mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-22 17:31:03 +01:00
added documents
This commit is contained in:
36
documents/Architecture/Architecture.md
Normal file
36
documents/Architecture/Architecture.md
Normal file
@@ -0,0 +1,36 @@
|
||||
## 整体架构
|
||||
|
||||
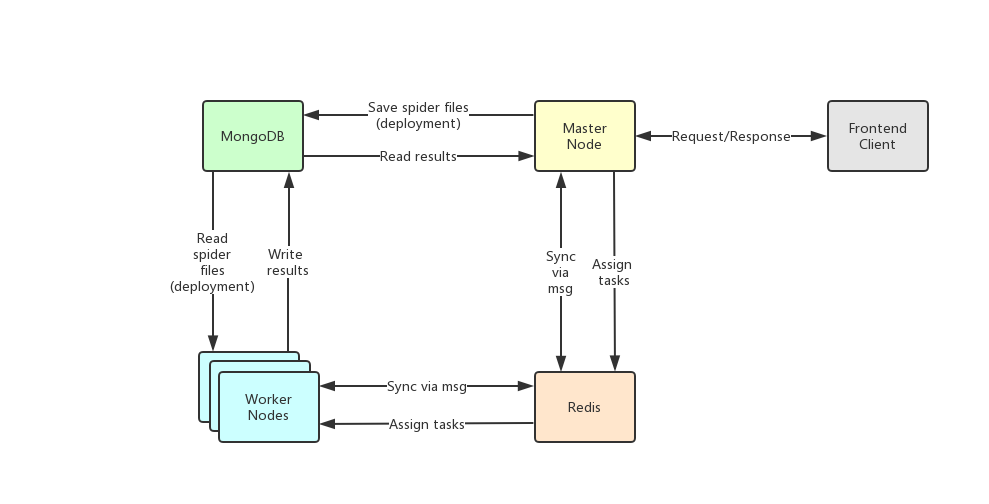
Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及负责通信和数据储存的Redis和MongoDB数据库。
|
||||
|
||||
|
||||
|
||||
前端应用向主节点请求数据,主节点通过MongoDB和Redis来执行任务派发调度以及部署,工作节点收到任务之后,开始执行爬虫任务,并将任务结果储存到MongoDB。架构相对于`v0.3.0`之前的Celery版本有所精简,去除了不必要的节点监控模块Flower,节点监控主要由Redis完成。
|
||||
|
||||
### 主节点
|
||||
|
||||
主节点是整个Crawlab架构的核心,属于Crawlab的中控系统。
|
||||
|
||||
主节点主要负责以下功能:
|
||||
1. 爬虫任务调度
|
||||
2. 工作节点管理和通信
|
||||
3. 爬虫部署
|
||||
4. 前端以及API服务
|
||||
5. 执行任务(可以将主节点当成工作节点)
|
||||
|
||||
主节点负责与前端应用进行通信,并通过Redis将爬虫任务派发给工作节点。同时,主节点会同步(部署)爬虫给工作节点,通过Redis和MongoDB的GridFS。
|
||||
|
||||
### 工作节点
|
||||
|
||||
工作节点的主要功能是执行爬虫任务和储存抓取数据与日志,并且通过Redis的`PubSub`跟主节点通信。通过增加工作节点数量,Crawlab可以做到横向扩展,不同的爬虫任务可以分配到不同的节点上执行。
|
||||
|
||||
### MongoDB
|
||||
|
||||
MongoDB是Crawlab的运行数据库,储存有节点、爬虫、任务、定时任务等数据,另外GridFS文件储存方式是主节点储存爬虫文件并同步到工作节点的中间媒介。
|
||||
|
||||
### Redis
|
||||
|
||||
Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点间数据通信的功能。例如,节点会将自己信息通过`HSET`储存在Redis的`nodes`哈希列表中,主节点根据哈希列表来判断在线节点。
|
||||
|
||||
### 前端
|
||||
|
||||
前端是一个基于[Vue-Element-Admin](https://github.com/PanJiaChen/vue-element-admin)的单页应用。其中重用了很多Element-UI的控件来支持相应的展示。
|
||||
46
documents/Architecture/NodeCommunication.md
Normal file
46
documents/Architecture/NodeCommunication.md
Normal file
@@ -0,0 +1,46 @@
|
||||
## 节点通信
|
||||
|
||||
这里的通信主要是指节点间的即时通信,即没有显著的延迟([爬虫部署](./SpiderDeployment.md)和[任务执行](./TaskExecution.md)是通过轮训来完成的,不在此列)。
|
||||
|
||||
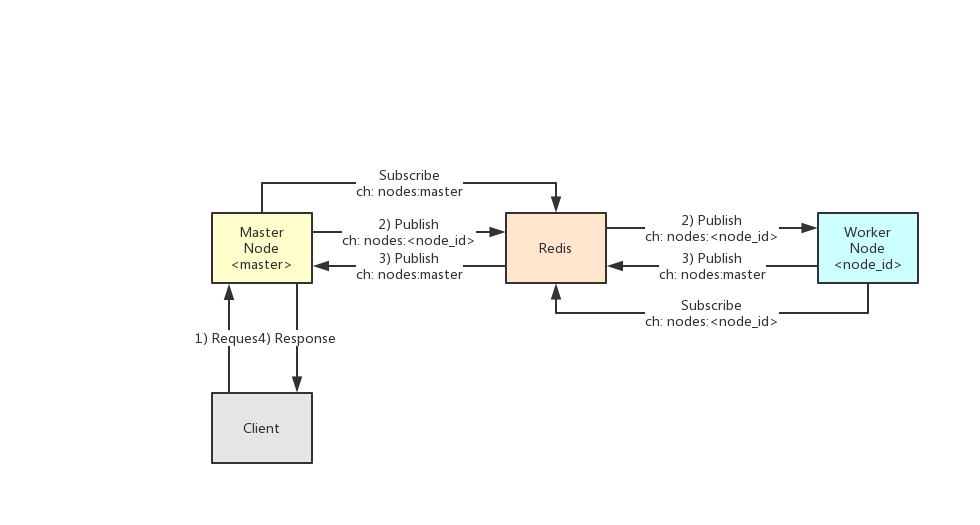
通信主要由Redis来完成。以下为节点通信原理示意图。
|
||||
|
||||
|
||||
|
||||
各个节点会通过Redis的`PubSub`功能来做相互通信。
|
||||
|
||||
所谓`PubSub`,简单来说是一个发布订阅模式。订阅者(Subscriber)会在Redis上订阅(Subscribe)一个通道,其他任何一个节点都可以作为发布者(Publisher)在该通道上发布(Publish)消息。
|
||||
|
||||
在Crawlab中,主节点会订阅`nodes:master`通道,其他节点如果需要向主节点发送消息,只需要向`nodes:master`发布消息就可以了。同理,各工作节点会各自订阅一个属于自己的通道`nodes:<node_id>`(`node_id`是MongoDB里的节点ID,是MongoDB ObjectId),如果需要给工作节点发送消息,只需要发布消息到该通道就可以了。
|
||||
|
||||
一个网络请求的简单过程如下:
|
||||
1. 客户端(前端应用)发送请求给主节点(API);
|
||||
2. 主节点通过Redis `PubSub`的`<nodes:<node_id>`通道发布消息给相应的工作节点;
|
||||
3. 工作节点收到消息之后,执行一些操作,并将相应的消息通过`<nodes:master>`通道发布给主节点;
|
||||
4. 主节点收到消息之后,将消息返回给客户端。
|
||||
|
||||
不是所有节点通信都是双向的,也就是说,主节点只会单方面对工作节点通信,工作节点并不会返回响应给主节点,所谓的单向通信。以下是Crawlab的通信类型。
|
||||
|
||||
操作名称 | 通信类别
|
||||
--- | ---
|
||||
获取日志 | 双向通信
|
||||
获取系统信息 | 双向通信
|
||||
取消任务 | 单向通信
|
||||
通知工作节点向GridFS获取爬虫文件 | 单向通信
|
||||
|
||||
### `chan`和`goroutine`
|
||||
|
||||
如果您在阅读Crawlab源码,会发现节点通信中有大量的`chan`语法,这是Golang的一个并发特性。
|
||||
|
||||
`chan`表示为一个通道,在Golang中分为无缓冲和有缓冲的通道,我们用了无缓冲通道来阻塞协程,只有当`chan`接收到信号(`chan <- "some signal"`),该阻塞才会释放,协程进行下一步操作)。在请求响应模式中,如果为双向通信,主节点收到请求后会起生成一个无缓冲通道来阻塞该请求,当收到来自工作节点的消息后,向该无缓冲通道赋值,阻塞释放,返回响应给客户端。
|
||||
|
||||
`go`命令会起一个`goroutine`(协程)来完成并发,配合`chan`,该协程可以利用无缓冲通道挂起,等待信号执行接下来的操作。任务取消就是`go`+`chan`来实现的。有兴趣的读者可以参考一下[源码](https://github.com/tikazyq/crawlab/blob/master/backend/services/task.go#L136)。
|
||||
|
||||
### Redis PubSub
|
||||
|
||||
这是Redis版发布/订阅消息模式的一种实现。其用法非常简单:
|
||||
1. 订阅者利用`SUBSCRIBE channel1 channel2 ...`来订阅一个或多个频道;
|
||||
2. 发布者利用`PUBLISH channelx message`来发布消息给该频道的订阅者。
|
||||
|
||||
Redis的`PubSub`可以用作广播模式,即一个发布者对应多个订阅者。而在Crawlab中,我们只有一个订阅者对应一个发布者的情况(主节点->工作节点:`nodes:<node_id>`)或一个订阅者对应多个发布者的情况(工作节点->主节点:`nodes:master>`)。这是为了方便双向通信。
|
||||
|
||||
参考:https://redis.io/topics/pubsub
|
||||
9
documents/Architecture/NodeMonitoring.md
Normal file
9
documents/Architecture/NodeMonitoring.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## 节点监控
