mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-22 17:31:03 +01:00
3
.gitignore
vendored
3
.gitignore
vendored
@@ -121,4 +121,5 @@ _book/
|
||||
.idea
|
||||
*.lock
|
||||
|
||||
backend/spiders
|
||||
backend/spiders
|
||||
spiders/*.zip
|
||||
|
||||
@@ -1,3 +1,20 @@
|
||||
# 0.4.4 (2020-01-17)
|
||||
|
||||
### 功能 / 优化
|
||||
- **邮件通知**. 允许用户发送邮件消息通知.
|
||||
- **钉钉机器人通知**. 允许用户发送钉钉机器人消息通知.
|
||||
- **企业微信机器人通知**. 允许用户发送企业微信机器人消息通知.
|
||||
- **API 地址优化**. 在前端加入相对路径,因此用户不需要特别注明 `CRAWLAB_API_ADDRESS`.
|
||||
- **SDK 兼容**. 允许用户通过 Crawlab SDK 与 Scrapy 或通用爬虫集成.
|
||||
- **优化文件管理**. 加入树状文件侧边栏,让用户更方便的编辑文件.
|
||||
- **高级定时任务 Cron**. 允许用户通过 Cron 可视化编辑器编辑定时任务.
|
||||
|
||||
### Bug 修复
|
||||
- **`nil retuened` 错误**.
|
||||
- **使用 HTTPS 出现的报错**.
|
||||
- **无法在爬虫列表页运行可配置爬虫**.
|
||||
- **上传爬虫文件缺少表单验证**.
|
||||
|
||||
# 0.4.3 (2020-01-07)
|
||||
|
||||
### 功能 / 优化
|
||||
|
||||
16
CHANGELOG.md
16
CHANGELOG.md
@@ -1,3 +1,19 @@
|
||||
# 0.4.4 (2020-01-17)
|
||||
### Features / Enhancement
|
||||
- **Email Notification**. Allow users to send email notifications.
|
||||
- **DingTalk Robot Notification**. Allow users to send DingTalk Robot notifications.
|
||||
- **Wechat Robot Notification**. Allow users to send Wechat Robot notifications.
|
||||
- **API Address Optimization**. Added relative URL path in frontend so that users don't have to specify `CRAWLAB_API_ADDRESS` explicitly.
|
||||
- **SDK Compatiblity**. Allow users to integrate Scrapy or general spiders with Crawlab SDK.
|
||||
- **Enhanced File Management**. Added tree-like file sidebar to allow users to edit files much more easier.
|
||||
- **Advanced Schedule Cron**. Allow users to edit schedule cron with visualized cron editor.
|
||||
|
||||
### Bug Fixes
|
||||
- **`nil retuened` error**.
|
||||
- **Error when using HTTPS**.
|
||||
- **Unable to run Configurable Spiders on Spider List**.
|
||||
- **Missing form validation before uploading spider files**.
|
||||
|
||||
# 0.4.3 (2020-01-07)
|
||||
|
||||
### Features / Enhancement
|
||||
|
||||
74
README-zh.md
74
README-zh.md
@@ -1,10 +1,10 @@
|
||||
# Crawlab
|
||||
|
||||
<p>
|
||||
<a href="https://hub.docker.com/r/tikazyq/crawlab" target="_blank">
|
||||
<a href="https://hub.docker.com/r/tikazyq/crawlab/builds" target="_blank">
|
||||
<img src="https://img.shields.io/docker/cloud/build/tikazyq/crawlab.svg?label=build&logo=docker">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/tikazyq/crawlab/builds" target="_blank">
|
||||
<a href="https://hub.docker.com/r/tikazyq/crawlab" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/tikazyq/crawlab?label=pulls&logo=docker">
|
||||
</a>
|
||||
<a href="https://github.com/crawlab-team/crawlab/releases" target="_blank">
|
||||
@@ -138,9 +138,9 @@ Docker部署的详情,请见[相关文档](https://tikazyq.github.io/crawlab-d
|
||||
|
||||
|
||||
|
||||
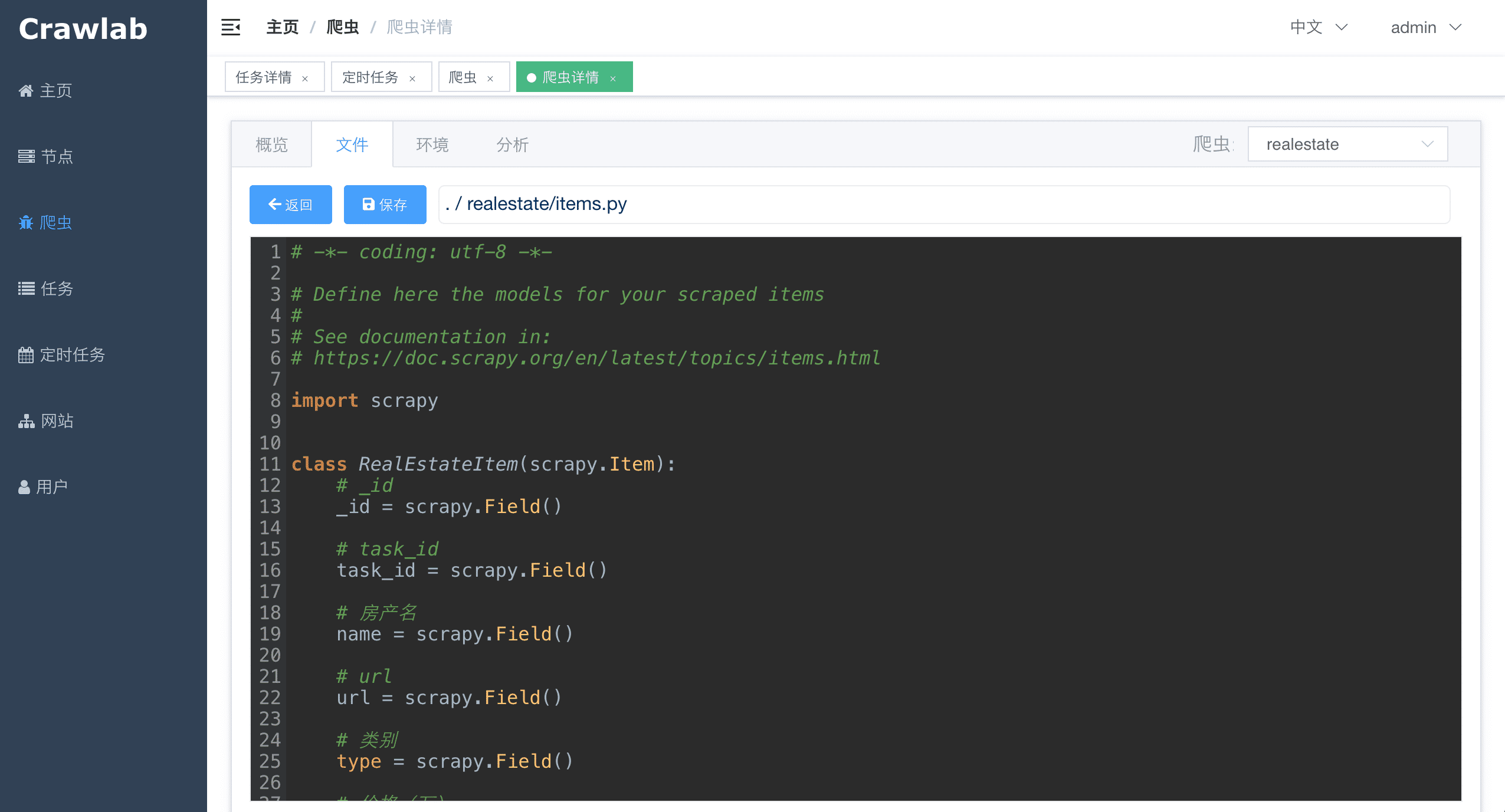
#### 爬虫文件
|
||||
#### 爬虫文件编辑
|
||||
|
||||
|
||||

|
||||
|
||||
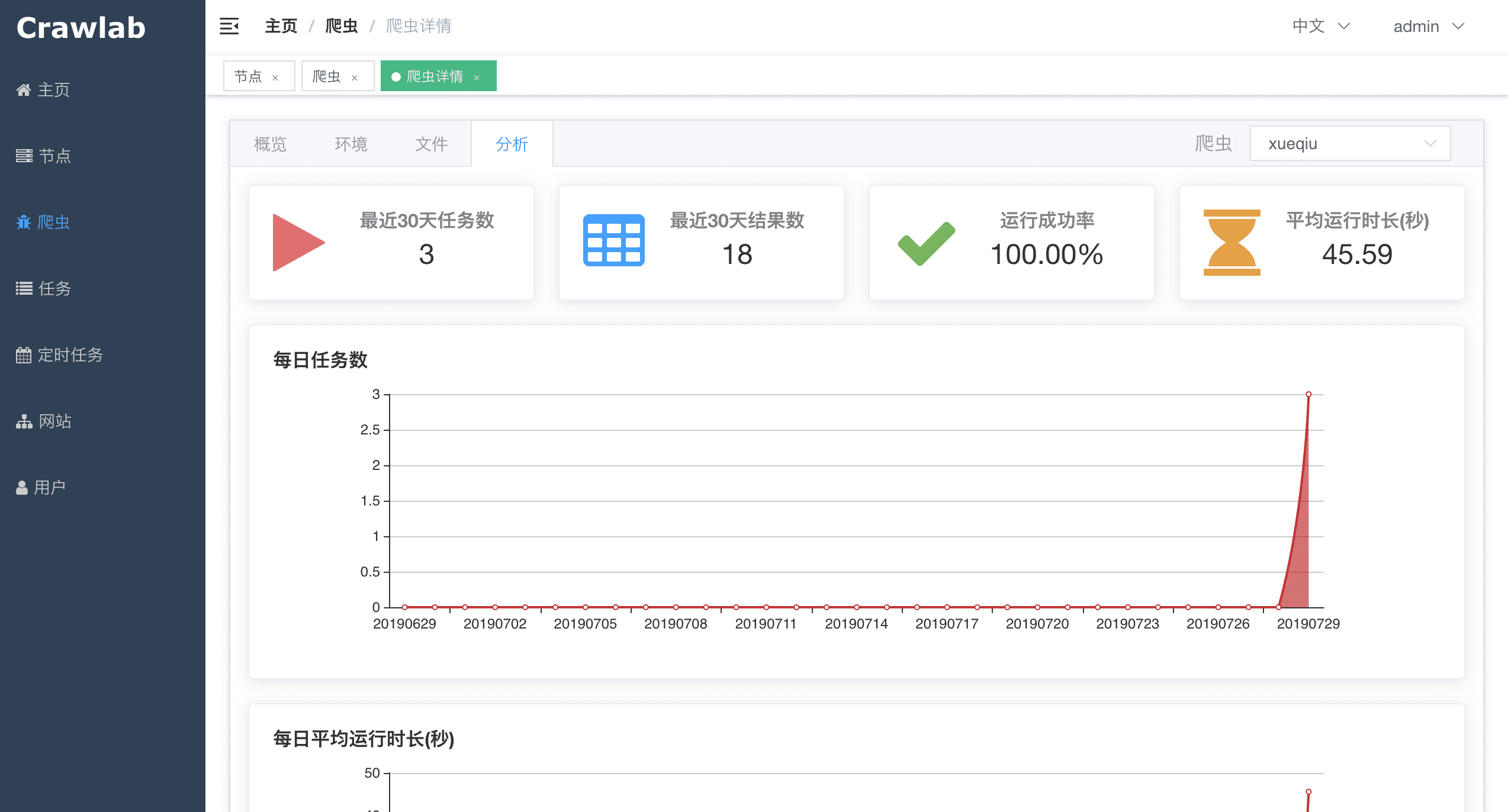
#### 任务详情 - 抓取结果
|
||||
|
||||
@@ -148,12 +148,16 @@ Docker部署的详情,请见[相关文档](https://tikazyq.github.io/crawlab-d
|
||||
|
||||
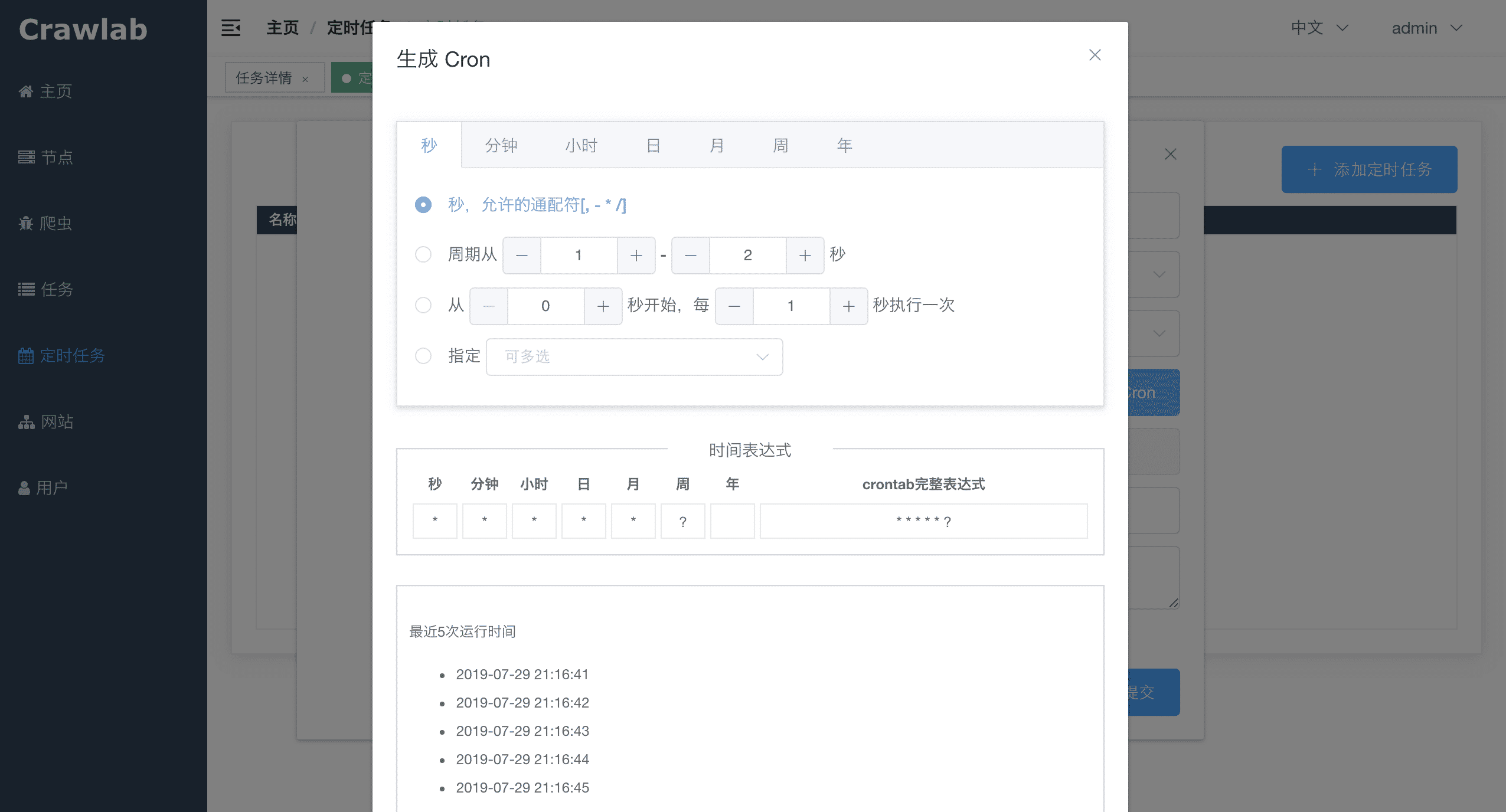
#### 定时任务
|
||||
|
||||
|
||||

|
||||
|
||||
#### 依赖安装
|
||||
|
||||

|
||||
|
||||
#### 消息通知
|
||||
|
||||
<img src="http://static-docs.crawlab.cn/notification-mobile.jpeg" height="480px">
|
||||
|
||||
## 架构
|
||||
|
||||
Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及负责通信和数据储存的Redis和MongoDB数据库。
|
||||
@@ -193,37 +197,43 @@ Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点
|
||||
|
||||
## 与其他框架的集成
|
||||
|
||||
[Crawlab SDK](https://github.com/crawlab-team/crawlab-sdk) 提供了一些 `helper` 方法来让您的爬虫更好的集成到 Crawlab 中,例如保存结果数据到 Crawlab 中等等。
|
||||
|
||||
### 集成 Scrapy
|
||||
|
||||
在 `settings.py` 中找到 `ITEM_PIPELINES`(`dict` 类型的变量),在其中添加如下内容。
|
||||
|
||||
```python
|
||||
ITEM_PIPELINES = {
|
||||
'crawlab.pipelines.CrawlabMongoPipeline': 888,
|
||||
}
|
||||
```
|
||||
|
||||
然后,启动 Scrapy 爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情-结果** 里。
|
||||
|
||||
### 通用 Python 爬虫
|
||||
|
||||
将下列代码加入到您爬虫中的结果保存部分。
|
||||
|
||||
```python
|
||||
# 引入保存结果方法
|
||||
from crawlab import save_item
|
||||
|
||||
# 这是一个结果,需要为 dict 类型
|
||||
result = {'name': 'crawlab'}
|
||||
|
||||
# 调用保存结果方法
|
||||
save_item(result)
|
||||
```
|
||||
|
||||
然后,启动爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情-结果** 里。
|
||||
|
||||
### 其他框架和语言
|
||||
|
||||
爬虫任务本质上是由一个shell命令来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。另外,`CRAWLAB_COLLECTION`是Crawlab传过来的所存放collection的名称。
|
||||
|
||||
在爬虫程序中,需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中`CRAWLAB_COLLECTION`的collection中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
|
||||
|
||||
### 集成Scrapy
|
||||
|
||||
以下是Crawlab跟Scrapy集成的例子,利用了Crawlab传过来的task_id和collection_name。
|
||||
|
||||
```python
|
||||
import os
|
||||
from pymongo import MongoClient
|
||||
|
||||
MONGO_HOST = '192.168.99.100'
|
||||
MONGO_PORT = 27017
|
||||
MONGO_DB = 'crawlab_test'
|
||||
|
||||
# scrapy example in the pipeline
|
||||
class JuejinPipeline(object):
|
||||
mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT)
|
||||
db = mongo[MONGO_DB]
|
||||
col_name = os.environ.get('CRAWLAB_COLLECTION')
|
||||
if not col_name:
|
||||
col_name = 'test'
|
||||
col = db[col_name]
|
||||
|
||||
def process_item(self, item, spider):
|
||||
item['task_id'] = os.environ.get('CRAWLAB_TASK_ID')
|
||||
self.col.save(item)
|
||||
return item
|
||||
```
|
||||
|
||||
## 与其他框架比较
|
||||
|
||||
现在已经有一些爬虫管理框架了,因此为啥还要用Crawlab?
|
||||
|
||||
66
README.md
66
README.md
@@ -1,10 +1,10 @@
|
||||
# Crawlab
|
||||
|
||||
<p>
|
||||
<a href="https://hub.docker.com/r/tikazyq/crawlab" target="_blank">
|
||||
<a href="https://hub.docker.com/r/tikazyq/crawlab/builds" target="_blank">
|
||||
<img src="https://img.shields.io/docker/cloud/build/tikazyq/crawlab.svg?label=build&logo=docker">
|
||||
</a>
|
||||
<a href="https://hub.docker.com/r/tikazyq/crawlab/builds" target="_blank">
|
||||
<a href="https://hub.docker.com/r/tikazyq/crawlab" target="_blank">
|
||||
<img src="https://img.shields.io/docker/pulls/tikazyq/crawlab?label=pulls&logo=docker">
|
||||
</a>
|
||||
<a href="https://github.com/crawlab-team/crawlab/releases" target="_blank">
|
||||
@@ -136,9 +136,9 @@ For Docker Deployment details, please refer to [relevant documentation](https://
|
||||
|
||||

|
||||
|
||||
#### Spider Files
|
||||
#### Spider File Edit
|
||||
|
||||

|
||||

|
||||
|
||||
#### Task Results
|
||||
|
||||
@@ -146,12 +146,16 @@ For Docker Deployment details, please refer to [relevant documentation](https://
|
||||
|
||||
#### Cron Job
|
||||
|
||||

|
||||

|
||||
|
||||
#### Dependency Installation
|
||||
|
||||

|
||||
|
||||
#### Notifications
|
||||
|
||||
<img src="http://static-docs.crawlab.cn/notification-mobile.jpeg" height="480px">
|
||||
|
||||
## Architecture
|
||||
|
||||
The architecture of Crawlab is consisted of the Master Node and multiple Worker Nodes, and Redis and MongoDB databases which are mainly for nodes communication and data storage.
|
||||
@@ -192,35 +196,43 @@ Frontend is a SPA based on
|
||||
|
||||
## Integration with Other Frameworks
|
||||
|
||||
A crawling task is actually executed through a shell command. The Task ID will be passed to the crawling task process in the form of environment variable named `CRAWLAB_TASK_ID`. By doing so, the data can be related to a task. Also, another environment variable `CRAWLAB_COLLECTION` is passed by Crawlab as the name of the collection to store results data.
|
||||
[Crawlab SDK](https://github.com/crawlab-team/crawlab-sdk) provides some `helper` methods to make it easier for you to integrate your spiders into Crawlab, e.g. saving results.
|
||||
|
||||
⚠️Note: make sure you have already installed `crawlab-sdk` using pip.
|
||||
|
||||
### Scrapy
|
||||
|
||||
Below is an example to integrate Crawlab with Scrapy in pipelines.
|
||||
In `settings.py` in your Scrapy project, find the variable named `ITEM_PIPELINES` (a `dict` variable). Add content below.
|
||||
|
||||
```python
|
||||
import os
|
||||
from pymongo import MongoClient
|
||||
|
||||
MONGO_HOST = '192.168.99.100'
|
||||
MONGO_PORT = 27017
|
||||
MONGO_DB = 'crawlab_test'
|
||||
|
||||
# scrapy example in the pipeline
|
||||
class JuejinPipeline(object):
|
||||
mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT)
|
||||
db = mongo[MONGO_DB]
|
||||
col_name = os.environ.get('CRAWLAB_COLLECTION')
|
||||
if not col_name:
|
||||
col_name = 'test'
|
||||
col = db[col_name]
|
||||
|
||||
def process_item(self, item, spider):
|
||||
item['task_id'] = os.environ.get('CRAWLAB_TASK_ID')
|
||||
self.col.save(item)
|
||||
return item
|
||||
ITEM_PIPELINES = {
|
||||
'crawlab.pipelines.CrawlabMongoPipeline': 888,
|
||||
}
|
||||
```
|
||||
|
||||
Then, start the Scrapy spider. After it's done, you should be able to see scraped results in **Task Detail -> Result**
|
||||
|
||||
### General Python Spider
|
||||
|
||||
Please add below content to your spider files to save results.
|
||||
|
||||
```python
|
||||
# import result saving method
|
||||
from crawlab import save_item
|
||||
|
||||
# this is a result record, must be dict type
|
||||
result = {'name': 'crawlab'}
|
||||
|
||||
# call result saving method
|
||||
save_item(result)
|
||||
```
|
||||
|
||||
Then, start the spider. After it's done, you should be able to see scraped results in **Task Detail -> Result**
|
||||
|
||||
### Other Frameworks / Languages
|
||||
|
||||
A crawling task is actually executed through a shell command. The Task ID will be passed to the crawling task process in the form of environment variable named `CRAWLAB_TASK_ID`. By doing so, the data can be related to a task. Also, another environment variable `CRAWLAB_COLLECTION` is passed by Crawlab as the name of the collection to store results data.
|
||||
|
||||
## Comparison with Other Frameworks
|
||||
|
||||
There are existing spider management frameworks. So why use Crawlab?
|
||||
|
||||
@@ -35,6 +35,15 @@ task:
|
||||
workers: 4
|
||||
other:
|
||||
tmppath: "/tmp"
|
||||
version: 0.4.3
|
||||
version: 0.4.4
|
||||
setting:
|
||||
allowRegister: "N"
|
||||
allowRegister: "N"
|
||||
notification:
|
||||
mail:
|
||||
server: ''
|
||||
port: ''
|
||||
senderEmail: ''
|
||||
senderIdentity: ''
|
||||
smtp:
|
||||
user: ''
|
||||
password: ''
|
||||
|
||||
13
backend/constants/notification.go
Normal file
13
backend/constants/notification.go
Normal file
@@ -0,0 +1,13 @@
|
||||
package constants
|
||||
|
||||
const (
|
||||
NotificationTriggerOnTaskEnd = "notification_trigger_on_task_end"
|
||||
NotificationTriggerOnTaskError = "notification_trigger_on_task_error"
|
||||
NotificationTriggerNever = "notification_trigger_never"
|
||||
)
|
||||
|
||||
const (
|
||||
NotificationTypeMail = "notification_type_mail"
|
||||
NotificationTypeDingTalk = "notification_type_ding_talk"
|
||||
NotificationTypeWechat = "notification_type_wechat"
|
||||
)
|
||||
@@ -13,10 +13,16 @@ require (
|
||||
github.com/gomodule/redigo v2.0.0+incompatible
|
||||
github.com/imroc/req v0.2.4
|
||||
github.com/leodido/go-urn v1.1.0 // indirect
|
||||
github.com/matcornic/hermes v1.2.0
|
||||
github.com/matcornic/hermes/v2 v2.0.2 // indirect
|
||||
github.com/pkg/errors v0.8.1
|
||||
github.com/royeo/dingrobot v1.0.0
|
||||
github.com/satori/go.uuid v1.2.0
|
||||
github.com/smartystreets/goconvey v0.0.0-20190731233626-505e41936337
|
||||
github.com/spf13/viper v1.4.0
|
||||
gopkg.in/alexcesaro/quotedprintable.v3 v3.0.0-20150716171945-2caba252f4dc // indirect
|
||||
gopkg.in/go-playground/validator.v9 v9.29.1
|
||||
gopkg.in/gomail.v2 v2.0.0-20150902115704-41f357289737
|
||||
gopkg.in/russross/blackfriday.v2 v2.0.0 // indirect
|
||||
gopkg.in/yaml.v2 v2.2.2
|
||||
)
|
||||
|
||||
@@ -1,9 +1,15 @@
|
||||
cloud.google.com/go v0.26.0/go.mod h1:aQUYkXzVsufM+DwF1aE+0xfcU+56JwCaLick0ClmMTw=
|
||||
github.com/BurntSushi/toml v0.3.1 h1:WXkYYl6Yr3qBf1K79EBnL4mak0OimBfB0XUf9Vl28OQ=
|
||||
github.com/BurntSushi/toml v0.3.1/go.mod h1:xHWCNGjB5oqiDr8zfno3MHue2Ht5sIBksp03qcyfWMU=
|
||||
github.com/Masterminds/semver v1.4.2 h1:WBLTQ37jOCzSLtXNdoo8bNM8876KhNqOKvrlGITgsTc=
|
||||
github.com/Masterminds/semver v1.4.2/go.mod h1:MB6lktGJrhw8PrUyiEoblNEGEQ+RzHPF078ddwwvV3Y=
|
||||
github.com/Masterminds/sprig v2.16.0+incompatible h1:QZbMUPxRQ50EKAq3LFMnxddMu88/EUUG3qmxwtDmPsY=
|
||||
github.com/Masterminds/sprig v2.16.0+incompatible/go.mod h1:y6hNFY5UBTIWBxnzTeuNhlNS5hqE0NB0E6fgfo2Br3o=
|
||||
github.com/OneOfOne/xxhash v1.2.2/go.mod h1:HSdplMjZKSmBqAxg5vPj2TmRDmfkzw+cTzAElWljhcU=
|
||||
github.com/alecthomas/template v0.0.0-20160405071501-a0175ee3bccc/go.mod h1:LOuyumcjzFXgccqObfd/Ljyb9UuFJ6TxHnclSeseNhc=
|
||||
github.com/alecthomas/units v0.0.0-20151022065526-2efee857e7cf/go.mod h1:ybxpYRFXyAe+OPACYpWeL0wqObRcbAqCMya13uyzqw0=
|
||||
github.com/aokoli/goutils v1.0.1 h1:7fpzNGoJ3VA8qcrm++XEE1QUe0mIwNeLa02Nwq7RDkg=
|
||||
github.com/aokoli/goutils v1.0.1/go.mod h1:SijmP0QR8LtwsmDs8Yii5Z/S4trXFGFC2oO5g9DP+DQ=
|
||||
github.com/apex/log v1.1.1 h1:BwhRZ0qbjYtTob0I+2M+smavV0kOC8XgcnGZcyL9liA=
|
||||
github.com/apex/log v1.1.1/go.mod h1:Ls949n1HFtXfbDcjiTTFQqkVUrte0puoIBfO3SVgwOA=
|
||||
github.com/aphistic/golf v0.0.0-20180712155816-02c07f170c5a/go.mod h1:3NqKYiepwy8kCu4PNA+aP7WUV72eXWJeP9/r3/K9aLE=
|
||||
@@ -56,6 +62,8 @@ github.com/gomodule/redigo v2.0.0+incompatible h1:K/R+8tc58AaqLkqG2Ol3Qk+DR/TlNu
|
||||
github.com/gomodule/redigo v2.0.0+incompatible/go.mod h1:B4C85qUVwatsJoIUNIfCRsp7qO0iAmpGFZ4EELWSbC4=
|
||||
github.com/google/btree v1.0.0/go.mod h1:lNA+9X1NB3Zf8V7Ke586lFgjr2dZNuvo3lPJSGZ5JPQ=
|
||||
github.com/google/go-cmp v0.2.0/go.mod h1:oXzfMopK8JAjlY9xF4vHSVASa0yLyX7SntLO5aqRK0M=
|
||||
github.com/google/uuid v1.0.0/go.mod h1:TIyPZe4MgqvfeYDBFedMoGGpEw/LqOeaOT+nhxU+yHo=
|
||||
github.com/google/uuid v1.1.1 h1:Gkbcsh/GbpXz7lPftLA3P6TYMwjCLYm83jiFQZF/3gY=
|
||||
github.com/google/uuid v1.1.1/go.mod h1:TIyPZe4MgqvfeYDBFedMoGGpEw/LqOeaOT+nhxU+yHo=
|
||||
github.com/gopherjs/gopherjs v0.0.0-20181017120253-0766667cb4d1 h1:EGx4pi6eqNxGaHF6qqu48+N2wcFQ5qg5FXgOdqsJ5d8=
|
||||
github.com/gopherjs/gopherjs v0.0.0-20181017120253-0766667cb4d1/go.mod h1:wJfORRmW1u3UXTncJ5qlYoELFm8eSnnEO6hX4iZ3EWY=
|
||||
@@ -66,8 +74,14 @@ github.com/grpc-ecosystem/grpc-gateway v1.9.0/go.mod h1:vNeuVxBJEsws4ogUvrchl83t
|
||||
github.com/hashicorp/hcl v1.0.0 h1:0Anlzjpi4vEasTeNFn2mLJgTSwt0+6sfsiTG8qcWGx4=
|
||||
github.com/hashicorp/hcl v1.0.0/go.mod h1:E5yfLk+7swimpb2L/Alb/PJmXilQ/rhwaUYs4T20WEQ=
|
||||
github.com/hpcloud/tail v1.0.0/go.mod h1:ab1qPbhIpdTxEkNHXyeSf5vhxWSCs/tWer42PpOxQnU=
|
||||
github.com/huandu/xstrings v1.2.0 h1:yPeWdRnmynF7p+lLYz0H2tthW9lqhMJrQV/U7yy4wX0=
|
||||
github.com/huandu/xstrings v1.2.0/go.mod h1:DvyZB1rfVYsBIigL8HwpZgxHwXozlTgGqn63UyNX5k4=
|
||||
github.com/imdario/mergo v0.3.6 h1:xTNEAn+kxVO7dTZGu0CegyqKZmoWFI0rF8UxjlB2d28=
|
||||
github.com/imdario/mergo v0.3.6/go.mod h1:2EnlNZ0deacrJVfApfmtdGgDfMuh/nq6Ok1EcJh5FfA=
|
||||
github.com/imroc/req v0.2.4 h1:8XbvaQpERLAJV6as/cB186DtH5f0m5zAOtHEaTQ4ac0=
|
||||
github.com/imroc/req v0.2.4/go.mod h1:J9FsaNHDTIVyW/b5r6/Df5qKEEEq2WzZKIgKSajd1AE=
|
||||
github.com/jaytaylor/html2text v0.0.0-20180606194806-57d518f124b0 h1:xqgexXAGQgY3HAjNPSaCqn5Aahbo5TKsmhp8VRfr1iQ=
|
||||
github.com/jaytaylor/html2text v0.0.0-20180606194806-57d518f124b0/go.mod h1:CVKlgaMiht+LXvHG173ujK6JUhZXKb2u/BQtjPDIvyk=
|
||||
github.com/jmespath/go-jmespath v0.0.0-20180206201540-c2b33e8439af/go.mod h1:Nht3zPeWKUH0NzdCt2Blrr5ys8VGpn0CEB0cQHVjt7k=
|
||||
github.com/jonboulle/clockwork v0.1.0/go.mod h1:Ii8DK3G1RaLaWxj9trq07+26W01tbo22gdxWY5EU2bo=
|
||||
github.com/jpillora/backoff v0.0.0-20180909062703-3050d21c67d7/go.mod h1:2iMrUgbbvHEiQClaW2NsSzMyGHqN+rDFqY705q49KG0=
|
||||
@@ -89,12 +103,17 @@ github.com/leodido/go-urn v1.1.0 h1:Sm1gr51B1kKyfD2BlRcLSiEkffoG96g6TPv6eRoEiB8=
|
||||
github.com/leodido/go-urn v1.1.0/go.mod h1:+cyI34gQWZcE1eQU7NVgKkkzdXDQHr1dBMtdAPozLkw=
|
||||
github.com/magiconair/properties v1.8.0 h1:LLgXmsheXeRoUOBOjtwPQCWIYqM/LU1ayDtDePerRcY=
|
||||
github.com/magiconair/properties v1.8.0/go.mod h1:PppfXfuXeibc/6YijjN8zIbojt8czPbwD3XqdrwzmxQ=
|
||||
github.com/matcornic/hermes v1.2.0 h1:AuqZpYcTOtTB7cahdevLfnhIpfzmpqw5Czv8vpdnFDU=
|
||||
github.com/matcornic/hermes v1.2.0/go.mod h1:lujJomb016Xjv8wBnWlNvUdtmvowjjfkqri5J/+1hYc=
|
||||
github.com/matcornic/hermes/v2 v2.0.2/go.mod h1:iVsJWSIS4NtMNtgan22sy6lt7pImok7bATGPWCoaKNY=
|
||||
github.com/mattn/go-colorable v0.1.1/go.mod h1:FuOcm+DKB9mbwrcAfNl7/TZVBZ6rcnceauSikq3lYCQ=
|
||||
github.com/mattn/go-colorable v0.1.2/go.mod h1:U0ppj6V5qS13XJ6of8GYAs25YV2eR4EVcfRqFIhoBtE=
|
||||
github.com/mattn/go-isatty v0.0.5/go.mod h1:Iq45c/XA43vh69/j3iqttzPXn0bhXyGjM0Hdxcsrc5s=
|
||||
github.com/mattn/go-isatty v0.0.7/go.mod h1:Iq45c/XA43vh69/j3iqttzPXn0bhXyGjM0Hdxcsrc5s=
|
||||
github.com/mattn/go-isatty v0.0.8 h1:HLtExJ+uU2HOZ+wI0Tt5DtUDrx8yhUqDcp7fYERX4CE=
|
||||
github.com/mattn/go-isatty v0.0.8/go.mod h1:Iq45c/XA43vh69/j3iqttzPXn0bhXyGjM0Hdxcsrc5s=
|
||||
github.com/mattn/go-runewidth v0.0.3 h1:a+kO+98RDGEfo6asOGMmpodZq4FNtnGP54yps8BzLR4=
|
||||
github.com/mattn/go-runewidth v0.0.3/go.mod h1:LwmH8dsx7+W8Uxz3IHJYH5QSwggIsqBzpuz5H//U1FU=
|
||||
github.com/matttproud/golang_protobuf_extensions v1.0.1/go.mod h1:D8He9yQNgCq6Z5Ld7szi9bcBfOoFv/3dc6xSMkL2PC0=
|
||||
github.com/mgutz/ansi v0.0.0-20170206155736-9520e82c474b/go.mod h1:01TrycV0kFyexm33Z7vhZRXopbI8J3TDReVlkTgMUxE=
|
||||
github.com/mitchellh/mapstructure v1.1.2 h1:fmNYVwqnSfB9mZU6OS2O6GsXM+wcskZDuKQzvN1EDeE=
|
||||
@@ -105,6 +124,8 @@ github.com/modern-go/reflect2 v1.0.1 h1:9f412s+6RmYXLWZSEzVVgPGK7C2PphHj5RJrvfx9
|
||||
github.com/modern-go/reflect2 v1.0.1/go.mod h1:bx2lNnkwVCuqBIxFjflWJWanXIb3RllmbCylyMrvgv0=
|
||||
github.com/mwitkow/go-conntrack v0.0.0-20161129095857-cc309e4a2223/go.mod h1:qRWi+5nqEBWmkhHvq77mSJWrCKwh8bxhgT7d/eI7P4U=
|
||||
github.com/oklog/ulid v1.3.1/go.mod h1:CirwcVhetQ6Lv90oh/F+FBtV6XMibvdAFo93nm5qn4U=
|
||||
github.com/olekukonko/tablewriter v0.0.1 h1:b3iUnf1v+ppJiOfNX4yxxqfWKMQPZR5yoh8urCTFX88=
|
||||
github.com/olekukonko/tablewriter v0.0.1/go.mod h1:vsDQFd/mU46D+Z4whnwzcISnGGzXWMclvtLoiIKAKIo=
|
||||
github.com/onsi/ginkgo v1.6.0/go.mod h1:lLunBs/Ym6LB5Z9jYTR76FiuTmxDTDusOGeTQH+WWjE=
|
||||
github.com/onsi/gomega v1.5.0/go.mod h1:ex+gbHU/CVuBBDIJjb2X0qEXbFg53c61hWP/1CpauHY=
|
||||
github.com/pelletier/go-toml v1.2.0 h1:T5zMGML61Wp+FlcbWjRDT7yAxhJNAiPPLOFECq181zc=
|
||||
@@ -125,9 +146,14 @@ github.com/prometheus/procfs v0.0.0-20190507164030-5867b95ac084/go.mod h1:TjEm7z
|
||||
github.com/prometheus/tsdb v0.7.1/go.mod h1:qhTCs0VvXwvX/y3TZrWD7rabWM+ijKTux40TwIPHuXU=
|
||||
github.com/rogpeppe/fastuuid v0.0.0-20150106093220-6724a57986af/go.mod h1:XWv6SoW27p1b0cqNHllgS5HIMJraePCO15w5zCzIWYg=
|
||||
github.com/rogpeppe/fastuuid v1.1.0/go.mod h1:jVj6XXZzXRy/MSR5jhDC/2q6DgLz+nrA6LYCDYWNEvQ=
|
||||
github.com/royeo/dingrobot v1.0.0 h1:K4GrF+fOecNX0yi+oBKpfh7z0XP/8TzaIIHu1B2kKUQ=
|
||||
github.com/royeo/dingrobot v1.0.0/go.mod h1:RqDM8E/hySCVwI2aUFRJAUGDcHHRnIhzNmbNG3bamQs=
|
||||
github.com/russross/blackfriday/v2 v2.0.1/go.mod h1:+Rmxgy9KzJVeS9/2gXHxylqXiyQDYRxCVz55jmeOWTM=
|
||||
github.com/satori/go.uuid v1.2.0 h1:0uYX9dsZ2yD7q2RtLRtPSdGDWzjeM3TbMJP9utgA0ww=
|
||||
github.com/satori/go.uuid v1.2.0/go.mod h1:dA0hQrYB0VpLJoorglMZABFdXlWrHn1NEOzdhQKdks0=
|
||||
github.com/sergi/go-diff v1.0.0/go.mod h1:0CfEIISq7TuYL3j771MWULgwwjU+GofnZX9QAmXWZgo=
|
||||
github.com/shurcooL/sanitized_anchor_name v1.0.0 h1:PdmoCO6wvbs+7yrJyMORt4/BmY5IYyJwS/kOiWx8mHo=
|
||||
github.com/shurcooL/sanitized_anchor_name v1.0.0/go.mod h1:1NzhyTcUVG4SuEtjjoZeVRXNmyL/1OwPU0+IJeTBvfc=
|
||||
github.com/sirupsen/logrus v1.2.0/go.mod h1:LxeOpSwHxABJmUn/MG1IvRgCAasNZTLOkJPxbbu5VWo=
|
||||
github.com/smartystreets/assertions v0.0.0-20180927180507-b2de0cb4f26d/go.mod h1:OnSkiWE9lh6wB0YB77sQom3nweQdgAjqCqsofrRNTgc=
|
||||
github.com/smartystreets/assertions v1.0.0 h1:UVQPSSmc3qtTi+zPPkCXvZX9VvW/xT/NsRvKfwY81a8=
|
||||
@@ -148,6 +174,8 @@ github.com/spf13/pflag v1.0.3 h1:zPAT6CGy6wXeQ7NtTnaTerfKOsV6V6F8agHXFiazDkg=
|
||||
github.com/spf13/pflag v1.0.3/go.mod h1:DYY7MBk1bdzusC3SYhjObp+wFpr4gzcvqqNjLnInEg4=
|
||||
github.com/spf13/viper v1.4.0 h1:yXHLWeravcrgGyFSyCgdYpXQ9dR9c/WED3pg1RhxqEU=
|
||||
github.com/spf13/viper v1.4.0/go.mod h1:PTJ7Z/lr49W6bUbkmS1V3by4uWynFiR9p7+dSq/yZzE=
|
||||
github.com/ssor/bom v0.0.0-20170718123548-6386211fdfcf h1:pvbZ0lM0XWPBqUKqFU8cmavspvIl9nulOYwdy6IFRRo=
|
||||
github.com/ssor/bom v0.0.0-20170718123548-6386211fdfcf/go.mod h1:RJID2RhlZKId02nZ62WenDCkgHFerpIOmW0iT7GKmXM=
|
||||
github.com/stretchr/objx v0.1.0/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
|
||||
github.com/stretchr/objx v0.1.1/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
|
||||
github.com/stretchr/testify v1.2.2/go.mod h1:a8OnRcib4nhh0OaRAV+Yts87kKdq0PP7pXfy6kDkUVs=
|
||||
@@ -167,12 +195,15 @@ go.uber.org/atomic v1.4.0/go.mod h1:gD2HeocX3+yG+ygLZcrzQJaqmWj9AIm7n08wl/qW/PE=
|
||||
go.uber.org/multierr v1.1.0/go.mod h1:wR5kodmAFQ0UK8QlbwjlSNy0Z68gJhDJUG5sjR94q/0=
|
||||
go.uber.org/zap v1.10.0/go.mod h1:vwi/ZaCAaUcBkycHslxD9B2zi4UTXhF60s6SWpuDF0Q=
|
||||
golang.org/x/crypto v0.0.0-20180904163835-0709b304e793/go.mod h1:6SG95UA2DQfeDnfUPMdvaQW0Q7yPrPDi9nlGo2tz2b4=
|
||||
golang.org/x/crypto v0.0.0-20181029175232-7e6ffbd03851/go.mod h1:6SG95UA2DQfeDnfUPMdvaQW0Q7yPrPDi9nlGo2tz2b4=
|
||||
golang.org/x/crypto v0.0.0-20190308221718-c2843e01d9a2/go.mod h1:djNgcEr1/C05ACkg1iLfiJU5Ep61QUkGW8qpdssI0+w=
|
||||
golang.org/x/crypto v0.0.0-20190426145343-a29dc8fdc734 h1:p/H982KKEjUnLJkM3tt/LemDnOc1GiZL5FCVlORJ5zo=
|
||||
golang.org/x/crypto v0.0.0-20190426145343-a29dc8fdc734/go.mod h1:yigFU9vqHzYiE8UmvKecakEJjdnWj3jj499lnFckfCI=
|
||||
golang.org/x/lint v0.0.0-20181026193005-c67002cb31c3/go.mod h1:UVdnD1Gm6xHRNCYTkRU2/jEulfH38KcIWyp/GAMgvoE=
|
||||
golang.org/x/lint v0.0.0-20190313153728-d0100b6bd8b3/go.mod h1:6SW0HCj/g11FgYtHlgUYUwCkIfeOF89ocIRzGO/8vkc=
|
||||
golang.org/x/net v0.0.0-20180826012351-8a410e7b638d/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
|
||||
golang.org/x/net v0.0.0-20180906233101-161cd47e91fd/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
|
||||
golang.org/x/net v0.0.0-20181029044818-c44066c5c816/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
|
||||
golang.org/x/net v0.0.0-20181114220301-adae6a3d119a/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
|
||||
golang.org/x/net v0.0.0-20181220203305-927f97764cc3/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
|
||||
golang.org/x/net v0.0.0-20190311183353-d8887717615a/go.mod h1:t9HGtf8HONx5eT2rtn7q6eTqICYqUVnKs3thJo3Qplg=
|
||||
@@ -206,6 +237,8 @@ google.golang.org/genproto v0.0.0-20180817151627-c66870c02cf8/go.mod h1:JiN7NxoA
|
||||
google.golang.org/grpc v1.19.0/go.mod h1:mqu4LbDTu4XGKhr4mRzUsmM4RtVoemTSY81AxZiDr8c=
|
||||
google.golang.org/grpc v1.21.0/go.mod h1:oYelfM1adQP15Ek0mdvEgi9Df8B9CZIaU1084ijfRaM=
|
||||
gopkg.in/alecthomas/kingpin.v2 v2.2.6/go.mod h1:FMv+mEhP44yOT+4EoQTLFTRgOQ1FBLkstjWtayDeSgw=
|
||||
gopkg.in/alexcesaro/quotedprintable.v3 v3.0.0-20150716171945-2caba252f4dc h1:2gGKlE2+asNV9m7xrywl36YYNnBG5ZQ0r/BOOxqPpmk=
|
||||
gopkg.in/alexcesaro/quotedprintable.v3 v3.0.0-20150716171945-2caba252f4dc/go.mod h1:m7x9LTH6d71AHyAX77c9yqWCCa3UKHcVEj9y7hAtKDk=
|
||||
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127 h1:qIbj1fsPNlZgppZ+VLlY7N33q108Sa+fhmuc+sWQYwY=
|
||||
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
|
||||
@@ -216,7 +249,11 @@ gopkg.in/go-playground/validator.v8 v8.18.2 h1:lFB4DoMU6B626w8ny76MV7VX6W2VHct2G
|
||||
gopkg.in/go-playground/validator.v8 v8.18.2/go.mod h1:RX2a/7Ha8BgOhfk7j780h4/u/RRjR0eouCJSH80/M2Y=
|
||||
gopkg.in/go-playground/validator.v9 v9.29.1 h1:SvGtYmN60a5CVKTOzMSyfzWDeZRxRuGvRQyEAKbw1xc=
|
||||
gopkg.in/go-playground/validator.v9 v9.29.1/go.mod h1:+c9/zcJMFNgbLvly1L1V+PpxWdVbfP1avr/N00E2vyQ=
|
||||
gopkg.in/gomail.v2 v2.0.0-20150902115704-41f357289737 h1:NvePS/smRcFQ4bMtTddFtknbGCtoBkJxGmpSpVRafCc=
|
||||
gopkg.in/gomail.v2 v2.0.0-20150902115704-41f357289737/go.mod h1:LRQQ+SO6ZHR7tOkpBDuZnXENFzX8qRjMDMyPD6BRkCw=
|
||||
gopkg.in/resty.v1 v1.12.0/go.mod h1:mDo4pnntr5jdWRML875a/NmxYqAlA73dVijT2AXvQQo=
|
||||
gopkg.in/russross/blackfriday.v2 v2.0.0 h1:+FlnIV8DSQnT7NZ43hcVKcdJdzZoeCmJj4Ql8gq5keA=
|
||||
gopkg.in/russross/blackfriday.v2 v2.0.0/go.mod h1:6sSBNz/GtOm/pJTuh5UmBK2ZHfmnxGbl2NZg1UliSOI=
|
||||
gopkg.in/tomb.v1 v1.0.0-20141024135613-dd632973f1e7/go.mod h1:dt/ZhP58zS4L8KSrWDmTeBkI65Dw0HsyUHuEVlX15mw=
|
||||
gopkg.in/yaml.v2 v2.0.0-20170812160011-eb3733d160e7/go.mod h1:JAlM8MvJe8wmxCU4Bli9HhUf9+ttbYbLASfIpnQbh74=
|
||||
gopkg.in/yaml.v2 v2.2.1/go.mod h1:hI93XBmqTisBFMUTm0b8Fm+jr3Dg1NNxqwp+5A1VGuI=
|
||||
|
||||
@@ -160,6 +160,7 @@ func main() {
|
||||
authGroup.POST("/spiders/:id/upload", routes.UploadSpiderFromId) // 上传爬虫(ID)
|
||||
authGroup.DELETE("/spiders/:id", routes.DeleteSpider) // 删除爬虫
|
||||
authGroup.GET("/spiders/:id/tasks", routes.GetSpiderTasks) // 爬虫任务列表
|
||||
authGroup.GET("/spiders/:id/file/tree", routes.GetSpiderFileTree) // 爬虫文件目录树读取
|
||||
authGroup.GET("/spiders/:id/file", routes.GetSpiderFile) // 爬虫文件读取
|
||||
authGroup.POST("/spiders/:id/file", routes.PostSpiderFile) // 爬虫文件更改
|
||||
authGroup.PUT("/spiders/:id/file", routes.PutSpiderFile) // 爬虫文件创建
|
||||
@@ -204,11 +205,14 @@ func main() {
|
||||
authGroup.POST("/users/:id", routes.PostUser) // 更改用户
|
||||
authGroup.DELETE("/users/:id", routes.DeleteUser) // 删除用户
|
||||
authGroup.GET("/me", routes.GetMe) // 获取自己账户
|
||||
authGroup.POST("/me", routes.PostMe) // 修改自己账户
|
||||
// release版本
|
||||
authGroup.GET("/version", routes.GetVersion) // 获取发布的版本
|
||||
// 系统
|
||||
authGroup.GET("/system/deps/:lang", routes.GetAllDepList) // 节点所有第三方依赖列表
|
||||
authGroup.GET("/system/deps/:lang/:dep_name/json", routes.GetDepJson) // 节点第三方依赖JSON
|
||||
// 文件
|
||||
authGroup.GET("/file", routes.GetFile) // 获取文件
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
@@ -20,10 +20,13 @@ type GridFs struct {
|
||||
}
|
||||
|
||||
type File struct {
|
||||
Name string `json:"name"`
|
||||
Path string `json:"path"`
|
||||
IsDir bool `json:"is_dir"`
|
||||
Size int64 `json:"size"`
|
||||
Name string `json:"name"`
|
||||
Path string `json:"path"`
|
||||
RelativePath string `json:"relative_path"`
|
||||
IsDir bool `json:"is_dir"`
|
||||
Size int64 `json:"size"`
|
||||
Children []File `json:"children"`
|
||||
Label string `json:"label"`
|
||||
}
|
||||
|
||||
func (f *GridFs) Remove() {
|
||||
|
||||
@@ -23,6 +23,7 @@ type Schedule struct {
|
||||
NodeIds []bson.ObjectId `json:"node_ids" bson:"node_ids"`
|
||||
Status string `json:"status" bson:"status"`
|
||||
Enabled bool `json:"enabled" bson:"enabled"`
|
||||
UserId bson.ObjectId `json:"user_id" bson:"user_id"`
|
||||
|
||||
// 前端展示
|
||||
SpiderName string `json:"spider_name" bson:"spider_name"`
|
||||
@@ -49,27 +50,6 @@ func (sch *Schedule) Delete() error {
|
||||
return c.RemoveId(sch.Id)
|
||||
}
|
||||
|
||||
//func (sch *Schedule) SyncNodeIdAndSpiderId(node Node, spider Spider) {
|
||||
// sch.syncNodeId(node)
|
||||
// sch.syncSpiderId(spider)
|
||||
//}
|
||||
|
||||
//func (sch *Schedule) syncNodeId(node Node) {
|
||||
// if node.Id.Hex() == sch.NodeId.Hex() {
|
||||
// return
|
||||
// }
|
||||
// sch.NodeId = node.Id
|
||||
// _ = sch.Save()
|
||||
//}
|
||||
|
||||
//func (sch *Schedule) syncSpiderId(spider Spider) {
|
||||
// if spider.Id.Hex() == sch.SpiderId.Hex() {
|
||||
// return
|
||||
// }
|
||||
// sch.SpiderId = spider.Id
|
||||
// _ = sch.Save()
|
||||
//}
|
||||
|
||||
func GetScheduleList(filter interface{}) ([]Schedule, error) {
|
||||
s, c := database.GetCol("schedules")
|
||||
defer s.Close()
|
||||
@@ -125,13 +105,8 @@ func UpdateSchedule(id bson.ObjectId, item Schedule) error {
|
||||
if err := c.FindId(id).One(&result); err != nil {
|
||||
return err
|
||||
}
|
||||
//node, err := GetNode(item.NodeId)
|
||||
//if err != nil {
|
||||
// return err
|
||||
//}
|
