||||
max_num = len(_child_text_tags)
|
||||
|
||||
# get list item selector
|
||||
item_selector = None
|
||||
item_selector_type = 'css'
|
||||
if max_tag.get('id') is not None:
|
||||
item_selector = f'#{max_tag.get("id")} > {self._get_children(max_tag)[0].tag}'
|
||||
elif max_tag.get('class') is not None:
|
||||
cls_str = '.'.join([x for x in max_tag.get("class").split(' ') if x != ''])
|
||||
if len(sel.cssselect(f'.{cls_str}')) == 1:
|
||||
item_selector = f'.{cls_str} > {self._get_children(max_tag)[0].tag}'
|
||||
else:
|
||||
item_selector = max_tag.getroottree().getpath(max_tag)
|
||||
item_selector_type = 'xpath'
|
||||
|
||||
# get list fields
|
||||
fields = []
|
||||
if item_selector is not None:
|
||||
first_tag = self._get_children(max_tag)[0]
|
||||
for i, tag in enumerate(self._get_text_child_tags(first_tag)):
|
||||
el_list = first_tag.cssselect(f'{tag.tag}')
|
||||
if len(el_list) == 1:
|
||||
fields.append({
|
||||
'name': f'field{i + 1}',
|
||||
'type': 'css',
|
||||
'extract_type': 'text',
|
||||
'query': f'{tag.tag}',
|
||||
})
|
||||
elif tag.get('class') is not None:
|
||||
cls_str = '.'.join([x for x in tag.get("class").split(' ') if x != ''])
|
||||
if len(tag.cssselect(f'{tag.tag}.{cls_str}')) == 1:
|
||||
fields.append({
|
||||
'name': f'field{i + 1}',
|
||||
'type': 'css',
|
||||
'extract_type': 'text',
|
||||
'query': f'{tag.tag}.{cls_str}',
|
||||
})
|
||||
else:
|
||||
for j, el in enumerate(el_list):
|
||||
if tag == el:
|
||||
fields.append({
|
||||
'name': f'field{i + 1}',
|
||||
'type': 'css',
|
||||
'extract_type': 'text',
|
||||
'query': f'{tag.tag}:nth-of-type({j + 1})',
|
||||
})
|
||||
|
||||
for i, tag in enumerate(self._get_a_child_tags(self._get_children(max_tag)[0])):
|
||||
# if the tag is <a...></a>, extract its href
|
||||
if tag.get('class') is not None:
|
||||
cls_str = '.'.join([x for x in tag.get("class").split(' ') if x != ''])
|
||||
fields.append({
|
||||
'name': f'field{i + 1}_url',
|
||||
'type': 'css',
|
||||
'extract_type': 'attribute',
|
||||
'attribute': 'href',
|
||||
'query': f'{tag.tag}.{cls_str}',
|
||||
})
|
||||
|
||||
# get pagination tag
|
||||
pagination_selector = None
|
||||
pagination_tag = self._get_next_page_tag(sel)
|
||||
if pagination_tag is not None:
|
||||
if pagination_tag.get('id') is not None:
|
||||
pagination_selector = f'#{pagination_tag.get("id")}'
|
||||
elif pagination_tag.get('class') is not None and len(sel.cssselect(f'.{pagination_tag.get("id")}')) == 1:
|
||||
pagination_selector = f'.{pagination_tag.get("id")}'
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'item_selector': item_selector,
|
||||
'item_selector_type': item_selector_type,
|
||||
'pagination_selector': pagination_selector,
|
||||
'fields': fields
|
||||
}
|
||||
|
||||
|
||||
class SpiderImportApi(Resource):
|
||||
__doc__ = """
|
||||
API for importing spiders from external resources including Github, Gitlab, and subversion (WIP)
|
||||
"""
|
||||
parser = reqparse.RequestParser()
|
||||
arguments = [
|
||||
('url', str)
|
||||
]
|
||||
|
||||
def __init__(self):
|
||||
super(SpiderImportApi).__init__()
|
||||
for arg, type in self.arguments:
|
||||
self.parser.add_argument(arg, type=type)
|
||||
|
||||
def post(self, platform: str = None) -> (dict, tuple):
|
||||
if platform is None:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 404,
|
||||
'error': 'platform invalid'
|
||||
}, 404
|
||||
|
||||
if not hasattr(self, platform):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'platform "%s" invalid' % platform
|
||||
}, 400
|
||||
|
||||
return getattr(self, platform)()
|
||||
|
||||
def github(self) -> None:
|
||||
"""
|
||||
Import Github API
|
||||
"""
|
||||
self._git()
|
||||
|
||||
def gitlab(self) -> None:
|
||||
"""
|
||||
Import Gitlab API
|
||||
"""
|
||||
self._git()
|
||||
|
||||
def _git(self):
|
||||
"""
|
||||
Helper method to perform github important (basically "git clone" method).
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
url = args.get('url')
|
||||
if url is None:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'url should not be empty'
|
||||
}, 400
|
||||
|
||||
try:
|
||||
p = subprocess.Popen(['git', 'clone', url], cwd=PROJECT_SOURCE_FILE_FOLDER)
|
||||
_stdout, _stderr = p.communicate()
|
||||
except Exception as err:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 500,
|
||||
'error': str(err)
|
||||
}, 500
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'message': 'success'
|
||||
}
|
||||
|
||||
|
||||
class SpiderManageApi(Resource):
|
||||
parser = reqparse.RequestParser()
|
||||
arguments = [
|
||||
('url', str)
|
||||
]
|
||||
|
||||
def post(self, action: str) -> (dict, tuple):
|
||||
"""
|
||||
POST method for SpiderManageAPI.
|
||||
:param action:
|
||||
"""
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
|
||||
return getattr(self, action)()
|
||||
|
||||
def deploy_all(self) -> (dict, tuple):
|
||||
"""
|
||||
Deploy all spiders to all nodes.
|
||||
"""
|
||||
# active nodes
|
||||
nodes = db_manager.list('nodes', {'status': NodeStatus.ONLINE})
|
||||
|
||||
# all spiders
|
||||
spiders = db_manager.list('spiders', {'cmd': {'$exists': True}})
|
||||
|
||||
# iterate all nodes
|
||||
for node in nodes:
|
||||
node_id = node['_id']
|
||||
for spider in spiders:
|
||||
spider_id = spider['_id']
|
||||
spider_src = spider['src']
|
||||
|
||||
output_file_name = '%s_%s.zip' % (
|
||||
datetime.now().strftime('%Y%m%d%H%M%S'),
|
||||
str(random())[2:12]
|
||||
)
|
||||
output_file_path = os.path.join(PROJECT_TMP_FOLDER, output_file_name)
|
||||
|
||||
# zip source folder to zip file
|
||||
zip_file(source_dir=spider_src,
|
||||
output_filename=output_file_path)
|
||||
|
||||
# upload to api
|
||||
files = {'file': open(output_file_path, 'rb')}
|
||||
r = requests.post('http://%s:%s/api/spiders/%s/deploy_file?node_id=%s' % (
|
||||
node.get('ip'),
|
||||
node.get('port'),
|
||||
spider_id,
|
||||
node_id,
|
||||
), files=files)
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'message': 'success'
|
||||
}
|
||||
|
||||
def upload(self):
|
||||
f = request.files['file']
|
||||
|
||||
if get_file_suffix(f.filename) != 'zip':
|
||||
return {
|
||||
'status': 'ok',
|
||||
'error': 'file type mismatch'
|
||||
}, 400
|
||||
|
||||
# save zip file on temp folder
|
||||
file_path = '%s/%s' % (PROJECT_TMP_FOLDER, f.filename)
|
||||
with open(file_path, 'wb') as fw:
|
||||
fw.write(f.stream.read())
|
||||
|
||||
# unzip zip file
|
||||
dir_path = file_path.replace('.zip', '')
|
||||
if os.path.exists(dir_path):
|
||||
shutil.rmtree(dir_path)
|
||||
unzip_file(file_path, dir_path)
|
||||
|
||||
# copy to source folder
|
||||
output_path = os.path.join(PROJECT_SOURCE_FILE_FOLDER, f.filename.replace('.zip', ''))
|
||||
print(output_path)
|
||||
if os.path.exists(output_path):
|
||||
shutil.rmtree(output_path)
|
||||
shutil.copytree(dir_path, output_path)
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'message': 'success'
|
||||
}
|
||||
@@ -1,235 +0,0 @@
|
||||
import os
|
||||
from collections import defaultdict
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
from flask_restful import reqparse, Resource
|
||||
|
||||
from constants.task import TaskStatus
|
||||
from db.manager import db_manager
|
||||
from routes.base import BaseApi
|
||||
from utils import jsonify
|
||||
|
||||
|
||||
class StatsApi(BaseApi):
|
||||
arguments = [
|
||||
['spider_id', str],
|
||||
]
|
||||
|
||||
def get(self, action: str = None) -> (dict, tuple):
|
||||
"""
|
||||
GET method of StatsApi.
