mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-21 17:21:09 +01:00
Merge branch 'develop' of github.com:tikazyq/crawlab into develop
This commit is contained in:
24
README-zh.md
24
README-zh.md
@@ -52,7 +52,7 @@ docker run -d --rm --name crawlab \
|
||||
|
||||
当然也可以用`docker-compose`来一键启动,甚至不用配置MongoDB和Redis数据库,**当然我们推荐这样做**。在当前目录中创建`docker-compose.yml`文件,输入以下内容。
|
||||
|
||||
```bash
|
||||
```yaml
|
||||
version: '3.3'
|
||||
services:
|
||||
master:
|
||||
@@ -97,49 +97,49 @@ Docker部署的详情,请见[相关文档](https://tikazyq.github.io/crawlab/I
|
||||
|
||||
#### 登录
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/login.png?v0.3.0">
|
||||
|
||||
|
||||
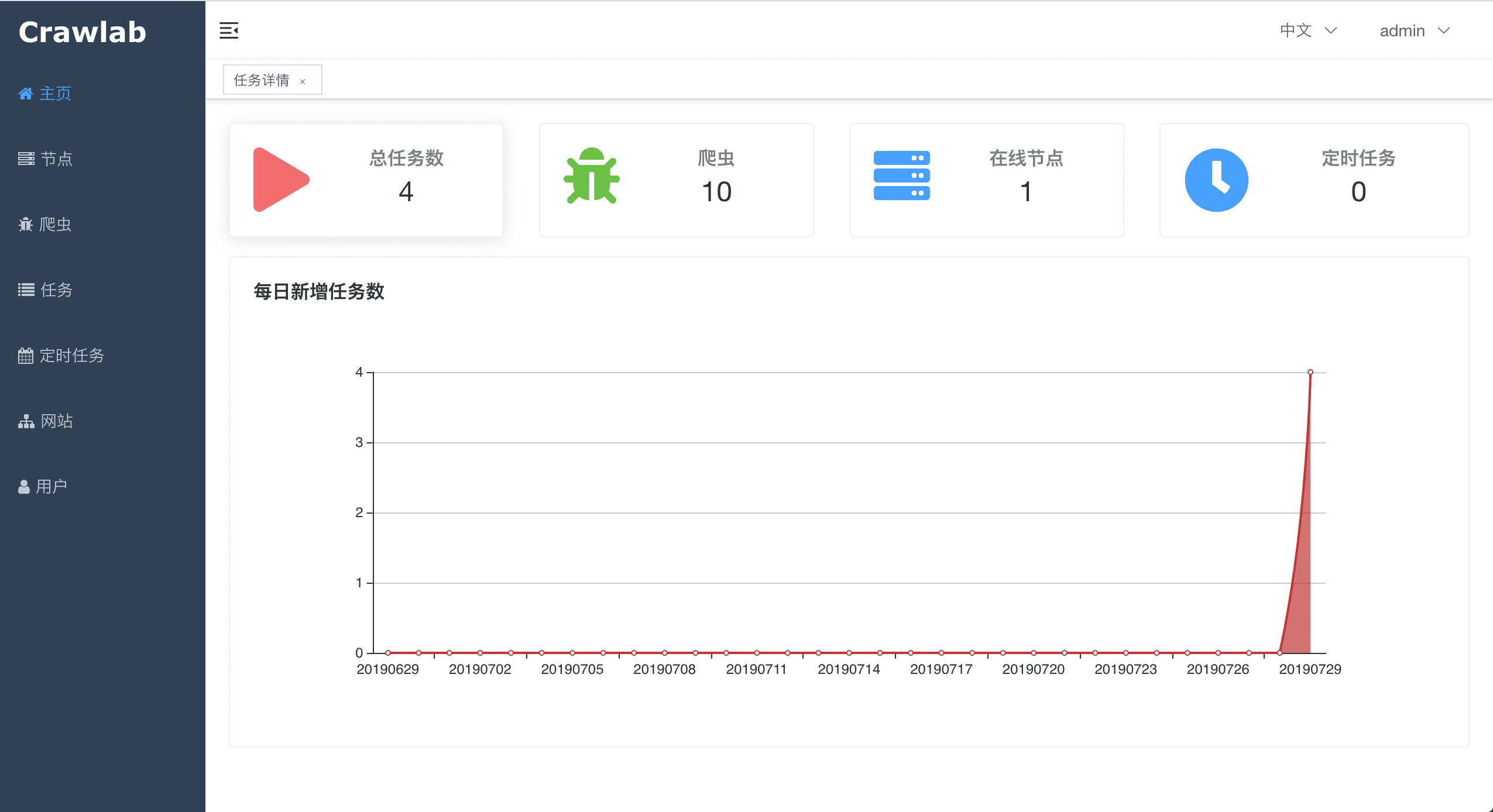
