 +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+  +
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
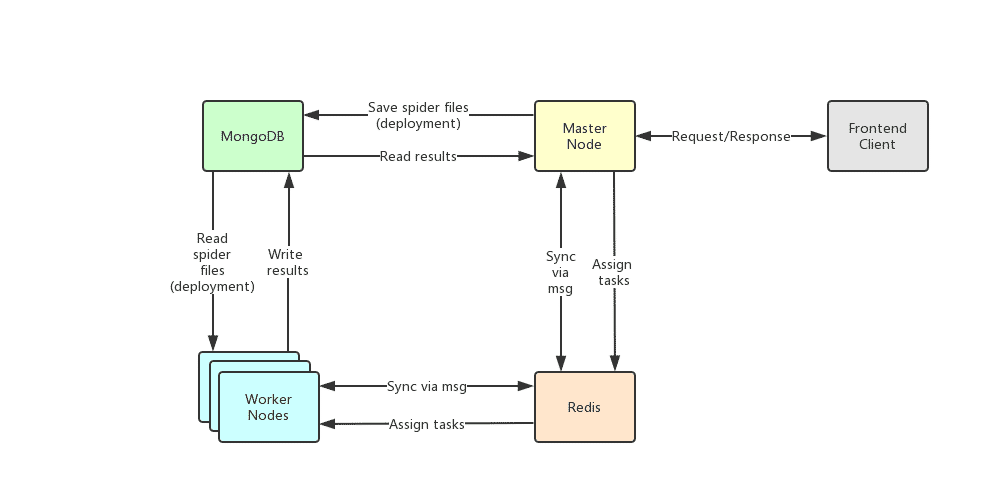
 ## 架构
Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及负责通信和数据储存的Redis和MongoDB数据库。
-
+
前端应用向主节点请求数据,主节点通过MongoDB和Redis来执行任务派发调度以及部署,工作节点收到任务之后,开始执行爬虫任务,并将任务结果储存到MongoDB。架构相对于`v0.3.0`之前的Celery版本有所精简,去除了不必要的节点监控模块Flower,节点监控主要由Redis完成。
@@ -162,37 +197,43 @@ Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点
## 与其他框架的集成
+[Crawlab SDK](https://github.com/crawlab-team/crawlab-sdk) 提供了一些 `helper` 方法来让您的爬虫更好的集成到 Crawlab 中,例如保存结果数据到 Crawlab 中等等。
+
+### 集成 Scrapy
+
+在 `settings.py` 中找到 `ITEM_PIPELINES`(`dict` 类型的变量),在其中添加如下内容。
+
+```python
+ITEM_PIPELINES = {
+ 'crawlab.pipelines.CrawlabMongoPipeline': 888,
+}
+```
+
+然后,启动 Scrapy 爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情-结果** 里。
+
+### 通用 Python 爬虫
+
+将下列代码加入到您爬虫中的结果保存部分。
+
+```python
+# 引入保存结果方法
+from crawlab import save_item
+
+# 这是一个结果,需要为 dict 类型
+result = {'name': 'crawlab'}
+
+# 调用保存结果方法
+save_item(result)
+```
+
+然后,启动爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情-结果** 里。
+
+### 其他框架和语言
+
爬虫任务本质上是由一个shell命令来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。另外,`CRAWLAB_COLLECTION`是Crawlab传过来的所存放collection的名称。
在爬虫程序中,需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中`CRAWLAB_COLLECTION`的collection中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
-### 集成Scrapy
-
-以下是Crawlab跟Scrapy集成的例子,利用了Crawlab传过来的task_id和collection_name。
-
-```python
-import os
-from pymongo import MongoClient
-
-MONGO_HOST = '192.168.99.100'
-MONGO_PORT = 27017
-MONGO_DB = 'crawlab_test'
-
-# scrapy example in the pipeline
-class JuejinPipeline(object):
- mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT)
- db = mongo[MONGO_DB]
- col_name = os.environ.get('CRAWLAB_COLLECTION')
- if not col_name:
- col_name = 'test'
- col = db[col_name]
-
- def process_item(self, item, spider):
- item['task_id'] = os.environ.get('CRAWLAB_TASK_ID')
- self.col.save(item)
- return item
-```
-
## 与其他框架比较
现在已经有一些爬虫管理框架了,因此为啥还要用Crawlab?
@@ -201,13 +242,12 @@ class JuejinPipeline(object):
Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流语言和框架。它还有一个精美的前端界面,让用户可以方便的管理和运行爬虫。
-|框架 | 类型 | 分布式 | 前端 | 依赖于Scrapyd |
-|:---:|:---:|:---:|:---:|:---:|
-| [Crawlab](https://github.com/crawlab-team/crawlab) | 管理平台 | Y | Y | N
-| [ScrapydWeb](https://github.com/my8100/scrapydweb) | 管理平台 | Y | Y | Y
-| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | 管理平台 | Y | Y | Y
-| [Gerapy](https://github.com/Gerapy/Gerapy) | 管理平台 | Y | Y | Y
-| [Scrapyd](https://github.com/scrapy/scrapyd) | 网络服务 | Y | N | N/A
+|框架 | 技术 | 优点 | 缺点 | Github 统计数据 |
+|:---|:---|:---|-----| :---- |
+| [Crawlab](https://github.com/crawlab-team/crawlab) | Golang + Vue|不局限于 scrapy,可以运行任何语言和框架的爬虫,精美的 UI 界面,天然支持分布式爬虫,支持节点管理、爬虫管理、任务管理、定时任务、结果导出、数据统计、消息通知、可配置爬虫、在线编辑代码等功能|暂时不支持爬虫版本管理|   |
+| [ScrapydWeb](https://github.com/my8100/scrapydweb) | Python Flask + Vue|精美的 UI 界面,内置了 scrapy 日志解析器,有较多任务运行统计图表,支持节点管理、定时任务、邮件提醒、移动界面,算是 scrapy-based 中功能完善的爬虫管理平台|不支持 scrapy 以外的爬虫,Python Flask 为后端,性能上有一定局限性|   |
+| [Gerapy](https://github.com/Gerapy/Gerapy) | Python Django + Vue|Gerapy 是崔庆才大神开发的爬虫管理平台,安装部署非常简单,同样基于 scrapyd,有精美的 UI 界面,支持节点管理、代码编辑、可配置规则等功能|同样不支持 scrapy 以外的爬虫,而且据使用者反馈,1.0 版本有很多 bug,期待 2.0 版本会有一定程度的改进|   |
+| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | Python Flask|基于 scrapyd,开源版 Scrapyhub,非常简洁的 UI 界面,支持定时任务|可能有些过于简洁了,不支持分页,不支持节点管理,不支持 scrapy 以外的爬虫|   |
## Q&A
@@ -254,6 +294,9 @@ Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流
## 架构
Crawlab的架构包括了一个主节点(Master Node)和多个工作节点(Worker Node),以及负责通信和数据储存的Redis和MongoDB数据库。
-
+
前端应用向主节点请求数据,主节点通过MongoDB和Redis来执行任务派发调度以及部署,工作节点收到任务之后,开始执行爬虫任务,并将任务结果储存到MongoDB。架构相对于`v0.3.0`之前的Celery版本有所精简,去除了不必要的节点监控模块Flower,节点监控主要由Redis完成。
@@ -162,37 +197,43 @@ Redis是非常受欢迎的Key-Value数据库,在Crawlab中主要实现节点
## 与其他框架的集成
+[Crawlab SDK](https://github.com/crawlab-team/crawlab-sdk) 提供了一些 `helper` 方法来让您的爬虫更好的集成到 Crawlab 中,例如保存结果数据到 Crawlab 中等等。
+
+### 集成 Scrapy
+
+在 `settings.py` 中找到 `ITEM_PIPELINES`(`dict` 类型的变量),在其中添加如下内容。
+
+```python
+ITEM_PIPELINES = {
+ 'crawlab.pipelines.CrawlabMongoPipeline': 888,
+}
+```
+
+然后,启动 Scrapy 爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情-结果** 里。
+
+### 通用 Python 爬虫
+
+将下列代码加入到您爬虫中的结果保存部分。
+
+```python
+# 引入保存结果方法
+from crawlab import save_item
+
+# 这是一个结果,需要为 dict 类型
+result = {'name': 'crawlab'}
+
+# 调用保存结果方法
+save_item(result)
+```
+
+然后,启动爬虫,运行完成之后,您就应该能看到抓取结果出现在 **任务详情-结果** 里。
+
+### 其他框架和语言
+
爬虫任务本质上是由一个shell命令来实现的。任务ID将以环境变量`CRAWLAB_TASK_ID`的形式存在于爬虫任务运行的进程中,并以此来关联抓取数据。另外,`CRAWLAB_COLLECTION`是Crawlab传过来的所存放collection的名称。
在爬虫程序中,需要将`CRAWLAB_TASK_ID`的值以`task_id`作为可以存入数据库中`CRAWLAB_COLLECTION`的collection中。这样Crawlab就知道如何将爬虫任务与抓取数据关联起来了。当前,Crawlab只支持MongoDB。
-### 集成Scrapy
-
-以下是Crawlab跟Scrapy集成的例子,利用了Crawlab传过来的task_id和collection_name。
-
-```python
-import os
-from pymongo import MongoClient
-
-MONGO_HOST = '192.168.99.100'
-MONGO_PORT = 27017
-MONGO_DB = 'crawlab_test'
-
-# scrapy example in the pipeline
-class JuejinPipeline(object):
- mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT)
- db = mongo[MONGO_DB]
- col_name = os.environ.get('CRAWLAB_COLLECTION')
- if not col_name:
- col_name = 'test'
- col = db[col_name]
-
- def process_item(self, item, spider):
- item['task_id'] = os.environ.get('CRAWLAB_TASK_ID')
- self.col.save(item)
- return item
-```
-
## 与其他框架比较
现在已经有一些爬虫管理框架了,因此为啥还要用Crawlab?
@@ -201,13 +242,12 @@ class JuejinPipeline(object):
Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流语言和框架。它还有一个精美的前端界面,让用户可以方便的管理和运行爬虫。
-|框架 | 类型 | 分布式 | 前端 | 依赖于Scrapyd |
-|:---:|:---:|:---:|:---:|:---:|
-| [Crawlab](https://github.com/crawlab-team/crawlab) | 管理平台 | Y | Y | N
-| [ScrapydWeb](https://github.com/my8100/scrapydweb) | 管理平台 | Y | Y | Y
-| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | 管理平台 | Y | Y | Y
-| [Gerapy](https://github.com/Gerapy/Gerapy) | 管理平台 | Y | Y | Y
-| [Scrapyd](https://github.com/scrapy/scrapyd) | 网络服务 | Y | N | N/A
+|框架 | 技术 | 优点 | 缺点 | Github 统计数据 |
+|:---|:---|:---|-----| :---- |
+| [Crawlab](https://github.com/crawlab-team/crawlab) | Golang + Vue|不局限于 scrapy,可以运行任何语言和框架的爬虫,精美的 UI 界面,天然支持分布式爬虫,支持节点管理、爬虫管理、任务管理、定时任务、结果导出、数据统计、消息通知、可配置爬虫、在线编辑代码等功能|暂时不支持爬虫版本管理|   |
+| [ScrapydWeb](https://github.com/my8100/scrapydweb) | Python Flask + Vue|精美的 UI 界面,内置了 scrapy 日志解析器,有较多任务运行统计图表,支持节点管理、定时任务、邮件提醒、移动界面,算是 scrapy-based 中功能完善的爬虫管理平台|不支持 scrapy 以外的爬虫,Python Flask 为后端,性能上有一定局限性|   |
+| [Gerapy](https://github.com/Gerapy/Gerapy) | Python Django + Vue|Gerapy 是崔庆才大神开发的爬虫管理平台,安装部署非常简单,同样基于 scrapyd,有精美的 UI 界面,支持节点管理、代码编辑、可配置规则等功能|同样不支持 scrapy 以外的爬虫,而且据使用者反馈,1.0 版本有很多 bug,期待 2.0 版本会有一定程度的改进|   |
+| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | Python Flask|基于 scrapyd,开源版 Scrapyhub,非常简洁的 UI 界面,支持定时任务|可能有些过于简洁了,不支持分页,不支持节点管理,不支持 scrapy 以外的爬虫|   |
## Q&A
@@ -254,6 +294,9 @@ Crawlab使用起来很方便,也很通用,可以适用于几乎任何主流
 +
+
+
+  +
## 社区 & 赞助
diff --git a/README.md b/README.md
index 70822b1d..54144a11 100644
--- a/README.md
+++ b/README.md
@@ -1,39 +1,68 @@
# Crawlab
-
-
-
-
-
-
-
+
+
## 社区 & 赞助
diff --git a/README.md b/README.md
index 70822b1d..54144a11 100644
--- a/README.md
+++ b/README.md
@@ -1,39 +1,68 @@
# Crawlab
-
-
-
-
-
-
-
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
## Architecture
The architecture of Crawlab is consisted of the Master Node and multiple Worker Nodes, and Redis and MongoDB databases which are mainly for nodes communication and data storage.
-
+
The frontend app makes requests to the Master Node, which assigns tasks and deploys spiders through MongoDB and Redis. When a Worker Node receives a task, it begins to execute the crawling task, and stores the results to MongoDB. The architecture is much more concise compared with versions before `v0.3.0`. It has removed unnecessary Flower module which offers node monitoring services. They are now done by Redis.
@@ -161,35 +196,43 @@ Frontend is a SPA based on
## Integration with Other Frameworks
-A crawling task is actually executed through a shell command. The Task ID will be passed to the crawling task process in the form of environment variable named `CRAWLAB_TASK_ID`. By doing so, the data can be related to a task. Also, another environment variable `CRAWLAB_COLLECTION` is passed by Crawlab as the name of the collection to store results data.
+[Crawlab SDK](https://github.com/crawlab-team/crawlab-sdk) provides some `helper` methods to make it easier for you to integrate your spiders into Crawlab, e.g. saving results.
+
+⚠️Note: make sure you have already installed `crawlab-sdk` using pip.
### Scrapy
-Below is an example to integrate Crawlab with Scrapy in pipelines.
+In `settings.py` in your Scrapy project, find the variable named `ITEM_PIPELINES` (a `dict` variable). Add content below.
```python
-import os
-from pymongo import MongoClient
-
-MONGO_HOST = '192.168.99.100'
-MONGO_PORT = 27017
-MONGO_DB = 'crawlab_test'
-
-# scrapy example in the pipeline
-class JuejinPipeline(object):
- mongo = MongoClient(host=MONGO_HOST, port=MONGO_PORT)
- db = mongo[MONGO_DB]
- col_name = os.environ.get('CRAWLAB_COLLECTION')
- if not col_name:
- col_name = 'test'
- col = db[col_name]
-
- def process_item(self, item, spider):
- item['task_id'] = os.environ.get('CRAWLAB_TASK_ID')
- self.col.save(item)
- return item
+ITEM_PIPELINES = {
+ 'crawlab.pipelines.CrawlabMongoPipeline': 888,
+}
```
+Then, start the Scrapy spider. After it's done, you should be able to see scraped results in **Task Detail -> Result**
+
+### General Python Spider
+
+Please add below content to your spider files to save results.
+
+```python
+# import result saving method
+from crawlab import save_item
+
+# this is a result record, must be dict type
+result = {'name': 'crawlab'}
+
+# call result saving method
+save_item(result)
+```
+
+Then, start the spider. After it's done, you should be able to see scraped results in **Task Detail -> Result**
+
+### Other Frameworks / Languages
+
+A crawling task is actually executed through a shell command. The Task ID will be passed to the crawling task process in the form of environment variable named `CRAWLAB_TASK_ID`. By doing so, the data can be related to a task. Also, another environment variable `CRAWLAB_COLLECTION` is passed by Crawlab as the name of the collection to store results data.
+
## Comparison with Other Frameworks
There are existing spider management frameworks. So why use Crawlab?
@@ -198,13 +241,12 @@ The reason is that most of the existing platforms are depending on Scrapyd, whic
Crawlab is easy to use, general enough to adapt spiders in any language and any framework. It has also a beautiful frontend interface for users to manage spiders much more easily.
-|Framework | Type | Distributed | Frontend | Scrapyd-Dependent |
-|:---:|:---:|:---:|:---:|:---:|
-| [Crawlab](https://github.com/crawlab-team/crawlab) | Admin Platform | Y | Y | N
-| [ScrapydWeb](https://github.com/my8100/scrapydweb) | Admin Platform | Y | Y | Y
-| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | Admin Platform | Y | Y | Y
-| [Gerapy](https://github.com/Gerapy/Gerapy) | Admin Platform | Y | Y | Y
-| [Scrapyd](https://github.com/scrapy/scrapyd) | Web Service | Y | N | N/A
+|Framework | Technology | Pros | Cons | Github Stats |
+|:---|:---|:---|-----| :---- |
+| [Crawlab](https://github.com/crawlab-team/crawlab) | Golang + Vue|Not limited to Scrapy, available for all programming languages and frameworks. Beautiful UI interface. Naturally support distributed spiders. Support spider mangement, task management, cron job, result export, analytics, notifications, configurable spiders, online code editor, etc.|Not yet support spider versioning|   |
+| [ScrapydWeb](https://github.com/my8100/scrapydweb) | Python Flask + Vue|Beautiful UI interface, built-in Scrapy log parser, stats and graphs for task execution, support node management, cron job, mail notification, mobile. Full-feature spider management platform.|Not support spiders other than Scrapy. Limited performance because of Python Flask backend.|   |
+| [Gerapy](https://github.com/Gerapy/Gerapy) | Python Django + Vue|Gerapy is built by web crawler guru [Germey Cui](https://github.com/Germey). Simple installation and deployment. Beautiful UI interface. Support node management, code edit, configurable crawl rules, etc.|Again not support spiders other than Scrapy. A lot of bugs based on user feedback in v1.0. Look forward to improvement in v2.0|   |
+| [SpiderKeeper](https://github.com/DormyMo/SpiderKeeper) | Python Flask|Open-source Scrapyhub. Concise and simple UI interface. Support cron job.|Perhaps too simplified, not support pagination, not support node management, not support spiders other than Scrapy.|   |
## Contributors
@@ -219,6 +261,9 @@ Crawlab is easy to use, general enough to adapt spiders in any language and any
+
+
+
## Community & Sponsorship
diff --git a/backend/conf/config.yml b/backend/conf/config.yml
index 3805762a..385834bd 100644
--- a/backend/conf/config.yml
+++ b/backend/conf/config.yml
@@ -15,20 +15,35 @@ redis:
log:
level: info
path: "/var/logs/crawlab"
- isDeletePeriodically: "Y"
+ isDeletePeriodically: "N"
deleteFrequency: "@hourly"
server:
host: 0.0.0.0
port: 8000
- master: "N"
+ master: "Y"
secret: "crawlab"
register:
# mac地址 或者 ip地址,如果是ip,则需要手动指定IP
type: "mac"
ip: ""
+ lang: # 安装语言环境, Y 为安装,N 为不安装,只对 Docker 有效
+ python: "Y"
+ node: "N"
spider:
path: "/app/spiders"
task:
workers: 4
other:
tmppath: "/tmp"
+version: 0.4.5
+setting:
+ allowRegister: "N"
+notification:
+ mail:
+ server: ''
+ port: ''
+ senderEmail: ''
+ senderIdentity: ''
+ smtp:
+ user: ''
+ password: ''
\ No newline at end of file
diff --git a/backend/config/config.go b/backend/config/config.go
index 4d83c0f7..e4c4616c 100644
--- a/backend/config/config.go
+++ b/backend/config/config.go
@@ -28,7 +28,7 @@ func (c *Config) Init() error {
}
viper.SetConfigType("yaml") // 设置配置文件格式为YAML
viper.AutomaticEnv() // 读取匹配的环境变量
- viper.SetEnvPrefix("CRAWLAB") // 读取环境变量的前缀为APISERVER
+ viper.SetEnvPrefix("CRAWLAB") // 读取环境变量的前缀为CRAWLAB
replacer := strings.NewReplacer(".", "_")
viper.SetEnvKeyReplacer(replacer)
if err := viper.ReadInConfig(); err != nil { // viper解析配置文件
diff --git a/backend/constants/anchor.go b/backend/constants/anchor.go
new file mode 100644
index 00000000..f462135f
--- /dev/null
+++ b/backend/constants/anchor.go
@@ -0,0 +1,8 @@
+package constants
+
+const (
+ AnchorStartStage = "START_STAGE"
+ AnchorStartUrl = "START_URL"
+ AnchorItems = "ITEMS"
+ AnchorParsers = "PARSERS"
+)
diff --git a/backend/constants/common.go b/backend/constants/common.go
new file mode 100644
index 00000000..9ac6cdbc
--- /dev/null
+++ b/backend/constants/common.go
@@ -0,0 +1,6 @@
+package constants
+
+const (
+ ASCENDING = "ascending"
+ DESCENDING = "descending"
+)
diff --git a/backend/constants/config_spider.go b/backend/constants/config_spider.go
new file mode 100644
index 00000000..c29624dc
--- /dev/null
+++ b/backend/constants/config_spider.go
@@ -0,0 +1,6 @@
+package constants
+
+const (
+ EngineScrapy = "scrapy"
+ EngineColly = "colly"
+)
diff --git a/backend/constants/notification.go b/backend/constants/notification.go
new file mode 100644
index 00000000..cf3da062
--- /dev/null
+++ b/backend/constants/notification.go
@@ -0,0 +1,13 @@
+package constants
+
+const (
+ NotificationTriggerOnTaskEnd = "notification_trigger_on_task_end"
+ NotificationTriggerOnTaskError = "notification_trigger_on_task_error"
+ NotificationTriggerNever = "notification_trigger_never"
+)
+
+const (
+ NotificationTypeMail = "notification_type_mail"
+ NotificationTypeDingTalk = "notification_type_ding_talk"
+ NotificationTypeWechat = "notification_type_wechat"
+)
diff --git a/backend/constants/rpc.go b/backend/constants/rpc.go
new file mode 100644
index 00000000..6eebf0d5
--- /dev/null
+++ b/backend/constants/rpc.go
@@ -0,0 +1,9 @@
+package constants
+
+const (
+ RpcInstallLang = "install_lang"
+ RpcInstallDep = "install_dep"
+ RpcUninstallDep = "uninstall_dep"
+ RpcGetDepList = "get_dep_list"
+ RpcGetInstalledDepList = "get_installed_dep_list"
+)
diff --git a/backend/constants/schedule.go b/backend/constants/schedule.go
new file mode 100644
index 00000000..520626a9
--- /dev/null
+++ b/backend/constants/schedule.go
@@ -0,0 +1,10 @@
+package constants
+
+const (
+ ScheduleStatusStop = "stopped"
+ ScheduleStatusRunning = "running"
+ ScheduleStatusError = "error"
+
+ ScheduleStatusErrorNotFoundNode = "Not Found Node"
+ ScheduleStatusErrorNotFoundSpider = "Not Found Spider"
+)
diff --git a/backend/constants/scrapy.go b/backend/constants/scrapy.go
new file mode 100644
index 00000000..bc82508f
--- /dev/null
+++ b/backend/constants/scrapy.go
@@ -0,0 +1,5 @@
+package constants
+
+const ScrapyProtectedStageNames = ""
+
+const ScrapyProtectedFieldNames = "_id,task_id,ts"
diff --git a/backend/constants/spider.go b/backend/constants/spider.go
index b4b7f65e..5119aa67 100644
--- a/backend/constants/spider.go
+++ b/backend/constants/spider.go
@@ -3,4 +3,5 @@ package constants
const (
Customized = "customized"
Configurable = "configurable"
+ Plugin = "plugin"
)
diff --git a/backend/constants/system.go b/backend/constants/system.go
index 59c39787..bec8b8c5 100644
--- a/backend/constants/system.go
+++ b/backend/constants/system.go
@@ -5,3 +5,9 @@ const (
Linux = "linux"
Darwin = "darwin"
)
+
+const (
+ Python = "python"
+ Nodejs = "node"
+ Java = "java"
+)
diff --git a/backend/constants/task.go b/backend/constants/task.go
index b6fb615c..63144e8b 100644
--- a/backend/constants/task.go
+++ b/backend/constants/task.go
@@ -19,3 +19,9 @@ const (
TaskFinish string = "finish"
TaskCancel string = "cancel"
)
+
+const (
+ RunTypeAllNodes string = "all-nodes"
+ RunTypeRandom string = "random"
+ RunTypeSelectedNodes string = "selected-nodes"
+)
diff --git a/backend/database/mongo.go b/backend/database/mongo.go
index e72baeaa..5d205ae4 100644
--- a/backend/database/mongo.go
+++ b/backend/database/mongo.go
@@ -61,11 +61,46 @@ func InitMongo() error {
dialInfo.Password = mongoPassword
dialInfo.Source = mongoAuth
}
- sess, err := mgo.DialWithInfo(&dialInfo)
- if err != nil {
- return err
+
+ // mongo session
+ var sess *mgo.Session
+
+ // 错误次数
+ errNum := 0
+
+ // 重复尝试连接mongo
+ for {
+ var err error
+
+ // 连接mongo
+ sess, err = mgo.DialWithInfo(&dialInfo)
+
+ if err != nil {
+ // 如果连接错误,休息1秒,错误次数+1
+ time.Sleep(1 * time.Second)
+ errNum++
+
+ // 如果错误次数超过30,返回错误
+ if errNum >= 30 {
+ return err
+ }
+ } else {
+ // 如果没有错误,退出循环
+ break
+ }
}
+
+ // 赋值给全局mongo session
Session = sess
}
+ //Add Unique index for 'key'
+ keyIndex := mgo.Index{
+ Key: []string{"key"},
+ Unique: true,
+ }
+ s, c := GetCol("nodes")
+ defer s.Close()
+ c.EnsureIndex(keyIndex)
+
return nil
}
diff --git a/backend/database/pubsub.go b/backend/database/pubsub.go
index 7f647cda..444ce91a 100644
--- a/backend/database/pubsub.go
+++ b/backend/database/pubsub.go
@@ -58,9 +58,9 @@ func (r *Redis) subscribe(ctx context.Context, consume ConsumeFunc, channel ...s
}
done <- nil
case <-tick.C:
- //fmt.Printf("ping message \n")
if err := psc.Ping(""); err != nil {
- done <- err
+ fmt.Printf("ping message error: %s \n", err)
+ //done <- err
}
case err := <-done:
close(done)
diff --git a/backend/database/redis.go b/backend/database/redis.go
index 348a74bb..bc6b4982 100644
--- a/backend/database/redis.go
+++ b/backend/database/redis.go
@@ -4,10 +4,12 @@ import (
"context"
"crawlab/entity"
"crawlab/utils"
+ "errors"
"github.com/apex/log"
"github.com/gomodule/redigo/redis"
"github.com/spf13/viper"
"runtime/debug"
+ "strings"
"time"
)
@@ -17,14 +19,36 @@ type Redis struct {
pool *redis.Pool
}
+type Mutex struct {
+ Name string
+ expiry time.Duration
+ tries int
+ delay time.Duration
+ value string
+}
+
func NewRedisClient() *Redis {
return &Redis{pool: NewRedisPool()}
}
+
func (r *Redis) RPush(collection string, value interface{}) error {
c := r.pool.Get()
defer utils.Close(c)
if _, err := c.Do("RPUSH", collection, value); err != nil {
+ log.Error(err.Error())
+ debug.PrintStack()
+ return err
+ }
+ return nil
+}
+
+func (r *Redis) LPush(collection string, value interface{}) error {
+ c := r.pool.Get()
+ defer utils.Close(c)
+
+ if _, err := c.Do("RPUSH", collection, value); err != nil {
+ log.Error(err.Error())
debug.PrintStack()
return err
}
@@ -47,6 +71,7 @@ func (r *Redis) HSet(collection string, key string, value string) error {
defer utils.Close(c)
if _, err := c.Do("HSET", collection, key, value); err != nil {
+ log.Error(err.Error())
debug.PrintStack()
return err
}
@@ -58,7 +83,9 @@ func (r *Redis) HGet(collection string, key string) (string, error) {
defer utils.Close(c)
value, err2 := redis.String(c.Do("HGET", collection, key))
- if err2 != nil {
+ if err2 != nil && err2 != redis.ErrNil {
+ log.Error(err2.Error())
+ debug.PrintStack()
return value, err2
}
return value, nil
@@ -69,6 +96,8 @@ func (r *Redis) HDel(collection string, key string) error {
defer utils.Close(c)
if _, err := c.Do("HDEL", collection, key); err != nil {
+ log.Error(err.Error())
+ debug.PrintStack()
return err
}
return nil
@@ -80,11 +109,27 @@ func (r *Redis) HKeys(collection string) ([]string, error) {
value, err2 := redis.Strings(c.Do("HKeys", collection))
if err2 != nil {
+ log.Error(err2.Error())
+ debug.PrintStack()
return []string{}, err2
}
return value, nil
}
+func (r *Redis) BRPop(collection string, timeout int) (string, error) {
+ if timeout <= 0 {
+ timeout = 60
+ }
+ c := r.pool.Get()
+ defer utils.Close(c)
+
+ values, err := redis.Strings(c.Do("BRPOP", collection, timeout))
+ if err != nil {
+ return "", err
+ }
+ return values[1], nil
+}
+
func NewRedisPool() *redis.Pool {
var address = viper.GetString("redis.address")
var port = viper.GetString("redis.port")
@@ -101,7 +146,7 @@ func NewRedisPool() *redis.Pool {
Dial: func() (conn redis.Conn, e error) {
return redis.DialURL(url,
redis.DialConnectTimeout(time.Second*10),
- redis.DialReadTimeout(time.Second*10),
+ redis.DialReadTimeout(time.Second*600),
redis.DialWriteTimeout(time.Second*10),
)
},
@@ -143,3 +188,59 @@ func Sub(channel string, consume ConsumeFunc) error {
}
return nil
}
+
+// 构建同步锁key
+func (r *Redis) getLockKey(lockKey string) string {
+ lockKey = strings.ReplaceAll(lockKey, ":", "-")
+ return "nodes:lock:" + lockKey
+}
+
+// 获得锁
+func (r *Redis) Lock(lockKey string) (int64, error) {
+ c := r.pool.Get()
+ defer utils.Close(c)
+ lockKey = r.getLockKey(lockKey)
+
+ ts := time.Now().Unix()
+ ok, err := c.Do("SET", lockKey, ts, "NX", "PX", 30000)
+ if err != nil {
+ log.Errorf("get lock fail with error: %s", err.Error())
+ debug.PrintStack()
+ return 0, err
+ }
+ if err == nil && ok == nil {
+ log.Errorf("the lockKey is locked: key=%s", lockKey)
+ return 0, errors.New("the lockKey is locked")
+ }
+ return ts, nil
+}
+
+func (r *Redis) UnLock(lockKey string, value int64) {
+ c := r.pool.Get()
+ defer utils.Close(c)
+ lockKey = r.getLockKey(lockKey)
+
+ getValue, err := redis.Int64(c.Do("GET", lockKey))
+ if err != nil {
+ log.Errorf("get lockKey error: %s", err.Error())
+ debug.PrintStack()
+ return
+ }
+
+ if getValue != value {
+ log.Errorf("the lockKey value diff: %d, %d", value, getValue)
+ return
+ }
+
+ v, err := redis.Int64(c.Do("DEL", lockKey))
+ if err != nil {
+ log.Errorf("unlock failed, error: %s", err.Error())
+ debug.PrintStack()
+ return
+ }
+
+ if v == 0 {
+ log.Errorf("unlock failed: key=%s", lockKey)
+ return
+ }
+}
diff --git a/backend/entity/common.go b/backend/entity/common.go
index 332cc494..c46ae4f9 100644
--- a/backend/entity/common.go
+++ b/backend/entity/common.go
@@ -3,15 +3,15 @@ package entity
import "strconv"
type Page struct {
- Skip int
- Limit int
- PageNum int
+ Skip int
+ Limit int
+ PageNum int
PageSize int
}
-func (p *Page)GetPage(pageNum string, pageSize string) {
+func (p *Page) GetPage(pageNum string, pageSize string) {
p.PageNum, _ = strconv.Atoi(pageNum)
p.PageSize, _ = strconv.Atoi(pageSize)
p.Skip = p.PageSize * (p.PageNum - 1)
p.Limit = p.PageSize
-}
\ No newline at end of file
+}
diff --git a/backend/entity/config_spider.go b/backend/entity/config_spider.go
new file mode 100644
index 00000000..054ee2fe
--- /dev/null
+++ b/backend/entity/config_spider.go
@@ -0,0 +1,40 @@
+package entity
+
+type ConfigSpiderData struct {
+ // 通用
+ Name string `yaml:"name" json:"name"`
+ DisplayName string `yaml:"display_name" json:"display_name"`
+ Col string `yaml:"col" json:"col"`
+ Remark string `yaml:"remark" json:"remark"`
+ Type string `yaml:"type" bson:"type"`
+
+ // 可配置爬虫
+ Engine string `yaml:"engine" json:"engine"`
+ StartUrl string `yaml:"start_url" json:"start_url"`
+ StartStage string `yaml:"start_stage" json:"start_stage"`
+ Stages []Stage `yaml:"stages" json:"stages"`
+ Settings map[string]string `yaml:"settings" json:"settings"`
+
+ // 自定义爬虫
+ Cmd string `yaml:"cmd" json:"cmd"`
+}
+
+type Stage struct {
+ Name string `yaml:"name" json:"name"`
+ IsList bool `yaml:"is_list" json:"is_list"`
+ ListCss string `yaml:"list_css" json:"list_css"`
+ ListXpath string `yaml:"list_xpath" json:"list_xpath"`
+ PageCss string `yaml:"page_css" json:"page_css"`
+ PageXpath string `yaml:"page_xpath" json:"page_xpath"`
+ PageAttr string `yaml:"page_attr" json:"page_attr"`
+ Fields []Field `yaml:"fields" json:"fields"`
+}
+
+type Field struct {
+ Name string `yaml:"name" json:"name"`
+ Css string `yaml:"css" json:"css"`
+ Xpath string `yaml:"xpath" json:"xpath"`
+ Attr string `yaml:"attr" json:"attr"`
+ NextStage string `yaml:"next_stage" json:"next_stage"`
+ Remark string `yaml:"remark" json:"remark"`
+}
diff --git a/backend/entity/system.go b/backend/entity/system.go
index dff637b7..ac3e9dec 100644
--- a/backend/entity/system.go
+++ b/backend/entity/system.go
@@ -13,3 +13,18 @@ type Executable struct {
FileName string `json:"file_name"`
DisplayName string `json:"display_name"`
}
+
+type Lang struct {
+ Name string `json:"name"`
+ ExecutableName string `json:"executable_name"`
+ ExecutablePath string `json:"executable_path"`
+ DepExecutablePath string `json:"dep_executable_path"`
+ Installed bool `json:"installed"`
+}
+
+type Dependency struct {
+ Name string `json:"name"`
+ Version string `json:"version"`
+ Description string `json:"description"`
+ Installed bool `json:"installed"`
+}
diff --git a/backend/go.mod b/backend/go.mod
index 428c2fd3..cbc7d75b 100644
--- a/backend/go.mod
+++ b/backend/go.mod
@@ -11,10 +11,18 @@ require (
github.com/go-playground/locales v0.12.1 // indirect
github.com/go-playground/universal-translator v0.16.0 // indirect
github.com/gomodule/redigo v2.0.0+incompatible
+ github.com/imroc/req v0.2.4
github.com/leodido/go-urn v1.1.0 // indirect
+ github.com/matcornic/hermes v1.2.0
+ github.com/matcornic/hermes/v2 v2.0.2 // indirect
github.com/pkg/errors v0.8.1
+ github.com/royeo/dingrobot v1.0.0
github.com/satori/go.uuid v1.2.0
github.com/smartystreets/goconvey v0.0.0-20190731233626-505e41936337
github.com/spf13/viper v1.4.0
+ gopkg.in/alexcesaro/quotedprintable.v3 v3.0.0-20150716171945-2caba252f4dc // indirect
gopkg.in/go-playground/validator.v9 v9.29.1
+ gopkg.in/gomail.v2 v2.0.0-20150902115704-41f357289737
+ gopkg.in/russross/blackfriday.v2 v2.0.0 // indirect
+ gopkg.in/yaml.v2 v2.2.2
)
diff --git a/backend/go.sum b/backend/go.sum
index 55a56852..a55ef74e 100644
--- a/backend/go.sum
+++ b/backend/go.sum
@@ -1,9 +1,15 @@
cloud.google.com/go v0.26.0/go.mod h1:aQUYkXzVsufM+DwF1aE+0xfcU+56JwCaLick0ClmMTw=
github.com/BurntSushi/toml v0.3.1 h1:WXkYYl6Yr3qBf1K79EBnL4mak0OimBfB0XUf9Vl28OQ=
github.com/BurntSushi/toml v0.3.1/go.mod h1:xHWCNGjB5oqiDr8zfno3MHue2Ht5sIBksp03qcyfWMU=
+github.com/Masterminds/semver v1.4.2 h1:WBLTQ37jOCzSLtXNdoo8bNM8876KhNqOKvrlGITgsTc=
+github.com/Masterminds/semver v1.4.2/go.mod h1:MB6lktGJrhw8PrUyiEoblNEGEQ+RzHPF078ddwwvV3Y=
+github.com/Masterminds/sprig v2.16.0+incompatible h1:QZbMUPxRQ50EKAq3LFMnxddMu88/EUUG3qmxwtDmPsY=
+github.com/Masterminds/sprig v2.16.0+incompatible/go.mod h1:y6hNFY5UBTIWBxnzTeuNhlNS5hqE0NB0E6fgfo2Br3o=
github.com/OneOfOne/xxhash v1.2.2/go.mod h1:HSdplMjZKSmBqAxg5vPj2TmRDmfkzw+cTzAElWljhcU=
github.com/alecthomas/template v0.0.0-20160405071501-a0175ee3bccc/go.mod h1:LOuyumcjzFXgccqObfd/Ljyb9UuFJ6TxHnclSeseNhc=
github.com/alecthomas/units v0.0.0-20151022065526-2efee857e7cf/go.mod h1:ybxpYRFXyAe+OPACYpWeL0wqObRcbAqCMya13uyzqw0=
+github.com/aokoli/goutils v1.0.1 h1:7fpzNGoJ3VA8qcrm++XEE1QUe0mIwNeLa02Nwq7RDkg=
+github.com/aokoli/goutils v1.0.1/go.mod h1:SijmP0QR8LtwsmDs8Yii5Z/S4trXFGFC2oO5g9DP+DQ=
github.com/apex/log v1.1.1 h1:BwhRZ0qbjYtTob0I+2M+smavV0kOC8XgcnGZcyL9liA=
github.com/apex/log v1.1.1/go.mod h1:Ls949n1HFtXfbDcjiTTFQqkVUrte0puoIBfO3SVgwOA=
github.com/aphistic/golf v0.0.0-20180712155816-02c07f170c5a/go.mod h1:3NqKYiepwy8kCu4PNA+aP7WUV72eXWJeP9/r3/K9aLE=
@@ -56,6 +62,8 @@ github.com/gomodule/redigo v2.0.0+incompatible h1:K/R+8tc58AaqLkqG2Ol3Qk+DR/TlNu
github.com/gomodule/redigo v2.0.0+incompatible/go.mod h1:B4C85qUVwatsJoIUNIfCRsp7qO0iAmpGFZ4EELWSbC4=
github.com/google/btree v1.0.0/go.mod h1:lNA+9X1NB3Zf8V7Ke586lFgjr2dZNuvo3lPJSGZ5JPQ=
github.com/google/go-cmp v0.2.0/go.mod h1:oXzfMopK8JAjlY9xF4vHSVASa0yLyX7SntLO5aqRK0M=
+github.com/google/uuid v1.0.0/go.mod h1:TIyPZe4MgqvfeYDBFedMoGGpEw/LqOeaOT+nhxU+yHo=
+github.com/google/uuid v1.1.1 h1:Gkbcsh/GbpXz7lPftLA3P6TYMwjCLYm83jiFQZF/3gY=
github.com/google/uuid v1.1.1/go.mod h1:TIyPZe4MgqvfeYDBFedMoGGpEw/LqOeaOT+nhxU+yHo=
github.com/gopherjs/gopherjs v0.0.0-20181017120253-0766667cb4d1 h1:EGx4pi6eqNxGaHF6qqu48+N2wcFQ5qg5FXgOdqsJ5d8=
github.com/gopherjs/gopherjs v0.0.0-20181017120253-0766667cb4d1/go.mod h1:wJfORRmW1u3UXTncJ5qlYoELFm8eSnnEO6hX4iZ3EWY=
@@ -66,6 +74,14 @@ github.com/grpc-ecosystem/grpc-gateway v1.9.0/go.mod h1:vNeuVxBJEsws4ogUvrchl83t
github.com/hashicorp/hcl v1.0.0 h1:0Anlzjpi4vEasTeNFn2mLJgTSwt0+6sfsiTG8qcWGx4=
github.com/hashicorp/hcl v1.0.0/go.mod h1:E5yfLk+7swimpb2L/Alb/PJmXilQ/rhwaUYs4T20WEQ=
github.com/hpcloud/tail v1.0.0/go.mod h1:ab1qPbhIpdTxEkNHXyeSf5vhxWSCs/tWer42PpOxQnU=
+github.com/huandu/xstrings v1.2.0 h1:yPeWdRnmynF7p+lLYz0H2tthW9lqhMJrQV/U7yy4wX0=
+github.com/huandu/xstrings v1.2.0/go.mod h1:DvyZB1rfVYsBIigL8HwpZgxHwXozlTgGqn63UyNX5k4=
+github.com/imdario/mergo v0.3.6 h1:xTNEAn+kxVO7dTZGu0CegyqKZmoWFI0rF8UxjlB2d28=
+github.com/imdario/mergo v0.3.6/go.mod h1:2EnlNZ0deacrJVfApfmtdGgDfMuh/nq6Ok1EcJh5FfA=
+github.com/imroc/req v0.2.4 h1:8XbvaQpERLAJV6as/cB186DtH5f0m5zAOtHEaTQ4ac0=
+github.com/imroc/req v0.2.4/go.mod h1:J9FsaNHDTIVyW/b5r6/Df5qKEEEq2WzZKIgKSajd1AE=
+github.com/jaytaylor/html2text v0.0.0-20180606194806-57d518f124b0 h1:xqgexXAGQgY3HAjNPSaCqn5Aahbo5TKsmhp8VRfr1iQ=
+github.com/jaytaylor/html2text v0.0.0-20180606194806-57d518f124b0/go.mod h1:CVKlgaMiht+LXvHG173ujK6JUhZXKb2u/BQtjPDIvyk=
github.com/jmespath/go-jmespath v0.0.0-20180206201540-c2b33e8439af/go.mod h1:Nht3zPeWKUH0NzdCt2Blrr5ys8VGpn0CEB0cQHVjt7k=
github.com/jonboulle/clockwork v0.1.0/go.mod h1:Ii8DK3G1RaLaWxj9trq07+26W01tbo22gdxWY5EU2bo=
github.com/jpillora/backoff v0.0.0-20180909062703-3050d21c67d7/go.mod h1:2iMrUgbbvHEiQClaW2NsSzMyGHqN+rDFqY705q49KG0=
@@ -87,12 +103,17 @@ github.com/leodido/go-urn v1.1.0 h1:Sm1gr51B1kKyfD2BlRcLSiEkffoG96g6TPv6eRoEiB8=
github.com/leodido/go-urn v1.1.0/go.mod h1:+cyI34gQWZcE1eQU7NVgKkkzdXDQHr1dBMtdAPozLkw=
github.com/magiconair/properties v1.8.0 h1:LLgXmsheXeRoUOBOjtwPQCWIYqM/LU1ayDtDePerRcY=
github.com/magiconair/properties v1.8.0/go.mod h1:PppfXfuXeibc/6YijjN8zIbojt8czPbwD3XqdrwzmxQ=
+github.com/matcornic/hermes v1.2.0 h1:AuqZpYcTOtTB7cahdevLfnhIpfzmpqw5Czv8vpdnFDU=
+github.com/matcornic/hermes v1.2.0/go.mod h1:lujJomb016Xjv8wBnWlNvUdtmvowjjfkqri5J/+1hYc=
+github.com/matcornic/hermes/v2 v2.0.2/go.mod h1:iVsJWSIS4NtMNtgan22sy6lt7pImok7bATGPWCoaKNY=
github.com/mattn/go-colorable v0.1.1/go.mod h1:FuOcm+DKB9mbwrcAfNl7/TZVBZ6rcnceauSikq3lYCQ=
github.com/mattn/go-colorable v0.1.2/go.mod h1:U0ppj6V5qS13XJ6of8GYAs25YV2eR4EVcfRqFIhoBtE=
github.com/mattn/go-isatty v0.0.5/go.mod h1:Iq45c/XA43vh69/j3iqttzPXn0bhXyGjM0Hdxcsrc5s=
github.com/mattn/go-isatty v0.0.7/go.mod h1:Iq45c/XA43vh69/j3iqttzPXn0bhXyGjM0Hdxcsrc5s=
github.com/mattn/go-isatty v0.0.8 h1:HLtExJ+uU2HOZ+wI0Tt5DtUDrx8yhUqDcp7fYERX4CE=
github.com/mattn/go-isatty v0.0.8/go.mod h1:Iq45c/XA43vh69/j3iqttzPXn0bhXyGjM0Hdxcsrc5s=
+github.com/mattn/go-runewidth v0.0.3 h1:a+kO+98RDGEfo6asOGMmpodZq4FNtnGP54yps8BzLR4=
+github.com/mattn/go-runewidth v0.0.3/go.mod h1:LwmH8dsx7+W8Uxz3IHJYH5QSwggIsqBzpuz5H//U1FU=
github.com/matttproud/golang_protobuf_extensions v1.0.1/go.mod h1:D8He9yQNgCq6Z5Ld7szi9bcBfOoFv/3dc6xSMkL2PC0=
github.com/mgutz/ansi v0.0.0-20170206155736-9520e82c474b/go.mod h1:01TrycV0kFyexm33Z7vhZRXopbI8J3TDReVlkTgMUxE=
github.com/mitchellh/mapstructure v1.1.2 h1:fmNYVwqnSfB9mZU6OS2O6GsXM+wcskZDuKQzvN1EDeE=
@@ -103,6 +124,8 @@ github.com/modern-go/reflect2 v1.0.1 h1:9f412s+6RmYXLWZSEzVVgPGK7C2PphHj5RJrvfx9
github.com/modern-go/reflect2 v1.0.1/go.mod h1:bx2lNnkwVCuqBIxFjflWJWanXIb3RllmbCylyMrvgv0=
github.com/mwitkow/go-conntrack v0.0.0-20161129095857-cc309e4a2223/go.mod h1:qRWi+5nqEBWmkhHvq77mSJWrCKwh8bxhgT7d/eI7P4U=
github.com/oklog/ulid v1.3.1/go.mod h1:CirwcVhetQ6Lv90oh/F+FBtV6XMibvdAFo93nm5qn4U=
+github.com/olekukonko/tablewriter v0.0.1 h1:b3iUnf1v+ppJiOfNX4yxxqfWKMQPZR5yoh8urCTFX88=
+github.com/olekukonko/tablewriter v0.0.1/go.mod h1:vsDQFd/mU46D+Z4whnwzcISnGGzXWMclvtLoiIKAKIo=
github.com/onsi/ginkgo v1.6.0/go.mod h1:lLunBs/Ym6LB5Z9jYTR76FiuTmxDTDusOGeTQH+WWjE=
github.com/onsi/gomega v1.5.0/go.mod h1:ex+gbHU/CVuBBDIJjb2X0qEXbFg53c61hWP/1CpauHY=
github.com/pelletier/go-toml v1.2.0 h1:T5zMGML61Wp+FlcbWjRDT7yAxhJNAiPPLOFECq181zc=
@@ -123,9 +146,14 @@ github.com/prometheus/procfs v0.0.0-20190507164030-5867b95ac084/go.mod h1:TjEm7z
github.com/prometheus/tsdb v0.7.1/go.mod h1:qhTCs0VvXwvX/y3TZrWD7rabWM+ijKTux40TwIPHuXU=
github.com/rogpeppe/fastuuid v0.0.0-20150106093220-6724a57986af/go.mod h1:XWv6SoW27p1b0cqNHllgS5HIMJraePCO15w5zCzIWYg=
github.com/rogpeppe/fastuuid v1.1.0/go.mod h1:jVj6XXZzXRy/MSR5jhDC/2q6DgLz+nrA6LYCDYWNEvQ=
+github.com/royeo/dingrobot v1.0.0 h1:K4GrF+fOecNX0yi+oBKpfh7z0XP/8TzaIIHu1B2kKUQ=
+github.com/royeo/dingrobot v1.0.0/go.mod h1:RqDM8E/hySCVwI2aUFRJAUGDcHHRnIhzNmbNG3bamQs=
+github.com/russross/blackfriday/v2 v2.0.1/go.mod h1:+Rmxgy9KzJVeS9/2gXHxylqXiyQDYRxCVz55jmeOWTM=
github.com/satori/go.uuid v1.2.0 h1:0uYX9dsZ2yD7q2RtLRtPSdGDWzjeM3TbMJP9utgA0ww=
github.com/satori/go.uuid v1.2.0/go.mod h1:dA0hQrYB0VpLJoorglMZABFdXlWrHn1NEOzdhQKdks0=
github.com/sergi/go-diff v1.0.0/go.mod h1:0CfEIISq7TuYL3j771MWULgwwjU+GofnZX9QAmXWZgo=
+github.com/shurcooL/sanitized_anchor_name v1.0.0 h1:PdmoCO6wvbs+7yrJyMORt4/BmY5IYyJwS/kOiWx8mHo=
+github.com/shurcooL/sanitized_anchor_name v1.0.0/go.mod h1:1NzhyTcUVG4SuEtjjoZeVRXNmyL/1OwPU0+IJeTBvfc=
github.com/sirupsen/logrus v1.2.0/go.mod h1:LxeOpSwHxABJmUn/MG1IvRgCAasNZTLOkJPxbbu5VWo=
github.com/smartystreets/assertions v0.0.0-20180927180507-b2de0cb4f26d/go.mod h1:OnSkiWE9lh6wB0YB77sQom3nweQdgAjqCqsofrRNTgc=
github.com/smartystreets/assertions v1.0.0 h1:UVQPSSmc3qtTi+zPPkCXvZX9VvW/xT/NsRvKfwY81a8=
@@ -146,6 +174,8 @@ github.com/spf13/pflag v1.0.3 h1:zPAT6CGy6wXeQ7NtTnaTerfKOsV6V6F8agHXFiazDkg=
github.com/spf13/pflag v1.0.3/go.mod h1:DYY7MBk1bdzusC3SYhjObp+wFpr4gzcvqqNjLnInEg4=
github.com/spf13/viper v1.4.0 h1:yXHLWeravcrgGyFSyCgdYpXQ9dR9c/WED3pg1RhxqEU=
github.com/spf13/viper v1.4.0/go.mod h1:PTJ7Z/lr49W6bUbkmS1V3by4uWynFiR9p7+dSq/yZzE=
+github.com/ssor/bom v0.0.0-20170718123548-6386211fdfcf h1:pvbZ0lM0XWPBqUKqFU8cmavspvIl9nulOYwdy6IFRRo=
+github.com/ssor/bom v0.0.0-20170718123548-6386211fdfcf/go.mod h1:RJID2RhlZKId02nZ62WenDCkgHFerpIOmW0iT7GKmXM=
github.com/stretchr/objx v0.1.0/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
github.com/stretchr/objx v0.1.1/go.mod h1:HFkY916IF+rwdDfMAkV7OtwuqBVzrE8GR6GFx+wExME=
github.com/stretchr/testify v1.2.2/go.mod h1:a8OnRcib4nhh0OaRAV+Yts87kKdq0PP7pXfy6kDkUVs=
@@ -165,12 +195,15 @@ go.uber.org/atomic v1.4.0/go.mod h1:gD2HeocX3+yG+ygLZcrzQJaqmWj9AIm7n08wl/qW/PE=
go.uber.org/multierr v1.1.0/go.mod h1:wR5kodmAFQ0UK8QlbwjlSNy0Z68gJhDJUG5sjR94q/0=
go.uber.org/zap v1.10.0/go.mod h1:vwi/ZaCAaUcBkycHslxD9B2zi4UTXhF60s6SWpuDF0Q=
golang.org/x/crypto v0.0.0-20180904163835-0709b304e793/go.mod h1:6SG95UA2DQfeDnfUPMdvaQW0Q7yPrPDi9nlGo2tz2b4=
+golang.org/x/crypto v0.0.0-20181029175232-7e6ffbd03851/go.mod h1:6SG95UA2DQfeDnfUPMdvaQW0Q7yPrPDi9nlGo2tz2b4=
golang.org/x/crypto v0.0.0-20190308221718-c2843e01d9a2/go.mod h1:djNgcEr1/C05ACkg1iLfiJU5Ep61QUkGW8qpdssI0+w=
+golang.org/x/crypto v0.0.0-20190426145343-a29dc8fdc734 h1:p/H982KKEjUnLJkM3tt/LemDnOc1GiZL5FCVlORJ5zo=
golang.org/x/crypto v0.0.0-20190426145343-a29dc8fdc734/go.mod h1:yigFU9vqHzYiE8UmvKecakEJjdnWj3jj499lnFckfCI=
golang.org/x/lint v0.0.0-20181026193005-c67002cb31c3/go.mod h1:UVdnD1Gm6xHRNCYTkRU2/jEulfH38KcIWyp/GAMgvoE=
golang.org/x/lint v0.0.0-20190313153728-d0100b6bd8b3/go.mod h1:6SW0HCj/g11FgYtHlgUYUwCkIfeOF89ocIRzGO/8vkc=
golang.org/x/net v0.0.0-20180826012351-8a410e7b638d/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
golang.org/x/net v0.0.0-20180906233101-161cd47e91fd/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
+golang.org/x/net v0.0.0-20181029044818-c44066c5c816/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
golang.org/x/net v0.0.0-20181114220301-adae6a3d119a/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
golang.org/x/net v0.0.0-20181220203305-927f97764cc3/go.mod h1:mL1N/T3taQHkDXs73rZJwtUhF3w3ftmwwsq0BUmARs4=
golang.org/x/net v0.0.0-20190311183353-d8887717615a/go.mod h1:t9HGtf8HONx5eT2rtn7q6eTqICYqUVnKs3thJo3Qplg=
@@ -204,6 +237,8 @@ google.golang.org/genproto v0.0.0-20180817151627-c66870c02cf8/go.mod h1:JiN7NxoA
google.golang.org/grpc v1.19.0/go.mod h1:mqu4LbDTu4XGKhr4mRzUsmM4RtVoemTSY81AxZiDr8c=
google.golang.org/grpc v1.21.0/go.mod h1:oYelfM1adQP15Ek0mdvEgi9Df8B9CZIaU1084ijfRaM=
gopkg.in/alecthomas/kingpin.v2 v2.2.6/go.mod h1:FMv+mEhP44yOT+4EoQTLFTRgOQ1FBLkstjWtayDeSgw=
+gopkg.in/alexcesaro/quotedprintable.v3 v3.0.0-20150716171945-2caba252f4dc h1:2gGKlE2+asNV9m7xrywl36YYNnBG5ZQ0r/BOOxqPpmk=
+gopkg.in/alexcesaro/quotedprintable.v3 v3.0.0-20150716171945-2caba252f4dc/go.mod h1:m7x9LTH6d71AHyAX77c9yqWCCa3UKHcVEj9y7hAtKDk=
gopkg.in/check.v1 v0.0.0-20161208181325-20d25e280405/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127 h1:qIbj1fsPNlZgppZ+VLlY7N33q108Sa+fhmuc+sWQYwY=
gopkg.in/check.v1 v1.0.0-20180628173108-788fd7840127/go.mod h1:Co6ibVJAznAaIkqp8huTwlJQCZ016jof/cbN4VW5Yz0=
@@ -214,7 +249,11 @@ gopkg.in/go-playground/validator.v8 v8.18.2 h1:lFB4DoMU6B626w8ny76MV7VX6W2VHct2G
gopkg.in/go-playground/validator.v8 v8.18.2/go.mod h1:RX2a/7Ha8BgOhfk7j780h4/u/RRjR0eouCJSH80/M2Y=
gopkg.in/go-playground/validator.v9 v9.29.1 h1:SvGtYmN60a5CVKTOzMSyfzWDeZRxRuGvRQyEAKbw1xc=
gopkg.in/go-playground/validator.v9 v9.29.1/go.mod h1:+c9/zcJMFNgbLvly1L1V+PpxWdVbfP1avr/N00E2vyQ=
+gopkg.in/gomail.v2 v2.0.0-20150902115704-41f357289737 h1:NvePS/smRcFQ4bMtTddFtknbGCtoBkJxGmpSpVRafCc=
+gopkg.in/gomail.v2 v2.0.0-20150902115704-41f357289737/go.mod h1:LRQQ+SO6ZHR7tOkpBDuZnXENFzX8qRjMDMyPD6BRkCw=
gopkg.in/resty.v1 v1.12.0/go.mod h1:mDo4pnntr5jdWRML875a/NmxYqAlA73dVijT2AXvQQo=
+gopkg.in/russross/blackfriday.v2 v2.0.0 h1:+FlnIV8DSQnT7NZ43hcVKcdJdzZoeCmJj4Ql8gq5keA=
+gopkg.in/russross/blackfriday.v2 v2.0.0/go.mod h1:6sSBNz/GtOm/pJTuh5UmBK2ZHfmnxGbl2NZg1UliSOI=
gopkg.in/tomb.v1 v1.0.0-20141024135613-dd632973f1e7/go.mod h1:dt/ZhP58zS4L8KSrWDmTeBkI65Dw0HsyUHuEVlX15mw=
gopkg.in/yaml.v2 v2.0.0-20170812160011-eb3733d160e7/go.mod h1:JAlM8MvJe8wmxCU4Bli9HhUf9+ttbYbLASfIpnQbh74=
gopkg.in/yaml.v2 v2.2.1/go.mod h1:hI93XBmqTisBFMUTm0b8Fm+jr3Dg1NNxqwp+5A1VGuI=
diff --git a/backend/main.go b/backend/main.go
index 2c92ab37..ab0d0e7b 100644
--- a/backend/main.go
+++ b/backend/main.go
@@ -31,22 +31,23 @@ func main() {
log.Error("init config error:" + err.Error())
panic(err)
}
- log.Info("初始化配置成功")
+ log.Info("initialized config successfully")
// 初始化日志设置
logLevel := viper.GetString("log.level")
if logLevel != "" {
log.SetLevelFromString(logLevel)
}
- log.Info("初始化日志设置成功")
-
+ log.Info("initialized log config successfully")
if viper.GetString("log.isDeletePeriodically") == "Y" {
err := services.InitDeleteLogPeriodically()
if err != nil {
- log.Error("Init DeletePeriodically Failed")
+ log.Error("init DeletePeriodically failed")
panic(err)
}
- log.Info("初始化定期清理日志配置成功")
+ log.Info("initialized periodically cleaning log successfully")
+ } else {
+ log.Info("periodically cleaning log is switched off")
}
// 初始化Mongodb数据库
@@ -55,7 +56,7 @@ func main() {
debug.PrintStack()
panic(err)
}
- log.Info("初始化Mongodb数据库成功")
+ log.Info("initialized MongoDB successfully")
// 初始化Redis数据库
if err := database.InitRedis(); err != nil {
@@ -63,7 +64,7 @@ func main() {
debug.PrintStack()
panic(err)
}
- log.Info("初始化Redis数据库成功")
+ log.Info("initialized Redis successfully")
if model.IsMaster() {
// 初始化定时任务
@@ -72,7 +73,23 @@ func main() {
debug.PrintStack()
panic(err)
}
- log.Info("初始化定时任务成功")
+ log.Info("initialized schedule successfully")
+
+ // 初始化用户服务
+ if err := services.InitUserService(); err != nil {
+ log.Error("init user service error:" + err.Error())
+ debug.PrintStack()
+ panic(err)
+ }
+ log.Info("initialized user service successfully")
+
+ // 初始化依赖服务
+ if err := services.InitDepsFetcher(); err != nil {
+ log.Error("init dependency fetcher error:" + err.Error())
+ debug.PrintStack()
+ panic(err)
+ }
+ log.Info("initialized dependency fetcher successfully")
}
// 初始化任务执行器
@@ -81,14 +98,14 @@ func main() {
debug.PrintStack()
panic(err)
}
- log.Info("初始化任务执行器成功")
+ log.Info("initialized task executor successfully")
// 初始化节点服务
if err := services.InitNodeService(); err != nil {
log.Error("init node service error:" + err.Error())
panic(err)
}
- log.Info("初始化节点配置成功")
+ log.Info("initialized node service successfully")
// 初始化爬虫服务
if err := services.InitSpiderService(); err != nil {
@@ -96,73 +113,133 @@ func main() {
debug.PrintStack()
panic(err)
}
- log.Info("初始化爬虫服务成功")
+ log.Info("initialized spider service successfully")
- // 初始化用户服务
- if err := services.InitUserService(); err != nil {
- log.Error("init user service error:" + err.Error())
+ // 初始化RPC服务
+ if err := services.InitRpcService(); err != nil {
+ log.Error("init rpc service error:" + err.Error())
debug.PrintStack()
panic(err)
}
- log.Info("初始化用户服务成功")
+ log.Info("initialized rpc service successfully")
// 以下为主节点服务
if model.IsMaster() {
// 中间件
app.Use(middlewares.CORSMiddleware())
- //app.Use(middlewares.AuthorizationMiddleware())
anonymousGroup := app.Group("/")
{
- anonymousGroup.POST("/login", routes.Login) // 用户登录
- anonymousGroup.PUT("/users", routes.PutUser) // 添加用户
-
+ anonymousGroup.POST("/login", routes.Login) // 用户登录
+ anonymousGroup.PUT("/users", routes.PutUser) // 添加用户
+ anonymousGroup.GET("/setting", routes.GetSetting) // 获取配置信息
+ // release版本
+ anonymousGroup.GET("/version", routes.GetVersion) // 获取发布的版本
}
authGroup := app.Group("/", middlewares.AuthorizationMiddleware())
{
- // 路由
// 节点
- authGroup.GET("/nodes", routes.GetNodeList) // 节点列表
- authGroup.GET("/nodes/:id", routes.GetNode) // 节点详情
- authGroup.POST("/nodes/:id", routes.PostNode) // 修改节点
- authGroup.GET("/nodes/:id/tasks", routes.GetNodeTaskList) // 节点任务列表
- authGroup.GET("/nodes/:id/system", routes.GetSystemInfo) // 节点任务列表
- authGroup.DELETE("/nodes/:id", routes.DeleteNode) // 删除节点
+ {
+ authGroup.GET("/nodes", routes.GetNodeList) // 节点列表
+ authGroup.GET("/nodes/:id", routes.GetNode) // 节点详情
+ authGroup.POST("/nodes/:id", routes.PostNode) // 修改节点
+ authGroup.GET("/nodes/:id/tasks", routes.GetNodeTaskList) // 节点任务列表
+ authGroup.GET("/nodes/:id/system", routes.GetSystemInfo) // 节点任务列表
+ authGroup.DELETE("/nodes/:id", routes.DeleteNode) // 删除节点
+ authGroup.GET("/nodes/:id/langs", routes.GetLangList) // 节点语言环境列表
+ authGroup.GET("/nodes/:id/deps", routes.GetDepList) // 节点第三方依赖列表
+ authGroup.GET("/nodes/:id/deps/installed", routes.GetInstalledDepList) // 节点已安装第三方依赖列表
+ authGroup.POST("/nodes/:id/deps/install", routes.InstallDep) // 节点安装依赖
+ authGroup.POST("/nodes/:id/deps/uninstall", routes.UninstallDep) // 节点卸载依赖
+ authGroup.POST("/nodes/:id/langs/install", routes.InstallLang) // 节点安装语言
+ }
// 爬虫
- authGroup.GET("/spiders", routes.GetSpiderList) // 爬虫列表
- authGroup.GET("/spiders/:id", routes.GetSpider) // 爬虫详情
- authGroup.POST("/spiders", routes.PutSpider) // 上传爬虫
- authGroup.POST("/spiders/:id", routes.PostSpider) // 修改爬虫
- authGroup.POST("/spiders/:id/publish", routes.PublishSpider) // 发布爬虫
- authGroup.DELETE("/spiders/:id", routes.DeleteSpider) // 删除爬虫
- authGroup.GET("/spiders/:id/tasks", routes.GetSpiderTasks) // 爬虫任务列表
- authGroup.GET("/spiders/:id/file", routes.GetSpiderFile) // 爬虫文件读取
- authGroup.POST("/spiders/:id/file", routes.PostSpiderFile) // 爬虫目录写入
- authGroup.GET("/spiders/:id/dir", routes.GetSpiderDir) // 爬虫目录
- authGroup.GET("/spiders/:id/stats", routes.GetSpiderStats) // 爬虫统计数据
- authGroup.GET("/spider/types", routes.GetSpiderTypes) // 爬虫类型
+ {
+ authGroup.GET("/spiders", routes.GetSpiderList) // 爬虫列表
+ authGroup.GET("/spiders/:id", routes.GetSpider) // 爬虫详情
+ authGroup.PUT("/spiders", routes.PutSpider) // 添加爬虫
+ authGroup.POST("/spiders", routes.UploadSpider) // 上传爬虫
+ authGroup.POST("/spiders/:id", routes.PostSpider) // 修改爬虫
+ authGroup.POST("/spiders/:id/publish", routes.PublishSpider) // 发布爬虫
+ authGroup.POST("/spiders/:id/upload", routes.UploadSpiderFromId) // 上传爬虫(ID)
+ authGroup.DELETE("/spiders/:id", routes.DeleteSpider) // 删除爬虫
+ authGroup.GET("/spiders/:id/tasks", routes.GetSpiderTasks) // 爬虫任务列表
+ authGroup.GET("/spiders/:id/file/tree", routes.GetSpiderFileTree) // 爬虫文件目录树读取
+ authGroup.GET("/spiders/:id/file", routes.GetSpiderFile) // 爬虫文件读取
+ authGroup.POST("/spiders/:id/file", routes.PostSpiderFile) // 爬虫文件更改
+ authGroup.PUT("/spiders/:id/file", routes.PutSpiderFile) // 爬虫文件创建
+ authGroup.PUT("/spiders/:id/dir", routes.PutSpiderDir) // 爬虫目录创建
+ authGroup.DELETE("/spiders/:id/file", routes.DeleteSpiderFile) // 爬虫文件删除
+ authGroup.POST("/spiders/:id/file/rename", routes.RenameSpiderFile) // 爬虫文件重命名
+ authGroup.GET("/spiders/:id/dir", routes.GetSpiderDir) // 爬虫目录
+ authGroup.GET("/spiders/:id/stats", routes.GetSpiderStats) // 爬虫统计数据
+ authGroup.GET("/spiders/:id/schedules", routes.GetSpiderSchedules) // 爬虫定时任务
+ }
+ // 可配置爬虫
+ {
+ authGroup.GET("/config_spiders/:id/config", routes.GetConfigSpiderConfig) // 获取可配置爬虫配置
+ authGroup.POST("/config_spiders/:id/config", routes.PostConfigSpiderConfig) // 更改可配置爬虫配置
+ authGroup.PUT("/config_spiders", routes.PutConfigSpider) // 添加可配置爬虫
+ authGroup.POST("/config_spiders/:id", routes.PostConfigSpider) // 修改可配置爬虫
+ authGroup.POST("/config_spiders/:id/upload", routes.UploadConfigSpider) // 上传可配置爬虫
+ authGroup.POST("/config_spiders/:id/spiderfile", routes.PostConfigSpiderSpiderfile) // 上传可配置爬虫
+ authGroup.GET("/config_spiders_templates", routes.GetConfigSpiderTemplateList) // 获取可配置爬虫模版列表
+ }
// 任务
- authGroup.GET("/tasks", routes.GetTaskList) // 任务列表
- authGroup.GET("/tasks/:id", routes.GetTask) // 任务详情
- authGroup.PUT("/tasks", routes.PutTask) // 派发任务
- authGroup.DELETE("/tasks/:id", routes.DeleteTask) // 删除任务
- authGroup.POST("/tasks/:id/cancel", routes.CancelTask) // 取消任务
- authGroup.GET("/tasks/:id/log", routes.GetTaskLog) // 任务日志
- authGroup.GET("/tasks/:id/results", routes.GetTaskResults) // 任务结果
- authGroup.GET("/tasks/:id/results/download", routes.DownloadTaskResultsCsv) // 下载任务结果
+ {
+ authGroup.GET("/tasks", routes.GetTaskList) // 任务列表
+ authGroup.GET("/tasks/:id", routes.GetTask) // 任务详情
+ authGroup.PUT("/tasks", routes.PutTask) // 派发任务
+ authGroup.DELETE("/tasks/:id", routes.DeleteTask) // 删除任务
+ authGroup.DELETE("/tasks_multiple", routes.DeleteMultipleTask) // 删除多个任务
+ authGroup.DELETE("/tasks_by_status", routes.DeleteTaskByStatus) //删除指定状态的任务
+ authGroup.POST("/tasks/:id/cancel", routes.CancelTask) // 取消任务
+ authGroup.GET("/tasks/:id/log", routes.GetTaskLog) // 任务日志
+ authGroup.GET("/tasks/:id/results", routes.GetTaskResults) // 任务结果
+ authGroup.GET("/tasks/:id/results/download", routes.DownloadTaskResultsCsv) // 下载任务结果
+ }
// 定时任务
- authGroup.GET("/schedules", routes.GetScheduleList) // 定时任务列表
- authGroup.GET("/schedules/:id", routes.GetSchedule) // 定时任务详情
- authGroup.PUT("/schedules", routes.PutSchedule) // 创建定时任务
- authGroup.POST("/schedules/:id", routes.PostSchedule) // 修改定时任务
- authGroup.DELETE("/schedules/:id", routes.DeleteSchedule) // 删除定时任务
+ {
+ authGroup.GET("/schedules", routes.GetScheduleList) // 定时任务列表
+ authGroup.GET("/schedules/:id", routes.GetSchedule) // 定时任务详情
+ authGroup.PUT("/schedules", routes.PutSchedule) // 创建定时任务
+ authGroup.POST("/schedules/:id", routes.PostSchedule) // 修改定时任务
+ authGroup.DELETE("/schedules/:id", routes.DeleteSchedule) // 删除定时任务
+ authGroup.POST("/schedules/:id/disable", routes.DisableSchedule) // 禁用定时任务
+ authGroup.POST("/schedules/:id/enable", routes.EnableSchedule) // 启用定时任务
+ }
+ // 用户
+ {
+ authGroup.GET("/users", routes.GetUserList) // 用户列表
+ authGroup.GET("/users/:id", routes.GetUser) // 用户详情
+ authGroup.POST("/users/:id", routes.PostUser) // 更改用户
+ authGroup.DELETE("/users/:id", routes.DeleteUser) // 删除用户
+ authGroup.GET("/me", routes.GetMe) // 获取自己账户
+ authGroup.POST("/me", routes.PostMe) // 修改自己账户
+ }
+ // 系统
+ {
+ authGroup.GET("/system/deps/:lang", routes.GetAllDepList) // 节点所有第三方依赖列表
+ authGroup.GET("/system/deps/:lang/:dep_name/json", routes.GetDepJson) // 节点第三方依赖JSON
+ }
+ // 全局变量
+ {
+ authGroup.GET("/variables", routes.GetVariableList) // 列表
+ authGroup.PUT("/variable", routes.PutVariable) // 新增
+ authGroup.POST("/variable/:id", routes.PostVariable) //修改
+ authGroup.DELETE("/variable/:id", routes.DeleteVariable) //删除
+ }
+ // 项目
+ {
+ authGroup.GET("/projects", routes.GetProjectList) // 列表
+ authGroup.GET("/projects/tags", routes.GetProjectTags) // 项目标签
+ authGroup.PUT("/projects", routes.PutProject) //修改
+ authGroup.POST("/projects/:id", routes.PostProject) // 新增
+ authGroup.DELETE("/projects/:id", routes.DeleteProject) //删除
+ }
// 统计数据
authGroup.GET("/stats/home", routes.GetHomeStats) // 首页统计数据
- // 用户
- authGroup.GET("/users", routes.GetUserList) // 用户列表
- authGroup.GET("/users/:id", routes.GetUser) // 用户详情
- authGroup.POST("/users/:id", routes.PostUser) // 更改用户
- authGroup.DELETE("/users/:id", routes.DeleteUser) // 删除用户
- authGroup.GET("/me", routes.GetMe) // 获取自己账户
+ // 文件
+ authGroup.GET("/file", routes.GetFile) // 获取文件
}
}
diff --git a/backend/mock/node_test.go b/backend/mock/node_test.go
index 669cafc5..abd568c2 100644
--- a/backend/mock/node_test.go
+++ b/backend/mock/node_test.go
@@ -42,12 +42,12 @@ func init() {
app.DELETE("/tasks/:id", DeleteTask) // 删除任务
app.GET("/tasks/:id/results", GetTaskResults) // 任务结果
app.GET("/tasks/:id/results/download", DownloadTaskResultsCsv) // 下载任务结果
- app.GET("/spiders", GetSpiderList) // 爬虫列表
- app.GET("/spiders/:id", GetSpider) // 爬虫详情
- app.POST("/spiders/:id", PostSpider) // 修改爬虫
- app.DELETE("/spiders/:id",DeleteSpider) // 删除爬虫
- app.GET("/spiders/:id/tasks",GetSpiderTasks) // 爬虫任务列表
- app.GET("/spiders/:id/dir",GetSpiderDir) // 爬虫目录
+ app.GET("/spiders", GetSpiderList) // 爬虫列表
+ app.GET("/spiders/:id", GetSpider) // 爬虫详情
+ app.POST("/spiders/:id", PostSpider) // 修改爬虫
+ app.DELETE("/spiders/:id", DeleteSpider) // 删除爬虫
+ app.GET("/spiders/:id/tasks", GetSpiderTasks) // 爬虫任务列表
+ app.GET("/spiders/:id/dir", GetSpiderDir) // 爬虫目录
}
//mock test, test data in ./mock
diff --git a/backend/mock/schedule.go b/backend/mock/schedule.go
index 702e8754..015236f8 100644
--- a/backend/mock/schedule.go
+++ b/backend/mock/schedule.go
@@ -10,17 +10,19 @@ import (
"time"
)
+var NodeIdss = []bson.ObjectId{bson.ObjectIdHex("5d429e6c19f7abede924fee2"),
+ bson.ObjectIdHex("5d429e6c19f7abede924fee1")}
+
var scheduleList = []model.Schedule{
{
Id: bson.ObjectId("5d429e6c19f7abede924fee2"),
Name: "test schedule",
SpiderId: "123",
- NodeId: bson.ObjectId("5d429e6c19f7abede924fee2"),
+ NodeIds: NodeIdss,
Cron: "***1*",
EntryId: 10,
// 前端展示
SpiderName: "test scedule",
- NodeName: "测试节点",
CreateTs: time.Now(),
UpdateTs: time.Now(),
@@ -29,12 +31,11 @@ var scheduleList = []model.Schedule{
Id: bson.ObjectId("xx429e6c19f7abede924fee2"),
Name: "test schedule2",
SpiderId: "234",
- NodeId: bson.ObjectId("5d429e6c19f7abede924fee2"),
+ NodeIds: NodeIdss,
Cron: "***1*",
EntryId: 10,
// 前端展示
SpiderName: "test scedule2",
- NodeName: "测试节点",
CreateTs: time.Now(),
UpdateTs: time.Now(),
@@ -100,8 +101,10 @@ func PutSchedule(c *gin.Context) {
}
// 如果node_id为空,则置为空ObjectId
- if item.NodeId == "" {
- item.NodeId = bson.ObjectIdHex(constants.ObjectIdNull)
+ for _, NodeId := range item.NodeIds {
+ if NodeId == "" {
+ NodeId = bson.ObjectIdHex(constants.ObjectIdNull)
+ }
}
c.JSON(http.StatusOK, Response{
diff --git a/backend/mock/schedule_test.go b/backend/mock/schedule_test.go
index 12843c75..87f1131a 100644
--- a/backend/mock/schedule_test.go
+++ b/backend/mock/schedule_test.go
@@ -75,12 +75,11 @@ func TestPostSchedule(t *testing.T) {
Id: bson.ObjectIdHex("5d429e6c19f7abede924fee2"),
Name: "test schedule",
SpiderId: bson.ObjectIdHex("5d429e6c19f7abede924fee2"),
- NodeId: bson.ObjectIdHex("5d429e6c19f7abede924fee2"),
+ NodeIds: NodeIdss,
Cron: "***1*",
EntryId: 10,
// 前端展示
SpiderName: "test scedule",
- NodeName: "测试节点",
CreateTs: time.Now(),
UpdateTs: time.Now(),
@@ -112,12 +111,11 @@ func TestPutSchedule(t *testing.T) {
Id: bson.ObjectIdHex("5d429e6c19f7abede924fee2"),
Name: "test schedule",
SpiderId: bson.ObjectIdHex("5d429e6c19f7abede924fee2"),
- NodeId: bson.ObjectIdHex("5d429e6c19f7abede924fee2"),
+ NodeIds: NodeIdss,
Cron: "***1*",
EntryId: 10,
// 前端展示
SpiderName: "test scedule",
- NodeName: "测试节点",
CreateTs: time.Now(),
UpdateTs: time.Now(),
diff --git a/backend/mock/stats.go b/backend/mock/stats.go
index db2348c6..f0227da9 100644
--- a/backend/mock/stats.go
+++ b/backend/mock/stats.go
@@ -6,8 +6,6 @@ import (
"net/http"
)
-
-
var taskDailyItems = []model.TaskDailyItem{
{
Date: "2019/08/19",
diff --git a/backend/mock/system.go b/backend/mock/system.go
index c4807247..f33e02ba 100644
--- a/backend/mock/system.go
+++ b/backend/mock/system.go
@@ -1 +1 @@
-package mock
\ No newline at end of file
+package mock
diff --git a/backend/mock/user.go b/backend/mock/user.go
index c4807247..f33e02ba 100644
--- a/backend/mock/user.go
+++ b/backend/mock/user.go
@@ -1 +1 @@
-package mock
\ No newline at end of file
+package mock
diff --git a/backend/model/config_spider/common.go b/backend/model/config_spider/common.go
new file mode 100644
index 00000000..4d244fe1
--- /dev/null
+++ b/backend/model/config_spider/common.go
@@ -0,0 +1,26 @@
+package config_spider
+
+import "crawlab/entity"
+
+func GetAllFields(data entity.ConfigSpiderData) []entity.Field {
+ var fields []entity.Field
+ for _, stage := range data.Stages {
+ for _, field := range stage.Fields {
+ fields = append(fields, field)
+ }
+ }
+ return fields
+}
+
+func GetStartStageName(data entity.ConfigSpiderData) string {
+ // 如果 start_stage 设置了且在 stages 里,则返回
+ if data.StartStage != "" {
+ return data.StartStage
+ }
+
+ // 否则返回第一个 stage
+ for _, stage := range data.Stages {
+ return stage.Name
+ }
+ return ""
+}
diff --git a/backend/model/config_spider/scrapy.go b/backend/model/config_spider/scrapy.go
new file mode 100644
index 00000000..ee24a3e7
--- /dev/null
+++ b/backend/model/config_spider/scrapy.go
@@ -0,0 +1,259 @@
+package config_spider
+
+import (
+ "crawlab/constants"
+ "crawlab/entity"
+ "crawlab/model"
+ "crawlab/utils"
+ "errors"
+ "fmt"
+ "path/filepath"
+)
+
+type ScrapyGenerator struct {
+ Spider model.Spider
+ ConfigData entity.ConfigSpiderData
+}
+
+// 生成爬虫文件
+func (g ScrapyGenerator) Generate() error {
+ // 生成 items.py
+ if err := g.ProcessItems(); err != nil {
+ return err
+ }
+
+ // 生成 spider.py
+ if err := g.ProcessSpider(); err != nil {
+ return err
+ }
+ return nil
+}
+
+// 生成 items.py
+func (g ScrapyGenerator) ProcessItems() error {
+ // 待处理文件名
+ src := g.Spider.Src
+ filePath := filepath.Join(src, "config_spider", "items.py")
+
+ // 获取所有字段
+ fields := g.GetAllFields()
+
+ // 字段名列表(包含默认字段名)
+ fieldNames := []string{
+ "_id",
+ "task_id",
+ "ts",
+ }
+
+ // 加入字段
+ for _, field := range fields {
+ fieldNames = append(fieldNames, field.Name)
+ }
+
+ // 将字段名转化为python代码
+ str := ""
+ for _, fieldName := range fieldNames {
+ line := g.PadCode(fmt.Sprintf("%s = scrapy.Field()", fieldName), 1)
+ str += line
+ }
+
+ // 将占位符替换为代码
+ if err := utils.SetFileVariable(filePath, constants.AnchorItems, str); err != nil {
+ return err
+ }
+
+ return nil
+}
+
+// 生成 spider.py
+func (g ScrapyGenerator) ProcessSpider() error {
+ // 待处理文件名
+ src := g.Spider.Src
+ filePath := filepath.Join(src, "config_spider", "spiders", "spider.py")
+
+ // 替换 start_stage
+ if err := utils.SetFileVariable(filePath, constants.AnchorStartStage, "parse_"+GetStartStageName(g.ConfigData)); err != nil {
+ return err
+ }
+
+ // 替换 start_url
+ if err := utils.SetFileVariable(filePath, constants.AnchorStartUrl, g.ConfigData.StartUrl); err != nil {
+ return err
+ }
+
+ // 替换 parsers
+ strParser := ""
+ for _, stage := range g.ConfigData.Stages {
+ stageName := stage.Name
+ stageStr := g.GetParserString(stageName, stage)
+ strParser += stageStr
+ }
+ if err := utils.SetFileVariable(filePath, constants.AnchorParsers, strParser); err != nil {
+ return err
+ }
+
+ return nil
+}
+
+func (g ScrapyGenerator) GetParserString(stageName string, stage entity.Stage) string {
+ // 构造函数定义行
+ strDef := g.PadCode(fmt.Sprintf("def parse_%s(self, response):", stageName), 1)
+
+ strParse := ""
+ if stage.IsList {
+ // 列表逻辑
+ strParse = g.GetListParserString(stageName, stage)
+ } else {
+ // 非列表逻辑
+ strParse = g.GetNonListParserString(stageName, stage)
+ }
+
+ // 构造
+ str := fmt.Sprintf(`%s%s`, strDef, strParse)