|
||||
|
||||
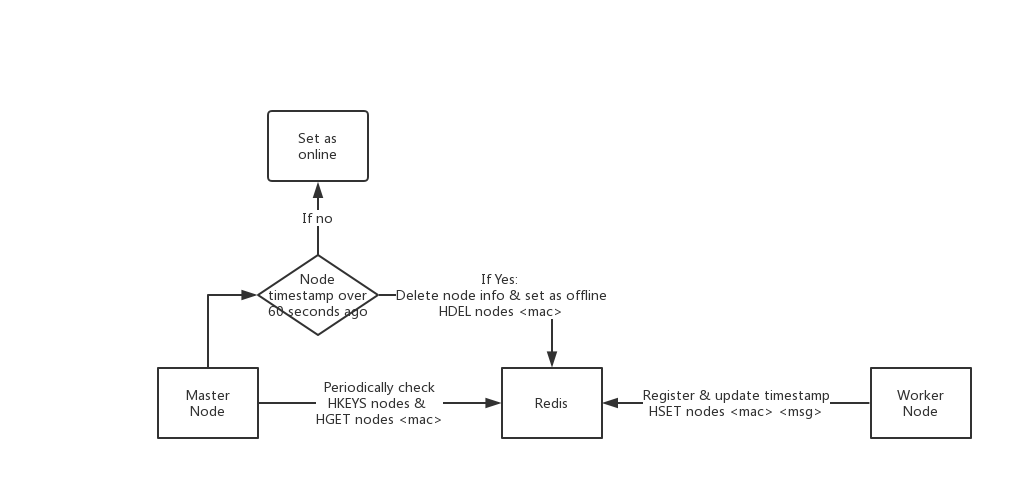
Crawlab的节点监控是通过Redis来完成的。原理如下图。
|
||||
|
||||
|
||||
|
||||
工作节点会不断更新心跳信息在Redis上,利用`HSET nodes <node_id> <msg>`,心跳信息`<msg>`包含节点MAC地址,IP地址,当前时间戳,
|
||||
|
||||
主节点会周期性获取Redis上的工作节点心跳信息。如果有工作节点的时间戳在60秒之前,则考虑该节点为离线状态,会在Redis中删除该节点的信息,并在MongoDB中设置为"离线";如果时间戳在过去60秒之内,则保留该节点信息,在MongoDB中设置为"在线"。
|
||||
10
documents/Architecture/README.md
Normal file
10
documents/Architecture/README.md
Normal file
@@ -0,0 +1,10 @@
|
||||
## 原理
|
||||
|
||||
本小节我们将介绍Crawlab的一些基础原理,主要包含以下内容。
|
||||
|
||||
1. [整体架构](./Architecture.md)
|
||||
2. [节点通信](./NodeCommunication.md)
|
||||
3. [节点监控](./NodeMonitoring.md)
|
||||
4. [爬虫部署](./SpiderDeployment.md)
|
||||
5. [任务执行](./TaskExecution.md)
|
||||
|
||||
22
documents/Architecture/SpiderDeployment.md
Normal file
22
documents/Architecture/SpiderDeployment.md
Normal file
@@ -0,0 +1,22 @@
|
||||
## 爬虫部署
|
||||
|
||||
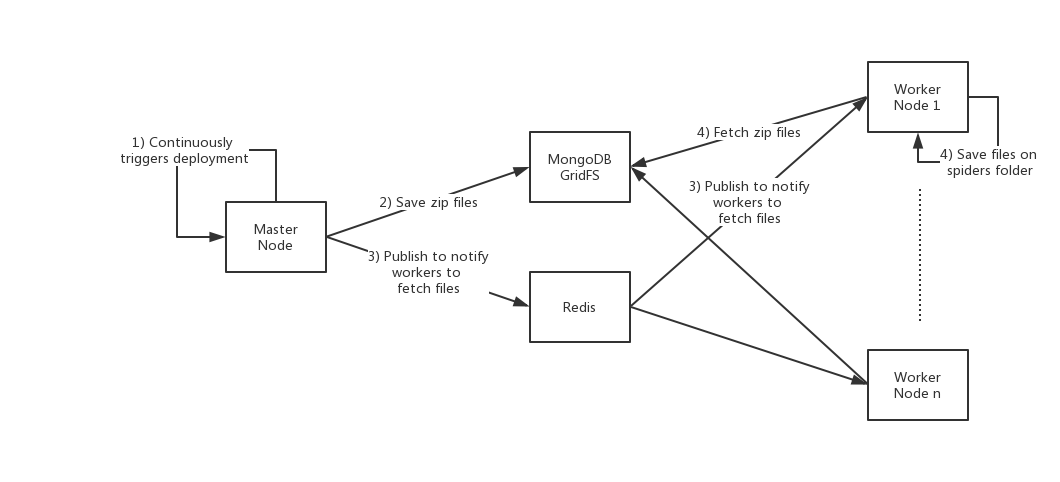
之前已经在[部署爬虫](../Usage/Spider/Deploy.md)中介绍了,爬虫是自动部署在工作节点上的。下面的示意图展示了Crawlab爬虫部署的架构。
|
||||
|
||||
|
||||
|
||||
如上图所示,整个爬虫自动部署的生命周期如下(源码在`services/spider.go#InitSpiderService`):
|
||||
|
||||
1. 主节点每5秒,会从爬虫的目录获取爬虫信息,然后更新到数据库(这个过程不涉及文件上传);
|
||||
2. 主节点每60秒,从数据库获取所有的爬虫信息,然后将爬虫打包成zip文件,并上传到MongoDB GridFS,并且在MongoDB的`spiders`表里写入`file_id`文件ID;
|
||||
3. 主节点通过Redis `PubSub`发布消息(`file.upload`事件,包含文件ID)给工作节点,通知工作节点获取爬虫文件;
|
||||
4. 工作节点接收到获取爬虫文件的消息,从MongoDB GridFS获取zip文件,并解压储存在本地。
|
||||
|
||||
这样,所有爬虫将被周期性的部署在工作节点上。
|
||||
|
||||
### MongoDB GridFS
|
||||
|
||||
GridFS是MongoDB储存大文件(大于16Mb)的文件系统。Crawlab利用GridFS作为了爬虫文件储存的中间媒介,可以让工作节点主动去获取并部署在本地。这样绕开了其他传统传输方式,例如RPC、消息队列、HTTP,因为这几种都要求更复杂也更麻烦的配置和处理。
|
||||
|
||||
Crawlab在GridFS上储存文件,会生成两个collection,`files.files`和`files.fs`。前者储存文件的元信息,后者储存文件内容。`spiders`里的`file_id`是指向`files.files`的`_id`。
|
||||
|
||||
参考: https://docs.mongodb.com/manual/core/gridfs/
|
||||
13
documents/Architecture/TaskExecution.md
Normal file
13
documents/Architecture/TaskExecution.md
Normal file
@@ -0,0 +1,13 @@
|
||||
## 任务执行
|
||||
|
||||
Crawlab的任务执行依赖于shell。执行一个爬虫任务相当于在shell中执行相应的命令,因此在执行爬虫任务之前,要求使用者将执行命令存入数据库。执行命令存在`spiders`表中的`cmd`字段。
|
||||
|
||||
任务执行的架构示意图如下。
|
||||
|
||||
|
||||
|
||||
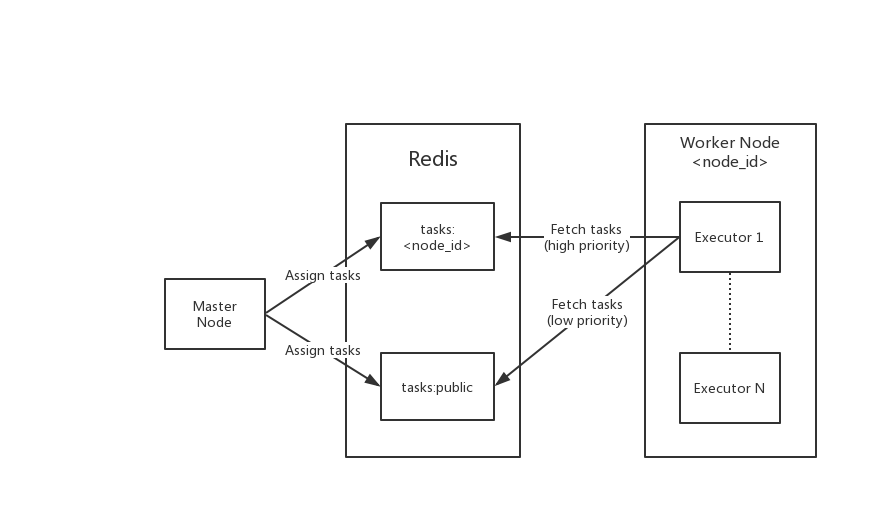
当爬虫任务被派发时,主节点会在Redis中的`tasks:<node_id>`(指定工作节点)和`tasks:public`(任意工作节点)派发任务,也就是`RPUSH`命令。
|
||||
|
||||
工作节点在启动时会起N个执行器(通过环境变量`CRAWLAB_TASK_WORKERS`配置,默认为4),每个执行器会轮训Redis的消息队列,优先获取指定节点消息队列`tasks:<node_id>`,如果指定队列中没有任务,才会获取任意节点消息队列中的任务`tasks:public`。
|
||||
|
||||
执行过程的具体情况就不细述了,详情请见[源码](https://github.com/tikazyq/crawlab/blob/master/backend/services/task.go)。
|
||||
69
documents/Config/README.md
Normal file
69
documents/Config/README.md
Normal file
@@ -0,0 +1,69 @@
|
||||
环境配置是由Go第三方库viper来实现的。当程序启动时,viper会去读取`yaml`配置文件,以及将环境变量与配置文件中的变量对应起来。
|
||||
|
||||
以下是`yaml`配置文件,其中的变量可以被以`CRAWLAB_`为前缀的环境变量所覆盖。
|
||||
|
||||
```yaml
|
||||
api:
|
||||
address: "localhost:8000"
|
||||
mongo:
|
||||
host: localhost
|
||||
port: 27017
|
||||
db: crawlab_test
|
||||
username: ""
|
||||
password: ""
|
||||
authSource: "admin"
|
||||
redis:
|
||||
address: localhost
|
||||
password: ""
|
||||
database: 1
|
||||
port: 6379
|
||||
log:
|
||||
level: info
|
||||
path: "/var/logs/crawlab"
|
||||
isDeletePeriodically: "Y"
|
||||
deleteFrequency: "@hourly"
|
||||
server:
|
||||
host: 0.0.0.0
|
||||
port: 8000
|
||||
master: "N"
|
||||
secret: "crawlab"
|
||||
register:
|
||||
# mac地址 或者 ip地址,如果是ip,则需要手动指定IP
|
||||
type: "mac"
|
||||
ip: ""
|
||||
spider:
|
||||
path: "/app/spiders"
|
||||
task:
|
||||
workers: 4
|
||||
other:
|
||||
tmppath: "/tmp"
|
||||
```
|
||||
|
||||
环境变量列表如下。
|
||||
|
||||
环境变量 | yaml变量路径 | 描述 | 默认 | 可能值