||||
|
||||
item.UpdateTs = time.Now()
|
||||
//item.NodeKey = node.Key
|
||||
if err := item.Save(); err != nil {
|
||||
return err
|
||||
}
|
||||
@@ -142,15 +117,9 @@ func AddSchedule(item Schedule) error {
|
||||
s, c := database.GetCol("schedules")
|
||||
defer s.Close()
|
||||
|
||||
//node, err := GetNode(item.NodeId)
|
||||
//if err != nil {
|
||||
// return err
|
||||
//}
|
||||
|
||||
item.Id = bson.NewObjectId()
|
||||
item.CreateTs = time.Now()
|
||||
item.UpdateTs = time.Now()
|
||||
//item.NodeKey = node.Key
|
||||
|
||||
if err := c.Insert(&item); err != nil {
|
||||
debug.PrintStack()
|
||||
|
||||
@@ -25,6 +25,7 @@ type Task struct {
|
||||
RuntimeDuration float64 `json:"runtime_duration" bson:"runtime_duration"`
|
||||
TotalDuration float64 `json:"total_duration" bson:"total_duration"`
|
||||
Pid int `json:"pid" bson:"pid"`
|
||||
UserId bson.ObjectId `json:"user_id" bson:"user_id"`
|
||||
|
||||
// 前端数据
|
||||
SpiderName string `json:"spider_name"`
|
||||
|
||||
@@ -16,11 +16,20 @@ type User struct {
|
||||
Username string `json:"username" bson:"username"`
|
||||
Password string `json:"password" bson:"password"`
|
||||
Role string `json:"role" bson:"role"`
|
||||
Email string `json:"email" bson:"email"`
|
||||
Setting UserSetting `json:"setting" bson:"setting"`
|
||||
|
||||
CreateTs time.Time `json:"create_ts" bson:"create_ts"`
|
||||
UpdateTs time.Time `json:"update_ts" bson:"update_ts"`
|
||||
}
|
||||
|
||||
type UserSetting struct {
|
||||
NotificationTrigger string `json:"notification_trigger" bson:"notification_trigger"`
|
||||
DingTalkRobotWebhook string `json:"ding_talk_robot_webhook" bson:"ding_talk_robot_webhook"`
|
||||
WechatRobotWebhook string `json:"wechat_robot_webhook" bson:"wechat_robot_webhook"`
|
||||
EnabledNotifications []string `json:"enabled_notifications" bson:"enabled_notifications"`
|
||||
}
|
||||
|
||||
func (user *User) Save() error {
|
||||
s, c := database.GetCol("users")
|
||||
defer s.Close()
|
||||
|
||||
@@ -76,6 +76,9 @@ func PutSchedule(c *gin.Context) {
|
||||
return
|
||||
}
|
||||
|
||||
// 加入用户ID
|
||||
item.UserId = services.GetCurrentUser(c).Id
|
||||
|
||||
// 更新数据库
|
||||
if err := model.AddSchedule(item); err != nil {
|
||||
HandleError(http.StatusInternalServerError, c, err)
|
||||
|
||||
@@ -440,6 +440,8 @@ func GetSpiderTasks(c *gin.Context) {
|
||||
})
|
||||
}
|
||||
|
||||
// 爬虫文件管理
|
||||
|
||||
func GetSpiderDir(c *gin.Context) {
|
||||
// 爬虫ID
|
||||
id := c.Param("id")
|
||||
@@ -481,8 +483,6 @@ func GetSpiderDir(c *gin.Context) {
|
||||
})
|
||||
}
|
||||
|
||||
// 爬虫文件管理
|
||||
|
||||
type SpiderFileReqBody struct {
|
||||
Path string `json:"path"`
|
||||
Content string `json:"content"`
|
||||
@@ -517,6 +517,36 @@ func GetSpiderFile(c *gin.Context) {
|
||||
})
|
||||
}
|
||||
|
||||
func GetSpiderFileTree(c *gin.Context) {
|
||||
// 爬虫ID
|
||||
id := c.Param("id")
|
||||
|
||||
// 获取爬虫
|
||||
spider, err := model.GetSpider(bson.ObjectIdHex(id))
|
||||
if err != nil {
|
||||
HandleError(http.StatusInternalServerError, c, err)
|
||||
return
|
||||
}
|
||||
|
||||
// 获取目录下文件列表
|
||||
spiderPath := viper.GetString("spider.path")
|
||||
spiderFilePath := filepath.Join(spiderPath, spider.Name)
|
||||
|
||||
// 获取文件目录树
|
||||
fileNodeTree, err := services.GetFileNodeTree(spiderFilePath, 0)
|
||||
if err != nil {
|
||||
HandleError(http.StatusInternalServerError, c, err)
|
||||
return
|
||||
}
|
||||
|
||||
// 返回结果
|
||||
c.JSON(http.StatusOK, Response{
|
||||
Status: "ok",
|
||||
Message: "success",
|
||||
Data: fileNodeTree,
|
||||
})
|
||||
}
|
||||
|
||||
func PostSpiderFile(c *gin.Context) {
|
||||
// 爬虫ID
|
||||
id := c.Param("id")
|
||||
@@ -678,7 +708,7 @@ func RenameSpiderFile(c *gin.Context) {
|
||||
|
||||
// 原文件路径
|
||||
filePath := path.Join(spider.Src, reqBody.Path)
|
||||
newFilePath := path.Join(spider.Src, reqBody.NewPath)
|
||||
newFilePath := path.Join(path.Join(path.Dir(filePath), reqBody.NewPath))
|
||||
|
||||
// 如果新文件已存在,则报错
|
||||
if utils.Exists(newFilePath) {
|
||||
|
||||
@@ -112,6 +112,7 @@ func PutTask(c *gin.Context) {
|
||||
SpiderId: reqBody.SpiderId,
|
||||
NodeId: node.Id,
|
||||
Param: reqBody.Param,
|
||||
UserId: services.GetCurrentUser(c).Id,
|
||||
}
|
||||
|
||||
if err := services.AddTask(t); err != nil {
|
||||
@@ -124,6 +125,7 @@ func PutTask(c *gin.Context) {
|
||||
t := model.Task{
|
||||
SpiderId: reqBody.SpiderId,
|
||||
Param: reqBody.Param,
|
||||
UserId: services.GetCurrentUser(c).Id,
|
||||
}
|
||||
if err := services.AddTask(t); err != nil {
|
||||
HandleError(http.StatusInternalServerError, c, err)
|
||||
@@ -136,6 +138,7 @@ func PutTask(c *gin.Context) {
|
||||
SpiderId: reqBody.SpiderId,
|
||||
NodeId: nodeId,
|
||||
Param: reqBody.Param,
|
||||
UserId: services.GetCurrentUser(c).Id,
|
||||
}
|
||||
|
||||
if err := services.AddTask(t); err != nil {
|
||||
|
||||
@@ -22,6 +22,7 @@ type UserRequestData struct {
|
||||
Username string `json:"username"`
|
||||
Password string `json:"password"`
|
||||
Role string `json:"role"`
|
||||
Email string `json:"email"`
|
||||
}
|
||||
|
||||
func GetUser(c *gin.Context) {
|
||||
@@ -95,12 +96,7 @@ func PutUser(c *gin.Context) {
|
||||
}
|
||||
|
||||
// 添加用户
|
||||
user := model.User{
|
||||
Username: strings.ToLower(reqData.Username),
|
||||
Password: utils.EncryptPassword(reqData.Password),
|
||||
Role: reqData.Role,
|
||||
}
|
||||
if err := user.Add(); err != nil {
|
||||
if err := services.CreateNewUser(reqData.Username, reqData.Password, reqData.Role, reqData.Email); err != nil {
|
||||
HandleError(http.StatusInternalServerError, c, err)
|
||||
return
|
||||
}
|
||||
@@ -205,3 +201,41 @@ func GetMe(c *gin.Context) {
|
||||
User: user,
|
||||
}, nil)
|
||||
}
|
||||
|
||||
func PostMe(c *gin.Context) {
|
||||
ctx := context.WithGinContext(c)
|
||||
user := ctx.User()
|
||||
if user == nil {
|
||||
ctx.FailedWithError(constants.ErrorUserNotFound, http.StatusUnauthorized)
|
||||
return
|
||||
}
|
||||
var reqBody model.User
|
||||
if err := c.ShouldBindJSON(&reqBody); err != nil {
|
||||
HandleErrorF(http.StatusBadRequest, c, "invalid request")
|
||||
return
|
||||
}
|
||||
if reqBody.Email != "" {
|
||||
user.Email = reqBody.Email
|
||||
}
|
||||
if reqBody.Password != "" {
|
||||
user.Password = utils.EncryptPassword(reqBody.Password)
|
||||
}
|
||||
if reqBody.Setting.NotificationTrigger != "" {
|
||||
user.Setting.NotificationTrigger = reqBody.Setting.NotificationTrigger
|
||||
}
|
||||
if reqBody.Setting.DingTalkRobotWebhook != "" {
|
||||
user.Setting.DingTalkRobotWebhook = reqBody.Setting.DingTalkRobotWebhook
|
||||
}
|
||||
if reqBody.Setting.WechatRobotWebhook != "" {
|
||||
user.Setting.WechatRobotWebhook = reqBody.Setting.WechatRobotWebhook
|
||||
}
|
||||
user.Setting.EnabledNotifications = reqBody.Setting.EnabledNotifications
|
||||
if err := user.Save(); err != nil {
|
||||
HandleError(http.StatusInternalServerError, c, err)
|
||||
return
|
||||
}
|
||||
c.JSON(http.StatusOK, Response{
|
||||
Status: "ok",
|
||||
Message: "success",
|
||||
})
|
||||
}
|
||||
|
||||
65
backend/services/file.go
Normal file
65
backend/services/file.go
Normal file
@@ -0,0 +1,65 @@
|
||||
package services
|
||||
|
||||
import (
|
||||
"crawlab/model"
|
||||
"github.com/apex/log"
|
||||
"os"
|
||||
"path"
|
||||
"runtime/debug"
|
||||
"strings"
|
||||
)
|
||||
|
||||
func GetFileNodeTree(dstPath string, level int) (f model.File, err error) {
|
||||
return getFileNodeTree(dstPath, level, dstPath)
|
||||
}
|
||||
|
||||
func getFileNodeTree(dstPath string, level int, rootPath string) (f model.File, err error) {
|
||||
dstF, err := os.Open(dstPath)
|
||||
if err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
return f, err
|
||||
}
|
||||
defer dstF.Close()
|
||||
fileInfo, err := dstF.Stat()
|
||||
if err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
return f, nil
|
||||
}
|
||||
if !fileInfo.IsDir() { //如果dstF是文件
|
||||
return model.File{
|
||||
Label: fileInfo.Name(),
|
||||
Name: fileInfo.Name(),
|
||||
Path: strings.Replace(dstPath, rootPath, "", -1),
|
||||
IsDir: false,
|
||||
Size: fileInfo.Size(),
|
||||
Children: nil,
|
||||
}, nil
|
||||
} else { //如果dstF是文件夹
|
||||
dir, err := dstF.Readdir(0) //获取文件夹下各个文件或文件夹的fileInfo
|
||||
if err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
return f, nil
|
||||
}
|
||||
f = model.File{
|
||||
Label: path.Base(dstPath),
|
||||
Name: path.Base(dstPath),
|
||||
Path: strings.Replace(dstPath, rootPath, "", -1),
|
||||
IsDir: true,
|
||||
Size: 0,
|
||||
Children: nil,
|
||||
}
|
||||
for _, subFileInfo := range dir {
|
||||
subFileNode, err := getFileNodeTree(path.Join(dstPath, subFileInfo.Name()), level+1, rootPath)
|
||||
if err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
return f, err
|
||||
}
|
||||
f.Children = append(f.Children, subFileNode)
|
||||
}
|
||||
return f, nil
|
||||
}
|
||||
}
|
||||
138
backend/services/notification/mail.go
Normal file
138
backend/services/notification/mail.go
Normal file
@@ -0,0 +1,138 @@
|
||||
package notification
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"github.com/apex/log"
|
||||
"github.com/matcornic/hermes"
|
||||
"gopkg.in/gomail.v2"
|
||||
"net/mail"
|
||||
"os"
|
||||
"runtime/debug"
|
||||
"strconv"
|
||||
)
|
||||
|
||||
func SendMail(toEmail string, toName string, subject string, content string) error {
|
||||
// hermes instance
|
||||
h := hermes.Hermes{
|
||||
Theme: new(hermes.Default),
|
||||
Product: hermes.Product{
|
||||
Name: "Crawlab Team",
|
||||
Copyright: "© 2019 Crawlab, Made by Crawlab-Team",
|
||||
},
|
||||
}
|
||||
|
||||
// config
|
||||
port, _ := strconv.Atoi(os.Getenv("CRAWLAB_NOTIFICATION_MAIL_PORT"))
|
||||
password := os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SMTP_PASSWORD")
|
||||
SMTPUser := os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SMTP_USER")
|
||||
smtpConfig := smtpAuthentication{
|
||||
Server: os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SERVER"),
|
||||
Port: port,
|
||||
SenderEmail: os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SENDEREMAIL"),
|
||||
SenderIdentity: os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SENDERIDENTITY"),
|
||||
SMTPPassword: password,
|
||||
SMTPUser: SMTPUser,
|
||||
}
|
||||
options := sendOptions{
|
||||
To: toEmail,
|
||||
Subject: subject,
|
||||
}
|
||||
|
||||
// email instance
|
||||
email := hermes.Email{
|
||||
Body: hermes.Body{
|
||||
Name: toName,
|
||||
FreeMarkdown: hermes.Markdown(content + GetFooter()),
|
||||
},
|
||||
}
|
||||
|
||||
// generate html
|
||||
html, err := h.GenerateHTML(email)
|
||||
if err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
return err
|
||||
}
|
||||
|
||||
// generate text
|
||||
text, err := h.GeneratePlainText(email)
|
||||
if err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
return err
|
||||
}
|
||||
|
||||
// send the email
|
||||
if err := send(smtpConfig, options, html, text); err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
return err
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
type smtpAuthentication struct {
|
||||
Server string
|
||||
Port int
|
||||
SenderEmail string
|
||||
SenderIdentity string
|
||||
SMTPUser string
|
||||
SMTPPassword string
|
||||
}
|
||||
|
||||
// sendOptions are options for sending an email
|
||||
type sendOptions struct {
|
||||
To string
|
||||
Subject string
|
||||
}
|
||||
|
||||
// send sends the email
|
||||
func send(smtpConfig smtpAuthentication, options sendOptions, htmlBody string, txtBody string) error {
|
||||
|
||||
if smtpConfig.Server == "" {
|
||||
return errors.New("SMTP server config is empty")
|
||||
}
|
||||
if smtpConfig.Port == 0 {
|
||||
return errors.New("SMTP port config is empty")
|
||||
}
|
||||
|
||||
if smtpConfig.SMTPUser == "" {
|
||||
return errors.New("SMTP user is empty")
|
||||
}
|
||||
|
||||
if smtpConfig.SenderIdentity == "" {
|
||||
return errors.New("SMTP sender identity is empty")
|
||||
}
|
||||
|
||||
if smtpConfig.SenderEmail == "" {
|
||||
return errors.New("SMTP sender email is empty")
|
||||
}
|
||||
|
||||
if options.To == "" {
|
||||
return errors.New("no receiver emails configured")
|
||||
}
|
||||
|
||||
from := mail.Address{
|
||||
Name: smtpConfig.SenderIdentity,
|
||||
Address: smtpConfig.SenderEmail,
|
||||
}
|
||||
|
||||
m := gomail.NewMessage()
|
||||
m.SetHeader("From", from.String())
|
||||
m.SetHeader("To", options.To)
|
||||
m.SetHeader("Subject", options.Subject)
|
||||
|
||||
m.SetBody("text/plain", txtBody)
|
||||
m.AddAlternative("text/html", htmlBody)
|
||||
|
||||
d := gomail.NewPlainDialer(smtpConfig.Server, smtpConfig.Port, smtpConfig.SMTPUser, smtpConfig.SMTPPassword)
|
||||
|
||||
return d.DialAndSend(m)
|
||||
}
|
||||
|
||||
func GetFooter() string {
|
||||
return `
|
||||
[Github](https://github.com/crawlab-team/crawlab) | [Documentation](http://docs.crawlab.cn) | [Docker](https://hub.docker.com/r/tikazyq/crawlab)
|
||||
`
|
||||
}
|
||||
59
backend/services/notification/mobile.go
Normal file
59
backend/services/notification/mobile.go
Normal file
@@ -0,0 +1,59 @@
|
||||
package notification
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"github.com/apex/log"
|
||||
"github.com/imroc/req"
|
||||
"runtime/debug"
|
||||
)
|
||||
|
||||
func SendMobileNotification(webhook string, title string, content string) error {
|
||||
type ResBody struct {
|
||||
ErrCode int `json:"errcode"`
|
||||
ErrMsg string `json:"errmsg"`
|
||||
}
|
||||
|
||||
// 请求头
|
||||
header := req.Header{
|
||||
"Content-Type": "application/json; charset=utf-8",
|
||||
}
|
||||
|
||||
// 请求数据
|
||||
data := req.Param{
|
||||
"msgtype": "markdown",
|
||||
"markdown": req.Param{
|
||||
"title": title,
|
||||
"text": content,
|
||||
"content": content,
|
||||
},
|
||||
"at": req.Param{
|
||||
"atMobiles": []string{},
|
||||
"isAtAll": false,
|
||||
},
|
||||
}
|
||||
|
||||
// 发起请求
|
||||
res, err := req.Post(webhook, header, req.BodyJSON(&data))
|
||||
if err != nil {
|
||||
log.Errorf("dingtalk notification error: " + err.Error())
|
||||
debug.PrintStack()
|
||||
return err
|
||||
}
|
||||
|
||||
// 解析响应
|
||||
var resBody ResBody
|
||||
if err := res.ToJSON(&resBody); err != nil {
|
||||
log.Errorf("dingtalk notification error: " + err.Error())
|
||||
debug.PrintStack()
|
||||
return err
|
||||
}
|
||||
|
||||
// 判断响应是否报错
|
||||
if resBody.ErrCode != 0 {
|
||||
log.Errorf("dingtalk notification error: " + resBody.ErrMsg)
|
||||
debug.PrintStack()
|
||||
return errors.New(resBody.ErrMsg)
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
@@ -34,6 +34,7 @@ func AddScheduleTask(s model.Schedule) func() {
|
||||
SpiderId: s.SpiderId,
|
||||
NodeId: node.Id,
|
||||
Param: s.Param,
|
||||
UserId: s.UserId,
|
||||
}
|
||||
|
||||
if err := AddTask(t); err != nil {
|
||||
@@ -46,6 +47,7 @@ func AddScheduleTask(s model.Schedule) func() {
|
||||
Id: id.String(),
|
||||
SpiderId: s.SpiderId,
|
||||
Param: s.Param,
|
||||
UserId: s.UserId,
|
||||
}
|
||||
if err := AddTask(t); err != nil {
|
||||
log.Errorf(err.Error())
|
||||
@@ -60,6 +62,7 @@ func AddScheduleTask(s model.Schedule) func() {
|
||||
SpiderId: s.SpiderId,
|
||||
NodeId: nodeId,
|
||||
Param: s.Param,
|
||||
UserId: s.UserId,
|
||||
}
|
||||
|
||||
if err := AddTask(t); err != nil {
|
||||
|
||||
@@ -6,9 +6,11 @@ import (
|
||||
"crawlab/entity"
|
||||
"crawlab/lib/cron"
|
||||
"crawlab/model"
|
||||
"crawlab/services/notification"
|
||||
"crawlab/utils"
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"fmt"
|
||||
"github.com/apex/log"
|
||||
"github.com/globalsign/mgo/bson"
|
||||
uuid "github.com/satori/go.uuid"
|
||||
@@ -474,9 +476,22 @@ func ExecuteTask(id int) {
|
||||
defer cronExec.Stop()
|
||||
}
|
||||
|
||||
// 获得触发任务用户
|
||||
user, err := model.GetUser(t.UserId)
|
||||
if err != nil {
|
||||
log.Errorf(GetWorkerPrefix(id) + err.Error())
|
||||
return
|
||||
}
|
||||
|
||||
// 执行Shell命令
|
||||
if err := ExecuteShellCmd(cmd, cwd, t, spider); err != nil {
|
||||
log.Errorf(GetWorkerPrefix(id) + err.Error())
|
||||
|
||||
// 如果发生错误,则发送通知
|
||||
t, _ = model.GetTask(t.Id)
|
||||
if user.Setting.NotificationTrigger == constants.NotificationTriggerOnTaskEnd || user.Setting.NotificationTrigger == constants.NotificationTriggerOnTaskError {
|
||||
SendNotifications(user, t, spider)
|
||||
}
|
||||
return
|
||||
}
|
||||
|
||||
@@ -499,6 +514,11 @@ func ExecuteTask(id int) {
|
||||
t.RuntimeDuration = t.FinishTs.Sub(t.StartTs).Seconds() // 运行时长
|
||||
t.TotalDuration = t.FinishTs.Sub(t.CreateTs).Seconds() // 总时长
|
||||
|
||||
// 如果是任务结束时发送通知,则发送通知
|
||||
if user.Setting.NotificationTrigger == constants.NotificationTriggerOnTaskEnd {
|
||||
SendNotifications(user, t, spider)
|
||||
}
|
||||
|
||||
// 保存任务
|
||||
if err := t.Save(); err != nil {
|
||||
log.Errorf(GetWorkerPrefix(id) + err.Error())
|
||||
@@ -669,6 +689,160 @@ func HandleTaskError(t model.Task, err error) {
|
||||
debug.PrintStack()
|
||||
}
|
||||
|
||||
func GetTaskEmailMarkdownContent(t model.Task, s model.Spider) string {
|
||||
n, _ := model.GetNode(t.NodeId)
|
||||
errMsg := ""
|
||||
statusMsg := fmt.Sprintf(`<span style="color:green">%s</span>`, t.Status)
|
||||
if t.Status == constants.StatusError {
|
||||
errMsg = " with errors"
|
||||
statusMsg = fmt.Sprintf(`<span style="color:red">%s</span>`, t.Status)
|
||||
}
|
||||
return fmt.Sprintf(`
|
||||
Your task has finished%s. Please find the task info below.
|
||||
|
||||
|
|
||||
--: | :--
|
||||
**Task ID:** | %s
|
||||
**Task Status:** | %s
|
||||
**Task Param:** | %s
|
||||
**Spider ID:** | %s
|
||||
**Spider Name:** | %s
|
||||
**Node:** | %s
|
||||
**Create Time:** | %s
|
||||
**Start Time:** | %s
|
||||
**Finish Time:** | %s
|
||||
**Wait Duration:** | %.0f sec
|
||||
**Runtime Duration:** | %.0f sec
|
||||
**Total Duration:** | %.0f sec
|
||||
**Number of Results:** | %d
|
||||
**Error:** | <span style="color:red">%s</span>
|
||||
|
||||
Please login to Crawlab to view the details.
|
||||
`,
|
||||
errMsg,
|
||||
t.Id,
|
||||
statusMsg,
|
||||
t.Param,
|
||||
s.Id.Hex(),
|
||||
s.Name,
|
||||
n.Name,
|
||||
utils.GetLocalTimeString(t.CreateTs),
|
||||
utils.GetLocalTimeString(t.StartTs),
|
||||
utils.GetLocalTimeString(t.FinishTs),
|
||||
t.WaitDuration,
|
||||
t.RuntimeDuration,
|
||||
t.TotalDuration,
|
||||
t.ResultCount,
|
||||
t.Error,
|
||||
)
|
||||
}
|
||||
|
||||
func GetTaskMarkdownContent(t model.Task, s model.Spider) string {
|
||||
n, _ := model.GetNode(t.NodeId)
|
||||
errMsg := ""
|
||||
errLog := "-"
|
||||
statusMsg := fmt.Sprintf(`<font color="#00FF00">%s</font>`, t.Status)
|
||||
if t.Status == constants.StatusError {
|
||||
errMsg = `(有错误)`
|
||||
errLog = fmt.Sprintf(`<font color="#FF0000">%s</font>`, t.Error)
|
||||
statusMsg = fmt.Sprintf(`<font color="#FF0000">%s</font>`, t.Status)
|
||||
}
|
||||
return fmt.Sprintf(`
|
||||
您的任务已完成%s,请查看任务信息如下。
|
||||
|
||||
> **任务ID:** %s
|
||||
> **任务状态:** %s
|
||||
> **任务参数:** %s
|
||||
> **爬虫ID:** %s
|
||||
> **爬虫名称:** %s
|
||||
> **节点:** %s
|
||||
> **创建时间:** %s
|
||||
> **开始时间:** %s
|
||||
> **完成时间:** %s
|
||||
> **等待时间:** %.0f秒
|
||||
> **运行时间:** %.0f秒
|
||||
> **总时间:** %.0f秒
|
||||
> **结果数:** %d
|
||||
> **错误:** %s
|
||||
|
||||
请登录Crawlab查看详情。
|
||||
`,
|
||||
errMsg,
|
||||
t.Id,
|
||||
statusMsg,
|
||||
t.Param,
|
||||
s.Id.Hex(),
|
||||
s.Name,
|
||||
n.Name,
|
||||
utils.GetLocalTimeString(t.CreateTs),
|
||||
utils.GetLocalTimeString(t.StartTs),
|
||||
utils.GetLocalTimeString(t.FinishTs),
|
||||
t.WaitDuration,
|
||||
t.RuntimeDuration,
|
||||
t.TotalDuration,
|
||||
t.ResultCount,
|
||||
errLog,
|
||||
)
|
||||
}
|
||||
|
||||
func SendTaskEmail(u model.User, t model.Task, s model.Spider) {
|
||||
statusMsg := "has finished"
|
||||
if t.Status == constants.StatusError {
|
||||
statusMsg = "has an error"
|
||||
}
|
||||
title := fmt.Sprintf("[Crawlab] Task for \"%s\" %s", s.Name, statusMsg)
|
||||
if err := notification.SendMail(
|
||||
u.Email,
|
||||
u.Username,
|
||||
title,
|
||||
GetTaskEmailMarkdownContent(t, s),
|
||||
); err != nil {
|
||||
log.Errorf("mail error: " + err.Error())
|
||||
debug.PrintStack()
|
||||
}
|
||||
}
|
||||
|
||||
func SendTaskDingTalk(u model.User, t model.Task, s model.Spider) {
|
||||
statusMsg := "已完成"
|
||||
if t.Status == constants.StatusError {
|
||||
statusMsg = "发生错误"
|
||||
}
|
||||
title := fmt.Sprintf("[Crawlab] \"%s\" 任务%s", s.Name, statusMsg)
|
||||
content := GetTaskMarkdownContent(t, s)
|
||||
if err := notification.SendMobileNotification(u.Setting.DingTalkRobotWebhook, title, content); err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
}
|
||||
}
|
||||
|
||||
func SendTaskWechat(u model.User, t model.Task, s model.Spider) {
|
||||
content := GetTaskMarkdownContent(t, s)
|
||||
if err := notification.SendMobileNotification(u.Setting.WechatRobotWebhook, "", content); err != nil {
|
||||
log.Errorf(err.Error())
|
||||
debug.PrintStack()
|
||||
}
|
||||
}
|
||||
|
||||
func SendNotifications(u model.User, t model.Task, s model.Spider) {
|
||||
if u.Email != "" && utils.StringArrayContains(u.Setting.EnabledNotifications, constants.NotificationTypeMail) {
|
||||
go func() {
|
||||
SendTaskEmail(u, t, s)
|
||||
}()
|
||||
}
|
||||
|
||||
if u.Setting.DingTalkRobotWebhook != "" && utils.StringArrayContains(u.Setting.EnabledNotifications, constants.NotificationTypeDingTalk) {
|
||||
go func() {
|
||||
SendTaskDingTalk(u, t, s)
|
||||
}()
|
||||
}
|
||||
|
||||
if u.Setting.WechatRobotWebhook != "" && utils.StringArrayContains(u.Setting.EnabledNotifications, constants.NotificationTypeWechat) {
|
||||
go func() {
|
||||
SendTaskWechat(u, t, s)
|
||||
}()
|
||||
}
|
||||
}
|
||||
|
||||
func InitTaskExecutor() error {
|
||||
c := cron.New(cron.WithSeconds())
|
||||
Exec = &Executor{
|
||||
|
||||
@@ -6,20 +6,18 @@ import (
|
||||
"crawlab/utils"
|
||||
"errors"
|
||||
"github.com/dgrijalva/jwt-go"
|
||||
"github.com/gin-gonic/gin"
|
||||
"github.com/globalsign/mgo/bson"
|
||||
"github.com/spf13/viper"
|
||||
"strings"
|
||||
"time"
|
||||
)
|
||||
|
||||
func InitUserService() error {
|
||||
adminUser := model.User{
|
||||
Username: "admin",
|
||||
Password: utils.EncryptPassword("admin"),
|
||||
Role: constants.RoleAdmin,
|
||||
}
|
||||
_ = adminUser.Add()
|
||||
_ = CreateNewUser("admin", "admin", constants.RoleAdmin, "")
|
||||
return nil
|
||||
}
|
||||
|
||||
func MakeToken(user *model.User) (tokenStr string, err error) {
|
||||
token := jwt.NewWithClaims(jwt.SigningMethodHS256, jwt.MapClaims{
|
||||
"id": user.Id,
|
||||
@@ -91,3 +89,29 @@ func CheckToken(tokenStr string) (user model.User, err error) {
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
func CreateNewUser(username string, password string, role string, email string) error {
|
||||
user := model.User{
|
||||
Username: strings.ToLower(username),
|
||||
Password: utils.EncryptPassword(password),
|
||||
Role: role,
|
||||
Email: email,
|
||||
Setting: model.UserSetting{
|
||||
NotificationTrigger: constants.NotificationTriggerNever,
|
||||
EnabledNotifications: []string{
|
||||
constants.NotificationTypeMail,
|
||||
constants.NotificationTypeDingTalk,
|
||||
constants.NotificationTypeWechat,
|
||||
},
|
||||
},
|
||||
}
|
||||
if err := user.Add(); err != nil {
|
||||
return err
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
func GetCurrentUser(c *gin.Context) *model.User {
|
||||
data, _ := c.Get("currentUser")
|
||||
return data.(*model.User)
|
||||
}
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
version: "0.4.0"
|
||||
version: "0.4.4"
|
||||
name: "toscrapy_books"
|
||||
start_url: "http://news.163.com/special/0001386F/rank_news.html"
|
||||
start_stage: "list"
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
version: 0.4.0
|
||||
version: 0.4.4
|
||||
name: toscrapy_books
|
||||
start_url: http://www.baidu.com/s?wd=crawlab
|
||||
start_stage: list
|
||||
|
||||
@@ -1,4 +1,4 @@
|
||||
version: "0.4.0"
|
||||
version: "0.4.4"
|
||||
name: "toscrapy_books"
|
||||
start_url: "http://books.toscrape.com"
|
||||
start_stage: "list"
|
||||
|
||||
10
backend/utils/array.go
Normal file
10
backend/utils/array.go
Normal file
@@ -0,0 +1,10 @@
|
||||
package utils
|
||||
|
||||
func StringArrayContains(arr []string, str string) bool {
|
||||
for _, s := range arr {
|
||||
if s == str {
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
16
backend/utils/encrypt.go
Normal file
16
backend/utils/encrypt.go
Normal file
@@ -0,0 +1,16 @@
|
||||
package utils
|
||||
|
||||
import (
|
||||
"crypto/hmac"
|
||||
"crypto/sha256"
|
||||
"encoding/base64"
|
||||
"encoding/hex"
|
||||
)
|
||||
|
||||
func ComputeHmacSha256(message string, secret string) string {
|
||||
key := []byte(secret)
|
||||
h := hmac.New(sha256.New, key)
|
||||
h.Write([]byte(message))
|
||||
sha := hex.EncodeToString(h.Sum(nil))
|
||||
return base64.StdEncoding.EncodeToString([]byte(sha))
|
||||
}
|
||||
16
backend/utils/time.go
Normal file
16
backend/utils/time.go
Normal file
@@ -0,0 +1,16 @@
|
||||
package utils
|
||||
|
||||
import "time"
|
||||
|
||||
func GetLocalTime(t time.Time) time.Time {
|
||||
return t.In(time.Local)
|
||||
}
|
||||
|
||||
func GetTimeString(t time.Time) string {
|
||||
return t.Format("2006-01-02 15:04:05")
|
||||
}
|
||||
|
||||
func GetLocalTimeString(t time.Time) string {
|
||||
t = GetLocalTime(t)
|
||||
return GetTimeString(t)
|
||||
}
|
||||
27
backend/vendor/github.com/Masterminds/semver/.travis.yml
generated
vendored
Normal file
27
backend/vendor/github.com/Masterminds/semver/.travis.yml
generated
vendored
Normal file
@@ -0,0 +1,27 @@
|
||||
language: go
|
||||
|
||||
go:
|
||||
- 1.6.x
|
||||
- 1.7.x
|
||||
- 1.8.x
|
||||
- 1.9.x
|
||||
- 1.10.x
|
||||
- tip
|
||||
|
||||
# Setting sudo access to false will let Travis CI use containers rather than
|
||||
# VMs to run the tests. For more details see:
|
||||
# - http://docs.travis-ci.com/user/workers/container-based-infrastructure/
|
||||
# - http://docs.travis-ci.com/user/workers/standard-infrastructure/
|
||||
sudo: false
|
||||
|
||||
script:
|
||||
- make setup
|
||||
- make test
|
||||
|
||||
notifications:
|
||||
webhooks:
|
||||
urls:
|
||||
- https://webhooks.gitter.im/e/06e3328629952dabe3e0
|
||||
on_success: change # options: [always|never|change] default: always
|
||||
on_failure: always # options: [always|never|change] default: always
|
||||
on_start: never # options: [always|never|change] default: always
|
||||
86
backend/vendor/github.com/Masterminds/semver/CHANGELOG.md
generated
vendored
Normal file
86
backend/vendor/github.com/Masterminds/semver/CHANGELOG.md
generated
vendored
Normal file
@@ -0,0 +1,86 @@
|
||||
# 1.4.2 (2018-04-10)
|
||||
|
||||
## Changed
|
||||
- #72: Updated the docs to point to vert for a console appliaction
|
||||
- #71: Update the docs on pre-release comparator handling
|
||||
|
||||
## Fixed
|
||||
- #70: Fix the handling of pre-releases and the 0.0.0 release edge case
|
||||
|
||||
# 1.4.1 (2018-04-02)
|
||||
|
||||
## Fixed
|
||||
- Fixed #64: Fix pre-release precedence issue (thanks @uudashr)
|
||||
|
||||
# 1.4.0 (2017-10-04)
|
||||
|
||||
## Changed
|
||||
- #61: Update NewVersion to parse ints with a 64bit int size (thanks @zknill)
|
||||
|
||||
# 1.3.1 (2017-07-10)
|
||||
|
||||
## Fixed
|
||||
- Fixed #57: number comparisons in prerelease sometimes inaccurate
|
||||
|
||||
# 1.3.0 (2017-05-02)
|
||||
|
||||
## Added
|
||||
- #45: Added json (un)marshaling support (thanks @mh-cbon)
|
||||
- Stability marker. See https://masterminds.github.io/stability/
|
||||
|
||||
## Fixed
|
||||
- #51: Fix handling of single digit tilde constraint (thanks @dgodd)
|
||||
|
||||
## Changed
|
||||
- #55: The godoc icon moved from png to svg
|
||||
|
||||
# 1.2.3 (2017-04-03)
|
||||
|
||||
## Fixed
|
||||
- #46: Fixed 0.x.x and 0.0.x in constraints being treated as *
|
||||
|
||||
# Release 1.2.2 (2016-12-13)
|
||||
|
||||
## Fixed
|
||||
- #34: Fixed issue where hyphen range was not working with pre-release parsing.