|
||||
:param action: action
|
||||
"""
|
||||
# action
|
||||
if action is not None:
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
return getattr(self, action)()
|
||||
|
||||
else:
|
||||
return {}
|
||||
|
||||
def get_home_stats(self):
|
||||
"""
|
||||
Get stats for home page
|
||||
"""
|
||||
# overview stats
|
||||
task_count = db_manager.count('tasks', {})
|
||||
spider_count = db_manager.count('spiders', {})
|
||||
node_count = db_manager.count('nodes', {})
|
||||
deploy_count = db_manager.count('deploys', {})
|
||||
|
||||
# daily stats
|
||||
cur = db_manager.aggregate('tasks', [
|
||||
{
|
||||
'$project': {
|
||||
'date': {
|
||||
'$dateToString': {
|
||||
'format': '%Y-%m-%d',
|
||||
'date': '$create_ts'
|
||||
}
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
'$group': {
|
||||
'_id': '$date',
|
||||
'count': {
|
||||
'$sum': 1
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
'$sort': {
|
||||
'_id': 1
|
||||
}
|
||||
}
|
||||
])
|
||||
date_cache = {}
|
||||
for item in cur:
|
||||
date_cache[item['_id']] = item['count']
|
||||
start_date = datetime.now() - timedelta(31)
|
||||
end_date = datetime.now() - timedelta(1)
|
||||
date = start_date
|
||||
daily_tasks = []
|
||||
while date < end_date:
|
||||
date = date + timedelta(1)
|
||||
date_str = date.strftime('%Y-%m-%d')
|
||||
daily_tasks.append({
|
||||
'date': date_str,
|
||||
'count': date_cache.get(date_str) or 0,
|
||||
})
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'overview_stats': {
|
||||
'task_count': task_count,
|
||||
'spider_count': spider_count,
|
||||
'node_count': node_count,
|
||||
'deploy_count': deploy_count,
|
||||
},
|
||||
'daily_tasks': daily_tasks
|
||||
}
|
||||
|
||||
def get_spider_stats(self):
|
||||
args = self.parser.parse_args()
|
||||
spider_id = args.get('spider_id')
|
||||
spider = db_manager.get('spiders', id=spider_id)
|
||||
tasks = db_manager.list(
|
||||
col_name='tasks',
|
||||
cond={
|
||||
'spider_id': spider['_id'],
|
||||
'create_ts': {
|
||||
'$gte': datetime.now() - timedelta(30)
|
||||
}
|
||||
},
|
||||
limit=9999999
|
||||
)
|
||||
|
||||
# task count
|
||||
task_count = len(tasks)
|
||||
|
||||
# calculate task count stats
|
||||
task_count_by_status = defaultdict(int)
|
||||
task_count_by_node = defaultdict(int)
|
||||
total_seconds = 0
|
||||
for task in tasks:
|
||||
task_count_by_status[task['status']] += 1
|
||||
task_count_by_node[task.get('node_id')] += 1
|
||||
if task['status'] == TaskStatus.SUCCESS and task.get('finish_ts'):
|
||||
duration = (task['finish_ts'] - task['create_ts']).total_seconds()
|
||||
total_seconds += duration
|
||||
|
||||
# task count by node
|
||||
task_count_by_node_ = []
|
||||
for status, value in task_count_by_node.items():
|
||||
task_count_by_node_.append({
|
||||
'name': status,
|
||||
'value': value
|
||||
})
|
||||
|
||||
# task count by status
|
||||
task_count_by_status_ = []
|
||||
for status, value in task_count_by_status.items():
|
||||
task_count_by_status_.append({
|
||||
'name': status,
|
||||
'value': value
|
||||
})
|
||||
|
||||
# success rate
|
||||
success_rate = task_count_by_status[TaskStatus.SUCCESS] / task_count
|
||||
|
||||
# average duration
|
||||
avg_duration = total_seconds / task_count
|
||||
|
||||
# calculate task count by date
|
||||
cur = db_manager.aggregate('tasks', [
|
||||
{
|
||||
'$match': {
|
||||
'spider_id': spider['_id']
|
||||
}
|
||||
},
|
||||
{
|
||||
'$project': {
|
||||
'date': {
|
||||
'$dateToString': {
|
||||
'format': '%Y-%m-%d',
|
||||
'date': '$create_ts'
|
||||
}
|
||||
},
|
||||
'duration': {
|
||||
'$subtract': [
|
||||
'$finish_ts',
|
||||
'$create_ts'
|
||||
]
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
'$group': {
|
||||
'_id': '$date',
|
||||
'count': {
|
||||
'$sum': 1
|
||||
},
|
||||
'duration': {
|
||||
'$avg': '$duration'
|
||||
}
|
||||
}
|
||||
},
|
||||
{
|
||||
'$sort': {
|
||||
'_id': 1
|
||||
}
|
||||
}
|
||||
])
|
||||
date_cache = {}
|
||||
for item in cur:
|
||||
date_cache[item['_id']] = {
|
||||
'duration': (item['duration'] or 0) / 1000,
|
||||
'count': item['count']
|
||||
}
|
||||
start_date = datetime.now() - timedelta(31)
|
||||
end_date = datetime.now() - timedelta(1)
|
||||
date = start_date
|
||||
daily_tasks = []
|
||||
while date < end_date:
|
||||
date = date + timedelta(1)
|
||||
date_str = date.strftime('%Y-%m-%d')
|
||||
d = date_cache.get(date_str)
|
||||
row = {
|
||||
'date': date_str,
|
||||
}
|
||||
if d is None:
|
||||
row['count'] = 0
|
||||
row['duration'] = 0
|
||||
else:
|
||||
row['count'] = d['count']
|
||||
row['duration'] = d['duration']
|
||||
daily_tasks.append(row)
|
||||
|
||||
# calculate total results
|
||||
result_count = 0
|
||||
col_name = spider.get('col')
|
||||
if col_name is not None:
|
||||
for task in tasks:
|
||||
result_count += db_manager.count(col_name, {'task_id': task['_id']})
|
||||
|
||||
# top tasks
|
||||
# top_10_tasks = db_manager.list('tasks', {'spider_id': spider['_id']})
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'overview': {
|
||||
'task_count': task_count,
|
||||
'result_count': result_count,
|
||||
'success_rate': success_rate,
|
||||
'avg_duration': avg_duration
|
||||
},
|
||||
'task_count_by_status': task_count_by_status_,
|
||||
'task_count_by_node': task_count_by_node_,
|
||||
'daily_stats': daily_tasks,
|
||||
}
|
||||
@@ -1,256 +0,0 @@
|
||||
import json
|
||||
import os
|
||||
import sys
|
||||
from time import time
|
||||
|
||||
from flask_csv import send_csv
|
||||
|
||||
try:
|
||||
from _signal import SIGKILL
|
||||
except ImportError:
|
||||
pass
|
||||
|
||||
import requests
|
||||
from bson import ObjectId
|
||||
from tasks.celery import celery_app
|
||||
|
||||
from constants.task import TaskStatus
|
||||
from db.manager import db_manager
|
||||
from routes.base import BaseApi
|
||||
from utils import jsonify
|
||||
from utils.spider import get_spider_col_fields
|
||||
|
||||
|
||||
class TaskApi(BaseApi):
|
||||
# collection name
|
||||
col_name = 'tasks'
|
||||
|
||||
arguments = (
|
||||
('deploy_id', str),
|
||||
('file_path', str)
|
||||
)
|
||||
|
||||
def get(self, id: str = None, action: str = None):
|
||||
"""
|
||||
GET method of TaskAPI.
|
||||
:param id: item id
|
||||
:param action: action
|
||||
"""
|
||||
# action by id
|
||||
if action is not None:
|
||||
if not hasattr(self, action):
|
||||
return {
|
||||
'status': 'ok',
|
||||
'code': 400,
|
||||
'error': 'action "%s" invalid' % action
|
||||
}, 400
|
||||
return getattr(self, action)(id)
|
||||
|
||||
elif id is not None:
|
||||
task = db_manager.get(col_name=self.col_name, id=id)
|
||||
spider = db_manager.get(col_name='spiders', id=str(task['spider_id']))
|
||||
|
||||
# spider
|
||||
task['num_results'] = 0
|
||||
if spider:
|
||||
task['spider_name'] = spider['name']
|
||||
if spider.get('col'):
|
||||
col = spider.get('col')
|
||||
num_results = db_manager.count(col, {'task_id': task['_id']})
|
||||
task['num_results'] = num_results
|
||||
|
||||
# duration
|
||||
if task.get('finish_ts') is not None:
|
||||
task['duration'] = (task['finish_ts'] - task['create_ts']).total_seconds()
|
||||
task['avg_num_results'] = round(task['num_results'] / task['duration'], 1)
|
||||
|
||||
try:
|
||||
with open(task['log_file_path']) as f:
|
||||
task['log'] = f.read()
|
||||
except Exception as err:
|
||||
task['log'] = ''
|
||||
return jsonify(task)
|
||||
|
||||
# list tasks
|
||||
args = self.parser.parse_args()
|
||||
page_size = args.get('page_size') or 10
|
||||
page_num = args.get('page_num') or 1
|
||||
filter_str = args.get('filter')
|
||||
filter_ = {}
|
||||
if filter_str is not None:
|
||||
filter_ = json.loads(filter_str)
|
||||
if filter_.get('spider_id'):
|
||||
filter_['spider_id'] = ObjectId(filter_['spider_id'])
|
||||
tasks = db_manager.list(col_name=self.col_name, cond=filter_, limit=page_size, skip=page_size * (page_num - 1),
|
||||
sort_key='create_ts')
|
||||
items = []
|
||||
for task in tasks:
|
||||
# get spider
|
||||
_spider = db_manager.get(col_name='spiders', id=str(task['spider_id']))
|
||||
|
||||
# status
|
||||
if task.get('status') is None:
|
||||
task['status'] = TaskStatus.UNAVAILABLE
|
||||
|
||||
# spider
|
||||
task['num_results'] = 0
|
||||
if _spider:
|
||||
# spider name
|
||||
task['spider_name'] = _spider['name']
|
||||
|
||||
# number of results
|
||||
if _spider.get('col'):
|
||||
col = _spider.get('col')
|
||||
num_results = db_manager.count(col, {'task_id': task['_id']})
|
||||
task['num_results'] = num_results
|
||||
|
||||
# duration
|
||||
if task.get('finish_ts') is not None:
|
||||
task['duration'] = (task['finish_ts'] - task['create_ts']).total_seconds()
|
||||
task['avg_num_results'] = round(task['num_results'] / task['duration'], 1)
|
||||
|
||||
items.append(task)
|
||||
|
||||
return {
|
||||
'status': 'ok',
|
||||
'total_count': db_manager.count('tasks', filter_),
|
||||
'page_num': page_num,
|
||||
'page_size': page_size,
|
||||
'items': jsonify(items)
|
||||
}
|
||||
|
||||
def on_get_log(self, id: (str, ObjectId)) -> (dict, tuple):
|
||||
"""
|
||||
Get the log of given task_id
|
||||
:param id: task_id
|
||||
"""
|
||||
try:
|
||||
task = db_manager.get(col_name=self.col_name, id=id)
|
||||
with open(task['log_file_path']) as f:
|
||||
log = f.read()
|
||||
return {
|
||||
'status': 'ok',
|
||||
'log': log
|
||||
}
|
||||
except Exception as err:
|
||||
return {
|
||||
'code': 500,
|
||||
'status': 'ok',
|
||||
'error': str(err)
|
||||
}, 500
|
||||
|
||||
def get_log(self, id: (str, ObjectId)) -> (dict, tuple):
|
||||
"""
|
||||
Submit an HTTP request to fetch log from the node of a given task.
|
||||
:param id: task_id
|
||||
:return:
|
||||
"""
|
||||
task = db_manager.get(col_name=self.col_name, id=id)
|
||||
node = db_manager.get(col_name='nodes', id=task['node_id'])
|
||||
r = requests.get('http://%s:%s/api/tasks/%s/on_get_log' % (
|
||||
node['ip'],
|
||||
node['port'],
|
||||
id
|
||||
))
|
||||
if r.status_code == 200:
|
||||
data = json.loads(r.content.decode('utf-8'))
|
||||
return {
|
||||
'status': 'ok',
|
||||
'log': data.get('log')
|
||||
}
|
||||
else:
|
||||
data = json.loads(r.content)
|
||||
return {
|
||||
'code': 500,
|
||||
'status': 'ok',
|
||||
'error': data['error']
|
||||
}, 500
|
||||
|
||||
def get_results(self, id: str) -> (dict, tuple):
|
||||
"""
|
||||
Get a list of results crawled in a given task.
|
||||
:param id: task_id
|
||||
"""
|
||||
args = self.parser.parse_args()
|
||||
page_size = args.get('page_size') or 10
|
||||
page_num = args.get('page_num') or 1
|
||||
|
||||
task = db_manager.get('tasks', id=id)
|
||||
spider = db_manager.get('spiders', id=task['spider_id'])
|
||||
col_name = spider.get('col')
|
||||
if not col_name:
|
||||
return []
|
||||
fields = get_spider_col_fields(col_name)
|
||||
items = db_manager.list(col_name, {'task_id': id}, skip=page_size * (page_num - 1), limit=page_size)
|
||||
return {
|
||||
'status': 'ok',
|
||||
'fields': jsonify(fields),
|
||||
'total_count': db_manager.count(col_name, {'task_id': id}),
|
||||
'page_num': page_num,
|
||||
'page_size': page_size,
|
||||
'items': jsonify(items)
|
||||
}
|
||||
|
||||
def stop(self, id):
|
||||
"""
|
||||
Send stop signal to a specific node
|
||||
:param id: task_id
|
||||
"""
|
||||
task = db_manager.get('tasks', id=id)
|
||||
node = db_manager.get('nodes', id=task['node_id'])
|
||||
r = requests.get('http://%s:%s/api/tasks/%s/on_stop' % (
|
||||
node['ip'],
|
||||
node['port'],
|
||||
id
|
||||
))
|
||||
if r.status_code == 200:
|
||||
return {
|
||||
'status': 'ok',
|
||||
'message': 'success'
|
||||
}
|
||||
else:
|
||||
data = json.loads(r.content)
|
||||
return {
|
||||
'code': 500,
|
||||
'status': 'ok',
|
||||
'error': data['error']
|
||||
}, 500
|
||||
|
||||
def on_stop(self, id):
|
||||
"""
|
||||
Stop the task in progress.