#### 首页
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/home.png?v0.3.0">
|
||||
|
||||
|
||||
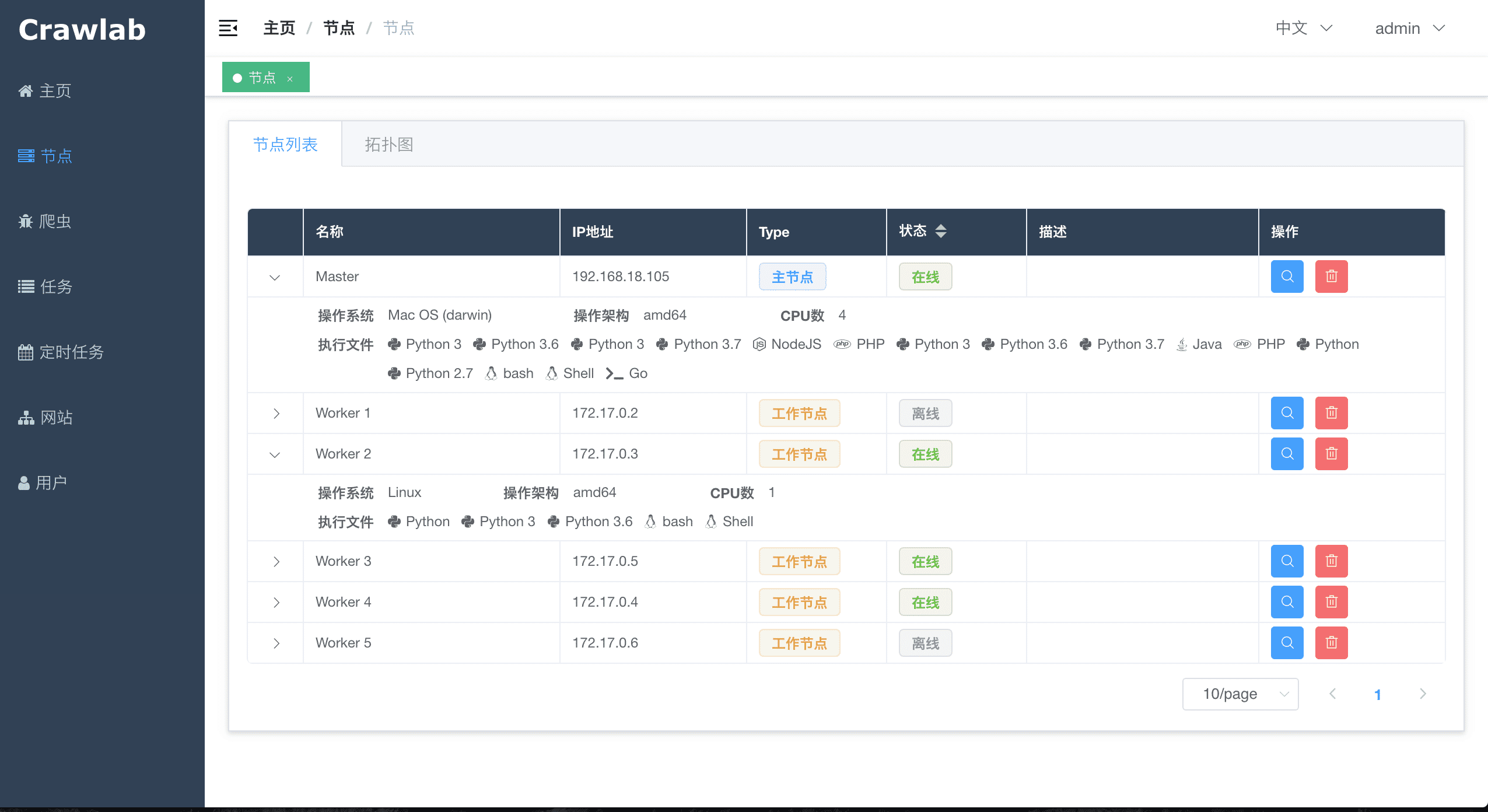
#### 节点列表
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/node-list.png?v0.3.0">
|
||||
|
||||
|
||||
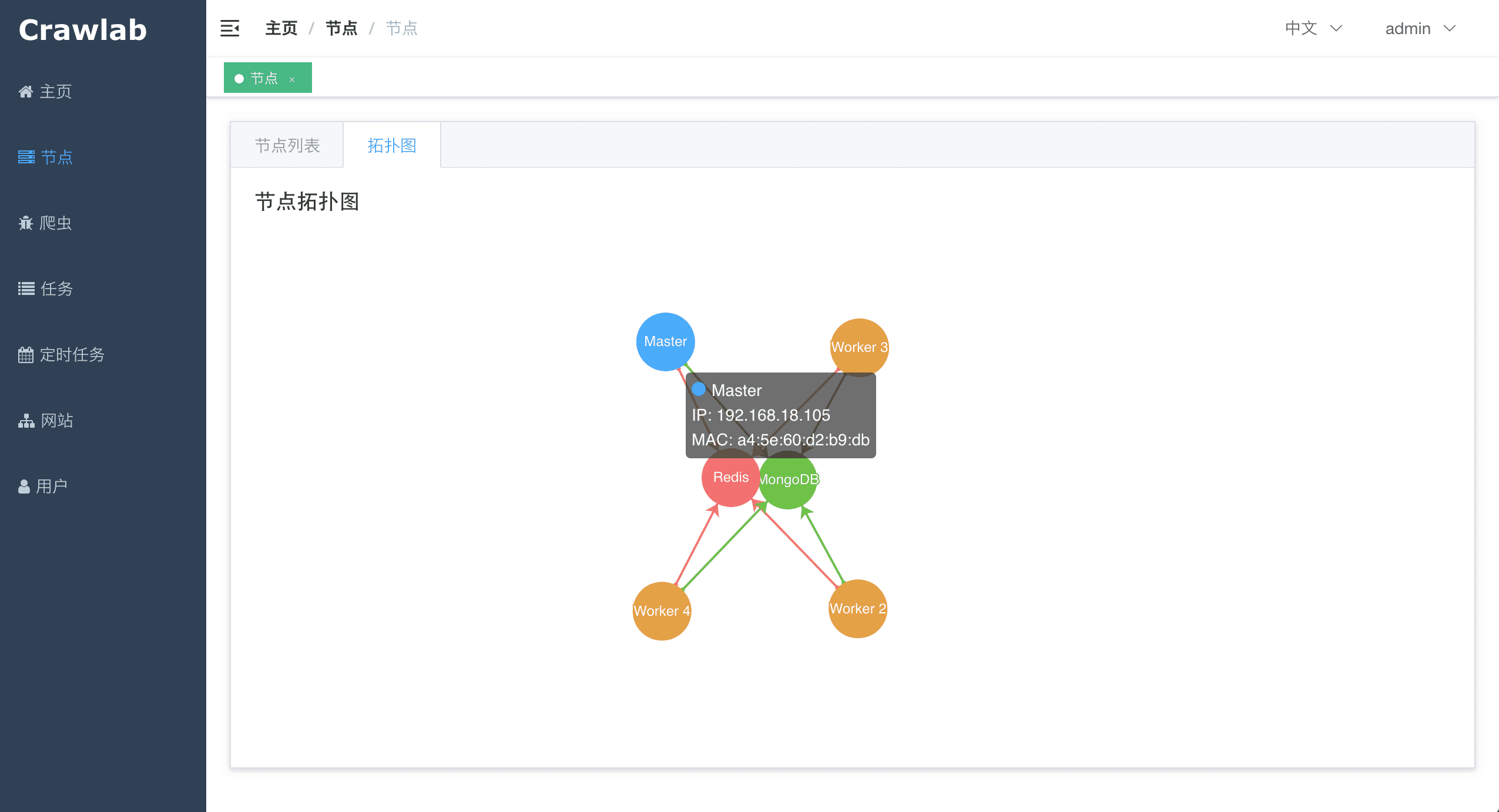
#### 节点拓扑图
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/node-network.png?v0.3.0">
|
||||
|
||||
|
||||
#### 爬虫列表
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/spider-list.png?v0.3.0">
|
||||
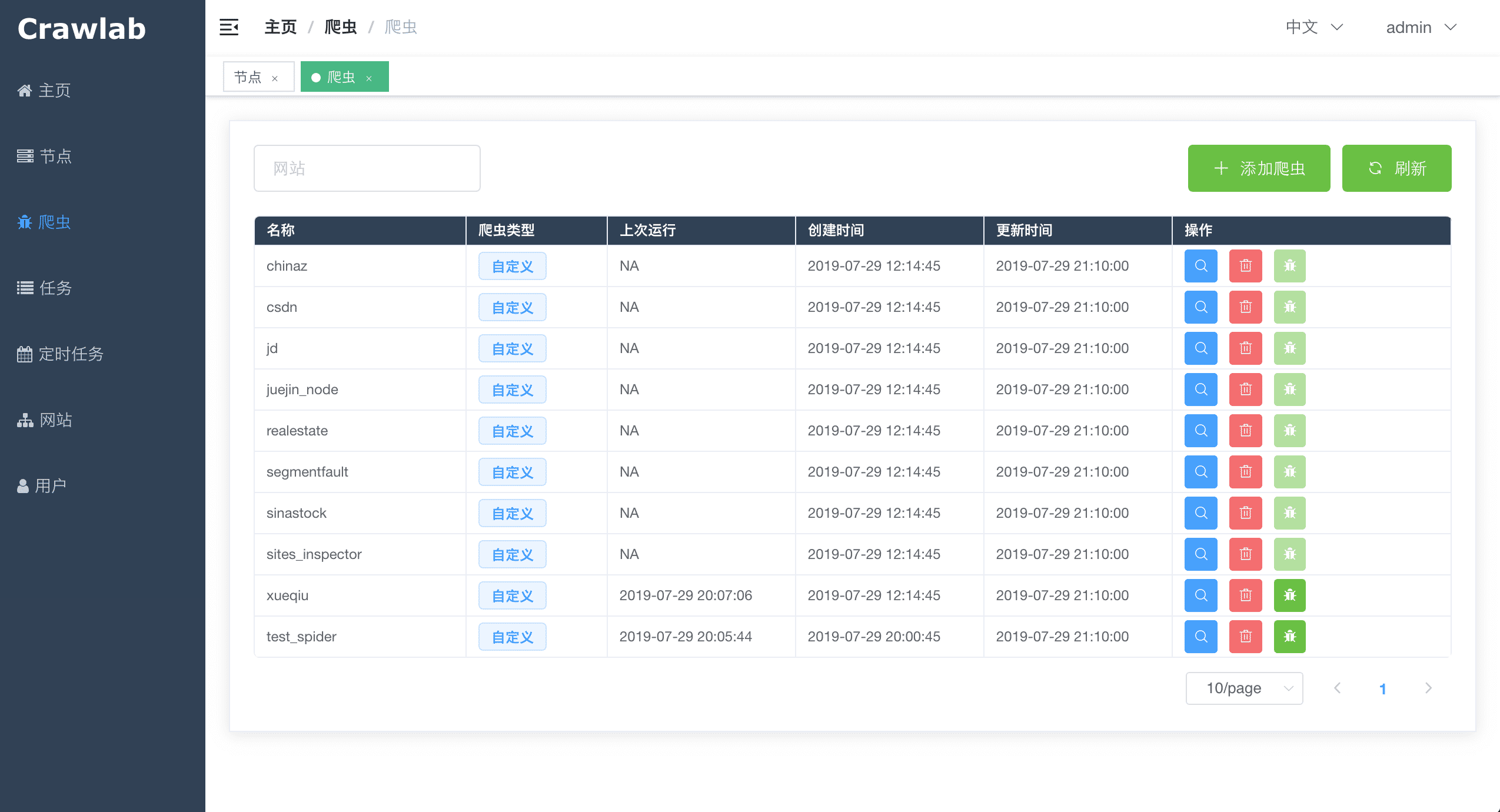
|
||||
|
||||
#### 爬虫概览
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/spider-overview.png?v0.3.0">
|
||||
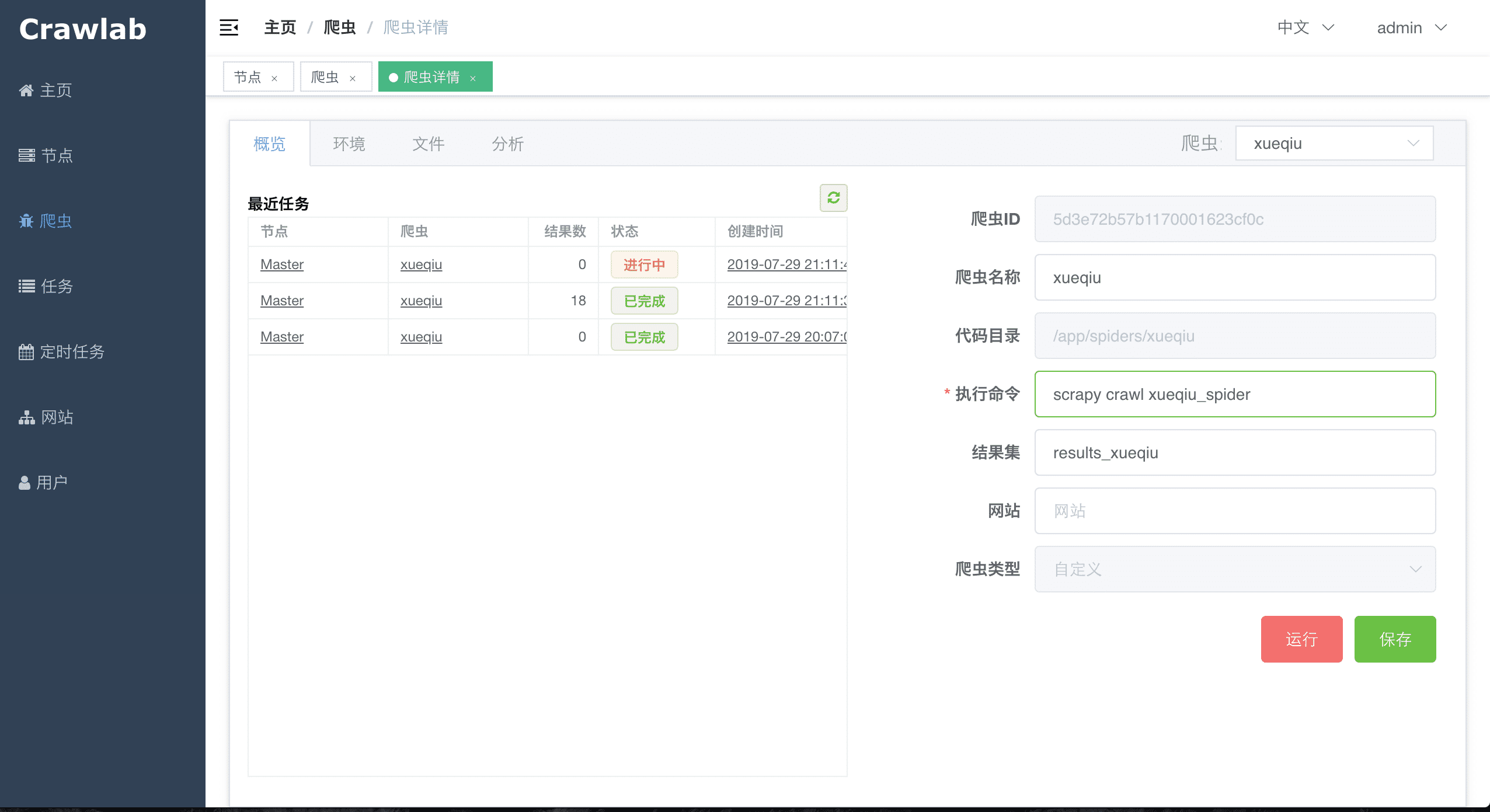
|
||||
|
||||
#### 爬虫分析
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/spider-analytics.png?v0.3.0">