+
+ return str
+}
+
+func (g ScrapyGenerator) PadCode(str string, num int) string {
+ res := ""
+ for i := 0; i < num; i++ {
+ res += " "
+ }
+ res += str
+ res += "\n"
+ return res
+}
+
+func (g ScrapyGenerator) GetNonListParserString(stageName string, stage entity.Stage) string {
+ str := ""
+
+ // 获取或构造item
+ str += g.PadCode("item = Item() if response.meta.get('item') is None else response.meta.get('item')", 2)
+
+ // 遍历字段列表
+ for _, f := range stage.Fields {
+ line := fmt.Sprintf(`item['%s'] = response.%s.extract_first()`, f.Name, g.GetExtractStringFromField(f))
+ line = g.PadCode(line, 2)
+ str += line
+ }
+
+ // next stage 字段
+ if f, err := g.GetNextStageField(stage); err == nil {
+ // 如果找到 next stage 字段,进行下一个回调
+ str += g.PadCode(fmt.Sprintf(`yield scrapy.Request(url="get_real_url(response, item['%s'])", callback=self.parse_%s, meta={'item': item})`, f.Name, f.NextStage), 2)
+ } else {
+ // 如果没找到 next stage 字段,返回 item
+ str += g.PadCode(fmt.Sprintf(`yield item`), 2)
+ }
+
+ // 加入末尾换行
+ str += g.PadCode("", 0)
+
+ return str
+}
+
+func (g ScrapyGenerator) GetListParserString(stageName string, stage entity.Stage) string {
+ str := ""
+
+ // 获取前一个 stage 的 item
+ str += g.PadCode(`prev_item = response.meta.get('item')`, 2)
+
+ // for 循环遍历列表
+ str += g.PadCode(fmt.Sprintf(`for elem in response.%s:`, g.GetListString(stage)), 2)
+
+ // 构造item
+ str += g.PadCode(`item = Item()`, 3)
+
+ // 遍历字段列表
+ for _, f := range stage.Fields {
+ line := fmt.Sprintf(`item['%s'] = elem.%s.extract_first()`, f.Name, g.GetExtractStringFromField(f))
+ line = g.PadCode(line, 3)
+ str += line
+ }
+
+ // 把前一个 stage 的 item 值赋给当前 item
+ str += g.PadCode(`if prev_item is not None:`, 3)
+ str += g.PadCode(`for key, value in prev_item.items():`, 4)
+ str += g.PadCode(`item[key] = value`, 5)
+
+ // next stage 字段
+ if f, err := g.GetNextStageField(stage); err == nil {
+ // 如果找到 next stage 字段,进行下一个回调
+ str += g.PadCode(fmt.Sprintf(`yield scrapy.Request(url=get_real_url(response, item['%s']), callback=self.parse_%s, meta={'item': item})`, f.Name, f.NextStage), 3)
+ } else {
+ // 如果没找到 next stage 字段,返回 item
+ str += g.PadCode(fmt.Sprintf(`yield item`), 3)
+ }
+
+ // 分页
+ if stage.PageCss != "" || stage.PageXpath != "" {
+ str += g.PadCode(fmt.Sprintf(`next_url = response.%s.extract_first()`, g.GetExtractStringFromStage(stage)), 2)
+ str += g.PadCode(fmt.Sprintf(`yield scrapy.Request(url=get_real_url(response, next_url), callback=self.parse_%s, meta={'item': prev_item})`, stageName), 2)
+ }
+
+ // 加入末尾换行
+ str += g.PadCode("", 0)
+
+ return str
+}
+
+// 获取所有字段
+func (g ScrapyGenerator) GetAllFields() []entity.Field {
+ return GetAllFields(g.ConfigData)
+}
+
+// 获取包含 next stage 的字段
+func (g ScrapyGenerator) GetNextStageField(stage entity.Stage) (entity.Field, error) {
+ for _, field := range stage.Fields {
+ if field.NextStage != "" {
+ return field, nil
+ }
+ }
+ return entity.Field{}, errors.New("cannot find next stage field")
+}
+
+func (g ScrapyGenerator) GetExtractStringFromField(f entity.Field) string {
+ if f.Css != "" {
+ // 如果为CSS
+ if f.Attr == "" {
+ // 文本
+ return fmt.Sprintf(`css('%s::text')`, f.Css)
+ } else {
+ // 属性
+ return fmt.Sprintf(`css('%s::attr("%s")')`, f.Css, f.Attr)
+ }
+ } else {
+ // 如果为XPath
+ if f.Attr == "" {
+ // 文本
+ return fmt.Sprintf(`xpath('string(%s)')`, f.Xpath)
+ } else {
+ // 属性
+ return fmt.Sprintf(`xpath('%s/@%s')`, f.Xpath, f.Attr)
+ }
+ }
+}
+
+func (g ScrapyGenerator) GetExtractStringFromStage(stage entity.Stage) string {
+ // 分页元素属性,默认为 href
+ pageAttr := "href"
+ if stage.PageAttr != "" {
+ pageAttr = stage.PageAttr
+ }
+
+ if stage.PageCss != "" {
+ // 如果为CSS
+ return fmt.Sprintf(`css('%s::attr("%s")')`, stage.PageCss, pageAttr)
+ } else {
+ // 如果为XPath
+ return fmt.Sprintf(`xpath('%s/@%s')`, stage.PageXpath, pageAttr)
+ }
+}
+
+func (g ScrapyGenerator) GetListString(stage entity.Stage) string {
+ if stage.ListCss != "" {
+ return fmt.Sprintf(`css('%s')`, stage.ListCss)
+ } else {
+ return fmt.Sprintf(`xpath('%s')`, stage.ListXpath)
+ }
+}
diff --git a/backend/model/file.go b/backend/model/file.go
index fe3ece0e..a2ad34eb 100644
--- a/backend/model/file.go
+++ b/backend/model/file.go
@@ -20,10 +20,13 @@ type GridFs struct {
}
type File struct {
- Name string `json:"name"`
- Path string `json:"path"`
- IsDir bool `json:"is_dir"`
- Size int64 `json:"size"`
+ Name string `json:"name"`
+ Path string `json:"path"`
+ RelativePath string `json:"relative_path"`
+ IsDir bool `json:"is_dir"`
+ Size int64 `json:"size"`
+ Children []File `json:"children"`
+ Label string `json:"label"`
}
func (f *GridFs) Remove() {
diff --git a/backend/model/node.go b/backend/model/node.go
index 1c63fc3e..88c4ed66 100644
--- a/backend/model/node.go
+++ b/backend/model/node.go
@@ -55,7 +55,7 @@ func GetCurrentNode() (Node, error) {
for {
// 如果错误次数超过10次
if errNum >= 10 {
- panic("cannot get current node")
+ return node, errors.New("cannot get current node")
}
// 尝试获取节点
@@ -63,7 +63,9 @@ func GetCurrentNode() (Node, error) {
// 如果获取失败
if err != nil {
// 如果为主节点,表示为第一次注册,插入节点信息
- if IsMaster() {
+ // update: 增加具体错误过滤。防止加入多个master节点,后续需要职责拆分,
+ //只在master节点运行的时候才检测master节点的信息是否存在
+ if IsMaster() && err == mgo.ErrNotFound {
// 获取本机信息
ip, mac, key, err := GetNodeBaseInfo()
if err != nil {
@@ -143,6 +145,7 @@ func (n *Node) GetTasks() ([]Task, error) {
return tasks, nil
}
+// 节点列表
func GetNodeList(filter interface{}) ([]Node, error) {
s, c := database.GetCol("nodes")
defer s.Close()
@@ -156,6 +159,7 @@ func GetNodeList(filter interface{}) ([]Node, error) {
return results, nil
}
+// 节点信息
func GetNode(id bson.ObjectId) (Node, error) {
var node Node
@@ -169,13 +173,14 @@ func GetNode(id bson.ObjectId) (Node, error) {
defer s.Close()
if err := c.FindId(id).One(&node); err != nil {
- log.Errorf(err.Error())
- debug.PrintStack()
+ //log.Errorf("get node error: %s, id: %s", err.Error(), id.Hex())
+ //debug.PrintStack()
return node, err
}
return node, nil
}
+// 节点信息
func GetNodeByKey(key string) (Node, error) {
s, c := database.GetCol("nodes")
defer s.Close()
@@ -191,6 +196,7 @@ func GetNodeByKey(key string) (Node, error) {
return node, nil
}
+// 更新节点
func UpdateNode(id bson.ObjectId, item Node) error {
s, c := database.GetCol("nodes")
defer s.Close()
@@ -206,6 +212,7 @@ func UpdateNode(id bson.ObjectId, item Node) error {
return nil
}
+// 任务列表
func GetNodeTaskList(id bson.ObjectId) ([]Task, error) {
node, err := GetNode(id)
if err != nil {
@@ -218,6 +225,7 @@ func GetNodeTaskList(id bson.ObjectId) ([]Task, error) {
return tasks, nil
}
+// 节点数
func GetNodeCount(query interface{}) (int, error) {
s, c := database.GetCol("nodes")
defer s.Close()
diff --git a/backend/model/project.go b/backend/model/project.go
new file mode 100644
index 00000000..92c72655
--- /dev/null
+++ b/backend/model/project.go
@@ -0,0 +1,146 @@
+package model
+
+import (
+ "crawlab/constants"
+ "crawlab/database"
+ "github.com/apex/log"
+ "github.com/globalsign/mgo/bson"
+ "runtime/debug"
+ "time"
+)
+
+type Project struct {
+ Id bson.ObjectId `json:"_id" bson:"_id"`
+ Name string `json:"name" bson:"name"`
+ Description string `json:"description" bson:"description"`
+ Tags []string `json:"tags" bson:"tags"`
+
+ CreateTs time.Time `json:"create_ts" bson:"create_ts"`
+ UpdateTs time.Time `json:"update_ts" bson:"update_ts"`
+
+ // 前端展示
+ Spiders []Spider `json:"spiders" bson:"spiders"`
+}
+
+func (p *Project) Save() error {
+ s, c := database.GetCol("projects")
+ defer s.Close()
+
+ p.UpdateTs = time.Now()
+
+ if err := c.UpdateId(p.Id, p); err != nil {
+ debug.PrintStack()
+ return err
+ }
+ return nil
+}
+
+func (p *Project) Add() error {
+ s, c := database.GetCol("projects")
+ defer s.Close()
+
+ p.Id = bson.NewObjectId()
+ p.UpdateTs = time.Now()
+ p.CreateTs = time.Now()
+ if err := c.Insert(p); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return err
+ }
+
+ return nil
+}
+
+func (p *Project) GetSpiders() ([]Spider, error) {
+ s, c := database.GetCol("spiders")
+ defer s.Close()
+
+ var query interface{}
+ if p.Id.Hex() == constants.ObjectIdNull {
+ query = bson.M{
+ "$or": []bson.M{
+ {"project_id": p.Id},
+ {"project_id": bson.M{"$exists": false}},
+ },
+ }
+ } else {
+ query = bson.M{"project_id": p.Id}
+ }
+
+ var spiders []Spider
+ if err := c.Find(query).All(&spiders); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return spiders, err
+ }
+
+ return spiders, nil
+}
+
+func GetProject(id bson.ObjectId) (Project, error) {
+ s, c := database.GetCol("projects")
+ defer s.Close()
+ var p Project
+ if err := c.Find(bson.M{"_id": id}).One(&p); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return p, err
+ }
+ return p, nil
+}
+
+func GetProjectList(filter interface{}, skip int, sortKey string) ([]Project, error) {
+ s, c := database.GetCol("projects")
+ defer s.Close()
+
+ var projects []Project
+ if err := c.Find(filter).Skip(skip).Limit(constants.Infinite).Sort(sortKey).All(&projects); err != nil {
+ debug.PrintStack()
+ return projects, err
+ }
+ return projects, nil
+}
+
+func GetProjectListTotal(filter interface{}) (int, error) {
+ s, c := database.GetCol("projects")
+ defer s.Close()
+
+ var result int
+ result, err := c.Find(filter).Count()
+ if err != nil {
+ return result, err
+ }
+ return result, nil
+}
+
+func UpdateProject(id bson.ObjectId, item Project) error {
+ s, c := database.GetCol("projects")
+ defer s.Close()
+
+ var result Project
+ if err := c.FindId(id).One(&result); err != nil {
+ debug.PrintStack()
+ return err
+ }
+
+ if err := item.Save(); err != nil {
+ return err
+ }
+ return nil
+}
+
+func RemoveProject(id bson.ObjectId) error {
+ s, c := database.GetCol("projects")
+ defer s.Close()
+
+ var result User
+ if err := c.FindId(id).One(&result); err != nil {
+ return err
+ }
+
+ if err := c.RemoveId(id); err != nil {
+ return err
+ }
+
+ return nil
+}
diff --git a/backend/model/schedule.go b/backend/model/schedule.go
index ef758fb6..d98dabf6 100644
--- a/backend/model/schedule.go
+++ b/backend/model/schedule.go
@@ -12,19 +12,23 @@ import (
)
type Schedule struct {
- Id bson.ObjectId `json:"_id" bson:"_id"`
- Name string `json:"name" bson:"name"`
- Description string `json:"description" bson:"description"`
- SpiderId bson.ObjectId `json:"spider_id" bson:"spider_id"`
- NodeId bson.ObjectId `json:"node_id" bson:"node_id"`
- NodeKey string `json:"node_key" bson:"node_key"`
- Cron string `json:"cron" bson:"cron"`
- EntryId cron.EntryID `json:"entry_id" bson:"entry_id"`
- Param string `json:"param" bson:"param"`
+ Id bson.ObjectId `json:"_id" bson:"_id"`
+ Name string `json:"name" bson:"name"`
+ Description string `json:"description" bson:"description"`
+ SpiderId bson.ObjectId `json:"spider_id" bson:"spider_id"`
+ Cron string `json:"cron" bson:"cron"`
+ EntryId cron.EntryID `json:"entry_id" bson:"entry_id"`
+ Param string `json:"param" bson:"param"`
+ RunType string `json:"run_type" bson:"run_type"`
+ NodeIds []bson.ObjectId `json:"node_ids" bson:"node_ids"`
+ Status string `json:"status" bson:"status"`
+ Enabled bool `json:"enabled" bson:"enabled"`
+ UserId bson.ObjectId `json:"user_id" bson:"user_id"`
// 前端展示
SpiderName string `json:"spider_name" bson:"spider_name"`
- NodeName string `json:"node_name" bson:"node_name"`
+ Nodes []Node `json:"nodes" bson:"nodes"`
+ Message string `json:"message" bson:"message"`
CreateTs time.Time `json:"create_ts" bson:"create_ts"`
UpdateTs time.Time `json:"update_ts" bson:"update_ts"`
@@ -46,27 +50,6 @@ func (sch *Schedule) Delete() error {
return c.RemoveId(sch.Id)
}
-func (sch *Schedule) SyncNodeIdAndSpiderId(node Node, spider Spider) {
- sch.syncNodeId(node)
- sch.syncSpiderId(spider)
-}
-
-func (sch *Schedule) syncNodeId(node Node) {
- if node.Id.Hex() == sch.NodeId.Hex() {
- return
- }
- sch.NodeId = node.Id
- _ = sch.Save()
-}
-
-func (sch *Schedule) syncSpiderId(spider Spider) {
- if spider.Id.Hex() == sch.SpiderId.Hex() {
- return
- }
- sch.SpiderId = spider.Id
- _ = sch.Save()
-}
-
func GetScheduleList(filter interface{}) ([]Schedule, error) {
s, c := database.GetCol("schedules")
defer s.Close()
@@ -79,28 +62,25 @@ func GetScheduleList(filter interface{}) ([]Schedule, error) {
var schs []Schedule
for _, schedule := range schedules {
// 获取节点名称
- if schedule.NodeId == bson.ObjectIdHex(constants.ObjectIdNull) {
- // 选择所有节点
- schedule.NodeName = "All Nodes"
- } else {
- // 选择单一节点
- node, err := GetNode(schedule.NodeId)
- if err != nil {
- log.Errorf(err.Error())
- continue
+ schedule.Nodes = []Node{}
+ if schedule.RunType == constants.RunTypeSelectedNodes {
+ for _, nodeId := range schedule.NodeIds {
+ // 选择单一节点
+ node, _ := GetNode(nodeId)
+ schedule.Nodes = append(schedule.Nodes, node)
}
- schedule.NodeName = node.Name
}
// 获取爬虫名称
spider, err := GetSpider(schedule.SpiderId)
if err != nil && err == mgo.ErrNotFound {
log.Errorf("get spider by id: %s, error: %s", schedule.SpiderId.Hex(), err.Error())
- debug.PrintStack()
- _ = schedule.Delete()
- continue
+ schedule.Status = constants.ScheduleStatusError
+ schedule.Message = constants.ScheduleStatusErrorNotFoundSpider
+ } else {
+ schedule.SpiderName = spider.Name
}
- schedule.SpiderName = spider.Name
+
schs = append(schs, schedule)
}
return schs, nil
@@ -125,12 +105,8 @@ func UpdateSchedule(id bson.ObjectId, item Schedule) error {
if err := c.FindId(id).One(&result); err != nil {
return err
}
- node, err := GetNode(item.NodeId)
- if err != nil {
- return err
- }
- item.NodeKey = node.Key
+ item.UpdateTs = time.Now()
if err := item.Save(); err != nil {
return err
}
@@ -141,15 +117,9 @@ func AddSchedule(item Schedule) error {
s, c := database.GetCol("schedules")
defer s.Close()
- node, err := GetNode(item.NodeId)
- if err != nil {
- return err
- }
-
item.Id = bson.NewObjectId()
item.CreateTs = time.Now()
item.UpdateTs = time.Now()
- item.NodeKey = node.Key
if err := c.Insert(&item); err != nil {
debug.PrintStack()
diff --git a/backend/model/spider.go b/backend/model/spider.go
index 5c2c92e8..2baeb6ed 100644
--- a/backend/model/spider.go
+++ b/backend/model/spider.go
@@ -1,11 +1,17 @@
package model
import (
+ "crawlab/constants"
"crawlab/database"
"crawlab/entity"
+ "crawlab/utils"
+ "errors"
"github.com/apex/log"
"github.com/globalsign/mgo"
"github.com/globalsign/mgo/bson"
+ "gopkg.in/yaml.v2"
+ "io/ioutil"
+ "path/filepath"
"runtime/debug"
"time"
)
@@ -25,25 +31,21 @@ type Spider struct {
Site string `json:"site" bson:"site"` // 爬虫网站
Envs []Env `json:"envs" bson:"envs"` // 环境变量
Remark string `json:"remark" bson:"remark"` // 备注
+ Src string `json:"src" bson:"src"` // 源码位置
+ ProjectId bson.ObjectId `json:"project_id" bson:"project_id"` // 项目ID
+
// 自定义爬虫
- Src string `json:"src" bson:"src"` // 源码位置
Cmd string `json:"cmd" bson:"cmd"` // 执行命令
+ // 可配置爬虫
+ Template string `json:"template" bson:"template"` // Spiderfile模版
+
// 前端展示
- LastRunTs time.Time `json:"last_run_ts"` // 最后一次执行时间
- LastStatus string `json:"last_status"` // 最后执行状态
-
- // TODO: 可配置爬虫
- //Fields []interface{} `json:"fields"`
- //DetailFields []interface{} `json:"detail_fields"`
- //CrawlType string `json:"crawl_type"`
- //StartUrl string `json:"start_url"`
- //UrlPattern string `json:"url_pattern"`
- //ItemSelector string `json:"item_selector"`
- //ItemSelectorType string `json:"item_selector_type"`
- //PaginationSelector string `json:"pagination_selector"`
- //PaginationSelectorType string `json:"pagination_selector_type"`
+ LastRunTs time.Time `json:"last_run_ts"` // 最后一次执行时间
+ LastStatus string `json:"last_status"` // 最后执行状态
+ Config entity.ConfigSpiderData `json:"config"` // 可配置爬虫配置
+ // 时间
CreateTs time.Time `json:"create_ts" bson:"create_ts"`
UpdateTs time.Time `json:"update_ts" bson:"update_ts"`
}
@@ -55,6 +57,11 @@ func (spider *Spider) Save() error {
spider.UpdateTs = time.Now()
+ // 兼容没有项目ID的爬虫
+ if spider.ProjectId.Hex() == "" {
+ spider.ProjectId = bson.ObjectIdHex(constants.ObjectIdNull)
+ }
+
if err := c.UpdateId(spider.Id, spider); err != nil {
debug.PrintStack()
return err
@@ -98,24 +105,29 @@ func (spider *Spider) GetLastTask() (Task, error) {
return tasks[0], nil
}
+// 删除爬虫
func (spider *Spider) Delete() error {
s, c := database.GetCol("spiders")
defer s.Close()
return c.RemoveId(spider.Id)
}
-// 爬虫列表
-func GetSpiderList(filter interface{}, skip int, limit int) ([]Spider, int, error) {
+// 获取爬虫列表
+func GetSpiderList(filter interface{}, skip int, limit int, sortStr string) ([]Spider, int, error) {
s, c := database.GetCol("spiders")
defer s.Close()
// 获取爬虫列表
var spiders []Spider
- if err := c.Find(filter).Skip(skip).Limit(limit).Sort("+name").All(&spiders); err != nil {
+ if err := c.Find(filter).Skip(skip).Limit(limit).Sort(sortStr).All(&spiders); err != nil {
debug.PrintStack()
return spiders, 0, err
}
+ if spiders == nil {
+ spiders = []Spider{}
+ }
+
// 遍历爬虫列表
for i, spider := range spiders {
// 获取最后一次任务
@@ -136,7 +148,7 @@ func GetSpiderList(filter interface{}, skip int, limit int) ([]Spider, int, erro
return spiders, count, nil
}
-// 获取爬虫
+// 获取爬虫(根据FileId)
func GetSpiderByFileId(fileId bson.ObjectId) *Spider {
s, c := database.GetCol("spiders")
defer s.Close()
@@ -150,34 +162,44 @@ func GetSpiderByFileId(fileId bson.ObjectId) *Spider {
return result
}
-// 获取爬虫
-func GetSpiderByName(name string) *Spider {
- s, c := database.GetCol("spiders")
- defer s.Close()
-
- var result *Spider
- if err := c.Find(bson.M{"name": name}).One(&result); err != nil {
- log.Errorf("get spider error: %s, spider_name: %s", err.Error(), name)
- debug.PrintStack()
- return nil
- }
- return result
-}
-
-// 获取爬虫
-func GetSpider(id bson.ObjectId) (Spider, error) {
+// 获取爬虫(根据名称)
+func GetSpiderByName(name string) Spider {
s, c := database.GetCol("spiders")
defer s.Close()
var result Spider
- if err := c.FindId(id).One(&result); err != nil {
+ if err := c.Find(bson.M{"name": name}).One(&result); err != nil && err != mgo.ErrNotFound {
+ log.Errorf("get spider error: %s, spider_name: %s", err.Error(), name)
+ //debug.PrintStack()
+ return result
+ }
+ return result
+}
+
+// 获取爬虫(根据ID)
+func GetSpider(id bson.ObjectId) (Spider, error) {
+ s, c := database.GetCol("spiders")
+ defer s.Close()
+
+ // 获取爬虫
+ var spider Spider
+ if err := c.FindId(id).One(&spider); err != nil {
if err != mgo.ErrNotFound {
log.Errorf("get spider error: %s, id: %id", err.Error(), id.Hex())
debug.PrintStack()
}
- return result, err
+ return spider, err
}
- return result, nil
+
+ // 如果为可配置爬虫,获取爬虫配置
+ if spider.Type == constants.Configurable && utils.Exists(filepath.Join(spider.Src, "Spiderfile")) {
+ config, err := GetConfigSpiderData(spider)
+ if err != nil {
+ return spider, err
+ }
+ spider.Config = config
+ }
+ return spider, nil
}
// 更新爬虫
@@ -217,10 +239,12 @@ func RemoveSpider(id bson.ObjectId) error {
s, gf := database.GetGridFs("files")
defer s.Close()
- if err := gf.RemoveId(result.FileId); err != nil {
- log.Error("remove file error, id:" + result.FileId.Hex())
- debug.PrintStack()
- return err
+ if result.FileId.Hex() != constants.ObjectIdNull {
+ if err := gf.RemoveId(result.FileId); err != nil {
+ log.Error("remove file error, id:" + result.FileId.Hex())
+ debug.PrintStack()
+ return err
+ }
}
return nil
@@ -245,7 +269,7 @@ func RemoveAllSpider() error {
return nil
}
-// 爬虫总数
+// 获取爬虫总数
func GetSpiderCount() (int, error) {
s, c := database.GetCol("spiders")
defer s.Close()
@@ -257,23 +281,29 @@ func GetSpiderCount() (int, error) {
return count, nil
}
-// 爬虫类型
-func GetSpiderTypes() ([]*entity.SpiderType, error) {
- s, c := database.GetCol("spiders")
- defer s.Close()
+// 获取爬虫定时任务
+func GetConfigSpiderData(spider Spider) (entity.ConfigSpiderData, error) {
+ // 构造配置数据
+ configData := entity.ConfigSpiderData{}
- group := bson.M{
- "$group": bson.M{
- "_id": "$type",
- "count": bson.M{"$sum": 1},
- },
- }
- var types []*entity.SpiderType
- if err := c.Pipe([]bson.M{group}).All(&types); err != nil {
- log.Errorf("get spider types error: %s", err.Error())
- debug.PrintStack()
- return nil, err
+ // 校验爬虫类别
+ if spider.Type != constants.Configurable {
+ return configData, errors.New("not a configurable spider")
}
- return types, nil
+ // Spiderfile 目录
+ sfPath := filepath.Join(spider.Src, "Spiderfile")
+
+ // 读取YAML文件
+ yamlFile, err := ioutil.ReadFile(sfPath)
+ if err != nil {
+ return configData, err
+ }
+
+ // 反序列化
+ if err := yaml.Unmarshal(yamlFile, &configData); err != nil {
+ return configData, err
+ }
+
+ return configData, nil
}
diff --git a/backend/model/task.go b/backend/model/task.go
index 64f06cd7..abb5ffc5 100644
--- a/backend/model/task.go
+++ b/backend/model/task.go
@@ -25,6 +25,7 @@ type Task struct {
RuntimeDuration float64 `json:"runtime_duration" bson:"runtime_duration"`
TotalDuration float64 `json:"total_duration" bson:"total_duration"`
Pid int `json:"pid" bson:"pid"`
+ UserId bson.ObjectId `json:"user_id" bson:"user_id"`
// 前端数据
SpiderName string `json:"spider_name"`
@@ -61,6 +62,7 @@ func (t *Task) Save() error {
defer s.Close()
t.UpdateTs = time.Now()
if err := c.UpdateId(t.Id, t); err != nil {
+ log.Errorf("update task error: %s", err.Error())
debug.PrintStack()
return err
}
@@ -93,7 +95,7 @@ func (t *Task) GetResults(pageNum int, pageSize int) (results []interface{}, tot
query := bson.M{
"task_id": t.Id,
}
- if err = c.Find(query).Skip((pageNum - 1) * pageSize).Limit(pageSize).Sort("-create_ts").All(&results); err != nil {
+ if err = c.Find(query).Skip((pageNum - 1) * pageSize).Limit(pageSize).All(&results); err != nil {
return
}
@@ -116,18 +118,12 @@ func GetTaskList(filter interface{}, skip int, limit int, sortKey string) ([]Tas
for i, task := range tasks {
// 获取爬虫名称
- spider, err := task.GetSpider()
- if err != nil || spider.Id.Hex() == "" {
- _ = spider.Delete()
- } else {
+ if spider, err := task.GetSpider(); err == nil {
tasks[i].SpiderName = spider.DisplayName
}
// 获取节点名称
- node, err := task.GetNode()
- if node.Id.Hex() == "" || err != nil {
- _ = task.Delete()
- } else {
+ if node, err := task.GetNode(); err == nil {
tasks[i].NodeName = node.Name
}
}
@@ -141,6 +137,8 @@ func GetTaskListTotal(filter interface{}) (int, error) {
var result int
result, err := c.Find(filter).Count()
if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
return result, err
}
return result, nil
@@ -152,6 +150,7 @@ func GetTask(id string) (Task, error) {
var task Task
if err := c.FindId(id).One(&task); err != nil {
+ log.Infof("get task error: %s, id: %s", err.Error(), id)
debug.PrintStack()
return task, err
}
@@ -166,6 +165,8 @@ func AddTask(item Task) error {
item.UpdateTs = time.Now()
if err := c.Insert(&item); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
return err
}
return nil
@@ -177,6 +178,8 @@ func RemoveTask(id string) error {
var result Task
if err := c.FindId(id).One(&result); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
return err
}
@@ -187,6 +190,20 @@ func RemoveTask(id string) error {
return nil
}
+func RemoveTaskByStatus(status string) error {
+ tasks, err := GetTaskList(bson.M{"status": status}, 0, constants.Infinite, "-create_ts")
+ if err != nil {
+ log.Error("get tasks error:" + err.Error())
+ }
+ for _, task := range tasks {
+ if err := RemoveTask(task.Id); err != nil {
+ log.Error("remove task error:" + err.Error())
+ continue
+ }
+ }
+ return nil
+}
+
// 删除task by spider_id
func RemoveTaskBySpiderId(id bson.ObjectId) error {
tasks, err := GetTaskList(bson.M{"spider_id": id}, 0, constants.Infinite, "-create_ts")
diff --git a/backend/model/user.go b/backend/model/user.go
index 19313e97..9dadec0f 100644
--- a/backend/model/user.go
+++ b/backend/model/user.go
@@ -16,11 +16,20 @@ type User struct {
Username string `json:"username" bson:"username"`
Password string `json:"password" bson:"password"`
Role string `json:"role" bson:"role"`
+ Email string `json:"email" bson:"email"`
+ Setting UserSetting `json:"setting" bson:"setting"`
CreateTs time.Time `json:"create_ts" bson:"create_ts"`
UpdateTs time.Time `json:"update_ts" bson:"update_ts"`
}
+type UserSetting struct {
+ NotificationTrigger string `json:"notification_trigger" bson:"notification_trigger"`
+ DingTalkRobotWebhook string `json:"ding_talk_robot_webhook" bson:"ding_talk_robot_webhook"`
+ WechatRobotWebhook string `json:"wechat_robot_webhook" bson:"wechat_robot_webhook"`
+ EnabledNotifications []string `json:"enabled_notifications" bson:"enabled_notifications"`
+}
+
func (user *User) Save() error {
s, c := database.GetCol("users")
defer s.Close()
diff --git a/backend/model/variable.go b/backend/model/variable.go
new file mode 100644
index 00000000..3af2188e
--- /dev/null
+++ b/backend/model/variable.go
@@ -0,0 +1,97 @@
+package model
+
+import (
+ "crawlab/database"
+ "errors"
+ "github.com/apex/log"
+ "github.com/globalsign/mgo/bson"
+ "runtime/debug"
+)
+
+/**
+全局变量
+*/
+
+type Variable struct {
+ Id bson.ObjectId `json:"_id" bson:"_id"`
+ Key string `json:"key" bson:"key"`
+ Value string `json:"value" bson:"value"`
+ Remark string `json:"remark" bson:"remark"`
+}
+
+func (model *Variable) Save() error {
+ s, c := database.GetCol("variable")
+ defer s.Close()
+
+ if err := c.UpdateId(model.Id, model); err != nil {
+ log.Errorf("update variable error: %s", err.Error())
+ return err
+ }
+ return nil
+}
+
+func (model *Variable) Add() error {
+ s, c := database.GetCol("variable")
+ defer s.Close()
+
+ // key 去重
+ _, err := GetByKey(model.Key)
+ if err == nil {
+ return errors.New("key already exists")
+ }
+
+ model.Id = bson.NewObjectId()
+ if err := c.Insert(model); err != nil {
+ log.Errorf("add variable error: %s", err.Error())
+ debug.PrintStack()
+ return err
+ }
+ return nil
+}
+
+func (model *Variable) Delete() error {
+ s, c := database.GetCol("variable")
+ defer s.Close()
+
+ if err := c.RemoveId(model.Id); err != nil {
+ log.Errorf("remove variable error: %s", err.Error())
+ debug.PrintStack()
+ return err
+ }
+ return nil
+}
+
+func GetByKey(key string) (Variable, error) {
+ s, c := database.GetCol("variable")
+ defer s.Close()
+
+ var model Variable
+ if err := c.Find(bson.M{"key": key}).One(&model); err != nil {
+ log.Errorf("variable found error: %s, key: %s", err.Error(), key)
+ return model, err
+ }
+ return model, nil
+}
+
+func GetVariable(id bson.ObjectId) (Variable, error) {
+ s, c := database.GetCol("variable")
+ defer s.Close()
+
+ var model Variable
+ if err := c.FindId(id).One(&model); err != nil {
+ log.Errorf("variable found error: %s", err.Error())
+ return model, err
+ }
+ return model, nil
+}
+
+func GetVariableList() []Variable {
+ s, c := database.GetCol("variable")
+ defer s.Close()
+
+ var list []Variable
+ if err := c.Find(nil).All(&list); err != nil {
+
+ }
+ return list
+}
diff --git a/backend/routes/config_spider.go b/backend/routes/config_spider.go
new file mode 100644
index 00000000..ac6a11e0
--- /dev/null
+++ b/backend/routes/config_spider.go
@@ -0,0 +1,316 @@
+package routes
+
+import (
+ "crawlab/constants"
+ "crawlab/entity"
+ "crawlab/model"
+ "crawlab/services"
+ "crawlab/utils"
+ "fmt"
+ "github.com/gin-gonic/gin"
+ "github.com/globalsign/mgo/bson"
+ "github.com/spf13/viper"
+ "gopkg.in/yaml.v2"
+ "io"
+ "io/ioutil"
+ "net/http"
+ "os"
+ "path/filepath"
+ "strings"
+)
+
+// 添加可配置爬虫
+func PutConfigSpider(c *gin.Context) {
+ var spider model.Spider
+ if err := c.ShouldBindJSON(&spider); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ // 爬虫名称不能为空
+ if spider.Name == "" {
+ HandleErrorF(http.StatusBadRequest, c, "spider name should not be empty")
+ return
+ }
+
+ // 模版名不能为空
+ if spider.Template == "" {
+ HandleErrorF(http.StatusBadRequest, c, "spider template should not be empty")
+ return
+ }
+
+ // 判断爬虫是否存在
+ if spider := model.GetSpiderByName(spider.Name); spider.Name != "" {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("spider for '%s' already exists", spider.Name))
+ return
+ }
+
+ // 设置爬虫类别
+ spider.Type = constants.Configurable
+
+ // 将FileId置空
+ spider.FileId = bson.ObjectIdHex(constants.ObjectIdNull)
+
+ // 创建爬虫目录
+ spiderDir := filepath.Join(viper.GetString("spider.path"), spider.Name)
+ if utils.Exists(spiderDir) {
+ if err := os.RemoveAll(spiderDir); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ if err := os.MkdirAll(spiderDir, 0777); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ spider.Src = spiderDir
+
+ // 复制Spiderfile模版
+ contentByte, err := ioutil.ReadFile("./template/spiderfile/Spiderfile." + spider.Template)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ f, err := os.Create(filepath.Join(spider.Src, "Spiderfile"))
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ defer f.Close()
+ if _, err := f.Write(contentByte); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 添加爬虫到数据库
+ if err := spider.Add(); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: spider,
+ })
+}
+
+// 更改可配置爬虫
+func PostConfigSpider(c *gin.Context) {
+ PostSpider(c)
+}
+
+// 上传可配置爬虫Spiderfile
+func UploadConfigSpider(c *gin.Context) {
+ id := c.Param("id")
+
+ // 获取爬虫
+ var spider model.Spider
+ spider, err := model.GetSpider(bson.ObjectIdHex(id))
+ if err != nil {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("cannot find spider (id: %s)", id))
+ }
+
+ // 获取上传文件
+ file, header, err := c.Request.FormFile("file")
+ if err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ // 文件名称必须为Spiderfile
+ filename := header.Filename
+ if filename != "Spiderfile" && filename != "Spiderfile.yaml" && filename != "Spiderfile.yml" {
+ HandleErrorF(http.StatusBadRequest, c, "filename must be 'Spiderfile(.yaml|.yml)'")
+ return
+ }
+
+ // 爬虫目录
+ spiderDir := filepath.Join(viper.GetString("spider.path"), spider.Name)
+
+ // 爬虫Spiderfile文件路径
+ sfPath := filepath.Join(spiderDir, filename)
+
+ // 创建(如果不存在)或打开Spiderfile(如果存在)
+ var f *os.File
+ if utils.Exists(sfPath) {
+ f, err = os.OpenFile(sfPath, os.O_WRONLY, 0777)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ }
+ } else {
+ f, err = os.Create(sfPath)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ }
+ }
+
+ // 将上传的文件拷贝到爬虫Spiderfile文件
+ _, err = io.Copy(f, file)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 关闭Spiderfile文件
+ _ = f.Close()
+
+ // 构造配置数据
+ configData := entity.ConfigSpiderData{}
+
+ // 读取YAML文件
+ yamlFile, err := ioutil.ReadFile(sfPath)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 反序列化
+ if err := yaml.Unmarshal(yamlFile, &configData); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 根据序列化后的数据处理爬虫文件
+ if err := services.ProcessSpiderFilesFromConfigData(spider, configData); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func PostConfigSpiderSpiderfile(c *gin.Context) {
+ type Body struct {
+ Content string `json:"content"`
+ }
+
+ id := c.Param("id")
+
+ // 文件内容
+ var reqBody Body
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+ content := reqBody.Content
+
+ // 获取爬虫
+ var spider model.Spider
+ spider, err := model.GetSpider(bson.ObjectIdHex(id))
+ if err != nil {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("cannot find spider (id: %s)", id))
+ return
+ }
+
+ // 反序列化
+ var configData entity.ConfigSpiderData
+ if err := yaml.Unmarshal([]byte(content), &configData); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ // 校验configData
+ if err := services.ValidateSpiderfile(configData); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 写文件
+ if err := ioutil.WriteFile(filepath.Join(spider.Src, "Spiderfile"), []byte(content), os.ModePerm); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 根据序列化后的数据处理爬虫文件
+ if err := services.ProcessSpiderFilesFromConfigData(spider, configData); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func PostConfigSpiderConfig(c *gin.Context) {
+ id := c.Param("id")
+
+ // 获取爬虫
+ var spider model.Spider
+ spider, err := model.GetSpider(bson.ObjectIdHex(id))
+ if err != nil {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("cannot find spider (id: %s)", id))
+ return
+ }
+
+ // 反序列化配置数据
+ var configData entity.ConfigSpiderData
+ if err := c.ShouldBindJSON(&configData); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ // 校验configData
+ if err := services.ValidateSpiderfile(configData); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 替换Spiderfile文件
+ if err := services.GenerateSpiderfileFromConfigData(spider, configData); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 根据序列化后的数据处理爬虫文件
+ if err := services.ProcessSpiderFilesFromConfigData(spider, configData); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func GetConfigSpiderConfig(c *gin.Context) {
+ id := c.Param("id")
+
+ // 校验ID
+ if !bson.IsObjectIdHex(id) {
+ HandleErrorF(http.StatusBadRequest, c, "invalid id")
+ }
+
+ // 获取爬虫
+ spider, err := model.GetSpider(bson.ObjectIdHex(id))
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: spider.Config,
+ })
+}
+
+// 获取模版名称列表
+func GetConfigSpiderTemplateList(c *gin.Context) {
+ var data []string
+ for _, fInfo := range utils.ListDir("./template/spiderfile") {
+ templateName := strings.Replace(fInfo.Name(), "Spiderfile.", "", -1)
+ data = append(data, templateName)
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: data,
+ })
+}
diff --git a/backend/routes/projects.go b/backend/routes/projects.go
new file mode 100644
index 00000000..34b2d7f4
--- /dev/null
+++ b/backend/routes/projects.go
@@ -0,0 +1,190 @@
+package routes
+
+import (
+ "crawlab/constants"
+ "crawlab/database"
+ "crawlab/model"
+ "github.com/gin-gonic/gin"
+ "github.com/globalsign/mgo/bson"
+ "net/http"
+)
+
+func GetProjectList(c *gin.Context) {
+ tag := c.Query("tag")
+
+ // 筛选条件
+ query := bson.M{}
+ if tag != "" {
+ query["tags"] = tag
+ }
+
+ // 获取列表
+ projects, err := model.GetProjectList(query, 0, "+_id")
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 获取总数
+ total, err := model.GetProjectListTotal(query)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 获取每个项目的爬虫列表
+ for i, p := range projects {
+ spiders, err := p.GetSpiders()
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ projects[i].Spiders = spiders
+ }
+
+ // 获取未被分配的爬虫数量
+ if tag == "" {
+ noProject := model.Project{
+ Id: bson.ObjectIdHex(constants.ObjectIdNull),
+ Name: "No Project",
+ Description: "Not assigned to any project",
+ }
+ spiders, err := noProject.GetSpiders()
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ noProject.Spiders = spiders
+ projects = append(projects, noProject)
+ }
+
+ c.JSON(http.StatusOK, ListResponse{
+ Status: "ok",
+ Message: "success",
+ Data: projects,
+ Total: total,
+ })
+}
+
+func PutProject(c *gin.Context) {
+ // 绑定请求数据
+ var p model.Project
+ if err := c.ShouldBindJSON(&p); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ if err := p.Add(); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func PostProject(c *gin.Context) {
+ id := c.Param("id")
+
+ if !bson.IsObjectIdHex(id) {
+ HandleErrorF(http.StatusBadRequest, c, "invalid id")
+ }
+
+ var item model.Project
+ if err := c.ShouldBindJSON(&item); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ if err := model.UpdateProject(bson.ObjectIdHex(id), item); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func DeleteProject(c *gin.Context) {
+ id := c.Param("id")
+
+ if !bson.IsObjectIdHex(id) {
+ HandleErrorF(http.StatusBadRequest, c, "invalid id")
+ return
+ }
+
+ // 从数据库中删除该爬虫
+ if err := model.RemoveProject(bson.ObjectIdHex(id)); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 获取相关的爬虫
+ var spiders []model.Spider
+ s, col := database.GetCol("spiders")
+ defer s.Close()
+ if err := col.Find(bson.M{"project_id": bson.ObjectIdHex(id)}).All(&spiders); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 将爬虫的项目ID置空
+ for _, spider := range spiders {
+ spider.ProjectId = bson.ObjectIdHex(constants.ObjectIdNull)
+ if err := spider.Save(); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func GetProjectTags(c *gin.Context) {
+ type Result struct {
+ Tag string `json:"tag" bson:"tag"`
+ }
+
+ s, col := database.GetCol("projects")
+ defer s.Close()
+
+ pipeline := []bson.M{
+ {
+ "$unwind": "$tags",
+ },
+ {
+ "$group": bson.M{
+ "_id": "$tags",
+ },
+ },
+ {
+ "$sort": bson.M{
+ "_id": 1,
+ },
+ },
+ {
+ "$addFields": bson.M{
+ "tag": "$_id",
+ },
+ },
+ }
+
+ var items []Result
+ if err := col.Pipe(pipeline).All(&items); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: items,
+ })
+}
diff --git a/backend/routes/schedule.go b/backend/routes/schedule.go
index 73b75323..3776019c 100644
--- a/backend/routes/schedule.go
+++ b/backend/routes/schedule.go
@@ -14,11 +14,7 @@ func GetScheduleList(c *gin.Context) {
HandleError(http.StatusInternalServerError, c, err)
return
}
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- Data: results,
- })
+ HandleSuccessData(c, results)
}
func GetSchedule(c *gin.Context) {
@@ -29,11 +25,8 @@ func GetSchedule(c *gin.Context) {
HandleError(http.StatusInternalServerError, c, err)
return
}
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- Data: result,
- })
+
+ HandleSuccessData(c, result)
}
func PostSchedule(c *gin.Context) {
@@ -48,7 +41,7 @@ func PostSchedule(c *gin.Context) {
// 验证cron表达式
if err := services.ParserCron(newItem.Cron); err != nil {
- HandleError(http.StatusOK, c, err)
+ HandleError(http.StatusInternalServerError, c, err)
return
}
@@ -65,10 +58,7 @@ func PostSchedule(c *gin.Context) {
return
}
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- })
+ HandleSuccess(c)
}
func PutSchedule(c *gin.Context) {
@@ -82,10 +72,13 @@ func PutSchedule(c *gin.Context) {
// 验证cron表达式
if err := services.ParserCron(item.Cron); err != nil {
- HandleError(http.StatusOK, c, err)
+ HandleError(http.StatusInternalServerError, c, err)
return
}
+ // 加入用户ID
+ item.UserId = services.GetCurrentUser(c).Id
+
// 更新数据库
if err := model.AddSchedule(item); err != nil {
HandleError(http.StatusInternalServerError, c, err)
@@ -98,10 +91,7 @@ func PutSchedule(c *gin.Context) {
return
}
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- })
+ HandleSuccess(c)
}
func DeleteSchedule(c *gin.Context) {
@@ -119,8 +109,25 @@ func DeleteSchedule(c *gin.Context) {
return
}
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- })
+ HandleSuccess(c)
+}
+
+// 停止定时任务
+func DisableSchedule(c *gin.Context) {
+ id := c.Param("id")
+ if err := services.Sched.Disable(bson.ObjectIdHex(id)); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ HandleSuccess(c)
+}
+
+// 运行定时任务
+func EnableSchedule(c *gin.Context) {
+ id := c.Param("id")
+ if err := services.Sched.Enable(bson.ObjectIdHex(id)); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ HandleSuccess(c)
}
diff --git a/backend/routes/setting.go b/backend/routes/setting.go
new file mode 100644
index 00000000..4429873e
--- /dev/null
+++ b/backend/routes/setting.go
@@ -0,0 +1,33 @@
+package routes
+
+import (
+ "github.com/gin-gonic/gin"
+ "github.com/spf13/viper"
+ "net/http"
+)
+
+type SettingBody struct {
+ AllowRegister string `json:"allow_register"`
+}
+
+func GetVersion(c *gin.Context) {
+ version := viper.GetString("version")
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: version,
+ })
+}
+
+func GetSetting(c *gin.Context) {
+ allowRegister := viper.GetString("setting.allowRegister")
+
+ body := SettingBody{AllowRegister: allowRegister}
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: body,
+ })
+}
diff --git a/backend/routes/spider.go b/backend/routes/spider.go
index 4c26fcee..2b6dfd63 100644
--- a/backend/routes/spider.go
+++ b/backend/routes/spider.go
@@ -7,6 +7,7 @@ import (
"crawlab/model"
"crawlab/services"
"crawlab/utils"
+ "fmt"
"github.com/apex/log"
"github.com/gin-gonic/gin"
"github.com/globalsign/mgo"
@@ -17,6 +18,7 @@ import (
"io/ioutil"
"net/http"
"os"
+ "path"
"path/filepath"
"runtime/debug"
"strconv"
@@ -25,22 +27,49 @@ import (
)
func GetSpiderList(c *gin.Context) {
- pageNum, _ := c.GetQuery("pageNum")
- pageSize, _ := c.GetQuery("pageSize")
+ pageNum, _ := c.GetQuery("page_num")
+ pageSize, _ := c.GetQuery("page_size")
keyword, _ := c.GetQuery("keyword")
+ pid, _ := c.GetQuery("project_id")
t, _ := c.GetQuery("type")
+ sortKey, _ := c.GetQuery("sort_key")
+ sortDirection, _ := c.GetQuery("sort_direction")
+ // 筛选
filter := bson.M{
"name": bson.M{"$regex": bson.RegEx{Pattern: keyword, Options: "im"}},
}
-
- if t != "" {
+ if t != "" && t != "all" {
filter["type"] = t
}
+ if pid == "" {
+ // do nothing
+ } else if pid == constants.ObjectIdNull {
+ filter["$or"] = []bson.M{
+ {"project_id": bson.ObjectIdHex(pid)},
+ {"project_id": bson.M{"$exists": false}},
+ }
+ } else {
+ filter["project_id"] = bson.ObjectIdHex(pid)
+ }
+ // 排序
+ sortStr := "-_id"
+ if sortKey != "" && sortDirection != "" {
+ if sortDirection == constants.DESCENDING {
+ sortStr = "-" + sortKey
+ } else if sortDirection == constants.ASCENDING {
+ sortStr = "+" + sortKey
+ } else {
+ HandleErrorF(http.StatusBadRequest, c, "invalid sort_direction")
+ }
+ }
+
+ // 分页
page := &entity.Page{}
page.GetPage(pageNum, pageSize)
- results, count, err := model.GetSpiderList(filter, page.Skip, page.Limit)
+
+ results, count, err := model.GetSpiderList(filter, page.Skip, page.Limit, sortStr)
if err != nil {
HandleError(http.StatusInternalServerError, c, err)
return
@@ -117,6 +146,64 @@ func PublishSpider(c *gin.Context) {
}
func PutSpider(c *gin.Context) {
+ var spider model.Spider
+ if err := c.ShouldBindJSON(&spider); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ // 爬虫名称不能为空
+ if spider.Name == "" {
+ HandleErrorF(http.StatusBadRequest, c, "spider name should not be empty")
+ return
+ }
+
+ // 判断爬虫是否存在
+ if spider := model.GetSpiderByName(spider.Name); spider.Name != "" {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("spider for '%s' already exists", spider.Name))
+ return
+ }
+
+ // 设置爬虫类别
+ spider.Type = constants.Customized
+
+ // 将FileId置空
+ spider.FileId = bson.ObjectIdHex(constants.ObjectIdNull)
+
+ // 创建爬虫目录
+ spiderDir := filepath.Join(viper.GetString("spider.path"), spider.Name)
+ if utils.Exists(spiderDir) {
+ if err := os.RemoveAll(spiderDir); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ if err := os.MkdirAll(spiderDir, 0777); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ spider.Src = spiderDir
+
+ // 添加爬虫到数据库
+ if err := spider.Add(); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 同步到GridFS
+ if err := services.UploadSpiderToGridFsFromMaster(spider); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: spider,
+ })
+}
+
+func UploadSpider(c *gin.Context) {
// 从body中获取文件
uploadFile, err := c.FormFile("file")
if err != nil {
@@ -125,6 +212,144 @@ func PutSpider(c *gin.Context) {
return
}
+ // 获取参数
+ name := c.PostForm("name")
+ displayName := c.PostForm("display_name")
+ col := c.PostForm("col")
+ cmd := c.PostForm("cmd")
+
+ // 如果不为zip文件,返回错误
+ if !strings.HasSuffix(uploadFile.Filename, ".zip") {
+ HandleError(http.StatusBadRequest, c, errors.New("not a valid zip file"))
+ return
+ }
+
+ // 以防tmp目录不存在
+ tmpPath := viper.GetString("other.tmppath")
+ if !utils.Exists(tmpPath) {
+ if err := os.MkdirAll(tmpPath, os.ModePerm); err != nil {
+ log.Error("mkdir other.tmppath dir error:" + err.Error())
+ debug.PrintStack()
+ HandleError(http.StatusBadRequest, c, errors.New("mkdir other.tmppath dir error"))
+ return
+ }
+ }
+
+ // 保存到本地临时文件
+ randomId := uuid.NewV4()
+ tmpFilePath := filepath.Join(tmpPath, randomId.String()+".zip")
+ if err := c.SaveUploadedFile(uploadFile, tmpFilePath); err != nil {
+ log.Error("save upload file error: " + err.Error())
+ debug.PrintStack()
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 获取 GridFS 实例
+ s, gf := database.GetGridFs("files")
+ defer s.Close()
+
+ // 判断文件是否已经存在
+ var gfFile model.GridFs
+ if err := gf.Find(bson.M{"filename": uploadFile.Filename}).One(&gfFile); err == nil {
+ // 已经存在文件,则删除
+ _ = gf.RemoveId(gfFile.Id)
+ }
+
+ // 上传到GridFs
+ fid, err := services.UploadToGridFs(uploadFile.Filename, tmpFilePath)
+ if err != nil {
+ log.Errorf("upload to grid fs error: %s", err.Error())
+ debug.PrintStack()
+ return
+ }
+
+ idx := strings.LastIndex(uploadFile.Filename, "/")
+ targetFilename := uploadFile.Filename[idx+1:]
+
+ // 判断爬虫是否存在
+ spiderName := strings.Replace(targetFilename, ".zip", "", 1)
+ if name != "" {
+ spiderName = name
+ }
+ spider := model.GetSpiderByName(spiderName)
+ if spider.Name == "" {
+ // 保存爬虫信息
+ srcPath := viper.GetString("spider.path")
+ spider := model.Spider{
+ Name: spiderName,
+ DisplayName: spiderName,
+ Type: constants.Customized,
+ Src: filepath.Join(srcPath, spiderName),
+ FileId: fid,
+ }
+ if name != "" {
+ spider.Name = name
+ }
+ if displayName != "" {
+ spider.DisplayName = displayName
+ }
+ if col != "" {
+ spider.Col = col
+ }
+ if cmd != "" {
+ spider.Cmd = cmd
+ }
+ _ = spider.Add()
+ } else {
+ if name != "" {
+ spider.Name = name
+ }
+ if displayName != "" {
+ spider.DisplayName = displayName
+ }
+ if col != "" {
+ spider.Col = col
+ }
+ if cmd != "" {
+ spider.Cmd = cmd
+ }
+ // 更新file_id
+ spider.FileId = fid
+ _ = spider.Save()
+ }
+
+ // 发起同步
+ services.PublishAllSpiders()
+
+ // 获取爬虫
+ spider = model.GetSpiderByName(spiderName)
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: spider,
+ })
+}
+
+func UploadSpiderFromId(c *gin.Context) {
+ // TODO: 与 UploadSpider 部分逻辑重复,需要优化代码
+ // 爬虫ID
+ spiderId := c.Param("id")
+
+ // 获取爬虫
+ spider, err := model.GetSpider(bson.ObjectIdHex(spiderId))
+ if err != nil {
+ if err == mgo.ErrNotFound {
+ HandleErrorF(http.StatusNotFound, c, "cannot find spider")
+ } else {
+ HandleError(http.StatusInternalServerError, c, err)
+ }
+ return
+ }
+
+ // 从body中获取文件
+ uploadFile, err := c.FormFile("file")
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
// 如果不为zip文件,返回错误
if !strings.HasSuffix(uploadFile.Filename, ".zip") {
debug.PrintStack()
@@ -153,6 +378,7 @@ func PutSpider(c *gin.Context) {
return
}
+ // 获取 GridFS 实例
s, gf := database.GetGridFs("files")
defer s.Close()
@@ -171,28 +397,12 @@ func PutSpider(c *gin.Context) {
return
}
- idx := strings.LastIndex(uploadFile.Filename, "/")
- targetFilename := uploadFile.Filename[idx+1:]
+ // 更新file_id
+ spider.FileId = fid
+ _ = spider.Save()
- // 判断爬虫是否存在
- spiderName := strings.Replace(targetFilename, ".zip", "", 1)
- spider := model.GetSpiderByName(spiderName)
- if spider == nil {
- // 保存爬虫信息
- srcPath := viper.GetString("spider.path")
- spider := model.Spider{
- Name: spiderName,
- DisplayName: spiderName,
- Type: constants.Customized,
- Src: filepath.Join(srcPath, spiderName),
- FileId: fid,
- }
- _ = spider.Add()
- } else {
- // 更新file_id
- spider.FileId = fid
- _ = spider.Save()
- }
+ // 发起同步
+ services.PublishSpider(spider)
c.JSON(http.StatusOK, Response{
Status: "ok",
@@ -241,6 +451,8 @@ func GetSpiderTasks(c *gin.Context) {
})
}
+// 爬虫文件管理
+
func GetSpiderDir(c *gin.Context) {
// 爬虫ID
id := c.Param("id")
@@ -282,6 +494,12 @@ func GetSpiderDir(c *gin.Context) {
})
}
+type SpiderFileReqBody struct {
+ Path string `json:"path"`
+ Content string `json:"content"`
+ NewPath string `json:"new_path"`
+}
+
func GetSpiderFile(c *gin.Context) {
// 爬虫ID
id := c.Param("id")
@@ -310,9 +528,34 @@ func GetSpiderFile(c *gin.Context) {
})
}
-type SpiderFileReqBody struct {
- Path string `json:"path"`
- Content string `json:"content"`
+func GetSpiderFileTree(c *gin.Context) {
+ // 爬虫ID
+ id := c.Param("id")
+
+ // 获取爬虫
+ spider, err := model.GetSpider(bson.ObjectIdHex(id))
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 获取目录下文件列表
+ spiderPath := viper.GetString("spider.path")
+ spiderFilePath := filepath.Join(spiderPath, spider.Name)
+
+ // 获取文件目录树
+ fileNodeTree, err := services.GetFileNodeTree(spiderFilePath, 0)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 返回结果
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: fileNodeTree,
+ })
}
func PostSpiderFile(c *gin.Context) {
@@ -339,6 +582,12 @@ func PostSpiderFile(c *gin.Context) {
return
}
+ // 同步到GridFS
+ if err := services.UploadSpiderToGridFsFromMaster(spider); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
// 返回结果
c.JSON(http.StatusOK, Response{
Status: "ok",
@@ -346,17 +595,158 @@ func PostSpiderFile(c *gin.Context) {
})
}
-// 爬虫类型
-func GetSpiderTypes(c *gin.Context) {
- types, err := model.GetSpiderTypes()
+func PutSpiderFile(c *gin.Context) {
+ spiderId := c.Param("id")
+ var reqBody SpiderFileReqBody
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+ spider, err := model.GetSpider(bson.ObjectIdHex(spiderId))
if err != nil {
HandleError(http.StatusInternalServerError, c, err)
return
}
+
+ // 文件路径
+ filePath := path.Join(spider.Src, reqBody.Path)
+
+ // 如果文件已存在,则报错
+ if utils.Exists(filePath) {
+ HandleErrorF(http.StatusInternalServerError, c, fmt.Sprintf(`%s already exists`, filePath))
+ return
+ }
+
+ // 写入文件
+ if err := ioutil.WriteFile(filePath, []byte(reqBody.Content), 0777); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 同步到GridFS
+ if err := services.UploadSpiderToGridFsFromMaster(spider); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func PutSpiderDir(c *gin.Context) {
+ spiderId := c.Param("id")
+ var reqBody SpiderFileReqBody
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+ spider, err := model.GetSpider(bson.ObjectIdHex(spiderId))
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 文件路径
+ filePath := path.Join(spider.Src, reqBody.Path)
+
+ // 如果文件已存在,则报错
+ if utils.Exists(filePath) {
+ HandleErrorF(http.StatusInternalServerError, c, fmt.Sprintf(`%s already exists`, filePath))
+ return
+ }
+
+ // 创建文件夹
+ if err := os.MkdirAll(filePath, 0777); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 同步到GridFS
+ if err := services.UploadSpiderToGridFsFromMaster(spider); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func DeleteSpiderFile(c *gin.Context) {
+ spiderId := c.Param("id")
+ var reqBody SpiderFileReqBody
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+ spider, err := model.GetSpider(bson.ObjectIdHex(spiderId))
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ filePath := path.Join(spider.Src, reqBody.Path)
+ if err := os.RemoveAll(filePath); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 同步到GridFS
+ if err := services.UploadSpiderToGridFsFromMaster(spider); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func RenameSpiderFile(c *gin.Context) {
+ spiderId := c.Param("id")
+ var reqBody SpiderFileReqBody
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ }
+ spider, err := model.GetSpider(bson.ObjectIdHex(spiderId))
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 原文件路径
+ filePath := path.Join(spider.Src, reqBody.Path)
+ newFilePath := path.Join(path.Join(path.Dir(filePath), reqBody.NewPath))
+
+ // 如果新文件已存在,则报错
+ if utils.Exists(newFilePath) {
+ HandleErrorF(http.StatusInternalServerError, c, fmt.Sprintf(`%s already exists`, newFilePath))
+ return
+ }
+
+ // 重命名
+ if err := os.Rename(filePath, newFilePath); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ // 删除原文件
+ if err := os.RemoveAll(filePath); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ }
+
+ // 同步到GridFS
+ if err := services.UploadSpiderToGridFsFromMaster(spider); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
c.JSON(http.StatusOK, Response{
Status: "ok",
Message: "success",
- Data: types,
})
}
@@ -479,3 +869,25 @@ func GetSpiderStats(c *gin.Context) {
},
})
}
+
+func GetSpiderSchedules(c *gin.Context) {
+ id := c.Param("id")
+
+ if !bson.IsObjectIdHex(id) {
+ HandleErrorF(http.StatusBadRequest, c, "spider_id is invalid")
+ return
+ }
+
+ // 获取定时任务
+ list, err := model.GetScheduleList(bson.M{"spider_id": bson.ObjectIdHex(id)})
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: list,
+ })
+}
diff --git a/backend/routes/system.go b/backend/routes/system.go
new file mode 100644
index 00000000..8c443d2a
--- /dev/null
+++ b/backend/routes/system.go
@@ -0,0 +1,316 @@
+package routes
+
+import (
+ "crawlab/constants"
+ "crawlab/entity"
+ "crawlab/services"
+ "fmt"
+ "github.com/gin-gonic/gin"
+ "net/http"
+ "strings"
+)
+
+func GetLangList(c *gin.Context) {
+ nodeId := c.Param("id")
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: services.GetLangList(nodeId),
+ })
+}
+
+func GetDepList(c *gin.Context) {
+ nodeId := c.Param("id")
+ lang := c.Query("lang")
+ depName := c.Query("dep_name")
+
+ var depList []entity.Dependency
+ if lang == constants.Python {
+ list, err := services.GetPythonDepList(nodeId, depName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ depList = list
+ } else if lang == constants.Nodejs {
+ list, err := services.GetNodejsDepList(nodeId, depName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ depList = list
+ } else {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("%s is not implemented", lang))
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: depList,
+ })
+}
+
+func GetInstalledDepList(c *gin.Context) {
+ nodeId := c.Param("id")
+ lang := c.Query("lang")
+ var depList []entity.Dependency
+ if lang == constants.Python {
+ if services.IsMasterNode(nodeId) {
+ list, err := services.GetPythonLocalInstalledDepList(nodeId)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ depList = list
+ } else {
+ list, err := services.GetPythonRemoteInstalledDepList(nodeId)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ depList = list
+ }
+ } else if lang == constants.Nodejs {
+ if services.IsMasterNode(nodeId) {
+ list, err := services.GetNodejsLocalInstalledDepList(nodeId)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ depList = list
+ } else {
+ list, err := services.GetNodejsRemoteInstalledDepList(nodeId)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ depList = list
+ }
+ } else {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("%s is not implemented", lang))
+ return
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: depList,
+ })
+}
+
+func GetAllDepList(c *gin.Context) {
+ lang := c.Param("lang")
+ depName := c.Query("dep_name")
+
+ // 获取所有依赖列表
+ var list []string
+ if lang == constants.Python {
+ _list, err := services.GetPythonDepListFromRedis()
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ list = _list
+ } else {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("%s is not implemented", lang))
+ return
+ }
+
+ // 过滤依赖列表
+ var depList []string
+ for _, name := range list {
+ if strings.HasPrefix(strings.ToLower(name), strings.ToLower(depName)) {
+ depList = append(depList, name)
+ }
+ }
+
+ // 只取前20
+ var returnList []string
+ for i, name := range depList {
+ if i >= 10 {
+ break
+ }
+ returnList = append(returnList, name)
+ }
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: returnList,
+ })
+}
+
+func InstallDep(c *gin.Context) {
+ type ReqBody struct {
+ Lang string `json:"lang"`
+ DepName string `json:"dep_name"`
+ }
+
+ nodeId := c.Param("id")
+
+ var reqBody ReqBody
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ if reqBody.Lang == constants.Python {
+ if services.IsMasterNode(nodeId) {
+ _, err := services.InstallPythonLocalDep(reqBody.DepName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ } else {
+ _, err := services.InstallPythonRemoteDep(nodeId, reqBody.DepName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ } else if reqBody.Lang == constants.Nodejs {
+ if services.IsMasterNode(nodeId) {
+ _, err := services.InstallNodejsLocalDep(reqBody.DepName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ } else {
+ _, err := services.InstallNodejsRemoteDep(nodeId, reqBody.DepName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ } else {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("%s is not implemented", reqBody.Lang))
+ return
+ }
+
+ // TODO: check if install is successful
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func UninstallDep(c *gin.Context) {
+ type ReqBody struct {
+ Lang string `json:"lang"`
+ DepName string `json:"dep_name"`
+ }
+
+ nodeId := c.Param("id")
+
+ var reqBody ReqBody
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ }
+
+ if reqBody.Lang == constants.Python {
+ if services.IsMasterNode(nodeId) {
+ _, err := services.UninstallPythonLocalDep(reqBody.DepName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ } else {
+ _, err := services.UninstallPythonRemoteDep(nodeId, reqBody.DepName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ } else if reqBody.Lang == constants.Nodejs {
+ if services.IsMasterNode(nodeId) {
+ _, err := services.UninstallNodejsLocalDep(reqBody.DepName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ } else {
+ _, err := services.UninstallNodejsRemoteDep(nodeId, reqBody.DepName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ } else {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("%s is not implemented", reqBody.Lang))
+ return
+ }
+
+ // TODO: check if uninstall is successful
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func GetDepJson(c *gin.Context) {
+ depName := c.Param("dep_name")
+ lang := c.Param("lang")
+
+ var dep entity.Dependency
+ if lang == constants.Python {
+ _dep, err := services.FetchPythonDepInfo(depName)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ dep = _dep
+ } else {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("%s is not implemented", lang))
+ return
+ }
+
+ c.Header("Cache-Control", "max-age=86400")
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: dep,
+ })
+}
+
+func InstallLang(c *gin.Context) {
+ type ReqBody struct {
+ Lang string `json:"lang"`
+ }
+
+ nodeId := c.Param("id")
+
+ var reqBody ReqBody
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+
+ if reqBody.Lang == constants.Nodejs {
+ if services.IsMasterNode(nodeId) {
+ _, err := services.InstallNodejsLocalLang()
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ } else {
+ _, err := services.InstallNodejsRemoteLang(nodeId)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ } else {
+ HandleErrorF(http.StatusBadRequest, c, fmt.Sprintf("%s is not implemented", reqBody.Lang))