|
||||
:param id:
|
||||
:return:
|
||||
"""
|
||||
task = db_manager.get('tasks', id=id)
|
||||
celery_app.control.revoke(id, terminate=True)
|
||||
db_manager.update_one('tasks', id=id, values={
|
||||
'status': TaskStatus.REVOKED
|
||||
})
|
||||
|
||||
# kill process
|
||||
if task.get('pid'):
|
||||
pid = task.get('pid')
|
||||
if 'win32' in sys.platform:
|
||||
os.popen('taskkill /pid:' + str(pid))
|
||||
else:
|
||||
# unix system
|
||||
os.kill(pid, SIGKILL)
|
||||
|
||||
return {
|
||||
'id': id,
|
||||
'status': 'ok',
|
||||
}
|
||||
|
||||
def download_results(self, id: str):
|
||||
task = db_manager.get('tasks', id=id)
|
||||
spider = db_manager.get('spiders', id=task['spider_id'])
|
||||
col_name = spider.get('col')
|
||||
if not col_name:
|
||||
return send_csv([], f'results_{col_name}_{round(time())}.csv')
|
||||
items = db_manager.list(col_name, {'task_id': id}, limit=999999999)
|
||||
fields = get_spider_col_fields(col_name, task_id=id, limit=999999999)
|
||||
return send_csv(items,
|
||||
filename=f'results_{col_name}_{round(time())}.csv',
|
||||
fields=fields,
|
||||
encoding='utf-8')
|
||||
@@ -1,11 +0,0 @@
|
||||
# Automatically created by: scrapy startproject
|
||||
#
|
||||
# For more information about the [deploy] section see:
|
||||
# https://scrapyd.readthedocs.io/en/latest/deploy.html
|
||||
|
||||
[settings]
|
||||
default = spiders.settings
|
||||
|
||||
[deploy]
|
||||
#url = http://localhost:6800/
|
||||
project = spiders
|
||||
@@ -1,18 +0,0 @@
|
||||
import os
|
||||
|
||||
from pymongo import MongoClient
|
||||
|
||||
MONGO_HOST = os.environ.get('MONGO_HOST') or 'localhost'
|
||||
MONGO_PORT = int(os.environ.get('MONGO_PORT')) or 27017
|
||||
MONGO_USERNAME = os.environ.get('MONGO_USERNAME')
|
||||
MONGO_PASSWORD = os.environ.get('MONGO_PASSWORD')
|
||||
MONGO_DB = os.environ.get('MONGO_DB') or 'crawlab_test'
|
||||
mongo = MongoClient(host=MONGO_HOST,
|
||||
port=MONGO_PORT,
|
||||
username=MONGO_USERNAME,
|
||||
password=MONGO_PASSWORD)
|
||||
db = mongo[MONGO_DB]
|
||||
task_id = os.environ.get('CRAWLAB_TASK_ID')
|
||||
col_name = os.environ.get('CRAWLAB_COLLECTION')
|
||||
task = db['tasks'].find_one({'_id': task_id})
|
||||
spider = db['spiders'].find_one({'_id': task['spider_id']})
|
||||
@@ -1,25 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Define here the models for your scraped items
|
||||
#
|
||||
# See documentation in:
|
||||
# https://doc.scrapy.org/en/latest/topics/items.html
|
||||
|
||||
import scrapy
|
||||
|
||||
from spiders.db import spider
|
||||
|
||||
|
||||
class SpidersItem(scrapy.Item):
|
||||
if spider['crawl_type'] == 'list':
|
||||
fields = {f['name']: scrapy.Field() for f in spider['fields']}
|
||||
elif spider['crawl_type'] == 'detail':
|
||||
fields = {f['name']: scrapy.Field() for f in spider['detail_fields']}
|
||||
elif spider['crawl_type'] == 'list-detail':
|
||||
fields = {f['name']: scrapy.Field() for f in (spider['fields'] + spider['detail_fields'])}
|
||||
else:
|
||||
fields = {}
|
||||
|
||||
# basic fields
|
||||
fields['_id'] = scrapy.Field()
|
||||
fields['task_id'] = scrapy.Field()
|
||||
@@ -1,103 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Define here the models for your spider middleware
|
||||
#
|
||||
# See documentation in:
|
||||
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
|
||||
|
||||
from scrapy import signals
|
||||
|
||||
|
||||
class SpidersSpiderMiddleware(object):
|
||||
# Not all methods need to be defined. If a method is not defined,
|
||||
# scrapy acts as if the spider middleware does not modify the
|
||||
# passed objects.
|
||||
|
||||
@classmethod
|
||||
def from_crawler(cls, crawler):
|
||||
# This method is used by Scrapy to create your spiders.
|
||||
s = cls()
|
||||
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
|
||||
return s
|
||||
|
||||
def process_spider_input(self, response, spider):
|
||||
# Called for each response that goes through the spider
|
||||
# middleware and into the spider.
|
||||
|
||||
# Should return None or raise an exception.
|
||||
return None
|
||||
|
||||
def process_spider_output(self, response, result, spider):
|
||||
# Called with the results returned from the Spider, after
|
||||
# it has processed the response.
|
||||
|
||||
# Must return an iterable of Request, dict or Item objects.
|
||||
for i in result:
|
||||
yield i
|
||||
|
||||
def process_spider_exception(self, response, exception, spider):
|
||||
# Called when a spider or process_spider_input() method
|
||||
# (from other spider middleware) raises an exception.
|
||||
|
||||
# Should return either None or an iterable of Response, dict
|
||||
# or Item objects.
|
||||
pass
|
||||
|
||||
def process_start_requests(self, start_requests, spider):
|
||||
# Called with the start requests of the spider, and works
|
||||
# similarly to the process_spider_output() method, except
|
||||
# that it doesn’t have a response associated.
|
||||
|
||||
# Must return only requests (not items).
|
||||
for r in start_requests:
|
||||
yield r
|
||||
|
||||
def spider_opened(self, spider):
|
||||
spider.logger.info('Spider opened: %s' % spider.name)
|
||||
|
||||
|
||||
class SpidersDownloaderMiddleware(object):
|
||||
# Not all methods need to be defined. If a method is not defined,
|
||||
# scrapy acts as if the downloader middleware does not modify the
|
||||
# passed objects.
|
||||
|
||||
@classmethod
|
||||
def from_crawler(cls, crawler):
|
||||
# This method is used by Scrapy to create your spiders.
|
||||
s = cls()
|
||||
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
|
||||
return s
|
||||
|
||||
def process_request(self, request, spider):
|
||||
# Called for each request that goes through the downloader
|
||||
# middleware.
|
||||
|
||||
# Must either:
|
||||
# - return None: continue processing this request
|
||||
# - or return a Response object
|
||||
# - or return a Request object
|
||||
# - or raise IgnoreRequest: process_exception() methods of
|
||||
# installed downloader middleware will be called
|
||||
return None
|
||||
|
||||
def process_response(self, request, response, spider):
|
||||
# Called with the response returned from the downloader.
|
||||
|
||||
# Must either;
|
||||
# - return a Response object
|
||||
# - return a Request object
|
||||
# - or raise IgnoreRequest
|
||||
return response
|
||||
|
||||
def process_exception(self, request, exception, spider):
|
||||
# Called when a download handler or a process_request()
|
||||
# (from other downloader middleware) raises an exception.
|
||||
|
||||
# Must either:
|
||||
# - return None: continue processing this exception
|
||||
# - return a Response object: stops process_exception() chain
|
||||
# - return a Request object: stops process_exception() chain
|
||||
pass
|
||||
|
||||
def spider_opened(self, spider):
|
||||
spider.logger.info('Spider opened: %s' % spider.name)
|
||||
@@ -1,17 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Define your item pipelines here
|
||||
#
|
||||
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
|
||||
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
|
||||
from spiders.db import db, col_name, task_id
|
||||
|
||||
|
||||
class SpidersPipeline(object):
|
||||
col = db[col_name]
|
||||
|
||||
def process_item(self, item, spider):
|
||||
item['task_id'] = task_id
|
||||
self.col.save(item)
|
||||
|
||||
return item
|
||||
@@ -1,90 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
# Scrapy settings for spiders project
|
||||
#
|
||||
# For simplicity, this file contains only settings considered important or
|
||||
# commonly used. You can find more settings consulting the documentation:
|
||||
#
|
||||
# https://doc.scrapy.org/en/latest/topics/settings.html
|
||||
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
|
||||
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
|
||||
from spiders.db import spider
|
||||
|
||||
BOT_NAME = 'Crawlab Spider'
|
||||
|
||||
SPIDER_MODULES = ['spiders.spiders']
|
||||
NEWSPIDER_MODULE = 'spiders.spiders'
|
||||
|
||||
# Crawl responsibly by identifying yourself (and your website) on the user-agent
|
||||
# USER_AGENT = 'spiders (+http://www.yourdomain.com)'
|
||||
|
||||
# Obey robots.txt rules
|
||||
ROBOTSTXT_OBEY = spider.get('obey_robots_txt') if spider.get('obey_robots_txt') is not None else True
|
||||
|
||||
# Configure maximum concurrent requests performed by Scrapy (default: 16)
|
||||
# CONCURRENT_REQUESTS = 32
|
||||
|
||||
# Configure a delay for requests for the same website (default: 0)
|
||||
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
|
||||
# See also autothrottle settings and docs
|
||||
# DOWNLOAD_DELAY = 3
|
||||
# The download delay setting will honor only one of:
|
||||
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
|
||||
# CONCURRENT_REQUESTS_PER_IP = 16
|
||||
|
||||
# Disable cookies (enabled by default)
|
||||
# COOKIES_ENABLED = False
|
||||
|
||||
# Disable Telnet Console (enabled by default)
|
||||
# TELNETCONSOLE_ENABLED = False
|
||||
|
||||
# Override the default request headers:
|
||||
# DEFAULT_REQUEST_HEADERS = {
|
||||
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
|
||||
# 'Accept-Language': 'en',
|
||||
# }
|
||||
|
||||
# Enable or disable spider middlewares
|
||||
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
|
||||
# SPIDER_MIDDLEWARES = {
|
||||
# 'spiders.middlewares.SpidersSpiderMiddleware': 543,
|
||||
# }
|
||||
|
||||
# Enable or disable downloader middlewares
|
||||
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
|
||||
# DOWNLOADER_MIDDLEWARES = {
|
||||
# 'spiders.middlewares.SpidersDownloaderMiddleware': 543,
|
||||
# }
|
||||
|
||||
# Enable or disable extensions
|
||||
# See https://doc.scrapy.org/en/latest/topics/extensions.html
|
||||
# EXTENSIONS = {
|
||||
# 'scrapy.extensions.telnet.TelnetConsole': None,
|
||||
# }
|
||||
|
||||
# Configure item pipelines
|
||||
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
|
||||
ITEM_PIPELINES = {
|
||||
'spiders.pipelines.SpidersPipeline': 300,
|
||||
}
|
||||
|
||||
# Enable and configure the AutoThrottle extension (disabled by default)
|
||||
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
|
||||
# AUTOTHROTTLE_ENABLED = True
|
||||
# The initial download delay
|
||||
# AUTOTHROTTLE_START_DELAY = 5
|
||||
# The maximum download delay to be set in case of high latencies
|
||||
# AUTOTHROTTLE_MAX_DELAY = 60
|
||||
# The average number of requests Scrapy should be sending in parallel to
|
||||
# each remote server
|
||||
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
|
||||
# Enable showing throttling stats for every response received:
|
||||
# AUTOTHROTTLE_DEBUG = False
|
||||
|
||||
# Enable and configure HTTP caching (disabled by default)
|
||||
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
|
||||
# HTTPCACHE_ENABLED = True
|
||||
# HTTPCACHE_EXPIRATION_SECS = 0
|
||||
# HTTPCACHE_DIR = 'httpcache'
|
||||
# HTTPCACHE_IGNORE_HTTP_CODES = []
|
||||
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
|
||||
@@ -1,4 +0,0 @@
|
||||
# This package will contain the spiders of your Scrapy project
|
||||
#
|
||||
# Please refer to the documentation for information on how to create and manage
|
||||
# your spiders.
|
||||
@@ -1,123 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
import os
|
||||
import sys
|
||||
from urllib.parse import urlparse, urljoin
|
||||
|
||||
import scrapy
|
||||
|
||||
from spiders.db import spider
|
||||
from spiders.items import SpidersItem
|
||||
from spiders.utils import generate_urls
|
||||
|
||||
sys.path.append(os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..', '..')))