|
||||
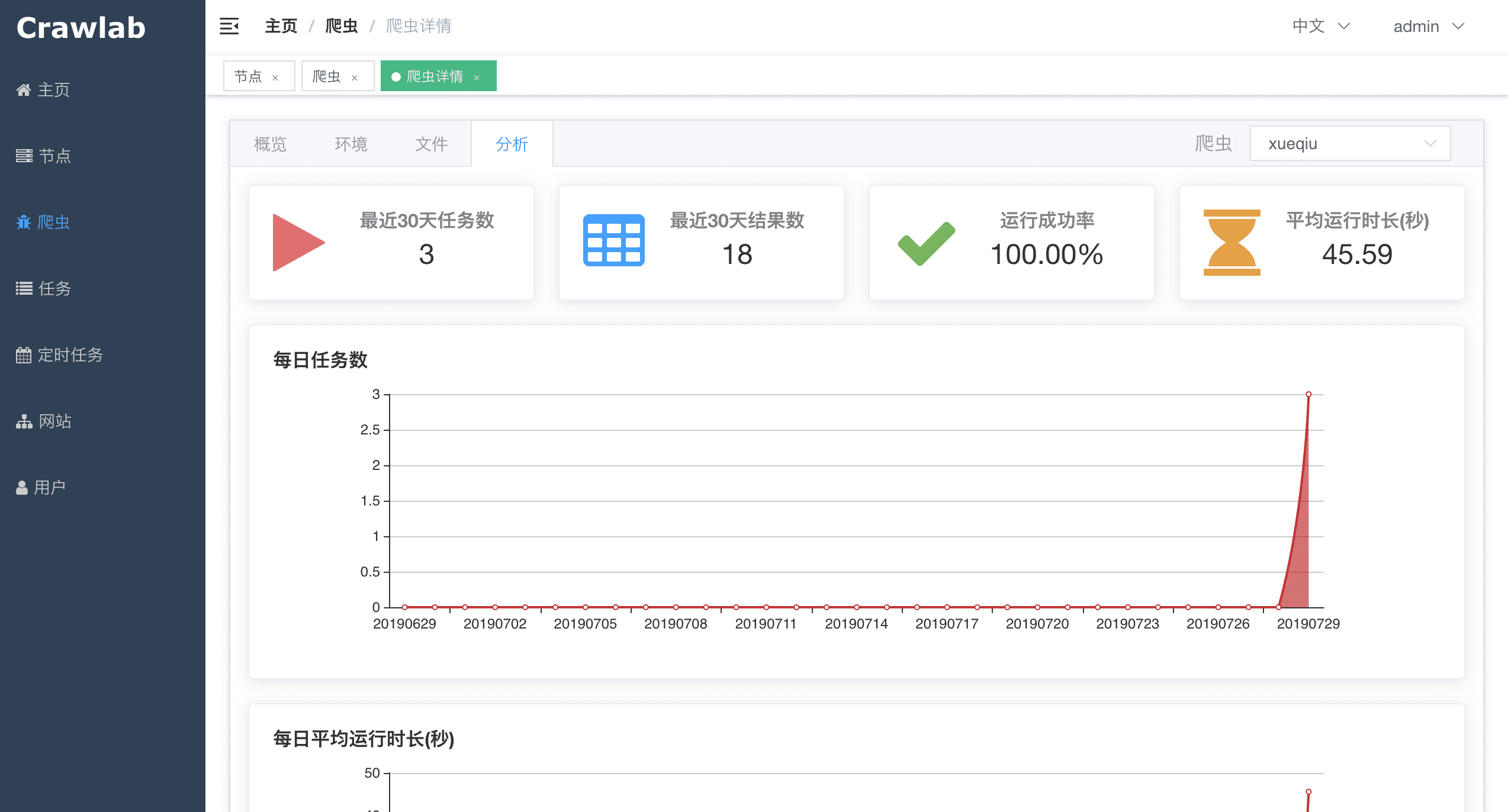
|
||||
|
||||
#### 爬虫文件
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/spider-file.png?v0.3.0">
|
||||
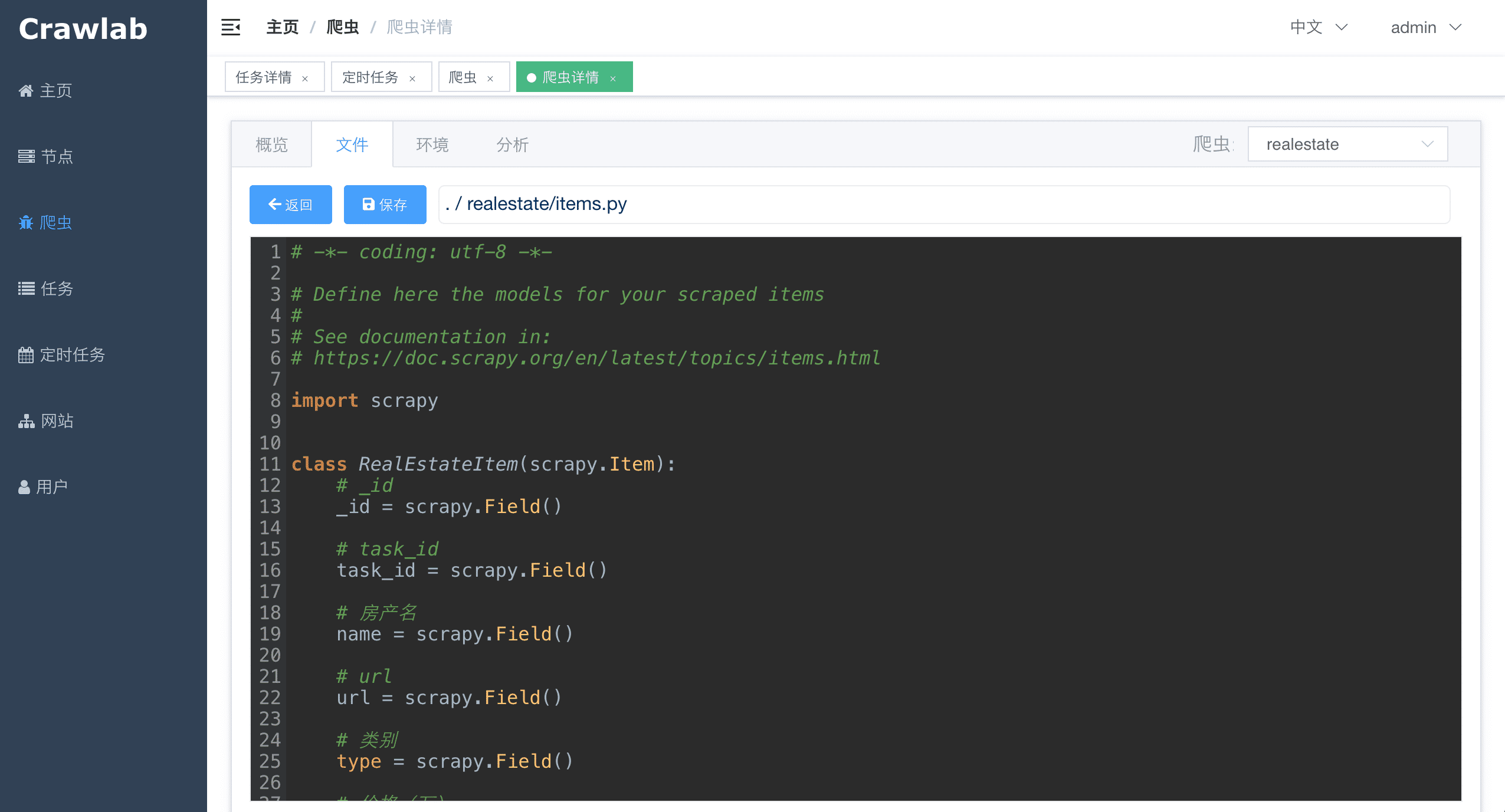
|
||||
|
||||
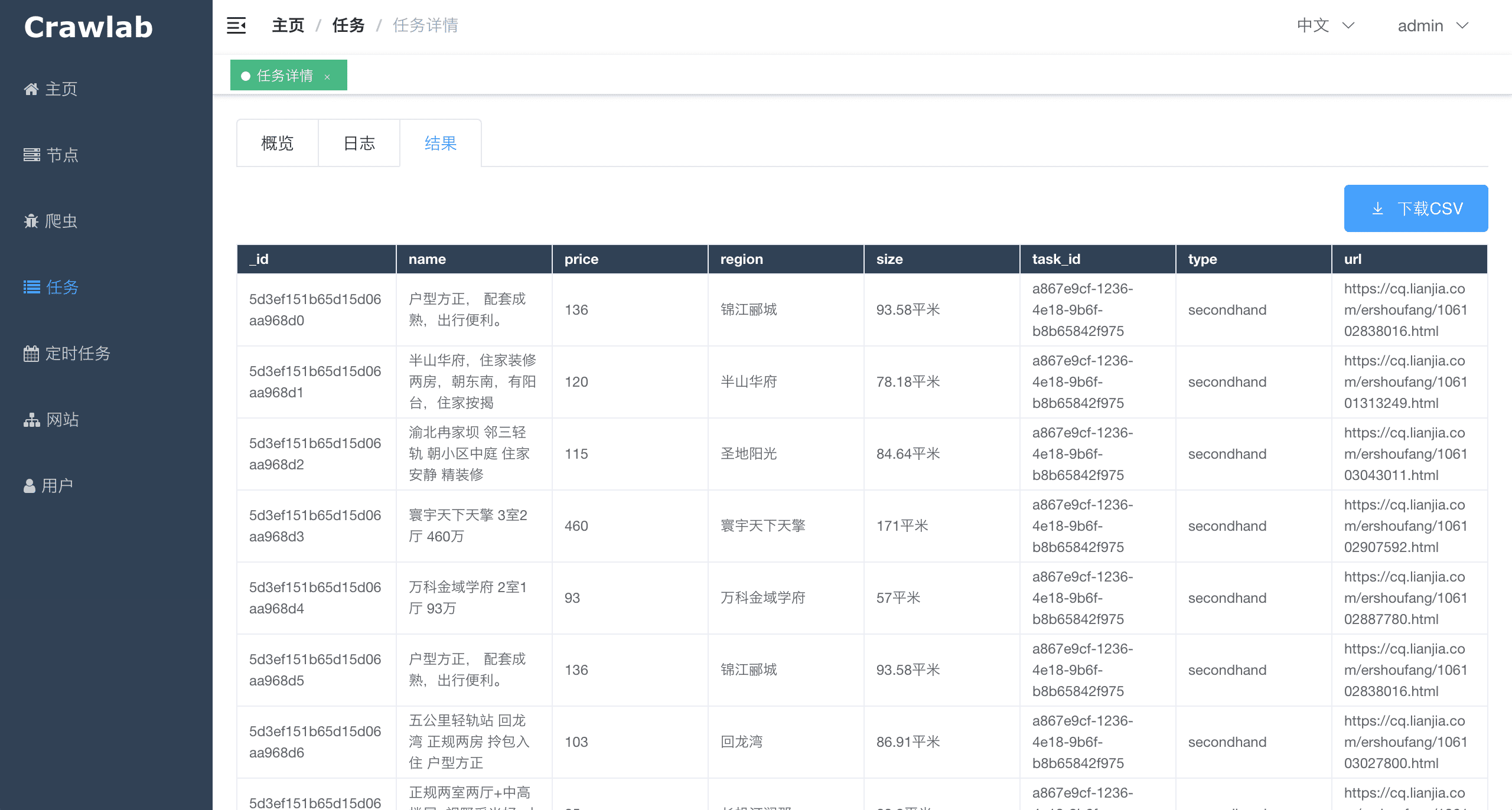
#### 任务详情 - 抓取结果
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/task-results.png?v0.3.0_1">
|
||||
|
||||
|
||||
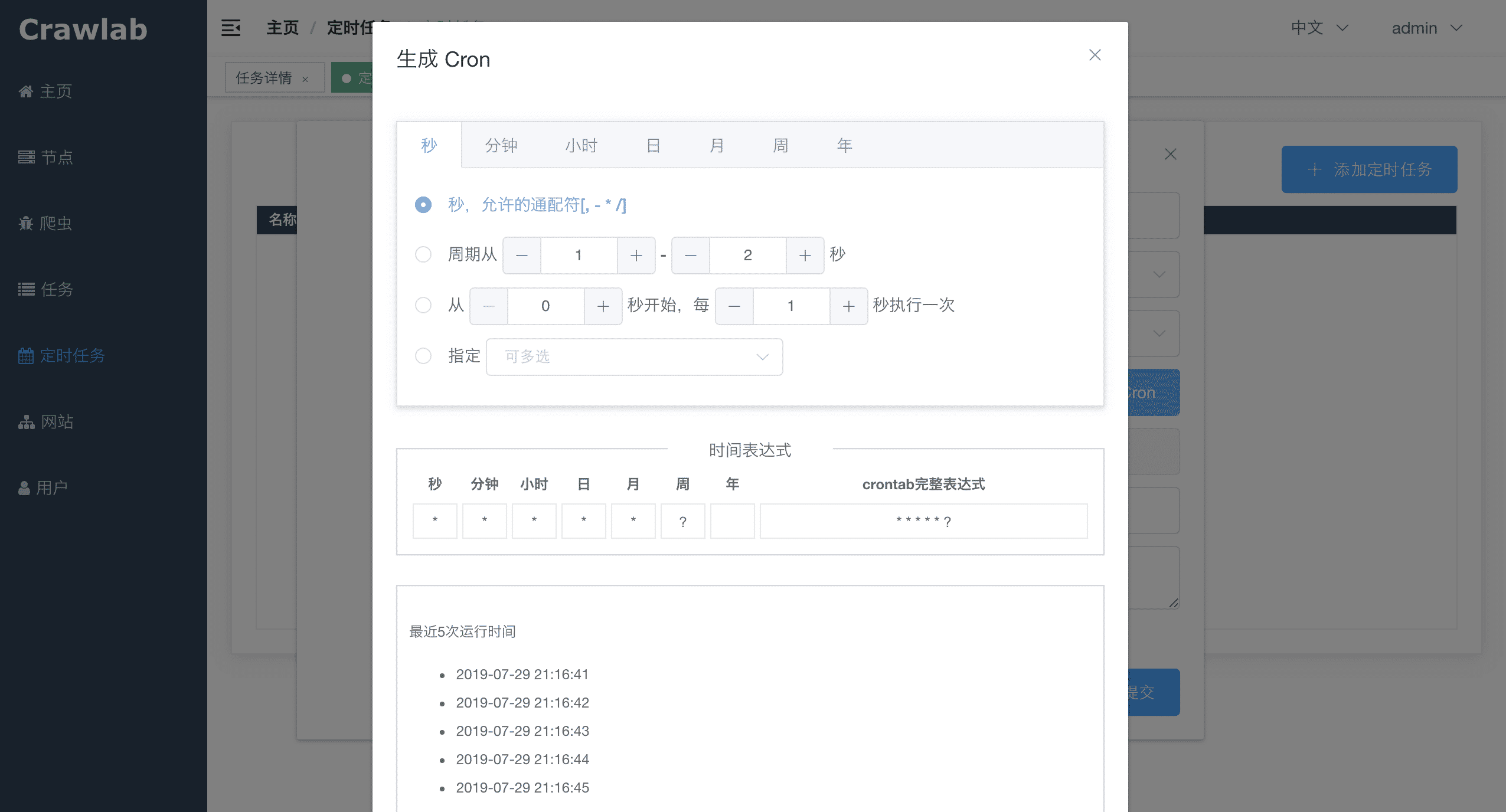
#### 定时任务
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/schedule.png?v0.3.0">
|
||||
|
||||
|
||||
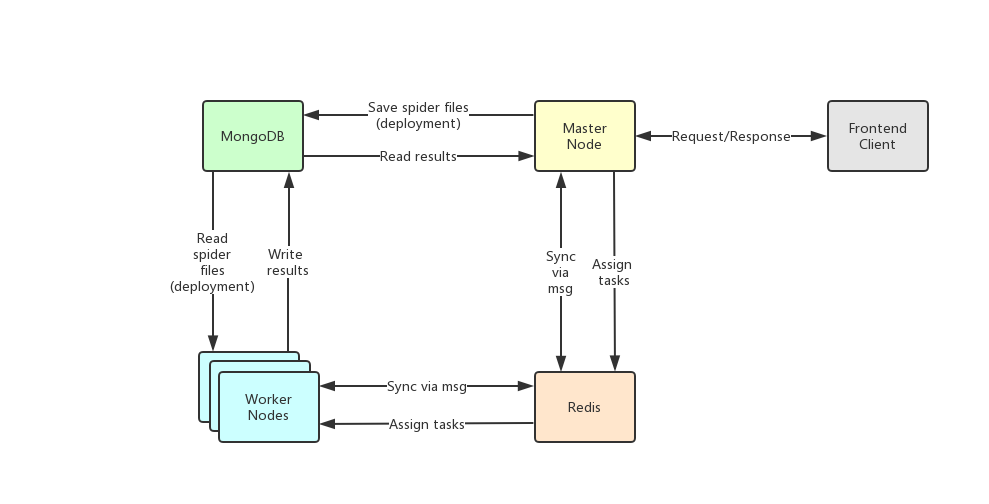
## 架构
|
||||
|
||||
Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及负责通信和数据储存的Redis和MongoDB数据库。
|
||||
|
||||
|
||||
|
||||
|
||||