+ return
+ }
+
+ // TODO: check if install is successful
+
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
diff --git a/backend/routes/task.go b/backend/routes/task.go
index c84ea210..07105f2d 100644
--- a/backend/routes/task.go
+++ b/backend/routes/task.go
@@ -9,7 +9,6 @@ import (
"encoding/csv"
"github.com/gin-gonic/gin"
"github.com/globalsign/mgo/bson"
- uuid "github.com/satori/go.uuid"
"net/http"
)
@@ -18,6 +17,7 @@ type TaskListRequestData struct {
PageSize int `form:"page_size"`
NodeId string `form:"node_id"`
SpiderId string `form:"spider_id"`
+ Status string `form:"status"`
}
type TaskResultsRequestData struct {
@@ -29,14 +29,14 @@ func GetTaskList(c *gin.Context) {
// 绑定数据
data := TaskListRequestData{}
if err := c.ShouldBindQuery(&data); err != nil {
- HandleError(http.StatusBadRequest, c, err)
+ HandleError(http.StatusInternalServerError, c, err)
return
}
if data.PageNum == 0 {
data.PageNum = 1
}
if data.PageSize == 0 {
- data.PageNum = 10
+ data.PageSize = 10
}
// 过滤条件
@@ -47,6 +47,10 @@ func GetTaskList(c *gin.Context) {
if data.SpiderId != "" {
query["spider_id"] = bson.ObjectIdHex(data.SpiderId)
}
+ //新增根据任务状态获取task列表
+ if data.Status != "" {
+ query["status"] = data.Status
+ }
// 获取任务列表
tasks, err := model.GetTaskList(query, (data.PageNum-1)*data.PageSize, data.PageSize, "-create_ts")
@@ -78,49 +82,117 @@ func GetTask(c *gin.Context) {
HandleError(http.StatusInternalServerError, c, err)
return
}
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- Data: result,
- })
+ HandleSuccessData(c, result)
}
func PutTask(c *gin.Context) {
- // 生成任务ID
- id := uuid.NewV4()
+ type TaskRequestBody struct {
+ SpiderId bson.ObjectId `json:"spider_id"`
+ RunType string `json:"run_type"`
+ NodeIds []bson.ObjectId `json:"node_ids"`
+ Param string `json:"param"`
+ }
// 绑定数据
- var t model.Task
- if err := c.ShouldBindJSON(&t); err != nil {
- HandleError(http.StatusBadRequest, c, err)
- return
- }
- t.Id = id.String()
- t.Status = constants.StatusPending
-
- // 如果没有传入node_id,则置为null
- if t.NodeId.Hex() == "" {
- t.NodeId = bson.ObjectIdHex(constants.ObjectIdNull)
- }
-
- // 将任务存入数据库
- if err := model.AddTask(t); err != nil {
+ var reqBody TaskRequestBody
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
HandleError(http.StatusInternalServerError, c, err)
return
}
- // 加入任务队列
- if err := services.AssignTask(t); err != nil {
- HandleError(http.StatusInternalServerError, c, err)
+ if reqBody.RunType == constants.RunTypeAllNodes {
+ // 所有节点
+ nodes, err := model.GetNodeList(nil)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ for _, node := range nodes {
+ t := model.Task{
+ SpiderId: reqBody.SpiderId,
+ NodeId: node.Id,
+ Param: reqBody.Param,
+ UserId: services.GetCurrentUser(c).Id,
+ }
+
+ if err := services.AddTask(t); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ } else if reqBody.RunType == constants.RunTypeRandom {
+ // 随机
+ t := model.Task{
+ SpiderId: reqBody.SpiderId,
+ Param: reqBody.Param,
+ UserId: services.GetCurrentUser(c).Id,
+ }
+ if err := services.AddTask(t); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ } else if reqBody.RunType == constants.RunTypeSelectedNodes {
+ // 指定节点
+ for _, nodeId := range reqBody.NodeIds {
+ t := model.Task{
+ SpiderId: reqBody.SpiderId,
+ NodeId: nodeId,
+ Param: reqBody.Param,
+ UserId: services.GetCurrentUser(c).Id,
+ }
+
+ if err := services.AddTask(t); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ } else {
+ HandleErrorF(http.StatusInternalServerError, c, "invalid run_type")
return
}
-
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- })
+ HandleSuccess(c)
}
+func DeleteTaskByStatus(c *gin.Context) {
+ status := c.Query("status")
+
+ //删除相应的日志文件
+ if err := services.RemoveLogByTaskStatus(status); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ //删除该状态下的task
+ if err := model.RemoveTaskByStatus(status); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+
+ HandleSuccess(c)
+}
+
+// 删除多个任务
+func DeleteMultipleTask(c *gin.Context) {
+ ids := make(map[string][]string)
+ if err := c.ShouldBindJSON(&ids); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ list := ids["ids"]
+ for _, id := range list {
+ if err := services.RemoveLogByTaskId(id); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ if err := model.RemoveTask(id); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ }
+ HandleSuccess(c)
+}
+
+// 删除单个任务
func DeleteTask(c *gin.Context) {
id := c.Param("id")
@@ -129,33 +201,22 @@ func DeleteTask(c *gin.Context) {
HandleError(http.StatusInternalServerError, c, err)
return
}
-
// 删除task
if err := model.RemoveTask(id); err != nil {
HandleError(http.StatusInternalServerError, c, err)
return
}
-
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- })
+ HandleSuccess(c)
}
func GetTaskLog(c *gin.Context) {
id := c.Param("id")
-
logStr, err := services.GetTaskLog(id)
if err != nil {
HandleError(http.StatusInternalServerError, c, err)
return
}
-
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- Data: logStr,
- })
+ HandleSuccessData(c, logStr)
}
func GetTaskResults(c *gin.Context) {
@@ -164,7 +225,7 @@ func GetTaskResults(c *gin.Context) {
// 绑定数据
data := TaskResultsRequestData{}
if err := c.ShouldBindQuery(&data); err != nil {
- HandleError(http.StatusBadRequest, c, err)
+ HandleError(http.StatusInternalServerError, c, err)
return
}
@@ -266,9 +327,5 @@ func CancelTask(c *gin.Context) {
HandleError(http.StatusInternalServerError, c, err)
return
}
-
- c.JSON(http.StatusOK, Response{
- Status: "ok",
- Message: "success",
- })
+ HandleSuccess(c)
}
diff --git a/backend/routes/user.go b/backend/routes/user.go
index a6d44cae..fcca967e 100644
--- a/backend/routes/user.go
+++ b/backend/routes/user.go
@@ -21,6 +21,8 @@ type UserListRequestData struct {
type UserRequestData struct {
Username string `json:"username"`
Password string `json:"password"`
+ Role string `json:"role"`
+ Email string `json:"email"`
}
func GetUser(c *gin.Context) {
@@ -88,13 +90,13 @@ func PutUser(c *gin.Context) {
return
}
- // 添加用户
- user := model.User{
- Username: strings.ToLower(reqData.Username),
- Password: utils.EncryptPassword(reqData.Password),
- Role: constants.RoleNormal,
+ // 默认为正常用户
+ if reqData.Role == "" {
+ reqData.Role = constants.RoleNormal
}
- if err := user.Add(); err != nil {
+
+ // 添加用户
+ if err := services.CreateNewUser(reqData.Username, reqData.Password, reqData.Role, reqData.Email); err != nil {
HandleError(http.StatusInternalServerError, c, err)
return
}
@@ -199,3 +201,41 @@ func GetMe(c *gin.Context) {
User: user,
}, nil)
}
+
+func PostMe(c *gin.Context) {
+ ctx := context.WithGinContext(c)
+ user := ctx.User()
+ if user == nil {
+ ctx.FailedWithError(constants.ErrorUserNotFound, http.StatusUnauthorized)
+ return
+ }
+ var reqBody model.User
+ if err := c.ShouldBindJSON(&reqBody); err != nil {
+ HandleErrorF(http.StatusBadRequest, c, "invalid request")
+ return
+ }
+ if reqBody.Email != "" {
+ user.Email = reqBody.Email
+ }
+ if reqBody.Password != "" {
+ user.Password = utils.EncryptPassword(reqBody.Password)
+ }
+ if reqBody.Setting.NotificationTrigger != "" {
+ user.Setting.NotificationTrigger = reqBody.Setting.NotificationTrigger
+ }
+ if reqBody.Setting.DingTalkRobotWebhook != "" {
+ user.Setting.DingTalkRobotWebhook = reqBody.Setting.DingTalkRobotWebhook
+ }
+ if reqBody.Setting.WechatRobotWebhook != "" {
+ user.Setting.WechatRobotWebhook = reqBody.Setting.WechatRobotWebhook
+ }
+ user.Setting.EnabledNotifications = reqBody.Setting.EnabledNotifications
+ if err := user.Save(); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ c.JSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
diff --git a/backend/routes/utils.go b/backend/routes/utils.go
index 38ca35bb..dfa5420e 100644
--- a/backend/routes/utils.go
+++ b/backend/routes/utils.go
@@ -1,17 +1,15 @@
package routes
import (
- "github.com/apex/log"
"github.com/gin-gonic/gin"
+ "net/http"
"runtime/debug"
)
func HandleError(statusCode int, c *gin.Context, err error) {
- log.Errorf("handle error:" + err.Error())
- debug.PrintStack()
c.AbortWithStatusJSON(statusCode, Response{
- Status: "ok",
- Message: "error",
+ Status: "error",
+ Message: "failure",
Error: err.Error(),
})
}
@@ -24,3 +22,18 @@ func HandleErrorF(statusCode int, c *gin.Context, err string) {
Error: err,
})
}
+
+func HandleSuccess(c *gin.Context) {
+ c.AbortWithStatusJSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ })
+}
+
+func HandleSuccessData(c *gin.Context, data interface{}) {
+ c.AbortWithStatusJSON(http.StatusOK, Response{
+ Status: "ok",
+ Message: "success",
+ Data: data,
+ })
+}
diff --git a/backend/routes/variable.go b/backend/routes/variable.go
new file mode 100644
index 00000000..c35c16ab
--- /dev/null
+++ b/backend/routes/variable.go
@@ -0,0 +1,62 @@
+package routes
+
+import (
+ "crawlab/model"
+ "github.com/gin-gonic/gin"
+ "github.com/globalsign/mgo/bson"
+ "net/http"
+)
+
+// 新增
+func PutVariable(c *gin.Context) {
+ var variable model.Variable
+ if err := c.ShouldBindJSON(&variable); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+ if err := variable.Add(); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ HandleSuccess(c)
+}
+
+// 修改
+func PostVariable(c *gin.Context) {
+ var id = c.Param("id")
+ var variable model.Variable
+ if err := c.ShouldBindJSON(&variable); err != nil {
+ HandleError(http.StatusBadRequest, c, err)
+ return
+ }
+ variable.Id = bson.ObjectIdHex(id)
+ if err := variable.Save(); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ HandleSuccess(c)
+}
+
+// 删除
+func DeleteVariable(c *gin.Context) {
+ var idStr = c.Param("id")
+ var id = bson.ObjectIdHex(idStr)
+ variable, err := model.GetVariable(id)
+ if err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ variable.Id = id
+ if err := variable.Delete(); err != nil {
+ HandleError(http.StatusInternalServerError, c, err)
+ return
+ }
+ HandleSuccess(c)
+
+}
+
+// 列表
+func GetVariableList(c *gin.Context) {
+ list := model.GetVariableList()
+ HandleSuccessData(c, list)
+}
diff --git a/backend/scripts/install-nodejs.sh b/backend/scripts/install-nodejs.sh
new file mode 100644
index 00000000..1ca73b2d
--- /dev/null
+++ b/backend/scripts/install-nodejs.sh
@@ -0,0 +1,17 @@
+#!/bin/env bash
+
+# install nvm
+curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.2/install.sh | bash
+export NVM_DIR="$([ -z "${XDG_CONFIG_HOME-}" ] && printf %s "${HOME}/.nvm" || printf %s "${XDG_CONFIG_HOME}/nvm")"
+[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
+
+# install Node.js v8.12
+nvm install 8.12
+
+# create soft links
+ln -s $HOME/.nvm/versions/node/v8.12.0/bin/npm /usr/local/bin/npm
+ln -s $HOME/.nvm/versions/node/v8.12.0/bin/node /usr/local/bin/node
+
+# environments manipulation
+export NODE_PATH=$HOME.nvm/versions/node/v8.12.0/lib/node_modules
+export PATH=$NODE_PATH:$PATH
\ No newline at end of file
diff --git a/backend/services/config_spider.go b/backend/services/config_spider.go
new file mode 100644
index 00000000..29e1c2ca
--- /dev/null
+++ b/backend/services/config_spider.go
@@ -0,0 +1,273 @@
+package services
+
+import (
+ "crawlab/constants"
+ "crawlab/database"
+ "crawlab/entity"
+ "crawlab/model"
+ "crawlab/model/config_spider"
+ "crawlab/services/spider_handler"
+ "crawlab/utils"
+ "errors"
+ "fmt"
+ "github.com/apex/log"
+ "github.com/globalsign/mgo/bson"
+ uuid "github.com/satori/go.uuid"
+ "github.com/spf13/viper"
+ "gopkg.in/yaml.v2"
+ "os"
+ "path/filepath"
+ "strings"
+)
+
+func GenerateConfigSpiderFiles(spider model.Spider, configData entity.ConfigSpiderData) error {
+ // 校验Spiderfile正确性
+ if err := ValidateSpiderfile(configData); err != nil {
+ return err
+ }
+
+ // 构造代码生成器
+ generator := config_spider.ScrapyGenerator{
+ Spider: spider,
+ ConfigData: configData,
+ }
+
+ // 生成代码
+ if err := generator.Generate(); err != nil {
+ return err
+ }
+
+ return nil
+}
+
+// 验证Spiderfile
+func ValidateSpiderfile(configData entity.ConfigSpiderData) error {
+ // 获取所有字段
+ fields := config_spider.GetAllFields(configData)
+
+ // 校验是否存在 start_url
+ if configData.StartUrl == "" {
+ return errors.New("spiderfile invalid: start_url is empty")
+ }
+
+ // 校验是否存在 start_stage
+ if configData.StartStage == "" {
+ return errors.New("spiderfile invalid: start_stage is empty")
+ }
+
+ // 校验是否存在 stages
+ if len(configData.Stages) == 0 {
+ return errors.New("spiderfile invalid: stages is empty")
+ }
+
+ // 校验stages
+ dict := map[string]int{}
+ for _, stage := range configData.Stages {
+ stageName := stage.Name
+
+ // stage 名称不能为空
+ if stageName == "" {
+ return errors.New("spiderfile invalid: stage name is empty")
+ }
+
+ // stage 名称不能为保留字符串
+ // NOTE: 如果有其他Engine,可以扩展,默认为Scrapy
+ if configData.Engine == "" || configData.Engine == constants.EngineScrapy {
+ if strings.Contains(constants.ScrapyProtectedStageNames, stageName) {
+ return errors.New(fmt.Sprintf("spiderfile invalid: stage name '%s' is protected", stageName))
+ }
+ } else {
+ return errors.New(fmt.Sprintf("spiderfile invalid: engine '%s' is not implemented", configData.Engine))
+ }
+
+ // stage 名称不能重复
+ if dict[stageName] == 1 {
+ return errors.New(fmt.Sprintf("spiderfile invalid: stage name '%s' is duplicated", stageName))
+ }
+ dict[stageName] = 1
+
+ // stage 字段不能为空
+ if len(stage.Fields) == 0 {
+ return errors.New(fmt.Sprintf("spiderfile invalid: stage '%s' has no fields", stageName))
+ }
+
+ // 是否包含 next_stage
+ hasNextStage := false
+
+ // 遍历字段列表
+ for _, field := range stage.Fields {
+ // stage 的 next stage 只能有一个
+ if field.NextStage != "" {
+ if hasNextStage {
+ return errors.New(fmt.Sprintf("spiderfile invalid: stage '%s' has more than 1 next_stage", stageName))
+ }
+ hasNextStage = true
+ }
+
+ // 字段里 css 和 xpath 只能包含一个
+ if field.Css != "" && field.Xpath != "" {
+ return errors.New(fmt.Sprintf("spiderfile invalid: field '%s' in stage '%s' has both css and xpath set which is prohibited", field.Name, stageName))
+ }
+ }
+
+ // stage 里 page_css 和 page_xpath 只能包含一个
+ if stage.PageCss != "" && stage.PageXpath != "" {
+ return errors.New(fmt.Sprintf("spiderfile invalid: stage '%s' has both page_css and page_xpath set which is prohibited", stageName))
+ }
+
+ // stage 里 list_css 和 list_xpath 只能包含一个
+ if stage.ListCss != "" && stage.ListXpath != "" {
+ return errors.New(fmt.Sprintf("spiderfile invalid: stage '%s' has both list_css and list_xpath set which is prohibited", stageName))
+ }
+
+ // 如果 stage 的 is_list 为 true 但 list_css 为空,报错
+ if stage.IsList && (stage.ListCss == "" && stage.ListXpath == "") {
+ return errors.New("spiderfile invalid: stage with is_list = true should have either list_css or list_xpath being set")
+ }
+ }
+
+ // 校验字段唯一性
+ if !IsUniqueConfigSpiderFields(fields) {
+ return errors.New("spiderfile invalid: fields not unique")
+ }
+
+ // 字段名称不能为保留字符串
+ for _, field := range fields {
+ if strings.Contains(constants.ScrapyProtectedFieldNames, field.Name) {
+ return errors.New(fmt.Sprintf("spiderfile invalid: field name '%s' is protected", field.Name))
+ }
+ }
+
+ return nil
+}
+
+func IsUniqueConfigSpiderFields(fields []entity.Field) bool {
+ dict := map[string]int{}
+ for _, field := range fields {
+ if dict[field.Name] == 1 {
+ return false
+ }
+ dict[field.Name] = 1
+ }
+ return true
+}
+
+func ProcessSpiderFilesFromConfigData(spider model.Spider, configData entity.ConfigSpiderData) error {
+ spiderDir := spider.Src
+
+ // 删除已有的爬虫文件
+ for _, fInfo := range utils.ListDir(spiderDir) {
+ // 不删除Spiderfile
+ if fInfo.Name() == "Spiderfile" {
+ continue
+ }
+
+ // 删除其他文件
+ if err := os.RemoveAll(filepath.Join(spiderDir, fInfo.Name())); err != nil {
+ return err
+ }
+ }
+
+ // 拷贝爬虫文件
+ tplDir := "./template/scrapy"
+ for _, fInfo := range utils.ListDir(tplDir) {
+ // 跳过Spiderfile
+ if fInfo.Name() == "Spiderfile" {
+ continue
+ }
+
+ srcPath := filepath.Join(tplDir, fInfo.Name())
+ if fInfo.IsDir() {
+ dirPath := filepath.Join(spiderDir, fInfo.Name())
+ if err := utils.CopyDir(srcPath, dirPath); err != nil {
+ return err
+ }
+ } else {
+ if err := utils.CopyFile(srcPath, filepath.Join(spiderDir, fInfo.Name())); err != nil {
+ return err
+ }
+ }
+ }
+
+ // 更改爬虫文件
+ if err := GenerateConfigSpiderFiles(spider, configData); err != nil {
+ return err
+ }
+
+ // 打包为 zip 文件
+ files, err := utils.GetFilesFromDir(spiderDir)
+ if err != nil {
+ return err
+ }
+ randomId := uuid.NewV4()
+ tmpFilePath := filepath.Join(viper.GetString("other.tmppath"), spider.Name+"."+randomId.String()+".zip")
+ spiderZipFileName := spider.Name + ".zip"
+ if err := utils.Compress(files, tmpFilePath); err != nil {
+ return err
+ }
+
+ // 获取 GridFS 实例
+ s, gf := database.GetGridFs("files")
+ defer s.Close()
+
+ // 判断文件是否已经存在
+ var gfFile model.GridFs
+ if err := gf.Find(bson.M{"filename": spiderZipFileName}).One(&gfFile); err == nil {
+ // 已经存在文件,则删除
+ _ = gf.RemoveId(gfFile.Id)
+ }
+
+ // 上传到GridFs
+ fid, err := UploadToGridFs(spiderZipFileName, tmpFilePath)
+ if err != nil {
+ log.Errorf("upload to grid fs error: %s", err.Error())
+ return err
+ }
+
+ // 保存爬虫 FileId
+ spider.FileId = fid
+ _ = spider.Save()
+
+ // 获取爬虫同步实例
+ spiderSync := spider_handler.SpiderSync{
+ Spider: spider,
+ }
+
+ // 获取gfFile
+ gfFile2 := model.GetGridFs(spider.FileId)
+
+ // 生成MD5
+ spiderSync.CreateMd5File(gfFile2.Md5)
+
+ return nil
+}
+
+func GenerateSpiderfileFromConfigData(spider model.Spider, configData entity.ConfigSpiderData) error {
+ // Spiderfile 路径
+ sfPath := filepath.Join(spider.Src, "Spiderfile")
+
+ // 生成Yaml内容
+ sfContentByte, err := yaml.Marshal(configData)
+ if err != nil {
+ return err
+ }
+
+ // 打开文件
+ var f *os.File
+ if utils.Exists(sfPath) {
+ f, err = os.OpenFile(sfPath, os.O_WRONLY|os.O_TRUNC, 0777)
+ } else {
+ f, err = os.OpenFile(sfPath, os.O_CREATE, 0777)
+ }
+ if err != nil {
+ return err
+ }
+ defer f.Close()
+
+ // 写入内容
+ if _, err := f.Write(sfContentByte); err != nil {
+ return err
+ }
+
+ return nil
+}
diff --git a/backend/services/file.go b/backend/services/file.go
new file mode 100644
index 00000000..d126fcab
--- /dev/null
+++ b/backend/services/file.go
@@ -0,0 +1,65 @@
+package services
+
+import (
+ "crawlab/model"
+ "github.com/apex/log"
+ "os"
+ "path"
+ "runtime/debug"
+ "strings"
+)
+
+func GetFileNodeTree(dstPath string, level int) (f model.File, err error) {
+ return getFileNodeTree(dstPath, level, dstPath)
+}
+
+func getFileNodeTree(dstPath string, level int, rootPath string) (f model.File, err error) {
+ dstF, err := os.Open(dstPath)
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return f, err
+ }
+ defer dstF.Close()
+ fileInfo, err := dstF.Stat()
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return f, nil
+ }
+ if !fileInfo.IsDir() { //如果dstF是文件
+ return model.File{
+ Label: fileInfo.Name(),
+ Name: fileInfo.Name(),
+ Path: strings.Replace(dstPath, rootPath, "", -1),
+ IsDir: false,
+ Size: fileInfo.Size(),
+ Children: nil,
+ }, nil
+ } else { //如果dstF是文件夹
+ dir, err := dstF.Readdir(0) //获取文件夹下各个文件或文件夹的fileInfo
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return f, nil
+ }
+ f = model.File{
+ Label: path.Base(dstPath),
+ Name: path.Base(dstPath),
+ Path: strings.Replace(dstPath, rootPath, "", -1),
+ IsDir: true,
+ Size: 0,
+ Children: nil,
+ }
+ for _, subFileInfo := range dir {
+ subFileNode, err := getFileNodeTree(path.Join(dstPath, subFileInfo.Name()), level+1, rootPath)
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return f, err
+ }
+ f.Children = append(f.Children, subFileNode)
+ }
+ return f, nil
+ }
+}
diff --git a/backend/services/log.go b/backend/services/log.go
index 5b5cd7ae..2034794d 100644
--- a/backend/services/log.go
+++ b/backend/services/log.go
@@ -49,10 +49,8 @@ func GetRemoteLog(task model.Task) (logStr string, err error) {
select {
case logStr = <-ch:
log.Infof("get remote log")
- break
case <-time.After(30 * time.Second):
logStr = "get remote log timeout"
- break
}
return logStr, nil
@@ -119,6 +117,18 @@ func RemoveLogByTaskId(id string) error {
return nil
}
+func RemoveLogByTaskStatus(status string) error {
+ tasks, err := model.GetTaskList(bson.M{"status": status}, 0, constants.Infinite, "-create_ts")
+ if err != nil {
+ log.Error("get tasks error:" + err.Error())
+ return err
+ }
+ for _, task := range tasks {
+ RemoveLogByTaskId(task.Id)
+ }
+ return nil
+}
+
func removeLog(t model.Task) {
if err := RemoveLocalLog(t.LogPath); err != nil {
log.Errorf("remove local log error: %s", err.Error())
diff --git a/backend/services/node.go b/backend/services/node.go
index dffe5ac9..d6124205 100644
--- a/backend/services/node.go
+++ b/backend/services/node.go
@@ -12,6 +12,7 @@ import (
"encoding/json"
"fmt"
"github.com/apex/log"
+ "github.com/globalsign/mgo"
"github.com/globalsign/mgo/bson"
"github.com/gomodule/redigo/redis"
"runtime/debug"
@@ -50,36 +51,44 @@ func GetNodeData() (Data, error) {
return data, err
}
+func GetRedisNode(key string) (*Data, error) {
+ // 获取节点数据
+ value, err := database.RedisClient.HGet("nodes", key)
+ if err != nil {
+ log.Errorf(err.Error())
+ return nil, err
+ }
+
+ // 解析节点列表数据
+ var data Data
+ if err := json.Unmarshal([]byte(value), &data); err != nil {
+ log.Errorf(err.Error())
+ return nil, err
+ }
+ return &data, nil
+}
+
// 更新所有节点状态
func UpdateNodeStatus() {
// 从Redis获取节点keys
list, err := database.RedisClient.HKeys("nodes")
if err != nil {
- log.Errorf(err.Error())
+ log.Errorf("get redis node keys error: %s", err.Error())
return
}
// 遍历节点keys
for _, key := range list {
- // 获取节点数据
- value, err := database.RedisClient.HGet("nodes", key)
+
+ data, err := GetRedisNode(key)
if err != nil {
- log.Errorf(err.Error())
- return
+ continue
}
-
- // 解析节点列表数据
- var data Data
- if err := json.Unmarshal([]byte(value), &data); err != nil {
- log.Errorf(err.Error())
- return
- }
-
// 如果记录的更新时间超过60秒,该节点被认为离线
if time.Now().Unix()-data.UpdateTsUnix > 60 {
// 在Redis中删除该节点
if err := database.RedisClient.HDel("nodes", data.Key); err != nil {
- log.Errorf(err.Error())
+ log.Errorf("delete redis node key error:%s, key:%s", err.Error(), data.Key)
}
continue
}
@@ -94,22 +103,21 @@ func UpdateNodeStatus() {
model.ResetNodeStatusToOffline(list)
}
-func handleNodeInfo(key string, data Data) {
+// 处理节点信息
+func handleNodeInfo(key string, data *Data) {
+ // 添加同步锁
+ v, err := database.RedisClient.Lock(key)
+ if err != nil {
+ return
+ }
+ defer database.RedisClient.UnLock(key, v)
+
// 更新节点信息到数据库
s, c := database.GetCol("nodes")
defer s.Close()
- // 同个key可能因为并发,被注册多次
- var nodes []model.Node
- _ = c.Find(bson.M{"key": key}).All(&nodes)
- if len(nodes) > 1 {
- for _, node := range nodes {
- _ = c.RemoveId(node.Id)
- }
- }
-
var node model.Node
- if err := c.Find(bson.M{"key": key}).One(&node); err != nil {
+ if err := c.Find(bson.M{"key": key}).One(&node); err != nil && err == mgo.ErrNotFound {
// 数据库不存在该节点
node = model.Node{
Key: key,
@@ -126,7 +134,7 @@ func handleNodeInfo(key string, data Data) {
log.Errorf(err.Error())
return
}
- } else {
+ } else if node.Key != "" {
// 数据库存在该节点
node.Status = constants.StatusOnline
node.UpdateTs = time.Now()
@@ -160,6 +168,7 @@ func UpdateNodeData() {
debug.PrintStack()
return
}
+
// 构造节点数据
data := Data{
Key: key,
@@ -177,10 +186,12 @@ func UpdateNodeData() {
debug.PrintStack()
return
}
+
if err := database.RedisClient.HSet("nodes", key, utils.BytesToString(dataBytes)); err != nil {
log.Errorf(err.Error())
return
}
+
}
func MasterNodeCallback(message redis.Message) (err error) {
@@ -258,7 +269,7 @@ func InitNodeService() error {
return err
}
- // 如果为主节点,每30秒刷新所有节点信息
+ // 如果为主节点,每10秒刷新所有节点信息
if model.IsMaster() {
spec := "*/10 * * * * *"
if _, err := c.AddFunc(spec, UpdateNodeStatus); err != nil {
diff --git a/backend/services/notification/mail.go b/backend/services/notification/mail.go
new file mode 100644
index 00000000..2231151b
--- /dev/null
+++ b/backend/services/notification/mail.go
@@ -0,0 +1,138 @@
+package notification
+
+import (
+ "errors"
+ "github.com/apex/log"
+ "github.com/matcornic/hermes"
+ "gopkg.in/gomail.v2"
+ "net/mail"
+ "os"
+ "runtime/debug"
+ "strconv"
+)
+
+func SendMail(toEmail string, toName string, subject string, content string) error {
+ // hermes instance
+ h := hermes.Hermes{
+ Theme: new(hermes.Default),
+ Product: hermes.Product{
+ Name: "Crawlab Team",
+ Copyright: "© 2019 Crawlab, Made by Crawlab-Team",
+ },
+ }
+
+ // config
+ port, _ := strconv.Atoi(os.Getenv("CRAWLAB_NOTIFICATION_MAIL_PORT"))
+ password := os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SMTP_PASSWORD")
+ SMTPUser := os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SMTP_USER")
+ smtpConfig := smtpAuthentication{
+ Server: os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SERVER"),
+ Port: port,
+ SenderEmail: os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SENDEREMAIL"),
+ SenderIdentity: os.Getenv("CRAWLAB_NOTIFICATION_MAIL_SENDERIDENTITY"),
+ SMTPPassword: password,
+ SMTPUser: SMTPUser,
+ }
+ options := sendOptions{
+ To: toEmail,
+ Subject: subject,
+ }
+
+ // email instance
+ email := hermes.Email{
+ Body: hermes.Body{
+ Name: toName,
+ FreeMarkdown: hermes.Markdown(content + GetFooter()),
+ },
+ }
+
+ // generate html
+ html, err := h.GenerateHTML(email)
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return err
+ }
+
+ // generate text
+ text, err := h.GeneratePlainText(email)
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return err
+ }
+
+ // send the email
+ if err := send(smtpConfig, options, html, text); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return err
+ }
+
+ return nil
+}
+
+type smtpAuthentication struct {
+ Server string
+ Port int
+ SenderEmail string
+ SenderIdentity string
+ SMTPUser string
+ SMTPPassword string
+}
+
+// sendOptions are options for sending an email
+type sendOptions struct {
+ To string
+ Subject string
+}
+
+// send sends the email
+func send(smtpConfig smtpAuthentication, options sendOptions, htmlBody string, txtBody string) error {
+
+ if smtpConfig.Server == "" {
+ return errors.New("SMTP server config is empty")
+ }
+ if smtpConfig.Port == 0 {
+ return errors.New("SMTP port config is empty")
+ }
+
+ if smtpConfig.SMTPUser == "" {
+ return errors.New("SMTP user is empty")
+ }
+
+ if smtpConfig.SenderIdentity == "" {
+ return errors.New("SMTP sender identity is empty")
+ }
+
+ if smtpConfig.SenderEmail == "" {
+ return errors.New("SMTP sender email is empty")
+ }
+
+ if options.To == "" {
+ return errors.New("no receiver emails configured")
+ }
+
+ from := mail.Address{
+ Name: smtpConfig.SenderIdentity,
+ Address: smtpConfig.SenderEmail,
+ }
+
+ m := gomail.NewMessage()
+ m.SetHeader("From", from.String())
+ m.SetHeader("To", options.To)
+ m.SetHeader("Subject", options.Subject)
+
+ m.SetBody("text/plain", txtBody)
+ m.AddAlternative("text/html", htmlBody)
+
+ d := gomail.NewPlainDialer(smtpConfig.Server, smtpConfig.Port, smtpConfig.SMTPUser, smtpConfig.SMTPPassword)
+
+ return d.DialAndSend(m)
+}
+
+func GetFooter() string {
+ return `
+[Github](https://github.com/crawlab-team/crawlab) | [Documentation](http://docs.crawlab.cn) | [Docker](https://hub.docker.com/r/tikazyq/crawlab)
+`
+}
diff --git a/backend/services/notification/mobile.go b/backend/services/notification/mobile.go
new file mode 100644
index 00000000..e140ecc5
--- /dev/null
+++ b/backend/services/notification/mobile.go
@@ -0,0 +1,59 @@
+package notification
+
+import (
+ "errors"
+ "github.com/apex/log"
+ "github.com/imroc/req"
+ "runtime/debug"
+)
+
+func SendMobileNotification(webhook string, title string, content string) error {
+ type ResBody struct {
+ ErrCode int `json:"errcode"`
+ ErrMsg string `json:"errmsg"`
+ }
+
+ // 请求头
+ header := req.Header{
+ "Content-Type": "application/json; charset=utf-8",
+ }
+
+ // 请求数据
+ data := req.Param{
+ "msgtype": "markdown",
+ "markdown": req.Param{
+ "title": title,
+ "text": content,
+ "content": content,
+ },
+ "at": req.Param{
+ "atMobiles": []string{},
+ "isAtAll": false,
+ },
+ }
+
+ // 发起请求
+ res, err := req.Post(webhook, header, req.BodyJSON(&data))
+ if err != nil {
+ log.Errorf("dingtalk notification error: " + err.Error())
+ debug.PrintStack()
+ return err
+ }
+
+ // 解析响应
+ var resBody ResBody
+ if err := res.ToJSON(&resBody); err != nil {
+ log.Errorf("dingtalk notification error: " + err.Error())
+ debug.PrintStack()
+ return err
+ }
+
+ // 判断响应是否报错
+ if resBody.ErrCode != 0 {
+ log.Errorf("dingtalk notification error: " + resBody.ErrMsg)
+ debug.PrintStack()
+ return errors.New(resBody.ErrMsg)
+ }
+
+ return nil
+}
diff --git a/backend/services/register/register.go b/backend/services/register/register.go
index ccd8b67d..ed4e1891 100644
--- a/backend/services/register/register.go
+++ b/backend/services/register/register.go
@@ -6,6 +6,7 @@ import (
"net"
"reflect"
"runtime/debug"
+ "sync"
)
type Register interface {
@@ -97,25 +98,31 @@ func getMac() (string, error) {
var register Register
// 获得注册器
-func GetRegister() Register {
- if register != nil {
- return register
- }
+var once sync.Once
- registerType := viper.GetString("server.register.type")
- if registerType == "mac" {
- register = &MacRegister{}
- } else {
- ip := viper.GetString("server.register.ip")
- if ip == "" {
- log.Error("server.register.ip is empty")
- debug.PrintStack()
- return nil
+func GetRegister() Register {
+ once.Do(func() {
+
+ if register != nil {
+ register = register
}
- register = &IpRegister{
- Ip: ip,
+
+ registerType := viper.GetString("server.register.type")
+ if registerType == "mac" {
+ register = &MacRegister{}
+ } else {
+ ip := viper.GetString("server.register.ip")
+ if ip == "" {
+ log.Error("server.register.ip is empty")
+ debug.PrintStack()
+ register = nil
+ }
+ register = &IpRegister{
+ Ip: ip,
+ }
}
- }
- log.Info("register type is :" + reflect.TypeOf(register).String())
+ log.Info("register type is :" + reflect.TypeOf(register).String())
+
+ })
return register
}
diff --git a/backend/services/rpc.go b/backend/services/rpc.go
new file mode 100644
index 00000000..66c04369
--- /dev/null
+++ b/backend/services/rpc.go
@@ -0,0 +1,234 @@
+package services
+
+import (
+ "crawlab/constants"
+ "crawlab/database"
+ "crawlab/entity"
+ "crawlab/model"
+ "crawlab/utils"
+ "encoding/json"
+ "fmt"
+ "github.com/apex/log"
+ "github.com/gomodule/redigo/redis"
+ uuid "github.com/satori/go.uuid"
+ "runtime/debug"
+)
+
+type RpcMessage struct {
+ Id string `json:"id"`
+ Method string `json:"method"`
+ Params map[string]string `json:"params"`
+ Result string `json:"result"`
+}
+
+func RpcServerInstallLang(msg RpcMessage) RpcMessage {
+ lang := GetRpcParam("lang", msg.Params)
+ if lang == constants.Nodejs {
+ output, _ := InstallNodejsLocalLang()
+ msg.Result = output
+ }
+ return msg
+}
+
+func RpcClientInstallLang(nodeId string, lang string) (output string, err error) {
+ params := map[string]string{}
+ params["lang"] = lang
+
+ data, err := RpcClientFunc(nodeId, constants.RpcInstallLang, params, 600)()
+ if err != nil {
+ return
+ }
+
+ output = data
+
+ return
+}
+
+func RpcServerInstallDep(msg RpcMessage) RpcMessage {
+ lang := GetRpcParam("lang", msg.Params)
+ depName := GetRpcParam("dep_name", msg.Params)
+ if lang == constants.Python {
+ output, _ := InstallPythonLocalDep(depName)
+ msg.Result = output
+ }
+ return msg
+}
+
+func RpcClientInstallDep(nodeId string, lang string, depName string) (output string, err error) {
+ params := map[string]string{}
+ params["lang"] = lang
+ params["dep_name"] = depName
+
+ data, err := RpcClientFunc(nodeId, constants.RpcInstallDep, params, 10)()
+ if err != nil {
+ return
+ }
+
+ output = data
+
+ return
+}
+
+func RpcServerUninstallDep(msg RpcMessage) RpcMessage {
+ lang := GetRpcParam("lang", msg.Params)
+ depName := GetRpcParam("dep_name", msg.Params)
+ if lang == constants.Python {
+ output, _ := UninstallPythonLocalDep(depName)
+ msg.Result = output
+ }
+ return msg
+}
+
+func RpcClientUninstallDep(nodeId string, lang string, depName string) (output string, err error) {
+ params := map[string]string{}
+ params["lang"] = lang
+ params["dep_name"] = depName
+
+ data, err := RpcClientFunc(nodeId, constants.RpcUninstallDep, params, 60)()
+ if err != nil {
+ return
+ }
+
+ output = data
+
+ return
+}
+
+func RpcServerGetInstalledDepList(nodeId string, msg RpcMessage) RpcMessage {
+ lang := GetRpcParam("lang", msg.Params)
+ if lang == constants.Python {
+ depList, _ := GetPythonLocalInstalledDepList(nodeId)
+ resultStr, _ := json.Marshal(depList)
+ msg.Result = string(resultStr)
+ } else if lang == constants.Nodejs {
+ depList, _ := GetNodejsLocalInstalledDepList(nodeId)
+ resultStr, _ := json.Marshal(depList)
+ msg.Result = string(resultStr)
+ }
+ return msg
+}
+
+func RpcClientGetInstalledDepList(nodeId string, lang string) (list []entity.Dependency, err error) {
+ params := map[string]string{}
+ params["lang"] = lang
+
+ data, err := RpcClientFunc(nodeId, constants.RpcGetInstalledDepList, params, 10)()
+ if err != nil {
+ return
+ }
+
+ // 反序列化结果
+ if err := json.Unmarshal([]byte(data), &list); err != nil {
+ return list, err
+ }
+
+ return
+}
+
+func RpcClientFunc(nodeId string, method string, params map[string]string, timeout int) func() (string, error) {
+ return func() (result string, err error) {
+ // 请求ID
+ id := uuid.NewV4().String()
+
+ // 构造RPC消息
+ msg := RpcMessage{
+ Id: id,
+ Method: method,
+ Params: params,
+ Result: "",
+ }
+
+ // 发送RPC消息
+ msgStr := ObjectToString(msg)
+ if err := database.RedisClient.LPush(fmt.Sprintf("rpc:%s", nodeId), msgStr); err != nil {
+ return result, err
+ }
+
+ // 获取RPC回复消息
+ dataStr, err := database.RedisClient.BRPop(fmt.Sprintf("rpc:%s", nodeId), timeout)
+ if err != nil {
+ return result, err
+ }
+
+ // 反序列化消息
+ if err := json.Unmarshal([]byte(dataStr), &msg); err != nil {
+ return result, err
+ }
+
+ return msg.Result, err
+ }
+}
+
+func GetRpcParam(key string, params map[string]string) string {
+ return params[key]
+}
+
+func ObjectToString(params interface{}) string {
+ bytes, _ := json.Marshal(params)
+ return utils.BytesToString(bytes)
+}
+
+var IsRpcStopped = false
+
+func StopRpcService() {
+ IsRpcStopped = true
+}
+
+func InitRpcService() error {
+ go func() {
+ for {
+ // 获取当前节点
+ node, err := model.GetCurrentNode()
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ continue
+ }
+
+ // 获取获取消息队列信息
+ dataStr, err := database.RedisClient.BRPop(fmt.Sprintf("rpc:%s", node.Id.Hex()), 0)
+ if err != nil {
+ if err != redis.ErrNil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ }
+ continue
+ }
+
+ // 反序列化消息
+ var msg RpcMessage
+ if err := json.Unmarshal([]byte(dataStr), &msg); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ continue
+ }
+
+ // 根据Method调用本地方法
+ var replyMsg RpcMessage
+ if msg.Method == constants.RpcInstallDep {
+ replyMsg = RpcServerInstallDep(msg)
+ } else if msg.Method == constants.RpcUninstallDep {
+ replyMsg = RpcServerUninstallDep(msg)
+ } else if msg.Method == constants.RpcInstallLang {
+ replyMsg = RpcServerInstallLang(msg)
+ } else if msg.Method == constants.RpcGetInstalledDepList {
+ replyMsg = RpcServerGetInstalledDepList(node.Id.Hex(), msg)
+ } else {
+ continue
+ }
+
+ // 发送返回消息
+ if err := database.RedisClient.LPush(fmt.Sprintf("rpc:%s", node.Id.Hex()), ObjectToString(replyMsg)); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ continue
+ }
+
+ // 如果停止RPC服务,则返回
+ if IsRpcStopped {
+ return
+ }
+ }
+ }()
+ return nil
+}
diff --git a/backend/services/schedule.go b/backend/services/schedule.go
index d4c1635b..a179b50f 100644
--- a/backend/services/schedule.go
+++ b/backend/services/schedule.go
@@ -4,8 +4,10 @@ import (
"crawlab/constants"
"crawlab/lib/cron"
"crawlab/model"
+ "errors"
"github.com/apex/log"
- "github.com/satori/go.uuid"
+ "github.com/globalsign/mgo/bson"
+ uuid "github.com/satori/go.uuid"
"runtime/debug"
)
@@ -15,48 +17,59 @@ type Scheduler struct {
cron *cron.Cron
}
-func AddTask(s model.Schedule) func() {
+func AddScheduleTask(s model.Schedule) func() {
return func() {
- node, err := model.GetNodeByKey(s.NodeKey)
- if err != nil || node.Id.Hex() == "" {
- log.Errorf("get node by key error: %s", err.Error())
- debug.PrintStack()
- return
- }
-
- spider := model.GetSpiderByName(s.SpiderName)
- if spider == nil || spider.Id.Hex() == "" {
- log.Errorf("get spider by name error: %s", err.Error())
- debug.PrintStack()
- return
- }
-
- // 同步ID到定时任务
- s.SyncNodeIdAndSpiderId(node, *spider)
-
// 生成任务ID
id := uuid.NewV4()
- // 生成任务模型
- t := model.Task{
- Id: id.String(),
- SpiderId: spider.Id,
- NodeId: node.Id,
- Status: constants.StatusPending,
- Param: s.Param,
- }
+ if s.RunType == constants.RunTypeAllNodes {
+ // 所有节点
+ nodes, err := model.GetNodeList(nil)
+ if err != nil {
+ return
+ }
+ for _, node := range nodes {
+ t := model.Task{
+ Id: id.String(),
+ SpiderId: s.SpiderId,
+ NodeId: node.Id,
+ Param: s.Param,
+ UserId: s.UserId,
+ }
- // 将任务存入数据库
- if err := model.AddTask(t); err != nil {
- log.Errorf(err.Error())
- debug.PrintStack()
- return
- }
+ if err := AddTask(t); err != nil {
+ return
+ }
+ }
+ } else if s.RunType == constants.RunTypeRandom {
+ // 随机
+ t := model.Task{
+ Id: id.String(),
+ SpiderId: s.SpiderId,
+ Param: s.Param,
+ UserId: s.UserId,
+ }
+ if err := AddTask(t); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return
+ }
+ } else if s.RunType == constants.RunTypeSelectedNodes {
+ // 指定节点
+ for _, nodeId := range s.NodeIds {
+ t := model.Task{
+ Id: id.String(),
+ SpiderId: s.SpiderId,
+ NodeId: nodeId,
+ Param: s.Param,
+ UserId: s.UserId,
+ }
- // 加入任务队列
- if err := AssignTask(t); err != nil {
- log.Errorf(err.Error())
- debug.PrintStack()
+ if err := AddTask(t); err != nil {
+ return
+ }
+ }
+ } else {
return
}
}
@@ -96,8 +109,8 @@ func (s *Scheduler) Start() error {
func (s *Scheduler) AddJob(job model.Schedule) error {
spec := job.Cron
- // 添加任务
- eid, err := s.cron.AddFunc(spec, AddTask(job))
+ // 添加定时任务
+ eid, err := s.cron.AddFunc(spec, AddScheduleTask(job))
if err != nil {
log.Errorf("add func task error: %s", err.Error())
debug.PrintStack()
@@ -106,6 +119,12 @@ func (s *Scheduler) AddJob(job model.Schedule) error {
// 更新EntryID
job.EntryId = eid
+
+ // 更新状态
+ job.Status = constants.ScheduleStatusRunning
+ job.Enabled = true
+
+ // 保存定时任务
if err := job.Save(); err != nil {
log.Errorf("job save error: %s", err.Error())
debug.PrintStack()
@@ -134,6 +153,41 @@ func ParserCron(spec string) error {
return nil
}
+// 禁用定时任务
+func (s *Scheduler) Disable(id bson.ObjectId) error {
+ schedule, err := model.GetSchedule(id)
+ if err != nil {
+ return err
+ }
+ if schedule.EntryId == 0 {
+ return errors.New("entry id not found")
+ }
+
+ // 从cron服务中删除该任务
+ s.cron.Remove(schedule.EntryId)
+
+ // 更新状态
+ schedule.Status = constants.ScheduleStatusStop
+ schedule.Enabled = false
+
+ if err = schedule.Save(); err != nil {
+ return err
+ }
+ return nil
+}
+
+// 启用定时任务
+func (s *Scheduler) Enable(id bson.ObjectId) error {
+ schedule, err := model.GetSchedule(id)
+ if err != nil {
+ return err
+ }
+ if err := s.AddJob(schedule); err != nil {
+ return err
+ }
+ return nil
+}
+
func (s *Scheduler) Update() error {
// 删除所有定时任务
s.RemoveAll()
@@ -146,11 +200,26 @@ func (s *Scheduler) Update() error {
return err
}
+ user, err := model.GetUserByUsername("admin")
+ if err != nil {
+ log.Errorf("get admin user error: %s", err.Error())
+ return err
+ }
+
// 遍历任务列表
for i := 0; i < len(sList); i++ {
// 单个任务
job := sList[i]
+ if job.Status == constants.ScheduleStatusStop {
+ continue
+ }
+
+ // 兼容以前版本
+ if job.UserId.Hex() == "" {
+ job.UserId = user.Id
+ }
+
// 添加到定时任务
if err := s.AddJob(job); err != nil {
log.Errorf("add job error: %s, job: %s, cron: %s", err.Error(), job.Name, job.Cron)
diff --git a/backend/services/spider.go b/backend/services/spider.go
index 84d218bb..fb785d85 100644
--- a/backend/services/spider.go
+++ b/backend/services/spider.go
@@ -12,11 +12,14 @@ import (
"github.com/apex/log"
"github.com/globalsign/mgo"
"github.com/globalsign/mgo/bson"
+ "github.com/satori/go.uuid"
"github.com/spf13/viper"
+ "gopkg.in/yaml.v2"
+ "io/ioutil"
"os"
+ "path"
"path/filepath"
"runtime/debug"
- "strings"
)
type SpiderFileData struct {
@@ -30,6 +33,59 @@ type SpiderUploadMessage struct {
SpiderId string
}
+// 从主节点上传爬虫到GridFS
+func UploadSpiderToGridFsFromMaster(spider model.Spider) error {
+ // 爬虫所在目录
+ spiderDir := spider.Src
+
+ // 打包为 zip 文件
+ files, err := utils.GetFilesFromDir(spiderDir)
+ if err != nil {
+ return err
+ }
+ randomId := uuid.NewV4()
+ tmpFilePath := filepath.Join(viper.GetString("other.tmppath"), spider.Name+"."+randomId.String()+".zip")
+ spiderZipFileName := spider.Name + ".zip"
+ if err := utils.Compress(files, tmpFilePath); err != nil {
+ return err
+ }
+
+ // 获取 GridFS 实例
+ s, gf := database.GetGridFs("files")
+ defer s.Close()
+
+ // 判断文件是否已经存在
+ var gfFile model.GridFs
+ if err := gf.Find(bson.M{"filename": spiderZipFileName}).One(&gfFile); err == nil {
+ // 已经存在文件,则删除
+ _ = gf.RemoveId(gfFile.Id)
+ }
+
+ // 上传到GridFs
+ fid, err := UploadToGridFs(spiderZipFileName, tmpFilePath)
+ if err != nil {
+ log.Errorf("upload to grid fs error: %s", err.Error())
+ return err
+ }
+
+ // 保存爬虫 FileId
+ spider.FileId = fid
+ _ = spider.Save()
+
+ // 获取爬虫同步实例
+ spiderSync := spider_handler.SpiderSync{
+ Spider: spider,
+ }
+
+ // 获取gfFile
+ gfFile2 := model.GetGridFs(spider.FileId)
+
+ // 生成MD5
+ spiderSync.CreateMd5File(gfFile2.Md5)
+
+ return nil
+}
+
// 上传zip文件到GridFS
func UploadToGridFs(fileName string, filePath string) (fid bson.ObjectId, err error) {
fid = ""
@@ -59,6 +115,7 @@ func UploadToGridFs(fileName string, filePath string) (fid bson.ObjectId, err er
}
// 关闭文件,提交写入
if err = f.Close(); err != nil {
+ debug.PrintStack()
return "", err
}
// 文件ID
@@ -100,7 +157,7 @@ func ReadFileByStep(filePath string, handle func([]byte, *mgo.GridFile), fileCre
// 发布所有爬虫
func PublishAllSpiders() {
// 获取爬虫列表
- spiders, _, _ := model.GetSpiderList(nil, 0, constants.Infinite)
+ spiders, _, _ := model.GetSpiderList(nil, 0, constants.Infinite, "-_id")
if len(spiders) == 0 {
return
}
@@ -116,12 +173,23 @@ func PublishAllSpiders() {
// 发布爬虫
func PublishSpider(spider model.Spider) {
- // 查询gf file,不存在则删除
- gfFile := model.GetGridFs(spider.FileId)
- if gfFile == nil {
- _ = model.RemoveSpider(spider.Id)
+ var gfFile *model.GridFs
+ if spider.FileId.Hex() != constants.ObjectIdNull {
+ // 查询gf file,不存在则标记为爬虫文件不存在
+ gfFile = model.GetGridFs(spider.FileId)
+ if gfFile == nil {
+ spider.FileId = constants.ObjectIdNull
+ _ = spider.Save()
+ return
+ }
+ }
+
+ // 如果FileId为空,表示还没有上传爬虫到GridFS,则跳过
+ if spider.FileId == bson.ObjectIdHex(constants.ObjectIdNull) {
return
}
+
+ // 获取爬虫同步实例
spiderSync := spider_handler.SpiderSync{
Spider: spider,
}
@@ -138,21 +206,14 @@ func PublishSpider(spider model.Spider) {
md5 := filepath.Join(path, spider_handler.Md5File)
if !utils.Exists(md5) {
log.Infof("md5 file not found: %s", md5)
- spiderSync.RemoveSpiderFile()
- spiderSync.Download()
- spiderSync.CreateMd5File(gfFile.Md5)
+ spiderSync.RemoveDownCreate(gfFile.Md5)
return
}
// md5值不一样,则下载
- md5Str := utils.ReadFileOneLine(md5)
- // 去掉空格以及换行符
- md5Str = strings.Replace(md5Str, " ", "", -1)
- md5Str = strings.Replace(md5Str, "\n", "", -1)
+ md5Str := utils.GetSpiderMd5Str(md5)
if gfFile.Md5 != md5Str {
log.Infof("md5 is different, gf-md5:%s, file-md5:%s", gfFile.Md5, md5Str)
- spiderSync.RemoveSpiderFile()
- spiderSync.Download()
- spiderSync.CreateMd5File(gfFile.Md5)
+ spiderSync.RemoveDownCreate(gfFile.Md5)
return
}
}
@@ -206,5 +267,110 @@ func InitSpiderService() error {
// 启动定时任务
c.Start()
+ if model.IsMaster() {
+ // 添加Demo爬虫
+ templateSpidersDir := "./template/spiders"
+ for _, info := range utils.ListDir(templateSpidersDir) {
+ if !info.IsDir() {
+ continue
+ }
+ spiderName := info.Name()
+
+ // 如果爬虫在数据库中不存在,则添加
+ spider := model.GetSpiderByName(spiderName)
+ if spider.Name != "" {
+ // 存在同名爬虫,跳过
+ continue
+ }
+
+ // 拷贝爬虫
+ templateSpiderPath := path.Join(templateSpidersDir, spiderName)
+ spiderPath := path.Join(viper.GetString("spider.path"), spiderName)
+ if utils.Exists(spiderPath) {
+ utils.RemoveFiles(spiderPath)
+ }
+ if err := utils.CopyDir(templateSpiderPath, spiderPath); err != nil {
+ log.Errorf("copy error: " + err.Error())
+ debug.PrintStack()
+ continue
+ }
+
+ // 构造配置数据
+ configData := entity.ConfigSpiderData{}
+
+ // 读取YAML文件
+ yamlFile, err := ioutil.ReadFile(path.Join(spiderPath, "Spiderfile"))
+ if err != nil {
+ log.Errorf("read yaml error: " + err.Error())
+ //debug.PrintStack()
+ continue
+ }
+
+ // 反序列化
+ if err := yaml.Unmarshal(yamlFile, &configData); err != nil {
+ log.Errorf("unmarshal error: " + err.Error())
+ debug.PrintStack()
+ continue
+ }
+
+ if configData.Type == constants.Customized {
+ // 添加该爬虫到数据库
+ spider = model.Spider{
+ Id: bson.NewObjectId(),
+ Name: spiderName,
+ DisplayName: configData.DisplayName,
+ Type: constants.Customized,
+ Col: configData.Col,
+ Src: spiderPath,
+ Remark: configData.Remark,
+ ProjectId: bson.ObjectIdHex(constants.ObjectIdNull),
+ FileId: bson.ObjectIdHex(constants.ObjectIdNull),
+ Cmd: configData.Cmd,
+ }
+ if err := spider.Add(); err != nil {
+ log.Errorf("add spider error: " + err.Error())
+ debug.PrintStack()
+ continue
+ }
+
+ // 上传爬虫到GridFS
+ if err := UploadSpiderToGridFsFromMaster(spider); err != nil {
+ log.Errorf("upload spider error: " + err.Error())
+ debug.PrintStack()
+ continue
+ }
+ } else if configData.Type == constants.Configurable || configData.Type == "config" {
+ // 添加该爬虫到数据库
+ spider = model.Spider{
+ Id: bson.NewObjectId(),
+ Name: configData.Name,
+ DisplayName: configData.DisplayName,
+ Type: constants.Configurable,
+ Col: configData.Col,
+ Src: spiderPath,
+ Remark: configData.Remark,
+ ProjectId: bson.ObjectIdHex(constants.ObjectIdNull),
+ FileId: bson.ObjectIdHex(constants.ObjectIdNull),
+ Config: configData,
+ }
+ if err := spider.Add(); err != nil {
+ log.Errorf("add spider error: " + err.Error())
+ debug.PrintStack()
+ continue
+ }
+
+ // 根据序列化后的数据处理爬虫文件
+ if err := ProcessSpiderFilesFromConfigData(spider, configData); err != nil {
+ log.Errorf("add spider error: " + err.Error())
+ debug.PrintStack()
+ continue
+ }
+ }
+ }
+
+ // 发布所有爬虫
+ PublishAllSpiders()
+ }
+
return nil
}
diff --git a/backend/services/spider_handler/spider.go b/backend/services/spider_handler/spider.go
index cce025dc..ddc94b57 100644
--- a/backend/services/spider_handler/spider.go
+++ b/backend/services/spider_handler/spider.go
@@ -4,12 +4,14 @@ import (
"crawlab/database"
"crawlab/model"
"crawlab/utils"
+ "fmt"
"github.com/apex/log"
"github.com/globalsign/mgo/bson"
"github.com/satori/go.uuid"
"github.com/spf13/viper"
"io"
"os"
+ "os/exec"
"path/filepath"
"runtime/debug"
)
@@ -24,7 +26,7 @@ type SpiderSync struct {
func (s *SpiderSync) CreateMd5File(md5 string) {
path := filepath.Join(viper.GetString("spider.path"), s.Spider.Name)
- utils.CreateFilePath(path)
+ utils.CreateDirPath(path)
fileName := filepath.Join(path, Md5File)
file := utils.OpenFile(fileName)
@@ -37,6 +39,12 @@ func (s *SpiderSync) CreateMd5File(md5 string) {
}
}
+func (s *SpiderSync) RemoveDownCreate(md5 string) {
+ s.RemoveSpiderFile()
+ s.Download()
+ s.CreateMd5File(md5)
+}
+
// 获得下载锁的key
func (s *SpiderSync) GetLockDownloadKey(spiderId string) string {
node, _ := model.GetCurrentNode()
@@ -59,10 +67,14 @@ func (s *SpiderSync) RemoveSpiderFile() {
// 检测是否已经下载中
func (s *SpiderSync) CheckDownLoading(spiderId string, fileId string) (bool, string) {
key := s.GetLockDownloadKey(spiderId)
- if _, err := database.RedisClient.HGet("spider", key); err == nil {
- return true, key
+ key2, err := database.RedisClient.HGet("spider", key)
+ if err != nil {
+ return false, key2
}
- return false, key
+ if key2 == "" {
+ return false, key2
+ }
+ return true, key2
}
// 下载爬虫
@@ -71,6 +83,7 @@ func (s *SpiderSync) Download() {
fileId := s.Spider.FileId.Hex()
isDownloading, key := s.CheckDownLoading(spiderId, fileId)
if isDownloading {
+ log.Infof(fmt.Sprintf("spider is already being downloaded, spider id: %s", s.Spider.Id.Hex()))
return
} else {
_ = database.RedisClient.HSet("spider", key, key)
@@ -99,7 +112,6 @@ func (s *SpiderSync) Download() {
// 创建临时文件
tmpFilePath := filepath.Join(tmpPath, randomId.String()+".zip")
tmpFile := utils.OpenFile(tmpFilePath)
- defer utils.Close(tmpFile)
// 将该文件写入临时文件
if _, err := io.Copy(tmpFile, f); err != nil {
@@ -119,6 +131,15 @@ func (s *SpiderSync) Download() {
return
}
+ //递归修改目标文件夹权限
+ // 解决scrapy.setting中开启LOG_ENABLED 和 LOG_FILE时不能创建log文件的问题
+ cmd := exec.Command("chmod", "-R", "777", dstPath)
+ if err := cmd.Run(); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return
+ }
+
// 关闭临时文件
if err := tmpFile.Close(); err != nil {
log.Errorf(err.Error())
diff --git a/backend/services/system.go b/backend/services/system.go
index 92f9cf96..6181afee 100644
--- a/backend/services/system.go
+++ b/backend/services/system.go
@@ -4,28 +4,42 @@ import (
"crawlab/constants"
"crawlab/database"
"crawlab/entity"
+ "crawlab/lib/cron"
"crawlab/model"
"crawlab/utils"
"encoding/json"
+ "errors"
+ "fmt"
+ "github.com/apex/log"
+ "github.com/imroc/req"
+ "os/exec"
+ "path"
+ "regexp"
+ "runtime/debug"
+ "sort"
+ "strings"
+ "sync"
)
+// 系统信息 chan 映射
var SystemInfoChanMap = utils.NewChanMap()
-func GetRemoteSystemInfo(id string) (sysInfo entity.SystemInfo, err error) {
+// 从远端获取系统信息
+func GetRemoteSystemInfo(nodeId string) (sysInfo entity.SystemInfo, err error) {
// 发送消息
msg := entity.NodeMessage{
Type: constants.MsgTypeGetSystemInfo,
- NodeId: id,
+ NodeId: nodeId,
}
// 序列化
msgBytes, _ := json.Marshal(&msg)
- if _, err := database.RedisClient.Publish("nodes:"+id, utils.BytesToString(msgBytes)); err != nil {
+ if _, err := database.RedisClient.Publish("nodes:"+nodeId, utils.BytesToString(msgBytes)); err != nil {
return entity.SystemInfo{}, err
}
// 通道
- ch := SystemInfoChanMap.ChanBlocked(id)
+ ch := SystemInfoChanMap.ChanBlocked(nodeId)
// 等待响应,阻塞
sysInfoStr := <-ch
@@ -38,11 +52,534 @@ func GetRemoteSystemInfo(id string) (sysInfo entity.SystemInfo, err error) {
return sysInfo, nil
}
-func GetSystemInfo(id string) (sysInfo entity.SystemInfo, err error) {
- if IsMasterNode(id) {
+// 获取系统信息
+func GetSystemInfo(nodeId string) (sysInfo entity.SystemInfo, err error) {
+ if IsMasterNode(nodeId) {
sysInfo, err = model.GetLocalSystemInfo()
} else {
- sysInfo, err = GetRemoteSystemInfo(id)
+ sysInfo, err = GetRemoteSystemInfo(nodeId)
}
return
}
+
+// 获取语言列表
+func GetLangList(nodeId string) []entity.Lang {
+ list := []entity.Lang{
+ {Name: "Python", ExecutableName: "python", ExecutablePath: "/usr/local/bin/python", DepExecutablePath: "/usr/local/bin/pip"},
+ {Name: "Node.js", ExecutableName: "node", ExecutablePath: "/usr/local/bin/node", DepExecutablePath: "/usr/local/bin/npm"},
+ //{Name: "Java", ExecutableName: "java", ExecutablePath: "/usr/local/bin/java"},
+ }
+ for i, lang := range list {
+ list[i].Installed = IsInstalledLang(nodeId, lang)
+ }
+ return list
+}
+
+// 根据语言名获取语言实例
+func GetLangFromLangName(nodeId string, name string) entity.Lang {
+ langList := GetLangList(nodeId)
+ for _, lang := range langList {
+ if lang.ExecutableName == name {
+ return lang
+ }
+ }
+ return entity.Lang{}
+}
+
+// 是否已安装该依赖
+func IsInstalledLang(nodeId string, lang entity.Lang) bool {
+ sysInfo, err := GetSystemInfo(nodeId)
+ if err != nil {
+ return false
+ }
+ for _, exec := range sysInfo.Executables {
+ if exec.Path == lang.ExecutablePath {
+ return true
+ }
+ }
+ return false
+}
+
+// 是否已安装该依赖
+func IsInstalledDep(installedDepList []entity.Dependency, dep entity.Dependency) bool {
+ for _, _dep := range installedDepList {
+ if strings.ToLower(_dep.Name) == strings.ToLower(dep.Name) {
+ return true
+ }
+ }
+ return false
+}
+
+// 初始化函数
+func InitDepsFetcher() error {
+ c := cron.New(cron.WithSeconds())
+ c.Start()
+ if _, err := c.AddFunc("0 */5 * * * *", UpdatePythonDepList); err != nil {
+ return err
+ }
+
+ go func() {
+ UpdatePythonDepList()
+ }()
+ return nil
+}
+
+// =========
+// Python
+// =========
+
+type PythonDepJsonData struct {
+ Info PythonDepJsonDataInfo `json:"info"`
+}
+
+type PythonDepJsonDataInfo struct {
+ Name string `json:"name"`
+ Summary string `json:"summary"`
+ Version string `json:"version"`
+}
+
+type PythonDepNameDict struct {
+ Name string `json:"name"`
+ Weight int `json:"weight"`
+}
+
+type PythonDepNameDictSlice []PythonDepNameDict
+
+func (s PythonDepNameDictSlice) Len() int { return len(s) }
+func (s PythonDepNameDictSlice) Swap(i, j int) { s[i], s[j] = s[j], s[i] }
+func (s PythonDepNameDictSlice) Less(i, j int) bool { return s[i].Weight > s[j].Weight }
+
+// 获取Python本地依赖列表
+func GetPythonDepList(nodeId string, searchDepName string) ([]entity.Dependency, error) {
+ var list []entity.Dependency
+
+ // 先从 Redis 获取
+ depList, err := GetPythonDepListFromRedis()
+ if err != nil {
+ return list, err
+ }
+
+ // 过滤相似的依赖
+ var depNameList PythonDepNameDictSlice
+ for _, depName := range depList {
+ if strings.HasPrefix(strings.ToLower(depName), strings.ToLower(searchDepName)) {
+ var weight int
+ if strings.ToLower(depName) == strings.ToLower(searchDepName) {
+ weight = 3
+ } else if strings.HasPrefix(strings.ToLower(depName), strings.ToLower(searchDepName)) {
+ weight = 2
+ } else {
+ weight = 1
+ }
+ depNameList = append(depNameList, PythonDepNameDict{
+ Name: depName,
+ Weight: weight,
+ })
+ }
+ }
+
+ // 获取已安装依赖列表
+ var installedDepList []entity.Dependency
+ if IsMasterNode(nodeId) {
+ installedDepList, err = GetPythonLocalInstalledDepList(nodeId)
+ if err != nil {
+ return list, err
+ }
+ } else {
+ installedDepList, err = GetPythonRemoteInstalledDepList(nodeId)
+ if err != nil {
+ return list, err
+ }
+ }
+
+ // 根据依赖名排序
+ sort.Stable(depNameList)
+
+ // 遍历依赖名列表,取前20个
+ for i, depNameDict := range depNameList {
+ if i > 20 {
+ break
+ }
+ dep := entity.Dependency{
+ Name: depNameDict.Name,
+ }
+ dep.Installed = IsInstalledDep(installedDepList, dep)
+ list = append(list, dep)
+ }
+
+ // 从依赖源获取信息
+ //list, err = GetPythonDepListWithInfo(list)
+
+ return list, nil
+}
+
+// 获取Python依赖的源数据信息
+func GetPythonDepListWithInfo(depList []entity.Dependency) ([]entity.Dependency, error) {
+ var goSync sync.WaitGroup
+ for i, dep := range depList {
+ if i > 10 {
+ break
+ }
+ goSync.Add(1)
+ go func(i int, dep entity.Dependency, depList []entity.Dependency, n *sync.WaitGroup) {
+ url := fmt.Sprintf("https://pypi.org/pypi/%s/json", dep.Name)
+ res, err := req.Get(url)
+ if err != nil {
+ n.Done()
+ return
+ }
+ var data PythonDepJsonData
+ if err := res.ToJSON(&data); err != nil {
+ n.Done()
+ return
+ }
+ depList[i].Version = data.Info.Version
+ depList[i].Description = data.Info.Summary
+ n.Done()
+ }(i, dep, depList, &goSync)
+ }
+ goSync.Wait()
+ return depList, nil
+}
+
+func FetchPythonDepInfo(depName string) (entity.Dependency, error) {
+ url := fmt.Sprintf("https://pypi.org/pypi/%s/json", depName)
+ res, err := req.Get(url)
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return entity.Dependency{}, err
+ }
+ var data PythonDepJsonData
+ if res.Response().StatusCode == 404 {
+ return entity.Dependency{}, errors.New("get depName from [https://pypi.org] error: 404")
+ }
+ if err := res.ToJSON(&data); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return entity.Dependency{}, err
+ }
+ dep := entity.Dependency{
+ Name: depName,
+ Version: data.Info.Version,
+ Description: data.Info.Summary,
+ }
+ return dep, nil
+}
+
+// 从Redis获取Python依赖列表
+func GetPythonDepListFromRedis() ([]string, error) {
+ var list []string
+
+ // 从 Redis 获取字符串
+ rawData, err := database.RedisClient.HGet("system", "deps:python")
+ if err != nil {
+ return list, err
+ }
+
+ // 反序列化
+ if err := json.Unmarshal([]byte(rawData), &list); err != nil {
+ return list, err
+ }
+
+ // 如果为空,则从依赖源获取列表
+ if len(list) == 0 {
+ UpdatePythonDepList()
+ }
+
+ return list, nil
+}
+
+// 从Python依赖源获取依赖列表并返回
+func FetchPythonDepList() ([]string, error) {
+ // 依赖URL
+ url := "https://pypi.tuna.tsinghua.edu.cn/simple"
+
+ // 输出列表
+ var list []string
+
+ // 请求URL
+ res, err := req.Get(url)
+ if err != nil {
+ log.Error(err.Error())
+ debug.PrintStack()
+ return list, err
+ }
+
+ // 获取响应数据
+ text, err := res.ToString()
+ if err != nil {
+ log.Error(err.Error())
+ debug.PrintStack()
+ return list, err
+ }
+
+ // 从响应数据中提取依赖名
+ regex := regexp.MustCompile("(.*)")
+ for _, line := range strings.Split(text, "\n") {
+ arr := regex.FindStringSubmatch(line)
+ if len(arr) < 2 {
+ continue
+ }
+ list = append(list, arr[1])
+ }
+
+ // 赋值给列表
+ return list, nil
+}
+
+// 更新Python依赖列表到Redis
+func UpdatePythonDepList() {
+ // 从依赖源获取列表
+ list, _ := FetchPythonDepList()
+
+ // 序列化
+ listBytes, err := json.Marshal(list)
+ if err != nil {
+ log.Error(err.Error())
+ debug.PrintStack()
+ return
+ }
+
+ // 设置Redis
+ if err := database.RedisClient.HSet("system", "deps:python", string(listBytes)); err != nil {
+ log.Error(err.Error())
+ debug.PrintStack()
+ return
+ }
+}
+
+// 获取Python本地已安装的依赖列表
+func GetPythonLocalInstalledDepList(nodeId string) ([]entity.Dependency, error) {
+ var list []entity.Dependency
+
+ lang := GetLangFromLangName(nodeId, constants.Python)
+ if !IsInstalledLang(nodeId, lang) {
+ return list, errors.New("python is not installed")
+ }
+ cmd := exec.Command("pip", "freeze")
+ outputBytes, err := cmd.Output()
+ if err != nil {
+ debug.PrintStack()
+ return list, err
+ }
+
+ for _, line := range strings.Split(string(outputBytes), "\n") {
+ arr := strings.Split(line, "==")
+ if len(arr) < 2 {
+ continue
+ }
+ dep := entity.Dependency{
+ Name: strings.ToLower(arr[0]),
+ Version: arr[1],
+ Installed: true,
+ }
+ list = append(list, dep)
+ }
+
+ return list, nil
+}
+
+// 获取Python远端依赖列表
+func GetPythonRemoteInstalledDepList(nodeId string) ([]entity.Dependency, error) {
