mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-22 17:31:03 +01:00
updated README
This commit is contained in:
167
README-zh.md
167
README-zh.md
@@ -41,23 +41,22 @@
|
||||
|
||||
### 要求(Docker)
|
||||
- Docker 18.03+
|
||||
- Redis 5.x+
|
||||
- MongoDB 3.6+
|
||||
- Docker Compose 1.24+ (可选,但推荐)
|
||||
|
||||
### 要求(直接部署)
|
||||
- Go 1.12+
|
||||
- Go 1.15+
|
||||
- Node 8.12+
|
||||
- Redis 5.x+
|
||||
- MongoDB 3.6+
|
||||
- [SeaweedFS](https://github.com/chrislusf/seaweedfs) 2.59+
|
||||
|
||||
## 快速开始
|
||||
|
||||
请打开命令行并执行下列命令。请保证您已经提前安装了 `docker-compose`。
|
||||
|
||||
```bash
|
||||
git clone https://github.com/crawlab-team/crawlab
|
||||
cd crawlab
|
||||
git clone https://github.com/crawlab-team/examples
|
||||
cd examples/docker/basic
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
@@ -70,36 +69,52 @@ docker-compose up -d
|
||||
请用`docker-compose`来一键启动,甚至不用配置MongoDB和Redis数据库,**当然我们推荐这样做**。在当前目录中创建`docker-compose.yml`文件,输入以下内容。
|
||||
|
||||
```yaml
|
||||
version: '3.3'
|
||||
services:
|
||||
master:
|
||||
image: tikazyq/crawlab:latest
|
||||
container_name: master
|
||||
master:
|
||||
image: crawlabteam/crawlab:latest
|
||||
container_name: crawlab_example_master
|
||||
environment:
|
||||
CRAWLAB_SERVER_MASTER: "Y"
|
||||
CRAWLAB_MONGO_HOST: "mongo"
|
||||
CRAWLAB_REDIS_ADDRESS: "redis"
|
||||
ports:
|
||||
volumes:
|
||||
- "./.crawlab/master:/root/.crawlab"
|
||||
ports:
|
||||
- "8080:8080"
|
||||
depends_on:
|
||||
- mongo
|
||||
- redis
|
||||
|
||||
worker01:
|
||||
image: crawlabteam/crawlab:latest
|
||||
container_name: crawlab_example_worker01
|
||||
environment:
|
||||
CRAWLAB_SERVER_MASTER: "N"
|
||||
CRAWLAB_GRPC_ADDRESS: "master"
|
||||