前端应用向主节点请求数据,主节点通过MongoDB和Redis来执行任务派发调度以及部署,工作节点收到任务之后,开始执行爬虫任务,并将任务结果储存到MongoDB。架构相对于`v0.3.0`之前的Celery版本有所精简,去除了不必要的节点监控模块Flower,节点监控主要由Redis完成。
|
||||
|
||||
|
||||
28
README.md
28
README.md
@@ -53,7 +53,7 @@ docker run -d --rm --name crawlab \
|
||||
Surely you can use `docker-compose` to one-click to start up. By doing so, you don't even have to configure MongoDB and Redis databases. Create a file named `docker-compose.yml` and input the code below.
|
||||
|
||||
|
||||
```bash
|
||||
```yaml
|
||||
version: '3.3'
|
||||
services:
|
||||
master:
|
||||
@@ -95,49 +95,49 @@ For Docker Deployment details, please refer to [relevant documentation](https://
|
||||
|
||||
#### Login
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/login.png?v0.3.0">
|
||||

|
||||
|
||||
#### Home Page
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/home.png?v0.3.0">
|
||||

|
||||
|
||||
#### Node List
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/node-list.png?v0.3.0">
|
||||

|
||||
|
||||
#### Node Network
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/node-network.png?v0.3.0">
|
||||

|
||||
|
||||
#### Spider List
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/spider-list.png?v0.3.0">
|
||||

|
||||
|
||||
#### Spider Overview
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/spider-overview.png?v0.3.0">
|
||||

|
||||
|
||||
#### Spider Analytics
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/spider-analytics.png?v0.3.0">
|
||||