|
||||
|
||||
|
||||
def get_detail_url(item):
|
||||
for f in spider['fields']:
|
||||
if f.get('is_detail'):
|
||||
return item.get(f['name'])
|
||||
return None
|
||||
|
||||
|
||||
def get_spiders_item(sel, fields, item=None):
|
||||
if item is None:
|
||||
item = SpidersItem()
|
||||
|
||||
for f in fields:
|
||||
if f['type'] == 'xpath':
|
||||
# xpath selector
|
||||
if f['extract_type'] == 'text':
|
||||
# text content
|
||||
query = f['query'] + '/text()'
|
||||
else:
|
||||
# attribute
|
||||
attribute = f["attribute"]
|
||||
query = f['query'] + f'/@("{attribute}")'
|
||||
item[f['name']] = sel.xpath(query).extract_first()
|
||||
|
||||
else:
|
||||
# css selector
|
||||
if f['extract_type'] == 'text':
|
||||
# text content
|
||||
query = f['query'] + '::text'
|
||||
else:
|
||||
# attribute
|
||||
attribute = f["attribute"]
|
||||
query = f['query'] + f'::attr("{attribute}")'
|
||||
item[f['name']] = sel.css(query).extract_first()
|
||||
|
||||
return item
|
||||
|
||||
|
||||
def get_list_items(response):
|
||||
if spider['item_selector_type'] == 'xpath':
|
||||
# xpath selector
|
||||
items = response.xpath(spider['item_selector'])
|
||||
else:
|
||||
# css selector
|
||||
items = response.css(spider['item_selector'])
|
||||
return items
|
||||
|
||||
|
||||
def get_next_url(response):
|
||||
# pagination
|
||||
if spider.get('pagination_selector') is not None:
|
||||
if spider['pagination_selector_type'] == 'xpath':
|
||||
# xpath selector
|
||||
next_url = response.xpath(spider['pagination_selector'] + '/@href').extract_first()
|
||||
else:
|
||||
# css selector
|
||||
next_url = response.css(spider['pagination_selector'] + '::attr("href")').extract_first()
|
||||
|
||||
# found next url
|
||||
if next_url is not None:
|
||||
if not next_url.startswith('http') and not next_url.startswith('//'):
|
||||
return urljoin(response.url, next_url)
|
||||
else:
|
||||
return next_url
|
||||
return None
|
||||
|
||||
|
||||
class ConfigSpiderSpider(scrapy.Spider):
|
||||
name = 'config_spider'
|
||||
|
||||
def start_requests(self):
|
||||
for url in generate_urls(spider['start_url']):
|
||||
yield scrapy.Request(url=url)
|
||||
|
||||
def parse(self, response):
|
||||
|
||||
if spider['crawl_type'] == 'list':
|
||||
# list page only
|
||||
items = get_list_items(response)
|
||||
for _item in items:
|
||||
item = get_spiders_item(sel=_item, fields=spider['fields'])
|
||||
yield item
|
||||
next_url = get_next_url(response)
|
||||
if next_url is not None:
|
||||
yield scrapy.Request(url=next_url)
|
||||
|
||||
elif spider['crawl_type'] == 'detail':
|
||||
# TODO: detail page only
|
||||
# detail page only
|
||||
pass
|
||||
|
||||
elif spider['crawl_type'] == 'list-detail':
|
||||
# list page + detail page
|
||||
items = get_list_items(response)
|
||||
for _item in items:
|
||||
item = get_spiders_item(sel=_item, fields=spider['fields'])
|
||||
detail_url = get_detail_url(item)
|
||||
if detail_url is not None:
|
||||
yield scrapy.Request(url=detail_url,
|
||||
callback=self.parse_detail,
|
||||
meta={
|
||||
'item': item
|
||||
})
|
||||
next_url = get_next_url(response)
|
||||
if next_url is not None:
|
||||
yield scrapy.Request(url=next_url)
|
||||
|
||||
def parse_detail(self, response):
|
||||
item = get_spiders_item(sel=response, fields=spider['detail_fields'], item=response.meta['item'])
|
||||
yield item
|
||||
@@ -1,55 +0,0 @@
|
||||
import itertools
|
||||
import re
|
||||
|
||||
|
||||
def generate_urls(base_url: str) -> str:
|
||||
url = base_url
|
||||
|
||||
# number range list
|
||||
list_arr = []
|
||||
for i, res in enumerate(re.findall(r'{(\d+),(\d+)}', base_url)):
|
||||
try:
|
||||
_min = int(res[0])
|
||||
_max = int(res[1])
|
||||
except ValueError as err:
|
||||
raise ValueError(f'{base_url} is not a valid URL pattern')
|
||||
|
||||
# list
|
||||
_list = range(_min, _max + 1)
|
||||
|
||||
# key
|
||||
_key = f'n{i}'
|
||||
|
||||
# append list and key
|
||||
list_arr.append((_list, _key))
|
||||
|
||||
# replace url placeholder with key
|
||||
url = url.replace('{' + res[0] + ',' + res[1] + '}', '{' + _key + '}', 1)
|
||||
|
||||
# string list
|
||||
for i, res in enumerate(re.findall(r'\[([\w\-,]+)\]', base_url)):
|
||||
# list
|
||||
_list = res.split(',')
|
||||
|
||||
# key
|
||||
_key = f's{i}'
|
||||
|
||||
# append list and key
|
||||
list_arr.append((_list, _key))
|
||||
|
||||
# replace url placeholder with key
|
||||
url = url.replace('[' + ','.join(_list) + ']', '{' + _key + '}', 1)
|
||||
|
||||
# combine together
|
||||
_list_arr = []
|
||||
for res in itertools.product(*map(lambda x: x[0], list_arr)):
|
||||
_url = url
|
||||
for _arr, _rep in zip(list_arr, res):
|
||||
_list, _key = _arr
|
||||
_url = _url.replace('{' + _key + '}', str(_rep), 1)
|
||||
yield _url
|
||||
|
||||
#
|
||||
# base_url = 'http://[baidu,ali].com/page-{1,10}-[1,2,3]'
|
||||
# for url in generate_urls(base_url):
|
||||
# print(url)
|
||||
@@ -1,353 +0,0 @@
|
||||
---
|
||||
swagger: '2.0'
|
||||
basePath: "/api"
|
||||
paths:
|
||||
"/deploys":
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of DeployAPI
|
||||
operationId: get_deploy_api
|
||||
tags:
|
||||
- deploy
|
||||
put:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: PUT method for creating a new item
|
||||
operationId: put_deploy_api
|
||||
tags:
|
||||
- deploy
|
||||
"/deploys/{id}":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of DeployAPI
|
||||
operationId: get_deploy_api_by_id
|
||||
tags:
|
||||
- deploy
|
||||
post:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: POST method of the given id for performing an action
|
||||
operationId: post_deploy_api
|
||||
tags:
|
||||
- deploy
|
||||
delete:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: DELETE method of given id for deleting an item
|
||||
operationId: delete_deploy_api
|
||||
tags:
|
||||
- deploy
|
||||
"/files":
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of FileAPI
|
||||
operationId: get_file_api
|
||||
tags:
|
||||
- file
|
||||
"/nodes":
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of NodeAPI
|
||||
operationId: get_node_api
|
||||
tags:
|
||||
- node
|
||||
put:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: PUT method for creating a new item
|
||||
operationId: put_node_api
|
||||
tags:
|
||||
- node
|
||||
"/nodes/{id}":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of NodeAPI
|
||||
operationId: get_node_api_by_id
|
||||
tags:
|
||||
- node
|
||||
post:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: POST method of the given id for performing an action
|
||||
operationId: post_node_api
|
||||
tags:
|
||||
- node
|
||||
delete:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: DELETE method of the given id
|
||||
operationId: delete_node_api
|
||||
tags:
|
||||
- node
|
||||
"/nodes/{id}/get_deploys":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Get a list of latest deploys of given node_id
|
||||
tags:
|
||||
- node
|
||||
"/nodes/{id}/get_tasks":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Get a list of latest tasks of given node_id
|
||||
tags:
|
||||
- node
|
||||
"/spiders":
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of SpiderAPI
|
||||
operationId: get_spider_api
|
||||
tags:
|
||||
- spider
|
||||
put:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: PUT method for creating a new item
|
||||
operationId: put_spider_api
|
||||
tags:
|
||||
- spider
|
||||
"/spiders/import/{platform}":
|
||||
parameters:
|
||||
- name: platform
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
post:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
operationId: post_spider_import_api
|
||||
tags:
|
||||
- spider
|
||||
"/spiders/manage/deploy_all":
|
||||
post:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Deploy all spiders to all nodes.
|
||||
tags:
|
||||
- spider
|
||||
"/spiders/{id}":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of SpiderAPI
|
||||
operationId: get_spider_api_by_id
|
||||
tags:
|
||||
- spider
|
||||
post:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: POST method of the given id for performing an action
|
||||
operationId: post_spider_api
|
||||
tags:
|
||||
- spider
|
||||
delete:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: DELETE method of given id for deleting an item
|
||||
operationId: delete_spider_api
|
||||
tags:
|
||||
- spider
|
||||
"/spiders/{id}/get_tasks":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
description: spider_id
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Get a list of latest tasks of given spider_id
|
||||
tags:
|
||||
- spider
|
||||
"/spiders/{id}/get_deploys":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
description: spider_id
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Get a list of latest deploys of given spider_id
|
||||
tags:
|
||||
- spider
|
||||
"/spiders/{id}/on_crawl":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
description: spider_id
|
||||
post:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Start a crawl task.
|
||||
tags:
|
||||
- spider
|
||||
"/spiders/{id}/deploy":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
description: spider_id
|
||||
post:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Start a crawl task.