volumes:
|
||||
- "./.crawlab/worker01:/root/.crawlab"
|
||||
depends_on:
|
||||
- master
|
||||
|
||||
worker02:
|
||||
image: crawlabteam/crawlab:latest
|
||||
container_name: crawlab_example_worker02
|
||||
environment:
|
||||
CRAWLAB_SERVER_MASTER: "N"
|
||||
CRAWLAB_GRPC_ADDRESS: "master"
|
||||
volumes:
|
||||
- "./.crawlab/worker02:/root/.crawlab"
|
||||
depends_on:
|
||||
- master
|
||||
|
||||
mongo:
|
||||
image: mongo:latest
|
||||
container_name: crawlab_example_mongo
|
||||
restart: always
|
||||
ports:
|
||||
- "27017:27017"
|
||||
redis:
|
||||
image: redis:latest
|
||||
restart: always
|
||||
ports:
|
||||
- "6379:6379"
|
||||
```
|
||||
|
||||
然后执行以下命令,Crawlab主节点+MongoDB+Redis就启动了。打开`http://localhost:8080`就能看到界面。
|
||||
然后执行以下命令,Crawlab主节点、工作节点+MongoDB 就启动了。打开`http://localhost:8080`就能看到界面。
|
||||
|
||||
```bash
|
||||
docker-compose up