|
||||
--- | --- | --- | --- | ---
|
||||
CRAWLAB_API_PATH | api.path | 前端API地址 | localhost:8000 | 任意
|
||||
CRAWLAB_MONGO_HOST | mongo.host | MongoDB Host地址 | localhost | 任意
|
||||
CRAWLAB_MONGO_PORT | mongo.port | MongoDB端口号 | 27017 | 任意
|
||||
CRAWLAB_MONGO_DB | mongo.db | MongoDB数据库名 | crawlab_test | 任意
|
||||
CRAWLAB_MONGO_USERNAME | mongo.username | MongoDB用户名 | 空 | 任意
|
||||
CRAWLAB_MONGO_PASSWORD | mongo.password | MongoDB密码 | 空 | 任意
|
||||
CRAWLAB_MONGO_AUTHSOURCE | mongo.authSource | MongoDB AuthSource | 空 | 任意
|
||||
CRAWLAB_REDIS_ADDRESS | redis.address | Redis地址 | localhost | 任意
|
||||
CRAWLAB_REDIS_PASSWORD | redis.password | Redis密码 | 空 | 任意
|
||||
CRAWLAB_REDIS_DATABASE | redis.database | Redis db | 1 | 数值
|
||||
CRAWLAB_REDIS_PORT | redis.port | Redis 端口 | 空 | 数值
|
||||
CRAWLAB_LOG_LEVEL | log.level | 日志级别 | info | debug, info, warn, error
|
||||
CRAWLAB_LOG_PATH | log.path | 任务日志所在目录 | `/var/logs/crawlab` | 任意
|
||||
CRAWLAB_LOG_ISDELETEPERIODICALLY | log.isDeletePeriodically | 是否定期删除日志 | Y | Y, N
|
||||
CRAWLAB_LOG_DELETEFREQUENCY | log.deleteFrequency | 定期删除日志频率 | @hourly | 任意
|
||||
CRAWLAB_SERVER_HOST | server.host | 服务器绑定IP | 0.0.0.0 | 任意
|
||||
CRAWLAB_SERVER_PORT | server.port | 服务器绑定端口 | 8000 | 任意
|
||||
CRAWLAB_SERVER_MASTER | server.master | 该节点是否为主节点 | N | Y, N
|
||||
CRAWLAB_SERVER_SECRET | server.secret | 服务器密钥 | crawlab | 任意
|
||||
CRAWLAB_SERVER_REGISTER_TYPE | server.register.type | 节点注册类别 | mac | mac, ip
|
||||
CRAWLAB_SERVER_REGISTER_IP | server.register.ip | 节点注册IP | 空 | 任意
|
||||
CRAWLAB_SPIDER_PATH | spider.path | 爬虫所在目录 | /app/spiders | 任意
|
||||
CRAWLAB_TASK_WORKERS | task.workers | 任务并行执行个数 | 4 | 任意数字
|
||||
CRAWLAB_OTHER_TMPPATH | other.tmppath | 临时文件目录 | /tmp | 任意
|
||||
0
documents/Examples/PuppeteerIntegration.md
Normal file
0
documents/Examples/PuppeteerIntegration.md
Normal file
4
documents/Examples/README.md
Normal file
4
documents/Examples/README.md
Normal file
@@ -0,0 +1,4 @@
|
||||
## 样例
|
||||
|
||||
1. [与Scrapy集成](/Examples/ScrapyIntegration.md)
|
||||
|
||||
26
documents/Examples/ScrapyIntegration.md
Normal file
26
documents/Examples/ScrapyIntegration.md
Normal file
@@ -0,0 +1,26 @@
|
||||
### 与Scrapy集成
|
||||
|
||||
以下是Crawlab跟`Scrapy`集成的例子,利用了Crawlab传过来的`task_id`和`collection_name`。
|
||||
|
||||
```python
|
||||
import os
|
||||
from pymongo import MongoClient
|
||||
|
||||
MONGO_HOST = '192.168.99.100'
|
||||
MONGO_PORT = 27017
|
||||
MONGO_DB = 'crawlab_test'
|
||||
|
||||
# scrapy example in the pipeline
|
||||
class JuejinPipeline(object):
|
||||
mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT)
|
||||
db = mongo[MONGO_DB]
|
||||
col_name = os.environ.get('CRAWLAB_COLLECTION')
|
||||
if not col_name:
|
||||
col_name = 'test'
|
||||
col = db[col_name]
|
||||
|
||||
def process_item(self, item, spider):
|
||||
item['task_id'] = os.environ.get('CRAWLAB_TASK_ID')
|
||||
self.col.save(item)
|
||||
return item
|
||||
```
|
||||
91
documents/Installation/Direct.md
Normal file
91
documents/Installation/Direct.md
Normal file
@@ -0,0 +1,91 @@
|
||||
## 直接部署
|
||||
|
||||
直接部署是之前没有Docker时的部署方式,相对于Docker部署来说有些繁琐。但了解如何直接部署可以帮助更深入地理解Docker是如何构建Crawlab镜像的。这里简单介绍一下。
|
||||
|
||||
### 拉取代码
|
||||
|
||||
首先是将github上的代码拉取到本地。
|
||||
|
||||
```bash
|
||||
git clone https://github.com/tikazyq/crawlab
|
||||
```
|
||||
|
||||
### 安装
|
||||
|
||||
安装前端所需库。
|
||||
|
||||
```bash
|
||||
npm install -g yarn
|
||||
cd frontend
|
||||
yarn install
|
||||
```
|
||||
|
||||
安装后端所需库。
|
||||
|
||||
```bash
|
||||
cd ../backend
|
||||
go install ./...
|
||||
```
|
||||
|
||||
### 配置
|
||||
|
||||
修改配置文件`./backend/config.yaml`。配置文件是以`yaml`的格式。配置详情请见[配置Crawlab](../Config/README.md)。
