mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-23 17:31:11 +01:00
1.6 KiB
1.6 KiB
爬虫部署
之前已经在部署爬虫中介绍了,爬虫是自动部署在工作节点上的。下面的示意图展示了Crawlab爬虫部署的架构。
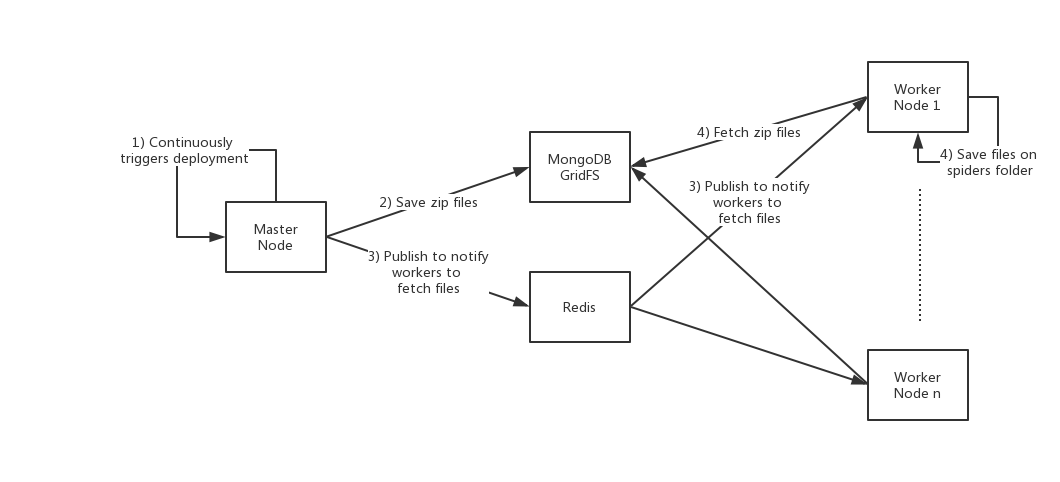
如上图所示,整个爬虫自动部署的生命周期如下(源码在services/spider.go#InitSpiderService):
- 主节点每5秒,会从爬虫的目录获取爬虫信息,然后更新到数据库(这个过程不涉及文件上传);
- 主节点每60秒,从数据库获取所有的爬虫信息,然后将爬虫打包成zip文件,并上传到MongoDB GridFS,并且在MongoDB的
spiders表里写入file_id文件ID; - 主节点通过Redis
PubSub发布消息(file.upload事件,包含文件ID)给工作节点,通知工作节点获取爬虫文件; - 工作节点接收到获取爬虫文件的消息,从MongoDB GridFS获取zip文件,并解压储存在本地。
这样,所有爬虫将被周期性的部署在工作节点上。
MongoDB GridFS
GridFS是MongoDB储存大文件(大于16Mb)的文件系统。Crawlab利用GridFS作为了爬虫文件储存的中间媒介,可以让工作节点主动去获取并部署在本地。这样绕开了其他传统传输方式,例如RPC、消息队列、HTTP,因为这几种都要求更复杂也更麻烦的配置和处理。
Crawlab在GridFS上储存文件,会生成两个collection,files.files和files.fs。前者储存文件的元信息,后者储存文件内容。spiders里的file_id是指向files.files的_id。