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
Docker部署的详情,请见[相关文档](https://tikazyq.github.io/crawlab-docs/Installation/Docker.html)。
|
||||
@@ -110,69 +125,49 @@ Docker部署的详情,请见[相关文档](https://tikazyq.github.io/crawlab-d
|
||||
|
||||
## 截图
|
||||
|
||||
#### 登录
|
||||
#### 登陆页
|
||||
|
||||
|
||||

|
||||
|
||||
#### 首页
|
||||
#### 主页
|
||||
|
||||
|
||||
|
||||
|
||||
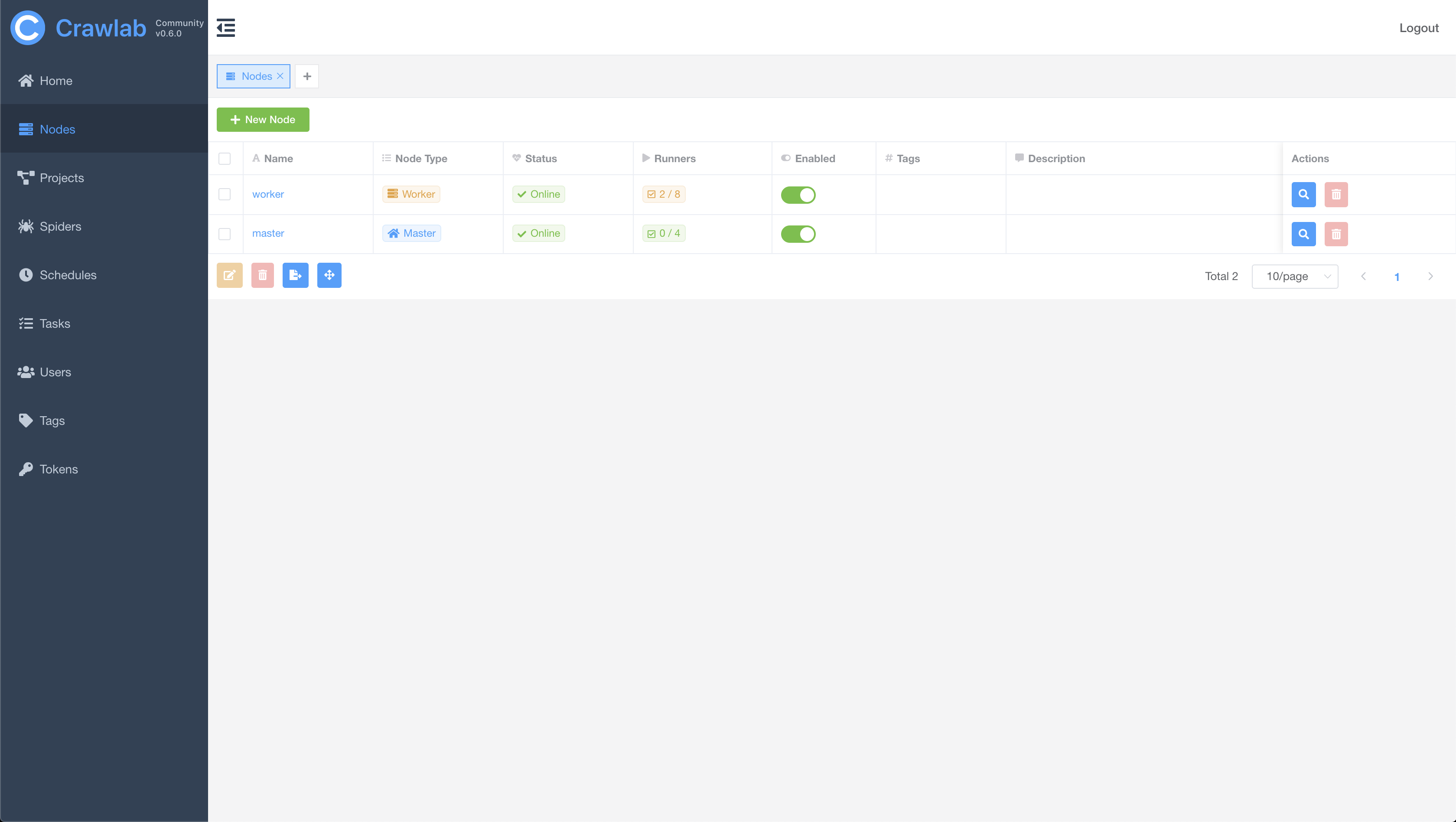
#### 节点列表
|
||||
|
||||
|
||||
|
||||
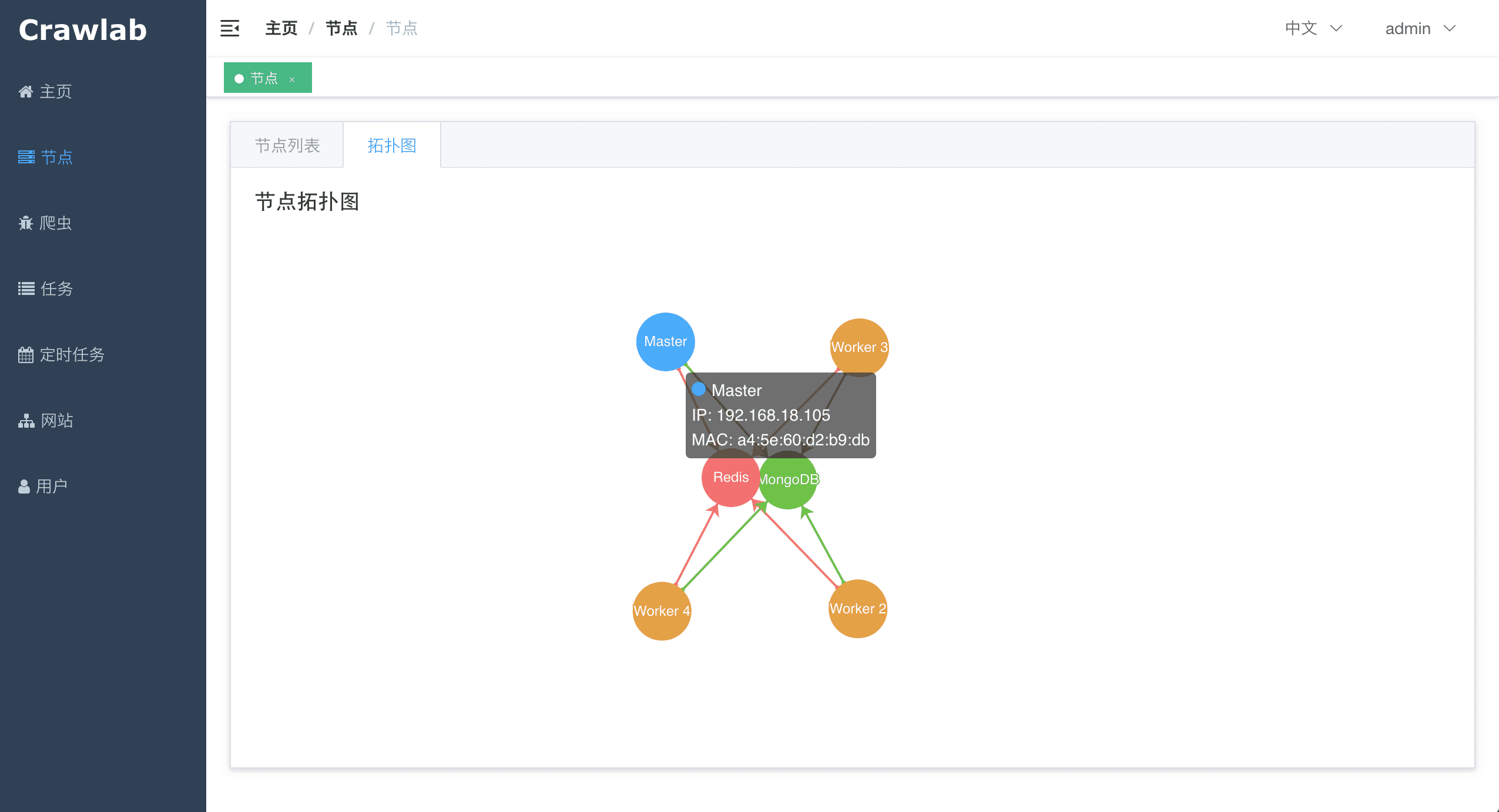
#### 节点拓扑图
|
||||
|
||||
|
||||
|
||||
|
||||
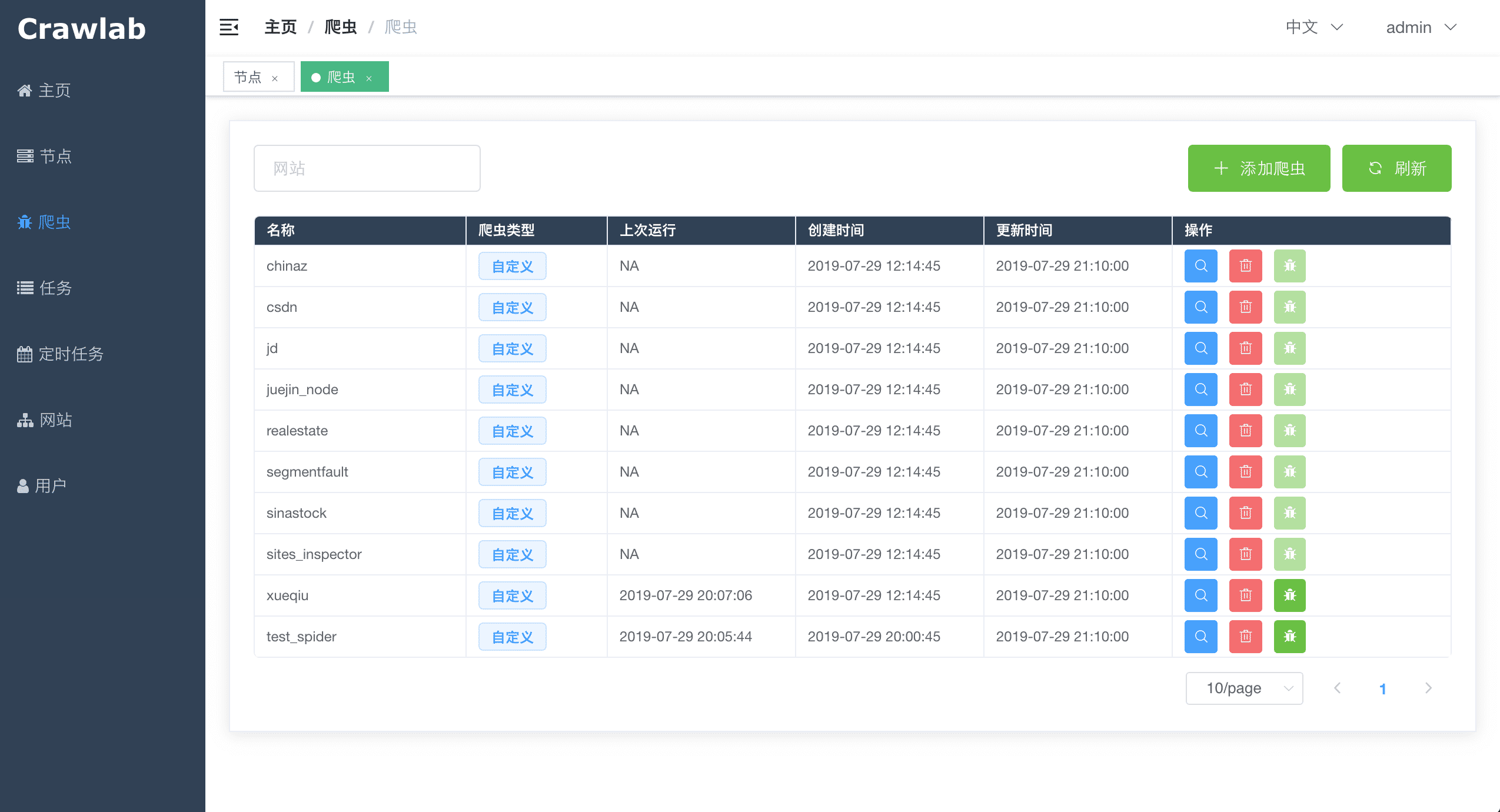
#### 爬虫列表
|
||||
|
||||
|
||||

|
||||
|
||||
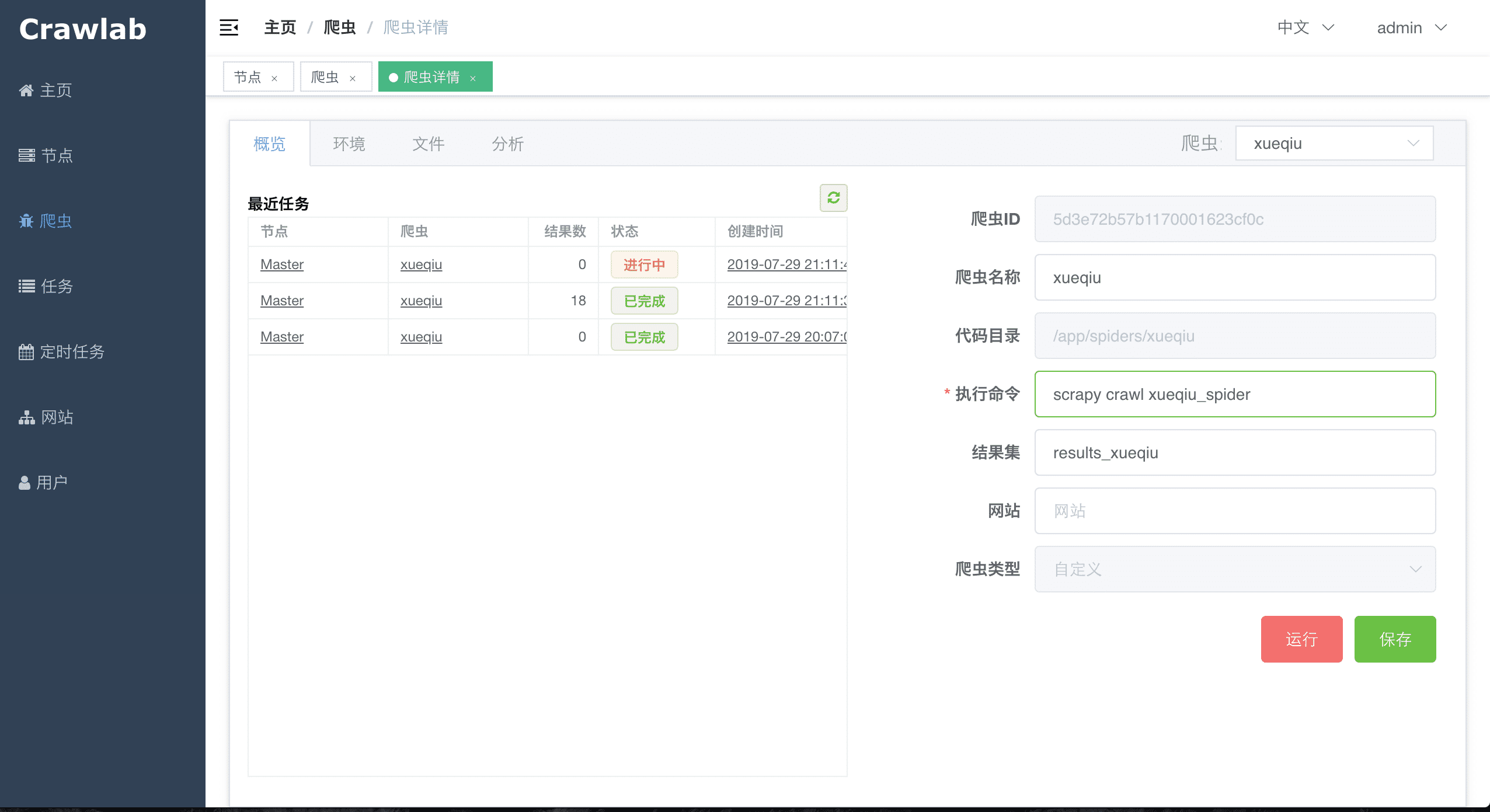
#### 爬虫概览
|
||||
|
||||
|
||||

|
||||
|
||||
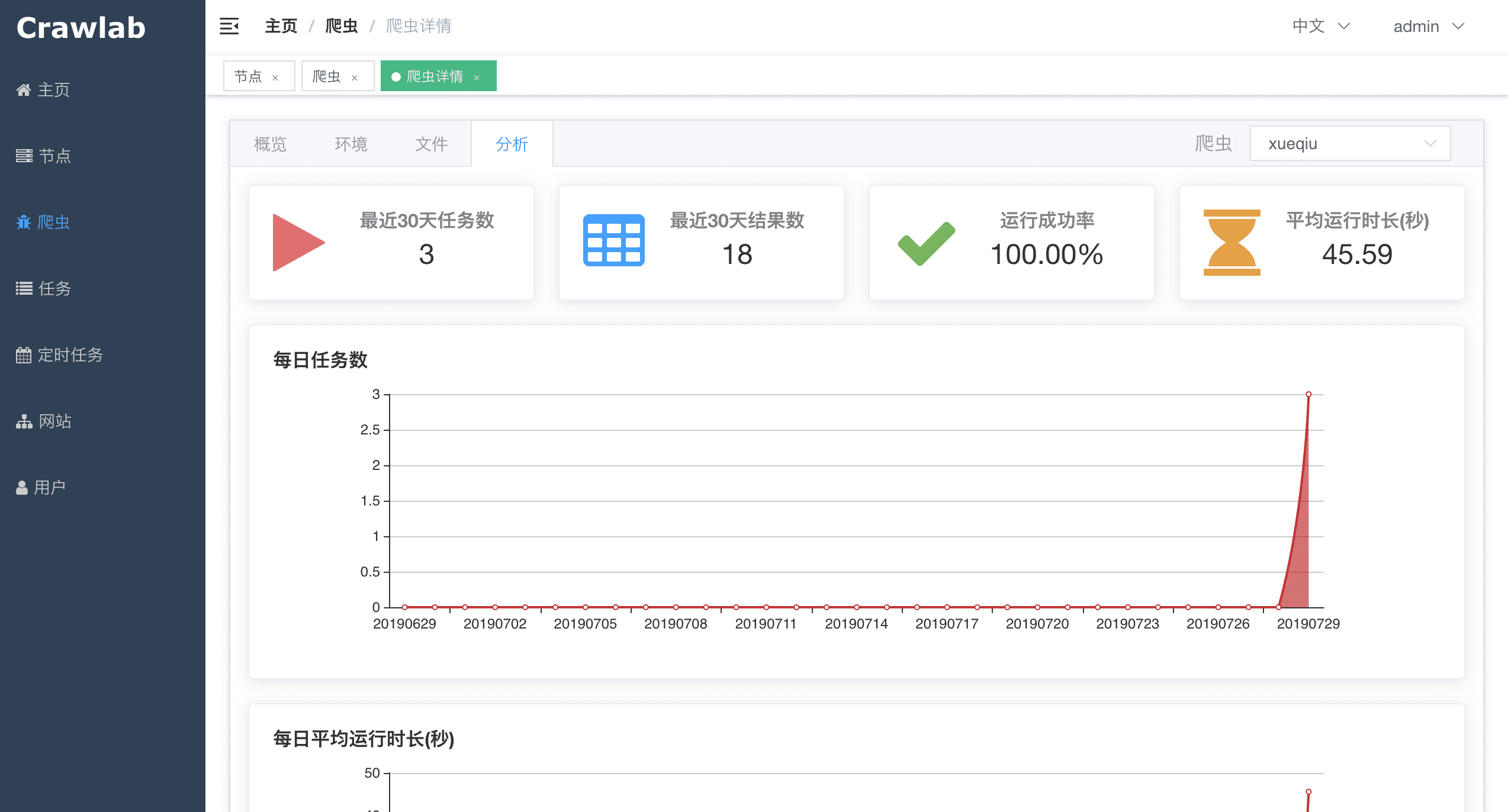
#### 爬虫分析
|
||||
#### 爬虫文件
|
||||
|
||||
|
||||
|
||||
#### 爬虫文件编辑
|
||||
|
||||

|
||||