|
||||
tags:
|
||||
- spider
|
||||
"/stats/get_home_stats":
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Get stats for home page
|
||||
operationId: get_stats_api
|
||||
tags:
|
||||
- stats
|
||||
"/tasks":
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of TaskAPI
|
||||
operationId: get_task_api
|
||||
tags:
|
||||
- task
|
||||
put:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: PUT method for creating a new item
|
||||
operationId: put_task_api
|
||||
tags:
|
||||
- task
|
||||
"/tasks/{id}":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: GET method of TaskAPI
|
||||
operationId: get_task_api_by_id
|
||||
tags:
|
||||
- task
|
||||
post:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: POST method of the given id for performing an action
|
||||
operationId: post_task_api
|
||||
tags:
|
||||
- task
|
||||
delete:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: DELETE method of given id for deleting an item
|
||||
operationId: delete_task_api
|
||||
tags:
|
||||
- task
|
||||
"/tasks/{id}/get_log":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Submit an HTTP request to fetch log from the node of a given task.
|
||||
operationId: get_task_api_get_log
|
||||
tags:
|
||||
- task
|
||||
"/tasks/{id}/on_get_log":
|
||||
parameters:
|
||||
- name: id
|
||||
in: path
|
||||
required: true
|
||||
type: string
|
||||
get:
|
||||
responses:
|
||||
'200':
|
||||
description: Success
|
||||
summary: Get the log of given task_id
|
||||
operationId: get_task_api_on_get_log
|
||||
tags:
|
||||
- task
|
||||
info:
|
||||
title: Crawlab API
|
||||
version: '1.0'
|
||||
produces:
|
||||
- application/json
|
||||
consumes:
|
||||
- application/json
|
||||
responses:
|
||||
ParseError:
|
||||
description: When a mask can't be parsed
|
||||
MaskError:
|
||||
description: When any error occurs on mask
|
||||
@@ -1,5 +0,0 @@
|
||||
from celery import Celery
|
||||
|
||||
# celery app instance
|
||||
celery_app = Celery(__name__)
|
||||
celery_app.config_from_object('config')
|
||||
@@ -1,18 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
from datetime import datetime
|
||||
|
||||
import requests
|
||||
from celery.utils.log import get_logger
|
||||
|
||||
from config import PROJECT_DEPLOY_FILE_FOLDER, PROJECT_LOGS_FOLDER
|
||||
from db.manager import db_manager
|
||||
from .celery import celery_app
|
||||
import subprocess
|
||||
|
||||
logger = get_logger(__name__)
|
||||
|
||||
|
||||
@celery_app.task
|
||||
def deploy_spider(id):
|
||||
pass
|
||||
@@ -1,7 +0,0 @@
|
||||
from utils import node
|
||||
from .celery import celery_app
|
||||
|
||||
|
||||
@celery_app.task
|
||||
def update_node_status():
|
||||
node.update_nodes_status(refresh=True)
|
||||
@@ -1,89 +0,0 @@
|
||||
import atexit
|
||||
import fcntl
|
||||
|
||||
import requests
|
||||
from apscheduler.schedulers.background import BackgroundScheduler
|
||||
from apscheduler.jobstores.mongodb import MongoDBJobStore
|
||||
from pymongo import MongoClient
|
||||
|
||||
from config import MONGO_DB, MONGO_HOST, MONGO_PORT, FLASK_HOST, FLASK_PORT
|
||||
from db.manager import db_manager
|
||||
|
||||
|
||||
class Scheduler(object):
|
||||
mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT, connect=False)
|
||||
task_col = 'apscheduler_jobs'
|
||||
|
||||
# scheduler jobstore
|
||||
jobstores = {
|
||||
'mongo': MongoDBJobStore(database=MONGO_DB,
|
||||
collection=task_col,
|
||||
client=mongo)
|
||||
}
|
||||
|
||||
# scheduler instance
|
||||
scheduler = BackgroundScheduler(jobstores=jobstores)
|
||||
|
||||
def execute_spider(self, id: str, params: str = None):
|
||||
print(f'executing spider {id}')
|
||||
print(f'params: {params}')
|
||||
self.scheduler.print_jobs(jobstore='mongo')
|
||||
query = {}
|
||||
if params is not None:
|
||||
query['params'] = params
|
||||
r = requests.get('http://%s:%s/api/spiders/%s/on_crawl' % (
|
||||
FLASK_HOST,
|
||||
FLASK_PORT,
|
||||
id
|
||||
), query)
|
||||
|
||||
def update(self):
|
||||
print('updating...')
|
||||
# remove all existing periodic jobs
|
||||
self.scheduler.remove_all_jobs()
|
||||
self.mongo[MONGO_DB][self.task_col].remove()
|
||||
|
||||
periodical_tasks = db_manager.list('schedules', {})
|
||||
for task in periodical_tasks:
|
||||
cron = task.get('cron')
|
||||
cron_arr = cron.split(' ')
|
||||
second = cron_arr[0]
|
||||
minute = cron_arr[1]
|
||||
hour = cron_arr[2]
|
||||
day = cron_arr[3]
|
||||
month = cron_arr[4]
|
||||
day_of_week = cron_arr[5]
|
||||
self.scheduler.add_job(func=self.execute_spider,
|
||||
args=(str(task['spider_id']), task.get('params'),),
|
||||
trigger='cron',
|
||||
jobstore='mongo',
|
||||
day_of_week=day_of_week,
|
||||
month=month,
|
||||
day=day,
|
||||
hour=hour,
|
||||
minute=minute,
|
||||
second=second)
|
||||
self.scheduler.print_jobs(jobstore='mongo')
|
||||
print(f'state: {self.scheduler.state}')
|
||||
print(f'running: {self.scheduler.running}')
|
||||
|
||||
def run(self):
|
||||
f = open("scheduler.lock", "wb")
|
||||
try:
|
||||
fcntl.flock(f, fcntl.LOCK_EX | fcntl.LOCK_NB)
|
||||
self.update()
|
||||
self.scheduler.start()
|
||||
except:
|
||||
pass
|
||||
|
||||
def unlock():
|
||||
fcntl.flock(f, fcntl.LOCK_UN)
|
||||
f.close()
|
||||
|
||||
atexit.register(unlock)
|
||||
|
||||
|
||||
scheduler = Scheduler()
|
||||
|
||||
if __name__ == '__main__':
|
||||
scheduler.run()
|
||||
@@ -1,272 +0,0 @@
|
||||
import os
|
||||
import sys
|
||||
from datetime import datetime
|
||||
from time import sleep
|
||||
import traceback
|
||||
|
||||
from bson import ObjectId
|
||||
from pymongo import ASCENDING, DESCENDING
|
||||
|
||||
from config import PROJECT_DEPLOY_FILE_FOLDER, PROJECT_LOGS_FOLDER, MONGO_HOST, MONGO_PORT, MONGO_DB, MONGO_USERNAME, \
|
||||
MONGO_PASSWORD
|
||||
from constants.task import TaskStatus
|
||||
from db.manager import db_manager
|
||||
from .celery import celery_app
|
||||
import subprocess
|
||||
from utils.log import other as logger
|
||||
|
||||
BASE_DIR = os.path.abspath(os.path.join(os.path.dirname(__file__), '..'))
|
||||
|
||||
|
||||
def get_task(id: str):
|
||||
i = 0
|
||||
while i < 5:
|
||||
task = db_manager.get('tasks', id=id)
|
||||
if task is not None:
|
||||
return task
|
||||
i += 1
|
||||
sleep(1)
|
||||
return None
|
||||
|
||||
|
||||
@celery_app.task(bind=True)
|
||||
def execute_spider(self, id: str, params: str = None):
|
||||
"""
|
||||
Execute spider task.
|
||||
:param self:
|
||||
:param id: task_id
|
||||
"""
|
||||
task_id = self.request.id
|
||||
hostname = self.request.hostname
|
||||
spider = db_manager.get('spiders', id=id)
|
||||
command = spider.get('cmd')
|
||||
|
||||
# if start with python, then use sys.executable to execute in the virtualenv
|
||||
if command.startswith('python '):
|
||||
command = command.replace('python ', sys.executable + ' ')
|
||||
|
||||
# if start with scrapy, then use sys.executable to execute scrapy as module in the virtualenv
|
||||
elif command.startswith('scrapy '):
|
||||
command = command.replace('scrapy ', sys.executable + ' -m scrapy ')
|
||||
|
||||
# pass params to the command
|
||||
if params is not None:
|
||||
command += ' ' + params
|
||||
|
||||
# get task object and return if not found
|
||||
task = get_task(task_id)
|
||||
if task is None:
|
||||
return
|
||||
|
||||
# current working directory
|
||||
current_working_directory = os.path.join(PROJECT_DEPLOY_FILE_FOLDER, str(spider.get('_id')))
|
||||
|
||||
# log info
|
||||
logger.info('task_id: %s' % task_id)
|
||||
logger.info('hostname: %s' % hostname)
|
||||
logger.info('current_working_directory: %s' % current_working_directory)
|
||||
logger.info('spider_id: %s' % id)
|
||||
logger.info(command)
|
||||
|
||||
# make sure the log folder exists
|
||||
log_path = os.path.join(PROJECT_LOGS_FOLDER, id)
|
||||
if not os.path.exists(log_path):
|
||||
os.makedirs(log_path)
|
||||
|
||||
# open log file streams
|
||||
log_file_path = os.path.join(log_path, '%s.log' % datetime.now().strftime('%Y%m%d%H%M%S'))
|
||||
stdout = open(log_file_path, 'a')
|
||||
stderr = open(log_file_path, 'a')
|
||||
|
||||
# update task status as started
|