|
||||
|
||||
### 构建前端
|
||||
|
||||
这里的构建是指前端构建,需要执行以下命令。
|
||||
|
||||
```bash
|
||||
cd ../frontend
|
||||
npm run build:prod
|
||||
```
|
||||
|
||||
构建完成后,会在`./frontend`目录下创建一个`dist`文件夹,里面是打包好后的静态文件。
|
||||
|
||||
### Nginx
|
||||
|
||||
安装`nginx`,在`ubuntu 16.04`是以下命令。
|
||||
|
||||
```bash
|
||||
sudo apt-get install nginx
|
||||
```
|
||||
|
||||
添加`/etc/nginx/conf.d/crawlab.conf`文件,输入以下内容。
|
||||
|
||||
```
|
||||
server {
|
||||
listen 8080;
|
||||
server_name dev.crawlab.com;
|
||||
root /path/to/dist;
|
||||
index index.html;
|
||||
}
|
||||
```
|
||||
|
||||
其中,`root`是静态文件的根目录,这里是`npm`打包好后的静态文件。
|
||||
|
||||
现在,只需要启动`nginx`服务就完成了启动前端服务。
|
||||
|
||||
```bash
|
||||
nginx reload
|
||||
```
|
||||
|
||||
### 构建后端
|
||||
|
||||
执行以下命令。
|
||||
|
||||
```bash
|
||||
cd ../backend
|
||||
go build
|
||||
```
|
||||
|
||||
`go build`命令会将Golang代码打包为一个执行文件,默认在`$GOPATH/bin`里。
|
||||
|
||||
### 启动服务
|
||||
|
||||
这里是指启动后端服务。执行以下命令。
|
||||
|
||||
```bash
|
||||
$GOPATH/bin/crawlab
|
||||
```
|
||||
|
||||
然后在浏览器中输入`http://localhost:8080`就可以看到界面了。
|
||||
119
documents/Installation/Docker.md
Normal file
119
documents/Installation/Docker.md
Normal file
@@ -0,0 +1,119 @@
|
||||
## Docker安装部署
|
||||
|
||||
这应该是部署应用的最方便也是最节省时间的方式了。在最近的一次版本更新[v0.3.0](https://github.com/tikazyq/crawlab/releases/tag/v0.3.0)中,我们发布了Golang版本,并且支持Docker部署。下面将一步一步介绍如何使用Docker来部署Crawlab。
|
||||
|
||||
对Docker不了解的开发者,可以参考一下这篇文章([9102 年了,学点 Docker 知识](https://juejin.im/post/5c2c69cee51d450d9707236e))做进一步了解。简单来说,Docker可以利用已存在的镜像帮助构建一些常用的服务和应用,例如Nginx、MongoDB、Redis等等。用Docker运行一个MongoDB服务仅需`docker run -d --name mongo -p 27017:27017 mongo`一行命令。如何安装Docker跟操作系统有关,这里就不展开讲了,需要的同学自行百度一下相关教程。
|
||||
|
||||
### 下载镜像
|
||||
|
||||
我们已经在[DockerHub](https://hub.docker.com/r/tikazyq/crawlab)上构建了Crawlab的镜像,开发者只需要将其pull下来使用。在pull 镜像之前,我们需要配置一下镜像源。因为我们在墙内,使用原有的镜像源速度非常感人,因此将使用DockerHub在国内的加速器。创建`/etc/docker/daemon.json`文件,在其中输入如下内容。
|
||||
|
||||
```json
|
||||
{
|
||||
"registry-mirrors": ["https://registry.docker-cn.com"]
|
||||
}
|
||||
```
|
||||
|
||||
这样的话,pull镜像的速度会比不改变镜像源的速度快很多。
|
||||
|
||||
执行以下命令将Crawlab的镜像下载下来。镜像大小大概在几百兆,因此下载需要几分钟时间。
|
||||
|
||||
```bash
|
||||
docker pull tikazyq/crawlab:latest
|
||||
```
|
||||
|
||||
### 运行Docker容器
|
||||
|
||||
之前的版本需要更改配置文件来配置数据库等参数,非常麻烦。在最近的版本`v0.3.0`中,我们实现了用环境变量来替代配置文件,简化了配置步骤。
|
||||
|
||||
运行以下命令启动主节点。
|
||||
|
||||
```bash
|
||||
docker run -d --restart always --name crawlab \
|
||||
-e CRAWLAB_REDIS_ADDRESS=192.168.99.1 \
|
||||
-e CRAWLAB_MONGO_HOST=192.168.99.1 \
|
||||
-e CRAWLAB_SERVER_MASTER=Y \
|
||||
-e CRAWLAB_API_ADDRESS=192.168.99.100:8000 \
|
||||
-p 8080:8080 \
|
||||
-p 8000:8000 \
|
||||
-v /var/logs/crawlab:/var/logs/crawlab \
|
||||
tikazyq/crawlab:0.3.0
|
||||
```
|
||||
|
||||
其中,我们设置了Redis和MongoDB的地址,分别通过`CRAWLAB_REDIS_ADDRESS`和`CRAWLAB_MONGO_HOST`参数。`CRAWLAB_SERVER_MASTER`设置为`Y`表示启动的是主节点(该参数默认是为`N`,表示为工作节点)。`CRAWLAB_API_ADDRESS`是前端的API地址,请将这个设置为公网能访问到主节点的地址,`8000`是API端口。环境变量配置详情请见[配置Crawlab](../Config/README.md),您可以根据自己的要求来进行配置。
|
||||
|
||||
此外,我们通过`-p`参数映射了8080端口(Nginx前端静态文件)以及8000端口(后端API)到宿主机。我们将任务日志目录`/var/logs/crawlab`映射出来,保证Docker重启时不会丢失日志文件(当然,我们现在用文件系统来保存日志的方式可能不是一个很好的解决方案,如果您有更好的建议,请在Github上提Issue或者Pull Request)。
|
||||
|
||||
您可能好奇为什么我们用`192.168.99.1`,而不是`localhost`。这是因为我这里的例子是用的Docker Machine,它会在宿主机创建一个`192.168.99.*`的网络,而`192.168.99.1`是宿主机的IP地址,`192.168.99.100`就是该Docker Container的地址。因此,这里的启动配置表示,我们启动的主节点连接的是宿主机的Redis和MongoDB,而API地址为该主节点地址。当然,为了方便配置,我们可以用`docker-compose`来管理Docker集群,让他们在同一个网络中,后面我们会介绍。
|
||||
|
||||
类似,我们也可以启动工作节点。
|
||||
|
||||
```bash
|
||||
docker run --restart always --name crawlab \
|
||||
-e CRAWLAB_REDIS_ADDRESS=192.168.99.1 \