|
||||
|
||||
# Release 1.2.1 (2016-11-28)
|
||||
|
||||
## Fixed
|
||||
- #24: Fixed edge case issue where constraint "> 0" does not handle "0.0.1-alpha"
|
||||
properly.
|
||||
|
||||
# Release 1.2.0 (2016-11-04)
|
||||
|
||||
## Added
|
||||
- #20: Added MustParse function for versions (thanks @adamreese)
|
||||
- #15: Added increment methods on versions (thanks @mh-cbon)
|
||||
|
||||
## Fixed
|
||||
- Issue #21: Per the SemVer spec (section 9) a pre-release is unstable and
|
||||
might not satisfy the intended compatibility. The change here ignores pre-releases
|
||||
on constraint checks (e.g., ~ or ^) when a pre-release is not part of the
|
||||
constraint. For example, `^1.2.3` will ignore pre-releases while
|
||||
`^1.2.3-alpha` will include them.
|
||||
|
||||
# Release 1.1.1 (2016-06-30)
|
||||
|
||||
## Changed
|
||||
- Issue #9: Speed up version comparison performance (thanks @sdboyer)
|
||||
- Issue #8: Added benchmarks (thanks @sdboyer)
|
||||
- Updated Go Report Card URL to new location
|
||||
- Updated Readme to add code snippet formatting (thanks @mh-cbon)
|
||||
- Updating tagging to v[SemVer] structure for compatibility with other tools.
|
||||
|
||||
# Release 1.1.0 (2016-03-11)
|
||||
|
||||
- Issue #2: Implemented validation to provide reasons a versions failed a
|
||||
constraint.
|
||||
|
||||
# Release 1.0.1 (2015-12-31)
|
||||
|
||||
- Fixed #1: * constraint failing on valid versions.
|
||||
|
||||
# Release 1.0.0 (2015-10-20)
|
||||
|
||||
- Initial release
|
||||
20
backend/vendor/github.com/Masterminds/semver/LICENSE.txt
generated
vendored
Normal file
20
backend/vendor/github.com/Masterminds/semver/LICENSE.txt
generated
vendored
Normal file
@@ -0,0 +1,20 @@
|
||||
The Masterminds
|
||||
Copyright (C) 2014-2015, Matt Butcher and Matt Farina
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
36
backend/vendor/github.com/Masterminds/semver/Makefile
generated
vendored
Normal file
36
backend/vendor/github.com/Masterminds/semver/Makefile
generated
vendored
Normal file
@@ -0,0 +1,36 @@
|
||||
.PHONY: setup
|
||||
setup:
|
||||
go get -u gopkg.in/alecthomas/gometalinter.v1
|
||||
gometalinter.v1 --install
|
||||
|
||||
.PHONY: test
|
||||
test: validate lint
|
||||
@echo "==> Running tests"
|
||||
go test -v
|
||||
|
||||
.PHONY: validate
|
||||
validate:
|
||||
@echo "==> Running static validations"
|
||||
@gometalinter.v1 \
|
||||
--disable-all \
|
||||
--enable deadcode \
|
||||
--severity deadcode:error \
|
||||
--enable gofmt \
|
||||
--enable gosimple \
|
||||
--enable ineffassign \
|
||||
--enable misspell \
|
||||
--enable vet \
|
||||
--tests \
|
||||
--vendor \
|
||||
--deadline 60s \
|
||||
./... || exit_code=1
|
||||
|
||||
.PHONY: lint
|
||||
lint:
|
||||
@echo "==> Running linters"
|
||||
@gometalinter.v1 \
|
||||
--disable-all \
|
||||
--enable golint \
|
||||
--vendor \
|
||||
--deadline 60s \
|
||||
./... || :
|
||||
165
backend/vendor/github.com/Masterminds/semver/README.md
generated
vendored
Normal file
165
backend/vendor/github.com/Masterminds/semver/README.md
generated
vendored
Normal file
@@ -0,0 +1,165 @@
|
||||
# SemVer
|
||||
|
||||
The `semver` package provides the ability to work with [Semantic Versions](http://semver.org) in Go. Specifically it provides the ability to:
|
||||
|
||||
* Parse semantic versions
|
||||
* Sort semantic versions
|
||||
* Check if a semantic version fits within a set of constraints
|
||||
* Optionally work with a `v` prefix
|
||||
|
||||
[](https://masterminds.github.io/stability/active.html)
|
||||
[](https://travis-ci.org/Masterminds/semver) [](https://ci.appveyor.com/project/mattfarina/semver/branch/master) [](https://godoc.org/github.com/Masterminds/semver) [](https://goreportcard.com/report/github.com/Masterminds/semver)
|
||||
|
||||
## Parsing Semantic Versions
|
||||
|
||||
To parse a semantic version use the `NewVersion` function. For example,
|
||||
|
||||
```go
|
||||
v, err := semver.NewVersion("1.2.3-beta.1+build345")
|
||||
```
|
||||
|
||||
If there is an error the version wasn't parseable. The version object has methods
|
||||
to get the parts of the version, compare it to other versions, convert the
|
||||
version back into a string, and get the original string. For more details
|
||||
please see the [documentation](https://godoc.org/github.com/Masterminds/semver).
|
||||
|
||||
## Sorting Semantic Versions
|
||||
|
||||
A set of versions can be sorted using the [`sort`](https://golang.org/pkg/sort/)
|
||||
package from the standard library. For example,
|
||||
|
||||
```go
|
||||
raw := []string{"1.2.3", "1.0", "1.3", "2", "0.4.2",}
|
||||
vs := make([]*semver.Version, len(raw))
|
||||
for i, r := range raw {
|
||||
v, err := semver.NewVersion(r)
|
||||
if err != nil {
|
||||
t.Errorf("Error parsing version: %s", err)
|
||||
}
|
||||
|
||||
vs[i] = v
|
||||
}
|
||||
|
||||
sort.Sort(semver.Collection(vs))
|
||||
```
|
||||
|
||||
## Checking Version Constraints
|
||||
|
||||
Checking a version against version constraints is one of the most featureful
|
||||
parts of the package.
|
||||
|
||||
```go
|
||||
c, err := semver.NewConstraint(">= 1.2.3")
|
||||
if err != nil {
|
||||
// Handle constraint not being parseable.
|
||||
}
|
||||
|
||||
v, _ := semver.NewVersion("1.3")
|
||||
if err != nil {
|
||||
// Handle version not being parseable.
|
||||
}
|
||||
// Check if the version meets the constraints. The a variable will be true.
|
||||
a := c.Check(v)
|
||||
```
|
||||
|
||||
## Basic Comparisons
|
||||
|
||||
There are two elements to the comparisons. First, a comparison string is a list
|
||||
of comma separated and comparisons. These are then separated by || separated or
|
||||
comparisons. For example, `">= 1.2, < 3.0.0 || >= 4.2.3"` is looking for a
|
||||
comparison that's greater than or equal to 1.2 and less than 3.0.0 or is
|
||||
greater than or equal to 4.2.3.
|
||||
|
||||
The basic comparisons are:
|
||||
|
||||
* `=`: equal (aliased to no operator)
|
||||
* `!=`: not equal
|
||||
* `>`: greater than
|
||||
* `<`: less than
|
||||
* `>=`: greater than or equal to
|
||||
* `<=`: less than or equal to
|
||||
|
||||
_Note, according to the Semantic Version specification pre-releases may not be
|
||||
API compliant with their release counterpart. It says,_
|
||||
|
||||
> _A pre-release version indicates that the version is unstable and might not satisfy the intended compatibility requirements as denoted by its associated normal version._
|
||||
|
||||
_SemVer comparisons without a pre-release value will skip pre-release versions.
|
||||
For example, `>1.2.3` will skip pre-releases when looking at a list of values
|
||||
while `>1.2.3-alpha.1` will evaluate pre-releases._
|
||||
|
||||
## Hyphen Range Comparisons
|
||||
|
||||
There are multiple methods to handle ranges and the first is hyphens ranges.
|
||||
These look like:
|
||||
|
||||
* `1.2 - 1.4.5` which is equivalent to `>= 1.2, <= 1.4.5`
|
||||
* `2.3.4 - 4.5` which is equivalent to `>= 2.3.4, <= 4.5`
|
||||
|
||||
## Wildcards In Comparisons
|
||||
|
||||
The `x`, `X`, and `*` characters can be used as a wildcard character. This works
|
||||
for all comparison operators. When used on the `=` operator it falls
|
||||
back to the pack level comparison (see tilde below). For example,
|
||||
|
||||
* `1.2.x` is equivalent to `>= 1.2.0, < 1.3.0`
|
||||
* `>= 1.2.x` is equivalent to `>= 1.2.0`
|
||||
* `<= 2.x` is equivalent to `<= 3`
|
||||
* `*` is equivalent to `>= 0.0.0`
|
||||
|
||||
## Tilde Range Comparisons (Patch)
|
||||
|
||||
The tilde (`~`) comparison operator is for patch level ranges when a minor
|
||||
version is specified and major level changes when the minor number is missing.
|
||||
For example,
|
||||
|
||||
* `~1.2.3` is equivalent to `>= 1.2.3, < 1.3.0`
|
||||
* `~1` is equivalent to `>= 1, < 2`
|
||||
* `~2.3` is equivalent to `>= 2.3, < 2.4`
|
||||
* `~1.2.x` is equivalent to `>= 1.2.0, < 1.3.0`
|
||||
* `~1.x` is equivalent to `>= 1, < 2`
|
||||
|
||||
## Caret Range Comparisons (Major)
|
||||
|
||||
The caret (`^`) comparison operator is for major level changes. This is useful
|
||||
when comparisons of API versions as a major change is API breaking. For example,
|
||||
|
||||
* `^1.2.3` is equivalent to `>= 1.2.3, < 2.0.0`
|
||||
* `^1.2.x` is equivalent to `>= 1.2.0, < 2.0.0`
|
||||
* `^2.3` is equivalent to `>= 2.3, < 3`
|
||||
* `^2.x` is equivalent to `>= 2.0.0, < 3`
|
||||
|
||||
# Validation
|
||||
|
||||
In addition to testing a version against a constraint, a version can be validated
|
||||
against a constraint. When validation fails a slice of errors containing why a
|
||||
version didn't meet the constraint is returned. For example,
|
||||
|
||||
```go
|
||||
c, err := semver.NewConstraint("<= 1.2.3, >= 1.4")
|
||||
if err != nil {
|
||||
// Handle constraint not being parseable.
|
||||
}
|
||||
|
||||
v, _ := semver.NewVersion("1.3")
|
||||
if err != nil {
|
||||
// Handle version not being parseable.
|
||||
}
|
||||
|
||||
// Validate a version against a constraint.
|
||||
a, msgs := c.Validate(v)
|
||||
// a is false
|
||||
for _, m := range msgs {
|
||||
fmt.Println(m)
|
||||
|
||||
// Loops over the errors which would read
|
||||
// "1.3 is greater than 1.2.3"
|
||||
// "1.3 is less than 1.4"
|
||||
}
|
||||
```
|
||||
|
||||
# Contribute
|
||||
|
||||
If you find an issue or want to contribute please file an [issue](https://github.com/Masterminds/semver/issues)
|
||||
or [create a pull request](https://github.com/Masterminds/semver/pulls).
|
||||
44
backend/vendor/github.com/Masterminds/semver/appveyor.yml
generated
vendored
Normal file
44
backend/vendor/github.com/Masterminds/semver/appveyor.yml
generated
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
version: build-{build}.{branch}
|
||||
|
||||
clone_folder: C:\gopath\src\github.com\Masterminds\semver
|
||||
shallow_clone: true
|
||||
|
||||
environment:
|
||||
GOPATH: C:\gopath
|
||||
|
||||
platform:
|
||||
- x64
|
||||
|
||||
install:
|
||||
- go version
|
||||
- go env
|
||||
- go get -u gopkg.in/alecthomas/gometalinter.v1
|
||||
- set PATH=%PATH%;%GOPATH%\bin
|
||||
- gometalinter.v1.exe --install
|
||||
|
||||
build_script:
|
||||
- go install -v ./...
|
||||
|
||||
test_script:
|
||||
- "gometalinter.v1 \
|
||||
--disable-all \
|
||||
--enable deadcode \
|
||||
--severity deadcode:error \
|
||||
--enable gofmt \
|
||||
--enable gosimple \
|
||||
--enable ineffassign \
|
||||
--enable misspell \
|
||||
--enable vet \
|
||||
--tests \
|
||||
--vendor \
|
||||
--deadline 60s \
|
||||
./... || exit_code=1"
|
||||
- "gometalinter.v1 \
|
||||
--disable-all \
|
||||
--enable golint \
|
||||
--vendor \
|
||||
--deadline 60s \
|
||||
./... || :"
|
||||
- go test -v
|
||||
|
||||
deploy: off
|
||||
24
backend/vendor/github.com/Masterminds/semver/collection.go
generated
vendored
Normal file
24
backend/vendor/github.com/Masterminds/semver/collection.go
generated
vendored
Normal file
@@ -0,0 +1,24 @@
|
||||
package semver
|
||||
|
||||
// Collection is a collection of Version instances and implements the sort
|
||||
// interface. See the sort package for more details.
|
||||
// https://golang.org/pkg/sort/
|
||||
type Collection []*Version
|
||||
|
||||
// Len returns the length of a collection. The number of Version instances
|
||||
// on the slice.
|
||||
func (c Collection) Len() int {
|
||||
return len(c)
|
||||
}
|
||||
|
||||
// Less is needed for the sort interface to compare two Version objects on the
|
||||
// slice. If checks if one is less than the other.
|
||||
func (c Collection) Less(i, j int) bool {
|
||||
return c[i].LessThan(c[j])
|
||||
}
|
||||
|
||||
// Swap is needed for the sort interface to replace the Version objects
|
||||
// at two different positions in the slice.
|
||||
func (c Collection) Swap(i, j int) {
|
||||
c[i], c[j] = c[j], c[i]
|
||||
}
|
||||
426
backend/vendor/github.com/Masterminds/semver/constraints.go
generated
vendored
Normal file
426
backend/vendor/github.com/Masterminds/semver/constraints.go
generated
vendored
Normal file
@@ -0,0 +1,426 @@
|
||||
package semver
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"fmt"
|
||||
"regexp"
|
||||
"strings"
|
||||
)
|
||||
|
||||
// Constraints is one or more constraint that a semantic version can be
|
||||
// checked against.
|
||||
type Constraints struct {
|
||||
constraints [][]*constraint
|
||||
}
|
||||
|
||||
// NewConstraint returns a Constraints instance that a Version instance can
|
||||
// be checked against. If there is a parse error it will be returned.
|
||||
func NewConstraint(c string) (*Constraints, error) {
|
||||
|
||||
// Rewrite - ranges into a comparison operation.
|
||||
c = rewriteRange(c)
|
||||
|
||||
ors := strings.Split(c, "||")
|
||||
or := make([][]*constraint, len(ors))
|
||||
for k, v := range ors {
|
||||
cs := strings.Split(v, ",")
|
||||
result := make([]*constraint, len(cs))
|
||||
for i, s := range cs {
|
||||
pc, err := parseConstraint(s)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
|
||||
result[i] = pc
|
||||
}
|
||||
or[k] = result
|
||||
}
|
||||
|
||||
o := &Constraints{constraints: or}
|
||||
return o, nil
|
||||
}
|
||||
|
||||
// Check tests if a version satisfies the constraints.
|
||||
func (cs Constraints) Check(v *Version) bool {
|
||||
// loop over the ORs and check the inner ANDs
|
||||
for _, o := range cs.constraints {
|
||||
joy := true
|
||||
for _, c := range o {
|
||||
if !c.check(v) {
|
||||
joy = false
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
if joy {
|
||||
return true
|
||||
}
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
// Validate checks if a version satisfies a constraint. If not a slice of
|
||||
// reasons for the failure are returned in addition to a bool.
|
||||
func (cs Constraints) Validate(v *Version) (bool, []error) {
|
||||
// loop over the ORs and check the inner ANDs
|
||||
var e []error
|
||||
for _, o := range cs.constraints {
|
||||
joy := true
|
||||
for _, c := range o {
|
||||
if !c.check(v) {
|
||||
em := fmt.Errorf(c.msg, v, c.orig)
|
||||
e = append(e, em)
|
||||
joy = false
|
||||
}
|
||||
}
|
||||
|
||||
if joy {
|
||||
return true, []error{}
|
||||
}
|
||||
}
|
||||
|
||||
return false, e
|
||||
}
|
||||
|
||||
var constraintOps map[string]cfunc
|
||||
var constraintMsg map[string]string
|
||||
var constraintRegex *regexp.Regexp
|
||||
|
||||
func init() {
|
||||
constraintOps = map[string]cfunc{
|
||||
"": constraintTildeOrEqual,
|
||||
"=": constraintTildeOrEqual,
|
||||
"!=": constraintNotEqual,
|
||||
">": constraintGreaterThan,
|
||||
"<": constraintLessThan,
|
||||
">=": constraintGreaterThanEqual,
|
||||
"=>": constraintGreaterThanEqual,
|
||||
"<=": constraintLessThanEqual,
|
||||
"=<": constraintLessThanEqual,
|
||||
"~": constraintTilde,
|
||||
"~>": constraintTilde,
|
||||
"^": constraintCaret,
|
||||
}
|
||||
|
||||
constraintMsg = map[string]string{
|
||||
"": "%s is not equal to %s",
|
||||
"=": "%s is not equal to %s",
|
||||
"!=": "%s is equal to %s",
|
||||
">": "%s is less than or equal to %s",
|
||||
"<": "%s is greater than or equal to %s",
|
||||
">=": "%s is less than %s",
|
||||
"=>": "%s is less than %s",
|
||||
"<=": "%s is greater than %s",
|
||||
"=<": "%s is greater than %s",
|
||||
"~": "%s does not have same major and minor version as %s",
|
||||
"~>": "%s does not have same major and minor version as %s",
|
||||
"^": "%s does not have same major version as %s",
|
||||
}
|
||||
|
||||
ops := make([]string, 0, len(constraintOps))
|
||||
for k := range constraintOps {
|
||||
ops = append(ops, regexp.QuoteMeta(k))
|
||||
}
|
||||
|
||||
constraintRegex = regexp.MustCompile(fmt.Sprintf(
|
||||
`^\s*(%s)\s*(%s)\s*$`,
|
||||
strings.Join(ops, "|"),
|
||||
cvRegex))
|
||||
|
||||
constraintRangeRegex = regexp.MustCompile(fmt.Sprintf(
|
||||
`\s*(%s)\s+-\s+(%s)\s*`,
|
||||
cvRegex, cvRegex))
|
||||
}
|
||||
|
||||
// An individual constraint
|
||||
type constraint struct {
|
||||
// The callback function for the restraint. It performs the logic for
|
||||
// the constraint.
|
||||
function cfunc
|
||||
|
||||
msg string
|
||||
|
||||
// The version used in the constraint check. For example, if a constraint
|
||||
// is '<= 2.0.0' the con a version instance representing 2.0.0.
|
||||
con *Version
|
||||
|
||||
// The original parsed version (e.g., 4.x from != 4.x)
|
||||
orig string
|
||||
|
||||
// When an x is used as part of the version (e.g., 1.x)
|
||||
minorDirty bool
|
||||
dirty bool
|
||||
patchDirty bool
|
||||
}
|
||||
|
||||
// Check if a version meets the constraint
|
||||
func (c *constraint) check(v *Version) bool {
|
||||
return c.function(v, c)
|
||||
}
|
||||
|
||||
type cfunc func(v *Version, c *constraint) bool
|
||||
|
||||
func parseConstraint(c string) (*constraint, error) {
|
||||
m := constraintRegex.FindStringSubmatch(c)
|
||||
if m == nil {
|
||||
return nil, fmt.Errorf("improper constraint: %s", c)
|
||||
}
|
||||
|
||||
ver := m[2]
|
||||
orig := ver
|
||||
minorDirty := false
|
||||
patchDirty := false
|
||||
dirty := false
|
||||
if isX(m[3]) {
|
||||
ver = "0.0.0"
|
||||
dirty = true
|
||||
} else if isX(strings.TrimPrefix(m[4], ".")) || m[4] == "" {
|
||||
minorDirty = true
|
||||
dirty = true
|
||||
ver = fmt.Sprintf("%s.0.0%s", m[3], m[6])
|
||||
} else if isX(strings.TrimPrefix(m[5], ".")) {
|
||||
dirty = true
|
||||
patchDirty = true
|
||||
ver = fmt.Sprintf("%s%s.0%s", m[3], m[4], m[6])
|
||||
}
|
||||
|
||||
con, err := NewVersion(ver)
|
||||
if err != nil {
|
||||
|
||||
// The constraintRegex should catch any regex parsing errors. So,
|
||||
// we should never get here.
|
||||
return nil, errors.New("constraint Parser Error")
|
||||
}
|
||||
|
||||
cs := &constraint{
|
||||
function: constraintOps[m[1]],
|
||||
msg: constraintMsg[m[1]],
|
||||
con: con,
|
||||
orig: orig,
|
||||
minorDirty: minorDirty,
|
||||
patchDirty: patchDirty,
|
||||
dirty: dirty,
|
||||
}
|
||||
return cs, nil
|
||||
}
|
||||
|
||||
// Constraint functions
|
||||
func constraintNotEqual(v *Version, c *constraint) bool {
|
||||
if c.dirty {
|
||||
|
||||
// If there is a pre-release on the version but the constraint isn't looking
|
||||
// for them assume that pre-releases are not compatible. See issue 21 for
|
||||
// more details.
|
||||
if v.Prerelease() != "" && c.con.Prerelease() == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
if c.con.Major() != v.Major() {
|
||||
return true
|
||||
}
|
||||
if c.con.Minor() != v.Minor() && !c.minorDirty {
|
||||
return true
|
||||
} else if c.minorDirty {
|
||||
return false
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
|
||||
return !v.Equal(c.con)
|
||||
}
|
||||
|
||||
func constraintGreaterThan(v *Version, c *constraint) bool {
|
||||
|
||||
// An edge case the constraint is 0.0.0 and the version is 0.0.0-someprerelease
|
||||
// exists. This that case.
|
||||
if !isNonZero(c.con) && isNonZero(v) {
|
||||
return true
|
||||
}
|
||||
|
||||
// If there is a pre-release on the version but the constraint isn't looking
|
||||
// for them assume that pre-releases are not compatible. See issue 21 for
|
||||
// more details.
|
||||
if v.Prerelease() != "" && c.con.Prerelease() == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
return v.Compare(c.con) == 1
|
||||
}
|
||||
|
||||
func constraintLessThan(v *Version, c *constraint) bool {
|
||||
// If there is a pre-release on the version but the constraint isn't looking
|
||||
// for them assume that pre-releases are not compatible. See issue 21 for
|
||||
// more details.
|
||||
if v.Prerelease() != "" && c.con.Prerelease() == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
if !c.dirty {
|
||||
return v.Compare(c.con) < 0
|
||||
}
|
||||
|
||||
if v.Major() > c.con.Major() {
|
||||
return false
|
||||
} else if v.Minor() > c.con.Minor() && !c.minorDirty {
|
||||
return false
|
||||
}
|
||||
|
||||
return true
|
||||
}
|
||||
|
||||
func constraintGreaterThanEqual(v *Version, c *constraint) bool {
|
||||
// An edge case the constraint is 0.0.0 and the version is 0.0.0-someprerelease
|
||||
// exists. This that case.
|
||||
if !isNonZero(c.con) && isNonZero(v) {
|
||||
return true
|
||||
}
|
||||
|
||||
// If there is a pre-release on the version but the constraint isn't looking
|
||||
// for them assume that pre-releases are not compatible. See issue 21 for
|
||||
// more details.
|
||||
if v.Prerelease() != "" && c.con.Prerelease() == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
return v.Compare(c.con) >= 0
|
||||
}
|
||||
|
||||
func constraintLessThanEqual(v *Version, c *constraint) bool {
|
||||
// If there is a pre-release on the version but the constraint isn't looking
|
||||
// for them assume that pre-releases are not compatible. See issue 21 for
|
||||
// more details.
|
||||
if v.Prerelease() != "" && c.con.Prerelease() == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
if !c.dirty {
|
||||
return v.Compare(c.con) <= 0
|
||||
}
|
||||
|
||||
if v.Major() > c.con.Major() {
|
||||
return false
|
||||
} else if v.Minor() > c.con.Minor() && !c.minorDirty {
|
||||
return false
|
||||
}
|
||||
|
||||
return true
|
||||
}
|
||||
|
||||
// ~*, ~>* --> >= 0.0.0 (any)
|
||||
// ~2, ~2.x, ~2.x.x, ~>2, ~>2.x ~>2.x.x --> >=2.0.0, <3.0.0
|
||||
// ~2.0, ~2.0.x, ~>2.0, ~>2.0.x --> >=2.0.0, <2.1.0
|
||||
// ~1.2, ~1.2.x, ~>1.2, ~>1.2.x --> >=1.2.0, <1.3.0
|
||||
// ~1.2.3, ~>1.2.3 --> >=1.2.3, <1.3.0
|
||||
// ~1.2.0, ~>1.2.0 --> >=1.2.0, <1.3.0
|
||||
func constraintTilde(v *Version, c *constraint) bool {
|
||||
// If there is a pre-release on the version but the constraint isn't looking
|
||||
// for them assume that pre-releases are not compatible. See issue 21 for
|
||||
// more details.
|
||||
if v.Prerelease() != "" && c.con.Prerelease() == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
if v.LessThan(c.con) {
|
||||
return false
|
||||
}
|
||||
|
||||
// ~0.0.0 is a special case where all constraints are accepted. It's
|
||||
// equivalent to >= 0.0.0.
|
||||
if c.con.Major() == 0 && c.con.Minor() == 0 && c.con.Patch() == 0 &&
|
||||
!c.minorDirty && !c.patchDirty {
|
||||
return true
|
||||
}
|
||||
|
||||
if v.Major() != c.con.Major() {
|
||||
return false
|
||||
}
|
||||
|
||||
if v.Minor() != c.con.Minor() && !c.minorDirty {
|
||||
return false
|
||||
}
|
||||
|
||||
return true
|
||||
}
|
||||
|
||||
// When there is a .x (dirty) status it automatically opts in to ~. Otherwise
|
||||
// it's a straight =
|
||||
func constraintTildeOrEqual(v *Version, c *constraint) bool {
|
||||
// If there is a pre-release on the version but the constraint isn't looking
|
||||
// for them assume that pre-releases are not compatible. See issue 21 for
|
||||
// more details.
|
||||
if v.Prerelease() != "" && c.con.Prerelease() == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
if c.dirty {
|
||||
c.msg = constraintMsg["~"]
|
||||
return constraintTilde(v, c)
|
||||
}
|
||||
|
||||
return v.Equal(c.con)
|
||||
}
|
||||
|
||||
// ^* --> (any)
|
||||
// ^2, ^2.x, ^2.x.x --> >=2.0.0, <3.0.0
|
||||
// ^2.0, ^2.0.x --> >=2.0.0, <3.0.0
|
||||
// ^1.2, ^1.2.x --> >=1.2.0, <2.0.0
|
||||
// ^1.2.3 --> >=1.2.3, <2.0.0
|
||||
// ^1.2.0 --> >=1.2.0, <2.0.0
|
||||
func constraintCaret(v *Version, c *constraint) bool {
|
||||
// If there is a pre-release on the version but the constraint isn't looking
|
||||
// for them assume that pre-releases are not compatible. See issue 21 for
|
||||
// more details.
|
||||
if v.Prerelease() != "" && c.con.Prerelease() == "" {
|
||||
return false
|
||||
}
|
||||
|
||||
if v.LessThan(c.con) {
|
||||
return false
|
||||
}
|
||||
|
||||
if v.Major() != c.con.Major() {
|
||||
return false
|
||||
}
|
||||
|
||||
return true
|
||||
}
|
||||
|
||||
var constraintRangeRegex *regexp.Regexp
|
||||
|
||||
const cvRegex string = `v?([0-9|x|X|\*]+)(\.[0-9|x|X|\*]+)?(\.[0-9|x|X|\*]+)?` +
|
||||
`(-([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*))?` +
|
||||
`(\+([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*))?`
|
||||
|
||||
func isX(x string) bool {
|
||||
switch x {
|
||||
case "x", "*", "X":
|
||||
return true
|
||||
default:
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
func rewriteRange(i string) string {
|
||||
m := constraintRangeRegex.FindAllStringSubmatch(i, -1)
|
||||
if m == nil {
|
||||
return i
|
||||
}
|
||||
o := i
|
||||
for _, v := range m {
|
||||
t := fmt.Sprintf(">= %s, <= %s", v[1], v[11])
|
||||
o = strings.Replace(o, v[0], t, 1)
|
||||
}
|
||||
|
||||
return o
|
||||
}
|
||||
|
||||
// Detect if a version is not zero (0.0.0)
|
||||
func isNonZero(v *Version) bool {
|
||||
if v.Major() != 0 || v.Minor() != 0 || v.Patch() != 0 || v.Prerelease() != "" {
|
||||
return true
|
||||
}
|
||||
|
||||
return false
|
||||
}
|
||||
115
backend/vendor/github.com/Masterminds/semver/doc.go
generated
vendored
Normal file
115
backend/vendor/github.com/Masterminds/semver/doc.go
generated
vendored
Normal file
@@ -0,0 +1,115 @@
|
||||
/*
|
||||
Package semver provides the ability to work with Semantic Versions (http://semver.org) in Go.
|
||||
|
||||
Specifically it provides the ability to:
|
||||
|
||||
* Parse semantic versions
|
||||
* Sort semantic versions
|
||||
* Check if a semantic version fits within a set of constraints
|
||||
* Optionally work with a `v` prefix
|
||||
|
||||
Parsing Semantic Versions
|
||||
|
||||
To parse a semantic version use the `NewVersion` function. For example,
|
||||
|
||||
v, err := semver.NewVersion("1.2.3-beta.1+build345")
|
||||
|
||||
If there is an error the version wasn't parseable. The version object has methods
|
||||
to get the parts of the version, compare it to other versions, convert the
|
||||
version back into a string, and get the original string. For more details
|
||||
please see the documentation at https://godoc.org/github.com/Masterminds/semver.
|
||||
|
||||
Sorting Semantic Versions
|
||||
|
||||
A set of versions can be sorted using the `sort` package from the standard library.
|
||||
For example,
|
||||
|
||||
raw := []string{"1.2.3", "1.0", "1.3", "2", "0.4.2",}
|
||||
vs := make([]*semver.Version, len(raw))
|
||||
for i, r := range raw {
|
||||
v, err := semver.NewVersion(r)
|
||||
if err != nil {
|
||||
t.Errorf("Error parsing version: %s", err)
|
||||
}
|
||||
|
||||
vs[i] = v
|
||||
}
|
||||
|
||||
sort.Sort(semver.Collection(vs))
|
||||
|
||||
Checking Version Constraints
|
||||
|
||||
Checking a version against version constraints is one of the most featureful
|
||||
parts of the package.
|
||||
|
||||
c, err := semver.NewConstraint(">= 1.2.3")
|
||||
if err != nil {
|
||||
// Handle constraint not being parseable.
|
||||
}
|
||||
|
||||
v, _ := semver.NewVersion("1.3")
|
||||
if err != nil {
|
||||
// Handle version not being parseable.
|
||||
}
|
||||
// Check if the version meets the constraints. The a variable will be true.
|
||||
a := c.Check(v)
|
||||
|
||||
Basic Comparisons
|
||||
|
||||
There are two elements to the comparisons. First, a comparison string is a list
|
||||
of comma separated and comparisons. These are then separated by || separated or
|
||||
comparisons. For example, `">= 1.2, < 3.0.0 || >= 4.2.3"` is looking for a
|
||||
comparison that's greater than or equal to 1.2 and less than 3.0.0 or is
|
||||
greater than or equal to 4.2.3.
|
||||
|
||||
The basic comparisons are:
|
||||
|
||||
* `=`: equal (aliased to no operator)
|
||||
* `!=`: not equal
|
||||
* `>`: greater than
|
||||
* `<`: less than
|
||||
* `>=`: greater than or equal to
|
||||
* `<=`: less than or equal to
|
||||
|
||||
Hyphen Range Comparisons
|
||||
|
||||
There are multiple methods to handle ranges and the first is hyphens ranges.
|
||||
These look like:
|
||||
|
||||
* `1.2 - 1.4.5` which is equivalent to `>= 1.2, <= 1.4.5`
|
||||
* `2.3.4 - 4.5` which is equivalent to `>= 2.3.4, <= 4.5`
|
||||
|
||||
Wildcards In Comparisons
|
||||
|
||||
The `x`, `X`, and `*` characters can be used as a wildcard character. This works
|
||||
for all comparison operators. When used on the `=` operator it falls
|
||||
back to the pack level comparison (see tilde below). For example,
|
||||
|
||||
* `1.2.x` is equivalent to `>= 1.2.0, < 1.3.0`
|
||||
* `>= 1.2.x` is equivalent to `>= 1.2.0`
|
||||
* `<= 2.x` is equivalent to `<= 3`
|
||||
* `*` is equivalent to `>= 0.0.0`
|
||||
|
||||
Tilde Range Comparisons (Patch)
|
||||
|
||||
The tilde (`~`) comparison operator is for patch level ranges when a minor
|
||||
version is specified and major level changes when the minor number is missing.
|
||||
For example,
|
||||
|
||||
* `~1.2.3` is equivalent to `>= 1.2.3, < 1.3.0`
|
||||
* `~1` is equivalent to `>= 1, < 2`
|
||||
* `~2.3` is equivalent to `>= 2.3, < 2.4`
|
||||
* `~1.2.x` is equivalent to `>= 1.2.0, < 1.3.0`
|
||||
* `~1.x` is equivalent to `>= 1, < 2`
|
||||
|
||||
Caret Range Comparisons (Major)
|
||||
|
||||
The caret (`^`) comparison operator is for major level changes. This is useful
|
||||
when comparisons of API versions as a major change is API breaking. For example,
|
||||
|
||||
* `^1.2.3` is equivalent to `>= 1.2.3, < 2.0.0`
|
||||
* `^1.2.x` is equivalent to `>= 1.2.0, < 2.0.0`
|
||||
* `^2.3` is equivalent to `>= 2.3, < 3`
|
||||
* `^2.x` is equivalent to `>= 2.0.0, < 3`
|
||||
*/
|
||||
package semver
|
||||
421
backend/vendor/github.com/Masterminds/semver/version.go
generated
vendored
Normal file
421
backend/vendor/github.com/Masterminds/semver/version.go
generated
vendored
Normal file
@@ -0,0 +1,421 @@
|
||||
package semver
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"encoding/json"
|
||||
"errors"
|
||||
"fmt"
|
||||
"regexp"
|
||||
"strconv"
|
||||
"strings"
|
||||
)
|
||||
|
||||
// The compiled version of the regex created at init() is cached here so it
|
||||
// only needs to be created once.
|
||||
var versionRegex *regexp.Regexp
|
||||
var validPrereleaseRegex *regexp.Regexp
|
||||
|
||||
var (
|
||||
// ErrInvalidSemVer is returned a version is found to be invalid when
|
||||
// being parsed.
|
||||
ErrInvalidSemVer = errors.New("Invalid Semantic Version")
|
||||
|
||||
// ErrInvalidMetadata is returned when the metadata is an invalid format
|
||||
ErrInvalidMetadata = errors.New("Invalid Metadata string")
|
||||
|
||||
// ErrInvalidPrerelease is returned when the pre-release is an invalid format
|
||||
ErrInvalidPrerelease = errors.New("Invalid Prerelease string")
|
||||
)
|
||||
|
||||
// SemVerRegex is the regular expression used to parse a semantic version.
|
||||
const SemVerRegex string = `v?([0-9]+)(\.[0-9]+)?(\.[0-9]+)?` +
|
||||
`(-([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*))?` +
|
||||
`(\+([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*))?`
|
||||
|
||||
// ValidPrerelease is the regular expression which validates
|
||||
// both prerelease and metadata values.
|
||||
const ValidPrerelease string = `^([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*)`
|
||||
|
||||
// Version represents a single semantic version.
|
||||
type Version struct {
|
||||
major, minor, patch int64
|
||||
pre string
|
||||
metadata string
|
||||
original string
|
||||
}
|
||||
|
||||
func init() {
|
||||
versionRegex = regexp.MustCompile("^" + SemVerRegex + "$")
|
||||
validPrereleaseRegex = regexp.MustCompile(ValidPrerelease)
|
||||
}
|
||||
|
||||
// NewVersion parses a given version and returns an instance of Version or
|
||||
// an error if unable to parse the version.
|
||||
func NewVersion(v string) (*Version, error) {
|
||||
m := versionRegex.FindStringSubmatch(v)
|
||||
if m == nil {
|
||||
return nil, ErrInvalidSemVer
|
||||
}
|
||||
|
||||
sv := &Version{
|
||||
metadata: m[8],
|
||||
pre: m[5],
|
||||
original: v,
|
||||
}
|
||||
|
||||
var temp int64
|
||||
temp, err := strconv.ParseInt(m[1], 10, 64)
|
||||
if err != nil {
|
||||
return nil, fmt.Errorf("Error parsing version segment: %s", err)
|
||||
}
|
||||
sv.major = temp
|
||||
|
||||
if m[2] != "" {
|
||||
temp, err = strconv.ParseInt(strings.TrimPrefix(m[2], "."), 10, 64)
|
||||
if err != nil {
|
||||
return nil, fmt.Errorf("Error parsing version segment: %s", err)
|
||||
}
|
||||
sv.minor = temp
|
||||
} else {
|
||||
sv.minor = 0
|
||||
}
|
||||
|
||||
if m[3] != "" {
|
||||
temp, err = strconv.ParseInt(strings.TrimPrefix(m[3], "."), 10, 64)
|
||||
if err != nil {
|
||||
return nil, fmt.Errorf("Error parsing version segment: %s", err)
|
||||
}
|
||||
sv.patch = temp
|
||||
} else {
|
||||
sv.patch = 0
|
||||
}
|
||||
|
||||
return sv, nil
|
||||
}
|
||||
|
||||
// MustParse parses a given version and panics on error.
|
||||
func MustParse(v string) *Version {
|
||||
sv, err := NewVersion(v)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return sv
|
||||
}
|
||||
|
||||
// String converts a Version object to a string.
|
||||
// Note, if the original version contained a leading v this version will not.
|
||||
// See the Original() method to retrieve the original value. Semantic Versions
|
||||
// don't contain a leading v per the spec. Instead it's optional on
|
||||
// impelementation.
|
||||
func (v *Version) String() string {
|
||||
var buf bytes.Buffer
|
||||
|
||||
fmt.Fprintf(&buf, "%d.%d.%d", v.major, v.minor, v.patch)
|
||||
if v.pre != "" {
|
||||
fmt.Fprintf(&buf, "-%s", v.pre)
|
||||
}
|
||||
if v.metadata != "" {
|
||||
fmt.Fprintf(&buf, "+%s", v.metadata)
|
||||
}
|
||||
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// Original returns the original value passed in to be parsed.
|
||||
func (v *Version) Original() string {
|
||||
return v.original
|
||||
}
|
||||
|
||||
// Major returns the major version.
|
||||
func (v *Version) Major() int64 {
|
||||
return v.major
|
||||
}
|
||||
|
||||
// Minor returns the minor version.
|
||||
func (v *Version) Minor() int64 {
|
||||
return v.minor
|
||||
}
|
||||
|
||||
// Patch returns the patch version.
|
||||
func (v *Version) Patch() int64 {
|
||||
return v.patch
|
||||
}
|
||||
|
||||
// Prerelease returns the pre-release version.
|
||||
func (v *Version) Prerelease() string {
|
||||
return v.pre
|
||||
}
|
||||
|
||||
// Metadata returns the metadata on the version.
|
||||
func (v *Version) Metadata() string {
|
||||
return v.metadata
|
||||
}
|
||||
|
||||
// originalVPrefix returns the original 'v' prefix if any.
|
||||
func (v *Version) originalVPrefix() string {
|
||||
|
||||
// Note, only lowercase v is supported as a prefix by the parser.
|
||||
if v.original != "" && v.original[:1] == "v" {
|
||||
return v.original[:1]
|
||||
}
|
||||
return ""
|
||||
}
|
||||
|
||||
// IncPatch produces the next patch version.
|
||||
// If the current version does not have prerelease/metadata information,
|
||||
// it unsets metadata and prerelease values, increments patch number.
|
||||
// If the current version has any of prerelease or metadata information,
|
||||
// it unsets both values and keeps curent patch value
|
||||
func (v Version) IncPatch() Version {
|
||||
vNext := v
|
||||
// according to http://semver.org/#spec-item-9
|
||||
// Pre-release versions have a lower precedence than the associated normal version.
|
||||
// according to http://semver.org/#spec-item-10
|
||||
// Build metadata SHOULD be ignored when determining version precedence.
|
||||
if v.pre != "" {
|
||||
vNext.metadata = ""
|
||||
vNext.pre = ""
|
||||
} else {
|
||||
vNext.metadata = ""
|
||||
vNext.pre = ""
|
||||
vNext.patch = v.patch + 1
|
||||
}
|
||||
vNext.original = v.originalVPrefix() + "" + vNext.String()
|
||||
return vNext
|
||||
}
|
||||
|
||||
// IncMinor produces the next minor version.
|
||||
// Sets patch to 0.
|
||||
// Increments minor number.
|
||||
// Unsets metadata.
|
||||
// Unsets prerelease status.
|
||||
func (v Version) IncMinor() Version {
|
||||
vNext := v
|
||||
vNext.metadata = ""
|
||||
vNext.pre = ""
|
||||
vNext.patch = 0
|
||||
vNext.minor = v.minor + 1
|
||||
vNext.original = v.originalVPrefix() + "" + vNext.String()
|
||||
return vNext
|
||||
}
|
||||
|
||||
// IncMajor produces the next major version.
|
||||
// Sets patch to 0.
|
||||
// Sets minor to 0.
|
||||
// Increments major number.
|
||||
// Unsets metadata.
|
||||
// Unsets prerelease status.
|
||||
func (v Version) IncMajor() Version {
|
||||
vNext := v
|
||||
vNext.metadata = ""
|
||||
vNext.pre = ""
|
||||
vNext.patch = 0
|
||||
vNext.minor = 0
|
||||
vNext.major = v.major + 1
|
||||
vNext.original = v.originalVPrefix() + "" + vNext.String()
|
||||
return vNext
|
||||
}
|
||||
|
||||
// SetPrerelease defines the prerelease value.
|
||||
// Value must not include the required 'hypen' prefix.
|
||||
func (v Version) SetPrerelease(prerelease string) (Version, error) {
|
||||
vNext := v
|
||||
if len(prerelease) > 0 && !validPrereleaseRegex.MatchString(prerelease) {
|
||||
return vNext, ErrInvalidPrerelease
|
||||
}
|
||||
vNext.pre = prerelease
|
||||
vNext.original = v.originalVPrefix() + "" + vNext.String()
|
||||
return vNext, nil
|
||||
}
|
||||
|
||||
// SetMetadata defines metadata value.
|
||||
// Value must not include the required 'plus' prefix.
|
||||
func (v Version) SetMetadata(metadata string) (Version, error) {
|
||||
vNext := v
|
||||
if len(metadata) > 0 && !validPrereleaseRegex.MatchString(metadata) {
|
||||
return vNext, ErrInvalidMetadata
|
||||
}
|
||||
vNext.metadata = metadata
|
||||
vNext.original = v.originalVPrefix() + "" + vNext.String()
|
||||
return vNext, nil
|
||||
}
|
||||
|
||||
// LessThan tests if one version is less than another one.
|
||||
func (v *Version) LessThan(o *Version) bool {
|
||||
return v.Compare(o) < 0
|
||||
}
|
||||
|
||||
// GreaterThan tests if one version is greater than another one.
|
||||
func (v *Version) GreaterThan(o *Version) bool {
|
||||
return v.Compare(o) > 0
|
||||
}
|
||||
|
||||
// Equal tests if two versions are equal to each other.
|
||||
// Note, versions can be equal with different metadata since metadata
|
||||
// is not considered part of the comparable version.