+ depList, err := RpcClientGetInstalledDepList(nodeId, constants.Python)
+ if err != nil {
+ return depList, err
+ }
+ return depList, nil
+}
+
+// 安装Python本地依赖
+func InstallPythonLocalDep(depName string) (string, error) {
+ // 依赖镜像URL
+ url := "https://pypi.tuna.tsinghua.edu.cn/simple"
+
+ cmd := exec.Command("pip", "install", depName, "-i", url)
+ outputBytes, err := cmd.Output()
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return fmt.Sprintf("error: %s", err.Error()), err
+ }
+ return string(outputBytes), nil
+}
+
+// 获取Python远端依赖列表
+func InstallPythonRemoteDep(nodeId string, depName string) (string, error) {
+ output, err := RpcClientInstallDep(nodeId, constants.Python, depName)
+ if err != nil {
+ return output, err
+ }
+ return output, nil
+}
+
+// 安装Python本地依赖
+func UninstallPythonLocalDep(depName string) (string, error) {
+ cmd := exec.Command("pip", "uninstall", "-y", depName)
+ outputBytes, err := cmd.Output()
+ if err != nil {
+ log.Errorf(string(outputBytes))
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return fmt.Sprintf("error: %s", err.Error()), err
+ }
+ return string(outputBytes), nil
+}
+
+// 获取Python远端依赖列表
+func UninstallPythonRemoteDep(nodeId string, depName string) (string, error) {
+ output, err := RpcClientUninstallDep(nodeId, constants.Python, depName)
+ if err != nil {
+ return output, err
+ }
+ return output, nil
+}
+
+// ==============
+// Node.js
+// ==============
+
+func InstallNodejsLocalLang() (string, error) {
+ cmd := exec.Command("/bin/sh", path.Join("scripts", "install-nodejs.sh"))
+ output, err := cmd.Output()
+ if err != nil {
+ log.Error(err.Error())
+ debug.PrintStack()
+ return string(output), err
+ }
+
+ // TODO: check if Node.js is installed successfully
+
+ return string(output), nil
+}
+
+// 获取Node.js远端依赖列表
+func InstallNodejsRemoteLang(nodeId string) (string, error) {
+ output, err := RpcClientInstallLang(nodeId, constants.Nodejs)
+ if err != nil {
+ return output, err
+ }
+ return output, nil
+}
+
+// 获取Nodejs本地已安装的依赖列表
+func GetNodejsLocalInstalledDepList(nodeId string) ([]entity.Dependency, error) {
+ var list []entity.Dependency
+
+ lang := GetLangFromLangName(nodeId, constants.Nodejs)
+ if !IsInstalledLang(nodeId, lang) {
+ return list, errors.New("nodejs is not installed")
+ }
+ cmd := exec.Command("npm", "ls", "-g", "--depth", "0")
+ outputBytes, _ := cmd.Output()
+ //if err != nil {
+ // log.Error("error: " + string(outputBytes))
+ // debug.PrintStack()
+ // return list, err
+ //}
+
+ regex := regexp.MustCompile("\\s(.*)@(.*)")
+ for _, line := range strings.Split(string(outputBytes), "\n") {
+ arr := regex.FindStringSubmatch(line)
+ if len(arr) < 3 {
+ continue
+ }
+ dep := entity.Dependency{
+ Name: strings.ToLower(arr[1]),
+ Version: arr[2],
+ Installed: true,
+ }
+ list = append(list, dep)
+ }
+
+ return list, nil
+}
+
+// 获取Nodejs远端依赖列表
+func GetNodejsRemoteInstalledDepList(nodeId string) ([]entity.Dependency, error) {
+ depList, err := RpcClientGetInstalledDepList(nodeId, constants.Nodejs)
+ if err != nil {
+ return depList, err
+ }
+ return depList, nil
+}
+
+// 安装Nodejs本地依赖
+func InstallNodejsLocalDep(depName string) (string, error) {
+ // 依赖镜像URL
+ url := "https://registry.npm.taobao.org"
+
+ cmd := exec.Command("npm", "install", depName, "-g", "--registry", url)
+ outputBytes, err := cmd.Output()
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return fmt.Sprintf("error: %s", err.Error()), err
+ }
+ return string(outputBytes), nil
+}
+
+// 获取Nodejs远端依赖列表
+func InstallNodejsRemoteDep(nodeId string, depName string) (string, error) {
+ output, err := RpcClientInstallDep(nodeId, constants.Nodejs, depName)
+ if err != nil {
+ return output, err
+ }
+ return output, nil
+}
+
+// 安装Nodejs本地依赖
+func UninstallNodejsLocalDep(depName string) (string, error) {
+ cmd := exec.Command("npm", "uninstall", depName, "-g")
+ outputBytes, err := cmd.Output()
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return fmt.Sprintf("error: %s", err.Error()), err
+ }
+ return string(outputBytes), nil
+}
+
+// 获取Nodejs远端依赖列表
+func UninstallNodejsRemoteDep(nodeId string, depName string) (string, error) {
+ output, err := RpcClientUninstallDep(nodeId, constants.Nodejs, depName)
+ if err != nil {
+ return output, err
+ }
+ return output, nil
+}
+
+// 获取Nodejs本地依赖列表
+func GetNodejsDepList(nodeId string, searchDepName string) (depList []entity.Dependency, err error) {
+ // 执行shell命令
+ cmd := exec.Command("npm", "search", "--json", searchDepName)
+ outputBytes, _ := cmd.Output()
+
+ // 获取已安装依赖列表
+ var installedDepList []entity.Dependency
+ if IsMasterNode(nodeId) {
+ installedDepList, err = GetNodejsLocalInstalledDepList(nodeId)
+ if err != nil {
+ return depList, err
+ }
+ } else {
+ installedDepList, err = GetNodejsRemoteInstalledDepList(nodeId)
+ if err != nil {
+ return depList, err
+ }
+ }
+
+ // 反序列化
+ if err := json.Unmarshal(outputBytes, &depList); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return depList, err
+ }
+
+ // 遍历安装列表
+ for i, dep := range depList {
+ depList[i].Installed = IsInstalledDep(installedDepList, dep)
+ }
+
+ return depList, nil
+}
diff --git a/backend/services/task.go b/backend/services/task.go
index 9e584e82..15513977 100644
--- a/backend/services/task.go
+++ b/backend/services/task.go
@@ -6,10 +6,15 @@ import (
"crawlab/entity"
"crawlab/lib/cron"
"crawlab/model"
+ "crawlab/services/notification"
+ "crawlab/services/spider_handler"
"crawlab/utils"
"encoding/json"
"errors"
+ "fmt"
"github.com/apex/log"
+ "github.com/globalsign/mgo/bson"
+ uuid "github.com/satori/go.uuid"
"github.com/spf13/viper"
"os"
"os/exec"
@@ -17,6 +22,7 @@ import (
"runtime"
"runtime/debug"
"strconv"
+ "strings"
"sync"
"syscall"
"time"
@@ -102,9 +108,34 @@ func AssignTask(task model.Task) error {
// 设置环境变量
func SetEnv(cmd *exec.Cmd, envs []model.Env, taskId string, dataCol string) *exec.Cmd {
+ // 默认把Node.js的全局node_modules加入环境变量
+ envPath := os.Getenv("PATH")
+ for _, _path := range strings.Split(envPath, ":") {
+ if strings.Contains(_path, "/.nvm/versions/node/") {
+ pathNodeModules := strings.Replace(_path, "/bin", "/lib/node_modules", -1)
+ _ = os.Setenv("PATH", pathNodeModules+":"+envPath)
+ _ = os.Setenv("NODE_PATH", pathNodeModules)
+ break
+ }
+ }
+
// 默认环境变量
cmd.Env = append(os.Environ(), "CRAWLAB_TASK_ID="+taskId)
cmd.Env = append(cmd.Env, "CRAWLAB_COLLECTION="+dataCol)
+ cmd.Env = append(cmd.Env, "CRAWLAB_MONGO_HOST="+viper.GetString("mongo.host"))
+ cmd.Env = append(cmd.Env, "CRAWLAB_MONGO_PORT="+viper.GetString("mongo.port"))
+ if viper.GetString("mongo.db") != "" {
+ cmd.Env = append(cmd.Env, "CRAWLAB_MONGO_DB="+viper.GetString("mongo.db"))
+ }
+ if viper.GetString("mongo.username") != "" {
+ cmd.Env = append(cmd.Env, "CRAWLAB_MONGO_USERNAME="+viper.GetString("mongo.username"))
+ }
+ if viper.GetString("mongo.password") != "" {
+ cmd.Env = append(cmd.Env, "CRAWLAB_MONGO_PASSWORD="+viper.GetString("mongo.password"))
+ }
+ if viper.GetString("mongo.authSource") != "" {
+ cmd.Env = append(cmd.Env, "CRAWLAB_MONGO_AUTHSOURCE="+viper.GetString("mongo.authSource"))
+ }
cmd.Env = append(cmd.Env, "PYTHONUNBUFFERED=0")
cmd.Env = append(cmd.Env, "PYTHONIOENCODING=utf-8")
cmd.Env = append(cmd.Env, "TZ=Asia/Shanghai")
@@ -114,7 +145,11 @@ func SetEnv(cmd *exec.Cmd, envs []model.Env, taskId string, dataCol string) *exe
cmd.Env = append(cmd.Env, env.Name+"="+env.Value)
}
- // TODO 全局环境变量
+ // 全局环境变量
+ variables := model.GetVariableList()
+ for _, variable := range variables {
+ cmd.Env = append(cmd.Env, variable.Key+"="+variable.Value)
+ }
return cmd
}
@@ -136,8 +171,15 @@ func FinishOrCancelTask(ch chan string, cmd *exec.Cmd, t model.Task) {
log.Infof("process received signal: %s", signal)
if signal == constants.TaskCancel && cmd.Process != nil {
+ var err error
+ // 兼容windows
+ if runtime.GOOS == constants.Windows {
+ err = cmd.Process.Kill()
+ } else {
+ err = syscall.Kill(-cmd.Process.Pid, syscall.SIGKILL)
+ }
// 取消进程
- if err := syscall.Kill(-cmd.Process.Pid, syscall.SIGKILL); err != nil {
+ if err != nil {
log.Errorf("process kill error: %s", err.Error())
debug.PrintStack()
@@ -217,7 +259,22 @@ func ExecuteShellCmd(cmdStr string, cwd string, t model.Task, s model.Spider) (e
}
// 环境变量配置
- cmd = SetEnv(cmd, s.Envs, t.Id, s.Col)
+ envs := s.Envs
+ if s.Type == constants.Configurable {
+ // 数据库配置
+ envs = append(envs, model.Env{Name: "CRAWLAB_MONGO_HOST", Value: viper.GetString("mongo.host")})
+ envs = append(envs, model.Env{Name: "CRAWLAB_MONGO_PORT", Value: viper.GetString("mongo.port")})
+ envs = append(envs, model.Env{Name: "CRAWLAB_MONGO_DB", Value: viper.GetString("mongo.db")})
+ envs = append(envs, model.Env{Name: "CRAWLAB_MONGO_USERNAME", Value: viper.GetString("mongo.username")})
+ envs = append(envs, model.Env{Name: "CRAWLAB_MONGO_PASSWORD", Value: viper.GetString("mongo.password")})
+ envs = append(envs, model.Env{Name: "CRAWLAB_MONGO_AUTHSOURCE", Value: viper.GetString("mongo.authSource")})
+
+ // 设置配置
+ for envName, envValue := range s.Config.Settings {
+ envs = append(envs, model.Env{Name: "CRAWLAB_SETTING_" + envName, Value: envValue})
+ }
+ }
+ cmd = SetEnv(cmd, envs, t.Id, s.Col)
// 起一个goroutine来监控进程
ch := utils.TaskExecChanMap.ChanBlocked(t.Id)
@@ -225,7 +282,9 @@ func ExecuteShellCmd(cmdStr string, cwd string, t model.Task, s model.Spider) (e
go FinishOrCancelTask(ch, cmd, t)
// kill的时候,可以kill所有的子进程
- cmd.SysProcAttr = &syscall.SysProcAttr{Setpgid: true}
+ if runtime.GOOS != constants.Windows {
+ cmd.SysProcAttr = &syscall.SysProcAttr{Setpgid: true}
+ }
// 启动进程
if err := StartTaskProcess(cmd, t); err != nil {
@@ -293,9 +352,12 @@ func SaveTaskResultCount(id string) func() {
// 执行任务
func ExecuteTask(id int) {
- if flag, _ := LockList.Load(id); flag.(bool) {
- log.Debugf(GetWorkerPrefix(id) + "正在执行任务...")
- return
+ if flag, ok := LockList.Load(id); ok {
+ if flag.(bool) {
+ log.Debugf(GetWorkerPrefix(id) + "正在执行任务...")
+ return
+ }
+
}
// 上锁
@@ -369,7 +431,14 @@ func ExecuteTask(id int) {
)
// 执行命令
- cmd := spider.Cmd
+ var cmd string
+ if spider.Type == constants.Configurable {
+ // 可配置爬虫命令
+ cmd = "scrapy crawl config_spider"
+ } else {
+ // 自定义爬虫命令
+ cmd = spider.Cmd
+ }
// 加入参数
if t.Param != "" {
@@ -382,15 +451,17 @@ func ExecuteTask(id int) {
t.Status = constants.StatusRunning // 任务状态
t.WaitDuration = t.StartTs.Sub(t.CreateTs).Seconds() // 等待时长
+ // 文件检查
+ if err := SpiderFileCheck(t, spider); err != nil {
+ log.Errorf("spider file check error: %s", err.Error())
+ return
+ }
+
// 开始执行任务
log.Infof(GetWorkerPrefix(id) + "开始执行任务(ID:" + t.Id + ")")
// 储存任务
- if err := t.Save(); err != nil {
- log.Errorf(err.Error())
- HandleTaskError(t, err)
- return
- }
+ _ = t.Save()
// 起一个cron执行器来统计任务结果数
if spider.Col != "" {
@@ -404,9 +475,22 @@ func ExecuteTask(id int) {
defer cronExec.Stop()
}
+ // 获得触发任务用户
+ user, err := model.GetUser(t.UserId)
+ if err != nil {
+ log.Errorf(GetWorkerPrefix(id) + err.Error())
+ return
+ }
+
// 执行Shell命令
if err := ExecuteShellCmd(cmd, cwd, t, spider); err != nil {
log.Errorf(GetWorkerPrefix(id) + err.Error())
+
+ // 如果发生错误,则发送通知
+ t, _ = model.GetTask(t.Id)
+ if user.Setting.NotificationTrigger == constants.NotificationTriggerOnTaskEnd || user.Setting.NotificationTrigger == constants.NotificationTriggerOnTaskError {
+ SendNotifications(user, t, spider)
+ }
return
}
@@ -429,6 +513,11 @@ func ExecuteTask(id int) {
t.RuntimeDuration = t.FinishTs.Sub(t.StartTs).Seconds() // 运行时长
t.TotalDuration = t.FinishTs.Sub(t.CreateTs).Seconds() // 总时长
+ // 如果是任务结束时发送通知,则发送通知
+ if user.Setting.NotificationTrigger == constants.NotificationTriggerOnTaskEnd {
+ SendNotifications(user, t, spider)
+ }
+
// 保存任务
if err := t.Save(); err != nil {
log.Errorf(GetWorkerPrefix(id) + err.Error())
@@ -444,6 +533,30 @@ func ExecuteTask(id int) {
log.Infof(GetWorkerPrefix(id) + "任务(ID:" + t.Id + ")" + "执行完毕. 消耗时间:" + durationStr + "秒")
}
+func SpiderFileCheck(t model.Task, spider model.Spider) error {
+ // 判断爬虫文件是否存在
+ gfFile := model.GetGridFs(spider.FileId)
+ if gfFile == nil {
+ t.Error = "找不到爬虫文件,请重新上传"
+ t.Status = constants.StatusError
+ t.FinishTs = time.Now() // 结束时间
+ t.RuntimeDuration = t.FinishTs.Sub(t.StartTs).Seconds() // 运行时长
+ t.TotalDuration = t.FinishTs.Sub(t.CreateTs).Seconds() // 总时长
+ _ = t.Save()
+ return errors.New(t.Error)
+ }
+
+ // 判断md5值是否一致
+ path := filepath.Join(viper.GetString("spider.path"), spider.Name)
+ md5File := filepath.Join(path, spider_handler.Md5File)
+ md5 := utils.GetSpiderMd5Str(md5File)
+ if gfFile.Md5 != md5 {
+ spiderSync := spider_handler.SpiderSync{Spider: spider}
+ spiderSync.RemoveDownCreate(gfFile.Md5)
+ }
+ return nil
+}
+
func GetTaskLog(id string) (logStr string, err error) {
task, err := model.GetTask(id)
@@ -452,6 +565,29 @@ func GetTaskLog(id string) (logStr string, err error) {
}
if IsMasterNode(task.NodeId.Hex()) {
+ if !utils.Exists(task.LogPath) {
+ fileDir, err := MakeLogDir(task)
+
+ if err != nil {
+ log.Errorf(err.Error())
+ }
+
+ fileP := GetLogFilePaths(fileDir)
+
+ // 获取日志文件路径
+ fLog, err := os.Create(fileP)
+ defer fLog.Close()
+ if err != nil {
+ log.Errorf("create task log file error: %s", fileP)
+ debug.PrintStack()
+ }
+ task.LogPath = fileP
+ if err := task.Save(); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ }
+
+ }
// 若为主节点,获取本机日志
logBytes, err := model.GetLocalLog(task.LogPath)
if err != nil {
@@ -533,17 +669,188 @@ func CancelTask(id string) (err error) {
return nil
}
-func HandleTaskError(t model.Task, err error) {
- log.Error("handle task error:" + err.Error())
- t.Status = constants.StatusError
- t.Error = err.Error()
- t.FinishTs = time.Now()
- if err := t.Save(); err != nil {
+func AddTask(t model.Task) error {
+ // 生成任务ID
+ id := uuid.NewV4()
+ t.Id = id.String()
+
+ // 设置任务状态
+ t.Status = constants.StatusPending
+
+ // 如果没有传入node_id,则置为null
+ if t.NodeId.Hex() == "" {
+ t.NodeId = bson.ObjectIdHex(constants.ObjectIdNull)
+ }
+
+ // 将任务存入数据库
+ if err := model.AddTask(t); err != nil {
log.Errorf(err.Error())
debug.PrintStack()
- return
+ return err
+ }
+
+ // 加入任务队列
+ if err := AssignTask(t); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return err
+ }
+
+ return nil
+}
+
+func GetTaskEmailMarkdownContent(t model.Task, s model.Spider) string {
+ n, _ := model.GetNode(t.NodeId)
+ errMsg := ""
+ statusMsg := fmt.Sprintf(`%s`, t.Status)
+ if t.Status == constants.StatusError {
+ errMsg = " with errors"
+ statusMsg = fmt.Sprintf(`%s`, t.Status)
+ }
+ return fmt.Sprintf(`
+Your task has finished%s. Please find the task info below.
+
+ |
+--: | :--
+**Task ID:** | %s
+**Task Status:** | %s
+**Task Param:** | %s
+**Spider ID:** | %s
+**Spider Name:** | %s
+**Node:** | %s
+**Create Time:** | %s
+**Start Time:** | %s
+**Finish Time:** | %s
+**Wait Duration:** | %.0f sec
+**Runtime Duration:** | %.0f sec
+**Total Duration:** | %.0f sec
+**Number of Results:** | %d
+**Error:** | %s
+
+Please login to Crawlab to view the details.
+`,
+ errMsg,
+ t.Id,
+ statusMsg,
+ t.Param,
+ s.Id.Hex(),
+ s.Name,
+ n.Name,
+ utils.GetLocalTimeString(t.CreateTs),
+ utils.GetLocalTimeString(t.StartTs),
+ utils.GetLocalTimeString(t.FinishTs),
+ t.WaitDuration,
+ t.RuntimeDuration,
+ t.TotalDuration,
+ t.ResultCount,
+ t.Error,
+ )
+}
+
+func GetTaskMarkdownContent(t model.Task, s model.Spider) string {
+ n, _ := model.GetNode(t.NodeId)
+ errMsg := ""
+ errLog := "-"
+ statusMsg := fmt.Sprintf(`%s`, t.Status)
+ if t.Status == constants.StatusError {
+ errMsg = `(有错误)`
+ errLog = fmt.Sprintf(`%s`, t.Error)
+ statusMsg = fmt.Sprintf(`%s`, t.Status)
+ }
+ return fmt.Sprintf(`
+您的任务已完成%s,请查看任务信息如下。
+
+> **任务ID:** %s
+> **任务状态:** %s
+> **任务参数:** %s
+> **爬虫ID:** %s
+> **爬虫名称:** %s
+> **节点:** %s
+> **创建时间:** %s
+> **开始时间:** %s
+> **完成时间:** %s
+> **等待时间:** %.0f秒
+> **运行时间:** %.0f秒
+> **总时间:** %.0f秒
+> **结果数:** %d
+> **错误:** %s
+
+请登录Crawlab查看详情。
+`,
+ errMsg,
+ t.Id,
+ statusMsg,
+ t.Param,
+ s.Id.Hex(),
+ s.Name,
+ n.Name,
+ utils.GetLocalTimeString(t.CreateTs),
+ utils.GetLocalTimeString(t.StartTs),
+ utils.GetLocalTimeString(t.FinishTs),
+ t.WaitDuration,
+ t.RuntimeDuration,
+ t.TotalDuration,
+ t.ResultCount,
+ errLog,
+ )
+}
+
+func SendTaskEmail(u model.User, t model.Task, s model.Spider) {
+ statusMsg := "has finished"
+ if t.Status == constants.StatusError {
+ statusMsg = "has an error"
+ }
+ title := fmt.Sprintf("[Crawlab] Task for \"%s\" %s", s.Name, statusMsg)
+ if err := notification.SendMail(
+ u.Email,
+ u.Username,
+ title,
+ GetTaskEmailMarkdownContent(t, s),
+ ); err != nil {
+ log.Errorf("mail error: " + err.Error())
+ debug.PrintStack()
+ }
+}
+
+func SendTaskDingTalk(u model.User, t model.Task, s model.Spider) {
+ statusMsg := "已完成"
+ if t.Status == constants.StatusError {
+ statusMsg = "发生错误"
+ }
+ title := fmt.Sprintf("[Crawlab] \"%s\" 任务%s", s.Name, statusMsg)
+ content := GetTaskMarkdownContent(t, s)
+ if err := notification.SendMobileNotification(u.Setting.DingTalkRobotWebhook, title, content); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ }
+}
+
+func SendTaskWechat(u model.User, t model.Task, s model.Spider) {
+ content := GetTaskMarkdownContent(t, s)
+ if err := notification.SendMobileNotification(u.Setting.WechatRobotWebhook, "", content); err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ }
+}
+
+func SendNotifications(u model.User, t model.Task, s model.Spider) {
+ if u.Email != "" && utils.StringArrayContains(u.Setting.EnabledNotifications, constants.NotificationTypeMail) {
+ go func() {
+ SendTaskEmail(u, t, s)
+ }()
+ }
+
+ if u.Setting.DingTalkRobotWebhook != "" && utils.StringArrayContains(u.Setting.EnabledNotifications, constants.NotificationTypeDingTalk) {
+ go func() {
+ SendTaskDingTalk(u, t, s)
+ }()
+ }
+
+ if u.Setting.WechatRobotWebhook != "" && utils.StringArrayContains(u.Setting.EnabledNotifications, constants.NotificationTypeWechat) {
+ go func() {
+ SendTaskWechat(u, t, s)
+ }()
}
- debug.PrintStack()
}
func InitTaskExecutor() error {
diff --git a/backend/services/user.go b/backend/services/user.go
index 61fd952e..a01e721b 100644
--- a/backend/services/user.go
+++ b/backend/services/user.go
@@ -6,20 +6,18 @@ import (
"crawlab/utils"
"errors"
"github.com/dgrijalva/jwt-go"
+ "github.com/gin-gonic/gin"
"github.com/globalsign/mgo/bson"
"github.com/spf13/viper"
+ "strings"
"time"
)
func InitUserService() error {
- adminUser := model.User{
- Username: "admin",
- Password: utils.EncryptPassword("admin"),
- Role: constants.RoleAdmin,
- }
- _ = adminUser.Add()
+ _ = CreateNewUser("admin", "admin", constants.RoleAdmin, "")
return nil
}
+
func MakeToken(user *model.User) (tokenStr string, err error) {
token := jwt.NewWithClaims(jwt.SigningMethodHS256, jwt.MapClaims{
"id": user.Id,
@@ -91,3 +89,29 @@ func CheckToken(tokenStr string) (user model.User, err error) {
return
}
+
+func CreateNewUser(username string, password string, role string, email string) error {
+ user := model.User{
+ Username: strings.ToLower(username),
+ Password: utils.EncryptPassword(password),
+ Role: role,
+ Email: email,
+ Setting: model.UserSetting{
+ NotificationTrigger: constants.NotificationTriggerNever,
+ EnabledNotifications: []string{
+ constants.NotificationTypeMail,
+ constants.NotificationTypeDingTalk,
+ constants.NotificationTypeWechat,
+ },
+ },
+ }
+ if err := user.Add(); err != nil {
+ return err
+ }
+ return nil
+}
+
+func GetCurrentUser(c *gin.Context) *model.User {
+ data, _ := c.Get("currentUser")
+ return data.(*model.User)
+}
diff --git a/spiders/chinaz/chinaz/__init__.py b/backend/template/scrapy/config_spider/__init__.py
similarity index 100%
rename from spiders/chinaz/chinaz/__init__.py
rename to backend/template/scrapy/config_spider/__init__.py
diff --git a/backend/template/scrapy/config_spider/items.py b/backend/template/scrapy/config_spider/items.py
new file mode 100644
index 00000000..16681a52
--- /dev/null
+++ b/backend/template/scrapy/config_spider/items.py
@@ -0,0 +1,12 @@
+# -*- coding: utf-8 -*-
+
+# Define here the models for your scraped items
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/items.html
+
+import scrapy
+
+
+class Item(scrapy.Item):
+###ITEMS###
diff --git a/backend/template/scrapy/config_spider/middlewares.py b/backend/template/scrapy/config_spider/middlewares.py
new file mode 100644
index 00000000..e864bd0b
--- /dev/null
+++ b/backend/template/scrapy/config_spider/middlewares.py
@@ -0,0 +1,103 @@
+# -*- coding: utf-8 -*-
+
+# Define here the models for your spider middleware
+#
+# See documentation in:
+# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
+
+from scrapy import signals
+
+
+class ConfigSpiderSpiderMiddleware(object):
+ # Not all methods need to be defined. If a method is not defined,
+ # scrapy acts as if the spider middleware does not modify the
+ # passed objects.
+
+ @classmethod
+ def from_crawler(cls, crawler):
+ # This method is used by Scrapy to create your spiders.
+ s = cls()
+ crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
+ return s
+
+ def process_spider_input(self, response, spider):
+ # Called for each response that goes through the spider
+ # middleware and into the spider.
+
+ # Should return None or raise an exception.
+ return None
+
+ def process_spider_output(self, response, result, spider):
+ # Called with the results returned from the Spider, after
+ # it has processed the response.
+
+ # Must return an iterable of Request, dict or Item objects.
+ for i in result:
+ yield i
+
+ def process_spider_exception(self, response, exception, spider):
+ # Called when a spider or process_spider_input() method
+ # (from other spider middleware) raises an exception.
+
+ # Should return either None or an iterable of Request, dict
+ # or Item objects.
+ pass
+
+ def process_start_requests(self, start_requests, spider):
+ # Called with the start requests of the spider, and works
+ # similarly to the process_spider_output() method, except
+ # that it doesn’t have a response associated.
+
+ # Must return only requests (not items).
+ for r in start_requests:
+ yield r
+
+ def spider_opened(self, spider):
+ spider.logger.info('Spider opened: %s' % spider.name)
+
+
+class ConfigSpiderDownloaderMiddleware(object):
+ # Not all methods need to be defined. If a method is not defined,
+ # scrapy acts as if the downloader middleware does not modify the
+ # passed objects.
+
+ @classmethod
+ def from_crawler(cls, crawler):
+ # This method is used by Scrapy to create your spiders.
+ s = cls()
+ crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
+ return s
+
+ def process_request(self, request, spider):
+ # Called for each request that goes through the downloader
+ # middleware.
+
+ # Must either:
+ # - return None: continue processing this request
+ # - or return a Response object
+ # - or return a Request object
+ # - or raise IgnoreRequest: process_exception() methods of
+ # installed downloader middleware will be called
+ return None
+
+ def process_response(self, request, response, spider):
+ # Called with the response returned from the downloader.
+
+ # Must either;
+ # - return a Response object
+ # - return a Request object
+ # - or raise IgnoreRequest
+ return response
+
+ def process_exception(self, request, exception, spider):
+ # Called when a download handler or a process_request()
+ # (from other downloader middleware) raises an exception.
+
+ # Must either:
+ # - return None: continue processing this exception
+ # - return a Response object: stops process_exception() chain
+ # - return a Request object: stops process_exception() chain
+ pass
+
+ def spider_opened(self, spider):
+ spider.logger.info('Spider opened: %s' % spider.name)
diff --git a/backend/template/scrapy/config_spider/pipelines.py b/backend/template/scrapy/config_spider/pipelines.py
new file mode 100644
index 00000000..69af4c85
--- /dev/null
+++ b/backend/template/scrapy/config_spider/pipelines.py
@@ -0,0 +1,27 @@
+# -*- coding: utf-8 -*-
+
+# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+
+import os
+from pymongo import MongoClient
+
+mongo = MongoClient(
+ host=os.environ.get('CRAWLAB_MONGO_HOST') or 'localhost',
+ port=int(os.environ.get('CRAWLAB_MONGO_PORT') or 27017),
+ username=os.environ.get('CRAWLAB_MONGO_USERNAME'),
+ password=os.environ.get('CRAWLAB_MONGO_PASSWORD'),
+ authSource=os.environ.get('CRAWLAB_MONGO_AUTHSOURCE') or 'admin'
+)
+db = mongo[os.environ.get('CRAWLAB_MONGO_DB') or 'test']
+col = db[os.environ.get('CRAWLAB_COLLECTION') or 'test']
+task_id = os.environ.get('CRAWLAB_TASK_ID')
+
+class ConfigSpiderPipeline(object):
+ def process_item(self, item, spider):
+ item['task_id'] = task_id
+ if col is not None:
+ col.save(item)
+ return item
diff --git a/backend/template/scrapy/config_spider/settings.py b/backend/template/scrapy/config_spider/settings.py
new file mode 100644
index 00000000..4b0965f2
--- /dev/null
+++ b/backend/template/scrapy/config_spider/settings.py
@@ -0,0 +1,111 @@
+# -*- coding: utf-8 -*-
+import os
+import re
+import json
+
+# Scrapy settings for config_spider project
+#
+# For simplicity, this file contains only settings considered important or
+# commonly used. You can find more settings consulting the documentation:
+#
+# https://docs.scrapy.org/en/latest/topics/settings.html
+# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
+# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
+
+BOT_NAME = 'Crawlab Configurable Spider'
+
+SPIDER_MODULES = ['config_spider.spiders']
+NEWSPIDER_MODULE = 'config_spider.spiders'
+
+
+# Crawl responsibly by identifying yourself (and your website) on the user-agent
+USER_AGENT = 'Crawlab Spider'
+
+# Obey robots.txt rules
+ROBOTSTXT_OBEY = True
+
+# Configure maximum concurrent requests performed by Scrapy (default: 16)
+#CONCURRENT_REQUESTS = 32
+
+# Configure a delay for requests for the same website (default: 0)
+# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
+# See also autothrottle settings and docs
+#DOWNLOAD_DELAY = 3
+# The download delay setting will honor only one of:
+#CONCURRENT_REQUESTS_PER_DOMAIN = 16
+#CONCURRENT_REQUESTS_PER_IP = 16
+
+# Disable cookies (enabled by default)
+#COOKIES_ENABLED = False
+
+# Disable Telnet Console (enabled by default)
+#TELNETCONSOLE_ENABLED = False
+
+# Override the default request headers:
+#DEFAULT_REQUEST_HEADERS = {
+# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
+# 'Accept-Language': 'en',
+#}
+
+# Enable or disable spider middlewares
+# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
+#SPIDER_MIDDLEWARES = {
+# 'config_spider.middlewares.ConfigSpiderSpiderMiddleware': 543,
+#}
+
+# Enable or disable downloader middlewares
+# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
+#DOWNLOADER_MIDDLEWARES = {
+# 'config_spider.middlewares.ConfigSpiderDownloaderMiddleware': 543,
+#}
+
+# Enable or disable extensions
+# See https://docs.scrapy.org/en/latest/topics/extensions.html
+#EXTENSIONS = {
+# 'scrapy.extensions.telnet.TelnetConsole': None,
+#}
+
+# Configure item pipelines
+# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
+ITEM_PIPELINES = {
+ 'config_spider.pipelines.ConfigSpiderPipeline': 300,
+}
+
+# Enable and configure the AutoThrottle extension (disabled by default)
+# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
+#AUTOTHROTTLE_ENABLED = True
+# The initial download delay
+#AUTOTHROTTLE_START_DELAY = 5
+# The maximum download delay to be set in case of high latencies
+#AUTOTHROTTLE_MAX_DELAY = 60
+# The average number of requests Scrapy should be sending in parallel to
+# each remote server
+#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
+# Enable showing throttling stats for every response received:
+#AUTOTHROTTLE_DEBUG = False
+
+# Enable and configure HTTP caching (disabled by default)
+# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
+#HTTPCACHE_ENABLED = True
+#HTTPCACHE_EXPIRATION_SECS = 0
+#HTTPCACHE_DIR = 'httpcache'
+#HTTPCACHE_IGNORE_HTTP_CODES = []
+#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
+
+for setting_env_name in [x for x in os.environ.keys() if x.startswith('CRAWLAB_SETTING_')]:
+ setting_name = setting_env_name.replace('CRAWLAB_SETTING_', '')
+ setting_value = os.environ.get(setting_env_name)
+ if setting_value.lower() == 'true':
+ setting_value = True
+ elif setting_value.lower() == 'false':
+ setting_value = False
+ elif re.search(r'^\d+$', setting_value) is not None:
+ setting_value = int(setting_value)
+ elif re.search(r'^\{.*\}$', setting_value.strip()) is not None:
+ setting_value = json.loads(setting_value)
+ elif re.search(r'^\[.*\]$', setting_value.strip()) is not None:
+ setting_value = json.loads(setting_value)
+ else:
+ pass
+ locals()[setting_name] = setting_value
+
diff --git a/spiders/chinaz/chinaz/spiders/__init__.py b/backend/template/scrapy/config_spider/spiders/__init__.py
similarity index 100%
rename from spiders/chinaz/chinaz/spiders/__init__.py
rename to backend/template/scrapy/config_spider/spiders/__init__.py
diff --git a/backend/template/scrapy/config_spider/spiders/spider.py b/backend/template/scrapy/config_spider/spiders/spider.py
new file mode 100644
index 00000000..d87f4297
--- /dev/null
+++ b/backend/template/scrapy/config_spider/spiders/spider.py
@@ -0,0 +1,21 @@
+# -*- coding: utf-8 -*-
+import scrapy
+import re
+from config_spider.items import Item
+from urllib.parse import urljoin, urlparse
+
+def get_real_url(response, url):
+ if re.search(r'^https?', url):
+ return url
+ elif re.search(r'^\/\/', url):
+ u = urlparse(response.url)
+ return u.scheme + url
+ return urljoin(response.url, url)
+
+class ConfigSpider(scrapy.Spider):
+ name = 'config_spider'
+
+ def start_requests(self):
+ yield scrapy.Request(url='###START_URL###', callback=self.###START_STAGE###)
+
+###PARSERS###
diff --git a/backend/template/scrapy/scrapy.cfg b/backend/template/scrapy/scrapy.cfg
new file mode 100644
index 00000000..a78d91e3
--- /dev/null
+++ b/backend/template/scrapy/scrapy.cfg
@@ -0,0 +1,11 @@
+# Automatically created by: scrapy startproject
+#
+# For more information about the [deploy] section see:
+# https://scrapyd.readthedocs.io/en/latest/deploy.html
+
+[settings]
+default = config_spider.settings
+
+[deploy]
+#url = http://localhost:6800/
+project = config_spider
diff --git a/backend/template/spiderfile/Spiderfile.163_news b/backend/template/spiderfile/Spiderfile.163_news
new file mode 100644
index 00000000..b87b8888
--- /dev/null
+++ b/backend/template/spiderfile/Spiderfile.163_news
@@ -0,0 +1,19 @@
+name: "toscrapy_books"
+start_url: "http://news.163.com/special/0001386F/rank_news.html"
+start_stage: "list"
+engine: "scrapy"
+stages:
+- name: list
+ is_list: true
+ list_css: "table tr:not(:first-child)"
+ fields:
+ - name: "title"
+ css: "td:nth-child(1) > a"
+ - name: "url"
+ css: "td:nth-child(1) > a"
+ attr: "href"
+ - name: "clicks"
+ css: "td.cBlue"
+settings:
+ ROBOTSTXT_OBEY: false
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
diff --git a/backend/template/spiderfile/Spiderfile.baidu b/backend/template/spiderfile/Spiderfile.baidu
new file mode 100644
index 00000000..0259c64f
--- /dev/null
+++ b/backend/template/spiderfile/Spiderfile.baidu
@@ -0,0 +1,21 @@
+name: toscrapy_books
+start_url: http://www.baidu.com/s?wd=crawlab
+start_stage: list
+engine: scrapy
+stages:
+- name: list
+ is_list: true
+ list_xpath: //*[contains(@class, "c-container")]
+ page_xpath: //*[@id="page"]//a[@class="n"][last()]
+ page_attr: href
+ fields:
+ - name: title
+ xpath: .//h3/a
+ - name: url
+ xpath: .//h3/a
+ attr: href
+ - name: abstract
+ xpath: .//*[@class="c-abstract"]
+settings:
+ ROBOTSTXT_OBEY: false
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
diff --git a/backend/template/spiderfile/Spiderfile.toscrapy_books b/backend/template/spiderfile/Spiderfile.toscrapy_books
new file mode 100644
index 00000000..d9100e21
--- /dev/null
+++ b/backend/template/spiderfile/Spiderfile.toscrapy_books
@@ -0,0 +1,27 @@
+name: "toscrapy_books"
+start_url: "http://books.toscrape.com"
+start_stage: "list"
+engine: "scrapy"
+stages:
+- name: list
+ is_list: true
+ list_css: "section article.product_pod"
+ page_css: "ul.pager li.next a"
+ page_attr: "href"
+ fields:
+ - name: "title"
+ css: "h3 > a"
+ - name: "url"
+ css: "h3 > a"
+ attr: "href"
+ next_stage: "detail"
+ - name: "price"
+ css: ".product_price > .price_color"
+- name: detail
+ is_list: false
+ fields:
+ - name: "description"
+ css: "#product_description + p"
+settings:
+ ROBOTSTXT_OBEY: true
+ AUTOTHROTTLE_ENABLED: true
diff --git a/backend/template/spiders/amazon_config/Spiderfile b/backend/template/spiders/amazon_config/Spiderfile
new file mode 100644
index 00000000..eea8a538
--- /dev/null
+++ b/backend/template/spiders/amazon_config/Spiderfile
@@ -0,0 +1,51 @@
+name: "amazon_config"
+display_name: "亚马逊中国(可配置)"
+remark: "亚马逊中国搜索手机,列表+分页"
+type: "configurable"
+col: "results_amazon_config"
+engine: scrapy
+start_url: https://www.amazon.cn/s?k=%E6%89%8B%E6%9C%BA&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&ref=nb_sb_noss_2
+start_stage: list
+stages:
+- name: list
+ is_list: true
+ list_css: .s-result-item
+ list_xpath: ""
+ page_css: .a-last > a
+ page_xpath: ""
+ page_attr: href
+ fields:
+ - name: title
+ css: span.a-text-normal
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: url
+ css: .a-link-normal
+ xpath: ""
+ attr: href
+ next_stage: ""
+ remark: ""
+ - name: price
+ css: ""
+ xpath: .//*[@class="a-price-whole"]
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: price_fraction
+ css: ""
+ xpath: .//*[@class="a-price-fraction"]
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: img
+ css: .s-image-square-aspect > img
+ xpath: ""
+ attr: src
+ next_stage: ""
+ remark: ""
+settings:
+ ROBOTSTXT_OBEY: "false"
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
+ like Gecko) Chrome/78.0.3904.108 Safari/537.36
diff --git a/backend/template/spiders/autohome_config/Spiderfile b/backend/template/spiders/autohome_config/Spiderfile
new file mode 100644
index 00000000..e69880cb
--- /dev/null
+++ b/backend/template/spiders/autohome_config/Spiderfile
@@ -0,0 +1,57 @@
+name: "autohome_config"
+display_name: "汽车之家(可配置)"
+remark: "汽车之家文章,列表+详情+分页"
+type: "configurable"
+col: "results_autohome_config"
+engine: scrapy
+start_url: https://www.autohome.com.cn/all/
+start_stage: list
+stages:
+- name: list
+ is_list: true
+ list_css: ul.article > li
+ list_xpath: ""
+ page_css: a.page-item-next
+ page_xpath: ""
+ page_attr: href
+ fields:
+ - name: title
+ css: li > a > h3
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: url
+ css: li > a
+ xpath: ""
+ attr: href
+ next_stage: ""
+ remark: ""
+ - name: abstract
+ css: li > a > p
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: time
+ css: li > a .fn-left
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: views
+ css: li > a .fn-right > em:first-child
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: comments
+ css: li > a .fn-right > em:last-child
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+settings:
+ ROBOTSTXT_OBEY: "false"
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
+ like Gecko) Chrome/78.0.3904.108 Safari/537.36
diff --git a/backend/template/spiders/baidu_config/Spiderfile b/backend/template/spiders/baidu_config/Spiderfile
new file mode 100644
index 00000000..a29d4acb
--- /dev/null
+++ b/backend/template/spiders/baidu_config/Spiderfile
@@ -0,0 +1,39 @@
+name: "baidu_config"
+display_name: "百度搜索(可配置)"
+remark: "百度搜索Crawlab,列表+分页"
+type: "configurable"
+col: "results_baidu_config"
+engine: scrapy
+start_url: http://www.baidu.com/s?wd=crawlab
+start_stage: list
+stages:
+- name: list
+ is_list: true
+ list_css: ".result.c-container"
+ list_xpath: ""
+ page_css: "a.n"
+ page_xpath: ""
+ page_attr: href
+ fields:
+ - name: title
+ css: ""
+ xpath: .//h3/a
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: url
+ css: ""
+ xpath: .//h3/a
+ attr: href
+ next_stage: ""
+ remark: ""
+ - name: abstract
+ css: ""
+ xpath: .//*[@class="c-abstract"]
+ attr: ""
+ next_stage: ""
+ remark: ""
+settings:
+ ROBOTSTXT_OBEY: "false"
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
+ like Gecko) Chrome/78.0.3904.108 Safari/537.36
diff --git a/backend/template/spiders/bing_general/Spiderfile b/backend/template/spiders/bing_general/Spiderfile
new file mode 100644
index 00000000..614c135e
--- /dev/null
+++ b/backend/template/spiders/bing_general/Spiderfile
@@ -0,0 +1,6 @@
+name: "bing_general"
+display_name: "必应搜索 (通用)"
+remark: "必应搜索 Crawlab,列表+分页"
+col: "results_bing_general"
+type: "customized"
+cmd: "python bing_spider.py"
\ No newline at end of file
diff --git a/backend/template/spiders/bing_general/bing_spider.py b/backend/template/spiders/bing_general/bing_spider.py
new file mode 100644
index 00000000..e982e4ee
--- /dev/null
+++ b/backend/template/spiders/bing_general/bing_spider.py
@@ -0,0 +1,41 @@
+import requests
+from bs4 import BeautifulSoup as bs
+from urllib.parse import urljoin, urlparse
+import re
+from crawlab import save_item
+
+s = requests.Session()
+
+def get_real_url(response, url):
+ if re.search(r'^https?', url):
+ return url
+ elif re.search(r'^\/\/', url):
+ u = urlparse(response.url)
+ return u.scheme + url
+ return urljoin(response.url, url)
+
+def start_requests():
+ for i in range(0, 9):
+ fr = 'PERE' if not i else 'MORE'
+ url = f'https://cn.bing.com/search?q=crawlab&first={10 * i + 1}&FROM={fr}'
+ request_page(url)
+
+def request_page(url):
+ print(f'requesting {url}')
+ r = s.get(url, headers={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'})
+ parse_list(r)
+
+def parse_list(response):
+ soup = bs(response.content.decode('utf-8'))
+ for el in list(soup.select('#b_results > li')):
+ try:
+ save_item({
+ 'title': el.select_one('h2').text,
+ 'url': el.select_one('h2 a').attrs.get('href'),
+ 'abstract': el.select_one('.b_caption p').text,
+ })
+ except:
+ pass
+
+if __name__ == '__main__':
+ start_requests()
\ No newline at end of file
diff --git a/backend/template/spiders/chinaz/Spiderfile b/backend/template/spiders/chinaz/Spiderfile
new file mode 100644
index 00000000..2fb940bb
--- /dev/null
+++ b/backend/template/spiders/chinaz/Spiderfile
@@ -0,0 +1,5 @@
+name: "chinaz"
+display_name: "站长之家 (Scrapy)"
+col: "results_chinaz"
+type: "customized"
+cmd: "scrapy crawl chinaz_spider"
\ No newline at end of file
diff --git a/spiders/jd/jd/__init__.py b/backend/template/spiders/chinaz/chinaz/__init__.py
similarity index 100%
rename from spiders/jd/jd/__init__.py
rename to backend/template/spiders/chinaz/chinaz/__init__.py
diff --git a/spiders/chinaz/chinaz/items.py b/backend/template/spiders/chinaz/chinaz/items.py
similarity index 100%
rename from spiders/chinaz/chinaz/items.py
rename to backend/template/spiders/chinaz/chinaz/items.py
diff --git a/spiders/chinaz/chinaz/middlewares.py b/backend/template/spiders/chinaz/chinaz/middlewares.py
similarity index 100%
rename from spiders/chinaz/chinaz/middlewares.py
rename to backend/template/spiders/chinaz/chinaz/middlewares.py
diff --git a/backend/template/spiders/chinaz/chinaz/pipelines.py b/backend/template/spiders/chinaz/chinaz/pipelines.py
new file mode 100644
index 00000000..b29f9eb7
--- /dev/null
+++ b/backend/template/spiders/chinaz/chinaz/pipelines.py
@@ -0,0 +1,7 @@
+# -*- coding: utf-8 -*-
+
+# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
+
diff --git a/spiders/chinaz/chinaz/settings.py b/backend/template/spiders/chinaz/chinaz/settings.py
similarity index 98%
rename from spiders/chinaz/chinaz/settings.py
rename to backend/template/spiders/chinaz/chinaz/settings.py
index 41fb31bf..932ec9ed 100644
--- a/spiders/chinaz/chinaz/settings.py
+++ b/backend/template/spiders/chinaz/chinaz/settings.py
@@ -65,7 +65,7 @@ ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
- 'chinaz.pipelines.MongoPipeline': 300,
+ 'crawlab.pipelines.CrawlabMongoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
diff --git a/spiders/jd/jd/spiders/__init__.py b/backend/template/spiders/chinaz/chinaz/spiders/__init__.py
similarity index 100%
rename from spiders/jd/jd/spiders/__init__.py
rename to backend/template/spiders/chinaz/chinaz/spiders/__init__.py
diff --git a/spiders/chinaz/chinaz/spiders/chinaz_spider.py b/backend/template/spiders/chinaz/chinaz/spiders/chinaz_spider.py
similarity index 100%
rename from spiders/chinaz/chinaz/spiders/chinaz_spider.py
rename to backend/template/spiders/chinaz/chinaz/spiders/chinaz_spider.py
diff --git a/spiders/chinaz/scrapy.cfg b/backend/template/spiders/chinaz/scrapy.cfg
similarity index 100%
rename from spiders/chinaz/scrapy.cfg
rename to backend/template/spiders/chinaz/scrapy.cfg
diff --git a/spiders/csdn/csdn_spider.js b/backend/template/spiders/csdn/csdn_spider.js
similarity index 100%
rename from spiders/csdn/csdn_spider.js
rename to backend/template/spiders/csdn/csdn_spider.js
diff --git a/backend/template/spiders/csdn_config/Spiderfile b/backend/template/spiders/csdn_config/Spiderfile
new file mode 100644
index 00000000..67f4f8c5
--- /dev/null
+++ b/backend/template/spiders/csdn_config/Spiderfile
@@ -0,0 +1,60 @@
+name: "csdn_config"
+display_name: "CSDN(可配置)"
+remark: "CSDN Crawlab 文章,列表+详情+分页"
+type: "configurable"
+col: "results_csdn_config"
+engine: scrapy
+start_url: https://so.csdn.net/so/search/s.do?q=crawlab
+start_stage: list
+stages:
+- name: list
+ is_list: true
+ list_css: .search-list-con > .search-list
+ list_xpath: ""
+ page_css: a.btn-next
+ page_xpath: ""
+ page_attr: href
+ fields:
+ - name: url
+ css: ""
+ xpath: .//*[@class="limit_width"]/a
+ attr: href
+ next_stage: detail
+ remark: ""
+- name: detail
+ is_list: false
+ list_css: ""
+ list_xpath: ""
+ page_css: ""
+ page_xpath: ""
+ page_attr: ""
+ fields:
+ - name: content
+ css: ""
+ xpath: .//div[@id="content_views"]
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: views
+ css: .read-count
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: title
+ css: .title-article
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: author
+ css: .follow-nickName
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+settings:
+ AUTOTHROTTLE_ENABLED: "false"
+ ROBOTSTXT_OBEY: "false"
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
+ like Gecko) Chrome/79.0.3945.117 Safari/537.36
diff --git a/backend/template/spiders/douban_config/Spiderfile b/backend/template/spiders/douban_config/Spiderfile
new file mode 100644
index 00000000..84f0647a
--- /dev/null
+++ b/backend/template/spiders/douban_config/Spiderfile
@@ -0,0 +1,57 @@
+name: "douban_config"
+display_name: "豆瓣读书(可配置)"
+remark: "豆瓣读书新书推荐,列表"
+type: "configurable"
+col: "results_douban_config"
+engine: scrapy
+start_url: https://book.douban.com/latest
+start_stage: list
+stages:
+- name: list
+ is_list: true
+ list_css: ul.cover-col-4 > li
+ list_xpath: ""
+ page_css: ""
+ page_xpath: ""
+ page_attr: ""
+ fields:
+ - name: title
+ css: h2 > a
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: url
+ css: h2 > a
+ xpath: ""
+ attr: href
+ next_stage: ""
+ remark: ""
+ - name: img
+ css: a.cover img
+ xpath: ""
+ attr: src
+ next_stage: ""
+ remark: ""
+ - name: rating
+ css: p.rating > .color-lightgray
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: abstract
+ css: p:last-child
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: info
+ css: .color-gray
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+settings:
+ ROBOTSTXT_OBEY: "false"
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
+ like Gecko) Chrome/78.0.3904.108 Safari/537.36
diff --git a/backend/template/spiders/jd/Spiderfile b/backend/template/spiders/jd/Spiderfile
new file mode 100644
index 00000000..d090472b
--- /dev/null
+++ b/backend/template/spiders/jd/Spiderfile
@@ -0,0 +1,5 @@
+name: "jd"
+display_name: "京东 (Scrapy)"
+col: "results_jd"
+type: "customized"
+cmd: "scrapy crawl jd_spider"
\ No newline at end of file
diff --git a/spiders/realestate/realestate/__init__.py b/backend/template/spiders/jd/jd/__init__.py
similarity index 100%
rename from spiders/realestate/realestate/__init__.py
rename to backend/template/spiders/jd/jd/__init__.py
diff --git a/spiders/jd/jd/items.py b/backend/template/spiders/jd/jd/items.py
similarity index 92%
rename from spiders/jd/jd/items.py
rename to backend/template/spiders/jd/jd/items.py
index 9a7ba1cb..b2c5e647 100644
--- a/spiders/jd/jd/items.py
+++ b/backend/template/spiders/jd/jd/items.py
@@ -12,3 +12,4 @@ class JdItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
price = scrapy.Field()
+ url = scrapy.Field()
diff --git a/spiders/jd/jd/middlewares.py b/backend/template/spiders/jd/jd/middlewares.py
similarity index 100%
rename from spiders/jd/jd/middlewares.py
rename to backend/template/spiders/jd/jd/middlewares.py
diff --git a/backend/template/spiders/jd/jd/pipelines.py b/backend/template/spiders/jd/jd/pipelines.py
new file mode 100644
index 00000000..5a7d7cbf
--- /dev/null
+++ b/backend/template/spiders/jd/jd/pipelines.py
@@ -0,0 +1,6 @@
+# -*- coding: utf-8 -*-
+
+# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
diff --git a/spiders/jd/jd/settings.py b/backend/template/spiders/jd/jd/settings.py
similarity index 97%
rename from spiders/jd/jd/settings.py
rename to backend/template/spiders/jd/jd/settings.py
index d83206b2..ef89ed0c 100644
--- a/spiders/jd/jd/settings.py
+++ b/backend/template/spiders/jd/jd/settings.py
@@ -19,7 +19,7 @@ NEWSPIDER_MODULE = 'jd.spiders'
#USER_AGENT = 'jd (+http://www.yourdomain.com)'
# Obey robots.txt rules
-ROBOTSTXT_OBEY = True
+ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
@@ -65,7 +65,7 @@ ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
- 'jd.pipelines.JdPipeline': 300,
+ 'crawlab.pipelines.CrawlabMongoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
diff --git a/spiders/realestate/realestate/spiders/__init__.py b/backend/template/spiders/jd/jd/spiders/__init__.py
similarity index 100%
rename from spiders/realestate/realestate/spiders/__init__.py
rename to backend/template/spiders/jd/jd/spiders/__init__.py
diff --git a/backend/template/spiders/jd/jd/spiders/jd_spider.py b/backend/template/spiders/jd/jd/spiders/jd_spider.py
new file mode 100644
index 00000000..4ec94fa9
--- /dev/null
+++ b/backend/template/spiders/jd/jd/spiders/jd_spider.py
@@ -0,0 +1,21 @@
+# -*- coding: utf-8 -*-
+import scrapy
+
+from jd.items import JdItem
+
+
+class JdSpiderSpider(scrapy.Spider):
+ name = 'jd_spider'
+ allowed_domains = ['jd.com']
+
+ def start_requests(self):
+ for i in range(1, 50):
+ yield scrapy.Request(url=f'https://search.jd.com/Search?keyword=手机&enc=utf-8&page={i}')
+
+ def parse(self, response):
+ for el in response.css('.gl-item'):
+ yield JdItem(
+ url=el.css('.p-name > a::attr("href")').extract_first(),
+ name=el.css('.p-name > a::attr("title")').extract_first(),
+ price=float(el.css('.p-price i::text').extract_first()),
+ )
diff --git a/spiders/jd/scrapy.cfg b/backend/template/spiders/jd/scrapy.cfg
similarity index 100%
rename from spiders/jd/scrapy.cfg
rename to backend/template/spiders/jd/scrapy.cfg
diff --git a/spiders/juejin_node/juejin_spider.js b/backend/template/spiders/juejin_node/juejin_spider.js
similarity index 100%
rename from spiders/juejin_node/juejin_spider.js
rename to backend/template/spiders/juejin_node/juejin_spider.js
diff --git a/backend/template/spiders/realestate/Spiderfile b/backend/template/spiders/realestate/Spiderfile
new file mode 100644
index 00000000..772e8312
--- /dev/null
+++ b/backend/template/spiders/realestate/Spiderfile
@@ -0,0 +1,4 @@
+name: "realestate"
+display_name: "链家网 (Scrapy)"
+col: "results_realestate"
+cmd: "scrapy crawl lianjia"
\ No newline at end of file
diff --git a/spiders/sinastock/sinastock/__init__.py b/backend/template/spiders/realestate/realestate/__init__.py
similarity index 100%
rename from spiders/sinastock/sinastock/__init__.py
rename to backend/template/spiders/realestate/realestate/__init__.py
diff --git a/spiders/realestate/realestate/items.py b/backend/template/spiders/realestate/realestate/items.py
similarity index 100%
rename from spiders/realestate/realestate/items.py
rename to backend/template/spiders/realestate/realestate/items.py
diff --git a/spiders/realestate/realestate/middlewares.py b/backend/template/spiders/realestate/realestate/middlewares.py
similarity index 100%
rename from spiders/realestate/realestate/middlewares.py
rename to backend/template/spiders/realestate/realestate/middlewares.py
diff --git a/backend/template/spiders/realestate/realestate/pipelines.py b/backend/template/spiders/realestate/realestate/pipelines.py
new file mode 100644
index 00000000..3371792b
--- /dev/null
+++ b/backend/template/spiders/realestate/realestate/pipelines.py
@@ -0,0 +1,6 @@
+# -*- coding: utf-8 -*-
+
+# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
diff --git a/spiders/realestate/realestate/settings.py b/backend/template/spiders/realestate/realestate/settings.py
similarity index 98%
rename from spiders/realestate/realestate/settings.py
rename to backend/template/spiders/realestate/realestate/settings.py
index da1ada29..758f8ed0 100644
--- a/spiders/realestate/realestate/settings.py
+++ b/backend/template/spiders/realestate/realestate/settings.py
@@ -64,7 +64,7 @@ ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
- 'realestate.pipelines.MongoPipeline': 300,
+ 'crawlab.pipelines.CrawlabMongoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
diff --git a/spiders/sinastock/sinastock/spiders/__init__.py b/backend/template/spiders/realestate/realestate/spiders/__init__.py
similarity index 100%
rename from spiders/sinastock/sinastock/spiders/__init__.py
rename to backend/template/spiders/realestate/realestate/spiders/__init__.py
diff --git a/spiders/realestate/realestate/spiders/lianjia.py b/backend/template/spiders/realestate/realestate/spiders/lianjia.py
similarity index 100%
rename from spiders/realestate/realestate/spiders/lianjia.py
rename to backend/template/spiders/realestate/realestate/spiders/lianjia.py
diff --git a/spiders/realestate/scrapy.cfg b/backend/template/spiders/realestate/scrapy.cfg
similarity index 100%
rename from spiders/realestate/scrapy.cfg
rename to backend/template/spiders/realestate/scrapy.cfg
diff --git a/spiders/segmentfault/segmentfault_spider.js b/backend/template/spiders/segmentfault/segmentfault_spider.js
similarity index 100%
rename from spiders/segmentfault/segmentfault_spider.js
rename to backend/template/spiders/segmentfault/segmentfault_spider.js
diff --git a/backend/template/spiders/sinastock/Spiderfile b/backend/template/spiders/sinastock/Spiderfile
new file mode 100644
index 00000000..b110cb48
--- /dev/null
+++ b/backend/template/spiders/sinastock/Spiderfile
@@ -0,0 +1,5 @@
+name: "sinastock"
+display_name: "新浪股票 (Scrapy)"
+type: "customized"
+col: "results_sinastock"
+cmd: "scrapy crawl sinastock_spider"
\ No newline at end of file
diff --git a/spiders/sinastock/scrapy.cfg b/backend/template/spiders/sinastock/scrapy.cfg
similarity index 100%
rename from spiders/sinastock/scrapy.cfg
rename to backend/template/spiders/sinastock/scrapy.cfg
diff --git a/spiders/xueqiu/xueqiu/__init__.py b/backend/template/spiders/sinastock/sinastock/__init__.py
similarity index 100%
rename from spiders/xueqiu/xueqiu/__init__.py
rename to backend/template/spiders/sinastock/sinastock/__init__.py
diff --git a/spiders/sinastock/sinastock/items.py b/backend/template/spiders/sinastock/sinastock/items.py
similarity index 100%
rename from spiders/sinastock/sinastock/items.py
rename to backend/template/spiders/sinastock/sinastock/items.py
diff --git a/spiders/sinastock/sinastock/middlewares.py b/backend/template/spiders/sinastock/sinastock/middlewares.py
similarity index 100%
rename from spiders/sinastock/sinastock/middlewares.py
rename to backend/template/spiders/sinastock/sinastock/middlewares.py
diff --git a/backend/template/spiders/sinastock/sinastock/pipelines.py b/backend/template/spiders/sinastock/sinastock/pipelines.py
new file mode 100644
index 00000000..5a7d7cbf
--- /dev/null
+++ b/backend/template/spiders/sinastock/sinastock/pipelines.py
@@ -0,0 +1,6 @@
+# -*- coding: utf-8 -*-
+
+# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
diff --git a/spiders/sinastock/sinastock/settings.py b/backend/template/spiders/sinastock/sinastock/settings.py
similarity index 98%
rename from spiders/sinastock/sinastock/settings.py
rename to backend/template/spiders/sinastock/sinastock/settings.py
index c63c2eb5..3e01d3ca 100644
--- a/spiders/sinastock/sinastock/settings.py
+++ b/backend/template/spiders/sinastock/sinastock/settings.py
@@ -64,7 +64,7 @@ ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
- 'sinastock.pipelines.SinastockPipeline': 300,
+ 'crawlab.pipelines.CrawlabMongoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
diff --git a/spiders/xueqiu/xueqiu/spiders/__init__.py b/backend/template/spiders/sinastock/sinastock/spiders/__init__.py
similarity index 100%
rename from spiders/xueqiu/xueqiu/spiders/__init__.py
rename to backend/template/spiders/sinastock/sinastock/spiders/__init__.py
diff --git a/spiders/sinastock/sinastock/spiders/sinastock_spider.py b/backend/template/spiders/sinastock/sinastock/spiders/sinastock_spider.py
similarity index 100%
rename from spiders/sinastock/sinastock/spiders/sinastock_spider.py
rename to backend/template/spiders/sinastock/sinastock/spiders/sinastock_spider.py
diff --git a/spiders/sites_inspector/sites_inspector.py b/backend/template/spiders/sites_inspector/sites_inspector.py
similarity index 100%
rename from spiders/sites_inspector/sites_inspector.py
rename to backend/template/spiders/sites_inspector/sites_inspector.py
diff --git a/backend/template/spiders/v2ex_config/Spiderfile b/backend/template/spiders/v2ex_config/Spiderfile
new file mode 100644
index 00000000..bb18d40a
--- /dev/null
+++ b/backend/template/spiders/v2ex_config/Spiderfile
@@ -0,0 +1,54 @@
+name: "v2ex_config"
+display_name: "V2ex(可配置)"
+remark: "V2ex,列表+详情"
+type: "configurable"
+col: "results_v2ex_config"
+engine: scrapy
+start_url: https://v2ex.com/
+start_stage: list
+stages:
+- name: list
+ is_list: true
+ list_css: .cell.item
+ list_xpath: ""
+ page_css: ""
+ page_xpath: ""
+ page_attr: href
+ fields:
+ - name: title
+ css: a.topic-link
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: url
+ css: a.topic-link
+ xpath: ""
+ attr: href
+ next_stage: detail
+ remark: ""
+ - name: replies
+ css: .count_livid
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+- name: detail
+ is_list: false
+ list_css: ""
+ list_xpath: ""
+ page_css: ""
+ page_xpath: ""
+ page_attr: ""
+ fields:
+ - name: content
+ css: ""
+ xpath: .//*[@class="markdown_body"]
+ attr: ""
+ next_stage: ""
+ remark: ""
+settings:
+ AUTOTHROTTLE_ENABLED: "true"
+ ROBOTSTXT_OBEY: "false"
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
+ like Gecko) Chrome/79.0.3945.117 Safari/537.36
diff --git a/backend/template/spiders/xueqiu/Spiderfile b/backend/template/spiders/xueqiu/Spiderfile
new file mode 100644
index 00000000..38aa5dbe
--- /dev/null
+++ b/backend/template/spiders/xueqiu/Spiderfile
@@ -0,0 +1,5 @@
+name: "xueqiu"
+display_name: "雪球网 (Scrapy)"
+type: "customized"
+col: "results_xueqiu"
+cmd: "scrapy crawl xueqiu_spider"
\ No newline at end of file
diff --git a/spiders/xueqiu/scrapy.cfg b/backend/template/spiders/xueqiu/scrapy.cfg
similarity index 100%
rename from spiders/xueqiu/scrapy.cfg
rename to backend/template/spiders/xueqiu/scrapy.cfg
diff --git a/backend/template/spiders/xueqiu/xueqiu/__init__.py b/backend/template/spiders/xueqiu/xueqiu/__init__.py
new file mode 100644
index 00000000..e69de29b
diff --git a/spiders/xueqiu/xueqiu/items.py b/backend/template/spiders/xueqiu/xueqiu/items.py
similarity index 100%
rename from spiders/xueqiu/xueqiu/items.py
rename to backend/template/spiders/xueqiu/xueqiu/items.py
diff --git a/spiders/xueqiu/xueqiu/middlewares.py b/backend/template/spiders/xueqiu/xueqiu/middlewares.py
similarity index 100%
rename from spiders/xueqiu/xueqiu/middlewares.py
rename to backend/template/spiders/xueqiu/xueqiu/middlewares.py
diff --git a/backend/template/spiders/xueqiu/xueqiu/pipelines.py b/backend/template/spiders/xueqiu/xueqiu/pipelines.py
new file mode 100644
index 00000000..5a7d7cbf
--- /dev/null
+++ b/backend/template/spiders/xueqiu/xueqiu/pipelines.py
@@ -0,0 +1,6 @@
+# -*- coding: utf-8 -*-
+
+# Define your item pipelines here
+#
+# Don't forget to add your pipeline to the ITEM_PIPELINES setting
+# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
diff --git a/spiders/xueqiu/xueqiu/settings.py b/backend/template/spiders/xueqiu/xueqiu/settings.py
similarity index 97%
rename from spiders/xueqiu/xueqiu/settings.py
rename to backend/template/spiders/xueqiu/xueqiu/settings.py
index b44a74e1..1d898e2f 100644
--- a/spiders/xueqiu/xueqiu/settings.py
+++ b/backend/template/spiders/xueqiu/xueqiu/settings.py
@@ -18,7 +18,7 @@ NEWSPIDER_MODULE = 'xueqiu.spiders'
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
# Obey robots.txt rules
-ROBOTSTXT_OBEY = True
+ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
@@ -64,7 +64,7 @@ ROBOTSTXT_OBEY = True
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
- 'xueqiu.pipelines.XueqiuPipeline': 300,
+ 'crawlab.pipelines.CrawlabMongoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
diff --git a/backend/template/spiders/xueqiu/xueqiu/spiders/__init__.py b/backend/template/spiders/xueqiu/xueqiu/spiders/__init__.py
new file mode 100644
index 00000000..ebd689ac
--- /dev/null
+++ b/backend/template/spiders/xueqiu/xueqiu/spiders/__init__.py
@@ -0,0 +1,4 @@
+# This package will contain the spiders of your Scrapy project
+#
+# Please refer to the documentation for information on how to create and manage
+# your spiders.