|
||||
-e CRAWLAB_MONGO_HOST=192.168.99.1 \
|
||||
-e CRAWLAB_SERVER_MASTER=N \
|
||||
-v /var/logs/crawlab:/var/logs/crawlab \
|
||||
tikazyq/crawlab:latest
|
||||
```
|
||||
|
||||
这里,我们将`CRAWLAB_SERVER_MASTER`设置为`N`,表示它为工作节点(切勿设置多个节点为`Y`,这可能会导致无法预测的问题)。
|
||||
|
||||
以上两个Docker启动的命令在Github上,详情请见[Examples](https://github.com/tikazyq/crawlab/tree/master/examples)。
|
||||
|
||||
### Docker-Compose
|
||||
|
||||
当然,也可以用`docker-compose`的方式来部署。`docker-compose`是一个集群管理方式,可以利用名为`docker-compose.yml`的`yaml`文件来定义需要启动的容器,可以是单个,也可以(通常)是多个的。
|
||||
|
||||
Crawlab的`docker-compose.yml`定义如下。
|
||||
|
||||
```yaml
|
||||
version: '3.3'
|
||||
services:
|
||||
master:
|
||||
image: tikazyq/crawlab:latest
|
||||
container_name: crawlab-master
|
||||
environment:
|
||||
CRAWLAB_API_ADDRESS: "192.168.99.100:8000"
|
||||
CRAWLAB_SERVER_MASTER: "Y"
|
||||
CRAWLAB_MONGO_HOST: "mongo"
|
||||
CRAWLAB_REDIS_ADDRESS: "redis"
|
||||
ports:
|
||||
- "8080:8080" # frontend
|
||||
- "8000:8000" # backend
|
||||
depends_on:
|
||||
- mongo
|
||||
- redis
|
||||
worker:
|
||||
image: tikazyq/crawlab:latest
|
||||
container_name: crawlab-worker
|
||||
environment:
|
||||
CRAWLAB_SERVER_MASTER: "N"
|
||||
CRAWLAB_MONGO_HOST: "mongo"
|
||||
CRAWLAB_REDIS_ADDRESS: "redis"
|
||||
depends_on:
|
||||
- mongo
|
||||
- redis
|
||||
mongo:
|
||||
image: mongo:latest
|
||||
restart: always
|
||||
ports:
|
||||
- "27017:27017"
|
||||
redis:
|
||||
image: redis:latest
|
||||
restart: always
|
||||
ports:
|
||||
- "6379:6379"
|
||||
```
|
||||
|
||||
这里先定义了`master`节点和`worker`节点,也就是Crawlab的主节点和工作节点。`master`和`worker`依赖于`mongo`和`redis`容器,因此在启动之前会同时启动`mongo`和`redis`容器。这样就不需要单独配置`mongo`和`redis`服务了,大大节省了环境配置的时间。
|
||||
|
||||
安装`docker-compose`也很简单,大家去网上百度一下有中文教程。英语水平还可以的可以参考一下[官方文档](https://docs.docker.com/compose/)。
|
||||
|
||||
安装完`docker-compose`和定义好`docker-compose.yml`后,只需要运行以下命令就可以启动Crawlab。
|
||||
|
||||
```bash
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
同样,在浏览器中输入`http://localhost:8080`就可以看到界面(Docker Machine是`192.168.99.100`)。
|
||||
9
documents/Installation/Preview.md
Normal file
9
documents/Installation/Preview.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## 预览模式
|
||||
|
||||
**预览模式**是一种让用户比较快的上手的一种部署模式。跟**直接部署**类似,但不用经过`构建`、`nginx`和`启动服务`的步骤。在启动时只需要执行以下命令就可以了。相较于直接部署来说方便一些。
|
||||
|
||||
```bash
|
||||
python manage.py serve
|
||||
```
|
||||
|
||||
该模式同样会启动3个后端服务和1个前端服务。前端服务是通过`npm run serve`来进行的,因此是开发者模式。**注意:强烈不建议在生产环境中用预览模式**。预览模式只是让开发者快速体验Crawlab以及调试代码问题的一种方式,而不是用作生产环境部署的。
|
||||
4
documents/Installation/README.md
Normal file
4
documents/Installation/README.md
Normal file
@@ -0,0 +1,4 @@
|
||||
本小节将介绍2种安装Crawlab的方式:
|
||||
|
||||
1. [Docker](./Docker.md)
|
||||
2. [直接部署](./Direct.md)
|
||||
33
documents/QA/README.md
Normal file
33
documents/QA/README.md
Normal file
@@ -0,0 +1,33 @@
|
||||
## Q&A
|
||||
|
||||
#### 1. 为何我访问 http://localhost:8080 提示访问不了?
|
||||
|
||||
假如您是Docker部署的,请检查一下您是否用了Docker Machine,这样的话您需要输入地址 http://192.168.99.100:8080 才行。
|
||||
|
||||
另外,请确保您用了`-p 8080:8080`来映射端口,并检查宿主机是否开放了8080端口。
|
||||
|
||||
#### 2. 我可以看到登录页面了,但为何我点击登陆的时候按钮一直转圈圈?
|
||||
|
||||
绝大多数情况下,您可能是没有正确配置`CRAWLAB_API_ADDRESS`这个环境变量。这个变量是告诉前端应该通过哪个地址来请求API数据的,因此需要将它设置为宿主机的IP地址+端口,例如 `192.168.0.1:8000`。接着,重启容器,在浏览器中输入宿主机IP+端口,就可以顺利登陆了。
|
||||
|
||||
请注意,8080是前端端口,8000是后端端口,您在浏览器中只需要输入前端的地址就可以了,要注意区分。
|
||||
|
||||
#### 3. 在爬虫页面有一些不认识的爬虫列表,这些是什么呢?
|
||||
|
||||
这些是demo爬虫,如果需要添加您自己的爬虫,请将您的爬虫文件打包成zip文件,再在爬虫页面中点击**添加爬虫**上传就可以了。
|
||||
|
||||
注意,Crawlab将取文件名作为爬虫名称,这个您可以后期更改。另外,请不要将zip文件名设置为中文,可能会导致上传不成功。
|
||||
|
||||
#### 4. 我执行了爬虫,但是在Crawlab上看不到结果
|
||||
|
||||
强烈建议您先阅读了[与Scrapy集成](https://tikazyq.github.io/crawlab-docs/Examples/ScrapyIntegration.html)。