|
||||
func (v *Version) Equal(o *Version) bool {
|
||||
return v.Compare(o) == 0
|
||||
}
|
||||
|
||||
// Compare compares this version to another one. It returns -1, 0, or 1 if
|
||||
// the version smaller, equal, or larger than the other version.
|
||||
//
|
||||
// Versions are compared by X.Y.Z. Build metadata is ignored. Prerelease is
|
||||
// lower than the version without a prerelease.
|
||||
func (v *Version) Compare(o *Version) int {
|
||||
// Compare the major, minor, and patch version for differences. If a
|
||||
// difference is found return the comparison.
|
||||
if d := compareSegment(v.Major(), o.Major()); d != 0 {
|
||||
return d
|
||||
}
|
||||
if d := compareSegment(v.Minor(), o.Minor()); d != 0 {
|
||||
return d
|
||||
}
|
||||
if d := compareSegment(v.Patch(), o.Patch()); d != 0 {
|
||||
return d
|
||||
}
|
||||
|
||||
// At this point the major, minor, and patch versions are the same.
|
||||
ps := v.pre
|
||||
po := o.Prerelease()
|
||||
|
||||
if ps == "" && po == "" {
|
||||
return 0
|
||||
}
|
||||
if ps == "" {
|
||||
return 1
|
||||
}
|
||||
if po == "" {
|
||||
return -1
|
||||
}
|
||||
|
||||
return comparePrerelease(ps, po)
|
||||
}
|
||||
|
||||
// UnmarshalJSON implements JSON.Unmarshaler interface.
|
||||
func (v *Version) UnmarshalJSON(b []byte) error {
|
||||
var s string
|
||||
if err := json.Unmarshal(b, &s); err != nil {
|
||||
return err
|
||||
}
|
||||
temp, err := NewVersion(s)
|
||||
if err != nil {
|
||||
return err
|
||||
}
|
||||
v.major = temp.major
|
||||
v.minor = temp.minor
|
||||
v.patch = temp.patch
|
||||
v.pre = temp.pre
|
||||
v.metadata = temp.metadata
|
||||
v.original = temp.original
|
||||
temp = nil
|
||||
return nil
|
||||
}
|
||||
|
||||
// MarshalJSON implements JSON.Marshaler interface.
|
||||
func (v *Version) MarshalJSON() ([]byte, error) {
|
||||
return json.Marshal(v.String())
|
||||
}
|
||||
|
||||
func compareSegment(v, o int64) int {
|
||||
if v < o {
|
||||
return -1
|
||||
}
|
||||
if v > o {
|
||||
return 1
|
||||
}
|
||||
|
||||
return 0
|
||||
}
|
||||
|
||||
func comparePrerelease(v, o string) int {
|
||||
|
||||
// split the prelease versions by their part. The separator, per the spec,
|
||||
// is a .
|
||||
sparts := strings.Split(v, ".")
|
||||
oparts := strings.Split(o, ".")
|
||||
|
||||
// Find the longer length of the parts to know how many loop iterations to
|
||||
// go through.
|
||||
slen := len(sparts)
|
||||
olen := len(oparts)
|
||||
|
||||
l := slen
|
||||
if olen > slen {
|
||||
l = olen
|
||||
}
|
||||
|
||||
// Iterate over each part of the prereleases to compare the differences.
|
||||
for i := 0; i < l; i++ {
|
||||
// Since the lentgh of the parts can be different we need to create
|
||||
// a placeholder. This is to avoid out of bounds issues.
|
||||
stemp := ""
|
||||
if i < slen {
|
||||
stemp = sparts[i]
|
||||
}
|
||||
|
||||
otemp := ""
|
||||
if i < olen {
|
||||
otemp = oparts[i]
|
||||
}
|
||||
|
||||
d := comparePrePart(stemp, otemp)
|
||||
if d != 0 {
|
||||
return d
|
||||
}
|
||||
}
|
||||
|
||||
// Reaching here means two versions are of equal value but have different
|
||||
// metadata (the part following a +). They are not identical in string form
|
||||
// but the version comparison finds them to be equal.
|
||||
return 0
|
||||
}
|
||||
|
||||
func comparePrePart(s, o string) int {
|
||||
// Fastpath if they are equal
|
||||
if s == o {
|
||||
return 0
|
||||
}
|
||||
|
||||
// When s or o are empty we can use the other in an attempt to determine
|
||||
// the response.
|
||||
if s == "" {
|
||||
if o != "" {
|
||||
return -1
|
||||
}
|
||||
return 1
|
||||
}
|
||||
|
||||
if o == "" {
|
||||
if s != "" {
|
||||
return 1
|
||||
}
|
||||
return -1
|
||||
}
|
||||
|
||||
// When comparing strings "99" is greater than "103". To handle
|
||||
// cases like this we need to detect numbers and compare them.
|
||||
|
||||
oi, n1 := strconv.ParseInt(o, 10, 64)
|
||||
si, n2 := strconv.ParseInt(s, 10, 64)
|
||||
|
||||
// The case where both are strings compare the strings
|
||||
if n1 != nil && n2 != nil {
|
||||
if s > o {
|
||||
return 1
|
||||
}
|
||||
return -1
|
||||
} else if n1 != nil {
|
||||
// o is a string and s is a number
|
||||
return -1
|
||||
} else if n2 != nil {
|
||||
// s is a string and o is a number
|
||||
return 1
|
||||
}
|
||||
// Both are numbers
|
||||
if si > oi {
|
||||
return 1
|
||||
}
|
||||
return -1
|
||||
|
||||
}
|
||||
2
backend/vendor/github.com/Masterminds/sprig/.gitignore
generated
vendored
Normal file
2
backend/vendor/github.com/Masterminds/sprig/.gitignore
generated
vendored
Normal file
@@ -0,0 +1,2 @@
|
||||
vendor/
|
||||
/.glide
|
||||
24
backend/vendor/github.com/Masterminds/sprig/.travis.yml
generated
vendored
Normal file
24
backend/vendor/github.com/Masterminds/sprig/.travis.yml
generated
vendored
Normal file
@@ -0,0 +1,24 @@
|
||||
language: go
|
||||
|
||||
go:
|
||||
- 1.9.x
|
||||
- 1.10.x
|
||||
- 1.11.x
|
||||
- tip
|
||||
|
||||
# Setting sudo access to false will let Travis CI use containers rather than
|
||||
# VMs to run the tests. For more details see:
|
||||
# - http://docs.travis-ci.com/user/workers/container-based-infrastructure/
|
||||
# - http://docs.travis-ci.com/user/workers/standard-infrastructure/
|
||||
sudo: false
|
||||
|
||||
script:
|
||||
- make setup test
|
||||
|
||||
notifications:
|
||||
webhooks:
|
||||
urls:
|
||||
- https://webhooks.gitter.im/e/06e3328629952dabe3e0
|
||||
on_success: change # options: [always|never|change] default: always
|
||||
on_failure: always # options: [always|never|change] default: always
|
||||
on_start: never # options: [always|never|change] default: always
|
||||
153
backend/vendor/github.com/Masterminds/sprig/CHANGELOG.md
generated
vendored
Normal file
153
backend/vendor/github.com/Masterminds/sprig/CHANGELOG.md
generated
vendored
Normal file
@@ -0,0 +1,153 @@
|
||||
# Changelog
|
||||
|
||||
## Release 2.15.0 (2018-04-02)
|
||||
|
||||
### Added
|
||||
|
||||
- #68 and #69: Add json helpers to docs (thanks @arunvelsriram)
|
||||
- #66: Add ternary function (thanks @binoculars)
|
||||
- #67: Allow keys function to take multiple dicts (thanks @binoculars)
|
||||
- #89: Added sha1sum to crypto function (thanks @benkeil)
|
||||
- #81: Allow customizing Root CA that used by genSignedCert (thanks @chenzhiwei)
|
||||
- #92: Add travis testing for go 1.10
|
||||
- #93: Adding appveyor config for windows testing
|
||||
|
||||
### Changed
|
||||
|
||||
- #90: Updating to more recent dependencies
|
||||
- #73: replace satori/go.uuid with google/uuid (thanks @petterw)
|
||||
|
||||
### Fixed
|
||||
|
||||
- #76: Fixed documentation typos (thanks @Thiht)
|
||||
- Fixed rounding issue on the `ago` function. Note, the removes support for Go 1.8 and older
|
||||
|
||||
## Release 2.14.1 (2017-12-01)
|
||||
|
||||
### Fixed
|
||||
|
||||
- #60: Fix typo in function name documentation (thanks @neil-ca-moore)
|
||||
- #61: Removing line with {{ due to blocking github pages genertion
|
||||
- #64: Update the list functions to handle int, string, and other slices for compatibility
|
||||
|
||||
## Release 2.14.0 (2017-10-06)
|
||||
|
||||
This new version of Sprig adds a set of functions for generating and working with SSL certificates.
|
||||
|
||||
- `genCA` generates an SSL Certificate Authority
|
||||
- `genSelfSignedCert` generates an SSL self-signed certificate
|
||||
- `genSignedCert` generates an SSL certificate and key based on a given CA
|
||||
|
||||
## Release 2.13.0 (2017-09-18)
|
||||
|
||||
This release adds new functions, including:
|
||||
|
||||
- `regexMatch`, `regexFindAll`, `regexFind`, `regexReplaceAll`, `regexReplaceAllLiteral`, and `regexSplit` to work with regular expressions
|
||||
- `floor`, `ceil`, and `round` math functions
|
||||
- `toDate` converts a string to a date
|
||||
- `nindent` is just like `indent` but also prepends a new line
|
||||
- `ago` returns the time from `time.Now`
|
||||
|
||||
### Added
|
||||
|
||||
- #40: Added basic regex functionality (thanks @alanquillin)
|
||||
- #41: Added ceil floor and round functions (thanks @alanquillin)
|
||||
- #48: Added toDate function (thanks @andreynering)
|
||||
- #50: Added nindent function (thanks @binoculars)
|
||||
- #46: Added ago function (thanks @slayer)
|
||||
|
||||
### Changed
|
||||
|
||||
- #51: Updated godocs to include new string functions (thanks @curtisallen)
|
||||
- #49: Added ability to merge multiple dicts (thanks @binoculars)
|
||||
|
||||
## Release 2.12.0 (2017-05-17)
|
||||
|
||||
- `snakecase`, `camelcase`, and `shuffle` are three new string functions
|
||||
- `fail` allows you to bail out of a template render when conditions are not met
|
||||
|
||||
## Release 2.11.0 (2017-05-02)
|
||||
|
||||
- Added `toJson` and `toPrettyJson`
|
||||
- Added `merge`
|
||||
- Refactored documentation
|
||||
|
||||
## Release 2.10.0 (2017-03-15)
|
||||
|
||||
- Added `semver` and `semverCompare` for Semantic Versions
|
||||
- `list` replaces `tuple`
|
||||
- Fixed issue with `join`
|
||||
- Added `first`, `last`, `intial`, `rest`, `prepend`, `append`, `toString`, `toStrings`, `sortAlpha`, `reverse`, `coalesce`, `pluck`, `pick`, `compact`, `keys`, `omit`, `uniq`, `has`, `without`
|
||||
|
||||
## Release 2.9.0 (2017-02-23)
|
||||
|
||||
- Added `splitList` to split a list
|
||||
- Added crypto functions of `genPrivateKey` and `derivePassword`
|
||||
|
||||
## Release 2.8.0 (2016-12-21)
|
||||
|
||||
- Added access to several path functions (`base`, `dir`, `clean`, `ext`, and `abs`)
|
||||
- Added functions for _mutating_ dictionaries (`set`, `unset`, `hasKey`)
|
||||
|
||||
## Release 2.7.0 (2016-12-01)
|
||||
|
||||
- Added `sha256sum` to generate a hash of an input
|
||||
- Added functions to convert a numeric or string to `int`, `int64`, `float64`
|
||||
|
||||
## Release 2.6.0 (2016-10-03)
|
||||
|
||||
- Added a `uuidv4` template function for generating UUIDs inside of a template.
|
||||
|
||||
## Release 2.5.0 (2016-08-19)
|
||||
|
||||
- New `trimSuffix`, `trimPrefix`, `hasSuffix`, and `hasPrefix` functions
|
||||
- New aliases have been added for a few functions that didn't follow the naming conventions (`trimAll` and `abbrevBoth`)
|
||||
- `trimall` and `abbrevboth` (notice the case) are deprecated and will be removed in 3.0.0
|
||||
|
||||
## Release 2.4.0 (2016-08-16)
|
||||
|
||||
- Adds two functions: `until` and `untilStep`
|
||||
|
||||
## Release 2.3.0 (2016-06-21)
|
||||
|
||||
- cat: Concatenate strings with whitespace separators.
|
||||
- replace: Replace parts of a string: `replace " " "-" "Me First"` renders "Me-First"
|
||||
- plural: Format plurals: `len "foo" | plural "one foo" "many foos"` renders "many foos"
|
||||
- indent: Indent blocks of text in a way that is sensitive to "\n" characters.
|
||||
|
||||
## Release 2.2.0 (2016-04-21)
|
||||
|
||||
- Added a `genPrivateKey` function (Thanks @bacongobbler)
|
||||
|
||||
## Release 2.1.0 (2016-03-30)
|
||||
|
||||
- `default` now prints the default value when it does not receive a value down the pipeline. It is much safer now to do `{{.Foo | default "bar"}}`.
|
||||
- Added accessors for "hermetic" functions. These return only functions that, when given the same input, produce the same output.
|
||||
|
||||
## Release 2.0.0 (2016-03-29)
|
||||
|
||||
Because we switched from `int` to `int64` as the return value for all integer math functions, the library's major version number has been incremented.
|
||||
|
||||
- `min` complements `max` (formerly `biggest`)
|
||||
- `empty` indicates that a value is the empty value for its type
|
||||
- `tuple` creates a tuple inside of a template: `{{$t := tuple "a", "b" "c"}}`
|
||||
- `dict` creates a dictionary inside of a template `{{$d := dict "key1" "val1" "key2" "val2"}}`
|
||||
- Date formatters have been added for HTML dates (as used in `date` input fields)
|
||||
- Integer math functions can convert from a number of types, including `string` (via `strconv.ParseInt`).
|
||||
|
||||
## Release 1.2.0 (2016-02-01)
|
||||
|
||||
- Added quote and squote
|
||||
- Added b32enc and b32dec
|
||||
- add now takes varargs
|
||||
- biggest now takes varargs
|
||||
|
||||
## Release 1.1.0 (2015-12-29)
|
||||
|
||||
- Added #4: Added contains function. strings.Contains, but with the arguments
|
||||
switched to simplify common pipelines. (thanks krancour)
|
||||
- Added Travis-CI testing support
|
||||
|
||||
## Release 1.0.0 (2015-12-23)
|
||||
|
||||
- Initial release
|
||||
20
backend/vendor/github.com/Masterminds/sprig/LICENSE.txt
generated
vendored
Normal file
20
backend/vendor/github.com/Masterminds/sprig/LICENSE.txt
generated
vendored
Normal file
@@ -0,0 +1,20 @@
|
||||
Sprig
|
||||
Copyright (C) 2013 Masterminds
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
13
backend/vendor/github.com/Masterminds/sprig/Makefile
generated
vendored
Normal file
13
backend/vendor/github.com/Masterminds/sprig/Makefile
generated
vendored
Normal file
@@ -0,0 +1,13 @@
|
||||
|
||||
HAS_GLIDE := $(shell command -v glide;)
|
||||
|
||||
.PHONY: test
|
||||
test:
|
||||
go test -v .
|
||||
|
||||
.PHONY: setup
|
||||
setup:
|
||||
ifndef HAS_GLIDE
|
||||
go get -u github.com/Masterminds/glide
|
||||
endif
|
||||
glide install
|
||||
81
backend/vendor/github.com/Masterminds/sprig/README.md
generated
vendored
Normal file
81
backend/vendor/github.com/Masterminds/sprig/README.md
generated
vendored
Normal file
@@ -0,0 +1,81 @@
|
||||
# Sprig: Template functions for Go templates
|
||||
[](https://masterminds.github.io/stability/sustained.html)
|
||||
[](https://travis-ci.org/Masterminds/sprig)
|
||||
|
||||
The Go language comes with a [built-in template
|
||||
language](http://golang.org/pkg/text/template/), but not
|
||||
very many template functions. This library provides a group of commonly
|
||||
used template functions.
|
||||
|
||||
It is inspired by the template functions found in
|
||||
[Twig](http://twig.sensiolabs.org/documentation) and also in various
|
||||
JavaScript libraries, such as [underscore.js](http://underscorejs.org/).
|
||||
|
||||
## Usage
|
||||
|
||||
Template developers can read the [Sprig function documentation](http://masterminds.github.io/sprig/) to
|
||||
learn about the >100 template functions available.
|
||||
|
||||
For Go developers wishing to include Sprig as a library in their programs,
|
||||
API documentation is available [at GoDoc.org](http://godoc.org/github.com/Masterminds/sprig), but
|
||||
read on for standard usage.
|
||||
|
||||
### Load the Sprig library
|
||||
|
||||
To load the Sprig `FuncMap`:
|
||||
|
||||
```go
|
||||
|
||||
import (
|
||||
"github.com/Masterminds/sprig"
|
||||
"html/template"
|
||||
)
|
||||
|
||||
// This example illustrates that the FuncMap *must* be set before the
|
||||
// templates themselves are loaded.
|
||||
tpl := template.Must(
|
||||
template.New("base").Funcs(sprig.FuncMap()).ParseGlob("*.html")
|
||||
)
|
||||
|
||||
|
||||
```
|
||||
|
||||
### Call the functions inside of templates
|
||||
|
||||
By convention, all functions are lowercase. This seems to follow the Go
|
||||
idiom for template functions (as opposed to template methods, which are
|
||||
TitleCase).
|
||||
|
||||
|
||||
Example:
|
||||
|
||||
```
|
||||
{{ "hello!" | upper | repeat 5 }}
|
||||
```
|
||||
|
||||
Produces:
|
||||
|
||||
```
|
||||
HELLO!HELLO!HELLO!HELLO!HELLO!
|
||||
```
|
||||
|
||||
## Principles:
|
||||
|
||||
The following principles were used in deciding on which functions to add, and
|
||||
determining how to implement them.
|
||||
|
||||
- Template functions should be used to build layout. Therefore, the following
|
||||
types of operations are within the domain of template functions:
|
||||
- Formatting
|
||||
- Layout
|
||||
- Simple type conversions
|
||||
- Utilities that assist in handling common formatting and layout needs (e.g. arithmetic)
|
||||
- Template functions should not return errors unless there is no way to print
|
||||
a sensible value. For example, converting a string to an integer should not
|
||||
produce an error if conversion fails. Instead, it should display a default
|
||||
value that can be displayed.
|
||||
- Simple math is necessary for grid layouts, pagers, and so on. Complex math
|
||||
(anything other than arithmetic) should be done outside of templates.
|
||||
- Template functions only deal with the data passed into them. They never retrieve
|
||||
data from a source.
|
||||
- Finally, do not override core Go template functions.
|
||||
26
backend/vendor/github.com/Masterminds/sprig/appveyor.yml
generated
vendored
Normal file
26
backend/vendor/github.com/Masterminds/sprig/appveyor.yml
generated
vendored
Normal file
@@ -0,0 +1,26 @@
|
||||
|
||||
version: build-{build}.{branch}
|
||||
|
||||
clone_folder: C:\gopath\src\github.com\Masterminds\sprig
|
||||
shallow_clone: true
|
||||
|
||||
environment:
|
||||
GOPATH: C:\gopath
|
||||
|
||||
platform:
|
||||
- x64
|
||||
|
||||
install:
|
||||
- go get -u github.com/Masterminds/glide
|
||||
- set PATH=%GOPATH%\bin;%PATH%
|
||||
- go version
|
||||
- go env
|
||||
|
||||
build_script:
|
||||
- glide install
|
||||
- go install ./...
|
||||
|
||||
test_script:
|
||||
- go test -v
|
||||
|
||||
deploy: off
|
||||
435
backend/vendor/github.com/Masterminds/sprig/crypto.go
generated
vendored
Normal file
435
backend/vendor/github.com/Masterminds/sprig/crypto.go
generated
vendored
Normal file
@@ -0,0 +1,435 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"crypto/dsa"
|
||||
"crypto/ecdsa"
|
||||
"crypto/elliptic"
|
||||
"crypto/hmac"
|
||||
"crypto/rand"
|
||||
"crypto/rsa"
|
||||
"crypto/sha1"
|
||||
"crypto/sha256"
|
||||
"crypto/x509"
|
||||
"crypto/x509/pkix"
|
||||
"encoding/asn1"
|
||||
"encoding/base64"
|
||||
"encoding/binary"
|
||||
"encoding/hex"
|
||||
"encoding/pem"
|
||||
"errors"
|
||||
"fmt"
|
||||
"math/big"
|
||||
"net"
|
||||
"time"
|
||||
|
||||
"github.com/google/uuid"
|
||||
"golang.org/x/crypto/scrypt"
|
||||
)
|
||||
|
||||
func sha256sum(input string) string {
|
||||
hash := sha256.Sum256([]byte(input))
|
||||
return hex.EncodeToString(hash[:])
|
||||
}
|
||||
|
||||
func sha1sum(input string) string {
|
||||
hash := sha1.Sum([]byte(input))
|
||||
return hex.EncodeToString(hash[:])
|
||||
}
|
||||
|
||||
// uuidv4 provides a safe and secure UUID v4 implementation
|
||||
func uuidv4() string {
|
||||
return fmt.Sprintf("%s", uuid.New())
|
||||
}
|
||||
|
||||
var master_password_seed = "com.lyndir.masterpassword"
|
||||
|
||||
var password_type_templates = map[string][][]byte{
|
||||
"maximum": {[]byte("anoxxxxxxxxxxxxxxxxx"), []byte("axxxxxxxxxxxxxxxxxno")},
|
||||
"long": {[]byte("CvcvnoCvcvCvcv"), []byte("CvcvCvcvnoCvcv"), []byte("CvcvCvcvCvcvno"), []byte("CvccnoCvcvCvcv"), []byte("CvccCvcvnoCvcv"),
|
||||
[]byte("CvccCvcvCvcvno"), []byte("CvcvnoCvccCvcv"), []byte("CvcvCvccnoCvcv"), []byte("CvcvCvccCvcvno"), []byte("CvcvnoCvcvCvcc"),
|
||||
[]byte("CvcvCvcvnoCvcc"), []byte("CvcvCvcvCvccno"), []byte("CvccnoCvccCvcv"), []byte("CvccCvccnoCvcv"), []byte("CvccCvccCvcvno"),
|
||||
[]byte("CvcvnoCvccCvcc"), []byte("CvcvCvccnoCvcc"), []byte("CvcvCvccCvccno"), []byte("CvccnoCvcvCvcc"), []byte("CvccCvcvnoCvcc"),
|
||||
[]byte("CvccCvcvCvccno")},
|
||||
"medium": {[]byte("CvcnoCvc"), []byte("CvcCvcno")},
|
||||
"short": {[]byte("Cvcn")},
|
||||
"basic": {[]byte("aaanaaan"), []byte("aannaaan"), []byte("aaannaaa")},
|
||||
"pin": {[]byte("nnnn")},
|
||||
}
|
||||
|
||||
var template_characters = map[byte]string{
|
||||
'V': "AEIOU",
|
||||
'C': "BCDFGHJKLMNPQRSTVWXYZ",
|
||||
'v': "aeiou",
|
||||
'c': "bcdfghjklmnpqrstvwxyz",
|
||||
'A': "AEIOUBCDFGHJKLMNPQRSTVWXYZ",
|
||||
'a': "AEIOUaeiouBCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz",
|
||||
'n': "0123456789",
|
||||
'o': "@&%?,=[]_:-+*$#!'^~;()/.",
|
||||
'x': "AEIOUaeiouBCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz0123456789!@#$%^&*()",
|
||||
}
|
||||
|
||||
func derivePassword(counter uint32, password_type, password, user, site string) string {
|
||||
var templates = password_type_templates[password_type]
|
||||
if templates == nil {
|
||||
return fmt.Sprintf("cannot find password template %s", password_type)
|
||||
}
|
||||
|
||||
var buffer bytes.Buffer
|
||||
buffer.WriteString(master_password_seed)
|
||||
binary.Write(&buffer, binary.BigEndian, uint32(len(user)))
|
||||
buffer.WriteString(user)
|
||||
|
||||
salt := buffer.Bytes()
|
||||
key, err := scrypt.Key([]byte(password), salt, 32768, 8, 2, 64)
|
||||
if err != nil {
|
||||
return fmt.Sprintf("failed to derive password: %s", err)
|
||||
}
|
||||
|
||||
buffer.Truncate(len(master_password_seed))
|
||||
binary.Write(&buffer, binary.BigEndian, uint32(len(site)))
|
||||
buffer.WriteString(site)
|
||||
binary.Write(&buffer, binary.BigEndian, counter)
|
||||
|
||||
var hmacv = hmac.New(sha256.New, key)
|
||||
hmacv.Write(buffer.Bytes())
|
||||
var seed = hmacv.Sum(nil)
|
||||
var temp = templates[int(seed[0])%len(templates)]
|
||||
|
||||
buffer.Truncate(0)
|
||||
for i, element := range temp {
|
||||
pass_chars := template_characters[element]
|
||||
pass_char := pass_chars[int(seed[i+1])%len(pass_chars)]
|
||||
buffer.WriteByte(pass_char)
|
||||
}
|
||||
|
||||
return buffer.String()
|
||||
}
|
||||
|
||||
func generatePrivateKey(typ string) string {
|
||||
var priv interface{}
|
||||
var err error
|
||||
switch typ {
|
||||
case "", "rsa":
|
||||
// good enough for government work
|
||||
priv, err = rsa.GenerateKey(rand.Reader, 4096)
|
||||
case "dsa":
|
||||
key := new(dsa.PrivateKey)
|
||||
// again, good enough for government work
|
||||
if err = dsa.GenerateParameters(&key.Parameters, rand.Reader, dsa.L2048N256); err != nil {
|
||||
return fmt.Sprintf("failed to generate dsa params: %s", err)
|
||||
}
|
||||
err = dsa.GenerateKey(key, rand.Reader)
|
||||
priv = key
|
||||
case "ecdsa":
|
||||
// again, good enough for government work
|
||||
priv, err = ecdsa.GenerateKey(elliptic.P256(), rand.Reader)
|
||||
default:
|
||||
return "Unknown type " + typ
|
||||
}
|
||||
if err != nil {
|
||||
return fmt.Sprintf("failed to generate private key: %s", err)
|
||||
}
|
||||
|
||||
return string(pem.EncodeToMemory(pemBlockForKey(priv)))
|
||||
}
|
||||
|
||||
type DSAKeyFormat struct {
|
||||
Version int
|
||||
P, Q, G, Y, X *big.Int
|
||||
}
|
||||
|
||||
func pemBlockForKey(priv interface{}) *pem.Block {
|
||||
switch k := priv.(type) {
|
||||
case *rsa.PrivateKey:
|
||||
return &pem.Block{Type: "RSA PRIVATE KEY", Bytes: x509.MarshalPKCS1PrivateKey(k)}
|
||||
case *dsa.PrivateKey:
|
||||
val := DSAKeyFormat{
|
||||
P: k.P, Q: k.Q, G: k.G,
|
||||
Y: k.Y, X: k.X,
|
||||
}
|
||||
bytes, _ := asn1.Marshal(val)
|
||||
return &pem.Block{Type: "DSA PRIVATE KEY", Bytes: bytes}
|
||||
case *ecdsa.PrivateKey:
|
||||
b, _ := x509.MarshalECPrivateKey(k)
|
||||
return &pem.Block{Type: "EC PRIVATE KEY", Bytes: b}
|
||||
default:
|
||||
return nil
|
||||
}
|
||||
}
|
||||
|
||||
type certificate struct {
|
||||
Cert string
|
||||
Key string
|
||||
}
|
||||
|
||||
func buildCustomCertificate(b64cert string, b64key string) (certificate, error) {
|
||||
crt := certificate{}
|
||||
|
||||
cert, err := base64.StdEncoding.DecodeString(b64cert)
|
||||
if err != nil {
|
||||
return crt, errors.New("unable to decode base64 certificate")
|
||||
}
|
||||
|
||||
key, err := base64.StdEncoding.DecodeString(b64key)
|
||||
if err != nil {
|
||||
return crt, errors.New("unable to decode base64 private key")
|
||||
}
|
||||
|
||||
decodedCert, _ := pem.Decode(cert)
|
||||
if decodedCert == nil {
|
||||
return crt, errors.New("unable to decode certificate")
|
||||
}
|
||||
_, err = x509.ParseCertificate(decodedCert.Bytes)
|
||||
if err != nil {
|
||||
return crt, fmt.Errorf(
|
||||
"error parsing certificate: decodedCert.Bytes: %s",
|
||||
err,
|
||||
)
|
||||
}
|
||||
|
||||
decodedKey, _ := pem.Decode(key)
|
||||
if decodedKey == nil {
|
||||
return crt, errors.New("unable to decode key")
|
||||
}
|
||||
_, err = x509.ParsePKCS1PrivateKey(decodedKey.Bytes)
|
||||
if err != nil {
|
||||
return crt, fmt.Errorf(
|
||||
"error parsing prive key: decodedKey.Bytes: %s",
|
||||
err,
|
||||
)
|
||||
}
|
||||
|
||||
crt.Cert = string(cert)
|
||||
crt.Key = string(key)
|
||||
|
||||
return crt, nil
|
||||
}
|
||||
|
||||
func generateCertificateAuthority(
|
||||
cn string,
|
||||
daysValid int,
|
||||
) (certificate, error) {
|
||||
ca := certificate{}
|
||||
|
||||
template, err := getBaseCertTemplate(cn, nil, nil, daysValid)
|
||||
if err != nil {
|
||||
return ca, err
|
||||
}
|
||||
// Override KeyUsage and IsCA
|
||||
template.KeyUsage = x509.KeyUsageKeyEncipherment |
|
||||
x509.KeyUsageDigitalSignature |
|
||||
x509.KeyUsageCertSign
|
||||
template.IsCA = true
|
||||
|
||||
priv, err := rsa.GenerateKey(rand.Reader, 2048)
|
||||
if err != nil {
|
||||
return ca, fmt.Errorf("error generating rsa key: %s", err)
|
||||
}
|
||||
|
||||
ca.Cert, ca.Key, err = getCertAndKey(template, priv, template, priv)
|
||||
if err != nil {
|
||||
return ca, err
|
||||
}
|
||||
|
||||
return ca, nil
|
||||
}
|
||||
|
||||
func generateSelfSignedCertificate(
|
||||
cn string,
|
||||
ips []interface{},
|
||||
alternateDNS []interface{},
|
||||
daysValid int,
|
||||
) (certificate, error) {
|
||||
cert := certificate{}
|
||||
|
||||
template, err := getBaseCertTemplate(cn, ips, alternateDNS, daysValid)
|
||||
if err != nil {
|
||||
return cert, err
|
||||
}
|
||||
|
||||
priv, err := rsa.GenerateKey(rand.Reader, 2048)
|
||||
if err != nil {
|
||||
return cert, fmt.Errorf("error generating rsa key: %s", err)
|
||||
}
|
||||
|
||||
cert.Cert, cert.Key, err = getCertAndKey(template, priv, template, priv)
|
||||
if err != nil {
|
||||
return cert, err
|
||||
}
|
||||
|
||||
return cert, nil
|
||||
}
|
||||
|
||||
func generateSignedCertificate(
|
||||
cn string,
|
||||
ips []interface{},
|
||||
alternateDNS []interface{},
|
||||
daysValid int,
|
||||
ca certificate,
|
||||
) (certificate, error) {
|
||||
cert := certificate{}
|
||||
|
||||
decodedSignerCert, _ := pem.Decode([]byte(ca.Cert))
|
||||
if decodedSignerCert == nil {
|
||||
return cert, errors.New("unable to decode certificate")
|
||||
}
|
||||
signerCert, err := x509.ParseCertificate(decodedSignerCert.Bytes)
|
||||
if err != nil {
|
||||
return cert, fmt.Errorf(
|
||||
"error parsing certificate: decodedSignerCert.Bytes: %s",
|
||||
err,
|
||||
)
|
||||
}
|
||||
decodedSignerKey, _ := pem.Decode([]byte(ca.Key))
|
||||
if decodedSignerKey == nil {
|
||||
return cert, errors.New("unable to decode key")
|
||||
}
|
||||
signerKey, err := x509.ParsePKCS1PrivateKey(decodedSignerKey.Bytes)
|
||||
if err != nil {
|
||||
return cert, fmt.Errorf(
|
||||
"error parsing prive key: decodedSignerKey.Bytes: %s",
|
||||
err,
|
||||
)
|
||||
}
|
||||
|
||||
template, err := getBaseCertTemplate(cn, ips, alternateDNS, daysValid)
|
||||
if err != nil {
|
||||
return cert, err
|
||||
}
|
||||
|
||||
priv, err := rsa.GenerateKey(rand.Reader, 2048)
|
||||
if err != nil {
|
||||
return cert, fmt.Errorf("error generating rsa key: %s", err)
|
||||
}
|
||||
|
||||
cert.Cert, cert.Key, err = getCertAndKey(
|
||||
template,
|
||||
priv,
|
||||
signerCert,
|
||||
signerKey,
|
||||
)
|
||||
if err != nil {
|
||||
return cert, err
|
||||
}
|
||||
|
||||
return cert, nil
|
||||
}
|
||||
|
||||
func getCertAndKey(
|
||||
template *x509.Certificate,
|
||||
signeeKey *rsa.PrivateKey,
|
||||
parent *x509.Certificate,
|
||||
signingKey *rsa.PrivateKey,
|
||||
) (string, string, error) {
|
||||
derBytes, err := x509.CreateCertificate(
|
||||
rand.Reader,
|
||||
template,
|
||||
parent,
|
||||
&signeeKey.PublicKey,
|
||||
signingKey,
|
||||
)
|
||||
if err != nil {
|
||||
return "", "", fmt.Errorf("error creating certificate: %s", err)
|
||||
}
|
||||
|
||||
certBuffer := bytes.Buffer{}
|
||||
if err := pem.Encode(
|
||||
&certBuffer,
|
||||
&pem.Block{Type: "CERTIFICATE", Bytes: derBytes},
|
||||
); err != nil {
|
||||
return "", "", fmt.Errorf("error pem-encoding certificate: %s", err)
|
||||
}
|
||||
|
||||
keyBuffer := bytes.Buffer{}
|
||||
if err := pem.Encode(
|
||||
&keyBuffer,
|
||||
&pem.Block{
|
||||
Type: "RSA PRIVATE KEY",
|
||||
Bytes: x509.MarshalPKCS1PrivateKey(signeeKey),
|
||||
},
|
||||
); err != nil {
|
||||
return "", "", fmt.Errorf("error pem-encoding key: %s", err)
|
||||
}
|
||||
|
||||
return string(certBuffer.Bytes()), string(keyBuffer.Bytes()), nil
|
||||
}
|
||||
|
||||
func getBaseCertTemplate(
|
||||
cn string,
|
||||
ips []interface{},
|
||||
alternateDNS []interface{},
|
||||
daysValid int,
|
||||
) (*x509.Certificate, error) {
|
||||
ipAddresses, err := getNetIPs(ips)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
dnsNames, err := getAlternateDNSStrs(alternateDNS)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
serialNumberUpperBound := new(big.Int).Lsh(big.NewInt(1), 128)
|
||||
serialNumber, err := rand.Int(rand.Reader, serialNumberUpperBound)
|
||||
if err != nil {
|
||||
return nil, err
|
||||
}
|
||||
return &x509.Certificate{
|
||||
SerialNumber: serialNumber,
|
||||
Subject: pkix.Name{
|
||||
CommonName: cn,
|
||||
},
|
||||
IPAddresses: ipAddresses,
|
||||
DNSNames: dnsNames,
|
||||
NotBefore: time.Now(),
|
||||
NotAfter: time.Now().Add(time.Hour * 24 * time.Duration(daysValid)),
|
||||
KeyUsage: x509.KeyUsageKeyEncipherment | x509.KeyUsageDigitalSignature,
|
||||
ExtKeyUsage: []x509.ExtKeyUsage{
|
||||
x509.ExtKeyUsageServerAuth,
|
||||
x509.ExtKeyUsageClientAuth,
|
||||
},
|
||||
BasicConstraintsValid: true,
|
||||
}, nil
|
||||
}
|
||||
|
||||
func getNetIPs(ips []interface{}) ([]net.IP, error) {
|
||||
if ips == nil {
|
||||
return []net.IP{}, nil
|
||||
}
|
||||
var ipStr string
|
||||
var ok bool
|
||||
var netIP net.IP
|
||||
netIPs := make([]net.IP, len(ips))
|
||||
for i, ip := range ips {
|
||||
ipStr, ok = ip.(string)
|
||||
if !ok {
|
||||
return nil, fmt.Errorf("error parsing ip: %v is not a string", ip)
|
||||
}
|
||||
netIP = net.ParseIP(ipStr)
|
||||
if netIP == nil {
|
||||
return nil, fmt.Errorf("error parsing ip: %s", ipStr)
|
||||
}
|
||||
netIPs[i] = netIP
|
||||
}
|
||||
return netIPs, nil
|
||||
}
|
||||
|
||||
func getAlternateDNSStrs(alternateDNS []interface{}) ([]string, error) {
|
||||
if alternateDNS == nil {
|
||||
return []string{}, nil
|
||||
}
|
||||
var dnsStr string
|
||||
var ok bool
|
||||
alternateDNSStrs := make([]string, len(alternateDNS))
|
||||
for i, dns := range alternateDNS {
|
||||
dnsStr, ok = dns.(string)
|
||||
if !ok {
|
||||
return nil, fmt.Errorf(
|
||||
"error processing alternate dns name: %v is not a string",
|
||||
dns,
|
||||
)
|
||||
}
|
||||
alternateDNSStrs[i] = dnsStr
|
||||
}
|
||||
return alternateDNSStrs, nil
|
||||
}
|
||||
76
backend/vendor/github.com/Masterminds/sprig/date.go
generated
vendored
Normal file
76
backend/vendor/github.com/Masterminds/sprig/date.go
generated
vendored
Normal file
@@ -0,0 +1,76 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"time"
|
||||
)
|
||||
|
||||
// Given a format and a date, format the date string.
|
||||
//
|
||||
// Date can be a `time.Time` or an `int, int32, int64`.
|
||||
// In the later case, it is treated as seconds since UNIX
|
||||
// epoch.
|
||||
func date(fmt string, date interface{}) string {
|
||||
return dateInZone(fmt, date, "Local")
|
||||
}
|
||||
|
||||
func htmlDate(date interface{}) string {
|
||||
return dateInZone("2006-01-02", date, "Local")
|
||||
}
|
||||
|
||||
func htmlDateInZone(date interface{}, zone string) string {
|
||||
return dateInZone("2006-01-02", date, zone)
|
||||
}
|
||||
|
||||
func dateInZone(fmt string, date interface{}, zone string) string {
|
||||
var t time.Time
|
||||
switch date := date.(type) {
|
||||
default:
|
||||
t = time.Now()
|
||||
case time.Time:
|
||||
t = date
|
||||
case int64:
|
||||
t = time.Unix(date, 0)
|
||||
case int:
|
||||
t = time.Unix(int64(date), 0)
|
||||
case int32:
|
||||
t = time.Unix(int64(date), 0)
|
||||
}
|
||||
|
||||
loc, err := time.LoadLocation(zone)
|
||||
if err != nil {
|
||||
loc, _ = time.LoadLocation("UTC")
|
||||
}
|
||||
|
||||
return t.In(loc).Format(fmt)
|
||||
}
|
||||
|
||||
func dateModify(fmt string, date time.Time) time.Time {
|
||||
d, err := time.ParseDuration(fmt)
|
||||
if err != nil {
|
||||
return date
|
||||
}
|
||||
return date.Add(d)
|
||||
}
|
||||
|
||||
func dateAgo(date interface{}) string {
|
||||
var t time.Time
|
||||
|
||||
switch date := date.(type) {
|
||||
default:
|
||||
t = time.Now()
|
||||
case time.Time:
|
||||
t = date
|
||||
case int64:
|
||||
t = time.Unix(date, 0)
|
||||
case int:
|
||||
t = time.Unix(int64(date), 0)
|
||||
}
|
||||
// Drop resolution to seconds
|
||||
duration := time.Since(t).Round(time.Second)
|
||||
return duration.String()
|
||||
}
|
||||
|
||||
func toDate(fmt, str string) time.Time {
|
||||
t, _ := time.ParseInLocation(fmt, str, time.Local)
|
||||
return t
|
||||
}
|
||||
83
backend/vendor/github.com/Masterminds/sprig/defaults.go
generated
vendored
Normal file
83
backend/vendor/github.com/Masterminds/sprig/defaults.go
generated
vendored
Normal file
@@ -0,0 +1,83 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"encoding/json"
|
||||
"reflect"
|
||||
)
|
||||
|
||||
// dfault checks whether `given` is set, and returns default if not set.
|
||||
//
|
||||
// This returns `d` if `given` appears not to be set, and `given` otherwise.
|
||||
//
|
||||
// For numeric types 0 is unset.
|
||||
// For strings, maps, arrays, and slices, len() = 0 is considered unset.
|
||||
// For bool, false is unset.
|
||||
// Structs are never considered unset.
|
||||
//
|
||||
// For everything else, including pointers, a nil value is unset.
|
||||
func dfault(d interface{}, given ...interface{}) interface{} {
|
||||
|
||||
if empty(given) || empty(given[0]) {
|
||||
return d
|
||||
}
|
||||
return given[0]
|
||||
}
|
||||
|
||||
// empty returns true if the given value has the zero value for its type.
|
||||
func empty(given interface{}) bool {
|
||||
g := reflect.ValueOf(given)
|
||||
if !g.IsValid() {
|
||||
return true
|
||||
}
|
||||
|
||||
// Basically adapted from text/template.isTrue
|
||||
switch g.Kind() {
|
||||
default:
|
||||
return g.IsNil()
|
||||
case reflect.Array, reflect.Slice, reflect.Map, reflect.String:
|
||||
return g.Len() == 0
|
||||
case reflect.Bool:
|
||||
return g.Bool() == false
|
||||
case reflect.Complex64, reflect.Complex128:
|
||||
return g.Complex() == 0
|
||||
case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
|
||||
return g.Int() == 0
|
||||
case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
|
||||
return g.Uint() == 0
|
||||
case reflect.Float32, reflect.Float64:
|
||||
return g.Float() == 0
|
||||
case reflect.Struct:
|
||||
return false
|
||||
}
|
||||
}
|
||||
|
||||
// coalesce returns the first non-empty value.
|
||||
func coalesce(v ...interface{}) interface{} {
|
||||
for _, val := range v {
|
||||
if !empty(val) {
|
||||
return val
|
||||
}
|
||||
}
|
||||
return nil
|
||||
}
|
||||
|
||||
// toJson encodes an item into a JSON string
|
||||
func toJson(v interface{}) string {
|
||||
output, _ := json.Marshal(v)
|
||||
return string(output)
|
||||
}
|
||||
|
||||
// toPrettyJson encodes an item into a pretty (indented) JSON string
|
||||
func toPrettyJson(v interface{}) string {
|
||||
output, _ := json.MarshalIndent(v, "", " ")
|
||||
return string(output)
|
||||
}
|
||||
|
||||
// ternary returns the first value if the last value is true, otherwise returns the second value.