diff --git a/spiders/xueqiu/xueqiu/spiders/xueqiu_spider.py b/backend/template/spiders/xueqiu/xueqiu/spiders/xueqiu_spider.py
similarity index 100%
rename from spiders/xueqiu/xueqiu/spiders/xueqiu_spider.py
rename to backend/template/spiders/xueqiu/xueqiu/spiders/xueqiu_spider.py
diff --git a/backend/template/spiders/xueqiu_config/Spiderfile b/backend/template/spiders/xueqiu_config/Spiderfile
new file mode 100644
index 00000000..0de50e9e
--- /dev/null
+++ b/backend/template/spiders/xueqiu_config/Spiderfile
@@ -0,0 +1,39 @@
+name: "xueqiu_config"
+display_name: "雪球网(可配置)"
+remark: "雪球网新闻,列表"
+type: "configurable"
+col: "results_xueqiu_config"
+engine: scrapy
+start_url: https://xueqiu.com/
+start_stage: list
+stages:
+- name: list
+ is_list: true
+ list_css: ""
+ list_xpath: .//*[contains(@class, "AnonymousHome_home__timeline__item")]
+ page_css: ""
+ page_xpath: ""
+ page_attr: ""
+ fields:
+ - name: title
+ css: h3 > a
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: url
+ css: h3 > a
+ xpath: ""
+ attr: href
+ next_stage: ""
+ remark: ""
+ - name: abstract
+ css: p
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+settings:
+ ROBOTSTXT_OBEY: "false"
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
+ like Gecko) Chrome/78.0.3904.108 Safari/537.36
diff --git a/backend/template/spiders/zongheng_config/Spiderfile b/backend/template/spiders/zongheng_config/Spiderfile
new file mode 100644
index 00000000..0163fac7
--- /dev/null
+++ b/backend/template/spiders/zongheng_config/Spiderfile
@@ -0,0 +1,45 @@
+name: "zongheng_config"
+display_name: "纵横(可配置)"
+remark: "纵横小说网,列表"
+type: "configurable"
+col: "results_zongheng_config"
+engine: scrapy
+start_url: http://www.zongheng.com/rank/details.html?rt=1&d=1
+start_stage: list
+stages:
+- name: list
+ is_list: true
+ list_css: .rank_d_list
+ list_xpath: ""
+ page_css: ""
+ page_xpath: ""
+ page_attr: href
+ fields:
+ - name: title
+ css: .rank_d_b_name > a
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: url
+ css: .rank_d_b_name > a
+ xpath: ""
+ attr: href
+ next_stage: ""
+ remark: ""
+ - name: abstract
+ css: body
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+ - name: votes
+ css: .rank_d_b_ticket
+ xpath: ""
+ attr: ""
+ next_stage: ""
+ remark: ""
+settings:
+ ROBOTSTXT_OBEY: "false"
+ USER_AGENT: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML,
+ like Gecko) Chrome/78.0.3904.108 Safari/537.36
diff --git a/backend/utils/array.go b/backend/utils/array.go
new file mode 100644
index 00000000..889430ed
--- /dev/null
+++ b/backend/utils/array.go
@@ -0,0 +1,10 @@
+package utils
+
+func StringArrayContains(arr []string, str string) bool {
+ for _, s := range arr {
+ if s == str {
+ return true
+ }
+ }
+ return false
+}
diff --git a/backend/utils/encrypt.go b/backend/utils/encrypt.go
new file mode 100644
index 00000000..52013b9c
--- /dev/null
+++ b/backend/utils/encrypt.go
@@ -0,0 +1,16 @@
+package utils
+
+import (
+ "crypto/hmac"
+ "crypto/sha256"
+ "encoding/base64"
+ "encoding/hex"
+)
+
+func ComputeHmacSha256(message string, secret string) string {
+ key := []byte(secret)
+ h := hmac.New(sha256.New, key)
+ h.Write([]byte(message))
+ sha := hex.EncodeToString(h.Sum(nil))
+ return base64.StdEncoding.EncodeToString([]byte(sha))
+}
diff --git a/backend/utils/file.go b/backend/utils/file.go
index babc0d69..072930cf 100644
--- a/backend/utils/file.go
+++ b/backend/utils/file.go
@@ -3,11 +3,15 @@ package utils
import (
"archive/zip"
"bufio"
+ "fmt"
"github.com/apex/log"
"io"
+ "io/ioutil"
"os"
+ "path"
"path/filepath"
"runtime/debug"
+ "strings"
)
// 删除文件
@@ -29,7 +33,14 @@ func ReadFileOneLine(fileName string) string {
return ""
}
return line
+}
+func GetSpiderMd5Str(file string) string {
+ md5Str := ReadFileOneLine(file)
+ // 去掉空格以及换行符
+ md5Str = strings.Replace(md5Str, " ", "", -1)
+ md5Str = strings.Replace(md5Str, "\n", "", -1)
+ return md5Str
}
// 创建文件
@@ -44,7 +55,7 @@ func OpenFile(fileName string) *os.File {
}
// 创建文件夹
-func CreateFilePath(filePath string) {
+func CreateDirPath(filePath string) {
if !Exists(filePath) {
if err := os.MkdirAll(filePath, os.ModePerm); err != nil {
log.Errorf("create file error: %s, file_path: %s", err.Error(), filePath)
@@ -71,6 +82,16 @@ func IsDir(path string) bool {
return s.IsDir()
}
+func ListDir(path string) []os.FileInfo {
+ list, err := ioutil.ReadDir(path)
+ if err != nil {
+ log.Errorf(err.Error())
+ debug.PrintStack()
+ return nil
+ }
+ return list
+}
+
// 判断所给路径是否为文件
func IsFile(path string) bool {
return !IsDir(path)
@@ -153,7 +174,6 @@ func DeCompress(srcFile *os.File, dstPath string) error {
debug.PrintStack()
continue
}
- defer Close(newFile)
// 拷贝该文件到新文件中
if _, err := io.Copy(newFile, srcFile); err != nil {
@@ -185,8 +205,7 @@ func Compress(files []*os.File, dest string) error {
w := zip.NewWriter(d)
defer Close(w)
for _, file := range files {
- err := _Compress(file, "", w)
- if err != nil {
+ if err := _Compress(file, "", w); err != nil {
return err
}
}
@@ -239,3 +258,128 @@ func _Compress(file *os.File, prefix string, zw *zip.Writer) error {
}
return nil
}
+
+func GetFilesFromDir(dirPath string) ([]*os.File, error) {
+ var res []*os.File
+ for _, fInfo := range ListDir(dirPath) {
+ f, err := os.Open(filepath.Join(dirPath, fInfo.Name()))
+ if err != nil {
+ return res, err
+ }
+ res = append(res, f)
+ }
+ return res, nil
+}
+
+func GetAllFilesFromDir(dirPath string) ([]*os.File, error) {
+ var res []*os.File
+ if err := filepath.Walk(dirPath, func(path string, info os.FileInfo, err error) error {
+ if !IsDir(path) {
+ f, err2 := os.Open(path)
+ if err2 != nil {
+ return err
+ }
+ res = append(res, f)
+ }
+ return nil
+ }); err != nil {
+ log.Error(err.Error())
+ debug.PrintStack()
+ return res, err
+ }
+ return res, nil
+}
+
+// File copies a single file from src to dst
+func CopyFile(src, dst string) error {
+ var err error
+ var srcFd *os.File
+ var dstFd *os.File
+ var srcInfo os.FileInfo
+
+ if srcFd, err = os.Open(src); err != nil {
+ return err
+ }
+ defer srcFd.Close()
+
+ if dstFd, err = os.Create(dst); err != nil {
+ return err
+ }
+ defer dstFd.Close()
+
+ if _, err = io.Copy(dstFd, srcFd); err != nil {
+ return err
+ }
+ if srcInfo, err = os.Stat(src); err != nil {
+ return err
+ }
+ return os.Chmod(dst, srcInfo.Mode())
+}
+
+// Dir copies a whole directory recursively
+func CopyDir(src string, dst string) error {
+ var err error
+ var fds []os.FileInfo
+ var srcInfo os.FileInfo
+
+ if srcInfo, err = os.Stat(src); err != nil {
+ return err
+ }
+
+ if err = os.MkdirAll(dst, srcInfo.Mode()); err != nil {
+ return err
+ }
+
+ if fds, err = ioutil.ReadDir(src); err != nil {
+ return err
+ }
+ for _, fd := range fds {
+ srcfp := path.Join(src, fd.Name())
+ dstfp := path.Join(dst, fd.Name())
+
+ if fd.IsDir() {
+ if err = CopyDir(srcfp, dstfp); err != nil {
+ fmt.Println(err)
+ }
+ } else {
+ if err = CopyFile(srcfp, dstfp); err != nil {
+ fmt.Println(err)
+ }
+ }
+ }
+ return nil
+}
+
+// 设置文件变量值
+// 可以理解为将文件中的变量占位符替换为想要设置的值
+func SetFileVariable(filePath string, key string, value string) error {
+ // 占位符标识
+ sep := "###"
+
+ // 读取文件到字节
+ contentBytes, err := ioutil.ReadFile(filePath)
+ if err != nil {
+ return err
+ }
+
+ // 将字节转化为文本
+ content := string(contentBytes)
+
+ // 替换文本
+ content = strings.Replace(content, fmt.Sprintf("%s%s%s", sep, key, sep), value, -1)
+
+ // 打开文件
+ f, err := os.OpenFile(filePath, os.O_WRONLY|os.O_TRUNC, 0777)
+ if err != nil {
+ return err
+ }
+
+ // 将替换后的内容写入文件
+ if _, err := f.Write([]byte(content)); err != nil {
+ return err
+ }
+
+ f.Close()
+
+ return nil
+}
diff --git a/backend/utils/helpers.go b/backend/utils/helpers.go
index 541d9002..e181c66c 100644
--- a/backend/utils/helpers.go
+++ b/backend/utils/helpers.go
@@ -6,6 +6,7 @@ import (
"github.com/apex/log"
"github.com/gomodule/redigo/redis"
"io"
+ "reflect"
"runtime/debug"
"unsafe"
)
@@ -37,6 +38,23 @@ func GetMessage(message redis.Message) *entity.NodeMessage {
func Close(c io.Closer) {
err := c.Close()
if err != nil {
- log.WithError(err).Error("关闭资源文件失败。")
+ //log.WithError(err).Error("关闭资源文件失败。")
}
}
+
+func Contains(array interface{}, val interface{}) (fla bool) {
+ fla = false
+ switch reflect.TypeOf(array).Kind() {
+ case reflect.Slice:
+ {
+ s := reflect.ValueOf(array)
+ for i := 0; i < s.Len(); i++ {
+ if reflect.DeepEqual(val, s.Index(i).Interface()) {
+ fla = true
+ return
+ }
+ }
+ }
+ }
+ return
+}
diff --git a/backend/utils/model.go b/backend/utils/model.go
index 21a295d6..048b0001 100644
--- a/backend/utils/model.go
+++ b/backend/utils/model.go
@@ -2,9 +2,9 @@ package utils
import (
"crawlab/constants"
+ "encoding/json"
"github.com/globalsign/mgo/bson"
- "strconv"
- "time"
+ "strings"
)
func IsObjectIdNull(id bson.ObjectId) bool {
@@ -12,16 +12,13 @@ func IsObjectIdNull(id bson.ObjectId) bool {
}
func InterfaceToString(value interface{}) string {
- switch realValue := value.(type) {
- case bson.ObjectId:
- return realValue.Hex()
- case string:
- return realValue
- case int:
- return strconv.Itoa(realValue)
- case time.Time:
- return realValue.String()
- default:
+ bytes, err := json.Marshal(value)
+ if err != nil {
return ""
}
+ str := string(bytes)
+ if strings.HasPrefix(str, "\"") && strings.HasSuffix(str, "\"") {
+ str = str[1 : len(str)-1]
+ }
+ return str
}
diff --git a/backend/utils/time.go b/backend/utils/time.go
new file mode 100644
index 00000000..84b40f4e
--- /dev/null
+++ b/backend/utils/time.go
@@ -0,0 +1,16 @@
+package utils
+
+import "time"
+
+func GetLocalTime(t time.Time) time.Time {
+ return t.In(time.Local)
+}
+
+func GetTimeString(t time.Time) string {
+ return t.Format("2006-01-02 15:04:05")
+}
+
+func GetLocalTimeString(t time.Time) string {
+ t = GetLocalTime(t)
+ return GetTimeString(t)
+}
diff --git a/backend/vendor/github.com/Masterminds/semver/.travis.yml b/backend/vendor/github.com/Masterminds/semver/.travis.yml
new file mode 100644
index 00000000..3d9ebadb
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/.travis.yml
@@ -0,0 +1,27 @@
+language: go
+
+go:
+ - 1.6.x
+ - 1.7.x
+ - 1.8.x
+ - 1.9.x
+ - 1.10.x
+ - tip
+
+# Setting sudo access to false will let Travis CI use containers rather than
+# VMs to run the tests. For more details see:
+# - http://docs.travis-ci.com/user/workers/container-based-infrastructure/
+# - http://docs.travis-ci.com/user/workers/standard-infrastructure/
+sudo: false
+
+script:
+ - make setup
+ - make test
+
+notifications:
+ webhooks:
+ urls:
+ - https://webhooks.gitter.im/e/06e3328629952dabe3e0
+ on_success: change # options: [always|never|change] default: always
+ on_failure: always # options: [always|never|change] default: always
+ on_start: never # options: [always|never|change] default: always
diff --git a/backend/vendor/github.com/Masterminds/semver/CHANGELOG.md b/backend/vendor/github.com/Masterminds/semver/CHANGELOG.md
new file mode 100644
index 00000000..b888e20a
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/CHANGELOG.md
@@ -0,0 +1,86 @@
+# 1.4.2 (2018-04-10)
+
+## Changed
+- #72: Updated the docs to point to vert for a console appliaction
+- #71: Update the docs on pre-release comparator handling
+
+## Fixed
+- #70: Fix the handling of pre-releases and the 0.0.0 release edge case
+
+# 1.4.1 (2018-04-02)
+
+## Fixed
+- Fixed #64: Fix pre-release precedence issue (thanks @uudashr)
+
+# 1.4.0 (2017-10-04)
+
+## Changed
+- #61: Update NewVersion to parse ints with a 64bit int size (thanks @zknill)
+
+# 1.3.1 (2017-07-10)
+
+## Fixed
+- Fixed #57: number comparisons in prerelease sometimes inaccurate
+
+# 1.3.0 (2017-05-02)
+
+## Added
+- #45: Added json (un)marshaling support (thanks @mh-cbon)
+- Stability marker. See https://masterminds.github.io/stability/
+
+## Fixed
+- #51: Fix handling of single digit tilde constraint (thanks @dgodd)
+
+## Changed
+- #55: The godoc icon moved from png to svg
+
+# 1.2.3 (2017-04-03)
+
+## Fixed
+- #46: Fixed 0.x.x and 0.0.x in constraints being treated as *
+
+# Release 1.2.2 (2016-12-13)
+
+## Fixed
+- #34: Fixed issue where hyphen range was not working with pre-release parsing.
+
+# Release 1.2.1 (2016-11-28)
+
+## Fixed
+- #24: Fixed edge case issue where constraint "> 0" does not handle "0.0.1-alpha"
+ properly.
+
+# Release 1.2.0 (2016-11-04)
+
+## Added
+- #20: Added MustParse function for versions (thanks @adamreese)
+- #15: Added increment methods on versions (thanks @mh-cbon)
+
+## Fixed
+- Issue #21: Per the SemVer spec (section 9) a pre-release is unstable and
+ might not satisfy the intended compatibility. The change here ignores pre-releases
+ on constraint checks (e.g., ~ or ^) when a pre-release is not part of the
+ constraint. For example, `^1.2.3` will ignore pre-releases while
+ `^1.2.3-alpha` will include them.
+
+# Release 1.1.1 (2016-06-30)
+
+## Changed
+- Issue #9: Speed up version comparison performance (thanks @sdboyer)
+- Issue #8: Added benchmarks (thanks @sdboyer)
+- Updated Go Report Card URL to new location
+- Updated Readme to add code snippet formatting (thanks @mh-cbon)
+- Updating tagging to v[SemVer] structure for compatibility with other tools.
+
+# Release 1.1.0 (2016-03-11)
+
+- Issue #2: Implemented validation to provide reasons a versions failed a
+ constraint.
+
+# Release 1.0.1 (2015-12-31)
+
+- Fixed #1: * constraint failing on valid versions.
+
+# Release 1.0.0 (2015-10-20)
+
+- Initial release
diff --git a/backend/vendor/github.com/Masterminds/semver/LICENSE.txt b/backend/vendor/github.com/Masterminds/semver/LICENSE.txt
new file mode 100644
index 00000000..0da4aead
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/LICENSE.txt
@@ -0,0 +1,20 @@
+The Masterminds
+Copyright (C) 2014-2015, Matt Butcher and Matt Farina
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/backend/vendor/github.com/Masterminds/semver/Makefile b/backend/vendor/github.com/Masterminds/semver/Makefile
new file mode 100644
index 00000000..a7a1b4e3
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/Makefile
@@ -0,0 +1,36 @@
+.PHONY: setup
+setup:
+ go get -u gopkg.in/alecthomas/gometalinter.v1
+ gometalinter.v1 --install
+
+.PHONY: test
+test: validate lint
+ @echo "==> Running tests"
+ go test -v
+
+.PHONY: validate
+validate:
+ @echo "==> Running static validations"
+ @gometalinter.v1 \
+ --disable-all \
+ --enable deadcode \
+ --severity deadcode:error \
+ --enable gofmt \
+ --enable gosimple \
+ --enable ineffassign \
+ --enable misspell \
+ --enable vet \
+ --tests \
+ --vendor \
+ --deadline 60s \
+ ./... || exit_code=1
+
+.PHONY: lint
+lint:
+ @echo "==> Running linters"
+ @gometalinter.v1 \
+ --disable-all \
+ --enable golint \
+ --vendor \
+ --deadline 60s \
+ ./... || :
diff --git a/backend/vendor/github.com/Masterminds/semver/README.md b/backend/vendor/github.com/Masterminds/semver/README.md
new file mode 100644
index 00000000..3e934ed7
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/README.md
@@ -0,0 +1,165 @@
+# SemVer
+
+The `semver` package provides the ability to work with [Semantic Versions](http://semver.org) in Go. Specifically it provides the ability to:
+
+* Parse semantic versions
+* Sort semantic versions
+* Check if a semantic version fits within a set of constraints
+* Optionally work with a `v` prefix
+
+[](https://masterminds.github.io/stability/active.html)
+[](https://travis-ci.org/Masterminds/semver) [](https://ci.appveyor.com/project/mattfarina/semver/branch/master) [](https://godoc.org/github.com/Masterminds/semver) [](https://goreportcard.com/report/github.com/Masterminds/semver)
+
+## Parsing Semantic Versions
+
+To parse a semantic version use the `NewVersion` function. For example,
+
+```go
+ v, err := semver.NewVersion("1.2.3-beta.1+build345")
+```
+
+If there is an error the version wasn't parseable. The version object has methods
+to get the parts of the version, compare it to other versions, convert the
+version back into a string, and get the original string. For more details
+please see the [documentation](https://godoc.org/github.com/Masterminds/semver).
+
+## Sorting Semantic Versions
+
+A set of versions can be sorted using the [`sort`](https://golang.org/pkg/sort/)
+package from the standard library. For example,
+
+```go
+ raw := []string{"1.2.3", "1.0", "1.3", "2", "0.4.2",}
+ vs := make([]*semver.Version, len(raw))
+ for i, r := range raw {
+ v, err := semver.NewVersion(r)
+ if err != nil {
+ t.Errorf("Error parsing version: %s", err)
+ }
+
+ vs[i] = v
+ }
+
+ sort.Sort(semver.Collection(vs))
+```
+
+## Checking Version Constraints
+
+Checking a version against version constraints is one of the most featureful
+parts of the package.
+
+```go
+ c, err := semver.NewConstraint(">= 1.2.3")
+ if err != nil {
+ // Handle constraint not being parseable.
+ }
+
+ v, _ := semver.NewVersion("1.3")
+ if err != nil {
+ // Handle version not being parseable.
+ }
+ // Check if the version meets the constraints. The a variable will be true.
+ a := c.Check(v)
+```
+
+## Basic Comparisons
+
+There are two elements to the comparisons. First, a comparison string is a list
+of comma separated and comparisons. These are then separated by || separated or
+comparisons. For example, `">= 1.2, < 3.0.0 || >= 4.2.3"` is looking for a
+comparison that's greater than or equal to 1.2 and less than 3.0.0 or is
+greater than or equal to 4.2.3.
+
+The basic comparisons are:
+
+* `=`: equal (aliased to no operator)
+* `!=`: not equal
+* `>`: greater than
+* `<`: less than
+* `>=`: greater than or equal to
+* `<=`: less than or equal to
+
+_Note, according to the Semantic Version specification pre-releases may not be
+API compliant with their release counterpart. It says,_
+
+> _A pre-release version indicates that the version is unstable and might not satisfy the intended compatibility requirements as denoted by its associated normal version._
+
+_SemVer comparisons without a pre-release value will skip pre-release versions.
+For example, `>1.2.3` will skip pre-releases when looking at a list of values
+while `>1.2.3-alpha.1` will evaluate pre-releases._
+
+## Hyphen Range Comparisons
+
+There are multiple methods to handle ranges and the first is hyphens ranges.
+These look like:
+
+* `1.2 - 1.4.5` which is equivalent to `>= 1.2, <= 1.4.5`
+* `2.3.4 - 4.5` which is equivalent to `>= 2.3.4, <= 4.5`
+
+## Wildcards In Comparisons
+
+The `x`, `X`, and `*` characters can be used as a wildcard character. This works
+for all comparison operators. When used on the `=` operator it falls
+back to the pack level comparison (see tilde below). For example,
+
+* `1.2.x` is equivalent to `>= 1.2.0, < 1.3.0`
+* `>= 1.2.x` is equivalent to `>= 1.2.0`
+* `<= 2.x` is equivalent to `<= 3`
+* `*` is equivalent to `>= 0.0.0`
+
+## Tilde Range Comparisons (Patch)
+
+The tilde (`~`) comparison operator is for patch level ranges when a minor
+version is specified and major level changes when the minor number is missing.
+For example,
+
+* `~1.2.3` is equivalent to `>= 1.2.3, < 1.3.0`
+* `~1` is equivalent to `>= 1, < 2`
+* `~2.3` is equivalent to `>= 2.3, < 2.4`
+* `~1.2.x` is equivalent to `>= 1.2.0, < 1.3.0`
+* `~1.x` is equivalent to `>= 1, < 2`
+
+## Caret Range Comparisons (Major)
+
+The caret (`^`) comparison operator is for major level changes. This is useful
+when comparisons of API versions as a major change is API breaking. For example,
+
+* `^1.2.3` is equivalent to `>= 1.2.3, < 2.0.0`
+* `^1.2.x` is equivalent to `>= 1.2.0, < 2.0.0`
+* `^2.3` is equivalent to `>= 2.3, < 3`
+* `^2.x` is equivalent to `>= 2.0.0, < 3`
+
+# Validation
+
+In addition to testing a version against a constraint, a version can be validated
+against a constraint. When validation fails a slice of errors containing why a
+version didn't meet the constraint is returned. For example,
+
+```go
+ c, err := semver.NewConstraint("<= 1.2.3, >= 1.4")
+ if err != nil {
+ // Handle constraint not being parseable.
+ }
+
+ v, _ := semver.NewVersion("1.3")
+ if err != nil {
+ // Handle version not being parseable.
+ }
+
+ // Validate a version against a constraint.
+ a, msgs := c.Validate(v)
+ // a is false
+ for _, m := range msgs {
+ fmt.Println(m)
+
+ // Loops over the errors which would read
+ // "1.3 is greater than 1.2.3"
+ // "1.3 is less than 1.4"
+ }
+```
+
+# Contribute
+
+If you find an issue or want to contribute please file an [issue](https://github.com/Masterminds/semver/issues)
+or [create a pull request](https://github.com/Masterminds/semver/pulls).
diff --git a/backend/vendor/github.com/Masterminds/semver/appveyor.yml b/backend/vendor/github.com/Masterminds/semver/appveyor.yml
new file mode 100644
index 00000000..b2778df1
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/appveyor.yml
@@ -0,0 +1,44 @@
+version: build-{build}.{branch}
+
+clone_folder: C:\gopath\src\github.com\Masterminds\semver
+shallow_clone: true
+
+environment:
+ GOPATH: C:\gopath
+
+platform:
+ - x64
+
+install:
+ - go version
+ - go env
+ - go get -u gopkg.in/alecthomas/gometalinter.v1
+ - set PATH=%PATH%;%GOPATH%\bin
+ - gometalinter.v1.exe --install
+
+build_script:
+ - go install -v ./...
+
+test_script:
+ - "gometalinter.v1 \
+ --disable-all \
+ --enable deadcode \
+ --severity deadcode:error \
+ --enable gofmt \
+ --enable gosimple \
+ --enable ineffassign \
+ --enable misspell \
+ --enable vet \
+ --tests \
+ --vendor \
+ --deadline 60s \
+ ./... || exit_code=1"
+ - "gometalinter.v1 \
+ --disable-all \
+ --enable golint \
+ --vendor \
+ --deadline 60s \
+ ./... || :"
+ - go test -v
+
+deploy: off
diff --git a/backend/vendor/github.com/Masterminds/semver/collection.go b/backend/vendor/github.com/Masterminds/semver/collection.go
new file mode 100644
index 00000000..a7823589
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/collection.go
@@ -0,0 +1,24 @@
+package semver
+
+// Collection is a collection of Version instances and implements the sort
+// interface. See the sort package for more details.
+// https://golang.org/pkg/sort/
+type Collection []*Version
+
+// Len returns the length of a collection. The number of Version instances
+// on the slice.
+func (c Collection) Len() int {
+ return len(c)
+}
+
+// Less is needed for the sort interface to compare two Version objects on the
+// slice. If checks if one is less than the other.
+func (c Collection) Less(i, j int) bool {
+ return c[i].LessThan(c[j])
+}
+
+// Swap is needed for the sort interface to replace the Version objects
+// at two different positions in the slice.
+func (c Collection) Swap(i, j int) {
+ c[i], c[j] = c[j], c[i]
+}
diff --git a/backend/vendor/github.com/Masterminds/semver/constraints.go b/backend/vendor/github.com/Masterminds/semver/constraints.go
new file mode 100644
index 00000000..a41a6a7a
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/constraints.go
@@ -0,0 +1,426 @@
+package semver
+
+import (
+ "errors"
+ "fmt"
+ "regexp"
+ "strings"
+)
+
+// Constraints is one or more constraint that a semantic version can be
+// checked against.
+type Constraints struct {
+ constraints [][]*constraint
+}
+
+// NewConstraint returns a Constraints instance that a Version instance can
+// be checked against. If there is a parse error it will be returned.
+func NewConstraint(c string) (*Constraints, error) {
+
+ // Rewrite - ranges into a comparison operation.
+ c = rewriteRange(c)
+
+ ors := strings.Split(c, "||")
+ or := make([][]*constraint, len(ors))
+ for k, v := range ors {
+ cs := strings.Split(v, ",")
+ result := make([]*constraint, len(cs))
+ for i, s := range cs {
+ pc, err := parseConstraint(s)
+ if err != nil {
+ return nil, err
+ }
+
+ result[i] = pc
+ }
+ or[k] = result
+ }
+
+ o := &Constraints{constraints: or}
+ return o, nil
+}
+
+// Check tests if a version satisfies the constraints.
+func (cs Constraints) Check(v *Version) bool {
+ // loop over the ORs and check the inner ANDs
+ for _, o := range cs.constraints {
+ joy := true
+ for _, c := range o {
+ if !c.check(v) {
+ joy = false
+ break
+ }
+ }
+
+ if joy {
+ return true
+ }
+ }
+
+ return false
+}
+
+// Validate checks if a version satisfies a constraint. If not a slice of
+// reasons for the failure are returned in addition to a bool.
+func (cs Constraints) Validate(v *Version) (bool, []error) {
+ // loop over the ORs and check the inner ANDs
+ var e []error
+ for _, o := range cs.constraints {
+ joy := true
+ for _, c := range o {
+ if !c.check(v) {
+ em := fmt.Errorf(c.msg, v, c.orig)
+ e = append(e, em)
+ joy = false
+ }
+ }
+
+ if joy {
+ return true, []error{}
+ }
+ }
+
+ return false, e
+}
+
+var constraintOps map[string]cfunc
+var constraintMsg map[string]string
+var constraintRegex *regexp.Regexp
+
+func init() {
+ constraintOps = map[string]cfunc{
+ "": constraintTildeOrEqual,
+ "=": constraintTildeOrEqual,
+ "!=": constraintNotEqual,
+ ">": constraintGreaterThan,
+ "<": constraintLessThan,
+ ">=": constraintGreaterThanEqual,
+ "=>": constraintGreaterThanEqual,
+ "<=": constraintLessThanEqual,
+ "=<": constraintLessThanEqual,
+ "~": constraintTilde,
+ "~>": constraintTilde,
+ "^": constraintCaret,
+ }
+
+ constraintMsg = map[string]string{
+ "": "%s is not equal to %s",
+ "=": "%s is not equal to %s",
+ "!=": "%s is equal to %s",
+ ">": "%s is less than or equal to %s",
+ "<": "%s is greater than or equal to %s",
+ ">=": "%s is less than %s",
+ "=>": "%s is less than %s",
+ "<=": "%s is greater than %s",
+ "=<": "%s is greater than %s",
+ "~": "%s does not have same major and minor version as %s",
+ "~>": "%s does not have same major and minor version as %s",
+ "^": "%s does not have same major version as %s",
+ }
+
+ ops := make([]string, 0, len(constraintOps))
+ for k := range constraintOps {
+ ops = append(ops, regexp.QuoteMeta(k))
+ }
+
+ constraintRegex = regexp.MustCompile(fmt.Sprintf(
+ `^\s*(%s)\s*(%s)\s*$`,
+ strings.Join(ops, "|"),
+ cvRegex))
+
+ constraintRangeRegex = regexp.MustCompile(fmt.Sprintf(
+ `\s*(%s)\s+-\s+(%s)\s*`,
+ cvRegex, cvRegex))
+}
+
+// An individual constraint
+type constraint struct {
+ // The callback function for the restraint. It performs the logic for
+ // the constraint.
+ function cfunc
+
+ msg string
+
+ // The version used in the constraint check. For example, if a constraint
+ // is '<= 2.0.0' the con a version instance representing 2.0.0.
+ con *Version
+
+ // The original parsed version (e.g., 4.x from != 4.x)
+ orig string
+
+ // When an x is used as part of the version (e.g., 1.x)
+ minorDirty bool
+ dirty bool
+ patchDirty bool
+}
+
+// Check if a version meets the constraint
+func (c *constraint) check(v *Version) bool {
+ return c.function(v, c)
+}
+
+type cfunc func(v *Version, c *constraint) bool
+
+func parseConstraint(c string) (*constraint, error) {
+ m := constraintRegex.FindStringSubmatch(c)
+ if m == nil {
+ return nil, fmt.Errorf("improper constraint: %s", c)
+ }
+
+ ver := m[2]
+ orig := ver
+ minorDirty := false
+ patchDirty := false
+ dirty := false
+ if isX(m[3]) {
+ ver = "0.0.0"
+ dirty = true
+ } else if isX(strings.TrimPrefix(m[4], ".")) || m[4] == "" {
+ minorDirty = true
+ dirty = true
+ ver = fmt.Sprintf("%s.0.0%s", m[3], m[6])
+ } else if isX(strings.TrimPrefix(m[5], ".")) {
+ dirty = true
+ patchDirty = true
+ ver = fmt.Sprintf("%s%s.0%s", m[3], m[4], m[6])
+ }
+
+ con, err := NewVersion(ver)
+ if err != nil {
+
+ // The constraintRegex should catch any regex parsing errors. So,
+ // we should never get here.
+ return nil, errors.New("constraint Parser Error")
+ }
+
+ cs := &constraint{
+ function: constraintOps[m[1]],
+ msg: constraintMsg[m[1]],
+ con: con,
+ orig: orig,
+ minorDirty: minorDirty,
+ patchDirty: patchDirty,
+ dirty: dirty,
+ }
+ return cs, nil
+}
+
+// Constraint functions
+func constraintNotEqual(v *Version, c *constraint) bool {
+ if c.dirty {
+
+ // If there is a pre-release on the version but the constraint isn't looking
+ // for them assume that pre-releases are not compatible. See issue 21 for
+ // more details.
+ if v.Prerelease() != "" && c.con.Prerelease() == "" {
+ return false
+ }
+
+ if c.con.Major() != v.Major() {
+ return true
+ }
+ if c.con.Minor() != v.Minor() && !c.minorDirty {
+ return true
+ } else if c.minorDirty {
+ return false
+ }
+
+ return false
+ }
+
+ return !v.Equal(c.con)
+}
+
+func constraintGreaterThan(v *Version, c *constraint) bool {
+
+ // An edge case the constraint is 0.0.0 and the version is 0.0.0-someprerelease
+ // exists. This that case.
+ if !isNonZero(c.con) && isNonZero(v) {
+ return true
+ }
+
+ // If there is a pre-release on the version but the constraint isn't looking
+ // for them assume that pre-releases are not compatible. See issue 21 for
+ // more details.
+ if v.Prerelease() != "" && c.con.Prerelease() == "" {
+ return false
+ }
+
+ return v.Compare(c.con) == 1
+}
+
+func constraintLessThan(v *Version, c *constraint) bool {
+ // If there is a pre-release on the version but the constraint isn't looking
+ // for them assume that pre-releases are not compatible. See issue 21 for
+ // more details.
+ if v.Prerelease() != "" && c.con.Prerelease() == "" {
+ return false
+ }
+
+ if !c.dirty {
+ return v.Compare(c.con) < 0
+ }
+
+ if v.Major() > c.con.Major() {
+ return false
+ } else if v.Minor() > c.con.Minor() && !c.minorDirty {
+ return false
+ }
+
+ return true
+}
+
+func constraintGreaterThanEqual(v *Version, c *constraint) bool {
+ // An edge case the constraint is 0.0.0 and the version is 0.0.0-someprerelease
+ // exists. This that case.
+ if !isNonZero(c.con) && isNonZero(v) {
+ return true
+ }
+
+ // If there is a pre-release on the version but the constraint isn't looking
+ // for them assume that pre-releases are not compatible. See issue 21 for
+ // more details.
+ if v.Prerelease() != "" && c.con.Prerelease() == "" {
+ return false
+ }
+
+ return v.Compare(c.con) >= 0
+}
+
+func constraintLessThanEqual(v *Version, c *constraint) bool {
+ // If there is a pre-release on the version but the constraint isn't looking
+ // for them assume that pre-releases are not compatible. See issue 21 for
+ // more details.
+ if v.Prerelease() != "" && c.con.Prerelease() == "" {
+ return false
+ }
+
+ if !c.dirty {
+ return v.Compare(c.con) <= 0
+ }
+
+ if v.Major() > c.con.Major() {
+ return false
+ } else if v.Minor() > c.con.Minor() && !c.minorDirty {
+ return false
+ }
+
+ return true
+}
+
+// ~*, ~>* --> >= 0.0.0 (any)
+// ~2, ~2.x, ~2.x.x, ~>2, ~>2.x ~>2.x.x --> >=2.0.0, <3.0.0
+// ~2.0, ~2.0.x, ~>2.0, ~>2.0.x --> >=2.0.0, <2.1.0
+// ~1.2, ~1.2.x, ~>1.2, ~>1.2.x --> >=1.2.0, <1.3.0
+// ~1.2.3, ~>1.2.3 --> >=1.2.3, <1.3.0
+// ~1.2.0, ~>1.2.0 --> >=1.2.0, <1.3.0
+func constraintTilde(v *Version, c *constraint) bool {
+ // If there is a pre-release on the version but the constraint isn't looking
+ // for them assume that pre-releases are not compatible. See issue 21 for
+ // more details.
+ if v.Prerelease() != "" && c.con.Prerelease() == "" {
+ return false
+ }
+
+ if v.LessThan(c.con) {
+ return false
+ }
+
+ // ~0.0.0 is a special case where all constraints are accepted. It's
+ // equivalent to >= 0.0.0.
+ if c.con.Major() == 0 && c.con.Minor() == 0 && c.con.Patch() == 0 &&
+ !c.minorDirty && !c.patchDirty {
+ return true
+ }
+
+ if v.Major() != c.con.Major() {
+ return false
+ }
+
+ if v.Minor() != c.con.Minor() && !c.minorDirty {
+ return false
+ }
+
+ return true
+}
+
+// When there is a .x (dirty) status it automatically opts in to ~. Otherwise
+// it's a straight =
+func constraintTildeOrEqual(v *Version, c *constraint) bool {
+ // If there is a pre-release on the version but the constraint isn't looking
+ // for them assume that pre-releases are not compatible. See issue 21 for
+ // more details.
+ if v.Prerelease() != "" && c.con.Prerelease() == "" {
+ return false
+ }
+
+ if c.dirty {
+ c.msg = constraintMsg["~"]
+ return constraintTilde(v, c)
+ }
+
+ return v.Equal(c.con)
+}
+
+// ^* --> (any)
+// ^2, ^2.x, ^2.x.x --> >=2.0.0, <3.0.0
+// ^2.0, ^2.0.x --> >=2.0.0, <3.0.0
+// ^1.2, ^1.2.x --> >=1.2.0, <2.0.0
+// ^1.2.3 --> >=1.2.3, <2.0.0
+// ^1.2.0 --> >=1.2.0, <2.0.0
+func constraintCaret(v *Version, c *constraint) bool {
+ // If there is a pre-release on the version but the constraint isn't looking
+ // for them assume that pre-releases are not compatible. See issue 21 for
+ // more details.
+ if v.Prerelease() != "" && c.con.Prerelease() == "" {
+ return false
+ }
+
+ if v.LessThan(c.con) {
+ return false
+ }
+
+ if v.Major() != c.con.Major() {
+ return false
+ }
+
+ return true
+}
+
+var constraintRangeRegex *regexp.Regexp
+
+const cvRegex string = `v?([0-9|x|X|\*]+)(\.[0-9|x|X|\*]+)?(\.[0-9|x|X|\*]+)?` +
+ `(-([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*))?` +
+ `(\+([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*))?`
+
+func isX(x string) bool {
+ switch x {
+ case "x", "*", "X":
+ return true
+ default:
+ return false
+ }
+}
+
+func rewriteRange(i string) string {
+ m := constraintRangeRegex.FindAllStringSubmatch(i, -1)
+ if m == nil {
+ return i
+ }
+ o := i
+ for _, v := range m {
+ t := fmt.Sprintf(">= %s, <= %s", v[1], v[11])
+ o = strings.Replace(o, v[0], t, 1)
+ }
+
+ return o
+}
+
+// Detect if a version is not zero (0.0.0)
+func isNonZero(v *Version) bool {
+ if v.Major() != 0 || v.Minor() != 0 || v.Patch() != 0 || v.Prerelease() != "" {
+ return true
+ }
+
+ return false
+}
diff --git a/backend/vendor/github.com/Masterminds/semver/doc.go b/backend/vendor/github.com/Masterminds/semver/doc.go
new file mode 100644
index 00000000..e00f65eb
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/doc.go
@@ -0,0 +1,115 @@
+/*
+Package semver provides the ability to work with Semantic Versions (http://semver.org) in Go.
+
+Specifically it provides the ability to:
+
+ * Parse semantic versions
+ * Sort semantic versions
+ * Check if a semantic version fits within a set of constraints
+ * Optionally work with a `v` prefix
+
+Parsing Semantic Versions
+
+To parse a semantic version use the `NewVersion` function. For example,
+
+ v, err := semver.NewVersion("1.2.3-beta.1+build345")
+
+If there is an error the version wasn't parseable. The version object has methods
+to get the parts of the version, compare it to other versions, convert the
+version back into a string, and get the original string. For more details
+please see the documentation at https://godoc.org/github.com/Masterminds/semver.
+
+Sorting Semantic Versions
+
+A set of versions can be sorted using the `sort` package from the standard library.
+For example,
+
+ raw := []string{"1.2.3", "1.0", "1.3", "2", "0.4.2",}
+ vs := make([]*semver.Version, len(raw))
+ for i, r := range raw {
+ v, err := semver.NewVersion(r)
+ if err != nil {
+ t.Errorf("Error parsing version: %s", err)
+ }
+
+ vs[i] = v
+ }
+
+ sort.Sort(semver.Collection(vs))
+
+Checking Version Constraints
+
+Checking a version against version constraints is one of the most featureful
+parts of the package.
+
+ c, err := semver.NewConstraint(">= 1.2.3")
+ if err != nil {
+ // Handle constraint not being parseable.
+ }
+
+ v, _ := semver.NewVersion("1.3")
+ if err != nil {
+ // Handle version not being parseable.
+ }
+ // Check if the version meets the constraints. The a variable will be true.
+ a := c.Check(v)
+
+Basic Comparisons
+
+There are two elements to the comparisons. First, a comparison string is a list
+of comma separated and comparisons. These are then separated by || separated or
+comparisons. For example, `">= 1.2, < 3.0.0 || >= 4.2.3"` is looking for a
+comparison that's greater than or equal to 1.2 and less than 3.0.0 or is
+greater than or equal to 4.2.3.
+
+The basic comparisons are:
+
+ * `=`: equal (aliased to no operator)
+ * `!=`: not equal
+ * `>`: greater than
+ * `<`: less than
+ * `>=`: greater than or equal to
+ * `<=`: less than or equal to
+
+Hyphen Range Comparisons
+
+There are multiple methods to handle ranges and the first is hyphens ranges.
+These look like:
+
+ * `1.2 - 1.4.5` which is equivalent to `>= 1.2, <= 1.4.5`
+ * `2.3.4 - 4.5` which is equivalent to `>= 2.3.4, <= 4.5`
+
+Wildcards In Comparisons
+
+The `x`, `X`, and `*` characters can be used as a wildcard character. This works
+for all comparison operators. When used on the `=` operator it falls
+back to the pack level comparison (see tilde below). For example,
+
+ * `1.2.x` is equivalent to `>= 1.2.0, < 1.3.0`
+ * `>= 1.2.x` is equivalent to `>= 1.2.0`
+ * `<= 2.x` is equivalent to `<= 3`
+ * `*` is equivalent to `>= 0.0.0`
+
+Tilde Range Comparisons (Patch)
+
+The tilde (`~`) comparison operator is for patch level ranges when a minor
+version is specified and major level changes when the minor number is missing.
+For example,
+
+ * `~1.2.3` is equivalent to `>= 1.2.3, < 1.3.0`
+ * `~1` is equivalent to `>= 1, < 2`
+ * `~2.3` is equivalent to `>= 2.3, < 2.4`
+ * `~1.2.x` is equivalent to `>= 1.2.0, < 1.3.0`
+ * `~1.x` is equivalent to `>= 1, < 2`
+
+Caret Range Comparisons (Major)
+
+The caret (`^`) comparison operator is for major level changes. This is useful
+when comparisons of API versions as a major change is API breaking. For example,
+
+ * `^1.2.3` is equivalent to `>= 1.2.3, < 2.0.0`
+ * `^1.2.x` is equivalent to `>= 1.2.0, < 2.0.0`
+ * `^2.3` is equivalent to `>= 2.3, < 3`
+ * `^2.x` is equivalent to `>= 2.0.0, < 3`
+*/
+package semver
diff --git a/backend/vendor/github.com/Masterminds/semver/version.go b/backend/vendor/github.com/Masterminds/semver/version.go
new file mode 100644
index 00000000..9d22ea63
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/semver/version.go
@@ -0,0 +1,421 @@
+package semver
+
+import (
+ "bytes"
+ "encoding/json"
+ "errors"
+ "fmt"
+ "regexp"
+ "strconv"
+ "strings"
+)
+
+// The compiled version of the regex created at init() is cached here so it
+// only needs to be created once.
+var versionRegex *regexp.Regexp
+var validPrereleaseRegex *regexp.Regexp
+
+var (
+ // ErrInvalidSemVer is returned a version is found to be invalid when
+ // being parsed.
+ ErrInvalidSemVer = errors.New("Invalid Semantic Version")
+
+ // ErrInvalidMetadata is returned when the metadata is an invalid format
+ ErrInvalidMetadata = errors.New("Invalid Metadata string")
+
+ // ErrInvalidPrerelease is returned when the pre-release is an invalid format
+ ErrInvalidPrerelease = errors.New("Invalid Prerelease string")
+)
+
+// SemVerRegex is the regular expression used to parse a semantic version.
+const SemVerRegex string = `v?([0-9]+)(\.[0-9]+)?(\.[0-9]+)?` +
+ `(-([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*))?` +
+ `(\+([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*))?`
+
+// ValidPrerelease is the regular expression which validates
+// both prerelease and metadata values.
+const ValidPrerelease string = `^([0-9A-Za-z\-]+(\.[0-9A-Za-z\-]+)*)`
+
+// Version represents a single semantic version.
+type Version struct {
+ major, minor, patch int64
+ pre string
+ metadata string
+ original string
+}
+
+func init() {
+ versionRegex = regexp.MustCompile("^" + SemVerRegex + "$")
+ validPrereleaseRegex = regexp.MustCompile(ValidPrerelease)
+}
+
+// NewVersion parses a given version and returns an instance of Version or
+// an error if unable to parse the version.
+func NewVersion(v string) (*Version, error) {
+ m := versionRegex.FindStringSubmatch(v)
+ if m == nil {
+ return nil, ErrInvalidSemVer
+ }
+
+ sv := &Version{
+ metadata: m[8],
+ pre: m[5],
+ original: v,
+ }
+
+ var temp int64
+ temp, err := strconv.ParseInt(m[1], 10, 64)
+ if err != nil {
+ return nil, fmt.Errorf("Error parsing version segment: %s", err)
+ }
+ sv.major = temp
+
+ if m[2] != "" {
+ temp, err = strconv.ParseInt(strings.TrimPrefix(m[2], "."), 10, 64)
+ if err != nil {
+ return nil, fmt.Errorf("Error parsing version segment: %s", err)
+ }
+ sv.minor = temp
+ } else {
+ sv.minor = 0
+ }
+
+ if m[3] != "" {
+ temp, err = strconv.ParseInt(strings.TrimPrefix(m[3], "."), 10, 64)
+ if err != nil {
+ return nil, fmt.Errorf("Error parsing version segment: %s", err)
+ }
+ sv.patch = temp
+ } else {
+ sv.patch = 0
+ }
+
+ return sv, nil
+}
+
+// MustParse parses a given version and panics on error.
+func MustParse(v string) *Version {
+ sv, err := NewVersion(v)
+ if err != nil {
+ panic(err)
+ }
+ return sv
+}
+
+// String converts a Version object to a string.
+// Note, if the original version contained a leading v this version will not.
+// See the Original() method to retrieve the original value. Semantic Versions
+// don't contain a leading v per the spec. Instead it's optional on
+// impelementation.
+func (v *Version) String() string {
+ var buf bytes.Buffer
+
+ fmt.Fprintf(&buf, "%d.%d.%d", v.major, v.minor, v.patch)
+ if v.pre != "" {
+ fmt.Fprintf(&buf, "-%s", v.pre)
+ }
+ if v.metadata != "" {
+ fmt.Fprintf(&buf, "+%s", v.metadata)
+ }
+
+ return buf.String()
+}
+
+// Original returns the original value passed in to be parsed.
+func (v *Version) Original() string {
+ return v.original
+}
+
+// Major returns the major version.
+func (v *Version) Major() int64 {
+ return v.major
+}
+
+// Minor returns the minor version.
+func (v *Version) Minor() int64 {
+ return v.minor
+}
+
+// Patch returns the patch version.
+func (v *Version) Patch() int64 {
+ return v.patch
+}
+
+// Prerelease returns the pre-release version.
+func (v *Version) Prerelease() string {
+ return v.pre
+}
+
+// Metadata returns the metadata on the version.
+func (v *Version) Metadata() string {
+ return v.metadata
+}
+
+// originalVPrefix returns the original 'v' prefix if any.
+func (v *Version) originalVPrefix() string {
+
+ // Note, only lowercase v is supported as a prefix by the parser.
+ if v.original != "" && v.original[:1] == "v" {
+ return v.original[:1]
+ }
+ return ""
+}
+
+// IncPatch produces the next patch version.
+// If the current version does not have prerelease/metadata information,
+// it unsets metadata and prerelease values, increments patch number.
+// If the current version has any of prerelease or metadata information,
+// it unsets both values and keeps curent patch value
+func (v Version) IncPatch() Version {
+ vNext := v
+ // according to http://semver.org/#spec-item-9
+ // Pre-release versions have a lower precedence than the associated normal version.
+ // according to http://semver.org/#spec-item-10
+ // Build metadata SHOULD be ignored when determining version precedence.
+ if v.pre != "" {
+ vNext.metadata = ""
+ vNext.pre = ""
+ } else {
+ vNext.metadata = ""
+ vNext.pre = ""
+ vNext.patch = v.patch + 1
+ }
+ vNext.original = v.originalVPrefix() + "" + vNext.String()
+ return vNext
+}
+
+// IncMinor produces the next minor version.
+// Sets patch to 0.
+// Increments minor number.
+// Unsets metadata.
+// Unsets prerelease status.
+func (v Version) IncMinor() Version {
+ vNext := v
+ vNext.metadata = ""
+ vNext.pre = ""
+ vNext.patch = 0
+ vNext.minor = v.minor + 1
+ vNext.original = v.originalVPrefix() + "" + vNext.String()
+ return vNext
+}
+
+// IncMajor produces the next major version.
+// Sets patch to 0.
+// Sets minor to 0.
+// Increments major number.
+// Unsets metadata.
+// Unsets prerelease status.
+func (v Version) IncMajor() Version {
+ vNext := v
+ vNext.metadata = ""
+ vNext.pre = ""
+ vNext.patch = 0
+ vNext.minor = 0
+ vNext.major = v.major + 1
+ vNext.original = v.originalVPrefix() + "" + vNext.String()
+ return vNext
+}
+
+// SetPrerelease defines the prerelease value.
+// Value must not include the required 'hypen' prefix.
+func (v Version) SetPrerelease(prerelease string) (Version, error) {
+ vNext := v
+ if len(prerelease) > 0 && !validPrereleaseRegex.MatchString(prerelease) {
+ return vNext, ErrInvalidPrerelease
+ }
+ vNext.pre = prerelease
+ vNext.original = v.originalVPrefix() + "" + vNext.String()
+ return vNext, nil
+}
+
+// SetMetadata defines metadata value.
+// Value must not include the required 'plus' prefix.
+func (v Version) SetMetadata(metadata string) (Version, error) {
+ vNext := v
+ if len(metadata) > 0 && !validPrereleaseRegex.MatchString(metadata) {
+ return vNext, ErrInvalidMetadata
+ }
+ vNext.metadata = metadata
+ vNext.original = v.originalVPrefix() + "" + vNext.String()
+ return vNext, nil
+}
+
+// LessThan tests if one version is less than another one.
+func (v *Version) LessThan(o *Version) bool {
+ return v.Compare(o) < 0
+}
+
+// GreaterThan tests if one version is greater than another one.
+func (v *Version) GreaterThan(o *Version) bool {
+ return v.Compare(o) > 0
+}
+
+// Equal tests if two versions are equal to each other.
+// Note, versions can be equal with different metadata since metadata
+// is not considered part of the comparable version.
+func (v *Version) Equal(o *Version) bool {
+ return v.Compare(o) == 0
+}
+
+// Compare compares this version to another one. It returns -1, 0, or 1 if
+// the version smaller, equal, or larger than the other version.
+//
+// Versions are compared by X.Y.Z. Build metadata is ignored. Prerelease is
+// lower than the version without a prerelease.
+func (v *Version) Compare(o *Version) int {
+ // Compare the major, minor, and patch version for differences. If a
+ // difference is found return the comparison.
+ if d := compareSegment(v.Major(), o.Major()); d != 0 {
+ return d
+ }
+ if d := compareSegment(v.Minor(), o.Minor()); d != 0 {
+ return d
+ }
+ if d := compareSegment(v.Patch(), o.Patch()); d != 0 {
+ return d
+ }
+
+ // At this point the major, minor, and patch versions are the same.
+ ps := v.pre
+ po := o.Prerelease()
+
+ if ps == "" && po == "" {
+ return 0
+ }
+ if ps == "" {
+ return 1
+ }
+ if po == "" {
+ return -1
+ }
+
+ return comparePrerelease(ps, po)
+}
+
+// UnmarshalJSON implements JSON.Unmarshaler interface.
+func (v *Version) UnmarshalJSON(b []byte) error {
+ var s string
+ if err := json.Unmarshal(b, &s); err != nil {
+ return err
+ }
+ temp, err := NewVersion(s)
+ if err != nil {
+ return err
+ }
+ v.major = temp.major
+ v.minor = temp.minor
+ v.patch = temp.patch
+ v.pre = temp.pre
+ v.metadata = temp.metadata
+ v.original = temp.original
+ temp = nil
+ return nil
+}
+
+// MarshalJSON implements JSON.Marshaler interface.
+func (v *Version) MarshalJSON() ([]byte, error) {
+ return json.Marshal(v.String())
+}
+
+func compareSegment(v, o int64) int {
+ if v < o {
+ return -1
+ }
+ if v > o {
+ return 1
+ }
+
+ return 0
+}
+
+func comparePrerelease(v, o string) int {
+
+ // split the prelease versions by their part. The separator, per the spec,
+ // is a .
+ sparts := strings.Split(v, ".")
+ oparts := strings.Split(o, ".")
+
+ // Find the longer length of the parts to know how many loop iterations to
+ // go through.
+ slen := len(sparts)
+ olen := len(oparts)
+
+ l := slen
+ if olen > slen {
+ l = olen
+ }
+
+ // Iterate over each part of the prereleases to compare the differences.
+ for i := 0; i < l; i++ {
+ // Since the lentgh of the parts can be different we need to create
+ // a placeholder. This is to avoid out of bounds issues.
+ stemp := ""
+ if i < slen {
+ stemp = sparts[i]
+ }
+
+ otemp := ""
+ if i < olen {
+ otemp = oparts[i]
+ }
+
+ d := comparePrePart(stemp, otemp)
+ if d != 0 {
+ return d
+ }
+ }
+
+ // Reaching here means two versions are of equal value but have different
+ // metadata (the part following a +). They are not identical in string form
+ // but the version comparison finds them to be equal.
+ return 0
+}
+
+func comparePrePart(s, o string) int {
+ // Fastpath if they are equal
+ if s == o {
+ return 0
+ }
+
+ // When s or o are empty we can use the other in an attempt to determine
+ // the response.
+ if s == "" {
+ if o != "" {
+ return -1
+ }
+ return 1
+ }
+
+ if o == "" {
+ if s != "" {
+ return 1
+ }
+ return -1
+ }
+
+ // When comparing strings "99" is greater than "103". To handle
+ // cases like this we need to detect numbers and compare them.
+
+ oi, n1 := strconv.ParseInt(o, 10, 64)
+ si, n2 := strconv.ParseInt(s, 10, 64)
+
+ // The case where both are strings compare the strings
+ if n1 != nil && n2 != nil {
+ if s > o {
+ return 1
+ }
+ return -1
+ } else if n1 != nil {
+ // o is a string and s is a number
+ return -1
+ } else if n2 != nil {
+ // s is a string and o is a number
+ return 1
+ }
+ // Both are numbers
+ if si > oi {
+ return 1
+ }
+ return -1
+
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/.gitignore b/backend/vendor/github.com/Masterminds/sprig/.gitignore
new file mode 100644
index 00000000..5e3002f8
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/.gitignore
@@ -0,0 +1,2 @@
+vendor/
+/.glide
diff --git a/backend/vendor/github.com/Masterminds/sprig/.travis.yml b/backend/vendor/github.com/Masterminds/sprig/.travis.yml
new file mode 100644
index 00000000..482aa3cd
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/.travis.yml
@@ -0,0 +1,24 @@
+language: go
+
+go:
+ - 1.9.x
+ - 1.10.x
+ - 1.11.x
+ - tip
+
+# Setting sudo access to false will let Travis CI use containers rather than
+# VMs to run the tests. For more details see:
+# - http://docs.travis-ci.com/user/workers/container-based-infrastructure/
+# - http://docs.travis-ci.com/user/workers/standard-infrastructure/
+sudo: false
+
+script:
+ - make setup test
+
+notifications:
+ webhooks:
+ urls:
+ - https://webhooks.gitter.im/e/06e3328629952dabe3e0
+ on_success: change # options: [always|never|change] default: always
+ on_failure: always # options: [always|never|change] default: always
+ on_start: never # options: [always|never|change] default: always
diff --git a/backend/vendor/github.com/Masterminds/sprig/CHANGELOG.md b/backend/vendor/github.com/Masterminds/sprig/CHANGELOG.md
new file mode 100644
index 00000000..44593713
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/CHANGELOG.md
@@ -0,0 +1,153 @@
+# Changelog
+
+## Release 2.15.0 (2018-04-02)
+
+### Added
+
+- #68 and #69: Add json helpers to docs (thanks @arunvelsriram)
+- #66: Add ternary function (thanks @binoculars)
+- #67: Allow keys function to take multiple dicts (thanks @binoculars)
+- #89: Added sha1sum to crypto function (thanks @benkeil)
+- #81: Allow customizing Root CA that used by genSignedCert (thanks @chenzhiwei)
+- #92: Add travis testing for go 1.10
+- #93: Adding appveyor config for windows testing
+
+### Changed
+
+- #90: Updating to more recent dependencies
+- #73: replace satori/go.uuid with google/uuid (thanks @petterw)
+
+### Fixed
+
+- #76: Fixed documentation typos (thanks @Thiht)
+- Fixed rounding issue on the `ago` function. Note, the removes support for Go 1.8 and older
+
+## Release 2.14.1 (2017-12-01)
+
+### Fixed
+
+- #60: Fix typo in function name documentation (thanks @neil-ca-moore)
+- #61: Removing line with {{ due to blocking github pages genertion
+- #64: Update the list functions to handle int, string, and other slices for compatibility
+
+## Release 2.14.0 (2017-10-06)
+
+This new version of Sprig adds a set of functions for generating and working with SSL certificates.
+
+- `genCA` generates an SSL Certificate Authority
+- `genSelfSignedCert` generates an SSL self-signed certificate
+- `genSignedCert` generates an SSL certificate and key based on a given CA
+
+## Release 2.13.0 (2017-09-18)
+
+This release adds new functions, including:
+
+- `regexMatch`, `regexFindAll`, `regexFind`, `regexReplaceAll`, `regexReplaceAllLiteral`, and `regexSplit` to work with regular expressions
+- `floor`, `ceil`, and `round` math functions
+- `toDate` converts a string to a date
+- `nindent` is just like `indent` but also prepends a new line
+- `ago` returns the time from `time.Now`
+
+### Added
+
+- #40: Added basic regex functionality (thanks @alanquillin)
+- #41: Added ceil floor and round functions (thanks @alanquillin)
+- #48: Added toDate function (thanks @andreynering)
+- #50: Added nindent function (thanks @binoculars)
+- #46: Added ago function (thanks @slayer)
+
+### Changed
+
+- #51: Updated godocs to include new string functions (thanks @curtisallen)
+- #49: Added ability to merge multiple dicts (thanks @binoculars)
+
+## Release 2.12.0 (2017-05-17)
+
+- `snakecase`, `camelcase`, and `shuffle` are three new string functions
+- `fail` allows you to bail out of a template render when conditions are not met
+
+## Release 2.11.0 (2017-05-02)
+
+- Added `toJson` and `toPrettyJson`
+- Added `merge`
+- Refactored documentation
+
+## Release 2.10.0 (2017-03-15)
+
+- Added `semver` and `semverCompare` for Semantic Versions
+- `list` replaces `tuple`
+- Fixed issue with `join`
+- Added `first`, `last`, `intial`, `rest`, `prepend`, `append`, `toString`, `toStrings`, `sortAlpha`, `reverse`, `coalesce`, `pluck`, `pick`, `compact`, `keys`, `omit`, `uniq`, `has`, `without`
+
+## Release 2.9.0 (2017-02-23)
+
+- Added `splitList` to split a list
+- Added crypto functions of `genPrivateKey` and `derivePassword`
+
+## Release 2.8.0 (2016-12-21)
+
+- Added access to several path functions (`base`, `dir`, `clean`, `ext`, and `abs`)
+- Added functions for _mutating_ dictionaries (`set`, `unset`, `hasKey`)
+
+## Release 2.7.0 (2016-12-01)
+
+- Added `sha256sum` to generate a hash of an input
+- Added functions to convert a numeric or string to `int`, `int64`, `float64`
+
+## Release 2.6.0 (2016-10-03)
+
+- Added a `uuidv4` template function for generating UUIDs inside of a template.
+
+## Release 2.5.0 (2016-08-19)
+
+- New `trimSuffix`, `trimPrefix`, `hasSuffix`, and `hasPrefix` functions
+- New aliases have been added for a few functions that didn't follow the naming conventions (`trimAll` and `abbrevBoth`)
+- `trimall` and `abbrevboth` (notice the case) are deprecated and will be removed in 3.0.0
+
+## Release 2.4.0 (2016-08-16)
+
+- Adds two functions: `until` and `untilStep`
+
+## Release 2.3.0 (2016-06-21)
+
+- cat: Concatenate strings with whitespace separators.
+- replace: Replace parts of a string: `replace " " "-" "Me First"` renders "Me-First"
+- plural: Format plurals: `len "foo" | plural "one foo" "many foos"` renders "many foos"
+- indent: Indent blocks of text in a way that is sensitive to "\n" characters.