|
||||
|
||||
简单来说,Crawlab目前只支持MongoDB,而且您需要保证存放的数据与Crawlab的数据库一致,另外您需要在传给MongoDB时加上`task_id`,并设置为Crawlab传过来的环境变量`CRAWLAB_TASK_ID`,您需要存放的collection名字为同样是传过来的`CRAWLAB_COLLECTION`。
|
||||
|
||||
#### 5. 为何启动Crawlab时,后台日志显示`no reachable servers`?
|
||||
|
||||
这是因为您没有连上MongoDB,请确保您的`CRAWLAB_MONGO_HOST`是否设置对。如果为Docker Compose,可以将其设置为`mongo`。
|
||||
|
||||
#### 6. 在爬虫程序中打印中文会报错
|
||||
|
||||
有不少朋友反映这个问题了,可能是跟Docker镜像有关。建议您暂时不打印中文,等待我们fix这个问题。
|
||||
13
documents/README.md
Normal file
13
documents/README.md
Normal file
@@ -0,0 +1,13 @@
|
||||
# Crawlab
|
||||
|
||||
基于Golang的分布式爬虫管理平台,支持多种编程语言以及多种爬虫框架.
|
||||
|
||||
[查看演示 Demo](http://114.67.75.98:8080)
|
||||
|
||||
项目自今年三月份上线以来受到爬虫爱好者们和开发者们的好评,不少使用者还表示会用Crawlab搭建公司的爬虫平台。经过近数月的迭代,我们陆续上线了定时任务、数据分析、网站信息、可配置爬虫、自动提取字段、下载结果、上传爬虫等功能,将Crawlab打造得更加实用,更加全面,能够真正帮助用户解决爬虫管理困难的问题。
|
||||
|
||||
Crawlab主要解决的是大量爬虫管理困难的问题,例如需要监控上百个网站的参杂`scrapy`和`selenium`的项目不容易做到同时管理,而且命令行管理的成本非常高,还容易出错。Crawlab支持任何语言和任何框架,配合任务调度、任务监控,很容易做到对成规模的爬虫项目进行有效监控管理。
|
||||
|
||||
本使用手册会帮助您解决在安装使用Crawlab遇到的任何问题。
|
||||
|
||||
首先,我们来看如何安装Crawlab吧,请查看[安装](./Installation/README.md)。
|
||||
33
documents/SUMMARY.md
Normal file
33
documents/SUMMARY.md
Normal file
@@ -0,0 +1,33 @@
|
||||
# Summary
|
||||
|
||||
* [Crawlab简介](README.md)
|
||||
* [安装Crawlab](Installation/README.md)
|
||||
* [Docker](Installation/Docker.md)
|
||||
* [直接部署](Installation/Direct.md)
|
||||
* [配置Crawlab](Config/README.md)
|
||||
* [使用Crawlab](Usage/README.md)
|
||||
* [节点](Usage/Node/README.md)
|
||||
* [查看节点列表](Usage/Node/View.md)
|
||||
* [查看节点拓扑图](Usage/Node/Network.md)
|
||||
* [爬虫](Usage/Spider/README.md)
|
||||
* [创建爬虫](Usage/Spider/Create.md)
|
||||
* [自定义爬虫](Usage/Spider/CustomizedSpider.md)
|
||||
* [可配置爬虫](Usage/Spider/ConfigurableSpider.md)
|
||||
* [部署爬虫](Usage/Spider/Deploy.md)
|
||||
* [运行爬虫](Usage/Spider/Run.md)
|
||||
* [统计数据](Usage/Spider/Analytics.md)
|
||||
* [任务](Usage/Task/README.md)
|
||||
* [查看任务](Usage/Task/View.md)
|
||||
* [操作任务](Usage/Task/Action.md)
|
||||
* [下载结果](Usage/Task/DownloadResults.md)
|
||||
* [定时任务](Usage/Schedule/README.md)
|
||||
* [原理](Architecture/README.md)
|
||||
* [整体架构](Architecture/Architecture.md)
|
||||
* [节点通信](Architecture/NodeCommunication.md)
|
||||
* [节点监控](Architecture/NodeMonitoring.md)
|
||||
* [爬虫部署](Architecture/SpiderDeployment.md)
|
||||
* [任务执行](Architecture/TaskExecution.md)
|
||||
* [样例](Examples/README.md)
|
||||
* [与Scrapy集成](Examples/ScrapyIntegration.md)
|
||||
* [与Puppeteer集成](Examples/PuppeteerIntegration.md)
|
||||
* [Q&A](QA/README.md)
|
||||
9
documents/Usage/Node/Edit.md
Normal file
9
documents/Usage/Node/Edit.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## 修改节点信息
|
||||
|
||||
后面我们需要让爬虫运行在各个节点上,需要让主机与节点进行通信,因此需要知道节点的IP地址和端口。我们需要手动配置一下节点的IP和端口。在`节点列表`中点击`操作`列里的蓝色查看按钮进入到节点详情。节点详情样子如下。
|
||||
|
||||
|
||||
|
||||
在右侧分别输入该节点对应的`节点IP`和`节点端口`,然后点击`保存`按钮,保存该节点信息。
|
||||
|
||||
这样,我们就完成了节点的配置工作。
|
||||
5
documents/Usage/Node/Network.md
Normal file
5
documents/Usage/Node/Network.md
Normal file
@@ -0,0 +1,5 @@
|
||||
## 节点拓扑图
|
||||
|
||||
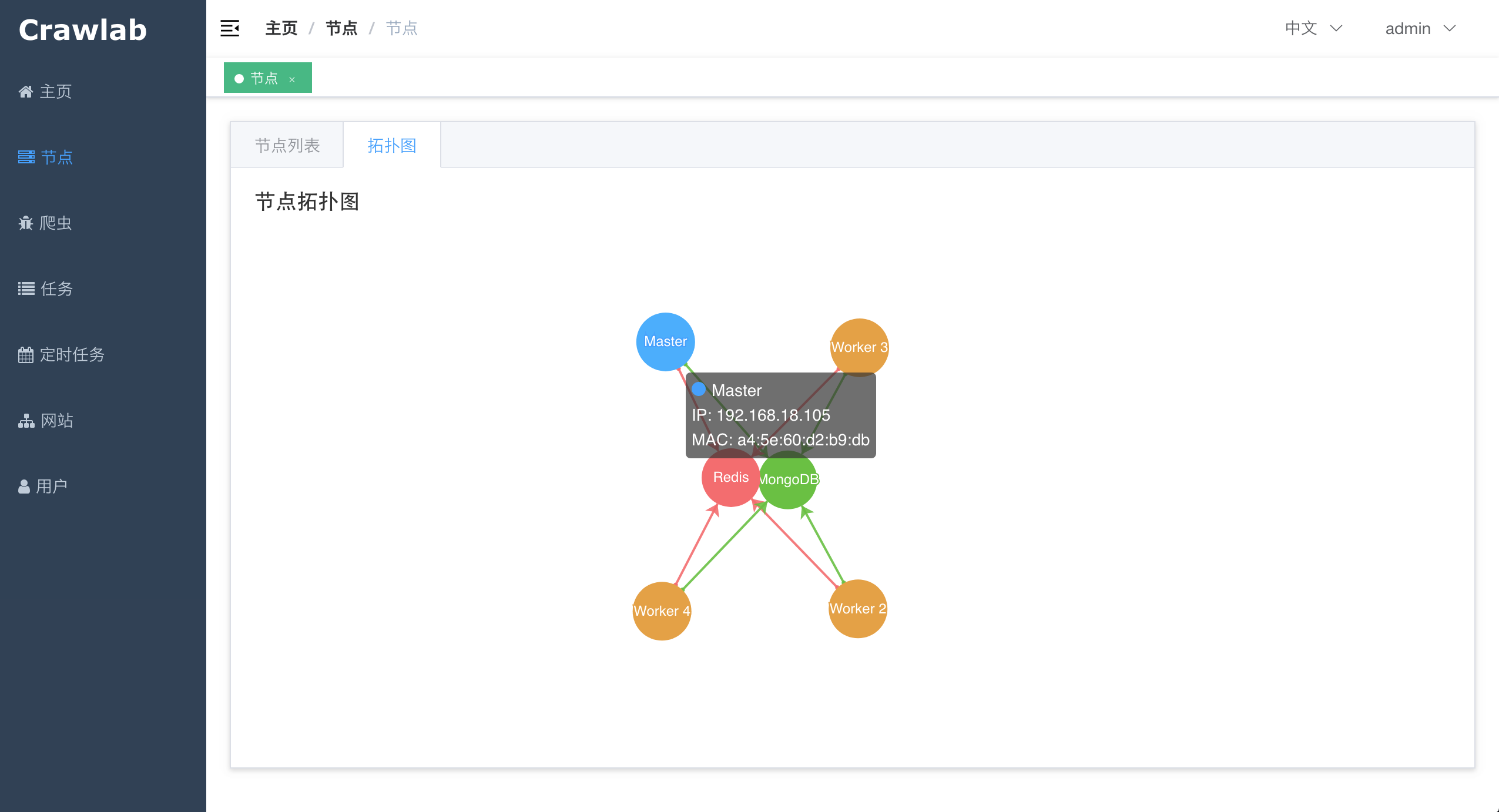
点击"拓扑图",查看节点之间的联系。
|
||||
|
||||
|
||||
6
documents/Usage/Node/README.md
Normal file
6
documents/Usage/Node/README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
## 节点
|
||||
|
||||
节点可以看作是一个服务器。节点负责执行爬虫任何、提供API等功能。节点之间是可以相互通信的,节点通信主要通过Redis。
|
||||
|
||||
1. [查看节点列表](./View.md)
|
||||
2. [查看节点拓扑图](./Network.md)
|
||||
5
documents/Usage/Node/View.md
Normal file
5
documents/Usage/Node/View.md
Normal file
@@ -0,0 +1,5 @@
|
||||
## 节点列表
|
||||
|
||||
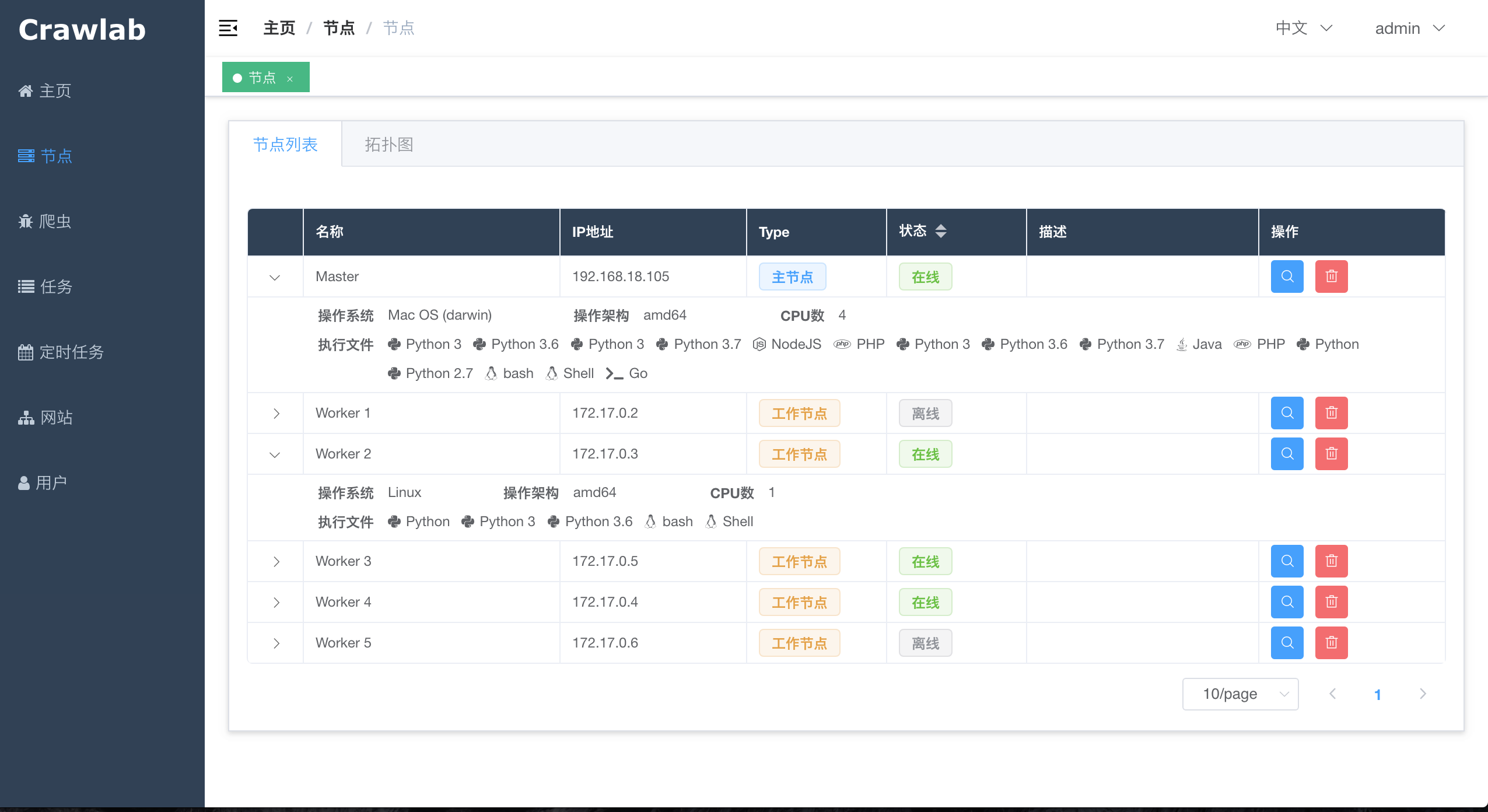
点击`侧边栏`的`节点`导航至`节点列表`,可以看到已上线的节点。点击在线节点的"展开"按钮可以查看该节点的系统详情。