|
||||
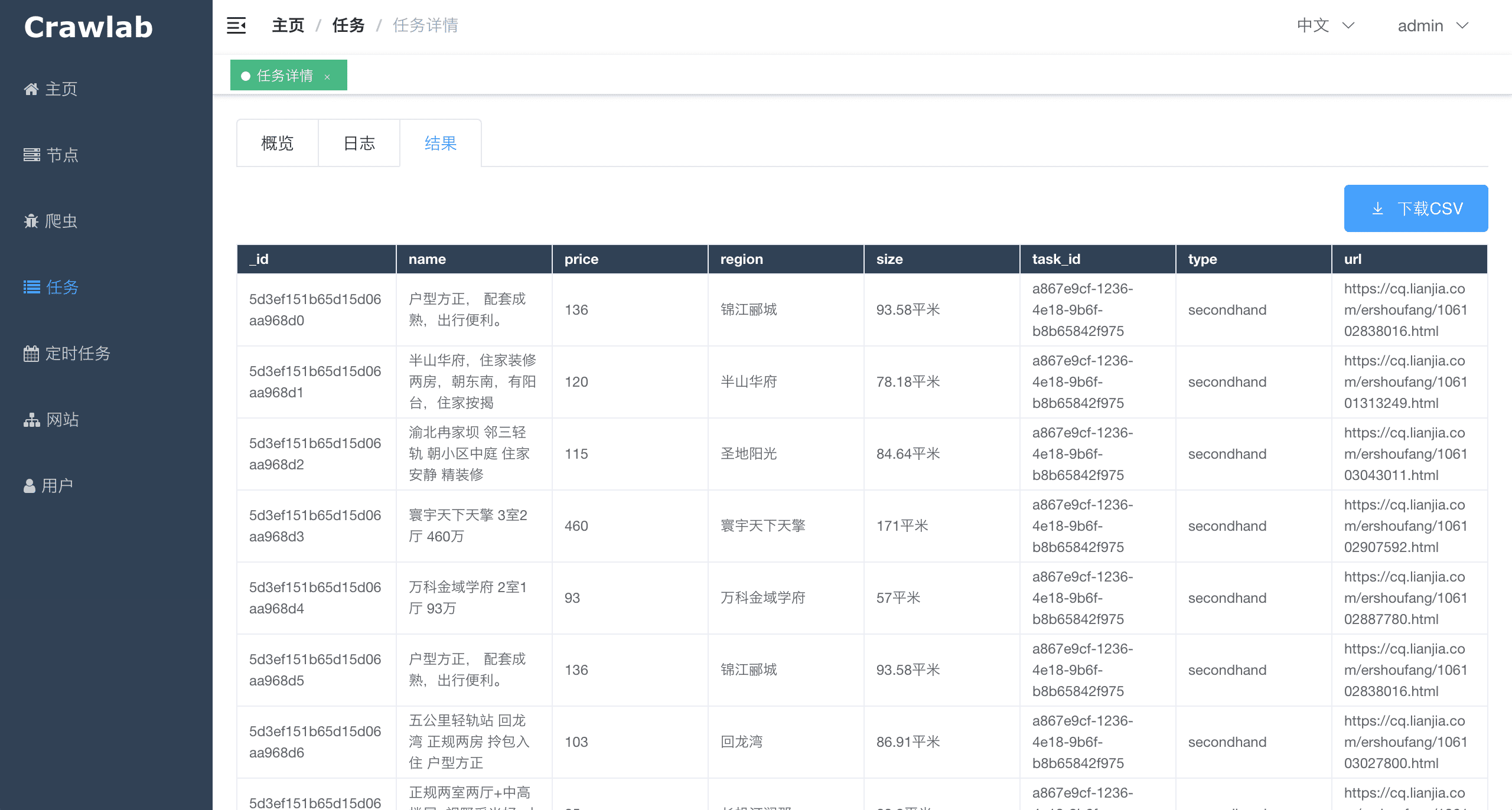
#### 任务抓取结果
|
||||
|
||||
|
||||
|
||||
|
||||
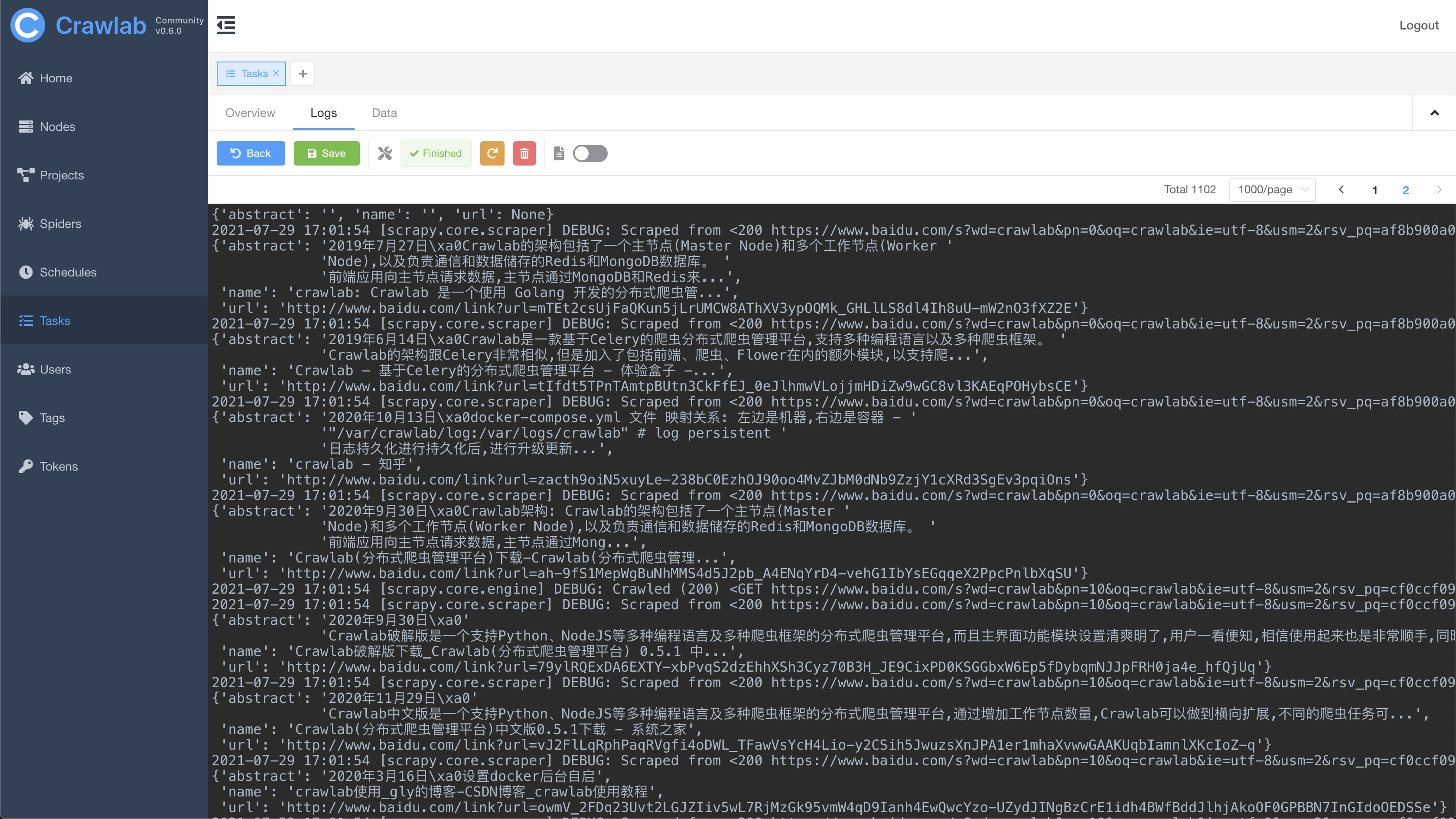
#### 任务日志
|
||||
|
||||

|
||||
|
||||
|
||||
#### 任务结果
|
||||
|
||||
|
||||
|
||||
#### 定时任务
|
||||
|
||||

|
||||
|
||||
#### 语言安装
|
||||
|
||||

|
||||
|
||||
#### 依赖安装
|
||||
|
||||

|
||||
|
||||
#### 消息通知
|
||||
|
||||
<img src="http://static-docs.crawlab.cn/notification-mobile.jpeg" height="480px">
|
||||
|
||||
|
||||
## 架构
|
||||
|
||||
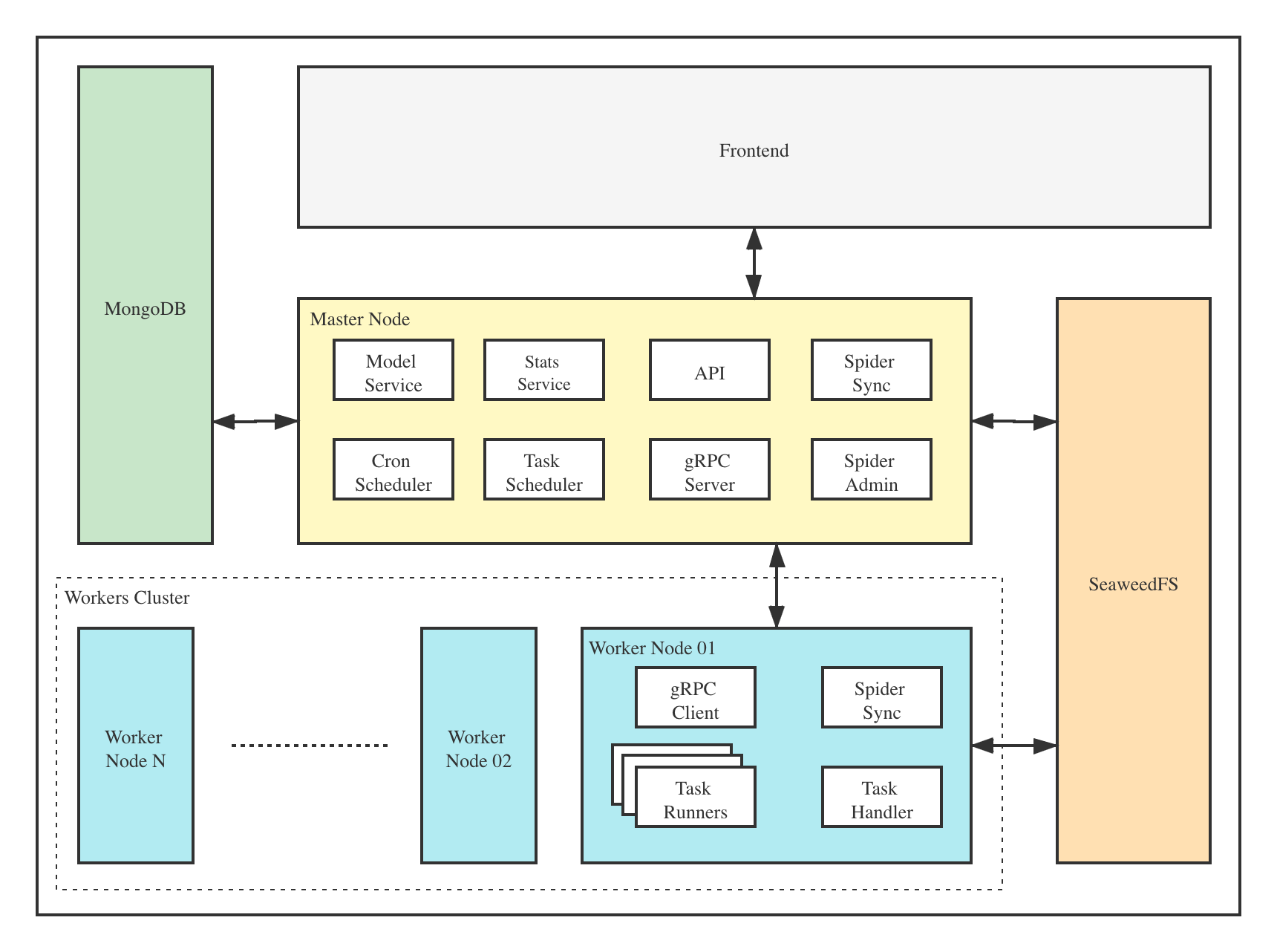
Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及负责通信和数据储存的Redis和MongoDB数据库。
|
||||
Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及 [SeaweeFS](https://github.com/chrislusf/seaweedfs) (分布式文件系统) 和 MongoDB 数据库。
|
||||
|
||||

|
||||
|
||||
|
||||