+
+## Release 2.2.0 (2016-04-21)
+
+- Added a `genPrivateKey` function (Thanks @bacongobbler)
+
+## Release 2.1.0 (2016-03-30)
+
+- `default` now prints the default value when it does not receive a value down the pipeline. It is much safer now to do `{{.Foo | default "bar"}}`.
+- Added accessors for "hermetic" functions. These return only functions that, when given the same input, produce the same output.
+
+## Release 2.0.0 (2016-03-29)
+
+Because we switched from `int` to `int64` as the return value for all integer math functions, the library's major version number has been incremented.
+
+- `min` complements `max` (formerly `biggest`)
+- `empty` indicates that a value is the empty value for its type
+- `tuple` creates a tuple inside of a template: `{{$t := tuple "a", "b" "c"}}`
+- `dict` creates a dictionary inside of a template `{{$d := dict "key1" "val1" "key2" "val2"}}`
+- Date formatters have been added for HTML dates (as used in `date` input fields)
+- Integer math functions can convert from a number of types, including `string` (via `strconv.ParseInt`).
+
+## Release 1.2.0 (2016-02-01)
+
+- Added quote and squote
+- Added b32enc and b32dec
+- add now takes varargs
+- biggest now takes varargs
+
+## Release 1.1.0 (2015-12-29)
+
+- Added #4: Added contains function. strings.Contains, but with the arguments
+ switched to simplify common pipelines. (thanks krancour)
+- Added Travis-CI testing support
+
+## Release 1.0.0 (2015-12-23)
+
+- Initial release
diff --git a/backend/vendor/github.com/Masterminds/sprig/LICENSE.txt b/backend/vendor/github.com/Masterminds/sprig/LICENSE.txt
new file mode 100644
index 00000000..5c95accc
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/LICENSE.txt
@@ -0,0 +1,20 @@
+Sprig
+Copyright (C) 2013 Masterminds
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in
+all copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
+THE SOFTWARE.
diff --git a/backend/vendor/github.com/Masterminds/sprig/Makefile b/backend/vendor/github.com/Masterminds/sprig/Makefile
new file mode 100644
index 00000000..63a93fdf
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/Makefile
@@ -0,0 +1,13 @@
+
+HAS_GLIDE := $(shell command -v glide;)
+
+.PHONY: test
+test:
+ go test -v .
+
+.PHONY: setup
+setup:
+ifndef HAS_GLIDE
+ go get -u github.com/Masterminds/glide
+endif
+ glide install
diff --git a/backend/vendor/github.com/Masterminds/sprig/README.md b/backend/vendor/github.com/Masterminds/sprig/README.md
new file mode 100644
index 00000000..25bf3d4f
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/README.md
@@ -0,0 +1,81 @@
+# Sprig: Template functions for Go templates
+[](https://masterminds.github.io/stability/sustained.html)
+[](https://travis-ci.org/Masterminds/sprig)
+
+The Go language comes with a [built-in template
+language](http://golang.org/pkg/text/template/), but not
+very many template functions. This library provides a group of commonly
+used template functions.
+
+It is inspired by the template functions found in
+[Twig](http://twig.sensiolabs.org/documentation) and also in various
+JavaScript libraries, such as [underscore.js](http://underscorejs.org/).
+
+## Usage
+
+Template developers can read the [Sprig function documentation](http://masterminds.github.io/sprig/) to
+learn about the >100 template functions available.
+
+For Go developers wishing to include Sprig as a library in their programs,
+API documentation is available [at GoDoc.org](http://godoc.org/github.com/Masterminds/sprig), but
+read on for standard usage.
+
+### Load the Sprig library
+
+To load the Sprig `FuncMap`:
+
+```go
+
+import (
+ "github.com/Masterminds/sprig"
+ "html/template"
+)
+
+// This example illustrates that the FuncMap *must* be set before the
+// templates themselves are loaded.
+tpl := template.Must(
+ template.New("base").Funcs(sprig.FuncMap()).ParseGlob("*.html")
+)
+
+
+```
+
+### Call the functions inside of templates
+
+By convention, all functions are lowercase. This seems to follow the Go
+idiom for template functions (as opposed to template methods, which are
+TitleCase).
+
+
+Example:
+
+```
+{{ "hello!" | upper | repeat 5 }}
+```
+
+Produces:
+
+```
+HELLO!HELLO!HELLO!HELLO!HELLO!
+```
+
+## Principles:
+
+The following principles were used in deciding on which functions to add, and
+determining how to implement them.
+
+- Template functions should be used to build layout. Therefore, the following
+ types of operations are within the domain of template functions:
+ - Formatting
+ - Layout
+ - Simple type conversions
+ - Utilities that assist in handling common formatting and layout needs (e.g. arithmetic)
+- Template functions should not return errors unless there is no way to print
+ a sensible value. For example, converting a string to an integer should not
+ produce an error if conversion fails. Instead, it should display a default
+ value that can be displayed.
+- Simple math is necessary for grid layouts, pagers, and so on. Complex math
+ (anything other than arithmetic) should be done outside of templates.
+- Template functions only deal with the data passed into them. They never retrieve
+ data from a source.
+- Finally, do not override core Go template functions.
diff --git a/backend/vendor/github.com/Masterminds/sprig/appveyor.yml b/backend/vendor/github.com/Masterminds/sprig/appveyor.yml
new file mode 100644
index 00000000..d545a987
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/appveyor.yml
@@ -0,0 +1,26 @@
+
+version: build-{build}.{branch}
+
+clone_folder: C:\gopath\src\github.com\Masterminds\sprig
+shallow_clone: true
+
+environment:
+ GOPATH: C:\gopath
+
+platform:
+ - x64
+
+install:
+ - go get -u github.com/Masterminds/glide
+ - set PATH=%GOPATH%\bin;%PATH%
+ - go version
+ - go env
+
+build_script:
+ - glide install
+ - go install ./...
+
+test_script:
+ - go test -v
+
+deploy: off
diff --git a/backend/vendor/github.com/Masterminds/sprig/crypto.go b/backend/vendor/github.com/Masterminds/sprig/crypto.go
new file mode 100644
index 00000000..dc6579d6
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/crypto.go
@@ -0,0 +1,435 @@
+package sprig
+
+import (
+ "bytes"
+ "crypto/dsa"
+ "crypto/ecdsa"
+ "crypto/elliptic"
+ "crypto/hmac"
+ "crypto/rand"
+ "crypto/rsa"
+ "crypto/sha1"
+ "crypto/sha256"
+ "crypto/x509"
+ "crypto/x509/pkix"
+ "encoding/asn1"
+ "encoding/base64"
+ "encoding/binary"
+ "encoding/hex"
+ "encoding/pem"
+ "errors"
+ "fmt"
+ "math/big"
+ "net"
+ "time"
+
+ "github.com/google/uuid"
+ "golang.org/x/crypto/scrypt"
+)
+
+func sha256sum(input string) string {
+ hash := sha256.Sum256([]byte(input))
+ return hex.EncodeToString(hash[:])
+}
+
+func sha1sum(input string) string {
+ hash := sha1.Sum([]byte(input))
+ return hex.EncodeToString(hash[:])
+}
+
+// uuidv4 provides a safe and secure UUID v4 implementation
+func uuidv4() string {
+ return fmt.Sprintf("%s", uuid.New())
+}
+
+var master_password_seed = "com.lyndir.masterpassword"
+
+var password_type_templates = map[string][][]byte{
+ "maximum": {[]byte("anoxxxxxxxxxxxxxxxxx"), []byte("axxxxxxxxxxxxxxxxxno")},
+ "long": {[]byte("CvcvnoCvcvCvcv"), []byte("CvcvCvcvnoCvcv"), []byte("CvcvCvcvCvcvno"), []byte("CvccnoCvcvCvcv"), []byte("CvccCvcvnoCvcv"),
+ []byte("CvccCvcvCvcvno"), []byte("CvcvnoCvccCvcv"), []byte("CvcvCvccnoCvcv"), []byte("CvcvCvccCvcvno"), []byte("CvcvnoCvcvCvcc"),
+ []byte("CvcvCvcvnoCvcc"), []byte("CvcvCvcvCvccno"), []byte("CvccnoCvccCvcv"), []byte("CvccCvccnoCvcv"), []byte("CvccCvccCvcvno"),
+ []byte("CvcvnoCvccCvcc"), []byte("CvcvCvccnoCvcc"), []byte("CvcvCvccCvccno"), []byte("CvccnoCvcvCvcc"), []byte("CvccCvcvnoCvcc"),
+ []byte("CvccCvcvCvccno")},
+ "medium": {[]byte("CvcnoCvc"), []byte("CvcCvcno")},
+ "short": {[]byte("Cvcn")},
+ "basic": {[]byte("aaanaaan"), []byte("aannaaan"), []byte("aaannaaa")},
+ "pin": {[]byte("nnnn")},
+}
+
+var template_characters = map[byte]string{
+ 'V': "AEIOU",
+ 'C': "BCDFGHJKLMNPQRSTVWXYZ",
+ 'v': "aeiou",
+ 'c': "bcdfghjklmnpqrstvwxyz",
+ 'A': "AEIOUBCDFGHJKLMNPQRSTVWXYZ",
+ 'a': "AEIOUaeiouBCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz",
+ 'n': "0123456789",
+ 'o': "@&%?,=[]_:-+*$#!'^~;()/.",
+ 'x': "AEIOUaeiouBCDFGHJKLMNPQRSTVWXYZbcdfghjklmnpqrstvwxyz0123456789!@#$%^&*()",
+}
+
+func derivePassword(counter uint32, password_type, password, user, site string) string {
+ var templates = password_type_templates[password_type]
+ if templates == nil {
+ return fmt.Sprintf("cannot find password template %s", password_type)
+ }
+
+ var buffer bytes.Buffer
+ buffer.WriteString(master_password_seed)
+ binary.Write(&buffer, binary.BigEndian, uint32(len(user)))
+ buffer.WriteString(user)
+
+ salt := buffer.Bytes()
+ key, err := scrypt.Key([]byte(password), salt, 32768, 8, 2, 64)
+ if err != nil {
+ return fmt.Sprintf("failed to derive password: %s", err)
+ }
+
+ buffer.Truncate(len(master_password_seed))
+ binary.Write(&buffer, binary.BigEndian, uint32(len(site)))
+ buffer.WriteString(site)
+ binary.Write(&buffer, binary.BigEndian, counter)
+
+ var hmacv = hmac.New(sha256.New, key)
+ hmacv.Write(buffer.Bytes())
+ var seed = hmacv.Sum(nil)
+ var temp = templates[int(seed[0])%len(templates)]
+
+ buffer.Truncate(0)
+ for i, element := range temp {
+ pass_chars := template_characters[element]
+ pass_char := pass_chars[int(seed[i+1])%len(pass_chars)]
+ buffer.WriteByte(pass_char)
+ }
+
+ return buffer.String()
+}
+
+func generatePrivateKey(typ string) string {
+ var priv interface{}
+ var err error
+ switch typ {
+ case "", "rsa":
+ // good enough for government work
+ priv, err = rsa.GenerateKey(rand.Reader, 4096)
+ case "dsa":
+ key := new(dsa.PrivateKey)
+ // again, good enough for government work
+ if err = dsa.GenerateParameters(&key.Parameters, rand.Reader, dsa.L2048N256); err != nil {
+ return fmt.Sprintf("failed to generate dsa params: %s", err)
+ }
+ err = dsa.GenerateKey(key, rand.Reader)
+ priv = key
+ case "ecdsa":
+ // again, good enough for government work
+ priv, err = ecdsa.GenerateKey(elliptic.P256(), rand.Reader)
+ default:
+ return "Unknown type " + typ
+ }
+ if err != nil {
+ return fmt.Sprintf("failed to generate private key: %s", err)
+ }
+
+ return string(pem.EncodeToMemory(pemBlockForKey(priv)))
+}
+
+type DSAKeyFormat struct {
+ Version int
+ P, Q, G, Y, X *big.Int
+}
+
+func pemBlockForKey(priv interface{}) *pem.Block {
+ switch k := priv.(type) {
+ case *rsa.PrivateKey:
+ return &pem.Block{Type: "RSA PRIVATE KEY", Bytes: x509.MarshalPKCS1PrivateKey(k)}
+ case *dsa.PrivateKey:
+ val := DSAKeyFormat{
+ P: k.P, Q: k.Q, G: k.G,
+ Y: k.Y, X: k.X,
+ }
+ bytes, _ := asn1.Marshal(val)
+ return &pem.Block{Type: "DSA PRIVATE KEY", Bytes: bytes}
+ case *ecdsa.PrivateKey:
+ b, _ := x509.MarshalECPrivateKey(k)
+ return &pem.Block{Type: "EC PRIVATE KEY", Bytes: b}
+ default:
+ return nil
+ }
+}
+
+type certificate struct {
+ Cert string
+ Key string
+}
+
+func buildCustomCertificate(b64cert string, b64key string) (certificate, error) {
+ crt := certificate{}
+
+ cert, err := base64.StdEncoding.DecodeString(b64cert)
+ if err != nil {
+ return crt, errors.New("unable to decode base64 certificate")
+ }
+
+ key, err := base64.StdEncoding.DecodeString(b64key)
+ if err != nil {
+ return crt, errors.New("unable to decode base64 private key")
+ }
+
+ decodedCert, _ := pem.Decode(cert)
+ if decodedCert == nil {
+ return crt, errors.New("unable to decode certificate")
+ }
+ _, err = x509.ParseCertificate(decodedCert.Bytes)
+ if err != nil {
+ return crt, fmt.Errorf(
+ "error parsing certificate: decodedCert.Bytes: %s",
+ err,
+ )
+ }
+
+ decodedKey, _ := pem.Decode(key)
+ if decodedKey == nil {
+ return crt, errors.New("unable to decode key")
+ }
+ _, err = x509.ParsePKCS1PrivateKey(decodedKey.Bytes)
+ if err != nil {
+ return crt, fmt.Errorf(
+ "error parsing prive key: decodedKey.Bytes: %s",
+ err,
+ )
+ }
+
+ crt.Cert = string(cert)
+ crt.Key = string(key)
+
+ return crt, nil
+}
+
+func generateCertificateAuthority(
+ cn string,
+ daysValid int,
+) (certificate, error) {
+ ca := certificate{}
+
+ template, err := getBaseCertTemplate(cn, nil, nil, daysValid)
+ if err != nil {
+ return ca, err
+ }
+ // Override KeyUsage and IsCA
+ template.KeyUsage = x509.KeyUsageKeyEncipherment |
+ x509.KeyUsageDigitalSignature |
+ x509.KeyUsageCertSign
+ template.IsCA = true
+
+ priv, err := rsa.GenerateKey(rand.Reader, 2048)
+ if err != nil {
+ return ca, fmt.Errorf("error generating rsa key: %s", err)
+ }
+
+ ca.Cert, ca.Key, err = getCertAndKey(template, priv, template, priv)
+ if err != nil {
+ return ca, err
+ }
+
+ return ca, nil
+}
+
+func generateSelfSignedCertificate(
+ cn string,
+ ips []interface{},
+ alternateDNS []interface{},
+ daysValid int,
+) (certificate, error) {
+ cert := certificate{}
+
+ template, err := getBaseCertTemplate(cn, ips, alternateDNS, daysValid)
+ if err != nil {
+ return cert, err
+ }
+
+ priv, err := rsa.GenerateKey(rand.Reader, 2048)
+ if err != nil {
+ return cert, fmt.Errorf("error generating rsa key: %s", err)
+ }
+
+ cert.Cert, cert.Key, err = getCertAndKey(template, priv, template, priv)
+ if err != nil {
+ return cert, err
+ }
+
+ return cert, nil
+}
+
+func generateSignedCertificate(
+ cn string,
+ ips []interface{},
+ alternateDNS []interface{},
+ daysValid int,
+ ca certificate,
+) (certificate, error) {
+ cert := certificate{}
+
+ decodedSignerCert, _ := pem.Decode([]byte(ca.Cert))
+ if decodedSignerCert == nil {
+ return cert, errors.New("unable to decode certificate")
+ }
+ signerCert, err := x509.ParseCertificate(decodedSignerCert.Bytes)
+ if err != nil {
+ return cert, fmt.Errorf(
+ "error parsing certificate: decodedSignerCert.Bytes: %s",
+ err,
+ )
+ }
+ decodedSignerKey, _ := pem.Decode([]byte(ca.Key))
+ if decodedSignerKey == nil {
+ return cert, errors.New("unable to decode key")
+ }
+ signerKey, err := x509.ParsePKCS1PrivateKey(decodedSignerKey.Bytes)
+ if err != nil {
+ return cert, fmt.Errorf(
+ "error parsing prive key: decodedSignerKey.Bytes: %s",
+ err,
+ )
+ }
+
+ template, err := getBaseCertTemplate(cn, ips, alternateDNS, daysValid)
+ if err != nil {
+ return cert, err
+ }
+
+ priv, err := rsa.GenerateKey(rand.Reader, 2048)
+ if err != nil {
+ return cert, fmt.Errorf("error generating rsa key: %s", err)
+ }
+
+ cert.Cert, cert.Key, err = getCertAndKey(
+ template,
+ priv,
+ signerCert,
+ signerKey,
+ )
+ if err != nil {
+ return cert, err
+ }
+
+ return cert, nil
+}
+
+func getCertAndKey(
+ template *x509.Certificate,
+ signeeKey *rsa.PrivateKey,
+ parent *x509.Certificate,
+ signingKey *rsa.PrivateKey,
+) (string, string, error) {
+ derBytes, err := x509.CreateCertificate(
+ rand.Reader,
+ template,
+ parent,
+ &signeeKey.PublicKey,
+ signingKey,
+ )
+ if err != nil {
+ return "", "", fmt.Errorf("error creating certificate: %s", err)
+ }
+
+ certBuffer := bytes.Buffer{}
+ if err := pem.Encode(
+ &certBuffer,
+ &pem.Block{Type: "CERTIFICATE", Bytes: derBytes},
+ ); err != nil {
+ return "", "", fmt.Errorf("error pem-encoding certificate: %s", err)
+ }
+
+ keyBuffer := bytes.Buffer{}
+ if err := pem.Encode(
+ &keyBuffer,
+ &pem.Block{
+ Type: "RSA PRIVATE KEY",
+ Bytes: x509.MarshalPKCS1PrivateKey(signeeKey),
+ },
+ ); err != nil {
+ return "", "", fmt.Errorf("error pem-encoding key: %s", err)
+ }
+
+ return string(certBuffer.Bytes()), string(keyBuffer.Bytes()), nil
+}
+
+func getBaseCertTemplate(
+ cn string,
+ ips []interface{},
+ alternateDNS []interface{},
+ daysValid int,
+) (*x509.Certificate, error) {
+ ipAddresses, err := getNetIPs(ips)
+ if err != nil {
+ return nil, err
+ }
+ dnsNames, err := getAlternateDNSStrs(alternateDNS)
+ if err != nil {
+ return nil, err
+ }
+ serialNumberUpperBound := new(big.Int).Lsh(big.NewInt(1), 128)
+ serialNumber, err := rand.Int(rand.Reader, serialNumberUpperBound)
+ if err != nil {
+ return nil, err
+ }
+ return &x509.Certificate{
+ SerialNumber: serialNumber,
+ Subject: pkix.Name{
+ CommonName: cn,
+ },
+ IPAddresses: ipAddresses,
+ DNSNames: dnsNames,
+ NotBefore: time.Now(),
+ NotAfter: time.Now().Add(time.Hour * 24 * time.Duration(daysValid)),
+ KeyUsage: x509.KeyUsageKeyEncipherment | x509.KeyUsageDigitalSignature,
+ ExtKeyUsage: []x509.ExtKeyUsage{
+ x509.ExtKeyUsageServerAuth,
+ x509.ExtKeyUsageClientAuth,
+ },
+ BasicConstraintsValid: true,
+ }, nil
+}
+
+func getNetIPs(ips []interface{}) ([]net.IP, error) {
+ if ips == nil {
+ return []net.IP{}, nil
+ }
+ var ipStr string
+ var ok bool
+ var netIP net.IP
+ netIPs := make([]net.IP, len(ips))
+ for i, ip := range ips {
+ ipStr, ok = ip.(string)
+ if !ok {
+ return nil, fmt.Errorf("error parsing ip: %v is not a string", ip)
+ }
+ netIP = net.ParseIP(ipStr)
+ if netIP == nil {
+ return nil, fmt.Errorf("error parsing ip: %s", ipStr)
+ }
+ netIPs[i] = netIP
+ }
+ return netIPs, nil
+}
+
+func getAlternateDNSStrs(alternateDNS []interface{}) ([]string, error) {
+ if alternateDNS == nil {
+ return []string{}, nil
+ }
+ var dnsStr string
+ var ok bool
+ alternateDNSStrs := make([]string, len(alternateDNS))
+ for i, dns := range alternateDNS {
+ dnsStr, ok = dns.(string)
+ if !ok {
+ return nil, fmt.Errorf(
+ "error processing alternate dns name: %v is not a string",
+ dns,
+ )
+ }
+ alternateDNSStrs[i] = dnsStr
+ }
+ return alternateDNSStrs, nil
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/date.go b/backend/vendor/github.com/Masterminds/sprig/date.go
new file mode 100644
index 00000000..1c2c3653
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/date.go
@@ -0,0 +1,76 @@
+package sprig
+
+import (
+ "time"
+)
+
+// Given a format and a date, format the date string.
+//
+// Date can be a `time.Time` or an `int, int32, int64`.
+// In the later case, it is treated as seconds since UNIX
+// epoch.
+func date(fmt string, date interface{}) string {
+ return dateInZone(fmt, date, "Local")
+}
+
+func htmlDate(date interface{}) string {
+ return dateInZone("2006-01-02", date, "Local")
+}
+
+func htmlDateInZone(date interface{}, zone string) string {
+ return dateInZone("2006-01-02", date, zone)
+}
+
+func dateInZone(fmt string, date interface{}, zone string) string {
+ var t time.Time
+ switch date := date.(type) {
+ default:
+ t = time.Now()
+ case time.Time:
+ t = date
+ case int64:
+ t = time.Unix(date, 0)
+ case int:
+ t = time.Unix(int64(date), 0)
+ case int32:
+ t = time.Unix(int64(date), 0)
+ }
+
+ loc, err := time.LoadLocation(zone)
+ if err != nil {
+ loc, _ = time.LoadLocation("UTC")
+ }
+
+ return t.In(loc).Format(fmt)
+}
+
+func dateModify(fmt string, date time.Time) time.Time {
+ d, err := time.ParseDuration(fmt)
+ if err != nil {
+ return date
+ }
+ return date.Add(d)
+}
+
+func dateAgo(date interface{}) string {
+ var t time.Time
+
+ switch date := date.(type) {
+ default:
+ t = time.Now()
+ case time.Time:
+ t = date
+ case int64:
+ t = time.Unix(date, 0)
+ case int:
+ t = time.Unix(int64(date), 0)
+ }
+ // Drop resolution to seconds
+ duration := time.Since(t).Round(time.Second)
+ return duration.String()
+}
+
+func toDate(fmt, str string) time.Time {
+ t, _ := time.ParseInLocation(fmt, str, time.Local)
+ return t
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/defaults.go b/backend/vendor/github.com/Masterminds/sprig/defaults.go
new file mode 100644
index 00000000..ed6a8ab2
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/defaults.go
@@ -0,0 +1,83 @@
+package sprig
+
+import (
+ "encoding/json"
+ "reflect"
+)
+
+// dfault checks whether `given` is set, and returns default if not set.
+//
+// This returns `d` if `given` appears not to be set, and `given` otherwise.
+//
+// For numeric types 0 is unset.
+// For strings, maps, arrays, and slices, len() = 0 is considered unset.
+// For bool, false is unset.
+// Structs are never considered unset.
+//
+// For everything else, including pointers, a nil value is unset.
+func dfault(d interface{}, given ...interface{}) interface{} {
+
+ if empty(given) || empty(given[0]) {
+ return d
+ }
+ return given[0]
+}
+
+// empty returns true if the given value has the zero value for its type.
+func empty(given interface{}) bool {
+ g := reflect.ValueOf(given)
+ if !g.IsValid() {
+ return true
+ }
+
+ // Basically adapted from text/template.isTrue
+ switch g.Kind() {
+ default:
+ return g.IsNil()
+ case reflect.Array, reflect.Slice, reflect.Map, reflect.String:
+ return g.Len() == 0
+ case reflect.Bool:
+ return g.Bool() == false
+ case reflect.Complex64, reflect.Complex128:
+ return g.Complex() == 0
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return g.Int() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return g.Uint() == 0
+ case reflect.Float32, reflect.Float64:
+ return g.Float() == 0
+ case reflect.Struct:
+ return false
+ }
+}
+
+// coalesce returns the first non-empty value.
+func coalesce(v ...interface{}) interface{} {
+ for _, val := range v {
+ if !empty(val) {
+ return val
+ }
+ }
+ return nil
+}
+
+// toJson encodes an item into a JSON string
+func toJson(v interface{}) string {
+ output, _ := json.Marshal(v)
+ return string(output)
+}
+
+// toPrettyJson encodes an item into a pretty (indented) JSON string
+func toPrettyJson(v interface{}) string {
+ output, _ := json.MarshalIndent(v, "", " ")
+ return string(output)
+}
+
+// ternary returns the first value if the last value is true, otherwise returns the second value.
+func ternary(vt interface{}, vf interface{}, v bool) interface{} {
+ if v {
+ return vt
+ }
+
+ return vf
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/dict.go b/backend/vendor/github.com/Masterminds/sprig/dict.go
new file mode 100644
index 00000000..3713e58a
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/dict.go
@@ -0,0 +1,97 @@
+package sprig
+
+import "github.com/imdario/mergo"
+
+func set(d map[string]interface{}, key string, value interface{}) map[string]interface{} {
+ d[key] = value
+ return d
+}
+
+func unset(d map[string]interface{}, key string) map[string]interface{} {
+ delete(d, key)
+ return d
+}
+
+func hasKey(d map[string]interface{}, key string) bool {
+ _, ok := d[key]
+ return ok
+}
+
+func pluck(key string, d ...map[string]interface{}) []interface{} {
+ res := []interface{}{}
+ for _, dict := range d {
+ if val, ok := dict[key]; ok {
+ res = append(res, val)
+ }
+ }
+ return res
+}
+
+func keys(dicts ...map[string]interface{}) []string {
+ k := []string{}
+ for _, dict := range dicts {
+ for key := range dict {
+ k = append(k, key)
+ }
+ }
+ return k
+}
+
+func pick(dict map[string]interface{}, keys ...string) map[string]interface{} {
+ res := map[string]interface{}{}
+ for _, k := range keys {
+ if v, ok := dict[k]; ok {
+ res[k] = v
+ }
+ }
+ return res
+}
+
+func omit(dict map[string]interface{}, keys ...string) map[string]interface{} {
+ res := map[string]interface{}{}
+
+ omit := make(map[string]bool, len(keys))
+ for _, k := range keys {
+ omit[k] = true
+ }
+
+ for k, v := range dict {
+ if _, ok := omit[k]; !ok {
+ res[k] = v
+ }
+ }
+ return res
+}
+
+func dict(v ...interface{}) map[string]interface{} {
+ dict := map[string]interface{}{}
+ lenv := len(v)
+ for i := 0; i < lenv; i += 2 {
+ key := strval(v[i])
+ if i+1 >= lenv {
+ dict[key] = ""
+ continue
+ }
+ dict[key] = v[i+1]
+ }
+ return dict
+}
+
+func merge(dst map[string]interface{}, srcs ...map[string]interface{}) interface{} {
+ for _, src := range srcs {
+ if err := mergo.Merge(&dst, src); err != nil {
+ // Swallow errors inside of a template.
+ return ""
+ }
+ }
+ return dst
+}
+
+func values(dict map[string]interface{}) []interface{} {
+ values := []interface{}{}
+ for _, value := range dict {
+ values = append(values, value)
+ }
+
+ return values
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/doc.go b/backend/vendor/github.com/Masterminds/sprig/doc.go
new file mode 100644
index 00000000..8f8f1d73
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/doc.go
@@ -0,0 +1,19 @@
+/*
+Sprig: Template functions for Go.
+
+This package contains a number of utility functions for working with data
+inside of Go `html/template` and `text/template` files.
+
+To add these functions, use the `template.Funcs()` method:
+
+ t := templates.New("foo").Funcs(sprig.FuncMap())
+
+Note that you should add the function map before you parse any template files.
+
+ In several cases, Sprig reverses the order of arguments from the way they
+ appear in the standard library. This is to make it easier to pipe
+ arguments into functions.
+
+See http://masterminds.github.io/sprig/ for more detailed documentation on each of the available functions.
+*/
+package sprig
diff --git a/backend/vendor/github.com/Masterminds/sprig/functions.go b/backend/vendor/github.com/Masterminds/sprig/functions.go
new file mode 100644
index 00000000..e985e969
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/functions.go
@@ -0,0 +1,285 @@
+package sprig
+
+import (
+ "errors"
+ "html/template"
+ "os"
+ "path"
+ "strconv"
+ "strings"
+ ttemplate "text/template"
+ "time"
+
+ util "github.com/aokoli/goutils"
+ "github.com/huandu/xstrings"
+)
+
+// Produce the function map.
+//
+// Use this to pass the functions into the template engine:
+//
+// tpl := template.New("foo").Funcs(sprig.FuncMap()))
+//
+func FuncMap() template.FuncMap {
+ return HtmlFuncMap()
+}
+
+// HermeticTextFuncMap returns a 'text/template'.FuncMap with only repeatable functions.
+func HermeticTxtFuncMap() ttemplate.FuncMap {
+ r := TxtFuncMap()
+ for _, name := range nonhermeticFunctions {
+ delete(r, name)
+ }
+ return r
+}
+
+// HermeticHtmlFuncMap returns an 'html/template'.Funcmap with only repeatable functions.
+func HermeticHtmlFuncMap() template.FuncMap {
+ r := HtmlFuncMap()
+ for _, name := range nonhermeticFunctions {
+ delete(r, name)
+ }
+ return r
+}
+
+// TextFuncMap returns a 'text/template'.FuncMap
+func TxtFuncMap() ttemplate.FuncMap {
+ return ttemplate.FuncMap(GenericFuncMap())
+}
+
+// HtmlFuncMap returns an 'html/template'.Funcmap
+func HtmlFuncMap() template.FuncMap {
+ return template.FuncMap(GenericFuncMap())
+}
+
+// GenericFuncMap returns a copy of the basic function map as a map[string]interface{}.
+func GenericFuncMap() map[string]interface{} {
+ gfm := make(map[string]interface{}, len(genericMap))
+ for k, v := range genericMap {
+ gfm[k] = v
+ }
+ return gfm
+}
+
+// These functions are not guaranteed to evaluate to the same result for given input, because they
+// refer to the environemnt or global state.
+var nonhermeticFunctions = []string{
+ // Date functions
+ "date",
+ "date_in_zone",
+ "date_modify",
+ "now",
+ "htmlDate",
+ "htmlDateInZone",
+ "dateInZone",
+ "dateModify",
+
+ // Strings
+ "randAlphaNum",
+ "randAlpha",
+ "randAscii",
+ "randNumeric",
+ "uuidv4",
+
+ // OS
+ "env",
+ "expandenv",
+}
+
+var genericMap = map[string]interface{}{
+ "hello": func() string { return "Hello!" },
+
+ // Date functions
+ "date": date,
+ "date_in_zone": dateInZone,
+ "date_modify": dateModify,
+ "now": func() time.Time { return time.Now() },
+ "htmlDate": htmlDate,
+ "htmlDateInZone": htmlDateInZone,
+ "dateInZone": dateInZone,
+ "dateModify": dateModify,
+ "ago": dateAgo,
+ "toDate": toDate,
+
+ // Strings
+ "abbrev": abbrev,
+ "abbrevboth": abbrevboth,
+ "trunc": trunc,
+ "trim": strings.TrimSpace,
+ "upper": strings.ToUpper,
+ "lower": strings.ToLower,
+ "title": strings.Title,
+ "untitle": untitle,
+ "substr": substring,
+ // Switch order so that "foo" | repeat 5
+ "repeat": func(count int, str string) string { return strings.Repeat(str, count) },
+ // Deprecated: Use trimAll.
+ "trimall": func(a, b string) string { return strings.Trim(b, a) },
+ // Switch order so that "$foo" | trimall "$"
+ "trimAll": func(a, b string) string { return strings.Trim(b, a) },
+ "trimSuffix": func(a, b string) string { return strings.TrimSuffix(b, a) },
+ "trimPrefix": func(a, b string) string { return strings.TrimPrefix(b, a) },
+ "nospace": util.DeleteWhiteSpace,
+ "initials": initials,
+ "randAlphaNum": randAlphaNumeric,
+ "randAlpha": randAlpha,
+ "randAscii": randAscii,
+ "randNumeric": randNumeric,
+ "swapcase": util.SwapCase,
+ "shuffle": xstrings.Shuffle,
+ "snakecase": xstrings.ToSnakeCase,
+ "camelcase": xstrings.ToCamelCase,
+ "wrap": func(l int, s string) string { return util.Wrap(s, l) },
+ "wrapWith": func(l int, sep, str string) string { return util.WrapCustom(str, l, sep, true) },
+ // Switch order so that "foobar" | contains "foo"
+ "contains": func(substr string, str string) bool { return strings.Contains(str, substr) },
+ "hasPrefix": func(substr string, str string) bool { return strings.HasPrefix(str, substr) },
+ "hasSuffix": func(substr string, str string) bool { return strings.HasSuffix(str, substr) },
+ "quote": quote,
+ "squote": squote,
+ "cat": cat,
+ "indent": indent,
+ "nindent": nindent,
+ "replace": replace,
+ "plural": plural,
+ "sha1sum": sha1sum,
+ "sha256sum": sha256sum,
+ "toString": strval,
+
+ // Wrap Atoi to stop errors.
+ "atoi": func(a string) int { i, _ := strconv.Atoi(a); return i },
+ "int64": toInt64,
+ "int": toInt,
+ "float64": toFloat64,
+
+ //"gt": func(a, b int) bool {return a > b},
+ //"gte": func(a, b int) bool {return a >= b},
+ //"lt": func(a, b int) bool {return a < b},
+ //"lte": func(a, b int) bool {return a <= b},
+
+ // split "/" foo/bar returns map[int]string{0: foo, 1: bar}
+ "split": split,
+ "splitList": func(sep, orig string) []string { return strings.Split(orig, sep) },
+ // splitn "/" foo/bar/fuu returns map[int]string{0: foo, 1: bar/fuu}
+ "splitn": splitn,
+ "toStrings": strslice,
+
+ "until": until,
+ "untilStep": untilStep,
+
+ // VERY basic arithmetic.
+ "add1": func(i interface{}) int64 { return toInt64(i) + 1 },
+ "add": func(i ...interface{}) int64 {
+ var a int64 = 0
+ for _, b := range i {
+ a += toInt64(b)
+ }
+ return a
+ },
+ "sub": func(a, b interface{}) int64 { return toInt64(a) - toInt64(b) },
+ "div": func(a, b interface{}) int64 { return toInt64(a) / toInt64(b) },
+ "mod": func(a, b interface{}) int64 { return toInt64(a) % toInt64(b) },
+ "mul": func(a interface{}, v ...interface{}) int64 {
+ val := toInt64(a)
+ for _, b := range v {
+ val = val * toInt64(b)
+ }
+ return val
+ },
+ "biggest": max,
+ "max": max,
+ "min": min,
+ "ceil": ceil,
+ "floor": floor,
+ "round": round,
+
+ // string slices. Note that we reverse the order b/c that's better
+ // for template processing.
+ "join": join,
+ "sortAlpha": sortAlpha,
+
+ // Defaults
+ "default": dfault,
+ "empty": empty,
+ "coalesce": coalesce,
+ "compact": compact,
+ "toJson": toJson,
+ "toPrettyJson": toPrettyJson,
+ "ternary": ternary,
+
+ // Reflection
+ "typeOf": typeOf,
+ "typeIs": typeIs,
+ "typeIsLike": typeIsLike,
+ "kindOf": kindOf,
+ "kindIs": kindIs,
+
+ // OS:
+ "env": func(s string) string { return os.Getenv(s) },
+ "expandenv": func(s string) string { return os.ExpandEnv(s) },
+
+ // File Paths:
+ "base": path.Base,
+ "dir": path.Dir,
+ "clean": path.Clean,
+ "ext": path.Ext,
+ "isAbs": path.IsAbs,
+
+ // Encoding:
+ "b64enc": base64encode,
+ "b64dec": base64decode,
+ "b32enc": base32encode,
+ "b32dec": base32decode,
+
+ // Data Structures:
+ "tuple": list, // FIXME: with the addition of append/prepend these are no longer immutable.
+ "list": list,
+ "dict": dict,
+ "set": set,
+ "unset": unset,
+ "hasKey": hasKey,
+ "pluck": pluck,
+ "keys": keys,
+ "pick": pick,
+ "omit": omit,
+ "merge": merge,
+ "values": values,
+
+ "append": push, "push": push,
+ "prepend": prepend,
+ "first": first,
+ "rest": rest,
+ "last": last,
+ "initial": initial,
+ "reverse": reverse,
+ "uniq": uniq,
+ "without": without,
+ "has": has,
+ "slice": slice,
+
+ // Crypto:
+ "genPrivateKey": generatePrivateKey,
+ "derivePassword": derivePassword,
+ "buildCustomCert": buildCustomCertificate,
+ "genCA": generateCertificateAuthority,
+ "genSelfSignedCert": generateSelfSignedCertificate,
+ "genSignedCert": generateSignedCertificate,
+
+ // UUIDs:
+ "uuidv4": uuidv4,
+
+ // SemVer:
+ "semver": semver,
+ "semverCompare": semverCompare,
+
+ // Flow Control:
+ "fail": func(msg string) (string, error) { return "", errors.New(msg) },
+
+ // Regex
+ "regexMatch": regexMatch,
+ "regexFindAll": regexFindAll,
+ "regexFind": regexFind,
+ "regexReplaceAll": regexReplaceAll,
+ "regexReplaceAllLiteral": regexReplaceAllLiteral,
+ "regexSplit": regexSplit,
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/glide.yaml b/backend/vendor/github.com/Masterminds/sprig/glide.yaml
new file mode 100644
index 00000000..772ba913
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/glide.yaml
@@ -0,0 +1,15 @@
+package: github.com/Masterminds/sprig
+import:
+- package: github.com/Masterminds/goutils
+ version: ^1.0.0
+- package: github.com/google/uuid
+ version: ^0.2
+- package: golang.org/x/crypto
+ subpackages:
+ - scrypt
+- package: github.com/Masterminds/semver
+ version: v1.2.2
+- package: github.com/stretchr/testify
+- package: github.com/imdario/mergo
+ version: ~0.2.2
+- package: github.com/huandu/xstrings
diff --git a/backend/vendor/github.com/Masterminds/sprig/list.go b/backend/vendor/github.com/Masterminds/sprig/list.go
new file mode 100644
index 00000000..184c1ca1
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/list.go
@@ -0,0 +1,291 @@
+package sprig
+
+import (
+ "fmt"
+ "reflect"
+ "sort"
+)
+
+// Reflection is used in these functions so that slices and arrays of strings,
+// ints, and other types not implementing []interface{} can be worked with.
+// For example, this is useful if you need to work on the output of regexs.
+
+func list(v ...interface{}) []interface{} {
+ return v
+}
+
+func push(list interface{}, v interface{}) []interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ nl := make([]interface{}, l)
+ for i := 0; i < l; i++ {
+ nl[i] = l2.Index(i).Interface()
+ }
+
+ return append(nl, v)
+
+ default:
+ panic(fmt.Sprintf("Cannot push on type %s", tp))
+ }
+}
+
+func prepend(list interface{}, v interface{}) []interface{} {
+ //return append([]interface{}{v}, list...)
+
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ nl := make([]interface{}, l)
+ for i := 0; i < l; i++ {
+ nl[i] = l2.Index(i).Interface()
+ }
+
+ return append([]interface{}{v}, nl...)
+
+ default:
+ panic(fmt.Sprintf("Cannot prepend on type %s", tp))
+ }
+}
+
+func last(list interface{}) interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ if l == 0 {
+ return nil
+ }
+
+ return l2.Index(l - 1).Interface()
+ default:
+ panic(fmt.Sprintf("Cannot find last on type %s", tp))
+ }
+}
+
+func first(list interface{}) interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ if l == 0 {
+ return nil
+ }
+
+ return l2.Index(0).Interface()
+ default:
+ panic(fmt.Sprintf("Cannot find first on type %s", tp))
+ }
+}
+
+func rest(list interface{}) []interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ if l == 0 {
+ return nil
+ }
+
+ nl := make([]interface{}, l-1)
+ for i := 1; i < l; i++ {
+ nl[i-1] = l2.Index(i).Interface()
+ }
+
+ return nl
+ default:
+ panic(fmt.Sprintf("Cannot find rest on type %s", tp))
+ }
+}
+
+func initial(list interface{}) []interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ if l == 0 {
+ return nil
+ }
+
+ nl := make([]interface{}, l-1)
+ for i := 0; i < l-1; i++ {
+ nl[i] = l2.Index(i).Interface()
+ }
+
+ return nl
+ default:
+ panic(fmt.Sprintf("Cannot find initial on type %s", tp))
+ }
+}
+
+func sortAlpha(list interface{}) []string {
+ k := reflect.Indirect(reflect.ValueOf(list)).Kind()
+ switch k {
+ case reflect.Slice, reflect.Array:
+ a := strslice(list)
+ s := sort.StringSlice(a)
+ s.Sort()
+ return s
+ }
+ return []string{strval(list)}
+}
+
+func reverse(v interface{}) []interface{} {
+ tp := reflect.TypeOf(v).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(v)
+
+ l := l2.Len()
+ // We do not sort in place because the incoming array should not be altered.
+ nl := make([]interface{}, l)
+ for i := 0; i < l; i++ {
+ nl[l-i-1] = l2.Index(i).Interface()
+ }
+
+ return nl
+ default:
+ panic(fmt.Sprintf("Cannot find reverse on type %s", tp))
+ }
+}
+
+func compact(list interface{}) []interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ nl := []interface{}{}
+ var item interface{}
+ for i := 0; i < l; i++ {
+ item = l2.Index(i).Interface()
+ if !empty(item) {
+ nl = append(nl, item)
+ }
+ }
+
+ return nl
+ default:
+ panic(fmt.Sprintf("Cannot compact on type %s", tp))
+ }
+}
+
+func uniq(list interface{}) []interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ dest := []interface{}{}
+ var item interface{}
+ for i := 0; i < l; i++ {
+ item = l2.Index(i).Interface()
+ if !inList(dest, item) {
+ dest = append(dest, item)
+ }
+ }
+
+ return dest
+ default:
+ panic(fmt.Sprintf("Cannot find uniq on type %s", tp))
+ }
+}
+
+func inList(haystack []interface{}, needle interface{}) bool {
+ for _, h := range haystack {
+ if reflect.DeepEqual(needle, h) {
+ return true
+ }
+ }
+ return false
+}
+
+func without(list interface{}, omit ...interface{}) []interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ res := []interface{}{}
+ var item interface{}
+ for i := 0; i < l; i++ {
+ item = l2.Index(i).Interface()
+ if !inList(omit, item) {
+ res = append(res, item)
+ }
+ }
+
+ return res
+ default:
+ panic(fmt.Sprintf("Cannot find without on type %s", tp))
+ }
+}
+
+func has(needle interface{}, haystack interface{}) bool {
+ tp := reflect.TypeOf(haystack).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(haystack)
+ var item interface{}
+ l := l2.Len()
+ for i := 0; i < l; i++ {
+ item = l2.Index(i).Interface()
+ if reflect.DeepEqual(needle, item) {
+ return true
+ }
+ }
+
+ return false
+ default:
+ panic(fmt.Sprintf("Cannot find has on type %s", tp))
+ }
+}
+
+// $list := [1, 2, 3, 4, 5]
+// slice $list -> list[0:5] = list[:]
+// slice $list 0 3 -> list[0:3] = list[:3]
+// slice $list 3 5 -> list[3:5]
+// slice $list 3 -> list[3:5] = list[3:]
+func slice(list interface{}, indices ...interface{}) interface{} {
+ tp := reflect.TypeOf(list).Kind()
+ switch tp {
+ case reflect.Slice, reflect.Array:
+ l2 := reflect.ValueOf(list)
+
+ l := l2.Len()
+ if l == 0 {
+ return nil
+ }
+
+ var start, end int
+ if len(indices) > 0 {
+ start = toInt(indices[0])
+ }
+ if len(indices) < 2 {
+ end = l
+ } else {
+ end = toInt(indices[1])
+ }
+
+ return l2.Slice(start, end).Interface()
+ default:
+ panic(fmt.Sprintf("list should be type of slice or array but %s", tp))
+ }
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/numeric.go b/backend/vendor/github.com/Masterminds/sprig/numeric.go
new file mode 100644
index 00000000..4bd89bf7
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/numeric.go
@@ -0,0 +1,159 @@
+package sprig
+
+import (
+ "math"
+ "reflect"
+ "strconv"
+)
+
+// toFloat64 converts 64-bit floats
+func toFloat64(v interface{}) float64 {
+ if str, ok := v.(string); ok {
+ iv, err := strconv.ParseFloat(str, 64)
+ if err != nil {
+ return 0
+ }
+ return iv
+ }
+
+ val := reflect.Indirect(reflect.ValueOf(v))
+ switch val.Kind() {
+ case reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64, reflect.Int:
+ return float64(val.Int())
+ case reflect.Uint8, reflect.Uint16, reflect.Uint32:
+ return float64(val.Uint())
+ case reflect.Uint, reflect.Uint64:
+ return float64(val.Uint())
+ case reflect.Float32, reflect.Float64:
+ return val.Float()
+ case reflect.Bool:
+ if val.Bool() == true {
+ return 1
+ }
+ return 0
+ default:
+ return 0
+ }
+}
+
+func toInt(v interface{}) int {
+ //It's not optimal. Bud I don't want duplicate toInt64 code.
+ return int(toInt64(v))
+}
+
+// toInt64 converts integer types to 64-bit integers
+func toInt64(v interface{}) int64 {
+ if str, ok := v.(string); ok {
+ iv, err := strconv.ParseInt(str, 10, 64)
+ if err != nil {
+ return 0
+ }
+ return iv
+ }
+
+ val := reflect.Indirect(reflect.ValueOf(v))
+ switch val.Kind() {
+ case reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64, reflect.Int:
+ return val.Int()
+ case reflect.Uint8, reflect.Uint16, reflect.Uint32:
+ return int64(val.Uint())
+ case reflect.Uint, reflect.Uint64:
+ tv := val.Uint()
+ if tv <= math.MaxInt64 {
+ return int64(tv)
+ }
+ // TODO: What is the sensible thing to do here?
+ return math.MaxInt64
+ case reflect.Float32, reflect.Float64:
+ return int64(val.Float())
+ case reflect.Bool:
+ if val.Bool() == true {
+ return 1
+ }
+ return 0
+ default:
+ return 0
+ }
+}
+
+func max(a interface{}, i ...interface{}) int64 {
+ aa := toInt64(a)
+ for _, b := range i {
+ bb := toInt64(b)
+ if bb > aa {
+ aa = bb
+ }
+ }
+ return aa
+}
+
+func min(a interface{}, i ...interface{}) int64 {
+ aa := toInt64(a)
+ for _, b := range i {
+ bb := toInt64(b)
+ if bb < aa {
+ aa = bb
+ }
+ }
+ return aa
+}
+
+func until(count int) []int {
+ step := 1
+ if count < 0 {
+ step = -1
+ }
+ return untilStep(0, count, step)
+}
+
+func untilStep(start, stop, step int) []int {
+ v := []int{}
+
+ if stop < start {
+ if step >= 0 {
+ return v
+ }
+ for i := start; i > stop; i += step {
+ v = append(v, i)
+ }
+ return v
+ }
+
+ if step <= 0 {
+ return v
+ }
+ for i := start; i < stop; i += step {
+ v = append(v, i)
+ }
+ return v
+}
+
+func floor(a interface{}) float64 {
+ aa := toFloat64(a)
+ return math.Floor(aa)
+}
+
+func ceil(a interface{}) float64 {
+ aa := toFloat64(a)
+ return math.Ceil(aa)
+}
+
+func round(a interface{}, p int, r_opt ...float64) float64 {
+ roundOn := .5
+ if len(r_opt) > 0 {
+ roundOn = r_opt[0]
+ }
+ val := toFloat64(a)
+ places := toFloat64(p)
+
+ var round float64
+ pow := math.Pow(10, places)
+ digit := pow * val
+ _, div := math.Modf(digit)
+ if div >= roundOn {
+ round = math.Ceil(digit)
+ } else {
+ round = math.Floor(digit)
+ }
+ return round / pow
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/reflect.go b/backend/vendor/github.com/Masterminds/sprig/reflect.go
new file mode 100644
index 00000000..8a65c132
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/reflect.go
@@ -0,0 +1,28 @@
+package sprig
+
+import (
+ "fmt"
+ "reflect"
+)
+
+// typeIs returns true if the src is the type named in target.
+func typeIs(target string, src interface{}) bool {
+ return target == typeOf(src)
+}
+
+func typeIsLike(target string, src interface{}) bool {
+ t := typeOf(src)
+ return target == t || "*"+target == t
+}
+
+func typeOf(src interface{}) string {
+ return fmt.Sprintf("%T", src)
+}
+
+func kindIs(target string, src interface{}) bool {
+ return target == kindOf(src)
+}
+
+func kindOf(src interface{}) string {
+ return reflect.ValueOf(src).Kind().String()
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/regex.go b/backend/vendor/github.com/Masterminds/sprig/regex.go
new file mode 100644
index 00000000..2016f663
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/regex.go
@@ -0,0 +1,35 @@
+package sprig
+
+import (
+ "regexp"
+)
+
+func regexMatch(regex string, s string) bool {
+ match, _ := regexp.MatchString(regex, s)
+ return match
+}
+
+func regexFindAll(regex string, s string, n int) []string {
+ r := regexp.MustCompile(regex)
+ return r.FindAllString(s, n)
+}
+
+func regexFind(regex string, s string) string {
+ r := regexp.MustCompile(regex)
+ return r.FindString(s)
+}
+
+func regexReplaceAll(regex string, s string, repl string) string {
+ r := regexp.MustCompile(regex)
+ return r.ReplaceAllString(s, repl)
+}
+
+func regexReplaceAllLiteral(regex string, s string, repl string) string {
+ r := regexp.MustCompile(regex)
+ return r.ReplaceAllLiteralString(s, repl)
+}
+
+func regexSplit(regex string, s string, n int) []string {
+ r := regexp.MustCompile(regex)
+ return r.Split(s, n)
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/semver.go b/backend/vendor/github.com/Masterminds/sprig/semver.go
new file mode 100644
index 00000000..c2bf8a1f
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/semver.go
@@ -0,0 +1,23 @@
+package sprig
+
+import (
+ sv2 "github.com/Masterminds/semver"
+)
+
+func semverCompare(constraint, version string) (bool, error) {
+ c, err := sv2.NewConstraint(constraint)
+ if err != nil {
+ return false, err
+ }
+
+ v, err := sv2.NewVersion(version)
+ if err != nil {
+ return false, err
+ }
+
+ return c.Check(v), nil
+}
+
+func semver(version string) (*sv2.Version, error) {
+ return sv2.NewVersion(version)
+}
diff --git a/backend/vendor/github.com/Masterminds/sprig/strings.go b/backend/vendor/github.com/Masterminds/sprig/strings.go
new file mode 100644
index 00000000..3a6967cf
--- /dev/null
+++ b/backend/vendor/github.com/Masterminds/sprig/strings.go
@@ -0,0 +1,210 @@
+package sprig
+
+import (
+ "encoding/base32"
+ "encoding/base64"
+ "fmt"
+ "reflect"
+ "strconv"
+ "strings"
+
+ util "github.com/aokoli/goutils"
+)
+
+func base64encode(v string) string {
+ return base64.StdEncoding.EncodeToString([]byte(v))
+}
+
+func base64decode(v string) string {
+ data, err := base64.StdEncoding.DecodeString(v)
+ if err != nil {
+ return err.Error()
+ }
+ return string(data)
+}
+
+func base32encode(v string) string {
+ return base32.StdEncoding.EncodeToString([]byte(v))
+}
+
+func base32decode(v string) string {
+ data, err := base32.StdEncoding.DecodeString(v)
+ if err != nil {
+ return err.Error()
+ }
+ return string(data)
+}
+
+func abbrev(width int, s string) string {
+ if width < 4 {
+ return s
+ }
+ r, _ := util.Abbreviate(s, width)
+ return r
+}
+
+func abbrevboth(left, right int, s string) string {
+ if right < 4 || left > 0 && right < 7 {
+ return s
+ }
+ r, _ := util.AbbreviateFull(s, left, right)
+ return r
+}
+func initials(s string) string {
+ // Wrap this just to eliminate the var args, which templates don't do well.
+ return util.Initials(s)
+}
+
+func randAlphaNumeric(count int) string {
+ // It is not possible, it appears, to actually generate an error here.
+ r, _ := util.RandomAlphaNumeric(count)
+ return r
+}
+
+func randAlpha(count int) string {
+ r, _ := util.RandomAlphabetic(count)
+ return r
+}
+
+func randAscii(count int) string {
+ r, _ := util.RandomAscii(count)
+ return r
+}
+
+func randNumeric(count int) string {
+ r, _ := util.RandomNumeric(count)
+ return r
+}
+
+func untitle(str string) string {
+ return util.Uncapitalize(str)
+}
+
+func quote(str ...interface{}) string {
+ out := make([]string, len(str))
+ for i, s := range str {
+ out[i] = fmt.Sprintf("%q", strval(s))
+ }
+ return strings.Join(out, " ")
+}
+
+func squote(str ...interface{}) string {
+ out := make([]string, len(str))
+ for i, s := range str {
+ out[i] = fmt.Sprintf("'%v'", s)
+ }
+ return strings.Join(out, " ")
+}
+
+func cat(v ...interface{}) string {
+ r := strings.TrimSpace(strings.Repeat("%v ", len(v)))
+ return fmt.Sprintf(r, v...)
+}
+
+func indent(spaces int, v string) string {
+ pad := strings.Repeat(" ", spaces)
+ return pad + strings.Replace(v, "\n", "\n"+pad, -1)
+}
+
+func nindent(spaces int, v string) string {
+ return "\n" + indent(spaces, v)
+}
+
+func replace(old, new, src string) string {
+ return strings.Replace(src, old, new, -1)
+}
+
+func plural(one, many string, count int) string {
+ if count == 1 {
+ return one
+ }
+ return many
+}
+
+func strslice(v interface{}) []string {
+ switch v := v.(type) {
+ case []string:
+ return v
+ case []interface{}:
+ l := len(v)
+ b := make([]string, l)
+ for i := 0; i < l; i++ {
+ b[i] = strval(v[i])
+ }
+ return b
+ default:
+ val := reflect.ValueOf(v)
+ switch val.Kind() {
+ case reflect.Array, reflect.Slice:
+ l := val.Len()
+ b := make([]string, l)
+ for i := 0; i < l; i++ {
+ b[i] = strval(val.Index(i).Interface())
+ }
+ return b
+ default:
+ return []string{strval(v)}
+ }
+ }
+}
+
+func strval(v interface{}) string {
+ switch v := v.(type) {
+ case string:
+ return v
+ case []byte:
+ return string(v)
+ case error:
+ return v.Error()
+ case fmt.Stringer:
+ return v.String()
+ default:
+ return fmt.Sprintf("%v", v)
+ }
+}
+
+func trunc(c int, s string) string {
+ if len(s) <= c {
+ return s
+ }
+ return s[0:c]
+}
+
+func join(sep string, v interface{}) string {
+ return strings.Join(strslice(v), sep)
+}
+
+func split(sep, orig string) map[string]string {
+ parts := strings.Split(orig, sep)
+ res := make(map[string]string, len(parts))
+ for i, v := range parts {
+ res["_"+strconv.Itoa(i)] = v
+ }
+ return res
+}
+
+func splitn(sep string, n int, orig string) map[string]string {
+ parts := strings.SplitN(orig, sep, n)
+ res := make(map[string]string, len(parts))
+ for i, v := range parts {
+ res["_"+strconv.Itoa(i)] = v
+ }
+ return res
+}
+
+// substring creates a substring of the given string.
+//
+// If start is < 0, this calls string[:length].
+//
+// If start is >= 0 and length < 0, this calls string[start:]
+//
+// Otherwise, this calls string[start, length].
+func substring(start, length int, s string) string {
+ if start < 0 {
+ return s[:length]
+ }
+ if length < 0 {
+ return s[start:]
+ }
+ return s[start:length]
+}
diff --git a/backend/vendor/github.com/aokoli/goutils/.travis.yml b/backend/vendor/github.com/aokoli/goutils/.travis.yml
new file mode 100644
index 00000000..4025e01e
--- /dev/null
+++ b/backend/vendor/github.com/aokoli/goutils/.travis.yml
@@ -0,0 +1,18 @@
+language: go
+
+go:
+ - 1.6
+ - 1.7
+ - 1.8
+ - tip
+
+script:
+ - go test -v
+
+notifications:
+ webhooks:
+ urls:
+ - https://webhooks.gitter.im/e/06e3328629952dabe3e0
+ on_success: change # options: [always|never|change] default: always
+ on_failure: always # options: [always|never|change] default: always
+ on_start: never # options: [always|never|change] default: always
diff --git a/backend/vendor/github.com/aokoli/goutils/CHANGELOG.md b/backend/vendor/github.com/aokoli/goutils/CHANGELOG.md
new file mode 100644
index 00000000..d700ec47
--- /dev/null
+++ b/backend/vendor/github.com/aokoli/goutils/CHANGELOG.md
@@ -0,0 +1,8 @@
+# 1.0.1 (2017-05-31)
+
+## Fixed
+- #21: Fix generation of alphanumeric strings (thanks @dbarranco)
+
+# 1.0.0 (2014-04-30)
+
+- Initial release.
diff --git a/backend/vendor/github.com/aokoli/goutils/LICENSE.txt b/backend/vendor/github.com/aokoli/goutils/LICENSE.txt
new file mode 100644
index 00000000..d6456956
--- /dev/null
+++ b/backend/vendor/github.com/aokoli/goutils/LICENSE.txt
@@ -0,0 +1,202 @@
+
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/backend/vendor/github.com/aokoli/goutils/README.md b/backend/vendor/github.com/aokoli/goutils/README.md
new file mode 100644
index 00000000..163ffe72
--- /dev/null
+++ b/backend/vendor/github.com/aokoli/goutils/README.md
@@ -0,0 +1,70 @@
+GoUtils
+===========
+[](https://masterminds.github.io/stability/maintenance.html)
+[](https://godoc.org/github.com/Masterminds/goutils) [](https://travis-ci.org/Masterminds/goutils) [](https://ci.appveyor.com/project/mattfarina/goutils)
+
+
+GoUtils provides users with utility functions to manipulate strings in various ways. It is a Go implementation of some
+string manipulation libraries of Java Apache Commons. GoUtils includes the following Java Apache Commons classes:
+* WordUtils
+* RandomStringUtils
+* StringUtils (partial implementation)
+
+## Installation
+If you have Go set up on your system, from the GOPATH directory within the command line/terminal, enter this:
+
+ go get github.com/Masterminds/goutils
+
+If you do not have Go set up on your system, please follow the [Go installation directions from the documenation](http://golang.org/doc/install), and then follow the instructions above to install GoUtils.
+
+
+## Documentation
+GoUtils doc is available here: [](https://godoc.org/github.com/Masterminds/goutils)
+
+
+## Usage
+The code snippets below show examples of how to use GoUtils. Some functions return errors while others do not. The first instance below, which does not return an error, is the `Initials` function (located within the `wordutils.go` file).
+
+ package main
+
+ import (
+ "fmt"
+ "github.com/Masterminds/goutils"
+ )
+
+ func main() {
+
+ // EXAMPLE 1: A goutils function which returns no errors
+ fmt.Println (goutils.Initials("John Doe Foo")) // Prints out "JDF"
+
+ }
+Some functions return errors mainly due to illegal arguements used as parameters. The code example below illustrates how to deal with function that returns an error. In this instance, the function is the `Random` function (located within the `randomstringutils.go` file).
+
+ package main
+
+ import (
+ "fmt"
+ "github.com/Masterminds/goutils"
+ )
+
+ func main() {
+
+ // EXAMPLE 2: A goutils function which returns an error
+ rand1, err1 := goutils.Random (-1, 0, 0, true, true)
+
+ if err1 != nil {
+ fmt.Println(err1) // Prints out error message because -1 was entered as the first parameter in goutils.Random(...)
+ } else {
+ fmt.Println(rand1)
+ }
+
+ }
+
+## License
+GoUtils is licensed under the Apache License, Version 2.0. Please check the LICENSE.txt file or visit http://www.apache.org/licenses/LICENSE-2.0 for a copy of the license.
+
+## Issue Reporting
+Make suggestions or report issues using the Git issue tracker: https://github.com/Masterminds/goutils/issues
+
+## Website
+* [GoUtils webpage](http://Masterminds.github.io/goutils/)
diff --git a/backend/vendor/github.com/aokoli/goutils/appveyor.yml b/backend/vendor/github.com/aokoli/goutils/appveyor.yml
new file mode 100644
index 00000000..657564a8
--- /dev/null
+++ b/backend/vendor/github.com/aokoli/goutils/appveyor.yml
@@ -0,0 +1,21 @@
+version: build-{build}.{branch}
+
+clone_folder: C:\gopath\src\github.com\Masterminds\goutils
+shallow_clone: true
+
+environment:
+ GOPATH: C:\gopath
+
+platform:
+ - x64
+
+build: off
+
+install:
+ - go version
+ - go env
+
+test_script:
+ - go test -v
+
+deploy: off
diff --git a/backend/vendor/github.com/aokoli/goutils/randomstringutils.go b/backend/vendor/github.com/aokoli/goutils/randomstringutils.go
new file mode 100644
index 00000000..1364e0ca
--- /dev/null
+++ b/backend/vendor/github.com/aokoli/goutils/randomstringutils.go
@@ -0,0 +1,268 @@
+/*
+Copyright 2014 Alexander Okoli
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+*/
+
+package goutils
+
+import (
+ "fmt"
+ "math"
+ "math/rand"
+ "regexp"
+ "time"
+ "unicode"
+)
+
+// RANDOM provides the time-based seed used to generate random numbers
+var RANDOM = rand.New(rand.NewSource(time.Now().UnixNano()))
+
+/*
+RandomNonAlphaNumeric creates a random string whose length is the number of characters specified.
+Characters will be chosen from the set of all characters (ASCII/Unicode values between 0 to 2,147,483,647 (math.MaxInt32)).
+
+Parameter:
+ count - the length of random string to create
+
+Returns:
+ string - the random string
+ error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
+*/
+func RandomNonAlphaNumeric(count int) (string, error) {
+ return RandomAlphaNumericCustom(count, false, false)
+}
+
+/*
+RandomAscii creates a random string whose length is the number of characters specified.
+Characters will be chosen from the set of characters whose ASCII value is between 32 and 126 (inclusive).
+
+Parameter:
+ count - the length of random string to create
+
+Returns:
+ string - the random string
+ error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
+*/
+func RandomAscii(count int) (string, error) {
+ return Random(count, 32, 127, false, false)
+}
+
+/*
+RandomNumeric creates a random string whose length is the number of characters specified.
+Characters will be chosen from the set of numeric characters.
+
+Parameter:
+ count - the length of random string to create
+
+Returns:
+ string - the random string
+ error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
+*/
+func RandomNumeric(count int) (string, error) {
+ return Random(count, 0, 0, false, true)
+}
+
+/*
+RandomAlphabetic creates a random string whose length is the number of characters specified.
+Characters will be chosen from the set of alpha-numeric characters as indicated by the arguments.
+
+Parameters:
+ count - the length of random string to create
+ letters - if true, generated string may include alphabetic characters
+ numbers - if true, generated string may include numeric characters
+
+Returns:
+ string - the random string
+ error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
+*/
+func RandomAlphabetic(count int) (string, error) {
+ return Random(count, 0, 0, true, false)
+}
+
+/*
+RandomAlphaNumeric creates a random string whose length is the number of characters specified.
+Characters will be chosen from the set of alpha-numeric characters.
+
+Parameter:
+ count - the length of random string to create
+
+Returns:
+ string - the random string
+ error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
+*/
+func RandomAlphaNumeric(count int) (string, error) {
+ RandomString, err := Random(count, 0, 0, true, true)
+ if err != nil {
+ return "", fmt.Errorf("Error: %s", err)
+ }
+ match, err := regexp.MatchString("([0-9]+)", RandomString)
+ if err != nil {
+ panic(err)
+ }
+
+ if !match {
+ //Get the position between 0 and the length of the string-1 to insert a random number
+ position := rand.Intn(count)
+ //Insert a random number between [0-9] in the position
+ RandomString = RandomString[:position] + string('0'+rand.Intn(10)) + RandomString[position+1:]
+ return RandomString, err
+ }
+ return RandomString, err
+
+}
+
+/*
+RandomAlphaNumericCustom creates a random string whose length is the number of characters specified.
+Characters will be chosen from the set of alpha-numeric characters as indicated by the arguments.
+
+Parameters:
+ count - the length of random string to create
+ letters - if true, generated string may include alphabetic characters
+ numbers - if true, generated string may include numeric characters
+
+Returns:
+ string - the random string
+ error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
+*/
+func RandomAlphaNumericCustom(count int, letters bool, numbers bool) (string, error) {
+ return Random(count, 0, 0, letters, numbers)
+}
+
+/*
+Random creates a random string based on a variety of options, using default source of randomness.
+This method has exactly the same semantics as RandomSeed(int, int, int, bool, bool, []char, *rand.Rand), but
+instead of using an externally supplied source of randomness, it uses the internal *rand.Rand instance.
+
+Parameters:
+ count - the length of random string to create
+ start - the position in set of chars (ASCII/Unicode int) to start at
+ end - the position in set of chars (ASCII/Unicode int) to end before
+ letters - if true, generated string may include alphabetic characters
+ numbers - if true, generated string may include numeric characters
+ chars - the set of chars to choose randoms from. If nil, then it will use the set of all chars.
+
+Returns:
+ string - the random string
+ error - an error stemming from an invalid parameter within underlying function, RandomSeed(...)
+*/
+func Random(count int, start int, end int, letters bool, numbers bool, chars ...rune) (string, error) {
+ return RandomSeed(count, start, end, letters, numbers, chars, RANDOM)
+}
+
+/*
+RandomSeed creates a random string based on a variety of options, using supplied source of randomness.
+If the parameters start and end are both 0, start and end are set to ' ' and 'z', the ASCII printable characters, will be used,
+unless letters and numbers are both false, in which case, start and end are set to 0 and math.MaxInt32, respectively.
+If chars is not nil, characters stored in chars that are between start and end are chosen.
+This method accepts a user-supplied *rand.Rand instance to use as a source of randomness. By seeding a single *rand.Rand instance
+with a fixed seed and using it for each call, the same random sequence of strings can be generated repeatedly and predictably.
+
+Parameters:
+ count - the length of random string to create
+ start - the position in set of chars (ASCII/Unicode decimals) to start at
+ end - the position in set of chars (ASCII/Unicode decimals) to end before
+ letters - if true, generated string may include alphabetic characters
+ numbers - if true, generated string may include numeric characters
+ chars - the set of chars to choose randoms from. If nil, then it will use the set of all chars.
+ random - a source of randomness.
+
+Returns:
+ string - the random string
+ error - an error stemming from invalid parameters: if count < 0; or the provided chars array is empty; or end <= start; or end > len(chars)
+*/
+func RandomSeed(count int, start int, end int, letters bool, numbers bool, chars []rune, random *rand.Rand) (string, error) {
+
+ if count == 0 {
+ return "", nil
+ } else if count < 0 {
+ err := fmt.Errorf("randomstringutils illegal argument: Requested random string length %v is less than 0.", count) // equiv to err := errors.New("...")
+ return "", err
+ }
+ if chars != nil && len(chars) == 0 {
+ err := fmt.Errorf("randomstringutils illegal argument: The chars array must not be empty")
+ return "", err
+ }
+
+ if start == 0 && end == 0 {
+ if chars != nil {
+ end = len(chars)
+ } else {
+ if !letters && !numbers {
+ end = math.MaxInt32
+ } else {
+ end = 'z' + 1
+ start = ' '
+ }
+ }
+ } else {
+ if end <= start {
+ err := fmt.Errorf("randomstringutils illegal argument: Parameter end (%v) must be greater than start (%v)", end, start)
+ return "", err
+ }
+
+ if chars != nil && end > len(chars) {
+ err := fmt.Errorf("randomstringutils illegal argument: Parameter end (%v) cannot be greater than len(chars) (%v)", end, len(chars))
+ return "", err
+ }
+ }
+
+ buffer := make([]rune, count)
+ gap := end - start
+
+ // high-surrogates range, (\uD800-\uDBFF) = 55296 - 56319
+ // low-surrogates range, (\uDC00-\uDFFF) = 56320 - 57343
+
+ for count != 0 {
+ count--
+ var ch rune
+ if chars == nil {
+ ch = rune(random.Intn(gap) + start)
+ } else {
+ ch = chars[random.Intn(gap)+start]
+ }
+
+ if letters && unicode.IsLetter(ch) || numbers && unicode.IsDigit(ch) || !letters && !numbers {
+ if ch >= 56320 && ch <= 57343 { // low surrogate range
+ if count == 0 {
+ count++
+ } else {
+ // Insert low surrogate
+ buffer[count] = ch
+ count--
+ // Insert high surrogate
+ buffer[count] = rune(55296 + random.Intn(128))
+ }
+ } else if ch >= 55296 && ch <= 56191 { // High surrogates range (Partial)
+ if count == 0 {
+ count++
+ } else {
+ // Insert low surrogate
+ buffer[count] = rune(56320 + random.Intn(128))
+ count--
+ // Insert high surrogate
+ buffer[count] = ch
+ }
+ } else if ch >= 56192 && ch <= 56319 {
+ // private high surrogate, skip it
+ count++
+ } else {
+ // not one of the surrogates*
+ buffer[count] = ch
+ }
+ } else {
+ count++
+ }
+ }
+ return string(buffer), nil
+}
diff --git a/backend/vendor/github.com/aokoli/goutils/stringutils.go b/backend/vendor/github.com/aokoli/goutils/stringutils.go
new file mode 100644
index 00000000..5037c451
--- /dev/null
+++ b/backend/vendor/github.com/aokoli/goutils/stringutils.go
@@ -0,0 +1,224 @@
+/*
+Copyright 2014 Alexander Okoli
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+*/
+
+package goutils
+
+import (
+ "bytes"
+ "fmt"
+ "strings"
+ "unicode"
+)
+
+// Typically returned by functions where a searched item cannot be found
+const INDEX_NOT_FOUND = -1
+
+/*
+Abbreviate abbreviates a string using ellipses. This will turn the string "Now is the time for all good men" into "Now is the time for..."