|
||||
|
||||
|
||||
6
documents/Usage/README.md
Normal file
6
documents/Usage/README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
本小节将介绍如何使用Crawlab,包括如下内容:
|
||||
|
||||
1. [节点](./Node/README.md)
|
||||
2. [爬虫](./Spider/README.md)
|
||||
3. [任务](./Task/README.md)
|
||||
4. [定时任务](./Schedule/README.md)
|
||||
23
documents/Usage/Schedule/README.md
Normal file
23
documents/Usage/Schedule/README.md
Normal file
@@ -0,0 +1,23 @@
|
||||
## 定时任务
|
||||
|
||||
定时任务是指定某个时刻,重复性地执行的任务,英文叫做`Periodical Tasks`,在`Linux`中也被称为`Crontab`。定时任务可以让任务可以被执行多次,而用户则不用手动的操作来执行任务。在生产环境中,这非常常见。定时任务对于对增量抓取或对数据实时性有要求的用户来说非常有用。
|
||||
|
||||
定时任务列表会进行更新。每一次爬虫更新、删除、创建,以及定时任务的更新、删除、创建,都会触发定时任务列表的更新。
|
||||
|
||||
### 创建定时任务
|
||||
|
||||
导航至`定时任务`页面,可以看到定时任务的列表。
|
||||
|
||||
点击`添加定时任务`,弹出创建定时任务的弹框。填写相应的内容,点击`提交`按钮创建定时任务。
|
||||
|
||||
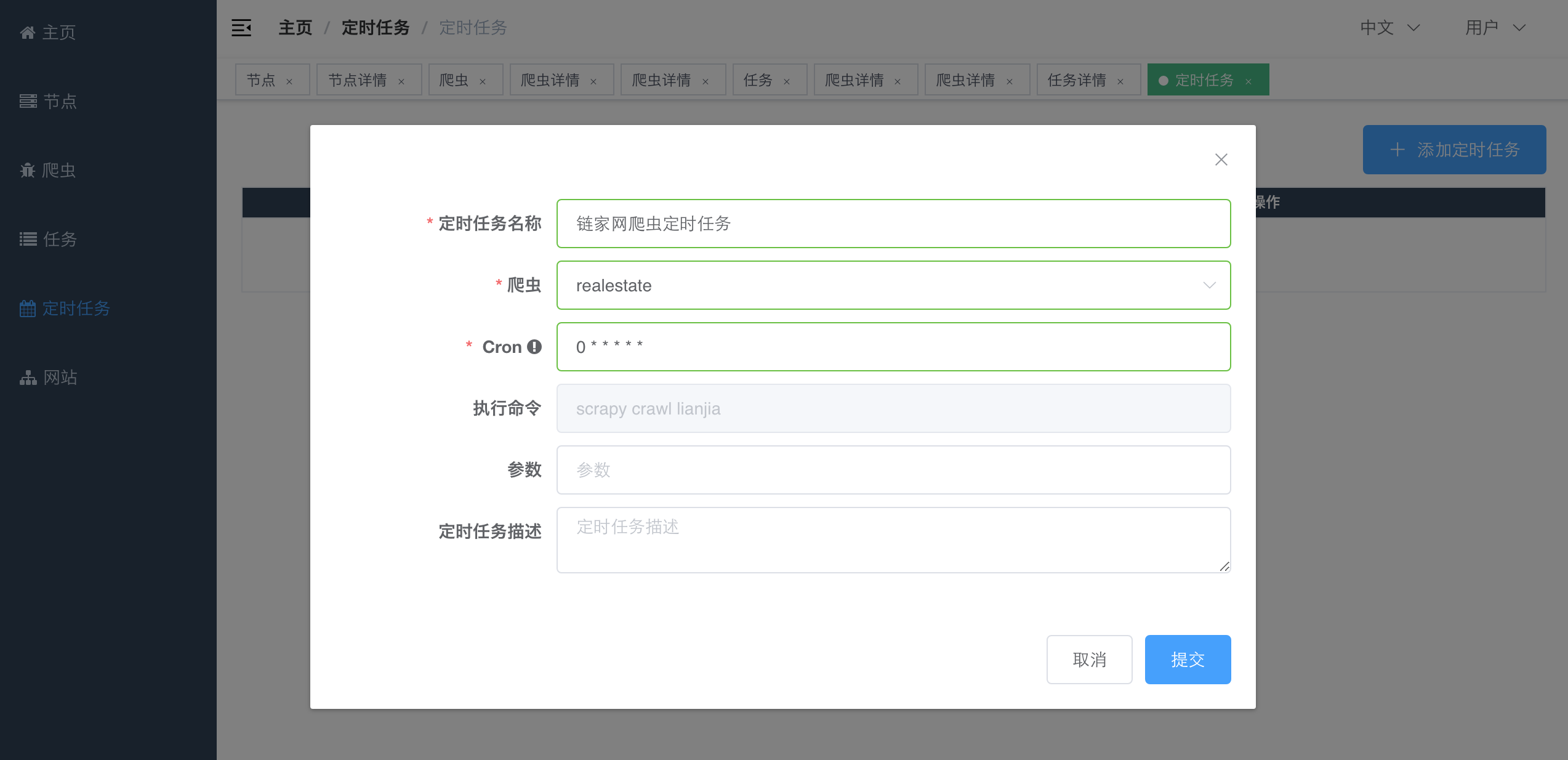
|
||||
|
||||
这里的`Cron`跟`Linux`中的`crontab`是一致的。如果对`crontab`不了解,可以参考[这篇文章](https://www.cnblogs.com/longjshz/p/5779215.html)。
|
||||
|
||||
### 修改定时任务
|
||||
|
||||
导航至`定时任务`页面,点击`操作`列的`修改`按钮,弹出修改定时任务的弹框。填写相应的内容,点击`提交`按钮修改定时任务。
|
||||
|
||||
### 删除定时任务
|
||||
|
||||
导航至`定时任务`页面,点击`操作`列的`删除`按钮,确认删除该任务。
|
||||
5
documents/Usage/Site/README.md
Normal file
5
documents/Usage/Site/README.md
Normal file
@@ -0,0 +1,5 @@
|
||||
## 网站
|
||||
|
||||
网站信息是帮助用户查看[站长之家](http://top.chinaz.com/hangye/)收录网站的信息的,包含`Robots协议`、`首页响应`等信息。
|
||||
|
||||
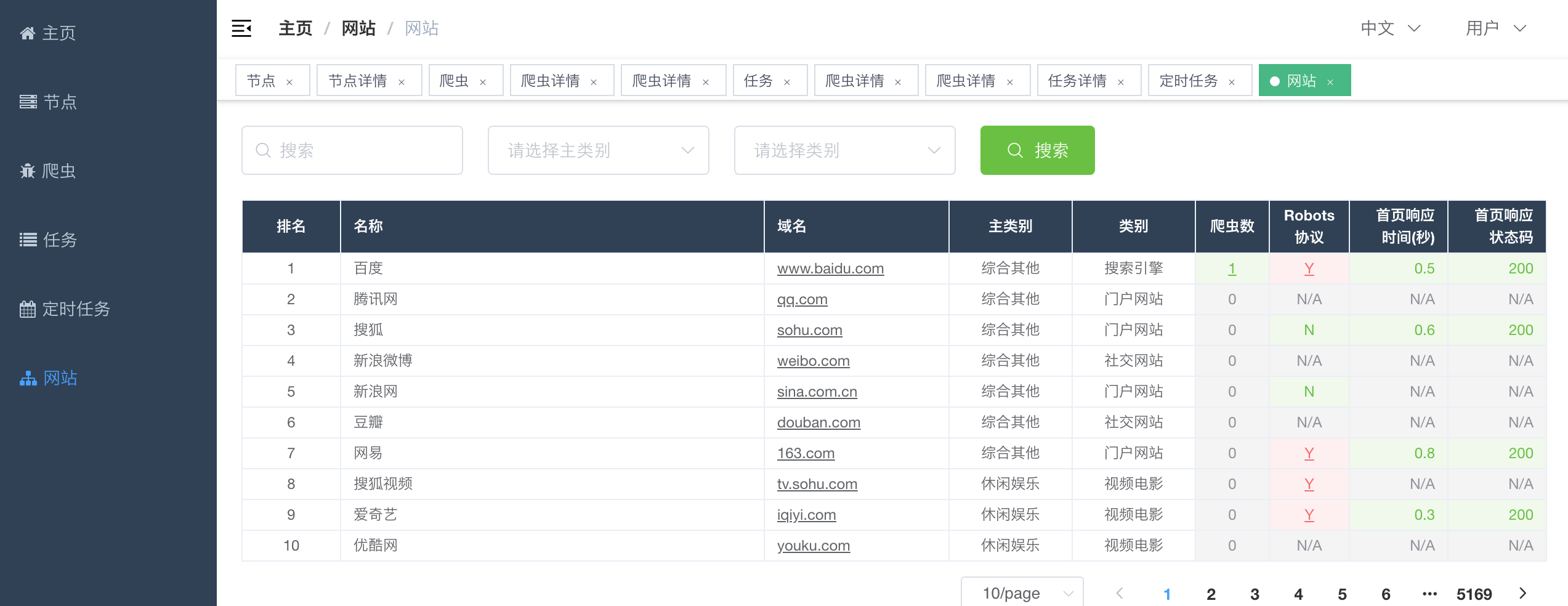
|
||||
7
documents/Usage/Spider/Analytics.md
Normal file
7
documents/Usage/Spider/Analytics.md
Normal file
@@ -0,0 +1,7 @@
|
||||
## 统计数据
|
||||
|
||||
在运行了一段时间之后,爬虫会积累一些统计数据,例如`运行成功率`、`任务数`、`运行时长`等指标。Crawlab将这些指标汇总并呈现给开发者。
|
||||
|
||||
要查看统计数据的话,只需要在`爬虫详情`中,点击`分析`标签,就可以看到爬虫的统计数据了。
|
||||
|
||||
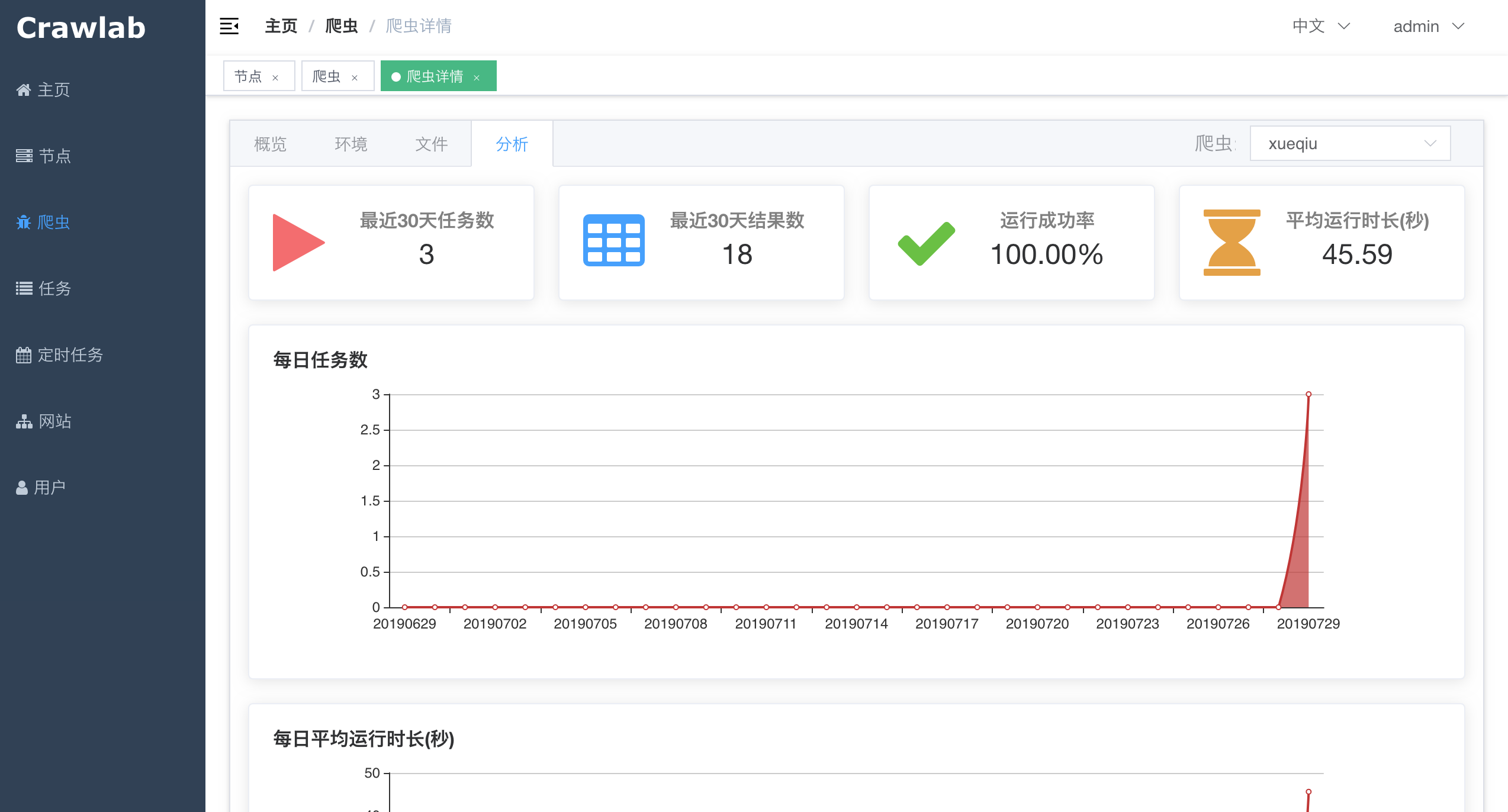
|
||||
66
documents/Usage/Spider/ConfigurableSpider.md
Normal file
66
documents/Usage/Spider/ConfigurableSpider.md
Normal file
@@ -0,0 +1,66 @@
|
||||
## 可配置爬虫
|
||||
|
||||
**注意: `v0.3.0`版本也就是Golang版本暂时不支持可配置爬虫**
|
||||
|
||||
可配置爬虫是版本[v0.2.1](https://github.com/tikazyq/crawlab/releases/tag/v0.2.1)开发的功能。目的是将具有相似网站结构的爬虫项目可配置化,将开发爬虫的过程流程化,大大提高爬虫开发效率。
|
||||
|
||||
Crawlab的可配置爬虫是基于Scrapy的,因此天生支持并发。而且,可配置爬虫完全支持[自定义爬虫](./CustomizedSpider.md)的一般功能,因此也支持任务调度、任务监控、日志监控、数据分析。
|
||||
|
||||
### 添加爬虫
|
||||
|
||||
在`侧边栏`点击`爬虫`导航至`爬虫列表`,点击**添加爬虫**按钮。
|
||||
|
||||

|
||||
|
||||
点击**可配置爬虫**。
|
||||
|
||||

|
||||
|
||||
输入完基本信息,点击**添加**。
|
||||
|
||||

|
||||
|
||||
### 配置爬虫
|
||||
|
||||
添加完成后,可以看到刚刚添加的可配置爬虫出现了在最下方,点击**查看**进入到**爬虫详情**。
|
||||
|
||||

|
||||
|
||||
点击**配置**标签进入到配置页面。接下来,我们需要对爬虫规则进行配置。
|
||||
|
||||

|
||||
|
||||
这里已经有一些配置好的初始输入项。我们简单介绍一下各自的含义。
|
||||
|
||||
#### 抓取类别
|
||||
|
||||
这也是爬虫抓取采用的策略,也就是爬虫遍历网页是如何进行的。作为第一个版本,我们有**仅列表**、**仅详情页**、**列表+详情页**。
|
||||
- 仅列表页。这也是最简单的形式,爬虫遍历列表上的列表项,将数据抓取下来。
|
||||
- 仅详情页。爬虫只抓取详情页。
|
||||
- 列表+详情页。爬虫先遍历列表页,将列表项中的详情页地址提取出来并跟进抓取详情页。
|
||||
|
||||
这里我们选择**列表+详情页**。
|
||||
|
||||
#### 列表项选择器 & 分页选择器
|
||||
|
||||
列表项的匹和分页按钮的匹配查询,由CSS或XPath来进行匹配。
|
||||
|
||||
#### 开始URL
|
||||
|
||||
爬虫最开始遍历的网址。
|
||||
|
||||
#### 遵守Robots协议
|
||||
|
||||
这个默认是开启的。如果开启,爬虫将先抓取网站的robots.txt并判断页面是否可抓;否则,不会对此进行验证。用户可以选择将其关闭。请注意,任何无视Robots协议的行为都有法律风险。
|
||||
|
||||
#### 列表页字段 & 详情页字段
|
||||
|
||||
这些都是再列表页或详情页中需要提取的字段。字段由CSS选择器或者XPath来匹配提取。可以选择文本或者属性。
|
||||
|
||||
在检查完目标网页的元素CSS选择器之后,我们输入列表项选择器、开始URL、列表页/详情页等信息。注意勾选url为详情页URL。
|
||||
|
||||

|
||||
|
||||
点击保存、预览,查看预览内容。
|
||||
|
||||

|
||||
5
documents/Usage/Spider/Create.md
Normal file
5
documents/Usage/Spider/Create.md
Normal file
@@ -0,0 +1,5 @@
|
||||
## 创建爬虫
|
||||
|
||||
Crawlab允许用户创建两种爬虫(很可惜,由于没有时间开发,可配置爬虫还没有加入到Golang版本中):
|
||||
1. [自定义爬虫](./CustomizedSpider.md)