前端应用向主节点请求数据,主节点通过MongoDB和Redis来执行任务派发调度以及部署,工作节点收到任务之后,开始执行爬虫任务,并将任务结果储存到MongoDB。架构相对于`v0.3.0`之前的Celery版本有所精简,去除了不必要的节点监控模块Flower,节点监控主要由Redis完成。
|
||||
前端应用与主节点 (Master Node) 进行交互,主节点与其他模块(例如 MongoDB、SeaweedFS、工作节点)进行通信。主节点和工作节点 (Worker Nodes) 通过 [gRPC](https://grpc.io) (一种 RPC 框架) 进行通信。任务通过主节点上的任务调度器 (Task Scheduler) 进行调度分发,并被工作节点上的任务处理模块 (Task Handler) 接收,然后分配到任务执行器 (Task Runners) 中。任务执行器实际上是执行爬虫程序的进程,它可以通过 gRPC (内置于 SDK) 发送数据到其他数据源中,例如 MongoDB。
|
||||
|
||||
### 主节点
|
||||
|
||||
@@ -185,7 +180,7 @@ Crawlab的架构包括了一个主节点(Master Node)和多个工作节点
|
||||
4. 前端以及API服务
|
||||
5. 执行任务(可以将主节点当成工作节点)
|
||||
|
||||
主节点负责与前端应用进行通信,并通过Redis将爬虫任务派发给工作节点。同时,主节点会同步(部署)爬虫给工作节点,通过Redis和MongoDB的GridFS。
|
||||
主节点负责与前端应用进行通信,并将爬虫任务派发给工作节点。同时,主节点会同步(部署)爬虫到分布式文件系统 SeaweedFS,用于工作节点的文件同步。
|
||||
|
||||
### 工作节点
|
||||
|
||||
@@ -193,15 +188,17 @@ Crawlab的架构包括了一个主节点(Master Node)和多个工作节点
|
||||
|
||||
### MongoDB
|
||||
|
||||