|
||||
func ternary(vt interface{}, vf interface{}, v bool) interface{} {
|
||||
if v {
|
||||
return vt
|
||||
}
|
||||
|
||||
return vf
|
||||
}
|
||||
97
backend/vendor/github.com/Masterminds/sprig/dict.go
generated
vendored
Normal file
97
backend/vendor/github.com/Masterminds/sprig/dict.go
generated
vendored
Normal file
@@ -0,0 +1,97 @@
|
||||
package sprig
|
||||
|
||||
import "github.com/imdario/mergo"
|
||||
|
||||
func set(d map[string]interface{}, key string, value interface{}) map[string]interface{} {
|
||||
d[key] = value
|
||||
return d
|
||||
}
|
||||
|
||||
func unset(d map[string]interface{}, key string) map[string]interface{} {
|
||||
delete(d, key)
|
||||
return d
|
||||
}
|
||||
|
||||
func hasKey(d map[string]interface{}, key string) bool {
|
||||
_, ok := d[key]
|
||||
return ok
|
||||
}
|
||||
|
||||
func pluck(key string, d ...map[string]interface{}) []interface{} {
|
||||
res := []interface{}{}
|
||||
for _, dict := range d {
|
||||
if val, ok := dict[key]; ok {
|
||||
res = append(res, val)
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func keys(dicts ...map[string]interface{}) []string {
|
||||
k := []string{}
|
||||
for _, dict := range dicts {
|
||||
for key := range dict {
|
||||
k = append(k, key)
|
||||
}
|
||||
}
|
||||
return k
|
||||
}
|
||||
|
||||
func pick(dict map[string]interface{}, keys ...string) map[string]interface{} {
|
||||
res := map[string]interface{}{}
|
||||
for _, k := range keys {
|
||||
if v, ok := dict[k]; ok {
|
||||
res[k] = v
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func omit(dict map[string]interface{}, keys ...string) map[string]interface{} {
|
||||
res := map[string]interface{}{}
|
||||
|
||||
omit := make(map[string]bool, len(keys))
|
||||
for _, k := range keys {
|
||||
omit[k] = true
|
||||
}
|
||||
|
||||
for k, v := range dict {
|
||||
if _, ok := omit[k]; !ok {
|
||||
res[k] = v
|
||||
}
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func dict(v ...interface{}) map[string]interface{} {
|
||||
dict := map[string]interface{}{}
|
||||
lenv := len(v)
|
||||
for i := 0; i < lenv; i += 2 {
|
||||
key := strval(v[i])
|
||||
if i+1 >= lenv {
|
||||
dict[key] = ""
|
||||
continue
|
||||
}
|
||||
dict[key] = v[i+1]
|
||||
}
|
||||
return dict
|
||||
}
|
||||
|
||||
func merge(dst map[string]interface{}, srcs ...map[string]interface{}) interface{} {
|
||||
for _, src := range srcs {
|
||||
if err := mergo.Merge(&dst, src); err != nil {
|
||||
// Swallow errors inside of a template.
|
||||
return ""
|
||||
}
|
||||
}
|
||||
return dst
|
||||
}
|
||||
|
||||
func values(dict map[string]interface{}) []interface{} {
|
||||
values := []interface{}{}
|
||||
for _, value := range dict {
|
||||
values = append(values, value)
|
||||
}
|
||||
|
||||
return values
|
||||
}
|
||||
19
backend/vendor/github.com/Masterminds/sprig/doc.go
generated
vendored
Normal file
19
backend/vendor/github.com/Masterminds/sprig/doc.go
generated
vendored
Normal file
@@ -0,0 +1,19 @@
|
||||
/*
|
||||
Sprig: Template functions for Go.
|
||||
|
||||
This package contains a number of utility functions for working with data
|
||||
inside of Go `html/template` and `text/template` files.
|
||||
|
||||
To add these functions, use the `template.Funcs()` method:
|
||||
|
||||
t := templates.New("foo").Funcs(sprig.FuncMap())
|
||||
|
||||
Note that you should add the function map before you parse any template files.
|
||||
|
||||
In several cases, Sprig reverses the order of arguments from the way they
|
||||
appear in the standard library. This is to make it easier to pipe
|
||||
arguments into functions.
|
||||
|
||||
See http://masterminds.github.io/sprig/ for more detailed documentation on each of the available functions.
|
||||
*/
|
||||
package sprig
|
||||
285
backend/vendor/github.com/Masterminds/sprig/functions.go
generated
vendored
Normal file
285
backend/vendor/github.com/Masterminds/sprig/functions.go
generated
vendored
Normal file
@@ -0,0 +1,285 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"errors"
|
||||
"html/template"
|
||||
"os"
|
||||
"path"
|
||||
"strconv"
|
||||
"strings"
|
||||
ttemplate "text/template"
|
||||
"time"
|
||||
|
||||
util "github.com/aokoli/goutils"
|
||||
"github.com/huandu/xstrings"
|
||||
)
|
||||
|
||||
// Produce the function map.
|
||||
//
|
||||
// Use this to pass the functions into the template engine:
|
||||
//
|
||||
// tpl := template.New("foo").Funcs(sprig.FuncMap()))
|
||||
//
|
||||
func FuncMap() template.FuncMap {
|
||||
return HtmlFuncMap()
|
||||
}
|
||||
|
||||
// HermeticTextFuncMap returns a 'text/template'.FuncMap with only repeatable functions.
|
||||
func HermeticTxtFuncMap() ttemplate.FuncMap {
|
||||
r := TxtFuncMap()
|
||||
for _, name := range nonhermeticFunctions {
|
||||
delete(r, name)
|
||||
}
|
||||
return r
|
||||
}
|
||||
|
||||
// HermeticHtmlFuncMap returns an 'html/template'.Funcmap with only repeatable functions.
|
||||
func HermeticHtmlFuncMap() template.FuncMap {
|
||||
r := HtmlFuncMap()
|
||||
for _, name := range nonhermeticFunctions {
|
||||
delete(r, name)
|
||||
}
|
||||
return r
|
||||
}
|
||||
|
||||
// TextFuncMap returns a 'text/template'.FuncMap
|
||||
func TxtFuncMap() ttemplate.FuncMap {
|
||||
return ttemplate.FuncMap(GenericFuncMap())
|
||||
}
|
||||
|
||||
// HtmlFuncMap returns an 'html/template'.Funcmap
|
||||
func HtmlFuncMap() template.FuncMap {
|
||||
return template.FuncMap(GenericFuncMap())
|
||||
}
|
||||
|
||||
// GenericFuncMap returns a copy of the basic function map as a map[string]interface{}.
|
||||
func GenericFuncMap() map[string]interface{} {
|
||||
gfm := make(map[string]interface{}, len(genericMap))
|
||||
for k, v := range genericMap {
|
||||
gfm[k] = v
|
||||
}
|
||||
return gfm
|
||||
}
|
||||
|
||||
// These functions are not guaranteed to evaluate to the same result for given input, because they
|
||||
// refer to the environemnt or global state.
|
||||
var nonhermeticFunctions = []string{
|
||||
// Date functions
|
||||
"date",
|
||||
"date_in_zone",
|
||||
"date_modify",
|
||||
"now",
|
||||
"htmlDate",
|
||||
"htmlDateInZone",
|
||||
"dateInZone",
|
||||
"dateModify",
|
||||
|
||||
// Strings
|
||||
"randAlphaNum",
|
||||
"randAlpha",
|
||||
"randAscii",
|
||||
"randNumeric",
|
||||
"uuidv4",
|
||||
|
||||
// OS
|
||||
"env",
|
||||
"expandenv",
|
||||
}
|
||||
|
||||
var genericMap = map[string]interface{}{
|
||||
"hello": func() string { return "Hello!" },
|
||||
|
||||
// Date functions
|
||||
"date": date,
|
||||
"date_in_zone": dateInZone,
|
||||
"date_modify": dateModify,
|
||||
"now": func() time.Time { return time.Now() },
|
||||
"htmlDate": htmlDate,
|
||||
"htmlDateInZone": htmlDateInZone,
|
||||
"dateInZone": dateInZone,
|
||||
"dateModify": dateModify,
|
||||
"ago": dateAgo,
|
||||
"toDate": toDate,
|
||||
|
||||
// Strings
|
||||
"abbrev": abbrev,
|
||||
"abbrevboth": abbrevboth,
|
||||
"trunc": trunc,
|
||||
"trim": strings.TrimSpace,
|
||||
"upper": strings.ToUpper,
|
||||
"lower": strings.ToLower,
|
||||
"title": strings.Title,
|
||||
"untitle": untitle,
|
||||
"substr": substring,
|
||||
// Switch order so that "foo" | repeat 5
|
||||
"repeat": func(count int, str string) string { return strings.Repeat(str, count) },
|
||||
// Deprecated: Use trimAll.
|
||||
"trimall": func(a, b string) string { return strings.Trim(b, a) },
|
||||
// Switch order so that "$foo" | trimall "$"
|
||||
"trimAll": func(a, b string) string { return strings.Trim(b, a) },
|
||||
"trimSuffix": func(a, b string) string { return strings.TrimSuffix(b, a) },
|
||||
"trimPrefix": func(a, b string) string { return strings.TrimPrefix(b, a) },
|
||||
"nospace": util.DeleteWhiteSpace,
|
||||
"initials": initials,
|
||||
"randAlphaNum": randAlphaNumeric,
|
||||
"randAlpha": randAlpha,
|
||||
"randAscii": randAscii,
|
||||
"randNumeric": randNumeric,
|
||||
"swapcase": util.SwapCase,
|
||||
"shuffle": xstrings.Shuffle,
|
||||
"snakecase": xstrings.ToSnakeCase,
|
||||
"camelcase": xstrings.ToCamelCase,
|
||||
"wrap": func(l int, s string) string { return util.Wrap(s, l) },
|
||||
"wrapWith": func(l int, sep, str string) string { return util.WrapCustom(str, l, sep, true) },
|
||||
// Switch order so that "foobar" | contains "foo"
|
||||
"contains": func(substr string, str string) bool { return strings.Contains(str, substr) },
|
||||
"hasPrefix": func(substr string, str string) bool { return strings.HasPrefix(str, substr) },
|
||||
"hasSuffix": func(substr string, str string) bool { return strings.HasSuffix(str, substr) },
|
||||
"quote": quote,
|
||||
"squote": squote,
|
||||
"cat": cat,
|
||||
"indent": indent,
|
||||
"nindent": nindent,
|
||||
"replace": replace,
|
||||
"plural": plural,
|
||||
"sha1sum": sha1sum,
|
||||
"sha256sum": sha256sum,
|
||||
"toString": strval,
|
||||
|
||||
// Wrap Atoi to stop errors.
|
||||
"atoi": func(a string) int { i, _ := strconv.Atoi(a); return i },
|
||||
"int64": toInt64,
|
||||
"int": toInt,
|
||||
"float64": toFloat64,
|
||||
|
||||
//"gt": func(a, b int) bool {return a > b},
|
||||
//"gte": func(a, b int) bool {return a >= b},
|
||||
//"lt": func(a, b int) bool {return a < b},
|
||||
//"lte": func(a, b int) bool {return a <= b},
|
||||
|
||||
// split "/" foo/bar returns map[int]string{0: foo, 1: bar}
|
||||
"split": split,
|
||||
"splitList": func(sep, orig string) []string { return strings.Split(orig, sep) },
|
||||
// splitn "/" foo/bar/fuu returns map[int]string{0: foo, 1: bar/fuu}
|
||||
"splitn": splitn,
|
||||
"toStrings": strslice,
|
||||
|
||||
"until": until,
|
||||
"untilStep": untilStep,
|
||||
|
||||
// VERY basic arithmetic.
|
||||
"add1": func(i interface{}) int64 { return toInt64(i) + 1 },
|
||||
"add": func(i ...interface{}) int64 {
|
||||
var a int64 = 0
|
||||
for _, b := range i {
|
||||
a += toInt64(b)
|
||||
}
|
||||
return a
|
||||
},
|
||||
"sub": func(a, b interface{}) int64 { return toInt64(a) - toInt64(b) },
|
||||
"div": func(a, b interface{}) int64 { return toInt64(a) / toInt64(b) },
|
||||
"mod": func(a, b interface{}) int64 { return toInt64(a) % toInt64(b) },
|
||||
"mul": func(a interface{}, v ...interface{}) int64 {
|
||||
val := toInt64(a)
|
||||
for _, b := range v {
|
||||
val = val * toInt64(b)
|
||||
}
|
||||
return val
|
||||
},
|
||||
"biggest": max,
|
||||
"max": max,
|
||||
"min": min,
|
||||
"ceil": ceil,
|
||||
"floor": floor,
|
||||
"round": round,
|
||||
|
||||
// string slices. Note that we reverse the order b/c that's better
|
||||
// for template processing.
|
||||
"join": join,
|
||||
"sortAlpha": sortAlpha,
|
||||
|
||||
// Defaults
|
||||
"default": dfault,
|
||||
"empty": empty,
|
||||
"coalesce": coalesce,
|
||||
"compact": compact,
|
||||
"toJson": toJson,
|
||||
"toPrettyJson": toPrettyJson,
|
||||
"ternary": ternary,
|
||||
|
||||
// Reflection
|
||||
"typeOf": typeOf,
|
||||
"typeIs": typeIs,
|
||||
"typeIsLike": typeIsLike,
|
||||
"kindOf": kindOf,
|
||||
"kindIs": kindIs,
|
||||
|
||||
// OS:
|
||||
"env": func(s string) string { return os.Getenv(s) },
|
||||
"expandenv": func(s string) string { return os.ExpandEnv(s) },
|
||||
|
||||
// File Paths:
|
||||
"base": path.Base,
|
||||
"dir": path.Dir,
|
||||
"clean": path.Clean,
|
||||
"ext": path.Ext,
|
||||
"isAbs": path.IsAbs,
|
||||
|
||||
// Encoding:
|
||||
"b64enc": base64encode,
|
||||
"b64dec": base64decode,
|
||||
"b32enc": base32encode,
|
||||
"b32dec": base32decode,
|
||||
|
||||
// Data Structures:
|
||||
"tuple": list, // FIXME: with the addition of append/prepend these are no longer immutable.
|
||||
"list": list,
|
||||
"dict": dict,
|
||||
"set": set,
|
||||
"unset": unset,
|
||||
"hasKey": hasKey,
|
||||
"pluck": pluck,
|
||||
"keys": keys,
|
||||
"pick": pick,
|
||||
"omit": omit,
|
||||
"merge": merge,
|
||||
"values": values,
|
||||
|
||||
"append": push, "push": push,
|
||||
"prepend": prepend,
|
||||
"first": first,
|
||||
"rest": rest,
|
||||
"last": last,
|
||||
"initial": initial,
|
||||
"reverse": reverse,
|
||||
"uniq": uniq,
|
||||
"without": without,
|
||||
"has": has,
|
||||
"slice": slice,
|
||||
|
||||
// Crypto:
|
||||
"genPrivateKey": generatePrivateKey,
|
||||
"derivePassword": derivePassword,
|
||||
"buildCustomCert": buildCustomCertificate,
|
||||
"genCA": generateCertificateAuthority,
|
||||
"genSelfSignedCert": generateSelfSignedCertificate,
|
||||
"genSignedCert": generateSignedCertificate,
|
||||
|
||||
// UUIDs:
|
||||
"uuidv4": uuidv4,
|
||||
|
||||
// SemVer:
|
||||
"semver": semver,
|
||||
"semverCompare": semverCompare,
|
||||
|
||||
// Flow Control:
|
||||
"fail": func(msg string) (string, error) { return "", errors.New(msg) },
|
||||
|
||||
// Regex
|
||||
"regexMatch": regexMatch,
|
||||
"regexFindAll": regexFindAll,
|
||||
"regexFind": regexFind,
|
||||
"regexReplaceAll": regexReplaceAll,
|
||||
"regexReplaceAllLiteral": regexReplaceAllLiteral,
|
||||
"regexSplit": regexSplit,
|
||||
}
|
||||
15
backend/vendor/github.com/Masterminds/sprig/glide.yaml
generated
vendored
Normal file
15
backend/vendor/github.com/Masterminds/sprig/glide.yaml
generated
vendored
Normal file
@@ -0,0 +1,15 @@
|
||||
package: github.com/Masterminds/sprig
|
||||
import:
|
||||
- package: github.com/Masterminds/goutils
|
||||
version: ^1.0.0
|
||||
- package: github.com/google/uuid
|
||||
version: ^0.2
|
||||
- package: golang.org/x/crypto
|
||||
subpackages:
|
||||
- scrypt
|
||||
- package: github.com/Masterminds/semver
|
||||
version: v1.2.2
|
||||
- package: github.com/stretchr/testify
|
||||
- package: github.com/imdario/mergo
|
||||
version: ~0.2.2
|
||||
- package: github.com/huandu/xstrings
|
||||
291
backend/vendor/github.com/Masterminds/sprig/list.go
generated
vendored
Normal file
291
backend/vendor/github.com/Masterminds/sprig/list.go
generated
vendored
Normal file
@@ -0,0 +1,291 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"reflect"
|
||||
"sort"
|
||||
)
|
||||
|
||||
// Reflection is used in these functions so that slices and arrays of strings,
|
||||
// ints, and other types not implementing []interface{} can be worked with.
|
||||
// For example, this is useful if you need to work on the output of regexs.
|
||||
|
||||
func list(v ...interface{}) []interface{} {
|
||||
return v
|
||||
}
|
||||
|
||||
func push(list interface{}, v interface{}) []interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
nl := make([]interface{}, l)
|
||||
for i := 0; i < l; i++ {
|
||||
nl[i] = l2.Index(i).Interface()
|
||||
}
|
||||
|
||||
return append(nl, v)
|
||||
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot push on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func prepend(list interface{}, v interface{}) []interface{} {
|
||||
//return append([]interface{}{v}, list...)
|
||||
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
nl := make([]interface{}, l)
|
||||
for i := 0; i < l; i++ {
|
||||
nl[i] = l2.Index(i).Interface()
|
||||
}
|
||||
|
||||
return append([]interface{}{v}, nl...)
|
||||
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot prepend on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func last(list interface{}) interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
if l == 0 {
|
||||
return nil
|
||||
}
|
||||
|
||||
return l2.Index(l - 1).Interface()
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot find last on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func first(list interface{}) interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
if l == 0 {
|
||||
return nil
|
||||
}
|
||||
|
||||
return l2.Index(0).Interface()
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot find first on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func rest(list interface{}) []interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
if l == 0 {
|
||||
return nil
|
||||
}
|
||||
|
||||
nl := make([]interface{}, l-1)
|
||||
for i := 1; i < l; i++ {
|
||||
nl[i-1] = l2.Index(i).Interface()
|
||||
}
|
||||
|
||||
return nl
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot find rest on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func initial(list interface{}) []interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
if l == 0 {
|
||||
return nil
|
||||
}
|
||||
|
||||
nl := make([]interface{}, l-1)
|
||||
for i := 0; i < l-1; i++ {
|
||||
nl[i] = l2.Index(i).Interface()
|
||||
}
|
||||
|
||||
return nl
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot find initial on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func sortAlpha(list interface{}) []string {
|
||||
k := reflect.Indirect(reflect.ValueOf(list)).Kind()
|
||||
switch k {
|
||||
case reflect.Slice, reflect.Array:
|
||||
a := strslice(list)
|
||||
s := sort.StringSlice(a)
|
||||
s.Sort()
|
||||
return s
|
||||
}
|
||||
return []string{strval(list)}
|
||||
}
|
||||
|
||||
func reverse(v interface{}) []interface{} {
|
||||
tp := reflect.TypeOf(v).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(v)
|
||||
|
||||
l := l2.Len()
|
||||
// We do not sort in place because the incoming array should not be altered.
|
||||
nl := make([]interface{}, l)
|
||||
for i := 0; i < l; i++ {
|
||||
nl[l-i-1] = l2.Index(i).Interface()
|
||||
}
|
||||
|
||||
return nl
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot find reverse on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func compact(list interface{}) []interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
nl := []interface{}{}
|
||||
var item interface{}
|
||||
for i := 0; i < l; i++ {
|
||||
item = l2.Index(i).Interface()
|
||||
if !empty(item) {
|
||||
nl = append(nl, item)
|
||||
}
|
||||
}
|
||||
|
||||
return nl
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot compact on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func uniq(list interface{}) []interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
dest := []interface{}{}
|
||||
var item interface{}
|
||||
for i := 0; i < l; i++ {
|
||||
item = l2.Index(i).Interface()
|
||||
if !inList(dest, item) {
|
||||
dest = append(dest, item)
|
||||
}
|
||||
}
|
||||
|
||||
return dest
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot find uniq on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func inList(haystack []interface{}, needle interface{}) bool {
|
||||
for _, h := range haystack {
|
||||
if reflect.DeepEqual(needle, h) {
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
func without(list interface{}, omit ...interface{}) []interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
res := []interface{}{}
|
||||
var item interface{}
|
||||
for i := 0; i < l; i++ {
|
||||
item = l2.Index(i).Interface()
|
||||
if !inList(omit, item) {
|
||||
res = append(res, item)
|
||||
}
|
||||
}
|
||||
|
||||
return res
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot find without on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
func has(needle interface{}, haystack interface{}) bool {
|
||||
tp := reflect.TypeOf(haystack).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(haystack)
|
||||
var item interface{}
|
||||
l := l2.Len()
|
||||
for i := 0; i < l; i++ {
|
||||
item = l2.Index(i).Interface()
|
||||
if reflect.DeepEqual(needle, item) {
|
||||
return true
|
||||
}
|
||||
}
|
||||
|
||||
return false
|
||||
default:
|
||||
panic(fmt.Sprintf("Cannot find has on type %s", tp))
|
||||
}
|
||||
}
|
||||
|
||||
// $list := [1, 2, 3, 4, 5]
|
||||
// slice $list -> list[0:5] = list[:]
|
||||
// slice $list 0 3 -> list[0:3] = list[:3]
|
||||
// slice $list 3 5 -> list[3:5]
|
||||
// slice $list 3 -> list[3:5] = list[3:]
|
||||
func slice(list interface{}, indices ...interface{}) interface{} {
|
||||
tp := reflect.TypeOf(list).Kind()
|
||||
switch tp {
|
||||
case reflect.Slice, reflect.Array:
|
||||
l2 := reflect.ValueOf(list)
|
||||
|
||||
l := l2.Len()
|
||||
if l == 0 {
|
||||
return nil
|
||||
}
|
||||
|
||||
var start, end int
|
||||
if len(indices) > 0 {
|
||||
start = toInt(indices[0])
|
||||
}
|
||||
if len(indices) < 2 {
|
||||
end = l
|
||||
} else {
|
||||
end = toInt(indices[1])
|
||||
}
|
||||
|
||||
return l2.Slice(start, end).Interface()
|
||||
default:
|
||||
panic(fmt.Sprintf("list should be type of slice or array but %s", tp))
|
||||
}
|
||||
}
|
||||
159
backend/vendor/github.com/Masterminds/sprig/numeric.go
generated
vendored
Normal file
159
backend/vendor/github.com/Masterminds/sprig/numeric.go
generated
vendored
Normal file
@@ -0,0 +1,159 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"math"
|
||||
"reflect"
|
||||
"strconv"
|
||||
)
|
||||
|
||||
// toFloat64 converts 64-bit floats
|
||||
func toFloat64(v interface{}) float64 {
|
||||
if str, ok := v.(string); ok {
|
||||
iv, err := strconv.ParseFloat(str, 64)
|
||||
if err != nil {
|
||||
return 0
|
||||
}
|
||||
return iv
|
||||
}
|
||||
|
||||
val := reflect.Indirect(reflect.ValueOf(v))
|
||||
switch val.Kind() {
|
||||
case reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64, reflect.Int:
|
||||
return float64(val.Int())
|
||||
case reflect.Uint8, reflect.Uint16, reflect.Uint32:
|
||||
return float64(val.Uint())
|
||||
case reflect.Uint, reflect.Uint64:
|
||||
return float64(val.Uint())
|
||||
case reflect.Float32, reflect.Float64:
|
||||
return val.Float()
|
||||
case reflect.Bool:
|
||||
if val.Bool() == true {
|
||||
return 1
|
||||
}
|
||||
return 0
|
||||
default:
|
||||
return 0
|
||||
}
|
||||
}
|
||||
|
||||
func toInt(v interface{}) int {
|
||||
//It's not optimal. Bud I don't want duplicate toInt64 code.
|
||||
return int(toInt64(v))
|
||||
}
|
||||
|
||||
// toInt64 converts integer types to 64-bit integers
|
||||
func toInt64(v interface{}) int64 {
|
||||
if str, ok := v.(string); ok {
|
||||
iv, err := strconv.ParseInt(str, 10, 64)
|
||||
if err != nil {
|
||||
return 0
|
||||
}
|
||||
return iv
|
||||
}
|
||||
|
||||
val := reflect.Indirect(reflect.ValueOf(v))
|
||||
switch val.Kind() {
|
||||
case reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64, reflect.Int:
|
||||
return val.Int()
|
||||
case reflect.Uint8, reflect.Uint16, reflect.Uint32:
|
||||
return int64(val.Uint())
|
||||
case reflect.Uint, reflect.Uint64:
|
||||
tv := val.Uint()
|
||||
if tv <= math.MaxInt64 {
|
||||
return int64(tv)
|
||||
}
|
||||
// TODO: What is the sensible thing to do here?
|
||||
return math.MaxInt64
|
||||
case reflect.Float32, reflect.Float64:
|
||||
return int64(val.Float())
|
||||
case reflect.Bool:
|
||||
if val.Bool() == true {
|
||||
return 1
|
||||
}
|
||||
return 0
|
||||
default:
|
||||
return 0
|
||||
}
|
||||
}
|
||||
|
||||
func max(a interface{}, i ...interface{}) int64 {
|
||||
aa := toInt64(a)
|
||||
for _, b := range i {
|
||||
bb := toInt64(b)
|
||||
if bb > aa {
|
||||
aa = bb
|
||||
}
|
||||
}
|
||||
return aa
|
||||
}
|
||||
|
||||
func min(a interface{}, i ...interface{}) int64 {
|
||||
aa := toInt64(a)
|
||||
for _, b := range i {
|
||||
bb := toInt64(b)
|
||||
if bb < aa {
|
||||
aa = bb
|
||||
}
|
||||
}
|
||||
return aa
|
||||
}
|
||||
|
||||
func until(count int) []int {
|
||||
step := 1
|
||||
if count < 0 {
|
||||
step = -1
|
||||
}
|
||||
return untilStep(0, count, step)
|
||||
}
|
||||
|
||||
func untilStep(start, stop, step int) []int {
|
||||
v := []int{}
|
||||
|
||||
if stop < start {
|
||||
if step >= 0 {
|
||||
return v
|
||||
}
|
||||
for i := start; i > stop; i += step {
|
||||
v = append(v, i)
|
||||
}
|
||||
return v
|
||||
}
|
||||
|
||||
if step <= 0 {
|
||||
return v
|
||||
}
|
||||
for i := start; i < stop; i += step {
|
||||
v = append(v, i)
|
||||
}
|
||||
return v
|
||||
}
|
||||
|
||||
func floor(a interface{}) float64 {
|
||||
aa := toFloat64(a)
|
||||
return math.Floor(aa)
|
||||
}
|
||||
|
||||
func ceil(a interface{}) float64 {
|
||||
aa := toFloat64(a)
|
||||
return math.Ceil(aa)
|
||||
}
|
||||
|
||||
func round(a interface{}, p int, r_opt ...float64) float64 {
|
||||
roundOn := .5
|
||||
if len(r_opt) > 0 {
|
||||
roundOn = r_opt[0]
|
||||
}
|
||||
val := toFloat64(a)
|
||||
places := toFloat64(p)
|
||||
|
||||
var round float64
|
||||
pow := math.Pow(10, places)
|
||||
digit := pow * val
|
||||
_, div := math.Modf(digit)
|
||||
if div >= roundOn {
|
||||
round = math.Ceil(digit)
|
||||
} else {
|
||||
round = math.Floor(digit)
|
||||
}
|
||||
return round / pow
|
||||
}
|
||||
28
backend/vendor/github.com/Masterminds/sprig/reflect.go
generated
vendored
Normal file
28
backend/vendor/github.com/Masterminds/sprig/reflect.go
generated
vendored
Normal file
@@ -0,0 +1,28 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"reflect"
|
||||
)
|
||||
|
||||
// typeIs returns true if the src is the type named in target.
|
||||
func typeIs(target string, src interface{}) bool {
|
||||
return target == typeOf(src)
|
||||
}
|
||||
|
||||
func typeIsLike(target string, src interface{}) bool {
|
||||
t := typeOf(src)
|
||||
return target == t || "*"+target == t
|
||||
}
|
||||
|
||||
func typeOf(src interface{}) string {
|
||||
return fmt.Sprintf("%T", src)
|
||||
}
|
||||
|
||||
func kindIs(target string, src interface{}) bool {
|
||||
return target == kindOf(src)
|
||||
}
|
||||
|
||||
func kindOf(src interface{}) string {
|
||||
return reflect.ValueOf(src).Kind().String()
|
||||
}
|
||||
35
backend/vendor/github.com/Masterminds/sprig/regex.go
generated
vendored
Normal file
35
backend/vendor/github.com/Masterminds/sprig/regex.go
generated
vendored
Normal file
@@ -0,0 +1,35 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"regexp"
|
||||
)
|
||||
|
||||
func regexMatch(regex string, s string) bool {
|
||||
match, _ := regexp.MatchString(regex, s)
|
||||
return match
|
||||
}
|
||||
|
||||
func regexFindAll(regex string, s string, n int) []string {
|
||||
r := regexp.MustCompile(regex)
|
||||
return r.FindAllString(s, n)
|
||||
}
|
||||
|
||||
func regexFind(regex string, s string) string {
|
||||
r := regexp.MustCompile(regex)
|
||||
return r.FindString(s)
|
||||
}
|
||||
|
||||
func regexReplaceAll(regex string, s string, repl string) string {
|
||||
r := regexp.MustCompile(regex)
|
||||
return r.ReplaceAllString(s, repl)
|
||||
}
|
||||
|
||||
func regexReplaceAllLiteral(regex string, s string, repl string) string {
|
||||
r := regexp.MustCompile(regex)
|
||||
return r.ReplaceAllLiteralString(s, repl)
|
||||
}
|
||||
|
||||
func regexSplit(regex string, s string, n int) []string {
|
||||
r := regexp.MustCompile(regex)
|
||||
return r.Split(s, n)
|
||||
}
|
||||
23
backend/vendor/github.com/Masterminds/sprig/semver.go
generated
vendored
Normal file
23
backend/vendor/github.com/Masterminds/sprig/semver.go
generated
vendored
Normal file
@@ -0,0 +1,23 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
sv2 "github.com/Masterminds/semver"
|
||||
)
|
||||
|
||||
func semverCompare(constraint, version string) (bool, error) {
|
||||
c, err := sv2.NewConstraint(constraint)
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
|
||||
v, err := sv2.NewVersion(version)
|
||||
if err != nil {
|
||||
return false, err
|
||||
}
|
||||
|
||||
return c.Check(v), nil
|
||||
}
|
||||
|
||||
func semver(version string) (*sv2.Version, error) {
|
||||
return sv2.NewVersion(version)
|
||||
}
|
||||
210
backend/vendor/github.com/Masterminds/sprig/strings.go
generated
vendored
Normal file
210
backend/vendor/github.com/Masterminds/sprig/strings.go
generated
vendored
Normal file
@@ -0,0 +1,210 @@
|
||||
package sprig
|
||||
|
||||
import (
|
||||
"encoding/base32"
|
||||
"encoding/base64"
|
||||
"fmt"
|
||||
"reflect"
|
||||
"strconv"
|
||||
"strings"
|
||||
|
||||
util "github.com/aokoli/goutils"
|
||||
)
|
||||
|
||||
func base64encode(v string) string {
|
||||
return base64.StdEncoding.EncodeToString([]byte(v))
|
||||
}
|
||||
|
||||
func base64decode(v string) string {
|
||||
data, err := base64.StdEncoding.DecodeString(v)
|
||||
if err != nil {
|
||||
return err.Error()
|
||||
}
|
||||
return string(data)
|
||||
}
|
||||
|
||||
func base32encode(v string) string {
|
||||
return base32.StdEncoding.EncodeToString([]byte(v))
|
||||
}
|
||||
|
||||
func base32decode(v string) string {
|
||||
data, err := base32.StdEncoding.DecodeString(v)
|
||||
if err != nil {
|
||||
return err.Error()
|
||||
}
|
||||
return string(data)
|
||||
}
|
||||
|
||||
func abbrev(width int, s string) string {
|
||||
if width < 4 {
|
||||
return s
|
||||
}
|
||||
r, _ := util.Abbreviate(s, width)
|
||||
return r
|
||||
}
|
||||
|
||||
func abbrevboth(left, right int, s string) string {
|
||||
if right < 4 || left > 0 && right < 7 {
|
||||
return s
|
||||
}
|
||||
r, _ := util.AbbreviateFull(s, left, right)
|
||||
return r
|
||||
}
|
||||
func initials(s string) string {
|
||||
// Wrap this just to eliminate the var args, which templates don't do well.
|
||||
return util.Initials(s)
|
||||
}
|
||||
|
||||
func randAlphaNumeric(count int) string {
|
||||
// It is not possible, it appears, to actually generate an error here.
|
||||
r, _ := util.RandomAlphaNumeric(count)
|
||||
return r
|
||||
}
|
||||
|
||||
func randAlpha(count int) string {
|
||||
r, _ := util.RandomAlphabetic(count)
|
||||
return r
|
||||
}
|
||||
|
||||
func randAscii(count int) string {
|
||||
r, _ := util.RandomAscii(count)
|
||||
return r
|
||||
}
|
||||
|
||||
func randNumeric(count int) string {
|
||||
r, _ := util.RandomNumeric(count)
|
||||
return r
|
||||
}
|
||||
|
||||
func untitle(str string) string {
|
||||
return util.Uncapitalize(str)
|
||||
}
|
||||
|
||||
func quote(str ...interface{}) string {
|
||||
out := make([]string, len(str))
|
||||
for i, s := range str {
|
||||
out[i] = fmt.Sprintf("%q", strval(s))
|
||||
}
|
||||
return strings.Join(out, " ")
|
||||
}
|
||||
|
||||
func squote(str ...interface{}) string {
|
||||
out := make([]string, len(str))
|
||||
for i, s := range str {
|
||||
out[i] = fmt.Sprintf("'%v'", s)
|
||||
}
|
||||
return strings.Join(out, " ")
|
||||
}
|
||||
|
||||
func cat(v ...interface{}) string {
|
||||
r := strings.TrimSpace(strings.Repeat("%v ", len(v)))
|
||||
return fmt.Sprintf(r, v...)
|
||||
}
|
||||
|
||||
func indent(spaces int, v string) string {
|
||||
pad := strings.Repeat(" ", spaces)
|
||||
return pad + strings.Replace(v, "\n", "\n"+pad, -1)
|
||||
}
|
||||
|
||||
func nindent(spaces int, v string) string {
|
||||
return "\n" + indent(spaces, v)
|
||||
}
|
||||
|
||||
func replace(old, new, src string) string {
|
||||
return strings.Replace(src, old, new, -1)
|
||||
}
|
||||
|
||||
func plural(one, many string, count int) string {
|
||||
if count == 1 {
|
||||
return one
|
||||
}
|
||||
return many
|
||||
}
|
||||
|
||||
func strslice(v interface{}) []string {
|
||||
switch v := v.(type) {
|
||||
case []string:
|
||||
return v
|
||||
case []interface{}:
|
||||
l := len(v)
|
||||
b := make([]string, l)
|
||||
for i := 0; i < l; i++ {
|
||||
b[i] = strval(v[i])
|
||||
}
|
||||
return b
|
||||
default:
|
||||
val := reflect.ValueOf(v)
|
||||
switch val.Kind() {
|
||||
case reflect.Array, reflect.Slice:
|
||||
l := val.Len()
|
||||
b := make([]string, l)
|
||||
for i := 0; i < l; i++ {
|
||||
b[i] = strval(val.Index(i).Interface())
|
||||
}
|
||||
return b
|
||||
default:
|
||||
return []string{strval(v)}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
func strval(v interface{}) string {
|
||||
switch v := v.(type) {
|
||||
case string:
|
||||
return v
|
||||
case []byte:
|
||||
return string(v)
|
||||
case error:
|
||||
return v.Error()
|
||||
case fmt.Stringer:
|
||||
return v.String()
|
||||
default:
|
||||
return fmt.Sprintf("%v", v)
|
||||
}
|
||||
}
|
||||
|
||||
func trunc(c int, s string) string {
|
||||
if len(s) <= c {
|
||||
return s
|
||||
}
|
||||
return s[0:c]
|
||||
}
|
||||
|
||||
func join(sep string, v interface{}) string {
|
||||
return strings.Join(strslice(v), sep)
|
||||
}
|
||||
|
||||
func split(sep, orig string) map[string]string {
|
||||
parts := strings.Split(orig, sep)
|
||||
res := make(map[string]string, len(parts))
|
||||
for i, v := range parts {
|
||||
res["_"+strconv.Itoa(i)] = v
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
func splitn(sep string, n int, orig string) map[string]string {
|
||||
parts := strings.SplitN(orig, sep, n)
|
||||
res := make(map[string]string, len(parts))
|
||||
for i, v := range parts {
|
||||
res["_"+strconv.Itoa(i)] = v
|
||||
}
|
||||
return res
|
||||
}
|
||||
|
||||
// substring creates a substring of the given string.
|
||||
//
|
||||
// If start is < 0, this calls string[:length].
|
||||
//
|
||||
// If start is >= 0 and length < 0, this calls string[start:]
|
||||
//
|
||||
// Otherwise, this calls string[start, length].
|
||||
func substring(start, length int, s string) string {
|
||||
if start < 0 {
|
||||
return s[:length]
|
||||
}
|
||||
if length < 0 {
|
||||
return s[start:]
|
||||
}
|
||||
return s[start:length]
|
||||
}
|
||||
18
backend/vendor/github.com/aokoli/goutils/.travis.yml
generated
vendored
Normal file
18
backend/vendor/github.com/aokoli/goutils/.travis.yml
generated
vendored
Normal file
@@ -0,0 +1,18 @@
|
||||
language: go
|
||||
|
||||
go:
|
||||
- 1.6
|
||||
- 1.7
|
||||
- 1.8
|
||||
- tip
|
||||
|
||||
script:
|
||||
- go test -v
|
||||
|
||||
notifications:
|
||||
webhooks:
|
||||
urls:
|
||||
- https://webhooks.gitter.im/e/06e3328629952dabe3e0
|
||||
on_success: change # options: [always|never|change] default: always
|
||||
on_failure: always # options: [always|never|change] default: always
|
||||
on_start: never # options: [always|never|change] default: always
|
||||
8
backend/vendor/github.com/aokoli/goutils/CHANGELOG.md
generated
vendored
Normal file
8
backend/vendor/github.com/aokoli/goutils/CHANGELOG.md
generated
vendored
Normal file
@@ -0,0 +1,8 @@
|
||||
# 1.0.1 (2017-05-31)
|
||||
|
||||
## Fixed
|
||||
- #21: Fix generation of alphanumeric strings (thanks @dbarranco)
|
||||
|
||||
# 1.0.0 (2014-04-30)
|
||||
|
||||
- Initial release.
|
||||
202
backend/vendor/github.com/aokoli/goutils/LICENSE.txt
generated
vendored
Normal file
202
backend/vendor/github.com/aokoli/goutils/LICENSE.txt
generated
vendored
Normal file
@@ -0,0 +1,202 @@
|
||||
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
70
backend/vendor/github.com/aokoli/goutils/README.md
generated
vendored
Normal file
70
backend/vendor/github.com/aokoli/goutils/README.md
generated
vendored
Normal file
@@ -0,0 +1,70 @@
|
||||
GoUtils
|
||||
===========
|
||||
[](https://masterminds.github.io/stability/maintenance.html)
|
||||
[](https://godoc.org/github.com/Masterminds/goutils) [](https://travis-ci.org/Masterminds/goutils) [](https://ci.appveyor.com/project/mattfarina/goutils)
|
||||
|
||||
|
||||
GoUtils provides users with utility functions to manipulate strings in various ways. It is a Go implementation of some
|
||||
string manipulation libraries of Java Apache Commons. GoUtils includes the following Java Apache Commons classes:
|
||||
* WordUtils
|
||||
* RandomStringUtils
|
||||
* StringUtils (partial implementation)
|
||||
|
||||
## Installation
|
||||
If you have Go set up on your system, from the GOPATH directory within the command line/terminal, enter this:
|
||||
|
||||
go get github.com/Masterminds/goutils
|
||||
|
||||
If you do not have Go set up on your system, please follow the [Go installation directions from the documenation](http://golang.org/doc/install), and then follow the instructions above to install GoUtils.
|
||||
|
||||
|
||||
## Documentation
|
||||
GoUtils doc is available here: [](https://godoc.org/github.com/Masterminds/goutils)
|
||||
|
||||
|
||||
## Usage
|
||||
The code snippets below show examples of how to use GoUtils. Some functions return errors while others do not. The first instance below, which does not return an error, is the `Initials` function (located within the `wordutils.go` file).
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"github.com/Masterminds/goutils"
|
||||
)
|
||||
|
||||
func main() {
|
||||
|
||||
// EXAMPLE 1: A goutils function which returns no errors
|
||||
fmt.Println (goutils.Initials("John Doe Foo")) // Prints out "JDF"
|
||||
|
||||
}
|
||||
Some functions return errors mainly due to illegal arguements used as parameters. The code example below illustrates how to deal with function that returns an error. In this instance, the function is the `Random` function (located within the `randomstringutils.go` file).