|
||||
|
||||
#### Spider Files
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/spider-file.png?v0.3.0">
|
||||

|
||||
|
||||
#### Task Results
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/task-results.png?v0.3.0_1">
|
||||

|
||||
|
||||
#### Cron Job
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/schedule.png?v0.3.0">
|
||||

|
||||
|
||||
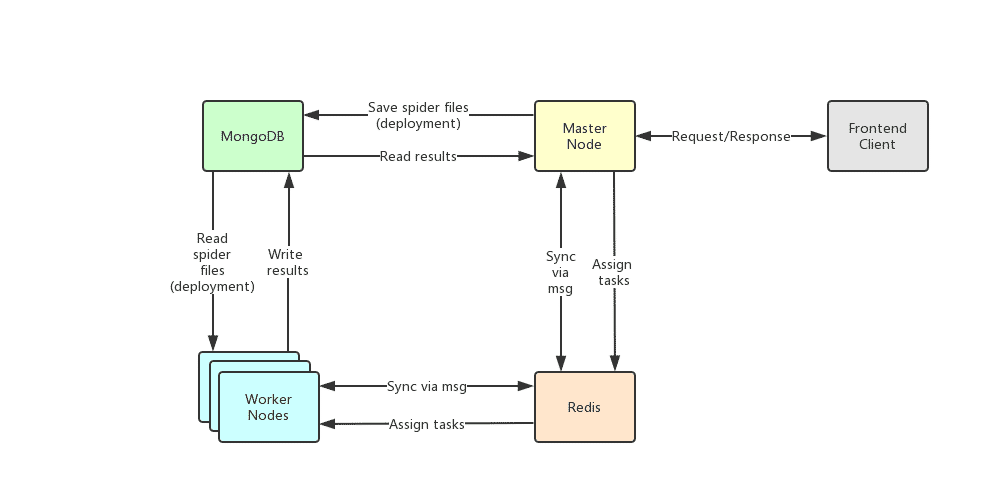
## Architecture
|
||||
|
||||
The architecture of Crawlab is consisted of the Master Node and multiple Worker Nodes, and Redis and MongoDB databases which are mainly for nodes communication and data storage.
|
||||
|
||||
<img src="https://crawlab.oss-cn-hangzhou.aliyuncs.com/v0.3.0/architecture.png">
|
||||

|
||||
|
||||
The frontend app makes requests to the Master Node, which assigns tasks and deploys spiders through MongoDB and Redis. When a Worker Node receives a task, it begins to execute the crawling task, and stores the results to MongoDB. The architecture is much more concise compared with versions before `v0.3.0`. It has removed unnecessary Flower module which offers node monitoring services. They are now done by Redis.
|
||||
|
||||
@@ -169,7 +169,7 @@ Redis is a very popular Key-Value database. It offers node communication service
|
||||
### Frontend
|
||||
|
||||
Frontend is a SPA based on
|
||||
[Vue-Element-Admin](https://github.com/PanJiaChen/vue-element-admin). It has re-used many Element-UI components to support correspoinding display.