MongoDB是Crawlab的运行数据库,储存有节点、爬虫、任务、定时任务等数据,另外GridFS文件储存方式是主节点储存爬虫文件并同步到工作节点的中间媒介。
|
||||
MongoDB是Crawlab的运行数据库,储存有节点、爬虫、任务、定时任务等数据。任务队列也储存在 MongoDB 里。
|
||||
|
||||
### Redis
|
||||
### SeaweedFS
|
||||
|
||||
Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点间数据通信的功能。例如,节点会将自己信息通过`HSET`储存在Redis的`nodes`哈希列表中,主节点根据哈希列表来判断在线节点。
|
||||
SeaweedFS 是开源分布式文件系统,由 [Chris Lu](https://github.com/chrislusf) 开发和维护。它能在分布式系统中有效稳定的储存和共享文件。在 Crawlab 中,SeaweedFS 主要用作文件同步和日志存储。
|
||||
|
||||
### 前端
|
||||
|
||||
前端是一个基于[Vue-Element-Admin](https://github.com/PanJiaChen/vue-element-admin)的单页应用。其中重用了很多Element-UI的控件来支持相应的展示。
|
||||
Frontend app is built upon [Element-Plus](https://github.com/element-plus/element-plus), a popular [Vue 3](https://github.com/vuejs/vue-next)-based UI framework. It interacts with API hosted on the Master Node, and indirectly controls Worker Nodes.