||||
db_manager.update_one('tasks', id=task_id, values={
|
||||
'start_ts': datetime.utcnow(),
|
||||
'node_id': hostname,
|
||||
'hostname': hostname,
|
||||
'log_file_path': log_file_path,
|
||||
'status': TaskStatus.STARTED
|
||||
})
|
||||
|
||||
# pass params as env variables
|
||||
env = os.environ.copy()
|
||||
|
||||
# custom environment variables
|
||||
if spider.get('envs'):
|
||||
for _env in spider.get('envs'):
|
||||
env[_env['name']] = _env['value']
|
||||
|
||||
# task id environment variable
|
||||
env['CRAWLAB_TASK_ID'] = task_id
|
||||
|
||||
# collection environment variable
|
||||
if spider.get('col'):
|
||||
env['CRAWLAB_COLLECTION'] = spider.get('col')
|
||||
|
||||
# create index to speed results data retrieval
|
||||
db_manager.create_index(spider.get('col'), [('task_id', ASCENDING)])
|
||||
|
||||
# start process
|
||||
cmd_arr = command.split(' ')
|
||||
cmd_arr = list(filter(lambda x: x != '', cmd_arr))
|
||||
try:
|
||||
p = subprocess.Popen(cmd_arr,
|
||||
stdout=stdout.fileno(),
|
||||
stderr=stderr.fileno(),
|
||||
cwd=current_working_directory,
|
||||
env=env,
|
||||
bufsize=1)
|
||||
|
||||
# update pid
|
||||
db_manager.update_one(col_name='tasks', id=task_id, values={
|
||||
'pid': p.pid
|
||||
})
|
||||
|
||||
# get output from the process
|
||||
_stdout, _stderr = p.communicate()
|
||||
|
||||
# get return code
|
||||
code = p.poll()
|
||||
if code == 0:
|
||||
status = TaskStatus.SUCCESS
|
||||
else:
|
||||
status = TaskStatus.FAILURE
|
||||
except Exception as err:
|
||||
logger.error(err)
|
||||
stderr.write(str(err))
|
||||
status = TaskStatus.FAILURE
|
||||
|
||||
# save task when the task is finished
|
||||
finish_ts = datetime.utcnow()
|
||||
db_manager.update_one('tasks', id=task_id, values={
|
||||
'finish_ts': finish_ts,
|
||||
'duration': (finish_ts - task['create_ts']).total_seconds(),
|
||||
'status': status
|
||||
})
|
||||
task = db_manager.get('tasks', id=id)
|
||||
|
||||
# close log file streams
|
||||
stdout.flush()
|
||||
stderr.flush()
|
||||
stdout.close()
|
||||
stderr.close()
|
||||
|
||||
return task
|
||||
|
||||
|
||||
@celery_app.task(bind=True)
|
||||
def execute_config_spider(self, id: str, params: str = None):
|
||||
task_id = self.request.id
|
||||
hostname = self.request.hostname
|
||||
spider = db_manager.get('spiders', id=id)
|
||||
|
||||
# get task object and return if not found
|
||||
task = get_task(task_id)
|
||||
if task is None:
|
||||
return
|
||||
|
||||
# current working directory
|
||||
current_working_directory = os.path.join(BASE_DIR, 'spiders')
|
||||
|
||||
# log info
|
||||
logger.info('task_id: %s' % task_id)
|
||||
logger.info('hostname: %s' % hostname)
|
||||
logger.info('current_working_directory: %s' % current_working_directory)
|
||||
logger.info('spider_id: %s' % id)
|
||||
|
||||
# make sure the log folder exists
|
||||
log_path = os.path.join(PROJECT_LOGS_FOLDER, id)
|
||||
if not os.path.exists(log_path):
|
||||
os.makedirs(log_path)
|
||||
|
||||
# open log file streams
|
||||
log_file_path = os.path.join(log_path, '%s.log' % datetime.now().strftime('%Y%m%d%H%M%S'))
|
||||
stdout = open(log_file_path, 'a')
|
||||
stderr = open(log_file_path, 'a')
|
||||
|
||||
# update task status as started
|
||||
db_manager.update_one('tasks', id=task_id, values={
|
||||
'start_ts': datetime.utcnow(),
|
||||
'node_id': hostname,
|
||||
'hostname': hostname,
|
||||
'log_file_path': log_file_path,
|
||||
'status': TaskStatus.STARTED
|
||||
})
|
||||
|
||||
# pass params as env variables
|
||||
env = os.environ.copy()
|
||||
|
||||
# custom environment variables
|
||||
if spider.get('envs'):
|
||||
for _env in spider.get('envs'):
|
||||
env[_env['name']] = _env['value']
|
||||
|
||||
# task id environment variable
|
||||
env['CRAWLAB_TASK_ID'] = task_id
|
||||
|
||||
# collection environment variable
|
||||
if spider.get('col'):
|
||||
env['CRAWLAB_COLLECTION'] = spider.get('col')
|
||||
|
||||
# create index to speed results data retrieval
|
||||
db_manager.create_index(spider.get('col'), [('task_id', ASCENDING)])
|
||||
|
||||
# mongodb environment variables
|
||||
env['MONGO_HOST'] = MONGO_HOST
|
||||
env['MONGO_PORT'] = str(MONGO_PORT)
|
||||
env['MONGO_DB'] = MONGO_DB
|
||||
if MONGO_USERNAME is not None:
|
||||
env['MONGO_USERNAME'] = MONGO_USERNAME
|
||||
if MONGO_PASSWORD:
|
||||
env['MONGO_PASSWORD'] = MONGO_PASSWORD
|
||||
|
||||
cmd_arr = [
|
||||
sys.executable,
|
||||
'-m',
|
||||
'scrapy',
|
||||
'crawl',
|
||||
'config_spider'
|
||||
]
|
||||
try:
|
||||
p = subprocess.Popen(cmd_arr,
|
||||
stdout=stdout.fileno(),
|
||||
stderr=stderr.fileno(),
|
||||
cwd=current_working_directory,
|
||||
env=env,
|
||||
bufsize=1)
|
||||
|
||||
# update pid
|
||||
db_manager.update_one(col_name='tasks', id=task_id, values={
|
||||
'pid': p.pid
|
||||
})
|
||||
|
||||
# get output from the process
|
||||
_stdout, _stderr = p.communicate()
|
||||
|
||||
# get return code
|
||||
code = p.poll()
|
||||
if code == 0:
|
||||
status = TaskStatus.SUCCESS
|
||||
else:
|
||||
status = TaskStatus.FAILURE
|
||||
except Exception as err:
|
||||
traceback.print_exc()
|
||||
logger.error(err)
|
||||
stderr.write(str(err))
|
||||
status = TaskStatus.FAILURE
|
||||
|
||||
# save task when the task is finished
|
||||
finish_ts = datetime.utcnow()
|
||||
db_manager.update_one('tasks', id=task_id, values={
|
||||
'finish_ts': finish_ts,
|
||||
'duration': (finish_ts - task['create_ts']).total_seconds(),
|
||||
'status': status
|
||||
})
|
||||
task = db_manager.get('tasks', id=id)
|
||||
|
||||
# close log file streams
|
||||
stdout.flush()
|
||||
stderr.flush()
|
||||
stdout.close()
|
||||
stderr.close()
|
||||
|
||||
return task
|
||||
@@ -1,53 +0,0 @@
|
||||
# For a quick start check out our HTTP Requests collection (Tools|HTTP Client|Open HTTP Requests Collection).
|
||||
#
|
||||
# Following HTTP Request Live Templates are available:
|
||||
# * 'gtrp' and 'gtr' create a GET request with or without query parameters;
|
||||
# * 'ptr' and 'ptrp' create a POST request with a simple or parameter-like body;
|
||||
# * 'mptr' and 'fptr' create a POST request to submit a form with a text or file field (multipart/form-data);
|
||||
|
||||
### Send PUT request with json body
|
||||
PUT http://localhost:5000/api/spiders
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"spider_name": "baidu spider",
|
||||
"cmd": "python /Users/yeqing/projects/crawlab/spiders/baidu/baidu.py",
|
||||
"src": "/Users/yeqing/projects/crawlab/spiders/baidu/baidu.py",
|
||||
"spider_type": 1,
|
||||
"lang_type": 1
|
||||
}
|
||||
|
||||
### Send POST request with json body
|
||||
POST http://localhost:5000/api/spiders/5c63a2ddb65d151bee71d76b
|
||||
Content-Type: application/json
|
||||
|
||||
{
|
||||
"spider_name": "baidu spider",
|
||||
"cmd": "/Users/yeqing/projects/crawlab/spiders/baidu/baidu.py",
|
||||
"src": "/Users/yeqing/projects/crawlab/spiders/baidu/baidu.py",
|
||||
"spider_type": 1,
|
||||
"lang_type": 1
|
||||
}
|
||||
|
||||
### Send POST request with json body by path
|
||||
POST http://localhost:5000/api/spiders/5c63a2ddb65d151bee71d76b/crawl
|
||||
Content-Type: application/json
|
||||
|
||||
{}
|
||||
|
||||
###
|
||||
|
||||
### Send GET request with json body by path
|
||||
POST http://localhost:5000/api/spiders/5c63a2ddb65d151bee71d76b/crawl
|
||||
Content-Type: application/json
|
||||
|
||||
{}
|
||||
|
||||
###
|
||||
### Send GET request with json body by path
|
||||
GET http://localhost:5000/api/files?path=/Users/yeqing/projects/crawlab
|
||||
Content-Type: application/json
|
||||
|
||||
{}
|
||||
|
||||
###
|
||||
@@ -1,34 +0,0 @@
|
||||
import json
|
||||
import re
|
||||
from datetime import datetime
|
||||
|
||||
from bson import json_util
|
||||
|
||||
|
||||
def is_object_id(id: str) -> bool:
|
||||
"""
|
||||
Determine if the id is a valid ObjectId string
|
||||
:param id: ObjectId string
|
||||
"""
|
||||
return re.search('^[a-zA-Z0-9]{24}$', id) is not None
|
||||
|
||||
|
||||
def jsonify(obj: (dict, list)) -> (dict, list):
|
||||
"""
|
||||
Convert dict/list to a valid json object.