+
+Specifically, the algorithm is as follows:
+
+ - If str is less than maxWidth characters long, return it.
+ - Else abbreviate it to (str[0:maxWidth - 3] + "...").
+ - If maxWidth is less than 4, return an illegal argument error.
+ - In no case will it return a string of length greater than maxWidth.
+
+Parameters:
+ str - the string to check
+ maxWidth - maximum length of result string, must be at least 4
+
+Returns:
+ string - abbreviated string
+ error - if the width is too small
+*/
+func Abbreviate(str string, maxWidth int) (string, error) {
+ return AbbreviateFull(str, 0, maxWidth)
+}
+
+/*
+AbbreviateFull abbreviates a string using ellipses. This will turn the string "Now is the time for all good men" into "...is the time for..."
+This function works like Abbreviate(string, int), but allows you to specify a "left edge" offset. Note that this left edge is not
+necessarily going to be the leftmost character in the result, or the first character following the ellipses, but it will appear
+somewhere in the result.
+In no case will it return a string of length greater than maxWidth.
+
+Parameters:
+ str - the string to check
+ offset - left edge of source string
+ maxWidth - maximum length of result string, must be at least 4
+
+Returns:
+ string - abbreviated string
+ error - if the width is too small
+*/
+func AbbreviateFull(str string, offset int, maxWidth int) (string, error) {
+ if str == "" {
+ return "", nil
+ }
+ if maxWidth < 4 {
+ err := fmt.Errorf("stringutils illegal argument: Minimum abbreviation width is 4")
+ return "", err
+ }
+ if len(str) <= maxWidth {
+ return str, nil
+ }
+ if offset > len(str) {
+ offset = len(str)
+ }
+ if len(str)-offset < (maxWidth - 3) { // 15 - 5 < 10 - 3 = 10 < 7
+ offset = len(str) - (maxWidth - 3)
+ }
+ abrevMarker := "..."
+ if offset <= 4 {
+ return str[0:maxWidth-3] + abrevMarker, nil // str.substring(0, maxWidth - 3) + abrevMarker;
+ }
+ if maxWidth < 7 {
+ err := fmt.Errorf("stringutils illegal argument: Minimum abbreviation width with offset is 7")
+ return "", err
+ }
+ if (offset + maxWidth - 3) < len(str) { // 5 + (10-3) < 15 = 12 < 15
+ abrevStr, _ := Abbreviate(str[offset:len(str)], (maxWidth - 3))
+ return abrevMarker + abrevStr, nil // abrevMarker + abbreviate(str.substring(offset), maxWidth - 3);
+ }
+ return abrevMarker + str[(len(str)-(maxWidth-3)):len(str)], nil // abrevMarker + str.substring(str.length() - (maxWidth - 3));
+}
+
+/*
+DeleteWhiteSpace deletes all whitespaces from a string as defined by unicode.IsSpace(rune).
+It returns the string without whitespaces.
+
+Parameter:
+ str - the string to delete whitespace from, may be nil
+
+Returns:
+ the string without whitespaces
+*/
+func DeleteWhiteSpace(str string) string {
+ if str == "" {
+ return str
+ }
+ sz := len(str)
+ var chs bytes.Buffer
+ count := 0
+ for i := 0; i < sz; i++ {
+ ch := rune(str[i])
+ if !unicode.IsSpace(ch) {
+ chs.WriteRune(ch)
+ count++
+ }
+ }
+ if count == sz {
+ return str
+ }
+ return chs.String()
+}
+
+/*
+IndexOfDifference compares two strings, and returns the index at which the strings begin to differ.
+
+Parameters:
+ str1 - the first string
+ str2 - the second string
+
+Returns:
+ the index where str1 and str2 begin to differ; -1 if they are equal
+*/
+func IndexOfDifference(str1 string, str2 string) int {
+ if str1 == str2 {
+ return INDEX_NOT_FOUND
+ }
+ if IsEmpty(str1) || IsEmpty(str2) {
+ return 0
+ }
+ var i int
+ for i = 0; i < len(str1) && i < len(str2); i++ {
+ if rune(str1[i]) != rune(str2[i]) {
+ break
+ }
+ }
+ if i < len(str2) || i < len(str1) {
+ return i
+ }
+ return INDEX_NOT_FOUND
+}
+
+/*
+IsBlank checks if a string is whitespace or empty (""). Observe the following behavior:
+
+ goutils.IsBlank("") = true
+ goutils.IsBlank(" ") = true
+ goutils.IsBlank("bob") = false
+ goutils.IsBlank(" bob ") = false
+
+Parameter:
+ str - the string to check
+
+Returns:
+ true - if the string is whitespace or empty ("")
+*/
+func IsBlank(str string) bool {
+ strLen := len(str)
+ if str == "" || strLen == 0 {
+ return true
+ }
+ for i := 0; i < strLen; i++ {
+ if unicode.IsSpace(rune(str[i])) == false {
+ return false
+ }
+ }
+ return true
+}
+
+/*
+IndexOf returns the index of the first instance of sub in str, with the search beginning from the
+index start point specified. -1 is returned if sub is not present in str.
+
+An empty string ("") will return -1 (INDEX_NOT_FOUND). A negative start position is treated as zero.
+A start position greater than the string length returns -1.
+
+Parameters:
+ str - the string to check
+ sub - the substring to find
+ start - the start position; negative treated as zero
+
+Returns:
+ the first index where the sub string was found (always >= start)
+*/
+func IndexOf(str string, sub string, start int) int {
+
+ if start < 0 {
+ start = 0
+ }
+
+ if len(str) < start {
+ return INDEX_NOT_FOUND
+ }
+
+ if IsEmpty(str) || IsEmpty(sub) {
+ return INDEX_NOT_FOUND
+ }
+
+ partialIndex := strings.Index(str[start:len(str)], sub)
+ if partialIndex == -1 {
+ return INDEX_NOT_FOUND
+ }
+ return partialIndex + start
+}
+
+// IsEmpty checks if a string is empty (""). Returns true if empty, and false otherwise.
+func IsEmpty(str string) bool {
+ return len(str) == 0
+}
diff --git a/backend/vendor/github.com/aokoli/goutils/wordutils.go b/backend/vendor/github.com/aokoli/goutils/wordutils.go
new file mode 100644
index 00000000..e92dd399
--- /dev/null
+++ b/backend/vendor/github.com/aokoli/goutils/wordutils.go
@@ -0,0 +1,356 @@
+/*
+Copyright 2014 Alexander Okoli
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
+*/
+
+/*
+Package goutils provides utility functions to manipulate strings in various ways.
+The code snippets below show examples of how to use goutils. Some functions return
+errors while others do not, so usage would vary as a result.
+
+Example:
+
+ package main
+
+ import (
+ "fmt"
+ "github.com/aokoli/goutils"
+ )
+
+ func main() {
+
+ // EXAMPLE 1: A goutils function which returns no errors
+ fmt.Println (goutils.Initials("John Doe Foo")) // Prints out "JDF"
+
+
+
+ // EXAMPLE 2: A goutils function which returns an error
+ rand1, err1 := goutils.Random (-1, 0, 0, true, true)
+
+ if err1 != nil {
+ fmt.Println(err1) // Prints out error message because -1 was entered as the first parameter in goutils.Random(...)
+ } else {
+ fmt.Println(rand1)
+ }
+ }
+*/
+package goutils
+
+import (
+ "bytes"
+ "strings"
+ "unicode"
+)
+
+// VERSION indicates the current version of goutils
+const VERSION = "1.0.0"
+
+/*
+Wrap wraps a single line of text, identifying words by ' '.
+New lines will be separated by '\n'. Very long words, such as URLs will not be wrapped.
+Leading spaces on a new line are stripped. Trailing spaces are not stripped.
+
+Parameters:
+ str - the string to be word wrapped
+ wrapLength - the column (a column can fit only one character) to wrap the words at, less than 1 is treated as 1
+
+Returns:
+ a line with newlines inserted
+*/
+func Wrap(str string, wrapLength int) string {
+ return WrapCustom(str, wrapLength, "", false)
+}
+
+/*
+WrapCustom wraps a single line of text, identifying words by ' '.
+Leading spaces on a new line are stripped. Trailing spaces are not stripped.
+
+Parameters:
+ str - the string to be word wrapped
+ wrapLength - the column number (a column can fit only one character) to wrap the words at, less than 1 is treated as 1
+ newLineStr - the string to insert for a new line, "" uses '\n'
+ wrapLongWords - true if long words (such as URLs) should be wrapped
+
+Returns:
+ a line with newlines inserted
+*/
+func WrapCustom(str string, wrapLength int, newLineStr string, wrapLongWords bool) string {
+
+ if str == "" {
+ return ""
+ }
+ if newLineStr == "" {
+ newLineStr = "\n" // TODO Assumes "\n" is seperator. Explore SystemUtils.LINE_SEPARATOR from Apache Commons
+ }
+ if wrapLength < 1 {
+ wrapLength = 1
+ }
+
+ inputLineLength := len(str)
+ offset := 0
+
+ var wrappedLine bytes.Buffer
+
+ for inputLineLength-offset > wrapLength {
+
+ if rune(str[offset]) == ' ' {
+ offset++
+ continue
+ }
+
+ end := wrapLength + offset + 1
+ spaceToWrapAt := strings.LastIndex(str[offset:end], " ") + offset
+
+ if spaceToWrapAt >= offset {
+ // normal word (not longer than wrapLength)
+ wrappedLine.WriteString(str[offset:spaceToWrapAt])
+ wrappedLine.WriteString(newLineStr)
+ offset = spaceToWrapAt + 1
+
+ } else {
+ // long word or URL
+ if wrapLongWords {
+ end := wrapLength + offset
+ // long words are wrapped one line at a time
+ wrappedLine.WriteString(str[offset:end])
+ wrappedLine.WriteString(newLineStr)
+ offset += wrapLength
+ } else {
+ // long words aren't wrapped, just extended beyond limit
+ end := wrapLength + offset
+ spaceToWrapAt = strings.IndexRune(str[end:len(str)], ' ') + end
+ if spaceToWrapAt >= 0 {
+ wrappedLine.WriteString(str[offset:spaceToWrapAt])
+ wrappedLine.WriteString(newLineStr)
+ offset = spaceToWrapAt + 1
+ } else {
+ wrappedLine.WriteString(str[offset:len(str)])
+ offset = inputLineLength
+ }
+ }
+ }
+ }
+
+ wrappedLine.WriteString(str[offset:len(str)])
+
+ return wrappedLine.String()
+
+}
+
+/*
+Capitalize capitalizes all the delimiter separated words in a string. Only the first letter of each word is changed.
+To convert the rest of each word to lowercase at the same time, use CapitalizeFully(str string, delimiters ...rune).
+The delimiters represent a set of characters understood to separate words. The first string character
+and the first non-delimiter character after a delimiter will be capitalized. A "" input string returns "".
+Capitalization uses the Unicode title case, normally equivalent to upper case.
+
+Parameters:
+ str - the string to capitalize
+ delimiters - set of characters to determine capitalization, exclusion of this parameter means whitespace would be delimeter
+
+Returns:
+ capitalized string
+*/
+func Capitalize(str string, delimiters ...rune) string {
+
+ var delimLen int
+
+ if delimiters == nil {
+ delimLen = -1
+ } else {
+ delimLen = len(delimiters)
+ }
+
+ if str == "" || delimLen == 0 {
+ return str
+ }
+
+ buffer := []rune(str)
+ capitalizeNext := true
+ for i := 0; i < len(buffer); i++ {
+ ch := buffer[i]
+ if isDelimiter(ch, delimiters...) {
+ capitalizeNext = true
+ } else if capitalizeNext {
+ buffer[i] = unicode.ToTitle(ch)
+ capitalizeNext = false
+ }
+ }
+ return string(buffer)
+
+}
+
+/*
+CapitalizeFully converts all the delimiter separated words in a string into capitalized words, that is each word is made up of a
+titlecase character and then a series of lowercase characters. The delimiters represent a set of characters understood
+to separate words. The first string character and the first non-delimiter character after a delimiter will be capitalized.
+Capitalization uses the Unicode title case, normally equivalent to upper case.
+
+Parameters:
+ str - the string to capitalize fully
+ delimiters - set of characters to determine capitalization, exclusion of this parameter means whitespace would be delimeter
+
+Returns:
+ capitalized string
+*/
+func CapitalizeFully(str string, delimiters ...rune) string {
+
+ var delimLen int
+
+ if delimiters == nil {
+ delimLen = -1
+ } else {
+ delimLen = len(delimiters)
+ }
+
+ if str == "" || delimLen == 0 {
+ return str
+ }
+ str = strings.ToLower(str)
+ return Capitalize(str, delimiters...)
+}
+
+/*
+Uncapitalize uncapitalizes all the whitespace separated words in a string. Only the first letter of each word is changed.
+The delimiters represent a set of characters understood to separate words. The first string character and the first non-delimiter
+character after a delimiter will be uncapitalized. Whitespace is defined by unicode.IsSpace(char).
+
+Parameters:
+ str - the string to uncapitalize fully
+ delimiters - set of characters to determine capitalization, exclusion of this parameter means whitespace would be delimeter
+
+Returns:
+ uncapitalized string
+*/
+func Uncapitalize(str string, delimiters ...rune) string {
+
+ var delimLen int
+
+ if delimiters == nil {
+ delimLen = -1
+ } else {
+ delimLen = len(delimiters)
+ }
+
+ if str == "" || delimLen == 0 {
+ return str
+ }
+
+ buffer := []rune(str)
+ uncapitalizeNext := true // TODO Always makes capitalize/un apply to first char.
+ for i := 0; i < len(buffer); i++ {
+ ch := buffer[i]
+ if isDelimiter(ch, delimiters...) {
+ uncapitalizeNext = true
+ } else if uncapitalizeNext {
+ buffer[i] = unicode.ToLower(ch)
+ uncapitalizeNext = false
+ }
+ }
+ return string(buffer)
+}
+
+/*
+SwapCase swaps the case of a string using a word based algorithm.
+
+Conversion algorithm:
+
+ Upper case character converts to Lower case
+ Title case character converts to Lower case
+ Lower case character after Whitespace or at start converts to Title case
+ Other Lower case character converts to Upper case
+ Whitespace is defined by unicode.IsSpace(char).
+
+Parameters:
+ str - the string to swap case
+
+Returns:
+ the changed string
+*/
+func SwapCase(str string) string {
+ if str == "" {
+ return str
+ }
+ buffer := []rune(str)
+
+ whitespace := true
+
+ for i := 0; i < len(buffer); i++ {
+ ch := buffer[i]
+ if unicode.IsUpper(ch) {
+ buffer[i] = unicode.ToLower(ch)
+ whitespace = false
+ } else if unicode.IsTitle(ch) {
+ buffer[i] = unicode.ToLower(ch)
+ whitespace = false
+ } else if unicode.IsLower(ch) {
+ if whitespace {
+ buffer[i] = unicode.ToTitle(ch)
+ whitespace = false
+ } else {
+ buffer[i] = unicode.ToUpper(ch)
+ }
+ } else {
+ whitespace = unicode.IsSpace(ch)
+ }
+ }
+ return string(buffer)
+}
+
+/*
+Initials extracts the initial letters from each word in the string. The first letter of the string and all first
+letters after the defined delimiters are returned as a new string. Their case is not changed. If the delimiters
+parameter is excluded, then Whitespace is used. Whitespace is defined by unicode.IsSpacea(char). An empty delimiter array returns an empty string.
+
+Parameters:
+ str - the string to get initials from
+ delimiters - set of characters to determine words, exclusion of this parameter means whitespace would be delimeter
+Returns:
+ string of initial letters
+*/
+func Initials(str string, delimiters ...rune) string {
+ if str == "" {
+ return str
+ }
+ if delimiters != nil && len(delimiters) == 0 {
+ return ""
+ }
+ strLen := len(str)
+ var buf bytes.Buffer
+ lastWasGap := true
+ for i := 0; i < strLen; i++ {
+ ch := rune(str[i])
+
+ if isDelimiter(ch, delimiters...) {
+ lastWasGap = true
+ } else if lastWasGap {
+ buf.WriteRune(ch)
+ lastWasGap = false
+ }
+ }
+ return buf.String()
+}
+
+// private function (lower case func name)
+func isDelimiter(ch rune, delimiters ...rune) bool {
+ if delimiters == nil {
+ return unicode.IsSpace(ch)
+ }
+ for _, delimiter := range delimiters {
+ if ch == delimiter {
+ return true
+ }
+ }
+ return false
+}
diff --git a/backend/vendor/github.com/globalsign/mgo/bson/bson_corpus_spec_test_generator.go b/backend/vendor/github.com/globalsign/mgo/bson/bson_corpus_spec_test_generator.go
deleted file mode 100644
index 3525a004..00000000
--- a/backend/vendor/github.com/globalsign/mgo/bson/bson_corpus_spec_test_generator.go
+++ /dev/null
@@ -1,294 +0,0 @@
-// +build ignore
-
-package main
-
-import (
- "bytes"
- "fmt"
- "go/format"
- "html/template"
- "io/ioutil"
- "log"
- "path/filepath"
- "strings"
-
- "github.com/globalsign/mgo/internal/json"
-)
-
-func main() {
- log.SetFlags(0)
- log.SetPrefix(name + ": ")
-
- var g Generator
-
- fmt.Fprintf(&g, "// Code generated by \"%s.go\"; DO NOT EDIT\n\n", name)
-
- src := g.generate()
-
- err := ioutil.WriteFile(fmt.Sprintf("%s.go", strings.TrimSuffix(name, "_generator")), src, 0644)
- if err != nil {
- log.Fatalf("writing output: %s", err)
- }
-}
-
-// Generator holds the state of the analysis. Primarily used to buffer
-// the output for format.Source.
-type Generator struct {
- bytes.Buffer // Accumulated output.
-}
-
-// format returns the gofmt-ed contents of the Generator's buffer.
-func (g *Generator) format() []byte {
- src, err := format.Source(g.Bytes())
- if err != nil {
- // Should never happen, but can arise when developing this code.
- // The user can compile the output to see the error.
- log.Printf("warning: internal error: invalid Go generated: %s", err)
- log.Printf("warning: compile the package to analyze the error")
- return g.Bytes()
- }
- return src
-}
-
-// EVERYTHING ABOVE IS CONSTANT BETWEEN THE GENERATORS
-
-const name = "bson_corpus_spec_test_generator"
-
-func (g *Generator) generate() []byte {
-
- testFiles, err := filepath.Glob("./specdata/specifications/source/bson-corpus/tests/*.json")
- if err != nil {
- log.Fatalf("error reading bson-corpus files: %s", err)
- }
-
- tests, err := g.loadTests(testFiles)
- if err != nil {
- log.Fatalf("error loading tests: %s", err)
- }
-
- tmpl, err := g.getTemplate()
- if err != nil {
- log.Fatalf("error loading template: %s", err)
- }
-
- tmpl.Execute(&g.Buffer, tests)
-
- return g.format()
-}
-
-func (g *Generator) loadTests(filenames []string) ([]*testDef, error) {
- var tests []*testDef
- for _, filename := range filenames {
- test, err := g.loadTest(filename)
- if err != nil {
- return nil, err
- }
-
- tests = append(tests, test)
- }
-
- return tests, nil
-}
-
-func (g *Generator) loadTest(filename string) (*testDef, error) {
- content, err := ioutil.ReadFile(filename)
- if err != nil {
- return nil, err
- }
-
- var testDef testDef
- err = json.Unmarshal(content, &testDef)
- if err != nil {
- return nil, err
- }
-
- names := make(map[string]struct{})
-
- for i := len(testDef.Valid) - 1; i >= 0; i-- {
- if testDef.BsonType == "0x05" && testDef.Valid[i].Description == "subtype 0x02" {
- testDef.Valid = append(testDef.Valid[:i], testDef.Valid[i+1:]...)
- continue
- }
-
- name := cleanupFuncName(testDef.Description + "_" + testDef.Valid[i].Description)
- nameIdx := name
- j := 1
- for {
- if _, ok := names[nameIdx]; !ok {
- break
- }
-
- nameIdx = fmt.Sprintf("%s_%d", name, j)
- }
-
- names[nameIdx] = struct{}{}
-
- testDef.Valid[i].TestDef = &testDef
- testDef.Valid[i].Name = nameIdx
- testDef.Valid[i].StructTest = testDef.TestKey != "" &&
- (testDef.BsonType != "0x05" || strings.Contains(testDef.Valid[i].Description, "0x00")) &&
- !testDef.Deprecated
- }
-
- for i := len(testDef.DecodeErrors) - 1; i >= 0; i-- {
- if strings.Contains(testDef.DecodeErrors[i].Description, "UTF-8") {
- testDef.DecodeErrors = append(testDef.DecodeErrors[:i], testDef.DecodeErrors[i+1:]...)
- continue
- }
-
- name := cleanupFuncName(testDef.Description + "_" + testDef.DecodeErrors[i].Description)
- nameIdx := name
- j := 1
- for {
- if _, ok := names[nameIdx]; !ok {
- break
- }
-
- nameIdx = fmt.Sprintf("%s_%d", name, j)
- }
- names[nameIdx] = struct{}{}
-
- testDef.DecodeErrors[i].Name = nameIdx
- }
-
- return &testDef, nil
-}
-
-func (g *Generator) getTemplate() (*template.Template, error) {
- content := `package bson_test
-
-import (
- "encoding/hex"
- "time"
-
- . "gopkg.in/check.v1"
- "github.com/globalsign/mgo/bson"
-)
-
-func testValid(c *C, in []byte, expected []byte, result interface{}) {
- err := bson.Unmarshal(in, result)
- c.Assert(err, IsNil)
-
- out, err := bson.Marshal(result)
- c.Assert(err, IsNil)
-
- c.Assert(string(expected), Equals, string(out), Commentf("roundtrip failed for %T, expected '%x' but got '%x'", result, expected, out))
-}
-
-func testDecodeSkip(c *C, in []byte) {
- err := bson.Unmarshal(in, &struct{}{})
- c.Assert(err, IsNil)
-}
-
-func testDecodeError(c *C, in []byte, result interface{}) {
- err := bson.Unmarshal(in, result)
- c.Assert(err, Not(IsNil))
-}
-
-{{range .}}
-{{range .Valid}}
-func (s *S) Test{{.Name}}(c *C) {
- b, err := hex.DecodeString("{{.Bson}}")
- c.Assert(err, IsNil)
-
- {{if .CanonicalBson}}
- cb, err := hex.DecodeString("{{.CanonicalBson}}")
- c.Assert(err, IsNil)
- {{else}}
- cb := b
- {{end}}
-
- var resultD bson.D
- testValid(c, b, cb, &resultD)
- {{if .StructTest}}var resultS struct {
- Element {{.TestDef.GoType}} ` + "`bson:\"{{.TestDef.TestKey}}\"`" + `
- }
- testValid(c, b, cb, &resultS){{end}}
-
- testDecodeSkip(c, b)
-}
-{{end}}
-
-{{range .DecodeErrors}}
-func (s *S) Test{{.Name}}(c *C) {
- b, err := hex.DecodeString("{{.Bson}}")
- c.Assert(err, IsNil)
-
- var resultD bson.D
- testDecodeError(c, b, &resultD)
-}
-{{end}}
-{{end}}
-`
- tmpl, err := template.New("").Parse(content)
- if err != nil {
- return nil, err
- }
- return tmpl, nil
-}
-
-func cleanupFuncName(name string) string {
- return strings.Map(func(r rune) rune {
- if (r >= 48 && r <= 57) || (r >= 65 && r <= 90) || (r >= 97 && r <= 122) {
- return r
- }
- return '_'
- }, name)
-}
-
-type testDef struct {
- Description string `json:"description"`
- BsonType string `json:"bson_type"`
- TestKey string `json:"test_key"`
- Valid []*valid `json:"valid"`
- DecodeErrors []*decodeError `json:"decodeErrors"`
- Deprecated bool `json:"deprecated"`
-}
-
-func (t *testDef) GoType() string {
- switch t.BsonType {
- case "0x01":
- return "float64"
- case "0x02":
- return "string"
- case "0x03":
- return "bson.D"
- case "0x04":
- return "[]interface{}"
- case "0x05":
- return "[]byte"
- case "0x07":
- return "bson.ObjectId"
- case "0x08":
- return "bool"
- case "0x09":
- return "time.Time"
- case "0x0E":
- return "string"
- case "0x10":
- return "int32"
- case "0x12":
- return "int64"
- case "0x13":
- return "bson.Decimal"
- default:
- return "interface{}"
- }
-}
-
-type valid struct {
- Description string `json:"description"`
- Bson string `json:"bson"`
- CanonicalBson string `json:"canonical_bson"`
-
- Name string
- StructTest bool
- TestDef *testDef
-}
-
-type decodeError struct {
- Description string `json:"description"`
- Bson string `json:"bson"`
-
- Name string
-}
diff --git a/backend/vendor/github.com/go-playground/locales/.gitignore b/backend/vendor/github.com/go-playground/locales/.gitignore
new file mode 100644
index 00000000..daf913b1
--- /dev/null
+++ b/backend/vendor/github.com/go-playground/locales/.gitignore
@@ -0,0 +1,24 @@
+# Compiled Object files, Static and Dynamic libs (Shared Objects)
+*.o
+*.a
+*.so
+
+# Folders
+_obj
+_test
+
+# Architecture specific extensions/prefixes
+*.[568vq]
+[568vq].out
+
+*.cgo1.go
+*.cgo2.c
+_cgo_defun.c
+_cgo_gotypes.go
+_cgo_export.*
+
+_testmain.go
+
+*.exe
+*.test
+*.prof
diff --git a/backend/vendor/github.com/go-playground/locales/LICENSE b/backend/vendor/github.com/go-playground/locales/LICENSE
new file mode 100644
index 00000000..75854ac4
--- /dev/null
+++ b/backend/vendor/github.com/go-playground/locales/LICENSE
@@ -0,0 +1,21 @@
+The MIT License (MIT)
+
+Copyright (c) 2016 Go Playground
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
\ No newline at end of file
diff --git a/backend/vendor/github.com/go-playground/locales/README.md b/backend/vendor/github.com/go-playground/locales/README.md
new file mode 100644
index 00000000..43329f8d
--- /dev/null
+++ b/backend/vendor/github.com/go-playground/locales/README.md
@@ -0,0 +1,172 @@
+## locales
+ +
+### Mergo in the wild
+
+- [moby/moby](https://github.com/moby/moby)
+- [kubernetes/kubernetes](https://github.com/kubernetes/kubernetes)
+- [vmware/dispatch](https://github.com/vmware/dispatch)
+- [Shopify/themekit](https://github.com/Shopify/themekit)
+- [imdario/zas](https://github.com/imdario/zas)
+- [matcornic/hermes](https://github.com/matcornic/hermes)
+- [OpenBazaar/openbazaar-go](https://github.com/OpenBazaar/openbazaar-go)
+- [kataras/iris](https://github.com/kataras/iris)
+- [michaelsauter/crane](https://github.com/michaelsauter/crane)
+- [go-task/task](https://github.com/go-task/task)
+- [sensu/uchiwa](https://github.com/sensu/uchiwa)
+- [ory/hydra](https://github.com/ory/hydra)
+- [sisatech/vcli](https://github.com/sisatech/vcli)
+- [dairycart/dairycart](https://github.com/dairycart/dairycart)
+- [projectcalico/felix](https://github.com/projectcalico/felix)
+- [resin-os/balena](https://github.com/resin-os/balena)
+- [go-kivik/kivik](https://github.com/go-kivik/kivik)
+- [Telefonica/govice](https://github.com/Telefonica/govice)
+- [supergiant/supergiant](supergiant/supergiant)
+- [SergeyTsalkov/brooce](https://github.com/SergeyTsalkov/brooce)
+- [soniah/dnsmadeeasy](https://github.com/soniah/dnsmadeeasy)
+- [ohsu-comp-bio/funnel](https://github.com/ohsu-comp-bio/funnel)
+- [EagerIO/Stout](https://github.com/EagerIO/Stout)
+- [lynndylanhurley/defsynth-api](https://github.com/lynndylanhurley/defsynth-api)
+- [russross/canvasassignments](https://github.com/russross/canvasassignments)
+- [rdegges/cryptly-api](https://github.com/rdegges/cryptly-api)
+- [casualjim/exeggutor](https://github.com/casualjim/exeggutor)
+- [divshot/gitling](https://github.com/divshot/gitling)
+- [RWJMurphy/gorl](https://github.com/RWJMurphy/gorl)
+- [andrerocker/deploy42](https://github.com/andrerocker/deploy42)
+- [elwinar/rambler](https://github.com/elwinar/rambler)
+- [tmaiaroto/gopartman](https://github.com/tmaiaroto/gopartman)
+- [jfbus/impressionist](https://github.com/jfbus/impressionist)
+- [Jmeyering/zealot](https://github.com/Jmeyering/zealot)
+- [godep-migrator/rigger-host](https://github.com/godep-migrator/rigger-host)
+- [Dronevery/MultiwaySwitch-Go](https://github.com/Dronevery/MultiwaySwitch-Go)
+- [thoas/picfit](https://github.com/thoas/picfit)
+- [mantasmatelis/whooplist-server](https://github.com/mantasmatelis/whooplist-server)
+- [jnuthong/item_search](https://github.com/jnuthong/item_search)
+- [bukalapak/snowboard](https://github.com/bukalapak/snowboard)
+
+## Installation
+
+ go get github.com/imdario/mergo
+
+ // use in your .go code
+ import (
+ "github.com/imdario/mergo"
+ )
+
+## Usage
+
+You can only merge same-type structs with exported fields initialized as zero value of their type and same-types maps. Mergo won't merge unexported (private) fields but will do recursively any exported one. It won't merge empty structs value as [they are not considered zero values](https://golang.org/ref/spec#The_zero_value) either. Also maps will be merged recursively except for structs inside maps (because they are not addressable using Go reflection).
+
+```go
+if err := mergo.Merge(&dst, src); err != nil {
+ // ...
+}
+```
+
+Also, you can merge overwriting values using the transformer `WithOverride`.
+
+```go
+if err := mergo.Merge(&dst, src, mergo.WithOverride); err != nil {
+ // ...
+}
+```
+
+Additionally, you can map a `map[string]interface{}` to a struct (and otherwise, from struct to map), following the same restrictions as in `Merge()`. Keys are capitalized to find each corresponding exported field.
+
+```go
+if err := mergo.Map(&dst, srcMap); err != nil {
+ // ...
+}
+```
+
+Warning: if you map a struct to map, it won't do it recursively. Don't expect Mergo to map struct members of your struct as `map[string]interface{}`. They will be just assigned as values.
+
+More information and examples in [godoc documentation](http://godoc.org/github.com/imdario/mergo).
+
+### Nice example
+
+```go
+package main
+
+import (
+ "fmt"
+ "github.com/imdario/mergo"
+)
+
+type Foo struct {
+ A string
+ B int64
+}
+
+func main() {
+ src := Foo{
+ A: "one",
+ B: 2,
+ }
+ dest := Foo{
+ A: "two",
+ }
+ mergo.Merge(&dest, src)
+ fmt.Println(dest)
+ // Will print
+ // {two 2}
+}
+```
+
+Note: if test are failing due missing package, please execute:
+
+ go get gopkg.in/yaml.v2
+
+### Transformers
+
+Transformers allow to merge specific types differently than in the default behavior. In other words, now you can customize how some types are merged. For example, `time.Time` is a struct; it doesn't have zero value but IsZero can return true because it has fields with zero value. How can we merge a non-zero `time.Time`?
+
+```go
+package main
+
+import (
+ "fmt"
+ "github.com/imdario/mergo"
+ "reflect"
+ "time"
+)
+
+type timeTransfomer struct {
+}
+
+func (t timeTransfomer) Transformer(typ reflect.Type) func(dst, src reflect.Value) error {
+ if typ == reflect.TypeOf(time.Time{}) {
+ return func(dst, src reflect.Value) error {
+ if dst.CanSet() {
+ isZero := dst.MethodByName("IsZero")
+ result := isZero.Call([]reflect.Value{})
+ if result[0].Bool() {
+ dst.Set(src)
+ }
+ }
+ return nil
+ }
+ }
+ return nil
+}
+
+type Snapshot struct {
+ Time time.Time
+ // ...
+}
+
+func main() {
+ src := Snapshot{time.Now()}
+ dest := Snapshot{}
+ mergo.Merge(&dest, src, mergo.WithTransformers(timeTransfomer{}))
+ fmt.Println(dest)
+ // Will print
+ // { 2018-01-12 01:15:00 +0000 UTC m=+0.000000001 }
+}
+```
+
+
+## Contact me
+
+If I can help you, you have an idea or you are using Mergo in your projects, don't hesitate to drop me a line (or a pull request): [@im_dario](https://twitter.com/im_dario)
+
+## About
+
+Written by [Dario Castañé](http://dario.im).
+
+## License
+
+[BSD 3-Clause](http://opensource.org/licenses/BSD-3-Clause) license, as [Go language](http://golang.org/LICENSE).
diff --git a/backend/vendor/github.com/imdario/mergo/doc.go b/backend/vendor/github.com/imdario/mergo/doc.go
new file mode 100644
index 00000000..6e9aa7ba
--- /dev/null
+++ b/backend/vendor/github.com/imdario/mergo/doc.go
@@ -0,0 +1,44 @@
+// Copyright 2013 Dario Castañé. All rights reserved.
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+/*
+Package mergo merges same-type structs and maps by setting default values in zero-value fields.
+
+Mergo won't merge unexported (private) fields but will do recursively any exported one. It also won't merge structs inside maps (because they are not addressable using Go reflection).
+
+Usage
+
+From my own work-in-progress project:
+
+ type networkConfig struct {
+ Protocol string
+ Address string
+ ServerType string `json: "server_type"`
+ Port uint16
+ }
+
+ type FssnConfig struct {
+ Network networkConfig
+ }
+
+ var fssnDefault = FssnConfig {
+ networkConfig {
+ "tcp",
+ "127.0.0.1",
+ "http",
+ 31560,
+ },
+ }
+
+ // Inside a function [...]
+
+ if err := mergo.Merge(&config, fssnDefault); err != nil {
+ log.Fatal(err)
+ }
+
+ // More code [...]
+
+*/
+package mergo
diff --git a/backend/vendor/github.com/imdario/mergo/map.go b/backend/vendor/github.com/imdario/mergo/map.go
new file mode 100644
index 00000000..6ea38e63
--- /dev/null
+++ b/backend/vendor/github.com/imdario/mergo/map.go
@@ -0,0 +1,174 @@
+// Copyright 2014 Dario Castañé. All rights reserved.
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+// Based on src/pkg/reflect/deepequal.go from official
+// golang's stdlib.
+
+package mergo
+
+import (
+ "fmt"
+ "reflect"
+ "unicode"
+ "unicode/utf8"
+)
+
+func changeInitialCase(s string, mapper func(rune) rune) string {
+ if s == "" {
+ return s
+ }
+ r, n := utf8.DecodeRuneInString(s)
+ return string(mapper(r)) + s[n:]
+}
+
+func isExported(field reflect.StructField) bool {
+ r, _ := utf8.DecodeRuneInString(field.Name)
+ return r >= 'A' && r <= 'Z'
+}
+
+// Traverses recursively both values, assigning src's fields values to dst.
+// The map argument tracks comparisons that have already been seen, which allows
+// short circuiting on recursive types.
+func deepMap(dst, src reflect.Value, visited map[uintptr]*visit, depth int, config *Config) (err error) {
+ overwrite := config.Overwrite
+ if dst.CanAddr() {
+ addr := dst.UnsafeAddr()
+ h := 17 * addr
+ seen := visited[h]
+ typ := dst.Type()
+ for p := seen; p != nil; p = p.next {
+ if p.ptr == addr && p.typ == typ {
+ return nil
+ }
+ }
+ // Remember, remember...
+ visited[h] = &visit{addr, typ, seen}
+ }
+ zeroValue := reflect.Value{}
+ switch dst.Kind() {
+ case reflect.Map:
+ dstMap := dst.Interface().(map[string]interface{})
+ for i, n := 0, src.NumField(); i < n; i++ {
+ srcType := src.Type()
+ field := srcType.Field(i)
+ if !isExported(field) {
+ continue
+ }
+ fieldName := field.Name
+ fieldName = changeInitialCase(fieldName, unicode.ToLower)
+ if v, ok := dstMap[fieldName]; !ok || (isEmptyValue(reflect.ValueOf(v)) || overwrite) {
+ dstMap[fieldName] = src.Field(i).Interface()
+ }
+ }
+ case reflect.Ptr:
+ if dst.IsNil() {
+ v := reflect.New(dst.Type().Elem())
+ dst.Set(v)
+ }
+ dst = dst.Elem()
+ fallthrough
+ case reflect.Struct:
+ srcMap := src.Interface().(map[string]interface{})
+ for key := range srcMap {
+ srcValue := srcMap[key]
+ fieldName := changeInitialCase(key, unicode.ToUpper)
+ dstElement := dst.FieldByName(fieldName)
+ if dstElement == zeroValue {
+ // We discard it because the field doesn't exist.
+ continue
+ }
+ srcElement := reflect.ValueOf(srcValue)
+ dstKind := dstElement.Kind()
+ srcKind := srcElement.Kind()
+ if srcKind == reflect.Ptr && dstKind != reflect.Ptr {
+ srcElement = srcElement.Elem()
+ srcKind = reflect.TypeOf(srcElement.Interface()).Kind()
+ } else if dstKind == reflect.Ptr {
+ // Can this work? I guess it can't.
+ if srcKind != reflect.Ptr && srcElement.CanAddr() {
+ srcPtr := srcElement.Addr()
+ srcElement = reflect.ValueOf(srcPtr)
+ srcKind = reflect.Ptr
+ }
+ }
+
+ if !srcElement.IsValid() {
+ continue
+ }
+ if srcKind == dstKind {
+ if err = deepMerge(dstElement, srcElement, visited, depth+1, config); err != nil {
+ return
+ }
+ } else if dstKind == reflect.Interface && dstElement.Kind() == reflect.Interface {
+ if err = deepMerge(dstElement, srcElement, visited, depth+1, config); err != nil {
+ return
+ }
+ } else if srcKind == reflect.Map {
+ if err = deepMap(dstElement, srcElement, visited, depth+1, config); err != nil {
+ return
+ }
+ } else {
+ return fmt.Errorf("type mismatch on %s field: found %v, expected %v", fieldName, srcKind, dstKind)
+ }
+ }
+ }
+ return
+}
+
+// Map sets fields' values in dst from src.
+// src can be a map with string keys or a struct. dst must be the opposite:
+// if src is a map, dst must be a valid pointer to struct. If src is a struct,
+// dst must be map[string]interface{}.
+// It won't merge unexported (private) fields and will do recursively
+// any exported field.
+// If dst is a map, keys will be src fields' names in lower camel case.
+// Missing key in src that doesn't match a field in dst will be skipped. This
+// doesn't apply if dst is a map.
+// This is separated method from Merge because it is cleaner and it keeps sane
+// semantics: merging equal types, mapping different (restricted) types.
+func Map(dst, src interface{}, opts ...func(*Config)) error {
+ return _map(dst, src, opts...)
+}
+
+// MapWithOverwrite will do the same as Map except that non-empty dst attributes will be overridden by
+// non-empty src attribute values.
+// Deprecated: Use Map(…) with WithOverride
+func MapWithOverwrite(dst, src interface{}, opts ...func(*Config)) error {
+ return _map(dst, src, append(opts, WithOverride)...)
+}
+
+func _map(dst, src interface{}, opts ...func(*Config)) error {
+ var (
+ vDst, vSrc reflect.Value
+ err error
+ )
+ config := &Config{}
+
+ for _, opt := range opts {
+ opt(config)
+ }
+
+ if vDst, vSrc, err = resolveValues(dst, src); err != nil {
+ return err
+ }
+ // To be friction-less, we redirect equal-type arguments
+ // to deepMerge. Only because arguments can be anything.
+ if vSrc.Kind() == vDst.Kind() {
+ return deepMerge(vDst, vSrc, make(map[uintptr]*visit), 0, config)
+ }
+ switch vSrc.Kind() {
+ case reflect.Struct:
+ if vDst.Kind() != reflect.Map {
+ return ErrExpectedMapAsDestination
+ }
+ case reflect.Map:
+ if vDst.Kind() != reflect.Struct {
+ return ErrExpectedStructAsDestination
+ }
+ default:
+ return ErrNotSupported
+ }
+ return deepMap(vDst, vSrc, make(map[uintptr]*visit), 0, config)
+}
diff --git a/backend/vendor/github.com/imdario/mergo/merge.go b/backend/vendor/github.com/imdario/mergo/merge.go
new file mode 100644
index 00000000..44f70a89
--- /dev/null
+++ b/backend/vendor/github.com/imdario/mergo/merge.go
@@ -0,0 +1,252 @@
+// Copyright 2013 Dario Castañé. All rights reserved.
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+// Based on src/pkg/reflect/deepequal.go from official
+// golang's stdlib.
+
+package mergo
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func hasExportedField(dst reflect.Value) (exported bool) {
+ for i, n := 0, dst.NumField(); i < n; i++ {
+ field := dst.Type().Field(i)
+ if field.Anonymous && dst.Field(i).Kind() == reflect.Struct {
+ exported = exported || hasExportedField(dst.Field(i))
+ } else {
+ exported = exported || len(field.PkgPath) == 0
+ }
+ }
+ return
+}
+
+type Config struct {
+ Overwrite bool
+ AppendSlice bool
+ Transformers Transformers
+}
+
+type Transformers interface {
+ Transformer(reflect.Type) func(dst, src reflect.Value) error
+}
+
+// Traverses recursively both values, assigning src's fields values to dst.
+// The map argument tracks comparisons that have already been seen, which allows
+// short circuiting on recursive types.
+func deepMerge(dst, src reflect.Value, visited map[uintptr]*visit, depth int, config *Config) (err error) {
+ overwrite := config.Overwrite
+
+ if !src.IsValid() {
+ return
+ }
+ if dst.CanAddr() {
+ addr := dst.UnsafeAddr()
+ h := 17 * addr
+ seen := visited[h]
+ typ := dst.Type()
+ for p := seen; p != nil; p = p.next {
+ if p.ptr == addr && p.typ == typ {
+ return nil
+ }
+ }
+ // Remember, remember...
+ visited[h] = &visit{addr, typ, seen}
+ }
+
+ if config.Transformers != nil && !isEmptyValue(dst) {
+ if fn := config.Transformers.Transformer(dst.Type()); fn != nil {
+ err = fn(dst, src)
+ return
+ }
+ }
+
+ switch dst.Kind() {
+ case reflect.Struct:
+ if hasExportedField(dst) {
+ for i, n := 0, dst.NumField(); i < n; i++ {
+ if err = deepMerge(dst.Field(i), src.Field(i), visited, depth+1, config); err != nil {
+ return
+ }
+ }
+ } else {
+ if dst.CanSet() && !isEmptyValue(src) && (overwrite || isEmptyValue(dst)) {
+ dst.Set(src)
+ }
+ }
+ case reflect.Map:
+ if dst.IsNil() && !src.IsNil() {
+ dst.Set(reflect.MakeMap(dst.Type()))
+ }
+ for _, key := range src.MapKeys() {
+ srcElement := src.MapIndex(key)
+ if !srcElement.IsValid() {
+ continue
+ }
+ dstElement := dst.MapIndex(key)
+ switch srcElement.Kind() {
+ case reflect.Chan, reflect.Func, reflect.Map, reflect.Interface, reflect.Slice:
+ if srcElement.IsNil() {
+ continue
+ }
+ fallthrough
+ default:
+ if !srcElement.CanInterface() {
+ continue
+ }
+ switch reflect.TypeOf(srcElement.Interface()).Kind() {
+ case reflect.Struct:
+ fallthrough
+ case reflect.Ptr:
+ fallthrough
+ case reflect.Map:
+ srcMapElm := srcElement
+ dstMapElm := dstElement
+ if srcMapElm.CanInterface() {
+ srcMapElm = reflect.ValueOf(srcMapElm.Interface())
+ if dstMapElm.IsValid() {
+ dstMapElm = reflect.ValueOf(dstMapElm.Interface())
+ }
+ }
+ if err = deepMerge(dstMapElm, srcMapElm, visited, depth+1, config); err != nil {
+ return
+ }
+ case reflect.Slice:
+ srcSlice := reflect.ValueOf(srcElement.Interface())
+
+ var dstSlice reflect.Value
+ if !dstElement.IsValid() || dstElement.IsNil() {
+ dstSlice = reflect.MakeSlice(srcSlice.Type(), 0, srcSlice.Len())
+ } else {
+ dstSlice = reflect.ValueOf(dstElement.Interface())
+ }
+
+ if !isEmptyValue(src) && (overwrite || isEmptyValue(dst)) && !config.AppendSlice {
+ dstSlice = srcSlice
+ } else if config.AppendSlice {
+ if srcSlice.Type() != dstSlice.Type() {
+ return fmt.Errorf("cannot append two slice with different type (%s, %s)", srcSlice.Type(), dstSlice.Type())
+ }
+ dstSlice = reflect.AppendSlice(dstSlice, srcSlice)
+ }
+ dst.SetMapIndex(key, dstSlice)
+ }
+ }
+ if dstElement.IsValid() && reflect.TypeOf(srcElement.Interface()).Kind() == reflect.Map {
+ continue
+ }
+
+ if srcElement.IsValid() && (overwrite || (!dstElement.IsValid() || isEmptyValue(dstElement))) {
+ if dst.IsNil() {
+ dst.Set(reflect.MakeMap(dst.Type()))
+ }
+ dst.SetMapIndex(key, srcElement)
+ }
+ }
+ case reflect.Slice:
+ if !dst.CanSet() {
+ break
+ }
+ if !isEmptyValue(src) && (overwrite || isEmptyValue(dst)) && !config.AppendSlice {
+ dst.Set(src)
+ } else if config.AppendSlice {
+ if src.Type() != dst.Type() {
+ return fmt.Errorf("cannot append two slice with different type (%s, %s)", src.Type(), dst.Type())
+ }
+ dst.Set(reflect.AppendSlice(dst, src))
+ }
+ case reflect.Ptr:
+ fallthrough
+ case reflect.Interface:
+ if src.IsNil() {
+ break
+ }
+ if src.Kind() != reflect.Interface {
+ if dst.IsNil() || overwrite {
+ if dst.CanSet() && (overwrite || isEmptyValue(dst)) {
+ dst.Set(src)
+ }
+ } else if src.Kind() == reflect.Ptr {
+ if err = deepMerge(dst.Elem(), src.Elem(), visited, depth+1, config); err != nil {
+ return
+ }
+ } else if dst.Elem().Type() == src.Type() {
+ if err = deepMerge(dst.Elem(), src, visited, depth+1, config); err != nil {
+ return
+ }
+ } else {
+ return ErrDifferentArgumentsTypes
+ }
+ break
+ }
+ if dst.IsNil() || overwrite {
+ if dst.CanSet() && (overwrite || isEmptyValue(dst)) {
+ dst.Set(src)
+ }
+ } else if err = deepMerge(dst.Elem(), src.Elem(), visited, depth+1, config); err != nil {
+ return
+ }
+ default:
+ if dst.CanSet() && !isEmptyValue(src) && (overwrite || isEmptyValue(dst)) {
+ dst.Set(src)
+ }
+ }
+ return
+}
+
+// Merge will fill any empty for value type attributes on the dst struct using corresponding
+// src attributes if they themselves are not empty. dst and src must be valid same-type structs
+// and dst must be a pointer to struct.
+// It won't merge unexported (private) fields and will do recursively any exported field.
+func Merge(dst, src interface{}, opts ...func(*Config)) error {
+ return merge(dst, src, opts...)
+}
+
+// MergeWithOverwrite will do the same as Merge except that non-empty dst attributes will be overriden by
+// non-empty src attribute values.
+// Deprecated: use Merge(…) with WithOverride
+func MergeWithOverwrite(dst, src interface{}, opts ...func(*Config)) error {
+ return merge(dst, src, append(opts, WithOverride)...)
+}
+
+// WithTransformers adds transformers to merge, allowing to customize the merging of some types.
+func WithTransformers(transformers Transformers) func(*Config) {
+ return func(config *Config) {
+ config.Transformers = transformers
+ }
+}
+
+// WithOverride will make merge override non-empty dst attributes with non-empty src attributes values.
+func WithOverride(config *Config) {
+ config.Overwrite = true
+}
+
+// WithAppendSlice will make merge append slices instead of overwriting it
+func WithAppendSlice(config *Config) {
+ config.AppendSlice = true
+}
+
+func merge(dst, src interface{}, opts ...func(*Config)) error {
+ var (
+ vDst, vSrc reflect.Value
+ err error
+ )
+
+ config := &Config{}
+
+ for _, opt := range opts {
+ opt(config)
+ }
+
+ if vDst, vSrc, err = resolveValues(dst, src); err != nil {
+ return err
+ }
+ if vDst.Type() != vSrc.Type() {
+ return ErrDifferentArgumentsTypes
+ }
+ return deepMerge(vDst, vSrc, make(map[uintptr]*visit), 0, config)
+}
diff --git a/backend/vendor/github.com/imdario/mergo/mergo.go b/backend/vendor/github.com/imdario/mergo/mergo.go
new file mode 100644
index 00000000..a82fea2f
--- /dev/null
+++ b/backend/vendor/github.com/imdario/mergo/mergo.go
@@ -0,0 +1,97 @@
+// Copyright 2013 Dario Castañé. All rights reserved.
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+// Based on src/pkg/reflect/deepequal.go from official
+// golang's stdlib.
+
+package mergo
+
+import (
+ "errors"
+ "reflect"
+)
+
+// Errors reported by Mergo when it finds invalid arguments.
+var (
+ ErrNilArguments = errors.New("src and dst must not be nil")
+ ErrDifferentArgumentsTypes = errors.New("src and dst must be of same type")
+ ErrNotSupported = errors.New("only structs and maps are supported")
+ ErrExpectedMapAsDestination = errors.New("dst was expected to be a map")
+ ErrExpectedStructAsDestination = errors.New("dst was expected to be a struct")
+)
+
+// During deepMerge, must keep track of checks that are
+// in progress. The comparison algorithm assumes that all
+// checks in progress are true when it reencounters them.
+// Visited are stored in a map indexed by 17 * a1 + a2;
+type visit struct {
+ ptr uintptr
+ typ reflect.Type
+ next *visit
+}
+
+// From src/pkg/encoding/json/encode.go.
+func isEmptyValue(v reflect.Value) bool {
+ switch v.Kind() {
+ case reflect.Array, reflect.Map, reflect.Slice, reflect.String:
+ return v.Len() == 0
+ case reflect.Bool:
+ return !v.Bool()
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return v.Int() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return v.Uint() == 0
+ case reflect.Float32, reflect.Float64:
+ return v.Float() == 0
+ case reflect.Interface, reflect.Ptr:
+ if v.IsNil() {
+ return true
+ }
+ return isEmptyValue(v.Elem())
+ case reflect.Func:
+ return v.IsNil()
+ case reflect.Invalid:
+ return true
+ }
+ return false
+}
+
+func resolveValues(dst, src interface{}) (vDst, vSrc reflect.Value, err error) {
+ if dst == nil || src == nil {
+ err = ErrNilArguments
+ return
+ }
+ vDst = reflect.ValueOf(dst).Elem()
+ if vDst.Kind() != reflect.Struct && vDst.Kind() != reflect.Map {
+ err = ErrNotSupported
+ return
+ }
+ vSrc = reflect.ValueOf(src)
+ // We check if vSrc is a pointer to dereference it.
+ if vSrc.Kind() == reflect.Ptr {
+ vSrc = vSrc.Elem()
+ }
+ return
+}
+
+// Traverses recursively both values, assigning src's fields values to dst.
+// The map argument tracks comparisons that have already been seen, which allows
+// short circuiting on recursive types.
+func deeper(dst, src reflect.Value, visited map[uintptr]*visit, depth int) (err error) {
+ if dst.CanAddr() {
+ addr := dst.UnsafeAddr()
+ h := 17 * addr
+ seen := visited[h]
+ typ := dst.Type()
+ for p := seen; p != nil; p = p.next {
+ if p.ptr == addr && p.typ == typ {
+ return nil
+ }
+ }
+ // Remember, remember...
+ visited[h] = &visit{addr, typ, seen}
+ }
+ return // TODO refactor
+}
diff --git a/backend/vendor/github.com/imroc/req/LICENSE b/backend/vendor/github.com/imroc/req/LICENSE
new file mode 100644
index 00000000..8dada3ed
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "{}"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright {yyyy} {name of copyright owner}
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/backend/vendor/github.com/imroc/req/README.md b/backend/vendor/github.com/imroc/req/README.md
new file mode 100644
index 00000000..c41d5ae0
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/README.md
@@ -0,0 +1,302 @@
+# req
+[](https://godoc.org/github.com/imroc/req)
+
+A golang http request library for humans
+
+
+
+Features
+========
+
+- Light weight
+- Simple
+- Easy play with JSON and XML
+- Easy for debug and logging
+- Easy file uploads and downloads
+- Easy manage cookie
+- Easy set up proxy
+- Easy set timeout
+- Easy customize http client
+
+
+Document
+========
+[中文](doc/README_cn.md)
+
+
+Install
+=======
+``` sh
+go get github.com/imroc/req
+```
+
+Overview
+=======
+`req` implements a friendly API over Go's existing `net/http` library.
+
+`Req` and `Resp` are two most important struct, you can think of `Req` as a client that initiate HTTP requests, `Resp` as a information container for the request and response. They all provide simple and convenient APIs that allows you to do a lot of things.
+``` go
+func (r *Req) Post(url string, v ...interface{}) (*Resp, error)
+```
+
+In most cases, only url is required, others are optional, like headers, params, files or body etc.
+
+There is a default `Req` object, all of its' public methods are wrapped by the `req` package, so you can also think of `req` package as a `Req` object
+``` go
+// use Req object to initiate requests.
+r := req.New()
+r.Get(url)
+
+// use req package to initiate request.
+req.Get(url)
+```
+You can use `req.New()` to create lots of `*Req` as client with independent configuration
+
+Examples
+=======
+[Basic](#Basic)
+[Set Header](#Set-Header)
+[Set Param](#Set-Param)
+[Set Body](#Set-Body)
+[Debug](#Debug)
+[Output Format](#Format)
+[ToJSON & ToXML](#ToJSON-ToXML)
+[Get *http.Response](#Response)
+[Upload](#Upload)
+[Download](#Download)
+[Cookie](#Cookie)
+[Set Timeout](#Set-Timeout)
+[Set Proxy](#Set-Proxy)
+[Customize Client](#Customize-Client)
+
+## Basic
+``` go
+header := req.Header{
+ "Accept": "application/json",
+ "Authorization": "Basic YWRtaW46YWRtaW4=",
+}
+param := req.Param{
+ "name": "imroc",
+ "cmd": "add",
+}
+// only url is required, others are optional.
+r, err = req.Post("http://foo.bar/api", header, param)
+if err != nil {
+ log.Fatal(err)
+}
+r.ToJSON(&foo) // response => struct/map
+log.Printf("%+v", r) // print info (try it, you may surprise)
+```
+
+## Set Header
+Use `req.Header` (it is actually a `map[string]string`)
+``` go
+authHeader := req.Header{
+ "Accept": "application/json",
+ "Authorization": "Basic YWRtaW46YWRtaW4=",
+}
+req.Get("https://www.baidu.com", authHeader, req.Header{"User-Agent": "V1.1"})
+```
+use `http.Header`
+``` go
+header := make(http.Header)
+header.Set("Accept", "application/json")
+req.Get("https://www.baidu.com", header)
+```
+
+## Set Param
+Use `req.Param` (it is actually a `map[string]interface{}`)
+``` go
+param := req.Param{
+ "id": "imroc",
+ "pwd": "roc",
+}
+req.Get("http://foo.bar/api", param) // http://foo.bar/api?id=imroc&pwd=roc
+req.Post(url, param) // body => id=imroc&pwd=roc
+```
+use `req.QueryParam` force to append params to the url (it is also actually a `map[string]interface{}`)
+``` go
+req.Post("http://foo.bar/api", req.Param{"name": "roc", "age": "22"}, req.QueryParam{"access_token": "fedledGF9Hg9ehTU"})
+/*
+POST /api?access_token=fedledGF9Hg9ehTU HTTP/1.1
+Host: foo.bar
+User-Agent: Go-http-client/1.1
+Content-Length: 15
+Content-Type: application/x-www-form-urlencoded;charset=UTF-8
+Accept-Encoding: gzip
+
+age=22&name=roc
+*/
+```
+
+## Set Body
+Put `string`, `[]byte` and `io.Reader` as body directly.
+``` go
+req.Post(url, "id=roc&cmd=query")
+```
+Put object as xml or json body (add `Content-Type` header automatically)
+``` go
+req.Post(url, req.BodyJSON(&foo))
+req.Post(url, req.BodyXML(&bar))
+```
+
+## Debug
+Set global variable `req.Debug` to true, it will print detail infomation for every request.
+``` go
+req.Debug = true
+req.Post("http://localhost/test" "hi")
+```
+
+
+## Output Format
+You can use different kind of output format to log the request and response infomation in your log file in defferent scenarios. For example, use `%+v` output format in the development phase, it allows you to observe the details. Use `%v` or `%-v` output format in production phase, just log the information necessarily.
+
+### `%+v` or `%+s`
+Output in detail
+``` go
+r, _ := req.Post(url, header, param)
+log.Printf("%+v", r) // output the same format as Debug is enabled
+```
+
+### `%v` or `%s`
+Output in simple way (default format)
+``` go
+r, _ := req.Get(url, param)
+log.Printf("%v\n", r) // GET http://foo.bar/api?name=roc&cmd=add {"code":"0","msg":"success"}
+log.Prinln(r) // smae as above
+```
+
+### `%-v` or `%-s`
+Output in simple way and keep all in one line (request body or response body may have multiple lines, this format will replace `"\r"` or `"\n"` with `" "`, it's useful when doing some search in your log file)
+
+### Flag
+You can call `SetFlags` to control the output content, decide which pieces can be output.
+``` go
+const (
+ LreqHead = 1 << iota // output request head (request line and request header)
+ LreqBody // output request body
+ LrespHead // output response head (response line and response header)
+ LrespBody // output response body
+ Lcost // output time costed by the request
+ LstdFlags = LreqHead | LreqBody | LrespHead | LrespBody
+)
+```
+``` go
+req.SetFlags(req.LreqHead | req.LreqBody | req.LrespHead)
+```
+
+### Monitoring time consuming
+``` go
+req.SetFlags(req.LstdFlags | req.Lcost) // output format add time costed by request
+r,_ := req.Get(url)
+log.Println(r) // http://foo.bar/api 3.260802ms {"code":0 "msg":"success"}
+if r.Cost() > 3 * time.Second { // check cost
+ log.Println("WARN: slow request:", r)
+}
+```
+
+## ToJSON & ToXML
+``` go
+r, _ := req.Get(url)
+r.ToJSON(&foo)
+r, _ = req.Post(url, req.BodyXML(&bar))
+r.ToXML(&baz)
+```
+
+## Get *http.Response
+```go
+// func (r *Req) Response() *http.Response
+r, _ := req.Get(url)
+resp := r.Response()
+fmt.Println(resp.StatusCode)
+```
+
+## Upload
+Use `req.File` to match files
+``` go
+req.Post(url, req.File("imroc.png"), req.File("/Users/roc/Pictures/*.png"))
+```
+Use `req.FileUpload` to fully control
+``` go
+file, _ := os.Open("imroc.png")
+req.Post(url, req.FileUpload{
+ File: file,
+ FieldName: "file", // FieldName is form field name
+ FileName: "avatar.png", //Filename is the name of the file that you wish to upload. We use this to guess the mimetype as well as pass it onto the server
+})
+```
+Use `req.UploadProgress` to listen upload progress
+```go
+progress := func(current, total int64) {
+ fmt.Println(float32(current)/float32(total)*100, "%")
+}
+req.Post(url, req.File("/Users/roc/Pictures/*.png"), req.UploadProgress(progress))
+fmt.Println("upload complete")
+```
+
+## Download
+``` go
+r, _ := req.Get(url)
+r.ToFile("imroc.png")
+```
+Use `req.DownloadProgress` to listen download progress
+```go
+progress := func(current, total int64) {
+ fmt.Println(float32(current)/float32(total)*100, "%")
+}
+r, _ := req.Get(url, req.DownloadProgress(progress))
+r.ToFile("hello.mp4")
+fmt.Println("download complete")
+```
+
+## Cookie
+By default, the underlying `*http.Client` will manage your cookie(send cookie header to server automatically if server has set a cookie for you), you can disable it by calling this function :
+``` go
+req.EnableCookie(false)
+```
+and you can set cookie in request just using `*http.Cookie`
+``` go
+cookie := new(http.Cookie)
+// ......
+req.Get(url, cookie)
+```
+
+## Set Timeout
+``` go
+req.SetTimeout(50 * time.Second)
+```
+
+## Set Proxy
+By default, req use proxy from system environment if `http_proxy` or `https_proxy` is specified, you can set a custom proxy or disable it by set `nil`
+``` go
+req.SetProxy(func(r *http.Request) (*url.URL, error) {
+ if strings.Contains(r.URL.Hostname(), "google") {
+ return url.Parse("http://my.vpn.com:23456")
+ }
+ return nil, nil
+})
+```
+Set a simple proxy (use fixed proxy url for every request)
+``` go
+req.SetProxyUrl("http://my.proxy.com:23456")
+```
+
+## Customize Client
+Use `SetClient` to change the default underlying `*http.Client`
+``` go
+req.SetClient(client)
+```
+Specify independent http client for some requests
+``` go
+client := &http.Client{Timeout: 30 * time.Second}
+req.Get(url, client)
+```
+Change some properties of default client you want
+``` go
+req.Client().Jar, _ = cookiejar.New(nil)
+trans, _ := req.Client().Transport.(*http.Transport)
+trans.MaxIdleConns = 20
+trans.TLSHandshakeTimeout = 20 * time.Second
+trans.DisableKeepAlives = true
+trans.TLSClientConfig = &tls.Config{InsecureSkipVerify: true}
+```
diff --git a/backend/vendor/github.com/imroc/req/dump.go b/backend/vendor/github.com/imroc/req/dump.go
new file mode 100644
index 00000000..ce6d3a5b
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/dump.go
@@ -0,0 +1,216 @@
+package req
+
+import (
+ "bufio"
+ "bytes"
+ "fmt"
+ "io"
+ "io/ioutil"
+ "net"
+ "net/http"
+ "net/http/httputil"
+ "net/url"
+ "strings"
+ "time"
+)
+
+// Debug enable debug mode if set to true
+var Debug bool
+
+// dumpConn is a net.Conn which writes to Writer and reads from Reader
+type dumpConn struct {
+ io.Writer
+ io.Reader
+}
+
+func (c *dumpConn) Close() error { return nil }
+func (c *dumpConn) LocalAddr() net.Addr { return nil }
+func (c *dumpConn) RemoteAddr() net.Addr { return nil }
+func (c *dumpConn) SetDeadline(t time.Time) error { return nil }
+func (c *dumpConn) SetReadDeadline(t time.Time) error { return nil }
+func (c *dumpConn) SetWriteDeadline(t time.Time) error { return nil }
+
+// delegateReader is a reader that delegates to another reader,
+// once it arrives on a channel.
+type delegateReader struct {
+ c chan io.Reader
+ r io.Reader // nil until received from c
+}
+
+func (r *delegateReader) Read(p []byte) (int, error) {
+ if r.r == nil {
+ r.r = <-r.c
+ }
+ return r.r.Read(p)
+}
+
+type dummyBody struct {
+ N int
+ off int
+}
+
+func (d *dummyBody) Read(p []byte) (n int, err error) {
+ if d.N <= 0 {
+ err = io.EOF
+ return
+ }
+ left := d.N - d.off
+ if left <= 0 {
+ err = io.EOF
+ return
+ }
+
+ if l := len(p); l > 0 {
+ if l >= left {
+ n = left
+ err = io.EOF
+ } else {
+ n = l
+ }
+ d.off += n
+ for i := 0; i < n; i++ {
+ p[i] = '*'
+ }
+ }
+
+ return
+}
+
+func (d *dummyBody) Close() error {
+ return nil
+}
+
+type dumpBuffer struct {
+ bytes.Buffer
+}
+
+func (b *dumpBuffer) Write(p []byte) {
+ if b.Len() > 0 {
+ b.Buffer.WriteString("\r\n\r\n")
+ }
+ b.Buffer.Write(p)
+}
+
+func (b *dumpBuffer) WriteString(s string) {
+ b.Write([]byte(s))
+}
+
+func (r *Resp) dumpRequest(dump *dumpBuffer) {
+ head := r.r.flag&LreqHead != 0
+ body := r.r.flag&LreqBody != 0
+
+ if head {
+ r.dumpReqHead(dump)
+ }
+ if body {
+ if r.multipartHelper != nil {
+ dump.Write(r.multipartHelper.Dump())
+ } else if len(r.reqBody) > 0 {
+ dump.Write(r.reqBody)
+ }
+ }
+}
+
+func (r *Resp) dumpReqHead(dump *dumpBuffer) {
+ reqSend := new(http.Request)
+ *reqSend = *r.req
+ if reqSend.URL.Scheme == "https" {
+ reqSend.URL = new(url.URL)
+ *reqSend.URL = *r.req.URL
+ reqSend.URL.Scheme = "http"
+ }
+
+ if reqSend.ContentLength > 0 {
+ reqSend.Body = &dummyBody{N: int(reqSend.ContentLength)}
+ } else {
+ reqSend.Body = &dummyBody{N: 1}
+ }
+
+ // Use the actual Transport code to record what we would send
+ // on the wire, but not using TCP. Use a Transport with a
+ // custom dialer that returns a fake net.Conn that waits
+ // for the full input (and recording it), and then responds
+ // with a dummy response.
+ var buf bytes.Buffer // records the output
+ pr, pw := io.Pipe()
+ defer pw.Close()
+ dr := &delegateReader{c: make(chan io.Reader)}
+
+ t := &http.Transport{
+ Dial: func(net, addr string) (net.Conn, error) {
+ return &dumpConn{io.MultiWriter(&buf, pw), dr}, nil
+ },
+ }
+ defer t.CloseIdleConnections()
+
+ client := new(http.Client)
+ *client = *r.client
+ client.Transport = t
+
+ // Wait for the request before replying with a dummy response:
+ go func() {
+ req, err := http.ReadRequest(bufio.NewReader(pr))
+ if err == nil {
+ // Ensure all the body is read; otherwise
+ // we'll get a partial dump.
+ io.Copy(ioutil.Discard, req.Body)
+ req.Body.Close()
+ }
+
+ dr.c <- strings.NewReader("HTTP/1.1 204 No Content\r\nConnection: close\r\n\r\n")
+ pr.Close()
+ }()
+
+ _, err := client.Do(reqSend)
+ if err != nil {
+ dump.WriteString(err.Error())
+ } else {
+ reqDump := buf.Bytes()
+ if i := bytes.Index(reqDump, []byte("\r\n\r\n")); i >= 0 {
+ reqDump = reqDump[:i]
+ }
+ dump.Write(reqDump)
+ }
+}
+
+func (r *Resp) dumpResponse(dump *dumpBuffer) {
+ head := r.r.flag&LrespHead != 0
+ body := r.r.flag&LrespBody != 0
+ if head {
+ respDump, err := httputil.DumpResponse(r.resp, false)
+ if err != nil {
+ dump.WriteString(err.Error())
+ } else {
+ if i := bytes.Index(respDump, []byte("\r\n\r\n")); i >= 0 {
+ respDump = respDump[:i]
+ }
+ dump.Write(respDump)
+ }
+ }
+ if body && len(r.Bytes()) > 0 {
+ dump.Write(r.Bytes())
+ }
+}
+
+// Cost return the time cost of the request
+func (r *Resp) Cost() time.Duration {
+ return r.cost
+}
+
+// Dump dump the request
+func (r *Resp) Dump() string {
+ dump := new(dumpBuffer)
+ if r.r.flag&Lcost != 0 {
+ dump.WriteString(fmt.Sprint(r.cost))
+ }
+ r.dumpRequest(dump)
+ l := dump.Len()
+ if l > 0 {
+ dump.WriteString("=================================")
+ l = dump.Len()
+ }
+
+ r.dumpResponse(dump)
+
+ return dump.String()
+}
diff --git a/backend/vendor/github.com/imroc/req/req.go b/backend/vendor/github.com/imroc/req/req.go
new file mode 100644
index 00000000..d1b3e712
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/req.go
@@ -0,0 +1,688 @@
+package req
+
+import (
+ "bytes"
+ "compress/gzip"
+ "context"
+ "encoding/json"
+ "encoding/xml"
+ "errors"
+ "fmt"
+ "io"
+ "io/ioutil"
+ "mime/multipart"
+ "net/http"
+ "net/textproto"
+ "net/url"
+ "os"
+ "path/filepath"
+ "strconv"
+ "strings"
+ "time"
+)
+
+// default *Req
+var std = New()
+
+// flags to decide which part can be outputed
+const (
+ LreqHead = 1 << iota // output request head (request line and request header)
+ LreqBody // output request body
+ LrespHead // output response head (response line and response header)
+ LrespBody // output response body
+ Lcost // output time costed by the request
+ LstdFlags = LreqHead | LreqBody | LrespHead | LrespBody
+)
+
+// Header represents http request header
+type Header map[string]string
+
+func (h Header) Clone() Header {
+ if h == nil {
+ return nil
+ }
+ hh := Header{}
+ for k, v := range h {
+ hh[k] = v
+ }
+ return hh
+}
+
+// Param represents http request param
+type Param map[string]interface{}
+
+// QueryParam is used to force append http request param to the uri
+type QueryParam map[string]interface{}
+
+// Host is used for set request's Host
+type Host string
+
+// FileUpload represents a file to upload
+type FileUpload struct {
+ // filename in multipart form.