|
||||
|
||||
前端应用是基于 [Element-Plus](https://github.com/element-plus/element-plus) 构建的,它是基于 [Vue 3](https://github.com/vuejs/vue-next) 的 UI 框架。前端应用与主节点上的 API 进行交互,并间接控制工作节点。
|
||||
|
||||
## 与其他框架的集成
|
||||
|
||||
@@ -213,11 +210,11 @@ Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点
|
||||
|
||||
```python
|
||||
ITEM_PIPELINES = {
|
||||
'crawlab.pipelines.CrawlabMongoPipeline': 888,
|
||||
'crawlab.scrapy.pipelines.CrawlabPipeline': 888,
|
||||
}
|
||||
```
|
||||
|
||||
然后,启动 Scrapy 爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情-结果** 里。
|
||||
然后,启动 Scrapy 爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情 -> 数据** 里。
|
||||
|
||||
### 通用 Python 爬虫
|
||||
|
||||
@@ -234,13 +231,11 @@ result = {'name': 'crawlab'}
|
||||
save_item(result)
|
||||
```
|
||||
|
||||
然后,启动爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情-结果** 里。
|
||||
然后,启动爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情 -> 数据** 里。
|
||||
|
||||
### 其他框架和语言
|
||||
|
||||
爬虫任务本质上是由一个shell命令来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。另外,`CRAWLAB_COLLECTION`是Crawlab传过来的所存放collection的名称。
|
||||
|
||||
在爬虫程序中,需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中`CRAWLAB_COLLECTION`的collection中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
|
||||
爬虫任务实际上是通过 shell 命令执行的。任务 ID (Task ID) 作为环境变量 `CRAWLAB_TASK_ID` 被传入爬虫任务进程中,从而抓取的数据可以跟任务管理。
|
||||
|
||||
## 与其他框架比较
|
||||
|
||||
@@ -257,38 +252,6 @@ Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流
|
||||
| [Gerapy](https://github.com/Gerapy/Gerapy) | Python Django + Vue|Gerapy 是崔庆才大神开发的爬虫管理平台,安装部署非常简单,同样基于 scrapyd,有精美的 UI 界面,支持节点管理、代码编辑、可配置规则等功能|同样不支持 scrapy 以外的爬虫,而且据使用者反馈,1.0 版本有很多 bug,期待 2.0 版本会有一定程度的改进|   |
|
||||
| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | Python Flask|基于 scrapyd,开源版 Scrapyhub,非常简洁的 UI 界面,支持定时任务|可能有些过于简洁了,不支持分页,不支持节点管理,不支持 scrapy 以外的爬虫|   |
|
||||
|
||||
## Q&A
|
||||
|
||||
#### 1. 为何我访问 http://localhost:8080 提示访问不了?
|
||||
|
||||
假如您是Docker部署的,请检查一下您是否用了Docker Machine,这样的话您需要输入地址 http://192.168.99.100:8080 才行。
|
||||
|
||||
另外,请确保您用了`-p 8080:8080`来映射端口,并检查宿主机是否开放了8080端口。
|
||||
|
||||
#### 2. 我可以看到登录页面了,但为何我点击登陆的时候按钮一直转圈圈?
|
||||
|
||||
绝大多数情况下,您可能是没有正确配置`CRAWLAB_API_ADDRESS`这个环境变量。这个变量是告诉前端应该通过哪个地址来请求API数据的,因此需要将它设置为宿主机的IP地址+端口,例如 `192.168.0.1:8000`。接着,重启容器,在浏览器中输入宿主机IP+端口,就可以顺利登陆了。
|
||||
|
||||
请注意,8080是前端端口,8000是后端端口,您在浏览器中只需要输入前端的地址就可以了,要注意区分。
|
||||
|
||||
#### 3. 在爬虫页面有一些不认识的爬虫列表,这些是什么呢?
|
||||
|
||||
这些是demo爬虫,如果需要添加您自己的爬虫,请将您的爬虫文件打包成zip文件,再在爬虫页面中点击**添加爬虫**上传就可以了。
|
||||
|
||||
注意,Crawlab将取文件名作为爬虫名称,这个您可以后期更改。另外,请不要将zip文件名设置为中文,可能会导致上传不成功。
|
||||
|
||||
## 相关文章
|
||||
|
||||
- [爬虫管理平台Crawlab v0.3.0发布(Golang版本)](https://juejin.im/post/5d418deff265da03c926d75c)
|
||||
- [爬虫平台Crawlab核心原理--分布式架构](https://juejin.im/post/5d4ba9d1e51d4561cf15df79)
|
||||
- [爬虫平台Crawlab核心原理--自动提取字段算法](https://juejin.im/post/5cf4a7fa5188254c5879facd)
|
||||
- [爬虫管理平台Crawlab部署指南(Docker and more)](https://juejin.im/post/5d01027a518825142939320f)
|
||||
- [[爬虫手记] 我是如何在3分钟内开发完一个爬虫的](https://juejin.im/post/5ceb4342f265da1bc8540660)
|
||||
- [手把手教你如何用Crawlab构建技术文章聚合平台(二)](https://juejin.im/post/5c92365d6fb9a070c5510e71)
|
||||
- [手把手教你如何用Crawlab构建技术文章聚合平台(一)](https://juejin.im/user/5a1ba6def265da430b7af463/posts)
|
||||
|
||||
**注意: v0.3.0版本已将基于Celery的Python版本切换为了Golang版本,如何部署请参照文档**
|
||||
|
||||
## 贡献者
|
||||
<a href="https://github.com/tikazyq">
|
||||
<img src="https://avatars3.githubusercontent.com/u/3393101?s=460&v=4" height="80">
|
||||
|
||||
@@ -113,7 +113,7 @@ services:
|
||||
restart: always
|
||||
```
|
||||
|
||||
Then execute the command below, and Crawlab Master Node + MongoDB + Redis will start up. Open the browser and enter `http://localhost:8080` to see the UI interface.
|
||||
Then execute the command below, and Crawlab Master and Worker Nodes + MongoDB will start up. Open the browser and enter `http://localhost:8080` to see the UI interface.
|
||||
|
||||
```bash
|
||||
docker-compose up -d
|
||||
@@ -173,7 +173,7 @@ The frontend app interacts with the master node, which communicates with other c
|
||||
The Master Node is the core of the Crawlab architecture. It is the center control system of Crawlab.
|
||||
|
||||
The Master Node provides below services:
|
||||
1. Task Coordination;
|
||||
1. Task Scheduling;
|
||||
2. Worker Node Management and Communication;
|
||||
3. Spider Deployment;
|
||||
4. Frontend and API Services;
|
||||
|
||||
Reference in New Issue
Block a user