|
||||
:param obj: object to be converted
|
||||
:return: dict/list
|
||||
"""
|
||||
dump_str = json_util.dumps(obj)
|
||||
converted_obj = json.loads(dump_str)
|
||||
if type(converted_obj) == dict:
|
||||
for k, v in converted_obj.items():
|
||||
if type(v) == dict:
|
||||
if v.get('$oid') is not None:
|
||||
converted_obj[k] = v['$oid']
|
||||
elif v.get('$date') is not None:
|
||||
converted_obj[k] = datetime.fromtimestamp(v['$date'] / 1000).strftime('%Y-%m-%d %H:%M:%S')
|
||||
elif type(converted_obj) == list:
|
||||
for i, v in enumerate(converted_obj):
|
||||
converted_obj[i] = jsonify(v)
|
||||
return converted_obj
|
||||
@@ -1,33 +0,0 @@
|
||||
import os, zipfile
|
||||
from utils.log import other
|
||||
|
||||
|
||||
def zip_file(source_dir, output_filename):
|
||||
"""
|
||||
打包目录为zip文件(未压缩)
|
||||
:param source_dir: source directory
|
||||
:param output_filename: output file name
|
||||
"""
|
||||
zipf = zipfile.ZipFile(output_filename, 'w')
|
||||
pre_len = len(os.path.dirname(source_dir))
|
||||
for parent, dirnames, filenames in os.walk(source_dir):
|
||||
for filename in filenames:
|
||||
pathfile = os.path.join(parent, filename)
|
||||
arcname = pathfile[pre_len:].strip(os.path.sep) # 相对路径
|
||||
zipf.write(pathfile, arcname)
|
||||
zipf.close()
|
||||
|
||||
|
||||
def unzip_file(zip_src, dst_dir):
|
||||
"""
|
||||
Unzip file
|
||||
:param zip_src: source zip file
|
||||
:param dst_dir: destination directory
|
||||
"""
|
||||
r = zipfile.is_zipfile(zip_src)
|
||||
if r:
|
||||
fz = zipfile.ZipFile(zip_src, 'r')
|
||||
for file in fz.namelist():
|
||||
fz.extract(file, dst_dir)
|
||||
else:
|
||||
other.info('This is not zip')
|
||||
@@ -1,79 +0,0 @@
|
||||
import os
|
||||
import re
|
||||
from collections import defaultdict
|
||||
|
||||
SUFFIX_PATTERN = r'\.([a-zA-Z]{,6})$'
|
||||
suffix_regex = re.compile(SUFFIX_PATTERN, re.IGNORECASE)
|
||||
|
||||
SUFFIX_LANG_MAPPING = {
|
||||
'py': 'python',
|
||||
'js': 'javascript',
|
||||
'sh': 'shell',
|
||||
'java': 'java',
|
||||
'c': 'c',
|
||||
'go': 'go',
|
||||
}
|
||||
|
||||
|
||||
def get_file_suffix(file_name: str) -> (str, None):
|
||||
"""
|
||||
Get suffix of a file
|
||||
:param file_name:
|
||||
:return:
|
||||
"""
|
||||
file_name = file_name.lower()
|
||||
m = suffix_regex.search(file_name)
|
||||
if m is not None:
|
||||
return m.groups()[0]
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
def get_file_list(path: str) -> list:
|
||||
"""
|
||||
Get a list of files of given directory path
|
||||
:param path: directory path
|
||||
"""
|
||||
for root, dirs, file_names in os.walk(path):
|
||||
# print(root) # 当前目录路径
|
||||
# print(dirs) # 当前路径下所有子目录
|
||||
# print(file_names) # 当前路径下所有非目录子文件
|
||||
|
||||
for file_name in file_names:
|
||||
file_path = os.path.join(root, file_name)
|
||||
yield file_path
|
||||
|
||||
|
||||
def get_file_suffix_stats(path) -> dict:
|
||||
"""
|
||||
Get suffix stats of given file
|
||||
:param path: file path
|
||||
"""
|
||||
_stats = defaultdict(int)
|
||||
for file_path in get_file_list(path):
|
||||
suffix = get_file_suffix(file_path)
|
||||
if suffix is not None:
|
||||
_stats[suffix] += 1
|
||||
|
||||
# only return suffixes with languages
|
||||
stats = {}
|
||||
for suffix, count in _stats.items():
|
||||
if SUFFIX_LANG_MAPPING.get(suffix) is not None:
|
||||
stats[suffix] = count
|
||||
|
||||
return stats
|
||||
|
||||
|
||||
def get_file_content(path) -> dict:
|
||||
"""
|
||||
Get file content
|
||||
:param path: file path
|
||||
"""
|
||||
with open(path) as f:
|
||||
suffix = get_file_suffix(path)
|
||||
lang = SUFFIX_LANG_MAPPING.get(suffix)
|
||||
return {
|
||||
'lang': lang,
|
||||
'suffix': suffix,
|
||||
'content': f.read()
|
||||
}
|
||||
@@ -1,75 +0,0 @@
|
||||
# -*- coding: utf-8 -*-
|
||||
# @Time : 2019-01-28 15:37
|
||||
# @Author : cxa
|
||||
# @File : log.py
|
||||
# @Software: PyCharm
|
||||
import os
|
||||
import logging
|
||||
import logging.config as log_conf
|
||||
import datetime
|
||||
import coloredlogs
|
||||
|
||||
log_dir = os.path.dirname(os.path.dirname(__file__)) + '/logs'
|
||||
if not os.path.exists(log_dir):
|
||||
os.mkdir(log_dir)
|
||||
today = datetime.datetime.now().strftime("%Y%m%d")
|
||||
|
||||
log_path = os.path.join(log_dir, f'app_{today}.log')
|
||||
|
||||
log_config = {
|
||||
'version': 1.0,
|
||||
'formatters': {
|
||||
'colored_console': {'()': 'coloredlogs.ColoredFormatter',
|
||||
'format': "%(asctime)s - %(name)s - %(levelname)s - %(message)s", 'datefmt': '%H:%M:%S'},
|
||||
'detail': {
|
||||
'format': '%(asctime)s - %(name)s - %(levelname)s - %(message)s',
|
||||
'datefmt': "%Y-%m-%d %H:%M:%S" # 如果不加这个会显示到毫秒。
|
||||
},
|
||||
'simple': {
|
||||
'format': '%(name)s - %(levelname)s - %(message)s',
|
||||
},
|
||||
},
|
||||
'handlers': {
|
||||
'console': {
|
||||
'class': 'logging.StreamHandler', # 日志打印到屏幕显示的类。
|
||||
'level': 'INFO',
|
||||
'formatter': 'colored_console'
|
||||
},
|
||||
'file': {
|
||||
'class': 'logging.handlers.RotatingFileHandler', # 日志打印到文件的类。
|
||||
'maxBytes': 1024 * 1024 * 1024, # 单个文件最大内存
|
||||
'backupCount': 1, # 备份的文件个数
|
||||
'filename': log_path, # 日志文件名
|
||||
'level': 'INFO', # 日志等级
|
||||
'formatter': 'detail', # 调用上面的哪个格式
|
||||
'encoding': 'utf-8', # 编码
|
||||
},
|
||||
},
|
||||
'loggers': {
|
||||
'crawler': {
|
||||
'handlers': ['console', 'file'], # 只打印屏幕
|
||||
'level': 'DEBUG', # 只显示错误的log
|
||||
},
|
||||
'parser': {
|
||||
'handlers': ['file'],
|
||||
'level': 'INFO',
|
||||
},
|
||||
'other': {
|
||||
'handlers': ['console', 'file'],
|
||||
'level': 'INFO',
|
||||
},
|
||||
'storage': {
|
||||
'handlers': ['console', 'file'],
|
||||
'level': 'INFO',
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
log_conf.dictConfig(log_config)
|
||||
|
||||
crawler = logging.getLogger('crawler')
|
||||
storage = logging.getLogger('storage')
|
||||
other = logging.getLogger('storage')
|
||||
coloredlogs.install(level='DEBUG', logger=crawler)
|
||||
coloredlogs.install(level='DEBUG', logger=storage)
|
||||
coloredlogs.install(level='DEBUG', logger=other)
|
||||
@@ -1,50 +0,0 @@
|
||||
import json
|
||||
|
||||
import requests
|
||||
|
||||
from config import FLOWER_API_ENDPOINT
|
||||
from constants.node import NodeStatus
|
||||
from db.manager import db_manager
|
||||
|
||||
|
||||
def check_nodes_status():
|
||||
"""
|
||||
Update node status from Flower.
|
||||
"""
|
||||
res = requests.get('%s/workers?status=1' % FLOWER_API_ENDPOINT)
|
||||
return json.loads(res.content.decode('utf-8'))
|
||||
|
||||
|
||||
def update_nodes_status(refresh=False):
|
||||
"""
|
||||
Update all nodes status
|
||||
:param refresh:
|
||||
"""
|
||||
online_node_ids = []
|
||||
url = '%s/workers?status=1' % FLOWER_API_ENDPOINT
|
||||
if refresh:
|
||||
url += '&refresh=1'
|
||||
|
||||
res = requests.get(url)
|
||||
if res.status_code != 200:
|
||||
return online_node_ids
|
||||
|
||||
for k, v in json.loads(res.content.decode('utf-8')).items():
|
||||
node_name = k
|
||||
node_status = NodeStatus.ONLINE if v else NodeStatus.OFFLINE
|
||||
# node_celery = v
|
||||
node = db_manager.get('nodes', id=node_name)
|
||||
|
||||
# new node
|
||||
if node is None:
|
||||
node = {'_id': node_name, 'name': node_name, 'status': node_status, 'ip': 'localhost', 'port': '8000'}
|
||||
db_manager.save('nodes', node)
|
||||
|
||||
# existing node
|
||||
else:
|
||||
node['status'] = node_status
|
||||
db_manager.save('nodes', node)
|
||||
|
||||
if node_status:
|
||||
online_node_ids.append(node_name)
|
||||
return online_node_ids
|
||||
@@ -1,179 +0,0 @@
|
||||
import itertools
|
||||
import os
|
||||
import re
|
||||
|
||||
import requests
|
||||
from datetime import datetime, timedelta
|
||||
|
||||
from bson import ObjectId
|
||||
from lxml import etree
|
||||
|
||||
from constants.spider import FILE_SUFFIX_LANG_MAPPING, LangType, SUFFIX_IGNORE, SpiderType, QueryType, ExtractType
|
||||
from constants.task import TaskStatus
|
||||
from db.manager import db_manager
|
||||
|
||||
|
||||
def get_lang_by_stats(stats: dict) -> LangType:
|
||||
"""
|
||||
Get programming language provided suffix stats
|
||||
:param stats: stats is generated by utils.file.get_file_suffix_stats
|
||||
:return:
|
||||
"""
|
||||
try:
|
||||
data = stats.items()
|
||||
data = sorted(data, key=lambda item: item[1])
|
||||
data = list(filter(lambda item: item[0] not in SUFFIX_IGNORE, data))
|
||||
top_suffix = data[-1][0]
|
||||
if FILE_SUFFIX_LANG_MAPPING.get(top_suffix) is not None:
|
||||
return FILE_SUFFIX_LANG_MAPPING.get(top_suffix)
|
||||
return LangType.OTHER
|
||||
except IndexError as e:
|
||||
pass
|
||||
|
||||
|
||||
def get_spider_type(path: str) -> SpiderType:
|
||||
"""
|
||||
Get spider type
|
||||
:param path: spider directory path
|
||||
"""
|
||||
for file_name in os.listdir(path):
|
||||
if file_name == 'scrapy.cfg':
|
||||
return SpiderType.SCRAPY
|
||||
|
||||
|
||||
def get_spider_col_fields(col_name: str, task_id: str = None, limit: int = 100) -> list:
|
||||
"""
|
||||
Get spider collection fields
|
||||
:param col_name: collection name
|
||||
:param task_id: task_id
|
||||
:param limit: limit
|
||||
"""
|
||||
filter_ = {}
|
||||
if task_id is not None:
|
||||
filter_['task_id'] = task_id
|
||||
items = db_manager.list(col_name, filter_, limit=limit, sort_key='_id')
|
||||
fields = set()
|
||||
for item in items:
|
||||
for k in item.keys():
|
||||
fields.add(k)
|
||||
return list(fields)
|
||||
|
||||
|
||||
def get_last_n_run_errors_count(spider_id: ObjectId, n: int) -> list:
|
||||
tasks = db_manager.list(col_name='tasks',
|
||||
cond={'spider_id': spider_id},
|
||||
sort_key='create_ts',
|
||||
limit=n)
|
||||
count = 0
|
||||
for task in tasks:
|
||||
if task['status'] == TaskStatus.FAILURE:
|
||||
count += 1
|
||||
return count
|
||||
|
||||
|
||||
def get_last_n_day_tasks_count(spider_id: ObjectId, n: int) -> list:
|
||||
return db_manager.count(col_name='tasks',
|
||||
cond={
|
||||
'spider_id': spider_id,
|
||||
'create_ts': {
|
||||
'$gte': (datetime.now() - timedelta(n))
|
||||
}
|
||||
})
|
||||
|
||||
|
||||
def get_list_page_data(spider, sel):
|
||||
data = []
|
||||
if spider['item_selector_type'] == QueryType.XPATH:
|
||||
items = sel.xpath(spider['item_selector'])
|
||||
else:
|
||||
items = sel.cssselect(spider['item_selector'])
|
||||
for item in items:
|
||||
row = {}
|
||||
for f in spider['fields']:
|
||||
if f['type'] == QueryType.CSS:
|
||||
# css selector
|
||||
res = item.cssselect(f['query'])
|
||||
else:
|
||||
# xpath
|
||||
res = item.xpath(f['query'])
|
||||
|
||||
if len(res) > 0:
|
||||
if f['extract_type'] == ExtractType.TEXT:
|
||||
row[f['name']] = res[0].text
|
||||
else:
|
||||
row[f['name']] = res[0].get(f['attribute'])
|
||||
data.append(row)
|
||||
return data
|
||||
|
||||
|
||||
def get_detail_page_data(url, spider, idx, data):
|
||||
r = requests.get(url)
|
||||
|
||||
sel = etree.HTML(r.content)
|
||||
|
||||
row = {}
|
||||
for f in spider['detail_fields']:
|
||||
if f['type'] == QueryType.CSS:
|
||||
# css selector
|
||||
res = sel.cssselect(f['query'])
|
||||
else:
|
||||
# xpath
|
||||
res = sel.xpath(f['query'])
|
||||
|
||||
if len(res) > 0:
|
||||
if f['extract_type'] == ExtractType.TEXT:
|
||||
row[f['name']] = res[0].text
|
||||
else:
|
||||
row[f['name']] = res[0].get(f['attribute'])
|
||||
|
||||
# assign values
|
||||
for k, v in row.items():
|
||||
data[idx][k] = v
|
||||
|
||||
|
||||
def generate_urls(base_url: str) -> str:
|
||||
url = base_url
|
||||
|
||||
# number range list
|
||||
list_arr = []
|
||||
for i, res in enumerate(re.findall(r'{(\d+),(\d+)}', base_url)):
|
||||
try:
|
||||
_min = int(res[0])
|
||||
_max = int(res[1])
|
||||
except ValueError as err:
|
||||
raise ValueError(f'{base_url} is not a valid URL pattern')
|
||||
|
||||
# list
|
||||
_list = range(_min, _max + 1)
|
||||
|
||||
# key
|
||||
_key = f'n{i}'
|
||||
|
||||
# append list and key
|
||||
list_arr.append((_list, _key))
|
||||
|
||||
# replace url placeholder with key
|
||||
url = url.replace('{' + res[0] + ',' + res[1] + '}', '{' + _key + '}', 1)
|
||||
|
||||
# string list
|
||||
for i, res in enumerate(re.findall(r'\[([\w\-,]+)\]', base_url)):
|
||||
# list
|
||||
_list = res.split(',')
|
||||
|
||||
# key
|
||||
_key = f's{i}'
|
||||
|
||||
# append list and key
|
||||
list_arr.append((_list, _key))
|
||||
|
||||
# replace url placeholder with key
|
||||
url = url.replace('[' + ','.join(_list) + ']', '{' + _key + '}', 1)
|
||||
|
||||
# combine together
|
||||
_list_arr = []
|
||||
for res in itertools.product(*map(lambda x: x[0], list_arr)):
|
||||
_url = url
|
||||
for _arr, _rep in zip(list_arr, res):
|
||||
_list, _key = _arr
|
||||
_url = _url.replace('{' + _key + '}', str(_rep), 1)
|
||||
yield _url
|
||||
@@ -1,19 +0,0 @@
|
||||
import sys
|
||||
import os
|
||||
|
||||
# make sure the working directory is in system path
|
||||
file_dir = os.path.dirname(os.path.realpath(__file__))
|
||||
root_path = os.path.abspath(os.path.join(file_dir, '..'))