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"github.com/Masterminds/goutils"
|
||||
)
|
||||
|
||||
func main() {
|
||||
|
||||
// EXAMPLE 2: A goutils function which returns an error
|
||||
rand1, err1 := goutils.Random (-1, 0, 0, true, true)
|
||||
|
||||
if err1 != nil {
|
||||
fmt.Println(err1) // Prints out error message because -1 was entered as the first parameter in goutils.Random(...)
|
||||
} else {
|
||||
fmt.Println(rand1)
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
## License
|
||||
GoUtils is licensed under the Apache License, Version 2.0. Please check the LICENSE.txt file or visit http://www.apache.org/licenses/LICENSE-2.0 for a copy of the license.
|
||||
|
||||
## Issue Reporting
|
||||
Make suggestions or report issues using the Git issue tracker: https://github.com/Masterminds/goutils/issues
|
||||
|
||||
## Website
|
||||
* [GoUtils webpage](http://Masterminds.github.io/goutils/)
|
||||
21
backend/vendor/github.com/aokoli/goutils/appveyor.yml
generated
vendored
Normal file
21
backend/vendor/github.com/aokoli/goutils/appveyor.yml
generated
vendored
Normal file
@@ -0,0 +1,21 @@
|
||||
version: build-{build}.{branch}
|
||||
|
||||
clone_folder: C:\gopath\src\github.com\Masterminds\goutils
|
||||
shallow_clone: true
|
||||
|
||||
environment:
|
||||
GOPATH: C:\gopath
|
||||
|
||||
platform:
|
||||
- x64
|
||||
|
||||
build: off
|
||||
|
||||
install:
|
||||
- go version
|
||||
- go env
|
||||
|
||||
test_script:
|
||||
- go test -v
|
||||
|
||||
deploy: off
|
||||
268
backend/vendor/github.com/aokoli/goutils/randomstringutils.go
generated
vendored
Normal file
268
backend/vendor/github.com/aokoli/goutils/randomstringutils.go
generated
vendored
Normal file
@@ -0,0 +1,268 @@
|
||||
/*
|
||||
Copyright 2014 Alexander Okoli
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
*/
|
||||
|
||||
package goutils
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"math"
|
||||
"math/rand"
|
||||
"regexp"
|
||||
"time"
|
||||
"unicode"
|
||||
)
|
||||
|
||||
// RANDOM provides the time-based seed used to generate random numbers
|
||||
var RANDOM = rand.New(rand.NewSource(time.Now().UnixNano()))
|
||||
|
||||
/*
|
||||
RandomNonAlphaNumeric creates a random string whose length is the number of characters specified.
|
||||
Characters will be chosen from the set of all characters (ASCII/Unicode values between 0 to 2,147,483,647 (math.MaxInt32)).
|
||||
|
||||
Parameter:
|
||||
count - the length of random string to create
|
||||
|
||||
Returns:
|
||||
string - the random string
|
||||
error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
|
||||
*/
|
||||
func RandomNonAlphaNumeric(count int) (string, error) {
|
||||
return RandomAlphaNumericCustom(count, false, false)
|
||||
}
|
||||
|
||||
/*
|
||||
RandomAscii creates a random string whose length is the number of characters specified.
|
||||
Characters will be chosen from the set of characters whose ASCII value is between 32 and 126 (inclusive).
|
||||
|
||||
Parameter:
|
||||
count - the length of random string to create
|
||||
|
||||
Returns:
|
||||
string - the random string
|
||||
error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
|
||||
*/
|
||||
func RandomAscii(count int) (string, error) {
|
||||
return Random(count, 32, 127, false, false)
|
||||
}
|
||||
|
||||
/*
|
||||
RandomNumeric creates a random string whose length is the number of characters specified.
|
||||
Characters will be chosen from the set of numeric characters.
|
||||
|
||||
Parameter:
|
||||
count - the length of random string to create
|
||||
|
||||
Returns:
|
||||
string - the random string
|
||||
error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
|
||||
*/
|
||||
func RandomNumeric(count int) (string, error) {
|
||||
return Random(count, 0, 0, false, true)
|
||||
}
|
||||
|
||||
/*
|
||||
RandomAlphabetic creates a random string whose length is the number of characters specified.
|
||||
Characters will be chosen from the set of alpha-numeric characters as indicated by the arguments.
|
||||
|
||||
Parameters:
|
||||
count - the length of random string to create
|
||||
letters - if true, generated string may include alphabetic characters
|
||||
numbers - if true, generated string may include numeric characters
|
||||
|
||||
Returns:
|
||||
string - the random string
|
||||
error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
|
||||
*/
|
||||
func RandomAlphabetic(count int) (string, error) {
|
||||
return Random(count, 0, 0, true, false)
|
||||
}
|
||||
|
||||
/*
|
||||
RandomAlphaNumeric creates a random string whose length is the number of characters specified.
|
||||
Characters will be chosen from the set of alpha-numeric characters.
|
||||
|
||||
Parameter:
|
||||
count - the length of random string to create
|
||||
|
||||
Returns:
|
||||
string - the random string
|
||||
error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
|
||||
*/
|
||||
func RandomAlphaNumeric(count int) (string, error) {
|
||||
RandomString, err := Random(count, 0, 0, true, true)
|
||||
if err != nil {
|
||||
return "", fmt.Errorf("Error: %s", err)
|
||||
}
|
||||
match, err := regexp.MatchString("([0-9]+)", RandomString)
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
|
||||
if !match {
|
||||
//Get the position between 0 and the length of the string-1 to insert a random number
|
||||
position := rand.Intn(count)
|
||||
//Insert a random number between [0-9] in the position
|
||||
RandomString = RandomString[:position] + string('0'+rand.Intn(10)) + RandomString[position+1:]
|
||||
return RandomString, err
|
||||
}
|
||||
return RandomString, err
|
||||
|
||||
}
|
||||
|
||||
/*
|
||||
RandomAlphaNumericCustom creates a random string whose length is the number of characters specified.
|
||||
Characters will be chosen from the set of alpha-numeric characters as indicated by the arguments.
|
||||
|
||||
Parameters:
|
||||
count - the length of random string to create
|
||||
letters - if true, generated string may include alphabetic characters
|
||||
numbers - if true, generated string may include numeric characters
|
||||
|
||||
Returns:
|
||||
string - the random string
|
||||
error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
|
||||
*/
|
||||
func RandomAlphaNumericCustom(count int, letters bool, numbers bool) (string, error) {
|
||||
return Random(count, 0, 0, letters, numbers)
|
||||
}
|
||||
|
||||
/*
|
||||
Random creates a random string based on a variety of options, using default source of randomness.
|
||||
This method has exactly the same semantics as RandomSeed(int, int, int, bool, bool, []char, *rand.Rand), but
|
||||
instead of using an externally supplied source of randomness, it uses the internal *rand.Rand instance.
|
||||
|
||||
Parameters:
|
||||
count - the length of random string to create
|
||||
start - the position in set of chars (ASCII/Unicode int) to start at
|
||||
end - the position in set of chars (ASCII/Unicode int) to end before
|
||||
letters - if true, generated string may include alphabetic characters
|
||||
numbers - if true, generated string may include numeric characters
|
||||
chars - the set of chars to choose randoms from. If nil, then it will use the set of all chars.
|
||||
|
||||
Returns:
|
||||
string - the random string
|
||||
error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
|
||||
*/
|
||||
func Random(count int, start int, end int, letters bool, numbers bool, chars ...rune) (string, error) {
|
||||
return RandomSeed(count, start, end, letters, numbers, chars, RANDOM)
|
||||
}
|
||||
|
||||
/*
|
||||
RandomSeed creates a random string based on a variety of options, using supplied source of randomness.
|
||||
If the parameters start and end are both 0, start and end are set to ' ' and 'z', the ASCII printable characters, will be used,
|
||||
unless letters and numbers are both false, in which case, start and end are set to 0 and math.MaxInt32, respectively.
|
||||
If chars is not nil, characters stored in chars that are between start and end are chosen.
|
||||
This method accepts a user-supplied *rand.Rand instance to use as a source of randomness. By seeding a single *rand.Rand instance
|
||||
with a fixed seed and using it for each call, the same random sequence of strings can be generated repeatedly and predictably.
|
||||
|
||||
Parameters:
|
||||
count - the length of random string to create
|
||||
start - the position in set of chars (ASCII/Unicode decimals) to start at
|
||||
end - the position in set of chars (ASCII/Unicode decimals) to end before
|
||||
letters - if true, generated string may include alphabetic characters
|
||||
numbers - if true, generated string may include numeric characters
|
||||
chars - the set of chars to choose randoms from. If nil, then it will use the set of all chars.
|
||||
random - a source of randomness.
|
||||
|
||||
Returns:
|
||||
string - the random string
|
||||
error - an error stemming from invalid parameters: if count < 0; or the provided chars array is empty; or end <= start; or end > len(chars)
|
||||
*/
|
||||
func RandomSeed(count int, start int, end int, letters bool, numbers bool, chars []rune, random *rand.Rand) (string, error) {
|
||||
|
||||
if count == 0 {
|
||||
return "", nil
|
||||
} else if count < 0 {
|
||||
err := fmt.Errorf("randomstringutils illegal argument: Requested random string length %v is less than 0.", count) // equiv to err := errors.New("...")
|
||||
return "", err
|
||||
}
|
||||
if chars != nil && len(chars) == 0 {
|
||||
err := fmt.Errorf("randomstringutils illegal argument: The chars array must not be empty")
|
||||
return "", err
|
||||
}
|
||||
|
||||
if start == 0 && end == 0 {
|
||||
if chars != nil {
|
||||
end = len(chars)
|
||||
} else {
|
||||
if !letters && !numbers {
|
||||
end = math.MaxInt32
|
||||
} else {
|
||||
end = 'z' + 1
|
||||
start = ' '
|
||||
}
|
||||
}
|
||||
} else {
|
||||
if end <= start {
|
||||
err := fmt.Errorf("randomstringutils illegal argument: Parameter end (%v) must be greater than start (%v)", end, start)
|
||||
return "", err
|
||||
}
|
||||
|
||||
if chars != nil && end > len(chars) {
|
||||
err := fmt.Errorf("randomstringutils illegal argument: Parameter end (%v) cannot be greater than len(chars) (%v)", end, len(chars))
|
||||
return "", err
|
||||
}
|
||||
}
|
||||
|
||||
buffer := make([]rune, count)
|
||||
gap := end - start
|
||||
|
||||
// high-surrogates range, (\uD800-\uDBFF) = 55296 - 56319
|
||||
// low-surrogates range, (\uDC00-\uDFFF) = 56320 - 57343
|
||||
|
||||
for count != 0 {
|
||||
count--
|
||||
var ch rune
|
||||
if chars == nil {
|
||||
ch = rune(random.Intn(gap) + start)
|
||||
} else {
|
||||
ch = chars[random.Intn(gap)+start]
|
||||
}
|
||||
|
||||
if letters && unicode.IsLetter(ch) || numbers && unicode.IsDigit(ch) || !letters && !numbers {
|
||||
if ch >= 56320 && ch <= 57343 { // low surrogate range
|
||||
if count == 0 {
|
||||
count++
|
||||
} else {
|
||||
// Insert low surrogate
|
||||
buffer[count] = ch
|
||||
count--
|
||||
// Insert high surrogate
|
||||
buffer[count] = rune(55296 + random.Intn(128))
|
||||
}
|
||||
} else if ch >= 55296 && ch <= 56191 { // High surrogates range (Partial)
|
||||
if count == 0 {
|
||||
count++
|
||||
} else {
|
||||
// Insert low surrogate
|
||||
buffer[count] = rune(56320 + random.Intn(128))
|
||||
count--
|
||||
// Insert high surrogate
|
||||
buffer[count] = ch
|
||||
}
|
||||
} else if ch >= 56192 && ch <= 56319 {
|
||||
// private high surrogate, skip it
|
||||
count++
|
||||
} else {
|
||||
// not one of the surrogates*
|
||||
buffer[count] = ch
|
||||
}
|
||||
} else {
|
||||
count++
|
||||
}
|
||||
}
|
||||
return string(buffer), nil
|
||||
}
|
||||
224
backend/vendor/github.com/aokoli/goutils/stringutils.go
generated
vendored
Normal file
224
backend/vendor/github.com/aokoli/goutils/stringutils.go
generated
vendored
Normal file
@@ -0,0 +1,224 @@
|
||||
/*
|
||||
Copyright 2014 Alexander Okoli
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
*/
|
||||
|
||||
package goutils
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"fmt"
|
||||
"strings"
|
||||
"unicode"
|
||||
)
|
||||
|
||||
// Typically returned by functions where a searched item cannot be found
|
||||
const INDEX_NOT_FOUND = -1
|
||||
|
||||
/*
|
||||
Abbreviate abbreviates a string using ellipses. This will turn the string "Now is the time for all good men" into "Now is the time for..."
|
||||
|
||||
Specifically, the algorithm is as follows:
|
||||
|
||||
- If str is less than maxWidth characters long, return it.
|
||||
- Else abbreviate it to (str[0:maxWidth - 3] + "...").
|
||||
- If maxWidth is less than 4, return an illegal argument error.
|
||||
- In no case will it return a string of length greater than maxWidth.
|
||||
|
||||
Parameters:
|
||||
str - the string to check
|
||||
maxWidth - maximum length of result string, must be at least 4
|
||||
|
||||
Returns:
|
||||
string - abbreviated string
|
||||
error - if the width is too small
|
||||
*/
|
||||
func Abbreviate(str string, maxWidth int) (string, error) {
|
||||
return AbbreviateFull(str, 0, maxWidth)
|
||||
}
|
||||
|
||||
/*
|
||||
AbbreviateFull abbreviates a string using ellipses. This will turn the string "Now is the time for all good men" into "...is the time for..."
|
||||
This function works like Abbreviate(string, int), but allows you to specify a "left edge" offset. Note that this left edge is not
|
||||
necessarily going to be the leftmost character in the result, or the first character following the ellipses, but it will appear
|
||||
somewhere in the result.
|
||||
In no case will it return a string of length greater than maxWidth.
|
||||
|
||||
Parameters:
|
||||
str - the string to check
|
||||
offset - left edge of source string
|
||||
maxWidth - maximum length of result string, must be at least 4
|
||||
|
||||
Returns:
|
||||
string - abbreviated string
|
||||
error - if the width is too small
|
||||
*/
|
||||
func AbbreviateFull(str string, offset int, maxWidth int) (string, error) {
|
||||
if str == "" {
|
||||
return "", nil
|
||||
}
|
||||
if maxWidth < 4 {
|
||||
err := fmt.Errorf("stringutils illegal argument: Minimum abbreviation width is 4")
|
||||
return "", err
|
||||
}
|
||||
if len(str) <= maxWidth {
|
||||
return str, nil
|
||||
}
|
||||
if offset > len(str) {
|
||||
offset = len(str)
|
||||
}
|
||||
if len(str)-offset < (maxWidth - 3) { // 15 - 5 < 10 - 3 = 10 < 7
|
||||
offset = len(str) - (maxWidth - 3)
|
||||
}
|
||||
abrevMarker := "..."
|
||||
if offset <= 4 {
|
||||
return str[0:maxWidth-3] + abrevMarker, nil // str.substring(0, maxWidth - 3) + abrevMarker;
|
||||
}
|
||||
if maxWidth < 7 {
|
||||
err := fmt.Errorf("stringutils illegal argument: Minimum abbreviation width with offset is 7")
|
||||
return "", err
|
||||
}
|
||||
if (offset + maxWidth - 3) < len(str) { // 5 + (10-3) < 15 = 12 < 15
|
||||
abrevStr, _ := Abbreviate(str[offset:len(str)], (maxWidth - 3))
|
||||
return abrevMarker + abrevStr, nil // abrevMarker + abbreviate(str.substring(offset), maxWidth - 3);
|
||||
}
|
||||
return abrevMarker + str[(len(str)-(maxWidth-3)):len(str)], nil // abrevMarker + str.substring(str.length() - (maxWidth - 3));
|
||||
}
|
||||
|
||||
/*
|
||||
DeleteWhiteSpace deletes all whitespaces from a string as defined by unicode.IsSpace(rune).
|
||||
It returns the string without whitespaces.
|
||||
|
||||
Parameter:
|
||||
str - the string to delete whitespace from, may be nil
|
||||
|
||||
Returns:
|
||||
the string without whitespaces
|
||||
*/
|
||||
func DeleteWhiteSpace(str string) string {
|
||||
if str == "" {
|
||||
return str
|
||||
}
|
||||
sz := len(str)
|
||||
var chs bytes.Buffer
|
||||
count := 0
|
||||
for i := 0; i < sz; i++ {
|
||||
ch := rune(str[i])
|
||||
if !unicode.IsSpace(ch) {
|
||||
chs.WriteRune(ch)
|
||||
count++
|
||||
}
|
||||
}
|
||||
if count == sz {
|
||||
return str
|
||||
}
|
||||
return chs.String()
|
||||
}
|
||||
|
||||
/*
|
||||
IndexOfDifference compares two strings, and returns the index at which the strings begin to differ.
|
||||
|
||||
Parameters:
|
||||
str1 - the first string
|
||||
str2 - the second string
|
||||
|
||||
Returns:
|
||||
the index where str1 and str2 begin to differ; -1 if they are equal
|
||||
*/
|
||||
func IndexOfDifference(str1 string, str2 string) int {
|
||||
if str1 == str2 {
|
||||
return INDEX_NOT_FOUND
|
||||
}
|
||||
if IsEmpty(str1) || IsEmpty(str2) {
|
||||
return 0
|
||||
}
|
||||
var i int
|
||||
for i = 0; i < len(str1) && i < len(str2); i++ {
|
||||
if rune(str1[i]) != rune(str2[i]) {
|
||||
break
|
||||
}
|
||||
}
|
||||
if i < len(str2) || i < len(str1) {
|
||||
return i
|
||||
}
|
||||
return INDEX_NOT_FOUND
|
||||
}
|
||||
|
||||
/*
|
||||
IsBlank checks if a string is whitespace or empty (""). Observe the following behavior:
|
||||
|
||||
goutils.IsBlank("") = true
|
||||
goutils.IsBlank(" ") = true
|
||||
goutils.IsBlank("bob") = false
|
||||
goutils.IsBlank(" bob ") = false
|
||||
|
||||
Parameter:
|
||||
str - the string to check
|
||||
|
||||
Returns:
|
||||
true - if the string is whitespace or empty ("")
|
||||
*/
|
||||
func IsBlank(str string) bool {
|
||||
strLen := len(str)
|
||||
if str == "" || strLen == 0 {
|
||||
return true
|
||||
}
|
||||
for i := 0; i < strLen; i++ {
|
||||
if unicode.IsSpace(rune(str[i])) == false {
|
||||
return false
|
||||
}
|
||||
}
|
||||
return true
|
||||
}
|
||||
|
||||
/*
|
||||
IndexOf returns the index of the first instance of sub in str, with the search beginning from the
|
||||
index start point specified. -1 is returned if sub is not present in str.
|
||||
|
||||
An empty string ("") will return -1 (INDEX_NOT_FOUND). A negative start position is treated as zero.
|
||||
A start position greater than the string length returns -1.
|
||||
|
||||
Parameters:
|
||||
str - the string to check
|
||||
sub - the substring to find
|
||||
start - the start position; negative treated as zero
|
||||
|
||||
Returns:
|
||||
the first index where the sub string was found (always >= start)
|
||||
*/
|
||||
func IndexOf(str string, sub string, start int) int {
|
||||
|
||||
if start < 0 {
|
||||
start = 0
|
||||
}
|
||||
|
||||
if len(str) < start {
|
||||
return INDEX_NOT_FOUND
|
||||
}
|
||||
|
||||
if IsEmpty(str) || IsEmpty(sub) {
|
||||
return INDEX_NOT_FOUND
|
||||
}
|
||||
|
||||
partialIndex := strings.Index(str[start:len(str)], sub)
|
||||
if partialIndex == -1 {
|
||||
return INDEX_NOT_FOUND
|
||||
}
|
||||
return partialIndex + start
|
||||
}
|
||||
|
||||
// IsEmpty checks if a string is empty (""). Returns true if empty, and false otherwise.
|
||||
func IsEmpty(str string) bool {
|
||||
return len(str) == 0
|
||||
}
|
||||
356
backend/vendor/github.com/aokoli/goutils/wordutils.go
generated
vendored
Normal file
356
backend/vendor/github.com/aokoli/goutils/wordutils.go
generated
vendored
Normal file
@@ -0,0 +1,356 @@
|
||||
/*
|
||||
Copyright 2014 Alexander Okoli
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
*/
|
||||
|
||||
/*
|
||||
Package goutils provides utility functions to manipulate strings in various ways.
|
||||
The code snippets below show examples of how to use goutils. Some functions return
|
||||
errors while others do not, so usage would vary as a result.
|
||||
|
||||
Example:
|
||||
|
||||
package main
|
||||
|
||||
import (
|
||||
"fmt"
|
||||
"github.com/aokoli/goutils"
|
||||
)
|
||||
|
||||
func main() {
|
||||
|
||||
// EXAMPLE 1: A goutils function which returns no errors
|
||||
fmt.Println (goutils.Initials("John Doe Foo")) // Prints out "JDF"
|
||||
|
||||
|
||||
|
||||
// EXAMPLE 2: A goutils function which returns an error
|
||||
rand1, err1 := goutils.Random (-1, 0, 0, true, true)
|
||||
|
||||
if err1 != nil {
|
||||
fmt.Println(err1) // Prints out error message because -1 was entered as the first parameter in goutils.Random(...)
|
||||
} else {
|
||||
fmt.Println(rand1)
|
||||
}
|
||||
}
|
||||
*/
|
||||
package goutils
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"strings"
|
||||
"unicode"
|
||||
)
|
||||
|
||||
// VERSION indicates the current version of goutils
|
||||
const VERSION = "1.0.0"
|
||||
|
||||
/*
|
||||
Wrap wraps a single line of text, identifying words by ' '.
|
||||
New lines will be separated by '\n'. Very long words, such as URLs will not be wrapped.
|
||||
Leading spaces on a new line are stripped. Trailing spaces are not stripped.
|
||||
|
||||
Parameters:
|
||||
str - the string to be word wrapped
|
||||
wrapLength - the column (a column can fit only one character) to wrap the words at, less than 1 is treated as 1
|
||||
|
||||
Returns:
|
||||
a line with newlines inserted
|
||||
*/
|
||||
func Wrap(str string, wrapLength int) string {
|
||||
return WrapCustom(str, wrapLength, "", false)
|
||||
}
|
||||
|
||||
/*
|
||||
WrapCustom wraps a single line of text, identifying words by ' '.
|
||||
Leading spaces on a new line are stripped. Trailing spaces are not stripped.
|
||||
|
||||
Parameters:
|
||||
str - the string to be word wrapped
|
||||
wrapLength - the column number (a column can fit only one character) to wrap the words at, less than 1 is treated as 1
|
||||
newLineStr - the string to insert for a new line, "" uses '\n'
|
||||
wrapLongWords - true if long words (such as URLs) should be wrapped
|
||||
|
||||
Returns:
|
||||
a line with newlines inserted
|
||||
*/
|
||||
func WrapCustom(str string, wrapLength int, newLineStr string, wrapLongWords bool) string {
|
||||
|
||||
if str == "" {
|
||||
return ""
|
||||
}
|
||||
if newLineStr == "" {
|
||||
newLineStr = "\n" // TODO Assumes "\n" is seperator. Explore SystemUtils.LINE_SEPARATOR from Apache Commons
|
||||
}
|
||||
if wrapLength < 1 {
|
||||
wrapLength = 1
|
||||
}
|
||||
|
||||
inputLineLength := len(str)
|
||||
offset := 0
|
||||
|
||||
var wrappedLine bytes.Buffer
|
||||
|
||||
for inputLineLength-offset > wrapLength {
|
||||
|
||||
if rune(str[offset]) == ' ' {
|
||||
offset++
|
||||
continue
|
||||
}
|
||||
|
||||
end := wrapLength + offset + 1
|
||||
spaceToWrapAt := strings.LastIndex(str[offset:end], " ") + offset
|
||||
|
||||
if spaceToWrapAt >= offset {
|
||||
// normal word (not longer than wrapLength)
|
||||
wrappedLine.WriteString(str[offset:spaceToWrapAt])
|
||||
wrappedLine.WriteString(newLineStr)
|
||||
offset = spaceToWrapAt + 1
|
||||
|
||||
} else {
|
||||
// long word or URL
|
||||
if wrapLongWords {
|
||||
end := wrapLength + offset
|
||||
// long words are wrapped one line at a time
|
||||
wrappedLine.WriteString(str[offset:end])
|
||||
wrappedLine.WriteString(newLineStr)
|
||||
offset += wrapLength
|
||||
} else {
|
||||
// long words aren't wrapped, just extended beyond limit
|
||||
end := wrapLength + offset
|
||||
spaceToWrapAt = strings.IndexRune(str[end:len(str)], ' ') + end
|
||||
if spaceToWrapAt >= 0 {
|
||||
wrappedLine.WriteString(str[offset:spaceToWrapAt])
|
||||
wrappedLine.WriteString(newLineStr)
|
||||
offset = spaceToWrapAt + 1
|
||||
} else {
|
||||
wrappedLine.WriteString(str[offset:len(str)])
|
||||
offset = inputLineLength
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
wrappedLine.WriteString(str[offset:len(str)])
|
||||
|
||||
return wrappedLine.String()
|
||||
|
||||
}
|
||||
|
||||
/*
|
||||
Capitalize capitalizes all the delimiter separated words in a string. Only the first letter of each word is changed.
|
||||
To convert the rest of each word to lowercase at the same time, use CapitalizeFully(str string, delimiters ...rune).
|
||||
The delimiters represent a set of characters understood to separate words. The first string character
|
||||
and the first non-delimiter character after a delimiter will be capitalized. A "" input string returns "".
|
||||
Capitalization uses the Unicode title case, normally equivalent to upper case.
|
||||
|
||||
Parameters:
|
||||
str - the string to capitalize
|
||||
delimiters - set of characters to determine capitalization, exclusion of this parameter means whitespace would be delimeter
|
||||
|
||||
Returns:
|
||||
capitalized string
|
||||
*/
|
||||
func Capitalize(str string, delimiters ...rune) string {
|
||||
|
||||
var delimLen int
|
||||
|
||||
if delimiters == nil {
|
||||
delimLen = -1
|
||||
} else {
|
||||
delimLen = len(delimiters)
|
||||
}
|
||||
|
||||
if str == "" || delimLen == 0 {
|
||||
return str
|
||||
}
|
||||
|
||||
buffer := []rune(str)
|
||||
capitalizeNext := true
|
||||
for i := 0; i < len(buffer); i++ {
|
||||
ch := buffer[i]
|
||||
if isDelimiter(ch, delimiters...) {
|
||||
capitalizeNext = true
|
||||
} else if capitalizeNext {
|
||||
buffer[i] = unicode.ToTitle(ch)
|
||||
capitalizeNext = false
|
||||
}
|
||||
}
|
||||
return string(buffer)
|
||||
|
||||
}
|
||||
|
||||
/*
|
||||
CapitalizeFully converts all the delimiter separated words in a string into capitalized words, that is each word is made up of a
|
||||
titlecase character and then a series of lowercase characters. The delimiters represent a set of characters understood
|
||||
to separate words. The first string character and the first non-delimiter character after a delimiter will be capitalized.
|
||||
Capitalization uses the Unicode title case, normally equivalent to upper case.
|
||||
|
||||
Parameters:
|
||||
str - the string to capitalize fully
|
||||
delimiters - set of characters to determine capitalization, exclusion of this parameter means whitespace would be delimeter
|
||||
|
||||
Returns:
|
||||
capitalized string
|
||||
*/
|
||||
func CapitalizeFully(str string, delimiters ...rune) string {
|
||||
|
||||
var delimLen int
|
||||
|
||||
if delimiters == nil {
|
||||
delimLen = -1
|
||||
} else {
|
||||
delimLen = len(delimiters)
|
||||
}
|
||||
|
||||
if str == "" || delimLen == 0 {
|
||||
return str
|
||||
}
|
||||
str = strings.ToLower(str)
|
||||
return Capitalize(str, delimiters...)
|
||||
}
|
||||
|
||||
/*
|
||||
Uncapitalize uncapitalizes all the whitespace separated words in a string. Only the first letter of each word is changed.
|
||||
The delimiters represent a set of characters understood to separate words. The first string character and the first non-delimiter
|
||||
character after a delimiter will be uncapitalized. Whitespace is defined by unicode.IsSpace(char).
|
||||
|
||||
Parameters:
|
||||
str - the string to uncapitalize fully
|
||||
delimiters - set of characters to determine capitalization, exclusion of this parameter means whitespace would be delimeter
|
||||
|
||||
Returns:
|
||||
uncapitalized string
|
||||
*/
|
||||
func Uncapitalize(str string, delimiters ...rune) string {
|
||||
|
||||
var delimLen int
|
||||
|
||||
if delimiters == nil {
|
||||
delimLen = -1
|
||||
} else {
|
||||
delimLen = len(delimiters)
|
||||
}
|
||||
|
||||
if str == "" || delimLen == 0 {
|
||||
return str
|
||||
}
|
||||
|
||||
buffer := []rune(str)
|
||||
uncapitalizeNext := true // TODO Always makes capitalize/un apply to first char.
|
||||
for i := 0; i < len(buffer); i++ {
|
||||
ch := buffer[i]
|
||||
if isDelimiter(ch, delimiters...) {
|
||||
uncapitalizeNext = true
|
||||
} else if uncapitalizeNext {
|
||||
buffer[i] = unicode.ToLower(ch)
|
||||
uncapitalizeNext = false
|
||||
}
|
||||
}
|
||||
return string(buffer)
|
||||
}
|
||||
|
||||
/*
|
||||
SwapCase swaps the case of a string using a word based algorithm.
|
||||
|
||||
Conversion algorithm:
|
||||
|
||||
Upper case character converts to Lower case
|
||||
Title case character converts to Lower case
|
||||
Lower case character after Whitespace or at start converts to Title case
|
||||
Other Lower case character converts to Upper case
|
||||
Whitespace is defined by unicode.IsSpace(char).
|
||||
|
||||
Parameters:
|
||||
str - the string to swap case
|
||||
|
||||
Returns:
|
||||
the changed string
|
||||
*/
|
||||
func SwapCase(str string) string {
|
||||
if str == "" {
|
||||
return str
|
||||
}
|
||||
buffer := []rune(str)
|
||||
|
||||
whitespace := true
|
||||
|
||||
for i := 0; i < len(buffer); i++ {
|
||||
ch := buffer[i]
|
||||
if unicode.IsUpper(ch) {
|
||||
buffer[i] = unicode.ToLower(ch)
|
||||
whitespace = false
|
||||
} else if unicode.IsTitle(ch) {
|
||||
buffer[i] = unicode.ToLower(ch)
|
||||
whitespace = false
|
||||
} else if unicode.IsLower(ch) {
|
||||
if whitespace {
|
||||
buffer[i] = unicode.ToTitle(ch)
|
||||
whitespace = false
|
||||
} else {
|
||||
buffer[i] = unicode.ToUpper(ch)
|
||||
}
|
||||
} else {
|
||||
whitespace = unicode.IsSpace(ch)
|
||||
}
|
||||
}
|
||||
return string(buffer)
|
||||
}
|
||||
|
||||
/*
|
||||
Initials extracts the initial letters from each word in the string. The first letter of the string and all first
|
||||
letters after the defined delimiters are returned as a new string. Their case is not changed. If the delimiters
|
||||
parameter is excluded, then Whitespace is used. Whitespace is defined by unicode.IsSpacea(char). An empty delimiter array returns an empty string.
|
||||
|
||||
Parameters:
|
||||
str - the string to get initials from
|
||||
delimiters - set of characters to determine words, exclusion of this parameter means whitespace would be delimeter
|
||||
Returns:
|
||||
string of initial letters
|
||||
*/
|
||||
func Initials(str string, delimiters ...rune) string {
|
||||
if str == "" {
|
||||
return str
|
||||
}
|
||||
if delimiters != nil && len(delimiters) == 0 {
|
||||
return ""
|
||||
}
|
||||
strLen := len(str)
|
||||
var buf bytes.Buffer
|
||||
lastWasGap := true
|
||||
for i := 0; i < strLen; i++ {
|
||||
ch := rune(str[i])
|
||||
|
||||
if isDelimiter(ch, delimiters...) {
|
||||
lastWasGap = true
|
||||
} else if lastWasGap {
|
||||
buf.WriteRune(ch)
|
||||
lastWasGap = false
|
||||
}
|
||||
}
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// private function (lower case func name)
|
||||
func isDelimiter(ch rune, delimiters ...rune) bool {
|
||||
if delimiters == nil {
|
||||
return unicode.IsSpace(ch)
|
||||
}
|
||||
for _, delimiter := range delimiters {
|
||||
if ch == delimiter {
|
||||
return true
|
||||
}
|
||||
}
|
||||
return false
|
||||
}
|
||||
9
backend/vendor/github.com/google/uuid/.travis.yml
generated
vendored
Normal file
9
backend/vendor/github.com/google/uuid/.travis.yml
generated
vendored
Normal file
@@ -0,0 +1,9 @@
|
||||
language: go
|
||||
|
||||
go:
|
||||
- 1.4.3
|
||||
- 1.5.3
|
||||
- tip
|
||||
|
||||
script:
|
||||
- go test -v ./...
|
||||
10
backend/vendor/github.com/google/uuid/CONTRIBUTING.md
generated
vendored
Normal file
10
backend/vendor/github.com/google/uuid/CONTRIBUTING.md
generated
vendored
Normal file
@@ -0,0 +1,10 @@
|
||||
# How to contribute
|
||||
|
||||
We definitely welcome patches and contribution to this project!
|
||||
|
||||
### Legal requirements
|
||||
|
||||
In order to protect both you and ourselves, you will need to sign the
|
||||
[Contributor License Agreement](https://cla.developers.google.com/clas).
|
||||
|
||||
You may have already signed it for other Google projects.
|
||||
9
backend/vendor/github.com/google/uuid/CONTRIBUTORS
generated
vendored
Normal file
9
backend/vendor/github.com/google/uuid/CONTRIBUTORS
generated
vendored
Normal file
@@ -0,0 +1,9 @@
|
||||
Paul Borman <borman@google.com>
|
||||
bmatsuo
|
||||
shawnps
|
||||
theory
|
||||
jboverfelt
|
||||
dsymonds
|
||||
cd1
|
||||
wallclockbuilder
|
||||
dansouza
|
||||
27
backend/vendor/github.com/google/uuid/LICENSE
generated
vendored
Normal file
27
backend/vendor/github.com/google/uuid/LICENSE
generated
vendored
Normal file
@@ -0,0 +1,27 @@
|
||||
Copyright (c) 2009,2014 Google Inc. All rights reserved.
|
||||
|
||||
Redistribution and use in source and binary forms, with or without
|
||||
modification, are permitted provided that the following conditions are
|
||||
met:
|
||||
|
||||
* Redistributions of source code must retain the above copyright
|
||||
notice, this list of conditions and the following disclaimer.
|
||||
* Redistributions in binary form must reproduce the above
|
||||
copyright notice, this list of conditions and the following disclaimer
|
||||
in the documentation and/or other materials provided with the
|
||||
distribution.
|
||||
* Neither the name of Google Inc. nor the names of its
|
||||
contributors may be used to endorse or promote products derived from
|
||||
this software without specific prior written permission.
|
||||
|
||||
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
|
||||
"AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
|
||||
LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
|
||||
A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
|
||||
OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
|
||||
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
|
||||
LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
|
||||
DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
|
||||
THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
||||
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
||||
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
||||
19
backend/vendor/github.com/google/uuid/README.md
generated
vendored
Normal file
19
backend/vendor/github.com/google/uuid/README.md
generated
vendored
Normal file
@@ -0,0 +1,19 @@
|
||||
# uuid 
|
||||
The uuid package generates and inspects UUIDs based on
|
||||
[RFC 4122](http://tools.ietf.org/html/rfc4122)
|
||||
and DCE 1.1: Authentication and Security Services.
|
||||
|
||||
This package is based on the github.com/pborman/uuid package (previously named
|
||||
code.google.com/p/go-uuid). It differs from these earlier packages in that
|
||||
a UUID is a 16 byte array rather than a byte slice. One loss due to this
|
||||
change is the ability to represent an invalid UUID (vs a NIL UUID).
|
||||
|
||||
###### Install
|
||||
`go get github.com/google/uuid`
|
||||
|
||||
###### Documentation
|
||||
[](http://godoc.org/github.com/google/uuid)
|
||||
|
||||
Full `go doc` style documentation for the package can be viewed online without
|
||||
installing this package by using the GoDoc site here:
|
||||
http://godoc.org/github.com/google/uuid
|
||||
80
backend/vendor/github.com/google/uuid/dce.go
generated
vendored
Normal file
80
backend/vendor/github.com/google/uuid/dce.go
generated
vendored
Normal file
@@ -0,0 +1,80 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import (
|
||||
"encoding/binary"
|
||||
"fmt"
|
||||
"os"
|
||||
)
|
||||
|
||||
// A Domain represents a Version 2 domain
|
||||
type Domain byte
|
||||
|
||||
// Domain constants for DCE Security (Version 2) UUIDs.
|
||||
const (
|
||||
Person = Domain(0)
|
||||
Group = Domain(1)
|
||||
Org = Domain(2)
|
||||
)
|
||||
|
||||
// NewDCESecurity returns a DCE Security (Version 2) UUID.
|
||||
//
|
||||
// The domain should be one of Person, Group or Org.
|
||||
// On a POSIX system the id should be the users UID for the Person
|
||||
// domain and the users GID for the Group. The meaning of id for
|
||||
// the domain Org or on non-POSIX systems is site defined.
|
||||
//
|
||||
// For a given domain/id pair the same token may be returned for up to
|
||||
// 7 minutes and 10 seconds.
|
||||
func NewDCESecurity(domain Domain, id uint32) (UUID, error) {
|
||||
uuid, err := NewUUID()
|
||||
if err == nil {
|
||||
uuid[6] = (uuid[6] & 0x0f) | 0x20 // Version 2
|
||||
uuid[9] = byte(domain)
|
||||
binary.BigEndian.PutUint32(uuid[0:], id)
|
||||
}
|
||||
return uuid, err
|
||||
}
|
||||
|
||||
// NewDCEPerson returns a DCE Security (Version 2) UUID in the person
|
||||
// domain with the id returned by os.Getuid.
|
||||
//
|
||||
// NewDCESecurity(Person, uint32(os.Getuid()))
|
||||
func NewDCEPerson() (UUID, error) {
|
||||
return NewDCESecurity(Person, uint32(os.Getuid()))
|
||||
}
|
||||
|
||||
// NewDCEGroup returns a DCE Security (Version 2) UUID in the group
|
||||
// domain with the id returned by os.Getgid.
|
||||
//
|
||||
// NewDCESecurity(Group, uint32(os.Getgid()))
|
||||
func NewDCEGroup() (UUID, error) {
|
||||
return NewDCESecurity(Group, uint32(os.Getgid()))
|
||||
}
|
||||
|
||||
// Domain returns the domain for a Version 2 UUID. Domains are only defined
|
||||
// for Version 2 UUIDs.
|
||||
func (uuid UUID) Domain() Domain {
|
||||
return Domain(uuid[9])
|
||||
}
|
||||
|
||||
// ID returns the id for a Version 2 UUID. IDs are only defined for Version 2
|
||||
// UUIDs.
|
||||
func (uuid UUID) ID() uint32 {
|
||||
return binary.BigEndian.Uint32(uuid[0:4])
|
||||
}
|
||||
|
||||
func (d Domain) String() string {
|
||||
switch d {
|
||||
case Person:
|
||||
return "Person"
|
||||
case Group:
|
||||
return "Group"
|
||||
case Org:
|
||||
return "Org"
|
||||
}
|
||||
return fmt.Sprintf("Domain%d", int(d))
|
||||
}
|
||||
12
backend/vendor/github.com/google/uuid/doc.go
generated
vendored
Normal file
12
backend/vendor/github.com/google/uuid/doc.go
generated
vendored
Normal file
@@ -0,0 +1,12 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
// Package uuid generates and inspects UUIDs.
|
||||
//
|
||||
// UUIDs are based on RFC 4122 and DCE 1.1: Authentication and Security
|
||||
// Services.
|
||||
//
|
||||
// A UUID is a 16 byte (128 bit) array. UUIDs may be used as keys to
|
||||
// maps or compared directly.
|
||||
package uuid
|
||||
1
backend/vendor/github.com/google/uuid/go.mod
generated
vendored
Normal file
1
backend/vendor/github.com/google/uuid/go.mod
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module github.com/google/uuid
|
||||
53
backend/vendor/github.com/google/uuid/hash.go
generated
vendored
Normal file
53
backend/vendor/github.com/google/uuid/hash.go
generated
vendored
Normal file
@@ -0,0 +1,53 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import (
|
||||
"crypto/md5"
|
||||
"crypto/sha1"
|
||||
"hash"
|
||||
)
|
||||
|
||||
// Well known namespace IDs and UUIDs
|
||||
var (
|
||||
NameSpaceDNS = Must(Parse("6ba7b810-9dad-11d1-80b4-00c04fd430c8"))
|
||||
NameSpaceURL = Must(Parse("6ba7b811-9dad-11d1-80b4-00c04fd430c8"))
|
||||
NameSpaceOID = Must(Parse("6ba7b812-9dad-11d1-80b4-00c04fd430c8"))
|
||||
NameSpaceX500 = Must(Parse("6ba7b814-9dad-11d1-80b4-00c04fd430c8"))
|
||||
Nil UUID // empty UUID, all zeros
|
||||
)
|
||||
|
||||
// NewHash returns a new UUID derived from the hash of space concatenated with
|
||||
// data generated by h. The hash should be at least 16 byte in length. The
|
||||
// first 16 bytes of the hash are used to form the UUID. The version of the
|
||||
// UUID will be the lower 4 bits of version. NewHash is used to implement
|
||||
// NewMD5 and NewSHA1.
|
||||
func NewHash(h hash.Hash, space UUID, data []byte, version int) UUID {
|
||||
h.Reset()
|
||||
h.Write(space[:])
|
||||
h.Write(data)
|
||||
s := h.Sum(nil)
|
||||
var uuid UUID
|
||||
copy(uuid[:], s)
|
||||
uuid[6] = (uuid[6] & 0x0f) | uint8((version&0xf)<<4)
|
||||
uuid[8] = (uuid[8] & 0x3f) | 0x80 // RFC 4122 variant
|
||||
return uuid
|
||||
}
|
||||
|
||||
// NewMD5 returns a new MD5 (Version 3) UUID based on the
|
||||
// supplied name space and data. It is the same as calling:
|
||||
//
|
||||
// NewHash(md5.New(), space, data, 3)
|
||||
func NewMD5(space UUID, data []byte) UUID {
|
||||
return NewHash(md5.New(), space, data, 3)
|
||||
}
|
||||
|
||||
// NewSHA1 returns a new SHA1 (Version 5) UUID based on the
|
||||
// supplied name space and data. It is the same as calling:
|
||||
//
|
||||
// NewHash(sha1.New(), space, data, 5)
|
||||
func NewSHA1(space UUID, data []byte) UUID {
|
||||
return NewHash(sha1.New(), space, data, 5)
|
||||
}
|
||||
37
backend/vendor/github.com/google/uuid/marshal.go
generated
vendored
Normal file
37
backend/vendor/github.com/google/uuid/marshal.go
generated
vendored
Normal file
@@ -0,0 +1,37 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import "fmt"
|
||||
|
||||
// MarshalText implements encoding.TextMarshaler.
|
||||
func (uuid UUID) MarshalText() ([]byte, error) {
|
||||
var js [36]byte
|
||||
encodeHex(js[:], uuid)
|
||||
return js[:], nil
|
||||
}
|
||||
|
||||
// UnmarshalText implements encoding.TextUnmarshaler.
|
||||
func (uuid *UUID) UnmarshalText(data []byte) error {
|
||||
id, err := ParseBytes(data)
|
||||
if err == nil {
|
||||
*uuid = id
|
||||
}
|
||||
return err
|
||||
}
|
||||
|
||||
// MarshalBinary implements encoding.BinaryMarshaler.
|
||||
func (uuid UUID) MarshalBinary() ([]byte, error) {
|
||||
return uuid[:], nil
|
||||
}
|
||||
|
||||
// UnmarshalBinary implements encoding.BinaryUnmarshaler.
|
||||
func (uuid *UUID) UnmarshalBinary(data []byte) error {
|
||||
if len(data) != 16 {
|
||||
return fmt.Errorf("invalid UUID (got %d bytes)", len(data))
|
||||
}
|
||||
copy(uuid[:], data)
|
||||
return nil
|
||||
}
|
||||
90
backend/vendor/github.com/google/uuid/node.go
generated
vendored
Normal file
90
backend/vendor/github.com/google/uuid/node.go
generated
vendored
Normal file
@@ -0,0 +1,90 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import (
|
||||
"sync"
|
||||
)
|
||||
|
||||
var (
|
||||
nodeMu sync.Mutex
|
||||
ifname string // name of interface being used
|
||||
nodeID [6]byte // hardware for version 1 UUIDs
|
||||
zeroID [6]byte // nodeID with only 0's
|
||||
)
|
||||
|
||||
// NodeInterface returns the name of the interface from which the NodeID was
|
||||
// derived. The interface "user" is returned if the NodeID was set by
|
||||
// SetNodeID.
|
||||
func NodeInterface() string {
|
||||
defer nodeMu.Unlock()
|
||||
nodeMu.Lock()
|
||||
return ifname
|
||||
}
|
||||
|
||||
// SetNodeInterface selects the hardware address to be used for Version 1 UUIDs.
|
||||
// If name is "" then the first usable interface found will be used or a random
|
||||
// Node ID will be generated. If a named interface cannot be found then false
|
||||
// is returned.
|
||||
//
|
||||
// SetNodeInterface never fails when name is "".
|
||||
func SetNodeInterface(name string) bool {
|
||||
defer nodeMu.Unlock()
|
||||
nodeMu.Lock()
|
||||
return setNodeInterface(name)
|
||||
}
|
||||
|
||||
func setNodeInterface(name string) bool {
|
||||
iname, addr := getHardwareInterface(name) // null implementation for js
|
||||
if iname != "" && addr != nil {
|
||||
ifname = iname
|
||||
copy(nodeID[:], addr)
|
||||
return true
|
||||
}
|
||||
|
||||
// We found no interfaces with a valid hardware address. If name
|
||||
// does not specify a specific interface generate a random Node ID
|
||||
// (section 4.1.6)
|
||||
if name == "" {
|
||||
ifname = "random"
|
||||
randomBits(nodeID[:])
|
||||
return true
|
||||
}
|
||||
return false
|
||||
}
|
||||
|
||||
// NodeID returns a slice of a copy of the current Node ID, setting the Node ID
|
||||
// if not already set.
|
||||
func NodeID() []byte {
|
||||
defer nodeMu.Unlock()
|
||||
nodeMu.Lock()
|
||||
if nodeID == zeroID {
|
||||
setNodeInterface("")
|
||||
}
|
||||
nid := nodeID
|
||||
return nid[:]
|
||||
}
|
||||
|
||||
// SetNodeID sets the Node ID to be used for Version 1 UUIDs. The first 6 bytes
|
||||
// of id are used. If id is less than 6 bytes then false is returned and the
|
||||
// Node ID is not set.
|
||||
func SetNodeID(id []byte) bool {
|
||||
if len(id) < 6 {
|
||||
return false
|
||||
}
|
||||
defer nodeMu.Unlock()
|
||||
nodeMu.Lock()
|
||||
copy(nodeID[:], id)
|
||||
ifname = "user"
|
||||
return true
|
||||
}
|
||||
|
||||
// NodeID returns the 6 byte node id encoded in uuid. It returns nil if uuid is
|
||||
// not valid. The NodeID is only well defined for version 1 and 2 UUIDs.