|
||||
2. [可配置爬虫](./ConfigurableSpider.md)
|
||||
31
documents/Usage/Spider/CustomizedSpider.md
Normal file
31
documents/Usage/Spider/CustomizedSpider.md
Normal file
@@ -0,0 +1,31 @@
|
||||
## 自定义爬虫
|
||||
|
||||
自定义爬虫是指用户可以添加的任何语言任何框架的爬虫,高度自定义化。当用户添加好自定义爬虫之后,Crawlab就可以将其集成到爬虫管理的系统中来。
|
||||
|
||||
自定义爬虫的添加有两种方式:
|
||||
1. 通过Web界面上传爬虫
|
||||
2. 通过创建项目目录
|
||||
|
||||
### 通过Web界面上传
|
||||
|
||||
在通过Web界面上传之前,需要将爬虫项目文件打包成`zip`格式。
|
||||
|
||||
|
||||
|
||||
然后,在`侧边栏`点击`爬虫`导航至`爬虫列表`,点击`添加爬虫`按钮,选择`自定义爬虫`,点击`上传`按钮,选择刚刚打包好的`zip`文件。上传成功后,`爬虫列表`中会出现新添加的自定义爬虫。这样就算添加好了。
|
||||
|
||||
这个方式稍微有些繁琐,但是对于无法轻松获取服务器的读写权限时是非常有用的,适合在生产环境上使用。
|
||||
|
||||
### 通过添加项目目录
|
||||
|
||||
Crawlab会自动发现`CRAWLAB_SPIDER_PATH`目录下的所有爬虫目录,并将这些目录生成自定义爬虫并集成到Crawlab中。
|
||||
|
||||
这种方式非常方便,但是需要获得主机服务器的读写权限,因而比较适合在开发环境上采用。
|
||||
|
||||
### 配置爬虫
|
||||
|
||||
在定义爬虫中,我们需要配置一下`执行命令`(运行爬虫时后台执行的`shell`命令)和`结果集`(通过环境变量`CRAWLAB_COLLECTION`传递给爬虫程序,爬虫程序存储结果的地方),然后点击`保存`按钮保存爬虫信息。
|
||||
|
||||
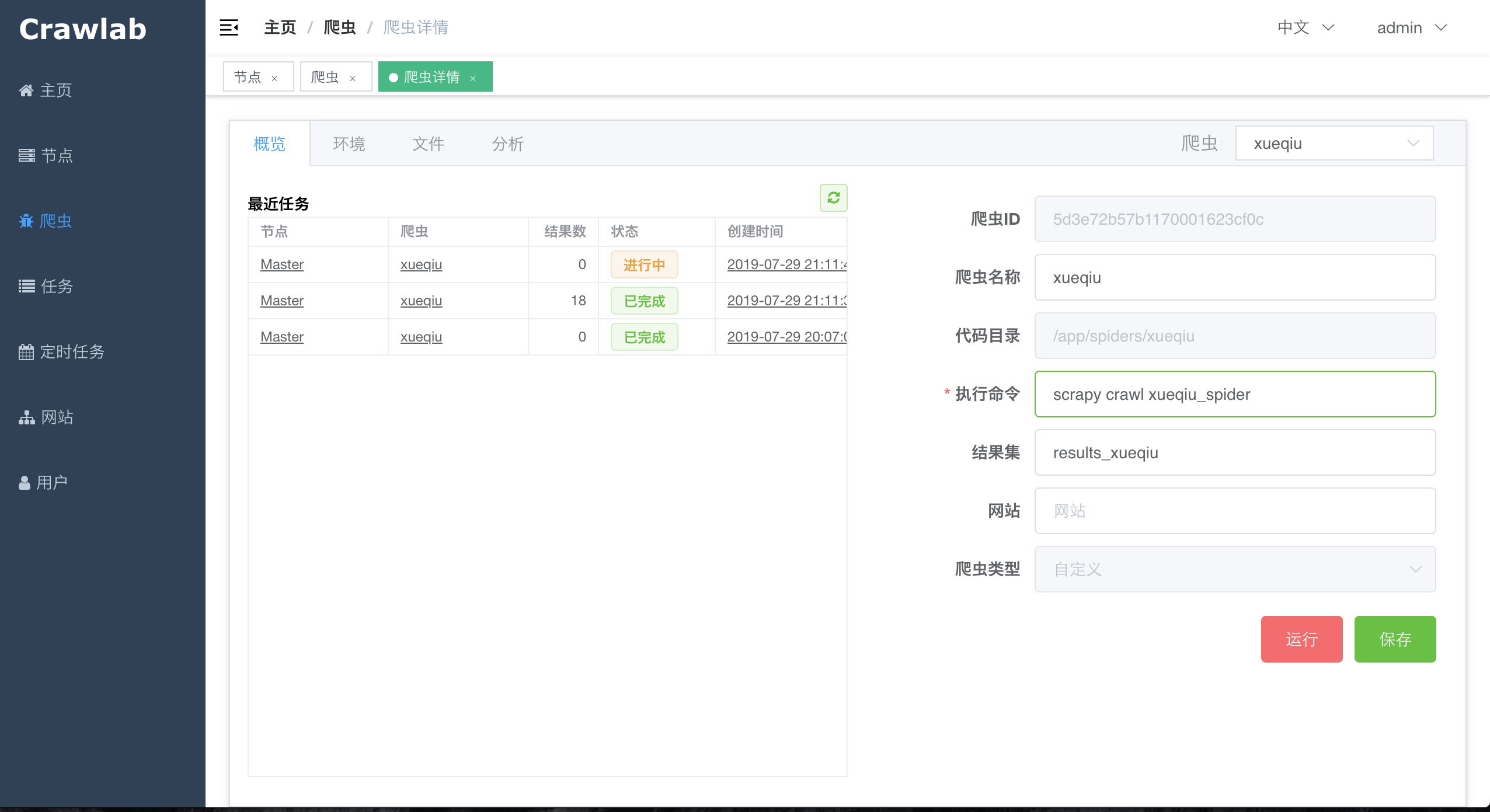
|
||||
|
||||
接下来,我们就可以部署、运行自定义爬虫了。
|
||||
3
documents/Usage/Spider/Deploy.md
Normal file
3
documents/Usage/Spider/Deploy.md
Normal file
@@ -0,0 +1,3 @@
|
||||
## 部署爬虫
|
||||
|
||||
Crawlab是自动部署爬虫的,每60秒主节点会将该节点上的爬虫文件同步给所有在线节点。因此,用户上传了爬虫之后,只需要等待最多60秒,就可以在所有节点上运行爬虫任务了。
|
||||
8
documents/Usage/Spider/README.md
Normal file
8
documents/Usage/Spider/README.md
Normal file
@@ -0,0 +1,8 @@
|
||||
## 爬虫
|
||||
|
||||
爬虫就是我们通常说的网络爬虫了,本小节将介绍如下内容:
|
||||
|
||||
1. [创建爬虫](./Create.md)
|
||||
2. [部署爬虫](./Deploy.md)
|
||||
3. [运行爬虫](./Run.md)
|
||||
4. [统计数据](./Analytics.md)
|
||||
16
documents/Usage/Spider/Run.md
Normal file
16
documents/Usage/Spider/Run.md
Normal file
@@ -0,0 +1,16 @@
|
||||
## 运行爬虫
|
||||
|
||||
Crawlab有两种运行爬虫的方式:
|
||||
1. 手动触发
|
||||
2. 定时任务触发
|
||||
|
||||
### 手动触发
|
||||
|
||||
1. 在`爬虫列表`中`操作`列点击`运行`按钮,或者
|
||||
2. 在`爬虫详情`中`概览`标签下点击`运行`按钮,或者
|
||||
|
||||
然后,Crawlab会提示任务已经派发到队列中去了,然后你可以在`爬虫详情`左侧看到新创建的任务。点击`创建时间`可以导航至`任务详情`。
|
||||
|
||||
### 定时任务触发
|
||||
|
||||
`定时任务触发`是比较常用的功能,对于`增量抓取`或对实时性有要求的任务很重要。这在[定时任务](../Schedule/README.md)中会详细介绍。
|
||||
11
documents/Usage/Task/Action.md
Normal file
11
documents/Usage/Task/Action.md
Normal file
@@ -0,0 +1,11 @@
|
||||
## 操作任务
|
||||
|
||||
### 停止任务
|
||||
|
||||
当任务运行起来之后,我们因为某个原因可能需要终止任务,这时我们需要在Crawlab中停止该任务。
|
||||
|
||||
导航至需要停止的任务的`任务详情`,点击`停止`按钮来终止任务。
|
||||
|
||||
### 删除任务
|
||||
|
||||
在`任务列表`中,点击`操作`列中的`删除`按钮,确认删除该任务。
|
||||
5
documents/Usage/Task/DownloadResults.md
Normal file
5
documents/Usage/Task/DownloadResults.md
Normal file
@@ -0,0 +1,5 @@
|
||||
## 下载结果
|
||||
|
||||
结果储存在数据库中之后,我们有时候需要将其导出,这时可以在界面中进行导出操作。
|
||||
|
||||
导航至`任务详情`,点击`结果`标签,点击`下载CSV`按钮,等待一会儿,结果就会以`CSV`的形式下载到本地。
|
||||
8
documents/Usage/Task/README.md
Normal file
8
documents/Usage/Task/README.md
Normal file
@@ -0,0 +1,8 @@
|
||||
## 任务
|
||||
|
||||
任务其实就是指某一次抓取任务或采集任务。任务与爬虫关联,其执行的也是爬虫指定的执行命令或采集规则。抓取或采集的结果与任务关联,因此可以查看到每一次任务的结果集。Crawlab的任务是整个采集流程的核心,抓取的过程都是跟任务关联起来的,因此任务对于Crawlab来说非常重要。任务被`主节点`触发,`工作节点`通过任务队列接收任务,然后在其所在节点上执行任务。
|
||||
|
||||
本小节将介绍以下内容:
|
||||
1. [查看任务](./View.md)
|
||||
2. [操作任务](./Action.md)
|
||||
3. [下载结果](./DownloadResults.md)
|
||||
21
documents/Usage/Task/View.md
Normal file
21
documents/Usage/Task/View.md
Normal file
@@ -0,0 +1,21 @@
|
||||
## 查看任务
|
||||
|
||||
### 任务列表
|
||||
|
||||
点击`侧边栏`的`任务`导航至`任务列表`。可以看到最近的10个生成的任务。可以根据`节点`、`爬虫`来过滤任务。
|
||||
|
||||
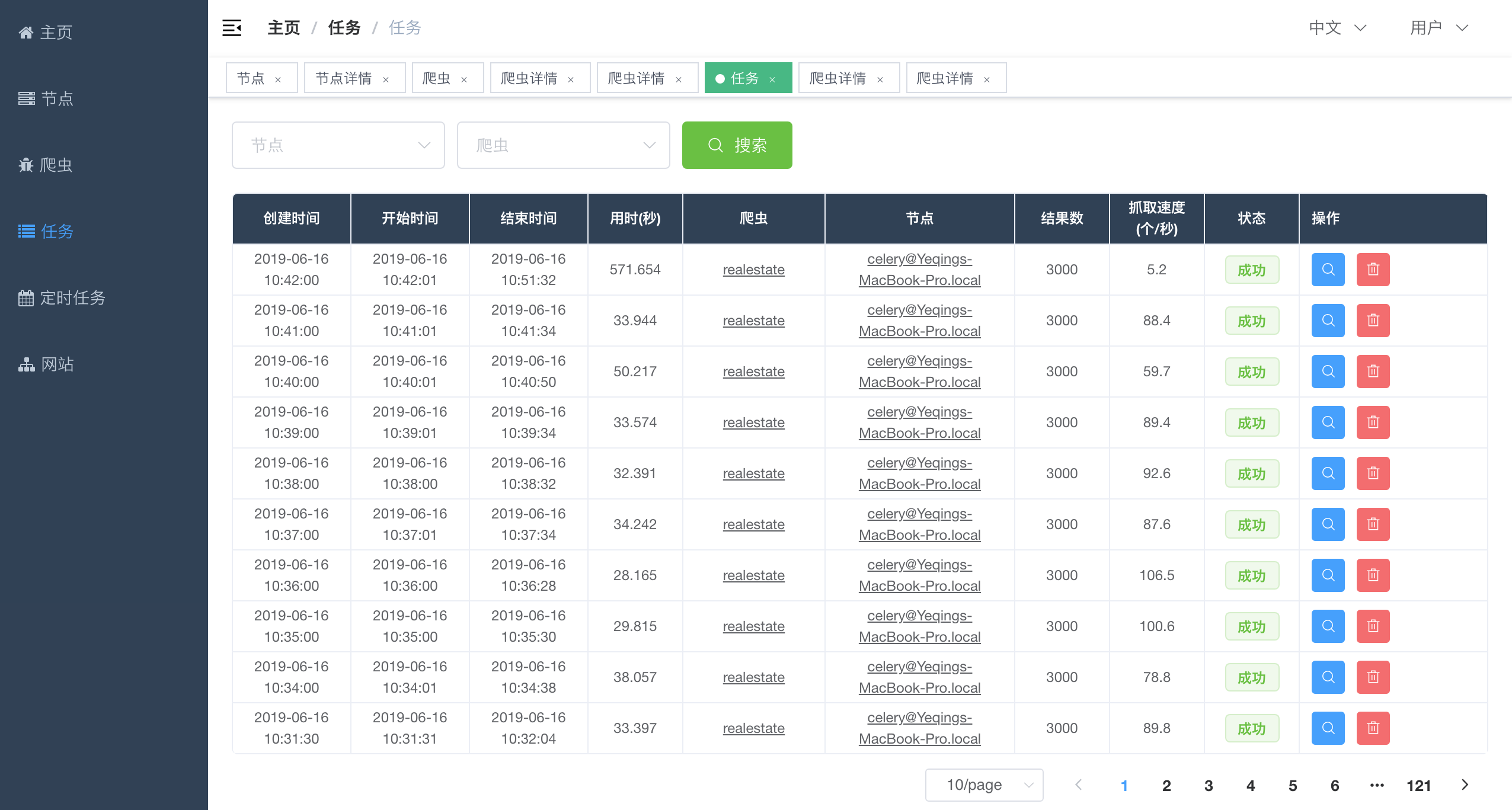
|
||||
|
||||
点击`操作`列的`查看`按钮,进入到该任务的`任务详情`。
|
||||
|
||||
### 任务日志
|
||||
|
||||
点击`日志`标签,可以查看任务日志。
|
||||
|
||||
|
||||
|
||||
### 任务结果
|
||||
|
||||
点击`结果`标签,可以查看任务结果。
|
||||
|
||||
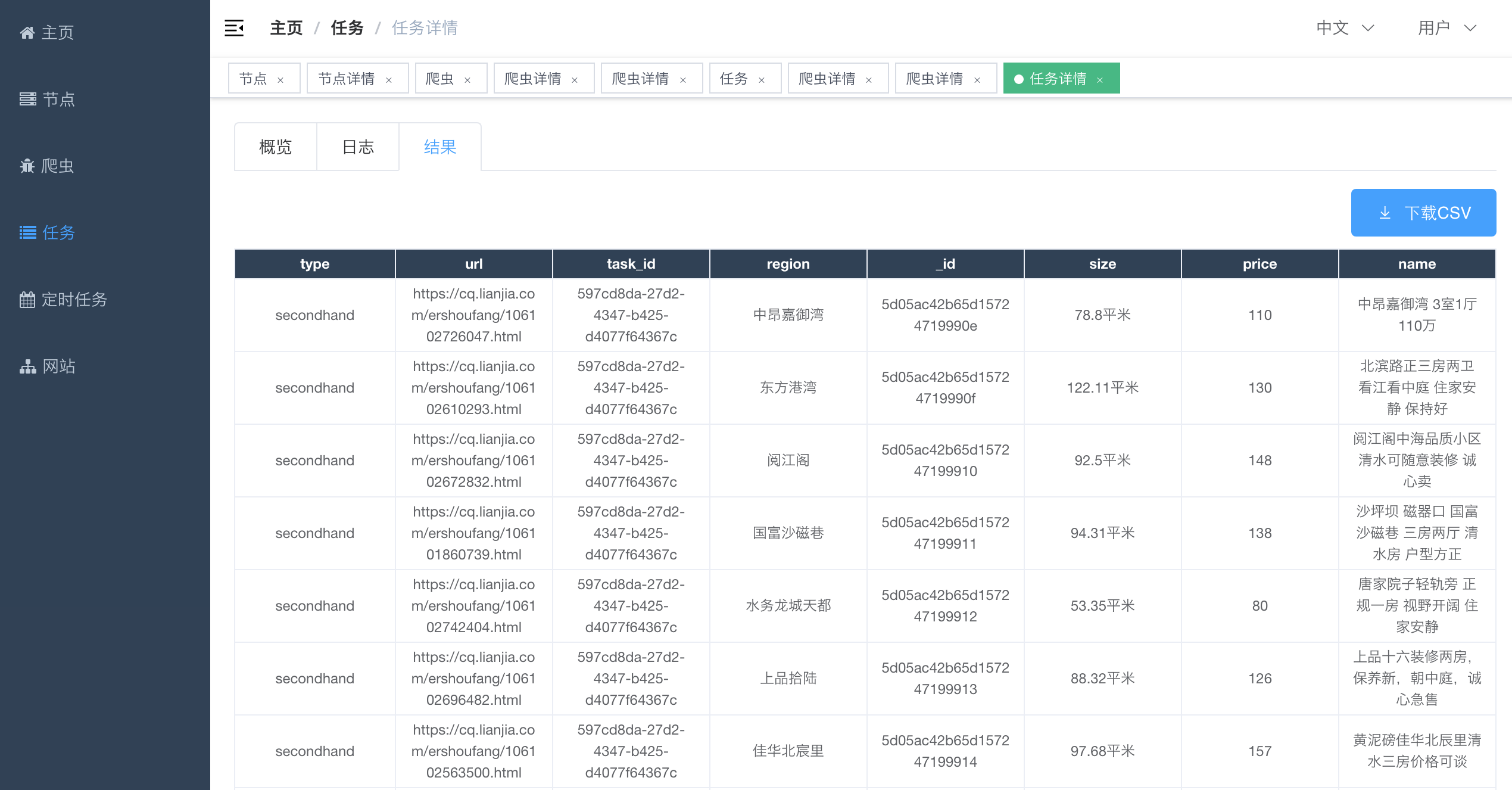
|
||||
Reference in New Issue
Block a user