|
||||
[Vue-Element-Admin](https://github.com/PanJiaChen/vue-element-admin). It has re-used many Element-UI components to support corresponding display.
|
||||
|
||||
## Integration with Other Frameworks
|
||||
|
||||
@@ -206,7 +206,7 @@ class JuejinPipeline(object):
|
||||
|
||||
There are existing spider management frameworks. So why use Crawlab?
|
||||
|
||||
The reason is that most of the existing platforms are depending on Scrapyd, which limits the choice only within python and scrapy. Surely scrapy is a great web crawl frameowrk, but it cannot do everything.
|
||||
The reason is that most of the existing platforms are depending on Scrapyd, which limits the choice only within python and scrapy. Surely scrapy is a great web crawl framework, but it cannot do everything.
|
||||
|
||||
Crawlab is easy to use, general enough to adapt spiders in any language and any framework. It has also a beautiful frontend interface for users to manage spiders much more easily.
|
||||
|
||||
|
||||
@@ -17,6 +17,7 @@ func main() {
|
||||
|
||||
// 初始化配置
|
||||
if err := config.InitConfig(""); err != nil {
|
||||
log.Error("init config error:" + err.Error())
|
||||
panic(err)
|
||||
}
|
||||
log.Info("初始化配置成功")
|
||||
@@ -30,6 +31,7 @@ func main() {
|
||||
|
||||
// 初始化Mongodb数据库
|
||||
if err := database.InitMongo(); err != nil {
|
||||
log.Error("init mongodb error:" + err.Error())
|
||||
debug.PrintStack()
|
||||
panic(err)
|
||||
}
|
||||
@@ -37,6 +39,7 @@ func main() {
|
||||
|
||||
// 初始化Redis数据库
|
||||
if err := database.InitRedis(); err != nil {
|
||||
log.Error("init redis error:" + err.Error())
|
||||
debug.PrintStack()
|
||||
panic(err)
|
||||
}
|
||||
@@ -45,6 +48,7 @@ func main() {
|
||||
if services.IsMaster() {
|
||||
// 初始化定时任务
|
||||
if err := services.InitScheduler(); err != nil {
|
||||
log.Error("init scheduler error:" + err.Error())
|
||||
debug.PrintStack()
|
||||
panic(err)
|
||||
}
|
||||
@@ -53,6 +57,7 @@ func main() {
|
||||
|
||||
// 初始化任务执行器
|
||||
if err := services.InitTaskExecutor(); err != nil {
|
||||
log.Error("init task executor error:" + err.Error())
|
||||
debug.PrintStack()
|
||||
panic(err)
|
||||
}
|
||||
@@ -60,12 +65,14 @@ func main() {
|
||||
|
||||
// 初始化节点服务
|
||||
if err := services.InitNodeService(); err != nil {
|
||||
log.Error("init node service error:" + err.Error())
|
||||
panic(err)
|
||||
}
|
||||
log.Info("初始化节点配置成功")
|
||||
|
||||
// 初始化爬虫服务
|
||||
if err := services.InitSpiderService(); err != nil {
|
||||
log.Error("init spider service error:" + err.Error())
|
||||
debug.PrintStack()
|
||||
panic(err)
|
||||
}
|
||||
@@ -73,6 +80,7 @@ func main() {
|
||||
|
||||
// 初始化用户服务
|
||||
if err := services.InitUserService(); err != nil {
|
||||
log.Error("init user service error:" + err.Error())
|
||||
debug.PrintStack()
|
||||
panic(err)
|
||||
}
|
||||
@@ -91,7 +99,7 @@ func main() {
|
||||
app.POST("/nodes/:id", routes.PostNode) // 修改节点
|
||||
app.GET("/nodes/:id/tasks", routes.GetNodeTaskList) // 节点任务列表
|
||||
app.GET("/nodes/:id/system", routes.GetSystemInfo) // 节点任务列表
|
||||
app.DELETE("/nodes/:id", routes.DeleteNode) // 删除节点
|
||||
app.DELETE("/nodes/:id", routes.DeleteNode) // 删除节点
|
||||
// 爬虫
|
||||
app.GET("/spiders", routes.GetSpiderList) // 爬虫列表
|
||||
app.GET("/spiders/:id", routes.GetSpider) // 爬虫详情
|
||||
@@ -138,6 +146,7 @@ func main() {
|
||||
host := viper.GetString("server.host")
|
||||
port := viper.GetString("server.port")
|
||||
if err := app.Run(host + ":" + port); err != nil {
|
||||
log.Error("run server error:" + err.Error())
|
||||
panic(err)
|
||||
}
|
||||
}
|
||||
|
||||
@@ -7,7 +7,7 @@ then
|
||||
else
|
||||
jspath=`ls /app/dist/js/app.*.js`
|
||||
cp ${jspath} ${jspath}.bak
|
||||
sed -i "s/localhost:8000/${CRAWLAB_API_ADDRESS}/g" ${jspath}
|
||||
sed -i "s?localhost:8000?${CRAWLAB_API_ADDRESS}?g" ${jspath}
|
||||
fi
|
||||
|
||||
# start nginx
|
||||
|
||||
@@ -21,3 +21,6 @@ docker build -t crawlab:worker .
|
||||
```
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
如果在多台服务器使用`docker-compose.yml`进行编排,可能出现节点注册不上的问题,因为mac地址冲突了。
|
||||
可以使用`networks`定义当前节点的IP段,这样就可以正常注册到redis
|
||||
Binary file not shown.
@@ -5,4 +5,14 @@ services:
|
||||
container_name: crawlab-worker
|
||||
volumes:
|
||||
- $PWD/conf/config.yml:/opt/crawlab/conf/config.yml
|
||||
- $PWD/crawlab:/usr/local/bin/crawlab
|
||||
# 二进制包使用源码生成
|
||||
- $PWD/crawlab:/usr/local/bin/crawlab
|
||||
networks:
|
||||
- crawlabnet
|
||||
|
||||
networks:
|
||||
crawlabnet:
|
||||
ipam:
|
||||
driver: default
|
||||
config:
|
||||
- subnet: 172.30.0.0/16
|
||||
Reference in New Issue
Block a user