|
||||
func (uuid UUID) NodeID() []byte {
|
||||
var node [6]byte
|
||||
copy(node[:], uuid[10:])
|
||||
return node[:]
|
||||
}
|
||||
12
backend/vendor/github.com/google/uuid/node_js.go
generated
vendored
Normal file
12
backend/vendor/github.com/google/uuid/node_js.go
generated
vendored
Normal file
@@ -0,0 +1,12 @@
|
||||
// Copyright 2017 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
// +build js
|
||||
|
||||
package uuid
|
||||
|
||||
// getHardwareInterface returns nil values for the JS version of the code.
|
||||
// This remvoves the "net" dependency, because it is not used in the browser.
|
||||
// Using the "net" library inflates the size of the transpiled JS code by 673k bytes.
|
||||
func getHardwareInterface(name string) (string, []byte) { return "", nil }
|
||||
33
backend/vendor/github.com/google/uuid/node_net.go
generated
vendored
Normal file
33
backend/vendor/github.com/google/uuid/node_net.go
generated
vendored
Normal file
@@ -0,0 +1,33 @@
|
||||
// Copyright 2017 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
// +build !js
|
||||
|
||||
package uuid
|
||||
|
||||
import "net"
|
||||
|
||||
var interfaces []net.Interface // cached list of interfaces
|
||||
|
||||
// getHardwareInterface returns the name and hardware address of interface name.
|
||||
// If name is "" then the name and hardware address of one of the system's
|
||||
// interfaces is returned. If no interfaces are found (name does not exist or
|
||||
// there are no interfaces) then "", nil is returned.
|
||||
//
|
||||
// Only addresses of at least 6 bytes are returned.
|
||||
func getHardwareInterface(name string) (string, []byte) {
|
||||
if interfaces == nil {
|
||||
var err error
|
||||
interfaces, err = net.Interfaces()
|
||||
if err != nil {
|
||||
return "", nil
|
||||
}
|
||||
}
|
||||
for _, ifs := range interfaces {
|
||||
if len(ifs.HardwareAddr) >= 6 && (name == "" || name == ifs.Name) {
|
||||
return ifs.Name, ifs.HardwareAddr
|
||||
}
|
||||
}
|
||||
return "", nil
|
||||
}
|
||||
59
backend/vendor/github.com/google/uuid/sql.go
generated
vendored
Normal file
59
backend/vendor/github.com/google/uuid/sql.go
generated
vendored
Normal file
@@ -0,0 +1,59 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import (
|
||||
"database/sql/driver"
|
||||
"fmt"
|
||||
)
|
||||
|
||||
// Scan implements sql.Scanner so UUIDs can be read from databases transparently
|
||||
// Currently, database types that map to string and []byte are supported. Please
|
||||
// consult database-specific driver documentation for matching types.
|
||||
func (uuid *UUID) Scan(src interface{}) error {
|
||||
switch src := src.(type) {
|
||||
case nil:
|
||||
return nil
|
||||
|
||||
case string:
|
||||
// if an empty UUID comes from a table, we return a null UUID
|
||||
if src == "" {
|
||||
return nil
|
||||
}
|
||||
|
||||
// see Parse for required string format
|
||||
u, err := Parse(src)
|
||||
if err != nil {
|
||||
return fmt.Errorf("Scan: %v", err)
|
||||
}
|
||||
|
||||
*uuid = u
|
||||
|
||||
case []byte:
|
||||
// if an empty UUID comes from a table, we return a null UUID
|
||||
if len(src) == 0 {
|
||||
return nil
|
||||
}
|
||||
|
||||
// assumes a simple slice of bytes if 16 bytes
|
||||
// otherwise attempts to parse
|
||||
if len(src) != 16 {
|
||||
return uuid.Scan(string(src))
|
||||
}
|
||||
copy((*uuid)[:], src)
|
||||
|
||||
default:
|
||||
return fmt.Errorf("Scan: unable to scan type %T into UUID", src)
|
||||
}
|
||||
|
||||
return nil
|
||||
}
|
||||
|
||||
// Value implements sql.Valuer so that UUIDs can be written to databases
|
||||
// transparently. Currently, UUIDs map to strings. Please consult
|
||||
// database-specific driver documentation for matching types.
|
||||
func (uuid UUID) Value() (driver.Value, error) {
|
||||
return uuid.String(), nil
|
||||
}
|
||||
123
backend/vendor/github.com/google/uuid/time.go
generated
vendored
Normal file
123
backend/vendor/github.com/google/uuid/time.go
generated
vendored
Normal file
@@ -0,0 +1,123 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import (
|
||||
"encoding/binary"
|
||||
"sync"
|
||||
"time"
|
||||
)
|
||||
|
||||
// A Time represents a time as the number of 100's of nanoseconds since 15 Oct
|
||||
// 1582.
|
||||
type Time int64
|
||||
|
||||
const (
|
||||
lillian = 2299160 // Julian day of 15 Oct 1582
|
||||
unix = 2440587 // Julian day of 1 Jan 1970
|
||||
epoch = unix - lillian // Days between epochs
|
||||
g1582 = epoch * 86400 // seconds between epochs
|
||||
g1582ns100 = g1582 * 10000000 // 100s of a nanoseconds between epochs
|
||||
)
|
||||
|
||||
var (
|
||||
timeMu sync.Mutex
|
||||
lasttime uint64 // last time we returned
|
||||
clockSeq uint16 // clock sequence for this run
|
||||
|
||||
timeNow = time.Now // for testing
|
||||
)
|
||||
|
||||
// UnixTime converts t the number of seconds and nanoseconds using the Unix
|
||||
// epoch of 1 Jan 1970.
|
||||
func (t Time) UnixTime() (sec, nsec int64) {
|
||||
sec = int64(t - g1582ns100)
|
||||
nsec = (sec % 10000000) * 100
|
||||
sec /= 10000000
|
||||
return sec, nsec
|
||||
}
|
||||
|
||||
// GetTime returns the current Time (100s of nanoseconds since 15 Oct 1582) and
|
||||
// clock sequence as well as adjusting the clock sequence as needed. An error
|
||||
// is returned if the current time cannot be determined.
|
||||
func GetTime() (Time, uint16, error) {
|
||||
defer timeMu.Unlock()
|
||||
timeMu.Lock()
|
||||
return getTime()
|
||||
}
|
||||
|
||||
func getTime() (Time, uint16, error) {
|
||||
t := timeNow()
|
||||
|
||||
// If we don't have a clock sequence already, set one.
|
||||
if clockSeq == 0 {
|
||||
setClockSequence(-1)
|
||||
}
|
||||
now := uint64(t.UnixNano()/100) + g1582ns100
|
||||
|
||||
// If time has gone backwards with this clock sequence then we
|
||||
// increment the clock sequence
|
||||
if now <= lasttime {
|
||||
clockSeq = ((clockSeq + 1) & 0x3fff) | 0x8000
|
||||
}
|
||||
lasttime = now
|
||||
return Time(now), clockSeq, nil
|
||||
}
|
||||
|
||||
// ClockSequence returns the current clock sequence, generating one if not
|
||||
// already set. The clock sequence is only used for Version 1 UUIDs.
|
||||
//
|
||||
// The uuid package does not use global static storage for the clock sequence or
|
||||
// the last time a UUID was generated. Unless SetClockSequence is used, a new
|
||||
// random clock sequence is generated the first time a clock sequence is
|
||||
// requested by ClockSequence, GetTime, or NewUUID. (section 4.2.1.1)
|
||||
func ClockSequence() int {
|
||||
defer timeMu.Unlock()
|
||||
timeMu.Lock()
|
||||
return clockSequence()
|
||||
}
|
||||
|
||||
func clockSequence() int {
|
||||
if clockSeq == 0 {
|
||||
setClockSequence(-1)
|
||||
}
|
||||
return int(clockSeq & 0x3fff)
|
||||
}
|
||||
|
||||
// SetClockSequence sets the clock sequence to the lower 14 bits of seq. Setting to
|
||||
// -1 causes a new sequence to be generated.
|
||||
func SetClockSequence(seq int) {
|
||||
defer timeMu.Unlock()
|
||||
timeMu.Lock()
|
||||
setClockSequence(seq)
|
||||
}
|
||||
|
||||
func setClockSequence(seq int) {
|
||||
if seq == -1 {
|
||||
var b [2]byte
|
||||
randomBits(b[:]) // clock sequence
|
||||
seq = int(b[0])<<8 | int(b[1])
|
||||
}
|
||||
oldSeq := clockSeq
|
||||
clockSeq = uint16(seq&0x3fff) | 0x8000 // Set our variant
|
||||
if oldSeq != clockSeq {
|
||||
lasttime = 0
|
||||
}
|
||||
}
|
||||
|
||||
// Time returns the time in 100s of nanoseconds since 15 Oct 1582 encoded in
|
||||
// uuid. The time is only defined for version 1 and 2 UUIDs.
|
||||
func (uuid UUID) Time() Time {
|
||||
time := int64(binary.BigEndian.Uint32(uuid[0:4]))
|
||||
time |= int64(binary.BigEndian.Uint16(uuid[4:6])) << 32
|
||||
time |= int64(binary.BigEndian.Uint16(uuid[6:8])&0xfff) << 48
|
||||
return Time(time)
|
||||
}
|
||||
|
||||
// ClockSequence returns the clock sequence encoded in uuid.
|
||||
// The clock sequence is only well defined for version 1 and 2 UUIDs.
|
||||
func (uuid UUID) ClockSequence() int {
|
||||
return int(binary.BigEndian.Uint16(uuid[8:10])) & 0x3fff
|
||||
}
|
||||
43
backend/vendor/github.com/google/uuid/util.go
generated
vendored
Normal file
43
backend/vendor/github.com/google/uuid/util.go
generated
vendored
Normal file
@@ -0,0 +1,43 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import (
|
||||
"io"
|
||||
)
|
||||
|
||||
// randomBits completely fills slice b with random data.
|
||||
func randomBits(b []byte) {
|
||||
if _, err := io.ReadFull(rander, b); err != nil {
|
||||
panic(err.Error()) // rand should never fail
|
||||
}
|
||||
}
|
||||
|
||||
// xvalues returns the value of a byte as a hexadecimal digit or 255.
|
||||
var xvalues = [256]byte{
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 255, 255, 255, 255, 255, 255,
|
||||
255, 10, 11, 12, 13, 14, 15, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 10, 11, 12, 13, 14, 15, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255, 255,
|
||||
}
|
||||
|
||||
// xtob converts hex characters x1 and x2 into a byte.
|
||||
func xtob(x1, x2 byte) (byte, bool) {
|
||||
b1 := xvalues[x1]
|
||||
b2 := xvalues[x2]
|
||||
return (b1 << 4) | b2, b1 != 255 && b2 != 255
|
||||
}
|
||||
245
backend/vendor/github.com/google/uuid/uuid.go
generated
vendored
Normal file
245
backend/vendor/github.com/google/uuid/uuid.go
generated
vendored
Normal file
@@ -0,0 +1,245 @@
|
||||
// Copyright 2018 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"crypto/rand"
|
||||
"encoding/hex"
|
||||
"errors"
|
||||
"fmt"
|
||||
"io"
|
||||
"strings"
|
||||
)
|
||||
|
||||
// A UUID is a 128 bit (16 byte) Universal Unique IDentifier as defined in RFC
|
||||
// 4122.
|
||||
type UUID [16]byte
|
||||
|
||||
// A Version represents a UUID's version.
|
||||
type Version byte
|
||||
|
||||
// A Variant represents a UUID's variant.
|
||||
type Variant byte
|
||||
|
||||
// Constants returned by Variant.
|
||||
const (
|
||||
Invalid = Variant(iota) // Invalid UUID
|
||||
RFC4122 // The variant specified in RFC4122
|
||||
Reserved // Reserved, NCS backward compatibility.
|
||||
Microsoft // Reserved, Microsoft Corporation backward compatibility.
|
||||
Future // Reserved for future definition.
|
||||
)
|
||||
|
||||
var rander = rand.Reader // random function
|
||||
|
||||
// Parse decodes s into a UUID or returns an error. Both the standard UUID
|
||||
// forms of xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx and
|
||||
// urn:uuid:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx are decoded as well as the
|
||||
// Microsoft encoding {xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx} and the raw hex
|
||||
// encoding: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.
|
||||
func Parse(s string) (UUID, error) {
|
||||
var uuid UUID
|
||||
switch len(s) {
|
||||
// xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
|
||||
case 36:
|
||||
|
||||
// urn:uuid:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
|
||||
case 36 + 9:
|
||||
if strings.ToLower(s[:9]) != "urn:uuid:" {
|
||||
return uuid, fmt.Errorf("invalid urn prefix: %q", s[:9])
|
||||
}
|
||||
s = s[9:]
|
||||
|
||||
// {xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx}
|
||||
case 36 + 2:
|
||||
s = s[1:]
|
||||
|
||||
// xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
case 32:
|
||||
var ok bool
|
||||
for i := range uuid {
|
||||
uuid[i], ok = xtob(s[i*2], s[i*2+1])
|
||||
if !ok {
|
||||
return uuid, errors.New("invalid UUID format")
|
||||
}
|
||||
}
|
||||
return uuid, nil
|
||||
default:
|
||||
return uuid, fmt.Errorf("invalid UUID length: %d", len(s))
|
||||
}
|
||||
// s is now at least 36 bytes long
|
||||
// it must be of the form xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
|
||||
if s[8] != '-' || s[13] != '-' || s[18] != '-' || s[23] != '-' {
|
||||
return uuid, errors.New("invalid UUID format")
|
||||
}
|
||||
for i, x := range [16]int{
|
||||
0, 2, 4, 6,
|
||||
9, 11,
|
||||
14, 16,
|
||||
19, 21,
|
||||
24, 26, 28, 30, 32, 34} {
|
||||
v, ok := xtob(s[x], s[x+1])
|
||||
if !ok {
|
||||
return uuid, errors.New("invalid UUID format")
|
||||
}
|
||||
uuid[i] = v
|
||||
}
|
||||
return uuid, nil
|
||||
}
|
||||
|
||||
// ParseBytes is like Parse, except it parses a byte slice instead of a string.
|
||||
func ParseBytes(b []byte) (UUID, error) {
|
||||
var uuid UUID
|
||||
switch len(b) {
|
||||
case 36: // xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
|
||||
case 36 + 9: // urn:uuid:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
|
||||
if !bytes.Equal(bytes.ToLower(b[:9]), []byte("urn:uuid:")) {
|
||||
return uuid, fmt.Errorf("invalid urn prefix: %q", b[:9])
|
||||
}
|
||||
b = b[9:]
|
||||
case 36 + 2: // {xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx}
|
||||
b = b[1:]
|
||||
case 32: // xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
|
||||
var ok bool
|
||||
for i := 0; i < 32; i += 2 {
|
||||
uuid[i/2], ok = xtob(b[i], b[i+1])
|
||||
if !ok {
|
||||
return uuid, errors.New("invalid UUID format")
|
||||
}
|
||||
}
|
||||
return uuid, nil
|
||||
default:
|
||||
return uuid, fmt.Errorf("invalid UUID length: %d", len(b))
|
||||
}
|
||||
// s is now at least 36 bytes long
|
||||
// it must be of the form xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
|
||||
if b[8] != '-' || b[13] != '-' || b[18] != '-' || b[23] != '-' {
|
||||
return uuid, errors.New("invalid UUID format")
|
||||
}
|
||||
for i, x := range [16]int{
|
||||
0, 2, 4, 6,
|
||||
9, 11,
|
||||
14, 16,
|
||||
19, 21,
|
||||
24, 26, 28, 30, 32, 34} {
|
||||
v, ok := xtob(b[x], b[x+1])
|
||||
if !ok {
|
||||
return uuid, errors.New("invalid UUID format")
|
||||
}
|
||||
uuid[i] = v
|
||||
}
|
||||
return uuid, nil
|
||||
}
|
||||
|
||||
// MustParse is like Parse but panics if the string cannot be parsed.
|
||||
// It simplifies safe initialization of global variables holding compiled UUIDs.
|
||||
func MustParse(s string) UUID {
|
||||
uuid, err := Parse(s)
|
||||
if err != nil {
|
||||
panic(`uuid: Parse(` + s + `): ` + err.Error())
|
||||
}
|
||||
return uuid
|
||||
}
|
||||
|
||||
// FromBytes creates a new UUID from a byte slice. Returns an error if the slice
|
||||
// does not have a length of 16. The bytes are copied from the slice.
|
||||
func FromBytes(b []byte) (uuid UUID, err error) {
|
||||
err = uuid.UnmarshalBinary(b)
|
||||
return uuid, err
|
||||
}
|
||||
|
||||
// Must returns uuid if err is nil and panics otherwise.
|
||||
func Must(uuid UUID, err error) UUID {
|
||||
if err != nil {
|
||||
panic(err)
|
||||
}
|
||||
return uuid
|
||||
}
|
||||
|
||||
// String returns the string form of uuid, xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
|
||||
// , or "" if uuid is invalid.
|
||||
func (uuid UUID) String() string {
|
||||
var buf [36]byte
|
||||
encodeHex(buf[:], uuid)
|
||||
return string(buf[:])
|
||||
}
|
||||
|
||||
// URN returns the RFC 2141 URN form of uuid,
|
||||
// urn:uuid:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx, or "" if uuid is invalid.
|
||||
func (uuid UUID) URN() string {
|
||||
var buf [36 + 9]byte
|
||||
copy(buf[:], "urn:uuid:")
|
||||
encodeHex(buf[9:], uuid)
|
||||
return string(buf[:])
|
||||
}
|
||||
|
||||
func encodeHex(dst []byte, uuid UUID) {
|
||||
hex.Encode(dst, uuid[:4])
|
||||
dst[8] = '-'
|
||||
hex.Encode(dst[9:13], uuid[4:6])
|
||||
dst[13] = '-'
|
||||
hex.Encode(dst[14:18], uuid[6:8])
|
||||
dst[18] = '-'
|
||||
hex.Encode(dst[19:23], uuid[8:10])
|
||||
dst[23] = '-'
|
||||
hex.Encode(dst[24:], uuid[10:])
|
||||
}
|
||||
|
||||
// Variant returns the variant encoded in uuid.
|
||||
func (uuid UUID) Variant() Variant {
|
||||
switch {
|
||||
case (uuid[8] & 0xc0) == 0x80:
|
||||
return RFC4122
|
||||
case (uuid[8] & 0xe0) == 0xc0:
|
||||
return Microsoft
|
||||
case (uuid[8] & 0xe0) == 0xe0:
|
||||
return Future
|
||||
default:
|
||||
return Reserved
|
||||
}
|
||||
}
|
||||
|
||||
// Version returns the version of uuid.
|
||||
func (uuid UUID) Version() Version {
|
||||
return Version(uuid[6] >> 4)
|
||||
}
|
||||
|
||||
func (v Version) String() string {
|
||||
if v > 15 {
|
||||
return fmt.Sprintf("BAD_VERSION_%d", v)
|
||||
}
|
||||
return fmt.Sprintf("VERSION_%d", v)
|
||||
}
|
||||
|
||||
func (v Variant) String() string {
|
||||
switch v {
|
||||
case RFC4122:
|
||||
return "RFC4122"
|
||||
case Reserved:
|
||||
return "Reserved"
|
||||
case Microsoft:
|
||||
return "Microsoft"
|
||||
case Future:
|
||||
return "Future"
|
||||
case Invalid:
|
||||
return "Invalid"
|
||||
}
|
||||
return fmt.Sprintf("BadVariant%d", int(v))
|
||||
}
|
||||
|
||||
// SetRand sets the random number generator to r, which implements io.Reader.
|
||||
// If r.Read returns an error when the package requests random data then
|
||||
// a panic will be issued.
|
||||
//
|
||||
// Calling SetRand with nil sets the random number generator to the default
|
||||
// generator.
|
||||
func SetRand(r io.Reader) {
|
||||
if r == nil {
|
||||
rander = rand.Reader
|
||||
return
|
||||
}
|
||||
rander = r
|
||||
}
|
||||
44
backend/vendor/github.com/google/uuid/version1.go
generated
vendored
Normal file
44
backend/vendor/github.com/google/uuid/version1.go
generated
vendored
Normal file
@@ -0,0 +1,44 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import (
|
||||
"encoding/binary"
|
||||
)
|
||||
|
||||
// NewUUID returns a Version 1 UUID based on the current NodeID and clock
|
||||
// sequence, and the current time. If the NodeID has not been set by SetNodeID
|
||||
// or SetNodeInterface then it will be set automatically. If the NodeID cannot
|
||||
// be set NewUUID returns nil. If clock sequence has not been set by
|
||||
// SetClockSequence then it will be set automatically. If GetTime fails to
|
||||
// return the current NewUUID returns nil and an error.
|
||||
//
|
||||
// In most cases, New should be used.
|
||||
func NewUUID() (UUID, error) {
|
||||
nodeMu.Lock()
|
||||
if nodeID == zeroID {
|
||||
setNodeInterface("")
|
||||
}
|
||||
nodeMu.Unlock()
|
||||
|
||||
var uuid UUID
|
||||
now, seq, err := GetTime()
|
||||
if err != nil {
|
||||
return uuid, err
|
||||
}
|
||||
|
||||
timeLow := uint32(now & 0xffffffff)
|
||||
timeMid := uint16((now >> 32) & 0xffff)
|
||||
timeHi := uint16((now >> 48) & 0x0fff)
|
||||
timeHi |= 0x1000 // Version 1
|
||||
|
||||
binary.BigEndian.PutUint32(uuid[0:], timeLow)
|
||||
binary.BigEndian.PutUint16(uuid[4:], timeMid)
|
||||
binary.BigEndian.PutUint16(uuid[6:], timeHi)
|
||||
binary.BigEndian.PutUint16(uuid[8:], seq)
|
||||
copy(uuid[10:], nodeID[:])
|
||||
|
||||
return uuid, nil
|
||||
}
|
||||
38
backend/vendor/github.com/google/uuid/version4.go
generated
vendored
Normal file
38
backend/vendor/github.com/google/uuid/version4.go
generated
vendored
Normal file
@@ -0,0 +1,38 @@
|
||||
// Copyright 2016 Google Inc. All rights reserved.
|
||||
// Use of this source code is governed by a BSD-style
|
||||
// license that can be found in the LICENSE file.
|
||||
|
||||
package uuid
|
||||
|
||||
import "io"
|
||||
|
||||
// New creates a new random UUID or panics. New is equivalent to
|
||||
// the expression
|
||||
//
|
||||
// uuid.Must(uuid.NewRandom())
|
||||
func New() UUID {
|
||||
return Must(NewRandom())
|
||||
}
|
||||
|
||||
// NewRandom returns a Random (Version 4) UUID.
|
||||
//
|
||||
// The strength of the UUIDs is based on the strength of the crypto/rand
|
||||
// package.
|
||||
//
|
||||
// A note about uniqueness derived from the UUID Wikipedia entry:
|
||||
//
|
||||
// Randomly generated UUIDs have 122 random bits. One's annual risk of being
|
||||
// hit by a meteorite is estimated to be one chance in 17 billion, that
|
||||
// means the probability is about 0.00000000006 (6 × 10−11),
|
||||
// equivalent to the odds of creating a few tens of trillions of UUIDs in a
|
||||
// year and having one duplicate.
|
||||
func NewRandom() (UUID, error) {
|
||||
var uuid UUID
|
||||
_, err := io.ReadFull(rander, uuid[:])
|
||||
if err != nil {
|
||||
return Nil, err
|
||||
}
|
||||
uuid[6] = (uuid[6] & 0x0f) | 0x40 // Version 4
|
||||
uuid[8] = (uuid[8] & 0x3f) | 0x80 // Variant is 10
|
||||
return uuid, nil
|
||||
}
|
||||
24
backend/vendor/github.com/huandu/xstrings/.gitignore
generated
vendored
Normal file
24
backend/vendor/github.com/huandu/xstrings/.gitignore
generated
vendored
Normal file
@@ -0,0 +1,24 @@
|
||||
# Compiled Object files, Static and Dynamic libs (Shared Objects)
|
||||
*.o
|
||||
*.a
|
||||
*.so
|
||||
|
||||
# Folders
|
||||
_obj
|
||||
_test
|
||||
|
||||
# Architecture specific extensions/prefixes
|
||||
*.[568vq]
|
||||
[568vq].out
|
||||
|
||||
*.cgo1.go
|
||||
*.cgo2.c
|
||||
_cgo_defun.c
|
||||
_cgo_gotypes.go
|
||||
_cgo_export.*
|
||||
|
||||
_testmain.go
|
||||
|
||||
*.exe
|
||||
*.test
|
||||
*.prof
|
||||
1
backend/vendor/github.com/huandu/xstrings/.travis.yml
generated
vendored
Normal file
1
backend/vendor/github.com/huandu/xstrings/.travis.yml
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
language: go
|
||||
23
backend/vendor/github.com/huandu/xstrings/CONTRIBUTING.md
generated
vendored
Normal file
23
backend/vendor/github.com/huandu/xstrings/CONTRIBUTING.md
generated
vendored
Normal file
@@ -0,0 +1,23 @@
|
||||
# Contributing #
|
||||
|
||||
Thanks for your contribution in advance. No matter what you will contribute to this project, pull request or bug report or feature discussion, it's always highly appreciated.
|
||||
|
||||
## New API or feature ##
|
||||
|
||||
I want to speak more about how to add new functions to this package.
|
||||
|
||||
Package `xstring` is a collection of useful string functions which should be implemented in Go. It's a bit subject to say which function should be included and which should not. I set up following rules in order to make it clear and as objective as possible.
|
||||
|
||||
* Rule 1: Only string algorithm, which takes string as input, can be included.
|
||||
* Rule 2: If a function has been implemented in package `string`, it must not be included.
|
||||
* Rule 3: If a function is not language neutral, it must not be included.
|
||||
* Rule 4: If a function is a part of standard library in other languages, it can be included.
|
||||
* Rule 5: If a function is quite useful in some famous framework or library, it can be included.
|
||||
|
||||
New function must be discussed in project issues before submitting any code. If a pull request with new functions is sent without any ref issue, it will be rejected.
|
||||
|
||||
## Pull request ##
|
||||
|
||||
Pull request is always welcome. Just make sure you have run `go fmt` and all test cases passed before submit.
|
||||
|
||||
If the pull request is to add a new API or feature, don't forget to update README.md and add new API in function list.
|
||||
22
backend/vendor/github.com/huandu/xstrings/LICENSE
generated
vendored
Normal file
22
backend/vendor/github.com/huandu/xstrings/LICENSE
generated
vendored
Normal file
@@ -0,0 +1,22 @@
|
||||
The MIT License (MIT)
|
||||
|
||||
Copyright (c) 2015 Huan Du
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in all
|
||||
copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
|
||||
115
backend/vendor/github.com/huandu/xstrings/README.md
generated
vendored
Normal file
115
backend/vendor/github.com/huandu/xstrings/README.md
generated
vendored
Normal file
@@ -0,0 +1,115 @@
|
||||
# xstrings #
|
||||
|
||||
[](https://travis-ci.org/huandu/xstrings)
|
||||
[](https://godoc.org/github.com/huandu/xstrings)
|
||||
|
||||
Go package [xstrings](https://godoc.org/github.com/huandu/xstrings) is a collection of string functions, which are widely used in other languages but absent in Go package [strings](http://golang.org/pkg/strings).
|
||||
|
||||
All functions are well tested and carefully tuned for performance.
|
||||
|
||||
## Propose a new function ##
|
||||
|
||||
Please review [contributing guideline](CONTRIBUTING.md) and [create new issue](https://github.com/huandu/xstrings/issues) to state why it should be included.
|
||||
|
||||
## Install ##
|
||||
|
||||
Use `go get` to install this library.
|
||||
|
||||
go get github.com/huandu/xstrings
|
||||
|
||||
## API document ##
|
||||
|
||||
See [GoDoc](https://godoc.org/github.com/huandu/xstrings) for full document.
|
||||
|
||||
## Function list ##
|
||||
|
||||
Go functions have a unique naming style. One, who has experience in other language but new in Go, may have difficulties to find out right string function to use.
|
||||
|
||||
Here is a list of functions in [strings](http://golang.org/pkg/strings) and [xstrings](https://godoc.org/github.com/huandu/xstrings) with enough extra information about how to map these functions to their friends in other languages. Hope this list could be helpful for fresh gophers.
|
||||
|
||||
### Package `xstrings` functions ###
|
||||
|
||||
*Keep this table sorted by Function in ascending order.*
|
||||
|
||||
| Function | Friends | # |
|
||||
| -------- | ------- | --- |
|
||||
| [Center](https://godoc.org/github.com/huandu/xstrings#Center) | `str.center` in Python; `String#center` in Ruby | [#30](https://github.com/huandu/xstrings/issues/30) |
|
||||
| [Count](https://godoc.org/github.com/huandu/xstrings#Count) | `String#count` in Ruby | [#16](https://github.com/huandu/xstrings/issues/16) |
|
||||
| [Delete](https://godoc.org/github.com/huandu/xstrings#Delete) | `String#delete` in Ruby | [#17](https://github.com/huandu/xstrings/issues/17) |
|
||||
| [ExpandTabs](https://godoc.org/github.com/huandu/xstrings#ExpandTabs) | `str.expandtabs` in Python | [#27](https://github.com/huandu/xstrings/issues/27) |
|
||||
| [FirstRuneToLower](https://godoc.org/github.com/huandu/xstrings#FirstRuneToLower) | `lcfirst` in PHP or Perl | [#15](https://github.com/huandu/xstrings/issues/15) |
|
||||
| [FirstRuneToUpper](https://godoc.org/github.com/huandu/xstrings#FirstRuneToUpper) | `String#capitalize` in Ruby; `ucfirst` in PHP or Perl | [#15](https://github.com/huandu/xstrings/issues/15) |
|
||||
| [Insert](https://godoc.org/github.com/huandu/xstrings#Insert) | `String#insert` in Ruby | [#18](https://github.com/huandu/xstrings/issues/18) |
|
||||
| [LastPartition](https://godoc.org/github.com/huandu/xstrings#LastPartition) | `str.rpartition` in Python; `String#rpartition` in Ruby | [#19](https://github.com/huandu/xstrings/issues/19) |
|
||||
| [LeftJustify](https://godoc.org/github.com/huandu/xstrings#LeftJustify) | `str.ljust` in Python; `String#ljust` in Ruby | [#28](https://github.com/huandu/xstrings/issues/28) |
|
||||
| [Len](https://godoc.org/github.com/huandu/xstrings#Len) | `mb_strlen` in PHP | [#23](https://github.com/huandu/xstrings/issues/23) |
|
||||
| [Partition](https://godoc.org/github.com/huandu/xstrings#Partition) | `str.partition` in Python; `String#partition` in Ruby | [#10](https://github.com/huandu/xstrings/issues/10) |
|
||||
| [Reverse](https://godoc.org/github.com/huandu/xstrings#Reverse) | `String#reverse` in Ruby; `strrev` in PHP; `reverse` in Perl | [#7](https://github.com/huandu/xstrings/issues/7) |
|
||||
| [RightJustify](https://godoc.org/github.com/huandu/xstrings#RightJustify) | `str.rjust` in Python; `String#rjust` in Ruby | [#29](https://github.com/huandu/xstrings/issues/29) |
|
||||
| [RuneWidth](https://godoc.org/github.com/huandu/xstrings#RuneWidth) | - | [#27](https://github.com/huandu/xstrings/issues/27) |
|
||||
| [Scrub](https://godoc.org/github.com/huandu/xstrings#Scrub) | `String#scrub` in Ruby | [#20](https://github.com/huandu/xstrings/issues/20) |
|
||||
| [Shuffle](https://godoc.org/github.com/huandu/xstrings#Shuffle) | `str_shuffle` in PHP | [#13](https://github.com/huandu/xstrings/issues/13) |
|
||||
| [ShuffleSource](https://godoc.org/github.com/huandu/xstrings#ShuffleSource) | `str_shuffle` in PHP | [#13](https://github.com/huandu/xstrings/issues/13) |
|
||||
| [Slice](https://godoc.org/github.com/huandu/xstrings#Slice) | `mb_substr` in PHP | [#9](https://github.com/huandu/xstrings/issues/9) |
|
||||
| [Squeeze](https://godoc.org/github.com/huandu/xstrings#Squeeze) | `String#squeeze` in Ruby | [#11](https://github.com/huandu/xstrings/issues/11) |
|
||||
| [Successor](https://godoc.org/github.com/huandu/xstrings#Successor) | `String#succ` or `String#next` in Ruby | [#22](https://github.com/huandu/xstrings/issues/22) |
|
||||
| [SwapCase](https://godoc.org/github.com/huandu/xstrings#SwapCase) | `str.swapcase` in Python; `String#swapcase` in Ruby | [#12](https://github.com/huandu/xstrings/issues/12) |
|
||||
| [ToCamelCase](https://godoc.org/github.com/huandu/xstrings#ToCamelCase) | `String#camelize` in RoR | [#1](https://github.com/huandu/xstrings/issues/1) |
|
||||
| [ToKebab](https://godoc.org/github.com/huandu/xstrings#ToKebabCase) | - | [#41](https://github.com/huandu/xstrings/issues/41) |
|
||||
| [ToSnakeCase](https://godoc.org/github.com/huandu/xstrings#ToSnakeCase) | `String#underscore` in RoR | [#1](https://github.com/huandu/xstrings/issues/1) |
|
||||
| [Translate](https://godoc.org/github.com/huandu/xstrings#Translate) | `str.translate` in Python; `String#tr` in Ruby; `strtr` in PHP; `tr///` in Perl | [#21](https://github.com/huandu/xstrings/issues/21) |
|
||||
| [Width](https://godoc.org/github.com/huandu/xstrings#Width) | `mb_strwidth` in PHP | [#26](https://github.com/huandu/xstrings/issues/26) |
|
||||
| [WordCount](https://godoc.org/github.com/huandu/xstrings#WordCount) | `str_word_count` in PHP | [#14](https://github.com/huandu/xstrings/issues/14) |
|
||||
| [WordSplit](https://godoc.org/github.com/huandu/xstrings#WordSplit) | - | [#14](https://github.com/huandu/xstrings/issues/14) |
|
||||
|
||||
### Package `strings` functions ###
|
||||
|
||||
*Keep this table sorted by Function in ascending order.*
|
||||
|
||||
| Function | Friends |
|
||||
| -------- | ------- |
|
||||
| [Contains](http://golang.org/pkg/strings/#Contains) | `String#include?` in Ruby |
|
||||
| [ContainsAny](http://golang.org/pkg/strings/#ContainsAny) | - |
|
||||
| [ContainsRune](http://golang.org/pkg/strings/#ContainsRune) | - |
|
||||
| [Count](http://golang.org/pkg/strings/#Count) | `str.count` in Python; `substr_count` in PHP |
|
||||
| [EqualFold](http://golang.org/pkg/strings/#EqualFold) | `stricmp` in PHP; `String#casecmp` in Ruby |
|
||||
| [Fields](http://golang.org/pkg/strings/#Fields) | `str.split` in Python; `split` in Perl; `String#split` in Ruby |
|
||||
| [FieldsFunc](http://golang.org/pkg/strings/#FieldsFunc) | - |
|
||||
| [HasPrefix](http://golang.org/pkg/strings/#HasPrefix) | `str.startswith` in Python; `String#start_with?` in Ruby |
|
||||
| [HasSuffix](http://golang.org/pkg/strings/#HasSuffix) | `str.endswith` in Python; `String#end_with?` in Ruby |
|
||||
| [Index](http://golang.org/pkg/strings/#Index) | `str.index` in Python; `String#index` in Ruby; `strpos` in PHP; `index` in Perl |
|
||||
| [IndexAny](http://golang.org/pkg/strings/#IndexAny) | - |
|
||||
| [IndexByte](http://golang.org/pkg/strings/#IndexByte) | - |
|
||||
| [IndexFunc](http://golang.org/pkg/strings/#IndexFunc) | - |
|
||||
| [IndexRune](http://golang.org/pkg/strings/#IndexRune) | - |
|
||||
| [Join](http://golang.org/pkg/strings/#Join) | `str.join` in Python; `Array#join` in Ruby; `implode` in PHP; `join` in Perl |
|
||||
| [LastIndex](http://golang.org/pkg/strings/#LastIndex) | `str.rindex` in Python; `String#rindex`; `strrpos` in PHP; `rindex` in Perl |
|
||||
| [LastIndexAny](http://golang.org/pkg/strings/#LastIndexAny) | - |
|
||||
| [LastIndexFunc](http://golang.org/pkg/strings/#LastIndexFunc) | - |
|
||||
| [Map](http://golang.org/pkg/strings/#Map) | `String#each_codepoint` in Ruby |
|
||||
| [Repeat](http://golang.org/pkg/strings/#Repeat) | operator `*` in Python and Ruby; `str_repeat` in PHP |
|
||||
| [Replace](http://golang.org/pkg/strings/#Replace) | `str.replace` in Python; `String#sub` in Ruby; `str_replace` in PHP |
|
||||
| [Split](http://golang.org/pkg/strings/#Split) | `str.split` in Python; `String#split` in Ruby; `explode` in PHP; `split` in Perl |
|
||||
| [SplitAfter](http://golang.org/pkg/strings/#SplitAfter) | - |
|
||||
| [SplitAfterN](http://golang.org/pkg/strings/#SplitAfterN) | - |
|
||||
| [SplitN](http://golang.org/pkg/strings/#SplitN) | `str.split` in Python; `String#split` in Ruby; `explode` in PHP; `split` in Perl |
|
||||
| [Title](http://golang.org/pkg/strings/#Title) | `str.title` in Python |
|
||||
| [ToLower](http://golang.org/pkg/strings/#ToLower) | `str.lower` in Python; `String#downcase` in Ruby; `strtolower` in PHP; `lc` in Perl |
|
||||
| [ToLowerSpecial](http://golang.org/pkg/strings/#ToLowerSpecial) | - |
|
||||
| [ToTitle](http://golang.org/pkg/strings/#ToTitle) | - |
|
||||
| [ToTitleSpecial](http://golang.org/pkg/strings/#ToTitleSpecial) | - |
|
||||
| [ToUpper](http://golang.org/pkg/strings/#ToUpper) | `str.upper` in Python; `String#upcase` in Ruby; `strtoupper` in PHP; `uc` in Perl |
|
||||
| [ToUpperSpecial](http://golang.org/pkg/strings/#ToUpperSpecial) | - |
|
||||
| [Trim](http://golang.org/pkg/strings/#Trim) | `str.strip` in Python; `String#strip` in Ruby; `trim` in PHP |
|
||||
| [TrimFunc](http://golang.org/pkg/strings/#TrimFunc) | - |
|
||||
| [TrimLeft](http://golang.org/pkg/strings/#TrimLeft) | `str.lstrip` in Python; `String#lstrip` in Ruby; `ltrim` in PHP |
|
||||
| [TrimLeftFunc](http://golang.org/pkg/strings/#TrimLeftFunc) | - |
|
||||
| [TrimPrefix](http://golang.org/pkg/strings/#TrimPrefix) | - |
|
||||
| [TrimRight](http://golang.org/pkg/strings/#TrimRight) | `str.rstrip` in Python; `String#rstrip` in Ruby; `rtrim` in PHP |
|
||||
| [TrimRightFunc](http://golang.org/pkg/strings/#TrimRightFunc) | - |
|
||||
| [TrimSpace](http://golang.org/pkg/strings/#TrimSpace) | `str.strip` in Python; `String#strip` in Ruby; `trim` in PHP |
|
||||
| [TrimSuffix](http://golang.org/pkg/strings/#TrimSuffix) | `String#chomp` in Ruby; `chomp` in Perl |
|
||||
|
||||
## License ##
|
||||
|
||||
This library is licensed under MIT license. See LICENSE for details.
|
||||
25
backend/vendor/github.com/huandu/xstrings/common.go
generated
vendored
Normal file
25
backend/vendor/github.com/huandu/xstrings/common.go
generated
vendored
Normal file
@@ -0,0 +1,25 @@
|
||||
// Copyright 2015 Huan Du. All rights reserved.
|
||||
// Licensed under the MIT license that can be found in the LICENSE file.
|
||||
|
||||
package xstrings
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
)
|
||||
|
||||
const bufferMaxInitGrowSize = 2048
|
||||
|
||||
// Lazy initialize a buffer.
|
||||
func allocBuffer(orig, cur string) *bytes.Buffer {
|
||||
output := &bytes.Buffer{}
|
||||
maxSize := len(orig) * 4
|
||||
|
||||
// Avoid to reserve too much memory at once.
|
||||
if maxSize > bufferMaxInitGrowSize {
|
||||
maxSize = bufferMaxInitGrowSize
|
||||
}
|
||||
|
||||
output.Grow(maxSize)
|
||||
output.WriteString(orig[:len(orig)-len(cur)])
|
||||
return output
|
||||
}
|
||||
400
backend/vendor/github.com/huandu/xstrings/convert.go
generated
vendored
Normal file
400
backend/vendor/github.com/huandu/xstrings/convert.go
generated
vendored
Normal file
@@ -0,0 +1,400 @@
|
||||
// Copyright 2015 Huan Du. All rights reserved.
|
||||
// Licensed under the MIT license that can be found in the LICENSE file.
|
||||
|
||||
package xstrings
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"math/rand"
|
||||
"unicode"
|
||||
"unicode/utf8"
|
||||
)
|
||||
|
||||
// ToCamelCase can convert all lower case characters behind underscores
|
||||
// to upper case character.
|
||||
// Underscore character will be removed in result except following cases.
|
||||
// * More than 1 underscore.
|
||||
// "a__b" => "A_B"
|
||||
// * At the beginning of string.
|
||||
// "_a" => "_A"
|
||||
// * At the end of string.
|
||||
// "ab_" => "Ab_"
|
||||
func ToCamelCase(str string) string {
|
||||
if len(str) == 0 {
|
||||
return ""
|
||||
}
|
||||
|
||||
buf := &bytes.Buffer{}
|
||||
var r0, r1 rune
|
||||
var size int
|
||||
|
||||
// leading '_' will appear in output.
|
||||
for len(str) > 0 {
|
||||
r0, size = utf8.DecodeRuneInString(str)
|
||||
str = str[size:]
|
||||
|
||||
if r0 != '_' {
|
||||
break
|
||||
}
|
||||
|
||||
buf.WriteRune(r0)
|
||||
}
|
||||
|
||||
if len(str) == 0 {
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
r0 = unicode.ToUpper(r0)
|
||||
|
||||
for len(str) > 0 {
|
||||
r1 = r0
|
||||
r0, size = utf8.DecodeRuneInString(str)
|
||||
str = str[size:]
|
||||
|
||||
if r1 == '_' && r0 == '_' {
|
||||
buf.WriteRune(r1)
|
||||
continue
|
||||
}
|
||||
|
||||
if r1 == '_' {
|
||||
r0 = unicode.ToUpper(r0)
|
||||
} else {
|
||||
r0 = unicode.ToLower(r0)
|
||||
}
|
||||
|
||||
if r1 != '_' {
|
||||
buf.WriteRune(r1)
|
||||
}
|
||||
}
|
||||
|
||||
buf.WriteRune(r0)
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// ToSnakeCase can convert all upper case characters in a string to
|
||||
// snake case format.
|
||||
//
|
||||
// Some samples.
|
||||
// "FirstName" => "first_name"
|
||||
// "HTTPServer" => "http_server"
|
||||
// "NoHTTPS" => "no_https"
|
||||
// "GO_PATH" => "go_path"
|
||||
// "GO PATH" => "go_path" // space is converted to underscore.
|
||||
// "GO-PATH" => "go_path" // hyphen is converted to underscore.
|
||||
// "HTTP2XX" => "http_2xx" // insert an underscore before a number and after an alphabet.
|
||||
// "http2xx" => "http_2xx"
|
||||
// "HTTP20xOK" => "http_20x_ok"
|
||||
func ToSnakeCase(str string) string {
|
||||
return camelCaseToLowerCase(str, '_')
|
||||
}
|
||||
|
||||
// ToKebabCase can convert all upper case characters in a string to
|
||||
// kebab case format.
|
||||
//
|
||||
// Some samples.
|
||||
// "FirstName" => "first-name"
|
||||
// "HTTPServer" => "http-server"
|
||||
// "NoHTTPS" => "no-https"
|
||||
// "GO_PATH" => "go-path"
|
||||
// "GO PATH" => "go-path" // space is converted to '-'.
|
||||
// "GO-PATH" => "go-path" // hyphen is converted to '-'.
|
||||
// "HTTP2XX" => "http-2xx" // insert a '-' before a number and after an alphabet.