|
||||
sys.path.append(root_path)
|
||||
|
||||
from tasks.celery import celery_app
|
||||
|
||||
# import necessary tasks
|
||||
import tasks.spider
|
||||
import tasks.deploy
|
||||
|
||||
if __name__ == '__main__':
|
||||
if 'win32' in sys.platform:
|
||||
celery_app.start(argv=['tasks', 'worker', '-P', 'eventlet', '-E', '-l', 'INFO'])
|
||||
else:
|
||||
celery_app.start(argv=['tasks', 'worker', '-E', '-l', 'INFO'])
|
||||
@@ -2,20 +2,28 @@ version: '3.3'
|
||||
services:
|
||||
master:
|
||||
image: tikazyq/crawlab:latest
|
||||
container_name: crawlab
|
||||
volumes:
|
||||
- /home/yeqing/config.py:/opt/crawlab/crawlab/config/config.py # 后端配置文件
|
||||
- /home/yeqing/.env.production:/opt/crawlab/frontend/.env.production # 前端配置文件
|
||||
container_name: crawlab-master
|
||||
environment:
|
||||
CRAWLAB_API_ADDRESS: "192.168.99.100:8000"
|
||||
CRAWLAB_SERVER_MASTER: "Y"
|
||||
CRAWLAB_MONGO_HOST: "mongo"
|
||||
CRAWLAB_REDIS_ADDRESS: "redis:6379"
|
||||
ports:
|
||||
- "8080:8080" # nginx
|
||||
- "8000:8000" # app
|
||||
- "8080:8080" # frontend
|
||||
- "8000:8000" # backend
|
||||
depends_on:
|
||||
- mongo
|
||||
- redis
|
||||
worker:
|
||||
image: tikazyq/crawlab:latest
|
||||
container_name: crawlab-worker
|
||||
environment:
|
||||
CRAWLAB_SERVER_MASTER: "N"
|
||||
CRAWLAB_MONGO_HOST: "mongo"
|
||||
CRAWLAB_REDIS_ADDRESS: "redis:6379"
|
||||
depends_on:
|
||||
- mongo
|
||||
- redis
|
||||
entrypoint:
|
||||
- /bin/sh
|
||||
- /opt/crawlab/docker_init.sh
|
||||
- master
|
||||
mongo:
|
||||
image: mongo:latest
|
||||
restart: always
|
||||
@@ -25,4 +33,4 @@ services:
|
||||
image: redis:latest
|
||||
restart: always
|
||||
ports:
|
||||
- "6379:6379"
|
||||
- "6379:6379"
|
||||
@@ -1,4 +1,4 @@
|
||||
docker run -d --rm --name crawlab \
|
||||
docker run -d --restart always --name crawlab \
|
||||
-e CRAWLAB_REDIS_ADDRESS=192.168.99.1:6379 \
|
||||
-e CRAWLAB_MONGO_HOST=192.168.99.1 \
|
||||
-e CRAWLAB_SERVER_MASTER=Y \
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
docker run --rm --name crawlab \
|
||||
docker run --restart always --name crawlab \
|
||||
-e CRAWLAB_REDIS_ADDRESS=192.168.99.1:6379 \
|
||||
-e CRAWLAB_MONGO_HOST=192.168.99.1 \
|
||||
-e CRAWLAB_SERVER_MASTER=N \
|
||||
|
||||
@@ -23,17 +23,28 @@ export default {
|
||||
|
||||
<style scoped>
|
||||
.log-item {
|
||||
display: flex;
|
||||
display: table;
|
||||
}
|
||||
|
||||
.log-item:first-child .line-no {
|
||||
padding-top: 10px;
|
||||
}
|
||||
|
||||
.log-item .line-no {
|
||||
margin-right: 10px;
|
||||
display: table-cell;
|
||||
color: #A9B7C6;
|
||||
background: #313335;
|
||||
padding-right: 10px;
|
||||
text-align: right;
|
||||
flex-basis: 40px;
|
||||
width: 70px;
|
||||
}
|
||||
|
||||
.log-item .line-content {
|
||||
display: inline-block;
|
||||
padding-left: 10px;
|
||||
display: table-cell;
|
||||
/*display: inline-block;*/
|
||||
word-break: break-word;
|
||||
flex-basis: calc(100% - 50px);
|
||||
}
|
||||
</style>
|
||||
|
||||
@@ -1,6 +1,7 @@
|
||||
<template>
|
||||
<virtual-list
|
||||
:size="18"
|
||||
class="log-view"
|
||||
:size="6"
|
||||
:remain="100"
|
||||
:item="item"
|
||||
:itemcount="logData.length"
|
||||
@@ -60,19 +61,12 @@ export default {
|
||||
|
||||
<style scoped>
|
||||
.log-view {
|
||||
margin-top: 0!important;
|
||||
min-height: 100%;
|
||||
overflow-y: scroll;
|
||||
list-style: none;
|
||||
}
|
||||
|
||||
.log-view .log-line {
|
||||
display: flex;
|
||||
}
|
||||
|
||||
.log-view .log-line:nth-child(odd) {
|
||||
}
|
||||
|
||||
.log-view .log-line:nth-child(even) {
|
||||
color: #A9B7C6;
|
||||
background: #2B2B2B;
|
||||
}
|
||||
|
||||
</style>
|
||||
|
||||
@@ -175,6 +175,7 @@ export default {
|
||||
'Create Time': '创建时间',
|
||||
'Start Time': '开始时间',
|
||||
'Finish Time': '结束时间',
|
||||
'Update Time': '更新时间',
|
||||
|
||||
// 部署
|
||||
'Time': '时间',
|
||||
|
||||
@@ -160,6 +160,7 @@ export const constantRouterMap = [
|
||||
name: 'Site',
|
||||
path: '/sites',
|
||||
component: Layout,
|
||||
hidden: true,
|
||||
meta: {
|
||||
title: 'Site',
|
||||
icon: 'fa fa-sitemap'
|
||||
|
||||
@@ -25,6 +25,9 @@ const user = {
|
||||
const userInfoStr = window.localStorage.getItem('user_info')
|
||||
if (!userInfoStr) return {}
|
||||
return JSON.parse(userInfoStr)
|
||||
},
|
||||
token () {
|
||||
return window.localStorage.getItem('token')
|
||||
}
|
||||
},
|
||||
|
||||
|
||||
@@ -84,7 +84,9 @@
|
||||
<el-form :model="spiderForm" ref="addConfigurableForm" inline-message>
|
||||
<el-form-item :label="$t('Upload Zip File')" label-width="120px" name="site">
|
||||
<el-upload
|
||||
:action="$request.baseUrl + '/spiders/manage/upload'"
|
||||
:action="$request.baseUrl + '/spiders'"
|
||||
:headers="{Authorization:token}"
|
||||
:on-change="onUploadChange"
|
||||
:on-success="onUploadSuccess"
|
||||
:file-list="fileList">
|
||||
<el-button type="primary" icon="el-icon-upload">{{$t('Upload')}}</el-button>
|
||||
@@ -229,7 +231,8 @@
|
||||
|
||||
<script>
|
||||
import {
|
||||
mapState
|
||||
mapState,
|
||||
mapGetters
|
||||
} from 'vuex'
|
||||
import dayjs from 'dayjs'
|
||||
import CrawlConfirmDialog from '../../components/Common/CrawlConfirmDialog'
|
||||
@@ -258,11 +261,13 @@ export default {
|
||||
// tableData,
|
||||
columns: [
|
||||
{ name: 'name', label: 'Name', width: '180', align: 'left' },
|
||||
{ name: 'site_name', label: 'Site', width: '140', align: 'left' },
|
||||
// { name: 'site_name', label: 'Site', width: '140', align: 'left' },
|
||||
{ name: 'type', label: 'Spider Type', width: '120' },
|
||||
// { name: 'cmd', label: 'Command Line', width: '200' },
|
||||
// { name: 'lang', label: 'Language', width: '120', sortable: true },
|
||||
{ name: 'last_run_ts', label: 'Last Run', width: '160' }
|
||||
{ name: 'last_run_ts', label: 'Last Run', width: '160' },
|
||||
{ name: 'create_ts', label: 'Create Time', width: '160' },
|
||||
{ name: 'update_ts', label: 'Update Time', width: '160' }
|
||||
// { name: 'last_7d_tasks', label: 'Last 7-Day Tasks', width: '80' },
|
||||
// { name: 'last_5_errors', label: 'Last 5-Run Errors', width: '80' }
|
||||
],
|
||||
@@ -278,6 +283,9 @@ export default {
|
||||
'spiderList',
|
||||
'spiderForm'
|
||||
]),
|
||||
...mapGetters('user', [
|
||||
'token'
|
||||
]),
|
||||
filteredTableData () {
|
||||
return this.spiderList
|
||||
.filter(d => {
|
||||
@@ -469,6 +477,8 @@ export default {
|
||||
}
|
||||
})
|
||||
},
|
||||
onUploadChange () {
|
||||
},
|
||||
onUploadSuccess () {
|
||||
// clear fileList
|
||||
this.fileList = []
|
||||
|
||||
Reference in New Issue
Block a user