|
||||
// "http2xx" => "http-2xx"
|
||||
// "HTTP20xOK" => "http-20x-ok"
|
||||
func ToKebabCase(str string) string {
|
||||
return camelCaseToLowerCase(str, '-')
|
||||
}
|
||||
|
||||
func camelCaseToLowerCase(str string, connector rune) string {
|
||||
if len(str) == 0 {
|
||||
return ""
|
||||
}
|
||||
|
||||
buf := &bytes.Buffer{}
|
||||
var prev, r0, r1 rune
|
||||
var size int
|
||||
|
||||
r0 = connector
|
||||
|
||||
for len(str) > 0 {
|
||||
prev = r0
|
||||
r0, size = utf8.DecodeRuneInString(str)
|
||||
str = str[size:]
|
||||
|
||||
switch {
|
||||
case r0 == utf8.RuneError:
|
||||
buf.WriteRune(r0)
|
||||
|
||||
case unicode.IsUpper(r0):
|
||||
if prev != connector && !unicode.IsNumber(prev) {
|
||||
buf.WriteRune(connector)
|
||||
}
|
||||
|
||||
buf.WriteRune(unicode.ToLower(r0))
|
||||
|
||||
if len(str) == 0 {
|
||||
break
|
||||
}
|
||||
|
||||
r0, size = utf8.DecodeRuneInString(str)
|
||||
str = str[size:]
|
||||
|
||||
if !unicode.IsUpper(r0) {
|
||||
buf.WriteRune(r0)
|
||||
break
|
||||
}
|
||||
|
||||
// find next non-upper-case character and insert connector properly.
|
||||
// it's designed to convert `HTTPServer` to `http_server`.
|
||||
// if there are more than 2 adjacent upper case characters in a word,
|
||||
// treat them as an abbreviation plus a normal word.
|
||||
for len(str) > 0 {
|
||||
r1 = r0
|
||||
r0, size = utf8.DecodeRuneInString(str)
|
||||
str = str[size:]
|
||||
|
||||
if r0 == utf8.RuneError {
|
||||
buf.WriteRune(unicode.ToLower(r1))
|
||||
buf.WriteRune(r0)
|
||||
break
|
||||
}
|
||||
|
||||
if !unicode.IsUpper(r0) {
|
||||
if r0 == '_' || r0 == ' ' || r0 == '-' {
|
||||
r0 = connector
|
||||
|
||||
buf.WriteRune(unicode.ToLower(r1))
|
||||
} else if unicode.IsNumber(r0) {
|
||||
// treat a number as an upper case rune
|
||||
// so that both `http2xx` and `HTTP2XX` can be converted to `http_2xx`.
|
||||
buf.WriteRune(unicode.ToLower(r1))
|
||||
buf.WriteRune(connector)
|
||||
buf.WriteRune(r0)
|
||||
} else {
|
||||
buf.WriteRune(connector)
|
||||
buf.WriteRune(unicode.ToLower(r1))
|
||||
buf.WriteRune(r0)
|
||||
}
|
||||
|
||||
break
|
||||
}
|
||||
|
||||
buf.WriteRune(unicode.ToLower(r1))
|
||||
}
|
||||
|
||||
if len(str) == 0 || r0 == connector {
|
||||
buf.WriteRune(unicode.ToLower(r0))
|
||||
}
|
||||
|
||||
case unicode.IsNumber(r0):
|
||||
if prev != connector && !unicode.IsNumber(prev) {
|
||||
buf.WriteRune(connector)
|
||||
}
|
||||
|
||||
buf.WriteRune(r0)
|
||||
|
||||
default:
|
||||
if r0 == ' ' || r0 == '-' || r0 == '_' {
|
||||
r0 = connector
|
||||
}
|
||||
|
||||
buf.WriteRune(r0)
|
||||
}
|
||||
}
|
||||
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// SwapCase will swap characters case from upper to lower or lower to upper.
|
||||
func SwapCase(str string) string {
|
||||
var r rune
|
||||
var size int
|
||||
|
||||
buf := &bytes.Buffer{}
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
|
||||
switch {
|
||||
case unicode.IsUpper(r):
|
||||
buf.WriteRune(unicode.ToLower(r))
|
||||
|
||||
case unicode.IsLower(r):
|
||||
buf.WriteRune(unicode.ToUpper(r))
|
||||
|
||||
default:
|
||||
buf.WriteRune(r)
|
||||
}
|
||||
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// FirstRuneToUpper converts first rune to upper case if necessary.
|
||||
func FirstRuneToUpper(str string) string {
|
||||
if str == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
r, size := utf8.DecodeRuneInString(str)
|
||||
|
||||
if !unicode.IsLower(r) {
|
||||
return str
|
||||
}
|
||||
|
||||
buf := &bytes.Buffer{}
|
||||
buf.WriteRune(unicode.ToUpper(r))
|
||||
buf.WriteString(str[size:])
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// FirstRuneToLower converts first rune to lower case if necessary.
|
||||
func FirstRuneToLower(str string) string {
|
||||
if str == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
r, size := utf8.DecodeRuneInString(str)
|
||||
|
||||
if !unicode.IsUpper(r) {
|
||||
return str
|
||||
}
|
||||
|
||||
buf := &bytes.Buffer{}
|
||||
buf.WriteRune(unicode.ToLower(r))
|
||||
buf.WriteString(str[size:])
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// Shuffle randomizes runes in a string and returns the result.
|
||||
// It uses default random source in `math/rand`.
|
||||
func Shuffle(str string) string {
|
||||
if str == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
runes := []rune(str)
|
||||
index := 0
|
||||
|
||||
for i := len(runes) - 1; i > 0; i-- {
|
||||
index = rand.Intn(i + 1)
|
||||
|
||||
if i != index {
|
||||
runes[i], runes[index] = runes[index], runes[i]
|
||||
}
|
||||
}
|
||||
|
||||
return string(runes)
|
||||
}
|
||||
|
||||
// ShuffleSource randomizes runes in a string with given random source.
|
||||
func ShuffleSource(str string, src rand.Source) string {
|
||||
if str == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
runes := []rune(str)
|
||||
index := 0
|
||||
r := rand.New(src)
|
||||
|
||||
for i := len(runes) - 1; i > 0; i-- {
|
||||
index = r.Intn(i + 1)
|
||||
|
||||
if i != index {
|
||||
runes[i], runes[index] = runes[index], runes[i]
|
||||
}
|
||||
}
|
||||
|
||||
return string(runes)
|
||||
}
|
||||
|
||||
// Successor returns the successor to string.
|
||||
//
|
||||
// If there is one alphanumeric rune is found in string, increase the rune by 1.
|
||||
// If increment generates a "carry", the rune to the left of it is incremented.
|
||||
// This process repeats until there is no carry, adding an additional rune if necessary.
|
||||
//
|
||||
// If there is no alphanumeric rune, the rightmost rune will be increased by 1
|
||||
// regardless whether the result is a valid rune or not.
|
||||
//
|
||||
// Only following characters are alphanumeric.
|
||||
// * a - z
|
||||
// * A - Z
|
||||
// * 0 - 9
|
||||
//
|
||||
// Samples (borrowed from ruby's String#succ document):
|
||||
// "abcd" => "abce"
|
||||
// "THX1138" => "THX1139"
|
||||
// "<<koala>>" => "<<koalb>>"
|
||||
// "1999zzz" => "2000aaa"
|
||||
// "ZZZ9999" => "AAAA0000"
|
||||
// "***" => "**+"
|
||||
func Successor(str string) string {
|
||||
if str == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
var r rune
|
||||
var i int
|
||||
carry := ' '
|
||||
runes := []rune(str)
|
||||
l := len(runes)
|
||||
lastAlphanumeric := l
|
||||
|
||||
for i = l - 1; i >= 0; i-- {
|
||||
r = runes[i]
|
||||
|
||||
if ('a' <= r && r <= 'y') ||
|
||||
('A' <= r && r <= 'Y') ||
|
||||
('0' <= r && r <= '8') {
|
||||
runes[i]++
|
||||
carry = ' '
|
||||
lastAlphanumeric = i
|
||||
break
|
||||
}
|
||||
|
||||
switch r {
|
||||
case 'z':
|
||||
runes[i] = 'a'
|
||||
carry = 'a'
|
||||
lastAlphanumeric = i
|
||||
|
||||
case 'Z':
|
||||
runes[i] = 'A'
|
||||
carry = 'A'
|
||||
lastAlphanumeric = i
|
||||
|
||||
case '9':
|
||||
runes[i] = '0'
|
||||
carry = '0'
|
||||
lastAlphanumeric = i
|
||||
}
|
||||
}
|
||||
|
||||
// Needs to add one character for carry.
|
||||
if i < 0 && carry != ' ' {
|
||||
buf := &bytes.Buffer{}
|
||||
buf.Grow(l + 4) // Reserve enough space for write.
|
||||
|
||||
if lastAlphanumeric != 0 {
|
||||
buf.WriteString(str[:lastAlphanumeric])
|
||||
}
|
||||
|
||||
buf.WriteRune(carry)
|
||||
|
||||
for _, r = range runes[lastAlphanumeric:] {
|
||||
buf.WriteRune(r)
|
||||
}
|
||||
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// No alphanumeric character. Simply increase last rune's value.
|
||||
if lastAlphanumeric == l {
|
||||
runes[l-1]++
|
||||
}
|
||||
|
||||
return string(runes)
|
||||
}
|
||||
120
backend/vendor/github.com/huandu/xstrings/count.go
generated
vendored
Normal file
120
backend/vendor/github.com/huandu/xstrings/count.go
generated
vendored
Normal file
@@ -0,0 +1,120 @@
|
||||
// Copyright 2015 Huan Du. All rights reserved.
|
||||
// Licensed under the MIT license that can be found in the LICENSE file.
|
||||
|
||||
package xstrings
|
||||
|
||||
import (
|
||||
"unicode"
|
||||
"unicode/utf8"
|
||||
)
|
||||
|
||||
// Len returns str's utf8 rune length.
|
||||
func Len(str string) int {
|
||||
return utf8.RuneCountInString(str)
|
||||
}
|
||||
|
||||
// WordCount returns number of words in a string.
|
||||
//
|
||||
// Word is defined as a locale dependent string containing alphabetic characters,
|
||||
// which may also contain but not start with `'` and `-` characters.
|
||||
func WordCount(str string) int {
|
||||
var r rune
|
||||
var size, n int
|
||||
|
||||
inWord := false
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
|
||||
switch {
|
||||
case isAlphabet(r):
|
||||
if !inWord {
|
||||
inWord = true
|
||||
n++
|
||||
}
|
||||
|
||||
case inWord && (r == '\'' || r == '-'):
|
||||
// Still in word.
|
||||
|
||||
default:
|
||||
inWord = false
|
||||
}
|
||||
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
return n
|
||||
}
|
||||
|
||||
const minCJKCharacter = '\u3400'
|
||||
|
||||
// Checks r is a letter but not CJK character.
|
||||
func isAlphabet(r rune) bool {
|
||||
if !unicode.IsLetter(r) {
|
||||
return false
|
||||
}
|
||||
|
||||
switch {
|
||||
// Quick check for non-CJK character.
|
||||
case r < minCJKCharacter:
|
||||
return true
|
||||
|
||||
// Common CJK characters.
|
||||
case r >= '\u4E00' && r <= '\u9FCC':
|
||||
return false
|
||||
|
||||
// Rare CJK characters.
|
||||
case r >= '\u3400' && r <= '\u4D85':
|
||||
return false
|
||||
|
||||
// Rare and historic CJK characters.
|
||||
case r >= '\U00020000' && r <= '\U0002B81D':
|
||||
return false
|
||||
}
|
||||
|
||||
return true
|
||||
}
|
||||
|
||||
// Width returns string width in monotype font.
|
||||
// Multi-byte characters are usually twice the width of single byte characters.
|
||||
//
|
||||
// Algorithm comes from `mb_strwidth` in PHP.
|
||||
// http://php.net/manual/en/function.mb-strwidth.php
|
||||
func Width(str string) int {
|
||||
var r rune
|
||||
var size, n int
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
n += RuneWidth(r)
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
return n
|
||||
}
|
||||
|
||||
// RuneWidth returns character width in monotype font.
|
||||
// Multi-byte characters are usually twice the width of single byte characters.
|
||||
//
|
||||
// Algorithm comes from `mb_strwidth` in PHP.
|
||||
// http://php.net/manual/en/function.mb-strwidth.php
|
||||
func RuneWidth(r rune) int {
|
||||
switch {
|
||||
case r == utf8.RuneError || r < '\x20':
|
||||
return 0
|
||||
|
||||
case '\x20' <= r && r < '\u2000':
|
||||
return 1
|
||||
|
||||
case '\u2000' <= r && r < '\uFF61':
|
||||
return 2
|
||||
|
||||
case '\uFF61' <= r && r < '\uFFA0':
|
||||
return 1
|
||||
|
||||
case '\uFFA0' <= r:
|
||||
return 2
|
||||
}
|
||||
|
||||
return 0
|
||||
}
|
||||
8
backend/vendor/github.com/huandu/xstrings/doc.go
generated
vendored
Normal file
8
backend/vendor/github.com/huandu/xstrings/doc.go
generated
vendored
Normal file
@@ -0,0 +1,8 @@
|
||||
// Copyright 2015 Huan Du. All rights reserved.
|
||||
// Licensed under the MIT license that can be found in the LICENSE file.
|
||||
|
||||
// Package xstrings is to provide string algorithms which are useful but not included in `strings` package.
|
||||
// See project home page for details. https://github.com/huandu/xstrings
|
||||
//
|
||||
// Package xstrings assumes all strings are encoded in utf8.
|
||||
package xstrings
|
||||
170
backend/vendor/github.com/huandu/xstrings/format.go
generated
vendored
Normal file
170
backend/vendor/github.com/huandu/xstrings/format.go
generated
vendored
Normal file
@@ -0,0 +1,170 @@
|
||||
// Copyright 2015 Huan Du. All rights reserved.
|
||||
// Licensed under the MIT license that can be found in the LICENSE file.
|
||||
|
||||
package xstrings
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"unicode/utf8"
|
||||
)
|
||||
|
||||
// ExpandTabs can expand tabs ('\t') rune in str to one or more spaces dpending on
|
||||
// current column and tabSize.
|
||||
// The column number is reset to zero after each newline ('\n') occurring in the str.
|
||||
//
|
||||
// ExpandTabs uses RuneWidth to decide rune's width.
|
||||
// For example, CJK characters will be treated as two characters.
|
||||
//
|
||||
// If tabSize <= 0, ExpandTabs panics with error.
|
||||
//
|
||||
// Samples:
|
||||
// ExpandTabs("a\tbc\tdef\tghij\tk", 4) => "a bc def ghij k"
|
||||
// ExpandTabs("abcdefg\thij\nk\tl", 4) => "abcdefg hij\nk l"
|
||||
// ExpandTabs("z中\t文\tw", 4) => "z中 文 w"
|
||||
func ExpandTabs(str string, tabSize int) string {
|
||||
if tabSize <= 0 {
|
||||
panic("tab size must be positive")
|
||||
}
|
||||
|
||||
var r rune
|
||||
var i, size, column, expand int
|
||||
var output *bytes.Buffer
|
||||
|
||||
orig := str
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
|
||||
if r == '\t' {
|
||||
expand = tabSize - column%tabSize
|
||||
|
||||
if output == nil {
|
||||
output = allocBuffer(orig, str)
|
||||
}
|
||||
|
||||
for i = 0; i < expand; i++ {
|
||||
output.WriteByte(byte(' '))
|
||||
}
|
||||
|
||||
column += expand
|
||||
} else {
|
||||
if r == '\n' {
|
||||
column = 0
|
||||
} else {
|
||||
column += RuneWidth(r)
|
||||
}
|
||||
|
||||
if output != nil {
|
||||
output.WriteRune(r)
|
||||
}
|
||||
}
|
||||
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
if output == nil {
|
||||
return orig
|
||||
}
|
||||
|
||||
return output.String()
|
||||
}
|
||||
|
||||
// LeftJustify returns a string with pad string at right side if str's rune length is smaller than length.
|
||||
// If str's rune length is larger than length, str itself will be returned.
|
||||
//
|
||||
// If pad is an empty string, str will be returned.
|
||||
//
|
||||
// Samples:
|
||||
// LeftJustify("hello", 4, " ") => "hello"
|
||||
// LeftJustify("hello", 10, " ") => "hello "
|
||||
// LeftJustify("hello", 10, "123") => "hello12312"
|
||||
func LeftJustify(str string, length int, pad string) string {
|
||||
l := Len(str)
|
||||
|
||||
if l >= length || pad == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
remains := length - l
|
||||
padLen := Len(pad)
|
||||
|
||||
output := &bytes.Buffer{}
|
||||
output.Grow(len(str) + (remains/padLen+1)*len(pad))
|
||||
output.WriteString(str)
|
||||
writePadString(output, pad, padLen, remains)
|
||||
return output.String()
|
||||
}
|
||||
|
||||
// RightJustify returns a string with pad string at left side if str's rune length is smaller than length.
|
||||
// If str's rune length is larger than length, str itself will be returned.
|
||||
//
|
||||
// If pad is an empty string, str will be returned.
|
||||
//
|
||||
// Samples:
|
||||
// RightJustify("hello", 4, " ") => "hello"
|
||||
// RightJustify("hello", 10, " ") => " hello"
|
||||
// RightJustify("hello", 10, "123") => "12312hello"
|
||||
func RightJustify(str string, length int, pad string) string {
|
||||
l := Len(str)
|
||||
|
||||
if l >= length || pad == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
remains := length - l
|
||||
padLen := Len(pad)
|
||||
|
||||
output := &bytes.Buffer{}
|
||||
output.Grow(len(str) + (remains/padLen+1)*len(pad))
|
||||
writePadString(output, pad, padLen, remains)
|
||||
output.WriteString(str)
|
||||
return output.String()
|
||||
}
|
||||
|
||||
// Center returns a string with pad string at both side if str's rune length is smaller than length.
|
||||
// If str's rune length is larger than length, str itself will be returned.
|
||||
//
|
||||
// If pad is an empty string, str will be returned.
|
||||
//
|
||||
// Samples:
|
||||
// Center("hello", 4, " ") => "hello"
|
||||
// Center("hello", 10, " ") => " hello "
|
||||
// Center("hello", 10, "123") => "12hello123"
|
||||
func Center(str string, length int, pad string) string {
|
||||
l := Len(str)
|
||||
|
||||
if l >= length || pad == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
remains := length - l
|
||||
padLen := Len(pad)
|
||||
|
||||
output := &bytes.Buffer{}
|
||||
output.Grow(len(str) + (remains/padLen+1)*len(pad))
|
||||
writePadString(output, pad, padLen, remains/2)
|
||||
output.WriteString(str)
|
||||
writePadString(output, pad, padLen, (remains+1)/2)
|
||||
return output.String()
|
||||
}
|
||||
|
||||
func writePadString(output *bytes.Buffer, pad string, padLen, remains int) {
|
||||
var r rune
|
||||
var size int
|
||||
|
||||
repeats := remains / padLen
|
||||
|
||||
for i := 0; i < repeats; i++ {
|
||||
output.WriteString(pad)
|
||||
}
|
||||
|
||||
remains = remains % padLen
|
||||
|
||||
if remains != 0 {
|
||||
for i := 0; i < remains; i++ {
|
||||
r, size = utf8.DecodeRuneInString(pad)
|
||||
output.WriteRune(r)
|
||||
pad = pad[size:]
|
||||
}
|
||||
}
|
||||
}
|
||||
1
backend/vendor/github.com/huandu/xstrings/go.mod
generated
vendored
Normal file
1
backend/vendor/github.com/huandu/xstrings/go.mod
generated
vendored
Normal file
@@ -0,0 +1 @@
|
||||
module github.com/huandu/xstrings
|
||||
217
backend/vendor/github.com/huandu/xstrings/manipulate.go
generated
vendored
Normal file
217
backend/vendor/github.com/huandu/xstrings/manipulate.go
generated
vendored
Normal file
@@ -0,0 +1,217 @@
|
||||
// Copyright 2015 Huan Du. All rights reserved.
|
||||
// Licensed under the MIT license that can be found in the LICENSE file.
|
||||
|
||||
package xstrings
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"strings"
|
||||
"unicode/utf8"
|
||||
)
|
||||
|
||||
// Reverse a utf8 encoded string.
|
||||
func Reverse(str string) string {
|
||||
var size int
|
||||
|
||||
tail := len(str)
|
||||
buf := make([]byte, tail)
|
||||
s := buf
|
||||
|
||||
for len(str) > 0 {
|
||||
_, size = utf8.DecodeRuneInString(str)
|
||||
tail -= size
|
||||
s = append(s[:tail], []byte(str[:size])...)
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
return string(buf)
|
||||
}
|
||||
|
||||
// Slice a string by rune.
|
||||
//
|
||||
// Start must satisfy 0 <= start <= rune length.
|
||||
//
|
||||
// End can be positive, zero or negative.
|
||||
// If end >= 0, start and end must satisfy start <= end <= rune length.
|
||||
// If end < 0, it means slice to the end of string.
|
||||
//
|
||||
// Otherwise, Slice will panic as out of range.
|
||||
func Slice(str string, start, end int) string {
|
||||
var size, startPos, endPos int
|
||||
|
||||
origin := str
|
||||
|
||||
if start < 0 || end > len(str) || (end >= 0 && start > end) {
|
||||
panic("out of range")
|
||||
}
|
||||
|
||||
if end >= 0 {
|
||||
end -= start
|
||||
}
|
||||
|
||||
for start > 0 && len(str) > 0 {
|
||||
_, size = utf8.DecodeRuneInString(str)
|
||||
start--
|
||||
startPos += size
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
if end < 0 {
|
||||
return origin[startPos:]
|
||||
}
|
||||
|
||||
endPos = startPos
|
||||
|
||||
for end > 0 && len(str) > 0 {
|
||||
_, size = utf8.DecodeRuneInString(str)
|
||||
end--
|
||||
endPos += size
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
if len(str) == 0 && (start > 0 || end > 0) {
|
||||
panic("out of range")
|
||||
}
|
||||
|
||||
return origin[startPos:endPos]
|
||||
}
|
||||
|
||||
// Partition splits a string by sep into three parts.
|
||||
// The return value is a slice of strings with head, match and tail.
|
||||
//
|
||||
// If str contains sep, for example "hello" and "l", Partition returns
|
||||
// "he", "l", "lo"
|
||||
//
|
||||
// If str doesn't contain sep, for example "hello" and "x", Partition returns
|
||||
// "hello", "", ""
|
||||
func Partition(str, sep string) (head, match, tail string) {
|
||||
index := strings.Index(str, sep)
|
||||
|
||||
if index == -1 {
|
||||
head = str
|
||||
return
|
||||
}
|
||||
|
||||
head = str[:index]
|
||||
match = str[index : index+len(sep)]
|
||||
tail = str[index+len(sep):]
|
||||
return
|
||||
}
|
||||
|
||||
// LastPartition splits a string by last instance of sep into three parts.
|
||||
// The return value is a slice of strings with head, match and tail.
|
||||
//
|
||||
// If str contains sep, for example "hello" and "l", LastPartition returns
|
||||
// "hel", "l", "o"
|
||||
//
|
||||
// If str doesn't contain sep, for example "hello" and "x", LastPartition returns
|
||||
// "", "", "hello"
|
||||
func LastPartition(str, sep string) (head, match, tail string) {
|
||||
index := strings.LastIndex(str, sep)
|
||||
|
||||
if index == -1 {
|
||||
tail = str
|
||||
return
|
||||
}
|
||||
|
||||
head = str[:index]
|
||||
match = str[index : index+len(sep)]
|
||||
tail = str[index+len(sep):]
|
||||
return
|
||||
}
|
||||
|
||||
// Insert src into dst at given rune index.
|
||||
// Index is counted by runes instead of bytes.
|
||||
//
|
||||
// If index is out of range of dst, panic with out of range.
|
||||
func Insert(dst, src string, index int) string {
|
||||
return Slice(dst, 0, index) + src + Slice(dst, index, -1)
|
||||
}
|
||||
|
||||
// Scrub scrubs invalid utf8 bytes with repl string.
|
||||
// Adjacent invalid bytes are replaced only once.
|
||||
func Scrub(str, repl string) string {
|
||||
var buf *bytes.Buffer
|
||||
var r rune
|
||||
var size, pos int
|
||||
var hasError bool
|
||||
|
||||
origin := str
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
|
||||
if r == utf8.RuneError {
|
||||
if !hasError {
|
||||
if buf == nil {
|
||||
buf = &bytes.Buffer{}
|
||||
}
|
||||
|
||||
buf.WriteString(origin[:pos])
|
||||
hasError = true
|
||||
}
|
||||
} else if hasError {
|
||||
hasError = false
|
||||
buf.WriteString(repl)
|
||||
|
||||
origin = origin[pos:]
|
||||
pos = 0
|
||||
}
|
||||
|
||||
pos += size
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
if buf != nil {
|
||||
buf.WriteString(origin)
|
||||
return buf.String()
|
||||
}
|
||||
|
||||
// No invalid byte.
|
||||
return origin
|
||||
}
|
||||
|
||||
// WordSplit splits a string into words. Returns a slice of words.
|
||||
// If there is no word in a string, return nil.
|
||||
//
|
||||
// Word is defined as a locale dependent string containing alphabetic characters,
|
||||
// which may also contain but not start with `'` and `-` characters.
|
||||
func WordSplit(str string) []string {
|
||||
var word string
|
||||
var words []string
|
||||
var r rune
|
||||
var size, pos int
|
||||
|
||||
inWord := false
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
|
||||
switch {
|
||||
case isAlphabet(r):
|
||||
if !inWord {
|
||||
inWord = true
|
||||
word = str
|
||||
pos = 0
|
||||
}
|
||||
|
||||
case inWord && (r == '\'' || r == '-'):
|
||||
// Still in word.
|
||||
|
||||
default:
|
||||
if inWord {
|
||||
inWord = false
|
||||
words = append(words, word[:pos])
|
||||
}
|
||||
}
|
||||
|
||||
pos += size
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
if inWord {
|
||||
words = append(words, word[:pos])
|
||||
}
|
||||
|
||||
return words
|
||||
}
|
||||
547
backend/vendor/github.com/huandu/xstrings/translate.go
generated
vendored
Normal file
547
backend/vendor/github.com/huandu/xstrings/translate.go
generated
vendored
Normal file
@@ -0,0 +1,547 @@
|
||||
// Copyright 2015 Huan Du. All rights reserved.
|
||||
// Licensed under the MIT license that can be found in the LICENSE file.
|
||||
|
||||
package xstrings
|
||||
|
||||
import (
|
||||
"bytes"
|
||||
"unicode"
|
||||
"unicode/utf8"
|
||||
)
|
||||
|
||||
type runeRangeMap struct {
|
||||
FromLo rune // Lower bound of range map.
|
||||
FromHi rune // An inclusive higher bound of range map.
|
||||
ToLo rune
|
||||
ToHi rune
|
||||
}
|
||||
|
||||
type runeDict struct {
|
||||
Dict [unicode.MaxASCII + 1]rune
|
||||
}
|
||||
|
||||
type runeMap map[rune]rune
|
||||
|
||||
// Translator can translate string with pre-compiled from and to patterns.
|
||||
// If a from/to pattern pair needs to be used more than once, it's recommended
|
||||
// to create a Translator and reuse it.
|
||||
type Translator struct {
|
||||
quickDict *runeDict // A quick dictionary to look up rune by index. Only availabe for latin runes.
|
||||
runeMap runeMap // Rune map for translation.
|
||||
ranges []*runeRangeMap // Ranges of runes.
|
||||
mappedRune rune // If mappedRune >= 0, all matched runes are translated to the mappedRune.
|
||||
reverted bool // If to pattern is empty, all matched characters will be deleted.
|
||||
hasPattern bool
|
||||
}
|
||||
|
||||
// NewTranslator creates new Translator through a from/to pattern pair.
|
||||
func NewTranslator(from, to string) *Translator {
|
||||
tr := &Translator{}
|
||||
|
||||
if from == "" {
|
||||
return tr
|
||||
}
|
||||
|
||||
reverted := from[0] == '^'
|
||||
deletion := len(to) == 0
|
||||
|
||||
if reverted {
|
||||
from = from[1:]
|
||||
}
|
||||
|
||||
var fromStart, fromEnd, fromRangeStep rune
|
||||
var toStart, toEnd, toRangeStep rune
|
||||
var fromRangeSize, toRangeSize rune
|
||||
var singleRunes []rune
|
||||
|
||||
// Update the to rune range.
|
||||
updateRange := func() {
|
||||
// No more rune to read in the to rune pattern.
|
||||
if toEnd == utf8.RuneError {
|
||||
return
|
||||
}
|
||||
|
||||
if toRangeStep == 0 {
|
||||
to, toStart, toEnd, toRangeStep = nextRuneRange(to, toEnd)
|
||||
return
|
||||
}
|
||||
|
||||
// Current range is not empty. Consume 1 rune from start.
|
||||
if toStart != toEnd {
|
||||
toStart += toRangeStep
|
||||
return
|
||||
}
|
||||
|
||||
// No more rune. Repeat the last rune.
|
||||
if to == "" {
|
||||
toEnd = utf8.RuneError
|
||||
return
|
||||
}
|
||||
|
||||
// Both start and end are used. Read two more runes from the to pattern.
|
||||
to, toStart, toEnd, toRangeStep = nextRuneRange(to, utf8.RuneError)
|
||||
}
|
||||
|
||||
if deletion {
|
||||
toStart = utf8.RuneError
|
||||
toEnd = utf8.RuneError
|
||||
} else {
|
||||
// If from pattern is reverted, only the last rune in the to pattern will be used.
|
||||
if reverted {
|
||||
var size int
|
||||
|
||||
for len(to) > 0 {
|
||||
toStart, size = utf8.DecodeRuneInString(to)
|
||||
to = to[size:]
|
||||
}
|
||||
|
||||
toEnd = utf8.RuneError
|
||||
} else {
|
||||
to, toStart, toEnd, toRangeStep = nextRuneRange(to, utf8.RuneError)
|
||||
}
|
||||
}
|
||||
|
||||
fromEnd = utf8.RuneError
|
||||
|
||||
for len(from) > 0 {
|
||||
from, fromStart, fromEnd, fromRangeStep = nextRuneRange(from, fromEnd)
|
||||
|
||||
// fromStart is a single character. Just map it with a rune in the to pattern.
|
||||
if fromRangeStep == 0 {
|
||||
singleRunes = tr.addRune(fromStart, toStart, singleRunes)
|
||||
updateRange()
|
||||
continue
|
||||
}
|
||||
|
||||
for toEnd != utf8.RuneError && fromStart != fromEnd {
|
||||
// If mapped rune is a single character instead of a range, simply shift first
|
||||
// rune in the range.
|
||||
if toRangeStep == 0 {
|
||||
singleRunes = tr.addRune(fromStart, toStart, singleRunes)
|
||||
updateRange()
|
||||
fromStart += fromRangeStep
|
||||
continue
|
||||
}
|
||||
|
||||
fromRangeSize = (fromEnd - fromStart) * fromRangeStep
|
||||
toRangeSize = (toEnd - toStart) * toRangeStep
|
||||
|
||||
// Not enough runes in the to pattern. Need to read more.
|
||||
if fromRangeSize > toRangeSize {
|
||||
fromStart, toStart = tr.addRuneRange(fromStart, fromStart+toRangeSize*fromRangeStep, toStart, toEnd, singleRunes)
|
||||
fromStart += fromRangeStep
|
||||
updateRange()
|
||||
|
||||
// Edge case: If fromRangeSize == toRangeSize + 1, the last fromStart value needs be considered
|
||||
// as a single rune.
|
||||
if fromStart == fromEnd {
|
||||
singleRunes = tr.addRune(fromStart, toStart, singleRunes)
|
||||
updateRange()
|
||||
}
|
||||
|
||||
continue
|
||||
}
|
||||
|
||||
fromStart, toStart = tr.addRuneRange(fromStart, fromEnd, toStart, toStart+fromRangeSize*toRangeStep, singleRunes)
|
||||
updateRange()
|
||||
break
|
||||
}
|
||||
|
||||
if fromStart == fromEnd {
|
||||
fromEnd = utf8.RuneError
|
||||
continue
|
||||
}
|
||||
|
||||
fromStart, toStart = tr.addRuneRange(fromStart, fromEnd, toStart, toStart, singleRunes)
|
||||
fromEnd = utf8.RuneError
|
||||
}
|
||||
|
||||
if fromEnd != utf8.RuneError {
|
||||
singleRunes = tr.addRune(fromEnd, toStart, singleRunes)
|
||||
}
|
||||
|
||||
tr.reverted = reverted
|
||||
tr.mappedRune = -1
|
||||
tr.hasPattern = true
|
||||
|
||||
// Translate RuneError only if in deletion or reverted mode.
|
||||
if deletion || reverted {
|
||||
tr.mappedRune = toStart
|
||||
}
|
||||
|
||||
return tr
|
||||
}
|
||||
|
||||
func (tr *Translator) addRune(from, to rune, singleRunes []rune) []rune {
|
||||
if from <= unicode.MaxASCII {
|
||||
if tr.quickDict == nil {
|
||||
tr.quickDict = &runeDict{}
|
||||
}
|
||||
|
||||
tr.quickDict.Dict[from] = to
|
||||
} else {
|
||||
if tr.runeMap == nil {
|
||||
tr.runeMap = make(runeMap)
|
||||
}
|
||||
|
||||
tr.runeMap[from] = to
|
||||
}
|
||||
|
||||
singleRunes = append(singleRunes, from)
|
||||
return singleRunes
|
||||
}
|
||||
|
||||
func (tr *Translator) addRuneRange(fromLo, fromHi, toLo, toHi rune, singleRunes []rune) (rune, rune) {
|
||||
var r rune
|
||||
var rrm *runeRangeMap
|
||||
|
||||
if fromLo < fromHi {
|
||||
rrm = &runeRangeMap{
|
||||
FromLo: fromLo,
|
||||
FromHi: fromHi,
|
||||
ToLo: toLo,
|
||||
ToHi: toHi,
|
||||
}
|
||||
} else {
|
||||
rrm = &runeRangeMap{
|
||||
FromLo: fromHi,
|
||||
FromHi: fromLo,
|
||||
ToLo: toHi,
|
||||
ToHi: toLo,
|
||||
}
|
||||
}
|
||||
|
||||
// If there is any single rune conflicts with this rune range, clear single rune record.
|
||||
for _, r = range singleRunes {
|
||||
if rrm.FromLo <= r && r <= rrm.FromHi {
|
||||
if r <= unicode.MaxASCII {
|
||||
tr.quickDict.Dict[r] = 0
|
||||
} else {
|
||||
delete(tr.runeMap, r)
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
tr.ranges = append(tr.ranges, rrm)
|
||||
return fromHi, toHi
|
||||
}
|
||||
|
||||
func nextRuneRange(str string, last rune) (remaining string, start, end rune, rangeStep rune) {
|
||||
var r rune
|
||||
var size int
|
||||
|
||||
remaining = str
|
||||
escaping := false
|
||||
isRange := false
|
||||
|
||||
for len(remaining) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(remaining)
|
||||
remaining = remaining[size:]
|
||||
|
||||
// Parse special characters.
|
||||
if !escaping {
|
||||
if r == '\\' {
|
||||
escaping = true
|
||||
continue
|
||||
}
|
||||
|
||||
if r == '-' {
|
||||
// Ignore slash at beginning of string.
|
||||
if last == utf8.RuneError {
|
||||
continue
|
||||
}
|
||||
|
||||
start = last
|
||||
isRange = true
|
||||
continue
|
||||
}
|
||||
}
|
||||
|
||||
escaping = false
|
||||
|
||||
if last != utf8.RuneError {
|
||||
// This is a range which start and end are the same.
|
||||
// Considier it as a normal character.
|
||||
if isRange && last == r {
|
||||
isRange = false
|
||||
continue
|
||||
}
|
||||
|
||||
start = last
|
||||
end = r
|
||||
|
||||
if isRange {
|
||||
if start < end {
|
||||
rangeStep = 1
|
||||
} else {
|
||||
rangeStep = -1
|
||||
}
|
||||
}
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
last = r
|
||||
}
|
||||
|
||||
start = last
|
||||
end = utf8.RuneError
|
||||
return
|
||||
}
|
||||
|
||||
// Translate str with a from/to pattern pair.
|
||||
//
|
||||
// See comment in Translate function for usage and samples.
|
||||
func (tr *Translator) Translate(str string) string {
|
||||
if !tr.hasPattern || str == "" {
|
||||
return str
|
||||
}
|
||||
|
||||
var r rune
|
||||
var size int
|
||||
var needTr bool
|
||||
|
||||
orig := str
|
||||
|
||||
var output *bytes.Buffer
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
r, needTr = tr.TranslateRune(r)
|
||||
|
||||
if needTr && output == nil {
|
||||
output = allocBuffer(orig, str)
|
||||
}
|
||||
|
||||
if r != utf8.RuneError && output != nil {
|
||||
output.WriteRune(r)
|
||||
}
|
||||
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
// No character is translated.
|
||||
if output == nil {
|
||||
return orig
|
||||
}
|
||||
|
||||
return output.String()
|
||||
}
|
||||
|
||||
// TranslateRune return translated rune and true if r matches the from pattern.
|
||||
// If r doesn't match the pattern, original r is returned and translated is false.
|
||||
func (tr *Translator) TranslateRune(r rune) (result rune, translated bool) {
|
||||
switch {
|
||||
case tr.quickDict != nil:
|
||||
if r <= unicode.MaxASCII {
|
||||
result = tr.quickDict.Dict[r]
|
||||
|
||||
if result != 0 {
|
||||
translated = true
|
||||
|
||||
if tr.mappedRune >= 0 {
|
||||
result = tr.mappedRune
|
||||
}
|
||||
|
||||
break
|
||||
}
|
||||
}
|
||||
|
||||
fallthrough
|
||||
|
||||
case tr.runeMap != nil:
|
||||
var ok bool
|
||||
|
||||
if result, ok = tr.runeMap[r]; ok {
|
||||
translated = true
|
||||
|
||||
if tr.mappedRune >= 0 {
|
||||
result = tr.mappedRune
|
||||
}
|
||||
|
||||
break
|
||||
}
|
||||
|
||||
fallthrough
|
||||
|
||||
default:
|
||||
var rrm *runeRangeMap
|
||||
ranges := tr.ranges
|
||||
|
||||
for i := len(ranges) - 1; i >= 0; i-- {
|
||||
rrm = ranges[i]
|
||||
|
||||
if rrm.FromLo <= r && r <= rrm.FromHi {
|
||||
translated = true
|
||||
|
||||
if tr.mappedRune >= 0 {
|
||||
result = tr.mappedRune
|
||||
break
|
||||
}
|
||||
|
||||
if rrm.ToLo < rrm.ToHi {
|
||||
result = rrm.ToLo + r - rrm.FromLo
|
||||
} else if rrm.ToLo > rrm.ToHi {
|
||||
// ToHi can be smaller than ToLo if range is from higher to lower.
|
||||
result = rrm.ToLo - r + rrm.FromLo
|
||||
} else {
|
||||
result = rrm.ToLo
|
||||
}
|
||||
|
||||
break
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if tr.reverted {
|
||||
if !translated {
|
||||
result = tr.mappedRune
|
||||
}
|
||||
|
||||
translated = !translated
|
||||
}
|
||||
|
||||
if !translated {
|
||||
result = r
|
||||
}
|
||||
|
||||
return
|
||||
}
|
||||
|
||||
// HasPattern returns true if Translator has one pattern at least.
|
||||
func (tr *Translator) HasPattern() bool {
|
||||
return tr.hasPattern
|
||||
}
|
||||
|
||||
// Translate str with the characters defined in from replaced by characters defined in to.
|
||||
//
|
||||
// From and to are patterns representing a set of characters. Pattern is defined as following.
|
||||
//
|
||||
// * Special characters
|
||||
// * '-' means a range of runes, e.g.
|
||||
// * "a-z" means all characters from 'a' to 'z' inclusive;
|
||||
// * "z-a" means all characters from 'z' to 'a' inclusive.
|
||||
// * '^' as first character means a set of all runes excepted listed, e.g.
|
||||
// * "^a-z" means all characters except 'a' to 'z' inclusive.
|
||||
// * '\' escapes special characters.
|
||||
// * Normal character represents itself, e.g. "abc" is a set including 'a', 'b' and 'c'.
|
||||
//
|
||||
// Translate will try to find a 1:1 mapping from from to to.
|
||||
// If to is smaller than from, last rune in to will be used to map "out of range" characters in from.
|
||||
//
|
||||
// Note that '^' only works in the from pattern. It will be considered as a normal character in the to pattern.
|
||||
//
|
||||
// If the to pattern is an empty string, Translate works exactly the same as Delete.
|
||||
//
|
||||
// Samples:
|
||||
// Translate("hello", "aeiou", "12345") => "h2ll4"
|
||||
// Translate("hello", "a-z", "A-Z") => "HELLO"
|
||||
// Translate("hello", "z-a", "a-z") => "svool"
|
||||
// Translate("hello", "aeiou", "*") => "h*ll*"
|
||||
// Translate("hello", "^l", "*") => "**ll*"
|
||||
// Translate("hello ^ world", `\^lo`, "*") => "he*** * w*r*d"
|
||||
func Translate(str, from, to string) string {
|
||||
tr := NewTranslator(from, to)
|
||||
return tr.Translate(str)
|
||||
}
|
||||
|
||||
// Delete runes in str matching the pattern.
|
||||
// Pattern is defined in Translate function.
|
||||
//
|
||||
// Samples:
|
||||
// Delete("hello", "aeiou") => "hll"
|
||||
// Delete("hello", "a-k") => "llo"
|
||||
// Delete("hello", "^a-k") => "he"
|
||||
func Delete(str, pattern string) string {
|
||||
tr := NewTranslator(pattern, "")
|
||||
return tr.Translate(str)
|
||||
}
|
||||
|
||||
// Count how many runes in str match the pattern.
|
||||
// Pattern is defined in Translate function.
|
||||
//
|
||||
// Samples:
|
||||
// Count("hello", "aeiou") => 3
|
||||
// Count("hello", "a-k") => 3
|
||||
// Count("hello", "^a-k") => 2
|
||||
func Count(str, pattern string) int {
|
||||
if pattern == "" || str == "" {
|
||||
return 0
|
||||
}
|
||||
|
||||
var r rune
|
||||
var size int
|
||||
var matched bool
|
||||
|
||||
tr := NewTranslator(pattern, "")
|
||||
cnt := 0
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
str = str[size:]
|
||||
|
||||
if _, matched = tr.TranslateRune(r); matched {
|
||||
cnt++
|
||||
}
|
||||
}
|
||||
|
||||
return cnt
|
||||
}
|
||||
|
||||
// Squeeze deletes adjacent repeated runes in str.
|
||||
// If pattern is not empty, only runes matching the pattern will be squeezed.
|
||||
//
|
||||
// Samples:
|
||||
// Squeeze("hello", "") => "helo"
|
||||
// Squeeze("hello", "m-z") => "hello"
|
||||
// Squeeze("hello world", " ") => "hello world"
|
||||
func Squeeze(str, pattern string) string {
|
||||
var last, r rune
|
||||
var size int
|
||||
var skipSqueeze, matched bool
|
||||
var tr *Translator
|
||||
var output *bytes.Buffer
|
||||
|
||||
orig := str
|
||||
last = -1
|
||||
|
||||
if len(pattern) > 0 {
|
||||
tr = NewTranslator(pattern, "")
|
||||
}
|
||||
|
||||
for len(str) > 0 {
|
||||
r, size = utf8.DecodeRuneInString(str)
|
||||
|
||||
// Need to squeeze the str.
|
||||
if last == r && !skipSqueeze {
|
||||
if tr != nil {
|
||||
if _, matched = tr.TranslateRune(r); !matched {
|
||||
skipSqueeze = true
|
||||
}
|
||||
}
|
||||
|
||||
if output == nil {
|
||||
output = allocBuffer(orig, str)
|
||||
}
|
||||
|
||||
if skipSqueeze {
|
||||
output.WriteRune(r)
|
||||
}
|
||||
} else {
|
||||
if output != nil {
|
||||
output.WriteRune(r)
|
||||
}
|
||||
|
||||
last = r
|
||||
skipSqueeze = false
|
||||
}
|
||||
|
||||
str = str[size:]
|
||||
}
|
||||
|
||||
if output == nil {
|
||||
return orig
|
||||
}
|
||||
|
||||
return output.String()
|
||||
}
|
||||
Some files were not shown because too many files have changed in this diff Show More
Reference in New Issue
Block a user