+ FileName string
+ // form field name
+ FieldName string
+ // file to uplaod, required
+ File io.ReadCloser
+}
+
+type DownloadProgress func(current, total int64)
+
+type UploadProgress func(current, total int64)
+
+// File upload files matching the name pattern such as
+// /usr/*/bin/go* (assuming the Separator is '/')
+func File(patterns ...string) interface{} {
+ matches := []string{}
+ for _, pattern := range patterns {
+ m, err := filepath.Glob(pattern)
+ if err != nil {
+ return err
+ }
+ matches = append(matches, m...)
+ }
+ if len(matches) == 0 {
+ return errors.New("req: no file have been matched")
+ }
+ uploads := []FileUpload{}
+ for _, match := range matches {
+ if s, e := os.Stat(match); e != nil || s.IsDir() {
+ continue
+ }
+ file, _ := os.Open(match)
+ uploads = append(uploads, FileUpload{
+ File: file,
+ FileName: filepath.Base(match),
+ FieldName: "media",
+ })
+ }
+
+ return uploads
+}
+
+type bodyJson struct {
+ v interface{}
+}
+
+type bodyXml struct {
+ v interface{}
+}
+
+// BodyJSON make the object be encoded in json format and set it to the request body
+func BodyJSON(v interface{}) *bodyJson {
+ return &bodyJson{v: v}
+}
+
+// BodyXML make the object be encoded in xml format and set it to the request body
+func BodyXML(v interface{}) *bodyXml {
+ return &bodyXml{v: v}
+}
+
+// Req is a convenient client for initiating requests
+type Req struct {
+ client *http.Client
+ jsonEncOpts *jsonEncOpts
+ xmlEncOpts *xmlEncOpts
+ flag int
+}
+
+// New create a new *Req
+func New() *Req {
+ return &Req{flag: LstdFlags}
+}
+
+type param struct {
+ url.Values
+}
+
+func (p *param) getValues() url.Values {
+ if p.Values == nil {
+ p.Values = make(url.Values)
+ }
+ return p.Values
+}
+
+func (p *param) Copy(pp param) {
+ if pp.Values == nil {
+ return
+ }
+ vs := p.getValues()
+ for key, values := range pp.Values {
+ for _, value := range values {
+ vs.Add(key, value)
+ }
+ }
+}
+func (p *param) Adds(m map[string]interface{}) {
+ if len(m) == 0 {
+ return
+ }
+ vs := p.getValues()
+ for k, v := range m {
+ vs.Add(k, fmt.Sprint(v))
+ }
+}
+
+func (p *param) Empty() bool {
+ return p.Values == nil
+}
+
+// Do execute a http request with sepecify method and url,
+// and it can also have some optional params, depending on your needs.
+func (r *Req) Do(method, rawurl string, vs ...interface{}) (resp *Resp, err error) {
+ if rawurl == "" {
+ return nil, errors.New("req: url not specified")
+ }
+ req := &http.Request{
+ Method: method,
+ Header: make(http.Header),
+ Proto: "HTTP/1.1",
+ ProtoMajor: 1,
+ ProtoMinor: 1,
+ }
+ resp = &Resp{req: req, r: r}
+
+ var queryParam param
+ var formParam param
+ var uploads []FileUpload
+ var uploadProgress UploadProgress
+ var progress func(int64, int64)
+ var delayedFunc []func()
+ var lastFunc []func()
+
+ for _, v := range vs {
+ switch vv := v.(type) {
+ case Header:
+ for key, value := range vv {
+ req.Header.Add(key, value)
+ }
+ case http.Header:
+ for key, values := range vv {
+ for _, value := range values {
+ req.Header.Add(key, value)
+ }
+ }
+ case *bodyJson:
+ fn, err := setBodyJson(req, resp, r.jsonEncOpts, vv.v)
+ if err != nil {
+ return nil, err
+ }
+ delayedFunc = append(delayedFunc, fn)
+ case *bodyXml:
+ fn, err := setBodyXml(req, resp, r.xmlEncOpts, vv.v)
+ if err != nil {
+ return nil, err
+ }
+ delayedFunc = append(delayedFunc, fn)
+ case url.Values:
+ p := param{vv}
+ if method == "GET" || method == "HEAD" {
+ queryParam.Copy(p)
+ } else {
+ formParam.Copy(p)
+ }
+ case Param:
+ if method == "GET" || method == "HEAD" {
+ queryParam.Adds(vv)
+ } else {
+ formParam.Adds(vv)
+ }
+ case QueryParam:
+ queryParam.Adds(vv)
+ case string:
+ setBodyBytes(req, resp, []byte(vv))
+ case []byte:
+ setBodyBytes(req, resp, vv)
+ case bytes.Buffer:
+ setBodyBytes(req, resp, vv.Bytes())
+ case *http.Client:
+ resp.client = vv
+ case FileUpload:
+ uploads = append(uploads, vv)
+ case []FileUpload:
+ uploads = append(uploads, vv...)
+ case *http.Cookie:
+ req.AddCookie(vv)
+ case Host:
+ req.Host = string(vv)
+ case io.Reader:
+ fn := setBodyReader(req, resp, vv)
+ lastFunc = append(lastFunc, fn)
+ case UploadProgress:
+ uploadProgress = vv
+ case DownloadProgress:
+ resp.downloadProgress = vv
+ case func(int64, int64):
+ progress = vv
+ case context.Context:
+ req = req.WithContext(vv)
+ resp.req = req
+ case error:
+ return nil, vv
+ }
+ }
+
+ if length := req.Header.Get("Content-Length"); length != "" {
+ if l, err := strconv.ParseInt(length, 10, 64); err == nil {
+ req.ContentLength = l
+ }
+ }
+
+ if len(uploads) > 0 && (req.Method == "POST" || req.Method == "PUT") { // multipart
+ var up UploadProgress
+ if uploadProgress != nil {
+ up = uploadProgress
+ } else if progress != nil {
+ up = UploadProgress(progress)
+ }
+ multipartHelper := &multipartHelper{
+ form: formParam.Values,
+ uploads: uploads,
+ uploadProgress: up,
+ }
+ multipartHelper.Upload(req)
+ resp.multipartHelper = multipartHelper
+ } else {
+ if progress != nil {
+ resp.downloadProgress = DownloadProgress(progress)
+ }
+ if !formParam.Empty() {
+ if req.Body != nil {
+ queryParam.Copy(formParam)
+ } else {
+ setBodyBytes(req, resp, []byte(formParam.Encode()))
+ setContentType(req, "application/x-www-form-urlencoded; charset=UTF-8")
+ }
+ }
+ }
+
+ if !queryParam.Empty() {
+ paramStr := queryParam.Encode()
+ if strings.IndexByte(rawurl, '?') == -1 {
+ rawurl = rawurl + "?" + paramStr
+ } else {
+ rawurl = rawurl + "&" + paramStr
+ }
+ }
+
+ u, err := url.Parse(rawurl)
+ if err != nil {
+ return nil, err
+ }
+ req.URL = u
+
+ if host := req.Header.Get("Host"); host != "" {
+ req.Host = host
+ }
+
+ for _, fn := range delayedFunc {
+ fn()
+ }
+
+ if resp.client == nil {
+ resp.client = r.Client()
+ }
+
+ var response *http.Response
+ if r.flag&Lcost != 0 {
+ before := time.Now()
+ response, err = resp.client.Do(req)
+ after := time.Now()
+ resp.cost = after.Sub(before)
+ } else {
+ response, err = resp.client.Do(req)
+ }
+ if err != nil {
+ return nil, err
+ }
+
+ for _, fn := range lastFunc {
+ fn()
+ }
+
+ resp.resp = response
+
+ if _, ok := resp.client.Transport.(*http.Transport); ok && response.Header.Get("Content-Encoding") == "gzip" && req.Header.Get("Accept-Encoding") != "" {
+ body, err := gzip.NewReader(response.Body)
+ if err != nil {
+ return nil, err
+ }
+ response.Body = body
+ }
+
+ // output detail if Debug is enabled
+ if Debug {
+ fmt.Println(resp.Dump())
+ }
+ return
+}
+
+func setBodyBytes(req *http.Request, resp *Resp, data []byte) {
+ resp.reqBody = data
+ req.Body = ioutil.NopCloser(bytes.NewReader(data))
+ req.ContentLength = int64(len(data))
+}
+
+func setBodyJson(req *http.Request, resp *Resp, opts *jsonEncOpts, v interface{}) (func(), error) {
+ var data []byte
+ switch vv := v.(type) {
+ case string:
+ data = []byte(vv)
+ case []byte:
+ data = vv
+ case *bytes.Buffer:
+ data = vv.Bytes()
+ default:
+ if opts != nil {
+ var buf bytes.Buffer
+ enc := json.NewEncoder(&buf)
+ enc.SetIndent(opts.indentPrefix, opts.indentValue)
+ enc.SetEscapeHTML(opts.escapeHTML)
+ err := enc.Encode(v)
+ if err != nil {
+ return nil, err
+ }
+ data = buf.Bytes()
+ } else {
+ var err error
+ data, err = json.Marshal(v)
+ if err != nil {
+ return nil, err
+ }
+ }
+ }
+ setBodyBytes(req, resp, data)
+ delayedFunc := func() {
+ setContentType(req, "application/json; charset=UTF-8")
+ }
+ return delayedFunc, nil
+}
+
+func setBodyXml(req *http.Request, resp *Resp, opts *xmlEncOpts, v interface{}) (func(), error) {
+ var data []byte
+ switch vv := v.(type) {
+ case string:
+ data = []byte(vv)
+ case []byte:
+ data = vv
+ case *bytes.Buffer:
+ data = vv.Bytes()
+ default:
+ if opts != nil {
+ var buf bytes.Buffer
+ enc := xml.NewEncoder(&buf)
+ enc.Indent(opts.prefix, opts.indent)
+ err := enc.Encode(v)
+ if err != nil {
+ return nil, err
+ }
+ data = buf.Bytes()
+ } else {
+ var err error
+ data, err = xml.Marshal(v)
+ if err != nil {
+ return nil, err
+ }
+ }
+ }
+ setBodyBytes(req, resp, data)
+ delayedFunc := func() {
+ setContentType(req, "application/xml; charset=UTF-8")
+ }
+ return delayedFunc, nil
+}
+
+func setContentType(req *http.Request, contentType string) {
+ if req.Header.Get("Content-Type") == "" {
+ req.Header.Set("Content-Type", contentType)
+ }
+}
+
+func setBodyReader(req *http.Request, resp *Resp, rd io.Reader) func() {
+ var rc io.ReadCloser
+ switch r := rd.(type) {
+ case *os.File:
+ stat, err := r.Stat()
+ if err == nil {
+ req.ContentLength = stat.Size()
+ }
+ rc = r
+
+ case io.ReadCloser:
+ rc = r
+ default:
+ rc = ioutil.NopCloser(rd)
+ }
+ bw := &bodyWrapper{
+ ReadCloser: rc,
+ limit: 102400,
+ }
+ req.Body = bw
+ lastFunc := func() {
+ resp.reqBody = bw.buf.Bytes()
+ }
+ return lastFunc
+}
+
+type bodyWrapper struct {
+ io.ReadCloser
+ buf bytes.Buffer
+ limit int
+}
+
+func (b *bodyWrapper) Read(p []byte) (n int, err error) {
+ n, err = b.ReadCloser.Read(p)
+ if left := b.limit - b.buf.Len(); left > 0 && n > 0 {
+ if n <= left {
+ b.buf.Write(p[:n])
+ } else {
+ b.buf.Write(p[:left])
+ }
+ }
+ return
+}
+
+type multipartHelper struct {
+ form url.Values
+ uploads []FileUpload
+ dump []byte
+ uploadProgress UploadProgress
+}
+
+func (m *multipartHelper) Upload(req *http.Request) {
+ pr, pw := io.Pipe()
+ bodyWriter := multipart.NewWriter(pw)
+ go func() {
+ for key, values := range m.form {
+ for _, value := range values {
+ bodyWriter.WriteField(key, value)
+ }
+ }
+ var upload func(io.Writer, io.Reader) error
+ if m.uploadProgress != nil {
+ var total int64
+ for _, up := range m.uploads {
+ if file, ok := up.File.(*os.File); ok {
+ stat, err := file.Stat()
+ if err != nil {
+ continue
+ }
+ total += stat.Size()
+ }
+ }
+ var current int64
+ buf := make([]byte, 1024)
+ var lastTime time.Time
+ upload = func(w io.Writer, r io.Reader) error {
+ for {
+ n, err := r.Read(buf)
+ if n > 0 {
+ _, _err := w.Write(buf[:n])
+ if _err != nil {
+ return _err
+ }
+ current += int64(n)
+ if now := time.Now(); now.Sub(lastTime) > 200*time.Millisecond {
+ lastTime = now
+ m.uploadProgress(current, total)
+ }
+ }
+ if err == io.EOF {
+ return nil
+ }
+ if err != nil {
+ return err
+ }
+ }
+ }
+ }
+
+ i := 0
+ for _, up := range m.uploads {
+ if up.FieldName == "" {
+ i++
+ up.FieldName = "file" + strconv.Itoa(i)
+ }
+ fileWriter, err := bodyWriter.CreateFormFile(up.FieldName, up.FileName)
+ if err != nil {
+ continue
+ }
+ //iocopy
+ if upload == nil {
+ io.Copy(fileWriter, up.File)
+ } else {
+ if _, ok := up.File.(*os.File); ok {
+ upload(fileWriter, up.File)
+ } else {
+ io.Copy(fileWriter, up.File)
+ }
+ }
+ up.File.Close()
+ }
+ bodyWriter.Close()
+ pw.Close()
+ }()
+ req.Header.Set("Content-Type", bodyWriter.FormDataContentType())
+ req.Body = ioutil.NopCloser(pr)
+}
+
+func (m *multipartHelper) Dump() []byte {
+ if m.dump != nil {
+ return m.dump
+ }
+ var buf bytes.Buffer
+ bodyWriter := multipart.NewWriter(&buf)
+ for key, values := range m.form {
+ for _, value := range values {
+ m.writeField(bodyWriter, key, value)
+ }
+ }
+ for _, up := range m.uploads {
+ m.writeFile(bodyWriter, up.FieldName, up.FileName)
+ }
+ bodyWriter.Close()
+ m.dump = buf.Bytes()
+ return m.dump
+}
+
+func (m *multipartHelper) writeField(w *multipart.Writer, fieldname, value string) error {
+ h := make(textproto.MIMEHeader)
+ h.Set("Content-Disposition",
+ fmt.Sprintf(`form-data; name="%s"`, fieldname))
+ p, err := w.CreatePart(h)
+ if err != nil {
+ return err
+ }
+ _, err = p.Write([]byte(value))
+ return err
+}
+
+func (m *multipartHelper) writeFile(w *multipart.Writer, fieldname, filename string) error {
+ h := make(textproto.MIMEHeader)
+ h.Set("Content-Disposition",
+ fmt.Sprintf(`form-data; name="%s"; filename="%s"`,
+ fieldname, filename))
+ h.Set("Content-Type", "application/octet-stream")
+ p, err := w.CreatePart(h)
+ if err != nil {
+ return err
+ }
+ _, err = p.Write([]byte("******"))
+ return err
+}
+
+// Get execute a http GET request
+func (r *Req) Get(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("GET", url, v...)
+}
+
+// Post execute a http POST request
+func (r *Req) Post(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("POST", url, v...)
+}
+
+// Put execute a http PUT request
+func (r *Req) Put(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("PUT", url, v...)
+}
+
+// Patch execute a http PATCH request
+func (r *Req) Patch(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("PATCH", url, v...)
+}
+
+// Delete execute a http DELETE request
+func (r *Req) Delete(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("DELETE", url, v...)
+}
+
+// Head execute a http HEAD request
+func (r *Req) Head(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("HEAD", url, v...)
+}
+
+// Options execute a http OPTIONS request
+func (r *Req) Options(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("OPTIONS", url, v...)
+}
+
+// Get execute a http GET request
+func Get(url string, v ...interface{}) (*Resp, error) {
+ return std.Get(url, v...)
+}
+
+// Post execute a http POST request
+func Post(url string, v ...interface{}) (*Resp, error) {
+ return std.Post(url, v...)
+}
+
+// Put execute a http PUT request
+func Put(url string, v ...interface{}) (*Resp, error) {
+ return std.Put(url, v...)
+}
+
+// Head execute a http HEAD request
+func Head(url string, v ...interface{}) (*Resp, error) {
+ return std.Head(url, v...)
+}
+
+// Options execute a http OPTIONS request
+func Options(url string, v ...interface{}) (*Resp, error) {
+ return std.Options(url, v...)
+}
+
+// Delete execute a http DELETE request
+func Delete(url string, v ...interface{}) (*Resp, error) {
+ return std.Delete(url, v...)
+}
+
+// Patch execute a http PATCH request
+func Patch(url string, v ...interface{}) (*Resp, error) {
+ return std.Patch(url, v...)
+}
+
+// Do execute request.
+func Do(method, url string, v ...interface{}) (*Resp, error) {
+ return std.Do(method, url, v...)
+}
diff --git a/backend/vendor/github.com/imroc/req/resp.go b/backend/vendor/github.com/imroc/req/resp.go
new file mode 100644
index 00000000..eb56b1bd
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/resp.go
@@ -0,0 +1,215 @@
+package req
+
+import (
+ "encoding/json"
+ "encoding/xml"
+ "fmt"
+ "io"
+ "io/ioutil"
+ "net/http"
+ "os"
+ "regexp"
+ "time"
+)
+
+// Resp represents a request with it's response
+type Resp struct {
+ r *Req
+ req *http.Request
+ resp *http.Response
+ client *http.Client
+ cost time.Duration
+ *multipartHelper
+ reqBody []byte
+ respBody []byte
+ downloadProgress DownloadProgress
+ err error // delayed error
+}
+
+// Request returns *http.Request
+func (r *Resp) Request() *http.Request {
+ return r.req
+}
+
+// Response returns *http.Response
+func (r *Resp) Response() *http.Response {
+ return r.resp
+}
+
+// Bytes returns response body as []byte
+func (r *Resp) Bytes() []byte {
+ data, _ := r.ToBytes()
+ return data
+}
+
+// ToBytes returns response body as []byte,
+// return error if error happend when reading
+// the response body
+func (r *Resp) ToBytes() ([]byte, error) {
+ if r.err != nil {
+ return nil, r.err
+ }
+ if r.respBody != nil {
+ return r.respBody, nil
+ }
+ defer r.resp.Body.Close()
+ respBody, err := ioutil.ReadAll(r.resp.Body)
+ if err != nil {
+ r.err = err
+ return nil, err
+ }
+ r.respBody = respBody
+ return r.respBody, nil
+}
+
+// String returns response body as string
+func (r *Resp) String() string {
+ data, _ := r.ToBytes()
+ return string(data)
+}
+
+// ToString returns response body as string,
+// return error if error happend when reading
+// the response body
+func (r *Resp) ToString() (string, error) {
+ data, err := r.ToBytes()
+ return string(data), err
+}
+
+// ToJSON convert json response body to struct or map
+func (r *Resp) ToJSON(v interface{}) error {
+ data, err := r.ToBytes()
+ if err != nil {
+ return err
+ }
+ return json.Unmarshal(data, v)
+}
+
+// ToXML convert xml response body to struct or map
+func (r *Resp) ToXML(v interface{}) error {
+ data, err := r.ToBytes()
+ if err != nil {
+ return err
+ }
+ return xml.Unmarshal(data, v)
+}
+
+// ToFile download the response body to file with optional download callback
+func (r *Resp) ToFile(name string) error {
+ //TODO set name to the suffix of url path if name == ""
+ file, err := os.Create(name)
+ if err != nil {
+ return err
+ }
+ defer file.Close()
+
+ if r.respBody != nil {
+ _, err = file.Write(r.respBody)
+ return err
+ }
+
+ if r.downloadProgress != nil && r.resp.ContentLength > 0 {
+ return r.download(file)
+ }
+
+ defer r.resp.Body.Close()
+ _, err = io.Copy(file, r.resp.Body)
+ return err
+}
+
+func (r *Resp) download(file *os.File) error {
+ p := make([]byte, 1024)
+ b := r.resp.Body
+ defer b.Close()
+ total := r.resp.ContentLength
+ var current int64
+ var lastTime time.Time
+ for {
+ l, err := b.Read(p)
+ if l > 0 {
+ _, _err := file.Write(p[:l])
+ if _err != nil {
+ return _err
+ }
+ current += int64(l)
+ if now := time.Now(); now.Sub(lastTime) > 200*time.Millisecond {
+ lastTime = now
+ r.downloadProgress(current, total)
+ }
+ }
+ if err != nil {
+ if err == io.EOF {
+ return nil
+ }
+ return err
+ }
+ }
+}
+
+var regNewline = regexp.MustCompile(`\n|\r`)
+
+func (r *Resp) autoFormat(s fmt.State) {
+ req := r.req
+ if r.r.flag&Lcost != 0 {
+ fmt.Fprint(s, req.Method, " ", req.URL.String(), " ", r.cost)
+ } else {
+ fmt.Fprint(s, req.Method, " ", req.URL.String())
+ }
+
+ // test if it is should be outputed pretty
+ var pretty bool
+ var parts []string
+ addPart := func(part string) {
+ if part == "" {
+ return
+ }
+ parts = append(parts, part)
+ if !pretty && regNewline.MatchString(part) {
+ pretty = true
+ }
+ }
+ if r.r.flag&LreqBody != 0 { // request body
+ addPart(string(r.reqBody))
+ }
+ if r.r.flag&LrespBody != 0 { // response body
+ addPart(r.String())
+ }
+
+ for _, part := range parts {
+ if pretty {
+ fmt.Fprint(s, "\n")
+ }
+ fmt.Fprint(s, " ", part)
+ }
+}
+
+func (r *Resp) miniFormat(s fmt.State) {
+ req := r.req
+ if r.r.flag&Lcost != 0 {
+ fmt.Fprint(s, req.Method, " ", req.URL.String(), " ", r.cost)
+ } else {
+ fmt.Fprint(s, req.Method, " ", req.URL.String())
+ }
+ if r.r.flag&LreqBody != 0 && len(r.reqBody) > 0 { // request body
+ str := regNewline.ReplaceAllString(string(r.reqBody), " ")
+ fmt.Fprint(s, " ", str)
+ }
+ if r.r.flag&LrespBody != 0 && r.String() != "" { // response body
+ str := regNewline.ReplaceAllString(r.String(), " ")
+ fmt.Fprint(s, " ", str)
+ }
+}
+
+// Format fort the response
+func (r *Resp) Format(s fmt.State, verb rune) {
+ if r == nil || r.req == nil {
+ return
+ }
+ if s.Flag('+') { // include header and format pretty.
+ fmt.Fprint(s, r.Dump())
+ } else if s.Flag('-') { // keep all informations in one line.
+ r.miniFormat(s)
+ } else { // auto
+ r.autoFormat(s)
+ }
+}
diff --git a/backend/vendor/github.com/imroc/req/setting.go b/backend/vendor/github.com/imroc/req/setting.go
new file mode 100644
index 00000000..74235f37
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/setting.go
@@ -0,0 +1,236 @@
+package req
+
+import (
+ "crypto/tls"
+ "errors"
+ "net"
+ "net/http"
+ "net/http/cookiejar"
+ "net/url"
+ "time"
+)
+
+// create a default client
+func newClient() *http.Client {
+ jar, _ := cookiejar.New(nil)
+ transport := &http.Transport{
+ Proxy: http.ProxyFromEnvironment,
+ DialContext: (&net.Dialer{
+ Timeout: 30 * time.Second,
+ KeepAlive: 30 * time.Second,
+ DualStack: true,
+ }).DialContext,
+ MaxIdleConns: 100,
+ IdleConnTimeout: 90 * time.Second,
+ TLSHandshakeTimeout: 10 * time.Second,
+ ExpectContinueTimeout: 1 * time.Second,
+ }
+ return &http.Client{
+ Jar: jar,
+ Transport: transport,
+ Timeout: 2 * time.Minute,
+ }
+}
+
+// Client return the default underlying http client
+func (r *Req) Client() *http.Client {
+ if r.client == nil {
+ r.client = newClient()
+ }
+ return r.client
+}
+
+// Client return the default underlying http client
+func Client() *http.Client {
+ return std.Client()
+}
+
+// SetClient sets the underlying http.Client.
+func (r *Req) SetClient(client *http.Client) {
+ r.client = client // use default if client == nil
+}
+
+// SetClient sets the default http.Client for requests.
+func SetClient(client *http.Client) {
+ std.SetClient(client)
+}
+
+// SetFlags control display format of *Resp
+func (r *Req) SetFlags(flags int) {
+ r.flag = flags
+}
+
+// SetFlags control display format of *Resp
+func SetFlags(flags int) {
+ std.SetFlags(flags)
+}
+
+// Flags return output format for the *Resp
+func (r *Req) Flags() int {
+ return r.flag
+}
+
+// Flags return output format for the *Resp
+func Flags() int {
+ return std.Flags()
+}
+
+func (r *Req) getTransport() *http.Transport {
+ trans, _ := r.Client().Transport.(*http.Transport)
+ return trans
+}
+
+// EnableInsecureTLS allows insecure https
+func (r *Req) EnableInsecureTLS(enable bool) {
+ trans := r.getTransport()
+ if trans == nil {
+ return
+ }
+ if trans.TLSClientConfig == nil {
+ trans.TLSClientConfig = &tls.Config{}
+ }
+ trans.TLSClientConfig.InsecureSkipVerify = enable
+}
+
+func EnableInsecureTLS(enable bool) {
+ std.EnableInsecureTLS(enable)
+}
+
+// EnableCookieenable or disable cookie manager
+func (r *Req) EnableCookie(enable bool) {
+ if enable {
+ jar, _ := cookiejar.New(nil)
+ r.Client().Jar = jar
+ } else {
+ r.Client().Jar = nil
+ }
+}
+
+// EnableCookieenable or disable cookie manager
+func EnableCookie(enable bool) {
+ std.EnableCookie(enable)
+}
+
+// SetTimeout sets the timeout for every request
+func (r *Req) SetTimeout(d time.Duration) {
+ r.Client().Timeout = d
+}
+
+// SetTimeout sets the timeout for every request
+func SetTimeout(d time.Duration) {
+ std.SetTimeout(d)
+}
+
+// SetProxyUrl set the simple proxy with fixed proxy url
+func (r *Req) SetProxyUrl(rawurl string) error {
+ trans := r.getTransport()
+ if trans == nil {
+ return errors.New("req: no transport")
+ }
+ u, err := url.Parse(rawurl)
+ if err != nil {
+ return err
+ }
+ trans.Proxy = http.ProxyURL(u)
+ return nil
+}
+
+// SetProxyUrl set the simple proxy with fixed proxy url
+func SetProxyUrl(rawurl string) error {
+ return std.SetProxyUrl(rawurl)
+}
+
+// SetProxy sets the proxy for every request
+func (r *Req) SetProxy(proxy func(*http.Request) (*url.URL, error)) error {
+ trans := r.getTransport()
+ if trans == nil {
+ return errors.New("req: no transport")
+ }
+ trans.Proxy = proxy
+ return nil
+}
+
+// SetProxy sets the proxy for every request
+func SetProxy(proxy func(*http.Request) (*url.URL, error)) error {
+ return std.SetProxy(proxy)
+}
+
+type jsonEncOpts struct {
+ indentPrefix string
+ indentValue string
+ escapeHTML bool
+}
+
+func (r *Req) getJSONEncOpts() *jsonEncOpts {
+ if r.jsonEncOpts == nil {
+ r.jsonEncOpts = &jsonEncOpts{escapeHTML: true}
+ }
+ return r.jsonEncOpts
+}
+
+// SetJSONEscapeHTML specifies whether problematic HTML characters
+// should be escaped inside JSON quoted strings.
+// The default behavior is to escape &, <, and > to \u0026, \u003c, and \u003e
+// to avoid certain safety problems that can arise when embedding JSON in HTML.
+//
+// In non-HTML settings where the escaping interferes with the readability
+// of the output, SetEscapeHTML(false) disables this behavior.
+func (r *Req) SetJSONEscapeHTML(escape bool) {
+ opts := r.getJSONEncOpts()
+ opts.escapeHTML = escape
+}
+
+// SetJSONEscapeHTML specifies whether problematic HTML characters
+// should be escaped inside JSON quoted strings.
+// The default behavior is to escape &, <, and > to \u0026, \u003c, and \u003e
+// to avoid certain safety problems that can arise when embedding JSON in HTML.
+//
+// In non-HTML settings where the escaping interferes with the readability
+// of the output, SetEscapeHTML(false) disables this behavior.
+func SetJSONEscapeHTML(escape bool) {
+ std.SetJSONEscapeHTML(escape)
+}
+
+// SetJSONIndent instructs the encoder to format each subsequent encoded
+// value as if indented by the package-level function Indent(dst, src, prefix, indent).
+// Calling SetIndent("", "") disables indentation.
+func (r *Req) SetJSONIndent(prefix, indent string) {
+ opts := r.getJSONEncOpts()
+ opts.indentPrefix = prefix
+ opts.indentValue = indent
+}
+
+// SetJSONIndent instructs the encoder to format each subsequent encoded
+// value as if indented by the package-level function Indent(dst, src, prefix, indent).
+// Calling SetIndent("", "") disables indentation.
+func SetJSONIndent(prefix, indent string) {
+ std.SetJSONIndent(prefix, indent)
+}
+
+type xmlEncOpts struct {
+ prefix string
+ indent string
+}
+
+func (r *Req) getXMLEncOpts() *xmlEncOpts {
+ if r.xmlEncOpts == nil {
+ r.xmlEncOpts = &xmlEncOpts{}
+ }
+ return r.xmlEncOpts
+}
+
+// SetXMLIndent sets the encoder to generate XML in which each element
+// begins on a new indented line that starts with prefix and is followed by
+// one or more copies of indent according to the nesting depth.
+func (r *Req) SetXMLIndent(prefix, indent string) {
+ opts := r.getXMLEncOpts()
+ opts.prefix = prefix
+ opts.indent = indent
+}
+
+// SetXMLIndent sets the encoder to generate XML in which each element
+// begins on a new indented line that starts with prefix and is followed by
+// one or more copies of indent according to the nesting depth.
+func SetXMLIndent(prefix, indent string) {
+ std.SetXMLIndent(prefix, indent)
+}
diff --git a/backend/vendor/github.com/jaytaylor/html2text/.gitignore b/backend/vendor/github.com/jaytaylor/html2text/.gitignore
new file mode 100644
index 00000000..daf913b1
--- /dev/null
+++ b/backend/vendor/github.com/jaytaylor/html2text/.gitignore
@@ -0,0 +1,24 @@
+# Compiled Object files, Static and Dynamic libs (Shared Objects)
+*.o
+*.a
+*.so
+
+# Folders
+_obj
+_test
+
+# Architecture specific extensions/prefixes
+*.[568vq]
+[568vq].out
+
+*.cgo1.go
+*.cgo2.c
+_cgo_defun.c
+_cgo_gotypes.go
+_cgo_export.*
+
+_testmain.go
+
+*.exe
+*.test
+*.prof
diff --git a/backend/vendor/github.com/jaytaylor/html2text/.travis.yml b/backend/vendor/github.com/jaytaylor/html2text/.travis.yml
new file mode 100644
index 00000000..6c7f48ef
--- /dev/null
+++ b/backend/vendor/github.com/jaytaylor/html2text/.travis.yml
@@ -0,0 +1,14 @@
+language: go
+go:
+ - tip
+ - 1.8
+ - 1.7
+ - 1.6
+ - 1.5
+ - 1.4
+ - 1.3
+ - 1.2
+notifications:
+ email:
+ on_success: change
+ on_failure: always
diff --git a/backend/vendor/github.com/jaytaylor/html2text/LICENSE b/backend/vendor/github.com/jaytaylor/html2text/LICENSE
new file mode 100644
index 00000000..24dc4abe
--- /dev/null
+++ b/backend/vendor/github.com/jaytaylor/html2text/LICENSE
@@ -0,0 +1,22 @@
+The MIT License (MIT)
+
+Copyright (c) 2015 Jay Taylor
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
+
diff --git a/backend/vendor/github.com/jaytaylor/html2text/README.md b/backend/vendor/github.com/jaytaylor/html2text/README.md
new file mode 100644
index 00000000..6b2494ee
--- /dev/null
+++ b/backend/vendor/github.com/jaytaylor/html2text/README.md
@@ -0,0 +1,137 @@
+# html2text
+
+[](https://godoc.org/github.com/jaytaylor/html2text)
+[](https://travis-ci.org/jaytaylor/html2text)
+[](https://goreportcard.com/report/github.com/jaytaylor/html2text)
+
+### Converts HTML into text of the markdown-flavored variety
+
+
+## Introduction
+
+Ensure your emails are readable by all!
+
+Turns HTML into raw text, useful for sending fancy HTML emails with an equivalently nicely formatted TXT document as a fallback (e.g. for people who don't allow HTML emails or have other display issues).
+
+html2text is a simple golang package for rendering HTML into plaintext.
+
+There are still lots of improvements to be had, but FWIW this has worked fine for my [basic] HTML-2-text needs.
+
+It requires go 1.x or newer ;)
+
+
+## Download the package
+
+```bash
+go get jaytaylor.com/html2text
+```
+
+## Example usage
+
+```go
+package main
+
+import (
+ "fmt"
+
+ "jaytaylor.com/html2text"
+)
+
+func main() {
+ inputHTML := `
+
+
+
+
+### Mergo in the wild
+
+- [moby/moby](https://github.com/moby/moby)
+- [kubernetes/kubernetes](https://github.com/kubernetes/kubernetes)
+- [vmware/dispatch](https://github.com/vmware/dispatch)
+- [Shopify/themekit](https://github.com/Shopify/themekit)
+- [imdario/zas](https://github.com/imdario/zas)
+- [matcornic/hermes](https://github.com/matcornic/hermes)
+- [OpenBazaar/openbazaar-go](https://github.com/OpenBazaar/openbazaar-go)
+- [kataras/iris](https://github.com/kataras/iris)
+- [michaelsauter/crane](https://github.com/michaelsauter/crane)
+- [go-task/task](https://github.com/go-task/task)
+- [sensu/uchiwa](https://github.com/sensu/uchiwa)
+- [ory/hydra](https://github.com/ory/hydra)
+- [sisatech/vcli](https://github.com/sisatech/vcli)
+- [dairycart/dairycart](https://github.com/dairycart/dairycart)
+- [projectcalico/felix](https://github.com/projectcalico/felix)
+- [resin-os/balena](https://github.com/resin-os/balena)
+- [go-kivik/kivik](https://github.com/go-kivik/kivik)
+- [Telefonica/govice](https://github.com/Telefonica/govice)
+- [supergiant/supergiant](supergiant/supergiant)
+- [SergeyTsalkov/brooce](https://github.com/SergeyTsalkov/brooce)
+- [soniah/dnsmadeeasy](https://github.com/soniah/dnsmadeeasy)
+- [ohsu-comp-bio/funnel](https://github.com/ohsu-comp-bio/funnel)
+- [EagerIO/Stout](https://github.com/EagerIO/Stout)
+- [lynndylanhurley/defsynth-api](https://github.com/lynndylanhurley/defsynth-api)
+- [russross/canvasassignments](https://github.com/russross/canvasassignments)
+- [rdegges/cryptly-api](https://github.com/rdegges/cryptly-api)
+- [casualjim/exeggutor](https://github.com/casualjim/exeggutor)
+- [divshot/gitling](https://github.com/divshot/gitling)
+- [RWJMurphy/gorl](https://github.com/RWJMurphy/gorl)
+- [andrerocker/deploy42](https://github.com/andrerocker/deploy42)
+- [elwinar/rambler](https://github.com/elwinar/rambler)
+- [tmaiaroto/gopartman](https://github.com/tmaiaroto/gopartman)
+- [jfbus/impressionist](https://github.com/jfbus/impressionist)
+- [Jmeyering/zealot](https://github.com/Jmeyering/zealot)
+- [godep-migrator/rigger-host](https://github.com/godep-migrator/rigger-host)
+- [Dronevery/MultiwaySwitch-Go](https://github.com/Dronevery/MultiwaySwitch-Go)
+- [thoas/picfit](https://github.com/thoas/picfit)
+- [mantasmatelis/whooplist-server](https://github.com/mantasmatelis/whooplist-server)
+- [jnuthong/item_search](https://github.com/jnuthong/item_search)
+- [bukalapak/snowboard](https://github.com/bukalapak/snowboard)
+
+## Installation
+
+ go get github.com/imdario/mergo
+
+ // use in your .go code
+ import (
+ "github.com/imdario/mergo"
+ )
+
+## Usage
+
+You can only merge same-type structs with exported fields initialized as zero value of their type and same-types maps. Mergo won't merge unexported (private) fields but will do recursively any exported one. It won't merge empty structs value as [they are not considered zero values](https://golang.org/ref/spec#The_zero_value) either. Also maps will be merged recursively except for structs inside maps (because they are not addressable using Go reflection).
+
+```go
+if err := mergo.Merge(&dst, src); err != nil {
+ // ...
+}
+```
+
+Also, you can merge overwriting values using the transformer `WithOverride`.
+
+```go
+if err := mergo.Merge(&dst, src, mergo.WithOverride); err != nil {
+ // ...
+}
+```
+
+Additionally, you can map a `map[string]interface{}` to a struct (and otherwise, from struct to map), following the same restrictions as in `Merge()`. Keys are capitalized to find each corresponding exported field.
+
+```go
+if err := mergo.Map(&dst, srcMap); err != nil {
+ // ...
+}
+```
+
+Warning: if you map a struct to map, it won't do it recursively. Don't expect Mergo to map struct members of your struct as `map[string]interface{}`. They will be just assigned as values.
+
+More information and examples in [godoc documentation](http://godoc.org/github.com/imdario/mergo).
+
+### Nice example
+
+```go
+package main
+
+import (
+ "fmt"
+ "github.com/imdario/mergo"
+)
+
+type Foo struct {
+ A string
+ B int64
+}
+
+func main() {
+ src := Foo{
+ A: "one",
+ B: 2,
+ }
+ dest := Foo{
+ A: "two",
+ }
+ mergo.Merge(&dest, src)
+ fmt.Println(dest)
+ // Will print
+ // {two 2}
+}
+```
+
+Note: if test are failing due missing package, please execute:
+
+ go get gopkg.in/yaml.v2
+
+### Transformers
+
+Transformers allow to merge specific types differently than in the default behavior. In other words, now you can customize how some types are merged. For example, `time.Time` is a struct; it doesn't have zero value but IsZero can return true because it has fields with zero value. How can we merge a non-zero `time.Time`?
+
+```go
+package main
+
+import (
+ "fmt"
+ "github.com/imdario/mergo"
+ "reflect"
+ "time"
+)
+
+type timeTransfomer struct {
+}
+
+func (t timeTransfomer) Transformer(typ reflect.Type) func(dst, src reflect.Value) error {
+ if typ == reflect.TypeOf(time.Time{}) {
+ return func(dst, src reflect.Value) error {
+ if dst.CanSet() {
+ isZero := dst.MethodByName("IsZero")
+ result := isZero.Call([]reflect.Value{})
+ if result[0].Bool() {
+ dst.Set(src)
+ }
+ }
+ return nil
+ }
+ }
+ return nil
+}
+
+type Snapshot struct {
+ Time time.Time
+ // ...
+}
+
+func main() {
+ src := Snapshot{time.Now()}
+ dest := Snapshot{}
+ mergo.Merge(&dest, src, mergo.WithTransformers(timeTransfomer{}))
+ fmt.Println(dest)
+ // Will print
+ // { 2018-01-12 01:15:00 +0000 UTC m=+0.000000001 }
+}
+```
+
+
+## Contact me
+
+If I can help you, you have an idea or you are using Mergo in your projects, don't hesitate to drop me a line (or a pull request): [@im_dario](https://twitter.com/im_dario)
+
+## About
+
+Written by [Dario Castañé](http://dario.im).
+
+## License
+
+[BSD 3-Clause](http://opensource.org/licenses/BSD-3-Clause) license, as [Go language](http://golang.org/LICENSE).
diff --git a/backend/vendor/github.com/imdario/mergo/doc.go b/backend/vendor/github.com/imdario/mergo/doc.go
new file mode 100644
index 00000000..6e9aa7ba
--- /dev/null
+++ b/backend/vendor/github.com/imdario/mergo/doc.go
@@ -0,0 +1,44 @@
+// Copyright 2013 Dario Castañé. All rights reserved.
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+/*
+Package mergo merges same-type structs and maps by setting default values in zero-value fields.
+
+Mergo won't merge unexported (private) fields but will do recursively any exported one. It also won't merge structs inside maps (because they are not addressable using Go reflection).
+
+Usage
+
+From my own work-in-progress project:
+
+ type networkConfig struct {
+ Protocol string
+ Address string
+ ServerType string `json: "server_type"`
+ Port uint16
+ }
+
+ type FssnConfig struct {
+ Network networkConfig
+ }
+
+ var fssnDefault = FssnConfig {
+ networkConfig {
+ "tcp",
+ "127.0.0.1",
+ "http",
+ 31560,
+ },
+ }
+
+ // Inside a function [...]
+
+ if err := mergo.Merge(&config, fssnDefault); err != nil {
+ log.Fatal(err)
+ }
+
+ // More code [...]
+
+*/
+package mergo
diff --git a/backend/vendor/github.com/imdario/mergo/map.go b/backend/vendor/github.com/imdario/mergo/map.go
new file mode 100644
index 00000000..6ea38e63
--- /dev/null
+++ b/backend/vendor/github.com/imdario/mergo/map.go
@@ -0,0 +1,174 @@
+// Copyright 2014 Dario Castañé. All rights reserved.
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+// Based on src/pkg/reflect/deepequal.go from official
+// golang's stdlib.
+
+package mergo
+
+import (
+ "fmt"
+ "reflect"
+ "unicode"
+ "unicode/utf8"
+)
+
+func changeInitialCase(s string, mapper func(rune) rune) string {
+ if s == "" {
+ return s
+ }
+ r, n := utf8.DecodeRuneInString(s)
+ return string(mapper(r)) + s[n:]
+}
+
+func isExported(field reflect.StructField) bool {
+ r, _ := utf8.DecodeRuneInString(field.Name)
+ return r >= 'A' && r <= 'Z'
+}
+
+// Traverses recursively both values, assigning src's fields values to dst.
+// The map argument tracks comparisons that have already been seen, which allows
+// short circuiting on recursive types.
+func deepMap(dst, src reflect.Value, visited map[uintptr]*visit, depth int, config *Config) (err error) {
+ overwrite := config.Overwrite
+ if dst.CanAddr() {
+ addr := dst.UnsafeAddr()
+ h := 17 * addr
+ seen := visited[h]
+ typ := dst.Type()
+ for p := seen; p != nil; p = p.next {
+ if p.ptr == addr && p.typ == typ {
+ return nil
+ }
+ }
+ // Remember, remember...
+ visited[h] = &visit{addr, typ, seen}
+ }
+ zeroValue := reflect.Value{}
+ switch dst.Kind() {
+ case reflect.Map:
+ dstMap := dst.Interface().(map[string]interface{})
+ for i, n := 0, src.NumField(); i < n; i++ {
+ srcType := src.Type()
+ field := srcType.Field(i)
+ if !isExported(field) {
+ continue
+ }
+ fieldName := field.Name
+ fieldName = changeInitialCase(fieldName, unicode.ToLower)
+ if v, ok := dstMap[fieldName]; !ok || (isEmptyValue(reflect.ValueOf(v)) || overwrite) {
+ dstMap[fieldName] = src.Field(i).Interface()
+ }
+ }
+ case reflect.Ptr:
+ if dst.IsNil() {
+ v := reflect.New(dst.Type().Elem())
+ dst.Set(v)
+ }
+ dst = dst.Elem()
+ fallthrough
+ case reflect.Struct:
+ srcMap := src.Interface().(map[string]interface{})
+ for key := range srcMap {
+ srcValue := srcMap[key]
+ fieldName := changeInitialCase(key, unicode.ToUpper)
+ dstElement := dst.FieldByName(fieldName)
+ if dstElement == zeroValue {
+ // We discard it because the field doesn't exist.
+ continue
+ }
+ srcElement := reflect.ValueOf(srcValue)
+ dstKind := dstElement.Kind()
+ srcKind := srcElement.Kind()
+ if srcKind == reflect.Ptr && dstKind != reflect.Ptr {
+ srcElement = srcElement.Elem()
+ srcKind = reflect.TypeOf(srcElement.Interface()).Kind()
+ } else if dstKind == reflect.Ptr {
+ // Can this work? I guess it can't.
+ if srcKind != reflect.Ptr && srcElement.CanAddr() {
+ srcPtr := srcElement.Addr()
+ srcElement = reflect.ValueOf(srcPtr)
+ srcKind = reflect.Ptr
+ }
+ }
+
+ if !srcElement.IsValid() {
+ continue
+ }
+ if srcKind == dstKind {
+ if err = deepMerge(dstElement, srcElement, visited, depth+1, config); err != nil {
+ return
+ }
+ } else if dstKind == reflect.Interface && dstElement.Kind() == reflect.Interface {
+ if err = deepMerge(dstElement, srcElement, visited, depth+1, config); err != nil {
+ return
+ }
+ } else if srcKind == reflect.Map {
+ if err = deepMap(dstElement, srcElement, visited, depth+1, config); err != nil {
+ return
+ }
+ } else {
+ return fmt.Errorf("type mismatch on %s field: found %v, expected %v", fieldName, srcKind, dstKind)
+ }
+ }
+ }
+ return
+}
+
+// Map sets fields' values in dst from src.
+// src can be a map with string keys or a struct. dst must be the opposite:
+// if src is a map, dst must be a valid pointer to struct. If src is a struct,
+// dst must be map[string]interface{}.
+// It won't merge unexported (private) fields and will do recursively
+// any exported field.
+// If dst is a map, keys will be src fields' names in lower camel case.
+// Missing key in src that doesn't match a field in dst will be skipped. This
+// doesn't apply if dst is a map.
+// This is separated method from Merge because it is cleaner and it keeps sane
+// semantics: merging equal types, mapping different (restricted) types.
+func Map(dst, src interface{}, opts ...func(*Config)) error {
+ return _map(dst, src, opts...)
+}
+
+// MapWithOverwrite will do the same as Map except that non-empty dst attributes will be overridden by
+// non-empty src attribute values.
+// Deprecated: Use Map(…) with WithOverride
+func MapWithOverwrite(dst, src interface{}, opts ...func(*Config)) error {
+ return _map(dst, src, append(opts, WithOverride)...)
+}
+
+func _map(dst, src interface{}, opts ...func(*Config)) error {
+ var (
+ vDst, vSrc reflect.Value
+ err error
+ )
+ config := &Config{}
+
+ for _, opt := range opts {
+ opt(config)
+ }
+
+ if vDst, vSrc, err = resolveValues(dst, src); err != nil {
+ return err
+ }
+ // To be friction-less, we redirect equal-type arguments
+ // to deepMerge. Only because arguments can be anything.
+ if vSrc.Kind() == vDst.Kind() {
+ return deepMerge(vDst, vSrc, make(map[uintptr]*visit), 0, config)
+ }
+ switch vSrc.Kind() {
+ case reflect.Struct:
+ if vDst.Kind() != reflect.Map {
+ return ErrExpectedMapAsDestination
+ }
+ case reflect.Map:
+ if vDst.Kind() != reflect.Struct {
+ return ErrExpectedStructAsDestination
+ }
+ default:
+ return ErrNotSupported
+ }
+ return deepMap(vDst, vSrc, make(map[uintptr]*visit), 0, config)
+}
diff --git a/backend/vendor/github.com/imdario/mergo/merge.go b/backend/vendor/github.com/imdario/mergo/merge.go
new file mode 100644
index 00000000..44f70a89
--- /dev/null
+++ b/backend/vendor/github.com/imdario/mergo/merge.go
@@ -0,0 +1,252 @@
+// Copyright 2013 Dario Castañé. All rights reserved.
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+// Based on src/pkg/reflect/deepequal.go from official
+// golang's stdlib.
+
+package mergo
+
+import (
+ "fmt"
+ "reflect"
+)
+
+func hasExportedField(dst reflect.Value) (exported bool) {
+ for i, n := 0, dst.NumField(); i < n; i++ {
+ field := dst.Type().Field(i)
+ if field.Anonymous && dst.Field(i).Kind() == reflect.Struct {
+ exported = exported || hasExportedField(dst.Field(i))
+ } else {
+ exported = exported || len(field.PkgPath) == 0
+ }
+ }
+ return
+}
+
+type Config struct {
+ Overwrite bool
+ AppendSlice bool
+ Transformers Transformers
+}
+
+type Transformers interface {
+ Transformer(reflect.Type) func(dst, src reflect.Value) error
+}
+
+// Traverses recursively both values, assigning src's fields values to dst.
+// The map argument tracks comparisons that have already been seen, which allows
+// short circuiting on recursive types.
+func deepMerge(dst, src reflect.Value, visited map[uintptr]*visit, depth int, config *Config) (err error) {
+ overwrite := config.Overwrite
+
+ if !src.IsValid() {
+ return
+ }
+ if dst.CanAddr() {
+ addr := dst.UnsafeAddr()
+ h := 17 * addr
+ seen := visited[h]
+ typ := dst.Type()
+ for p := seen; p != nil; p = p.next {
+ if p.ptr == addr && p.typ == typ {
+ return nil
+ }
+ }
+ // Remember, remember...
+ visited[h] = &visit{addr, typ, seen}
+ }
+
+ if config.Transformers != nil && !isEmptyValue(dst) {
+ if fn := config.Transformers.Transformer(dst.Type()); fn != nil {
+ err = fn(dst, src)
+ return
+ }
+ }
+
+ switch dst.Kind() {
+ case reflect.Struct:
+ if hasExportedField(dst) {
+ for i, n := 0, dst.NumField(); i < n; i++ {
+ if err = deepMerge(dst.Field(i), src.Field(i), visited, depth+1, config); err != nil {
+ return
+ }
+ }
+ } else {
+ if dst.CanSet() && !isEmptyValue(src) && (overwrite || isEmptyValue(dst)) {
+ dst.Set(src)
+ }
+ }
+ case reflect.Map:
+ if dst.IsNil() && !src.IsNil() {
+ dst.Set(reflect.MakeMap(dst.Type()))
+ }
+ for _, key := range src.MapKeys() {
+ srcElement := src.MapIndex(key)
+ if !srcElement.IsValid() {
+ continue
+ }
+ dstElement := dst.MapIndex(key)
+ switch srcElement.Kind() {
+ case reflect.Chan, reflect.Func, reflect.Map, reflect.Interface, reflect.Slice:
+ if srcElement.IsNil() {
+ continue
+ }
+ fallthrough
+ default:
+ if !srcElement.CanInterface() {
+ continue
+ }
+ switch reflect.TypeOf(srcElement.Interface()).Kind() {
+ case reflect.Struct:
+ fallthrough
+ case reflect.Ptr:
+ fallthrough
+ case reflect.Map:
+ srcMapElm := srcElement
+ dstMapElm := dstElement
+ if srcMapElm.CanInterface() {
+ srcMapElm = reflect.ValueOf(srcMapElm.Interface())
+ if dstMapElm.IsValid() {
+ dstMapElm = reflect.ValueOf(dstMapElm.Interface())
+ }
+ }
+ if err = deepMerge(dstMapElm, srcMapElm, visited, depth+1, config); err != nil {
+ return
+ }
+ case reflect.Slice:
+ srcSlice := reflect.ValueOf(srcElement.Interface())
+
+ var dstSlice reflect.Value
+ if !dstElement.IsValid() || dstElement.IsNil() {
+ dstSlice = reflect.MakeSlice(srcSlice.Type(), 0, srcSlice.Len())
+ } else {
+ dstSlice = reflect.ValueOf(dstElement.Interface())
+ }
+
+ if !isEmptyValue(src) && (overwrite || isEmptyValue(dst)) && !config.AppendSlice {
+ dstSlice = srcSlice
+ } else if config.AppendSlice {
+ if srcSlice.Type() != dstSlice.Type() {
+ return fmt.Errorf("cannot append two slice with different type (%s, %s)", srcSlice.Type(), dstSlice.Type())
+ }
+ dstSlice = reflect.AppendSlice(dstSlice, srcSlice)
+ }
+ dst.SetMapIndex(key, dstSlice)
+ }
+ }
+ if dstElement.IsValid() && reflect.TypeOf(srcElement.Interface()).Kind() == reflect.Map {
+ continue
+ }
+
+ if srcElement.IsValid() && (overwrite || (!dstElement.IsValid() || isEmptyValue(dstElement))) {
+ if dst.IsNil() {
+ dst.Set(reflect.MakeMap(dst.Type()))
+ }
+ dst.SetMapIndex(key, srcElement)
+ }
+ }
+ case reflect.Slice:
+ if !dst.CanSet() {
+ break
+ }
+ if !isEmptyValue(src) && (overwrite || isEmptyValue(dst)) && !config.AppendSlice {
+ dst.Set(src)
+ } else if config.AppendSlice {
+ if src.Type() != dst.Type() {
+ return fmt.Errorf("cannot append two slice with different type (%s, %s)", src.Type(), dst.Type())
+ }
+ dst.Set(reflect.AppendSlice(dst, src))
+ }
+ case reflect.Ptr:
+ fallthrough
+ case reflect.Interface:
+ if src.IsNil() {
+ break
+ }
+ if src.Kind() != reflect.Interface {
+ if dst.IsNil() || overwrite {
+ if dst.CanSet() && (overwrite || isEmptyValue(dst)) {
+ dst.Set(src)
+ }
+ } else if src.Kind() == reflect.Ptr {
+ if err = deepMerge(dst.Elem(), src.Elem(), visited, depth+1, config); err != nil {
+ return
+ }
+ } else if dst.Elem().Type() == src.Type() {
+ if err = deepMerge(dst.Elem(), src, visited, depth+1, config); err != nil {
+ return
+ }
+ } else {
+ return ErrDifferentArgumentsTypes
+ }
+ break
+ }
+ if dst.IsNil() || overwrite {
+ if dst.CanSet() && (overwrite || isEmptyValue(dst)) {
+ dst.Set(src)
+ }
+ } else if err = deepMerge(dst.Elem(), src.Elem(), visited, depth+1, config); err != nil {
+ return
+ }
+ default:
+ if dst.CanSet() && !isEmptyValue(src) && (overwrite || isEmptyValue(dst)) {
+ dst.Set(src)
+ }
+ }
+ return
+}
+
+// Merge will fill any empty for value type attributes on the dst struct using corresponding
+// src attributes if they themselves are not empty. dst and src must be valid same-type structs
+// and dst must be a pointer to struct.
+// It won't merge unexported (private) fields and will do recursively any exported field.
+func Merge(dst, src interface{}, opts ...func(*Config)) error {
+ return merge(dst, src, opts...)
+}
+
+// MergeWithOverwrite will do the same as Merge except that non-empty dst attributes will be overriden by
+// non-empty src attribute values.
+// Deprecated: use Merge(…) with WithOverride
+func MergeWithOverwrite(dst, src interface{}, opts ...func(*Config)) error {
+ return merge(dst, src, append(opts, WithOverride)...)
+}
+
+// WithTransformers adds transformers to merge, allowing to customize the merging of some types.
+func WithTransformers(transformers Transformers) func(*Config) {
+ return func(config *Config) {
+ config.Transformers = transformers
+ }
+}
+
+// WithOverride will make merge override non-empty dst attributes with non-empty src attributes values.
+func WithOverride(config *Config) {
+ config.Overwrite = true
+}
+
+// WithAppendSlice will make merge append slices instead of overwriting it
+func WithAppendSlice(config *Config) {
+ config.AppendSlice = true
+}
+
+func merge(dst, src interface{}, opts ...func(*Config)) error {
+ var (
+ vDst, vSrc reflect.Value
+ err error
+ )
+
+ config := &Config{}
+
+ for _, opt := range opts {
+ opt(config)
+ }
+
+ if vDst, vSrc, err = resolveValues(dst, src); err != nil {
+ return err
+ }
+ if vDst.Type() != vSrc.Type() {
+ return ErrDifferentArgumentsTypes
+ }
+ return deepMerge(vDst, vSrc, make(map[uintptr]*visit), 0, config)
+}
diff --git a/backend/vendor/github.com/imdario/mergo/mergo.go b/backend/vendor/github.com/imdario/mergo/mergo.go
new file mode 100644
index 00000000..a82fea2f
--- /dev/null
+++ b/backend/vendor/github.com/imdario/mergo/mergo.go
@@ -0,0 +1,97 @@
+// Copyright 2013 Dario Castañé. All rights reserved.
+// Copyright 2009 The Go Authors. All rights reserved.
+// Use of this source code is governed by a BSD-style
+// license that can be found in the LICENSE file.
+
+// Based on src/pkg/reflect/deepequal.go from official
+// golang's stdlib.
+
+package mergo
+
+import (
+ "errors"
+ "reflect"
+)
+
+// Errors reported by Mergo when it finds invalid arguments.
+var (
+ ErrNilArguments = errors.New("src and dst must not be nil")
+ ErrDifferentArgumentsTypes = errors.New("src and dst must be of same type")
+ ErrNotSupported = errors.New("only structs and maps are supported")
+ ErrExpectedMapAsDestination = errors.New("dst was expected to be a map")
+ ErrExpectedStructAsDestination = errors.New("dst was expected to be a struct")
+)
+
+// During deepMerge, must keep track of checks that are
+// in progress. The comparison algorithm assumes that all
+// checks in progress are true when it reencounters them.
+// Visited are stored in a map indexed by 17 * a1 + a2;
+type visit struct {
+ ptr uintptr
+ typ reflect.Type
+ next *visit
+}
+
+// From src/pkg/encoding/json/encode.go.
+func isEmptyValue(v reflect.Value) bool {
+ switch v.Kind() {
+ case reflect.Array, reflect.Map, reflect.Slice, reflect.String:
+ return v.Len() == 0
+ case reflect.Bool:
+ return !v.Bool()
+ case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
+ return v.Int() == 0
+ case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64, reflect.Uintptr:
+ return v.Uint() == 0
+ case reflect.Float32, reflect.Float64:
+ return v.Float() == 0
+ case reflect.Interface, reflect.Ptr:
+ if v.IsNil() {
+ return true
+ }
+ return isEmptyValue(v.Elem())
+ case reflect.Func:
+ return v.IsNil()
+ case reflect.Invalid:
+ return true
+ }
+ return false
+}
+
+func resolveValues(dst, src interface{}) (vDst, vSrc reflect.Value, err error) {
+ if dst == nil || src == nil {
+ err = ErrNilArguments
+ return
+ }
+ vDst = reflect.ValueOf(dst).Elem()
+ if vDst.Kind() != reflect.Struct && vDst.Kind() != reflect.Map {
+ err = ErrNotSupported
+ return
+ }
+ vSrc = reflect.ValueOf(src)
+ // We check if vSrc is a pointer to dereference it.
+ if vSrc.Kind() == reflect.Ptr {
+ vSrc = vSrc.Elem()
+ }
+ return
+}
+
+// Traverses recursively both values, assigning src's fields values to dst.
+// The map argument tracks comparisons that have already been seen, which allows
+// short circuiting on recursive types.
+func deeper(dst, src reflect.Value, visited map[uintptr]*visit, depth int) (err error) {
+ if dst.CanAddr() {
+ addr := dst.UnsafeAddr()
+ h := 17 * addr
+ seen := visited[h]
+ typ := dst.Type()
+ for p := seen; p != nil; p = p.next {
+ if p.ptr == addr && p.typ == typ {
+ return nil
+ }
+ }
+ // Remember, remember...
+ visited[h] = &visit{addr, typ, seen}
+ }
+ return // TODO refactor
+}
diff --git a/backend/vendor/github.com/imroc/req/LICENSE b/backend/vendor/github.com/imroc/req/LICENSE
new file mode 100644
index 00000000..8dada3ed
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "{}"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright {yyyy} {name of copyright owner}
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/backend/vendor/github.com/imroc/req/README.md b/backend/vendor/github.com/imroc/req/README.md
new file mode 100644
index 00000000..c41d5ae0
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/README.md
@@ -0,0 +1,302 @@
+# req
+[](https://godoc.org/github.com/imroc/req)
+
+A golang http request library for humans
+
+
+
+Features
+========
+
+- Light weight
+- Simple
+- Easy play with JSON and XML
+- Easy for debug and logging
+- Easy file uploads and downloads
+- Easy manage cookie
+- Easy set up proxy
+- Easy set timeout
+- Easy customize http client
+
+
+Document
+========
+[中文](doc/README_cn.md)
+
+
+Install
+=======
+``` sh
+go get github.com/imroc/req
+```
+
+Overview
+=======
+`req` implements a friendly API over Go's existing `net/http` library.
+
+`Req` and `Resp` are two most important struct, you can think of `Req` as a client that initiate HTTP requests, `Resp` as a information container for the request and response. They all provide simple and convenient APIs that allows you to do a lot of things.
+``` go
+func (r *Req) Post(url string, v ...interface{}) (*Resp, error)
+```
+
+In most cases, only url is required, others are optional, like headers, params, files or body etc.
+
+There is a default `Req` object, all of its' public methods are wrapped by the `req` package, so you can also think of `req` package as a `Req` object
+``` go
+// use Req object to initiate requests.
+r := req.New()
+r.Get(url)
+
+// use req package to initiate request.
+req.Get(url)
+```
+You can use `req.New()` to create lots of `*Req` as client with independent configuration
+
+Examples
+=======
+[Basic](#Basic)
+[Set Header](#Set-Header)
+[Set Param](#Set-Param)
+[Set Body](#Set-Body)
+[Debug](#Debug)
+[Output Format](#Format)
+[ToJSON & ToXML](#ToJSON-ToXML)
+[Get *http.Response](#Response)
+[Upload](#Upload)
+[Download](#Download)
+[Cookie](#Cookie)
+[Set Timeout](#Set-Timeout)
+[Set Proxy](#Set-Proxy)
+[Customize Client](#Customize-Client)
+
+## Basic
+``` go
+header := req.Header{
+ "Accept": "application/json",
+ "Authorization": "Basic YWRtaW46YWRtaW4=",
+}
+param := req.Param{
+ "name": "imroc",
+ "cmd": "add",
+}
+// only url is required, others are optional.
+r, err = req.Post("http://foo.bar/api", header, param)
+if err != nil {
+ log.Fatal(err)
+}
+r.ToJSON(&foo) // response => struct/map
+log.Printf("%+v", r) // print info (try it, you may surprise)
+```
+
+## Set Header
+Use `req.Header` (it is actually a `map[string]string`)
+``` go
+authHeader := req.Header{
+ "Accept": "application/json",
+ "Authorization": "Basic YWRtaW46YWRtaW4=",
+}
+req.Get("https://www.baidu.com", authHeader, req.Header{"User-Agent": "V1.1"})
+```
+use `http.Header`
+``` go
+header := make(http.Header)
+header.Set("Accept", "application/json")
+req.Get("https://www.baidu.com", header)
+```
+
+## Set Param
+Use `req.Param` (it is actually a `map[string]interface{}`)
+``` go
+param := req.Param{
+ "id": "imroc",
+ "pwd": "roc",
+}
+req.Get("http://foo.bar/api", param) // http://foo.bar/api?id=imroc&pwd=roc
+req.Post(url, param) // body => id=imroc&pwd=roc
+```
+use `req.QueryParam` force to append params to the url (it is also actually a `map[string]interface{}`)
+``` go
+req.Post("http://foo.bar/api", req.Param{"name": "roc", "age": "22"}, req.QueryParam{"access_token": "fedledGF9Hg9ehTU"})
+/*
+POST /api?access_token=fedledGF9Hg9ehTU HTTP/1.1
+Host: foo.bar
+User-Agent: Go-http-client/1.1
+Content-Length: 15
+Content-Type: application/x-www-form-urlencoded;charset=UTF-8
+Accept-Encoding: gzip
+
+age=22&name=roc
+*/
+```
+
+## Set Body
+Put `string`, `[]byte` and `io.Reader` as body directly.
+``` go
+req.Post(url, "id=roc&cmd=query")
+```
+Put object as xml or json body (add `Content-Type` header automatically)
+``` go
+req.Post(url, req.BodyJSON(&foo))
+req.Post(url, req.BodyXML(&bar))
+```
+
+## Debug
+Set global variable `req.Debug` to true, it will print detail infomation for every request.
+``` go
+req.Debug = true
+req.Post("http://localhost/test" "hi")
+```
+
+
+## Output Format
+You can use different kind of output format to log the request and response infomation in your log file in defferent scenarios. For example, use `%+v` output format in the development phase, it allows you to observe the details. Use `%v` or `%-v` output format in production phase, just log the information necessarily.
+
+### `%+v` or `%+s`
+Output in detail
+``` go
+r, _ := req.Post(url, header, param)
+log.Printf("%+v", r) // output the same format as Debug is enabled
+```
+
+### `%v` or `%s`
+Output in simple way (default format)
+``` go
+r, _ := req.Get(url, param)
+log.Printf("%v\n", r) // GET http://foo.bar/api?name=roc&cmd=add {"code":"0","msg":"success"}
+log.Prinln(r) // smae as above
+```
+
+### `%-v` or `%-s`
+Output in simple way and keep all in one line (request body or response body may have multiple lines, this format will replace `"\r"` or `"\n"` with `" "`, it's useful when doing some search in your log file)
+
+### Flag
+You can call `SetFlags` to control the output content, decide which pieces can be output.
+``` go
+const (
+ LreqHead = 1 << iota // output request head (request line and request header)
+ LreqBody // output request body
+ LrespHead // output response head (response line and response header)
+ LrespBody // output response body
+ Lcost // output time costed by the request
+ LstdFlags = LreqHead | LreqBody | LrespHead | LrespBody
+)
+```
+``` go
+req.SetFlags(req.LreqHead | req.LreqBody | req.LrespHead)
+```
+
+### Monitoring time consuming
+``` go
+req.SetFlags(req.LstdFlags | req.Lcost) // output format add time costed by request
+r,_ := req.Get(url)
+log.Println(r) // http://foo.bar/api 3.260802ms {"code":0 "msg":"success"}
+if r.Cost() > 3 * time.Second { // check cost
+ log.Println("WARN: slow request:", r)
+}
+```
+
+## ToJSON & ToXML
+``` go
+r, _ := req.Get(url)
+r.ToJSON(&foo)
+r, _ = req.Post(url, req.BodyXML(&bar))
+r.ToXML(&baz)
+```
+
+## Get *http.Response
+```go
+// func (r *Req) Response() *http.Response
+r, _ := req.Get(url)
+resp := r.Response()
+fmt.Println(resp.StatusCode)
+```
+
+## Upload
+Use `req.File` to match files
+``` go
+req.Post(url, req.File("imroc.png"), req.File("/Users/roc/Pictures/*.png"))
+```
+Use `req.FileUpload` to fully control
+``` go
+file, _ := os.Open("imroc.png")
+req.Post(url, req.FileUpload{
+ File: file,
+ FieldName: "file", // FieldName is form field name
+ FileName: "avatar.png", //Filename is the name of the file that you wish to upload. We use this to guess the mimetype as well as pass it onto the server
+})
+```
+Use `req.UploadProgress` to listen upload progress
+```go
+progress := func(current, total int64) {
+ fmt.Println(float32(current)/float32(total)*100, "%")
+}
+req.Post(url, req.File("/Users/roc/Pictures/*.png"), req.UploadProgress(progress))
+fmt.Println("upload complete")
+```
+
+## Download
+``` go
+r, _ := req.Get(url)
+r.ToFile("imroc.png")
+```
+Use `req.DownloadProgress` to listen download progress
+```go
+progress := func(current, total int64) {
+ fmt.Println(float32(current)/float32(total)*100, "%")
+}
+r, _ := req.Get(url, req.DownloadProgress(progress))
+r.ToFile("hello.mp4")
+fmt.Println("download complete")
+```
+
+## Cookie
+By default, the underlying `*http.Client` will manage your cookie(send cookie header to server automatically if server has set a cookie for you), you can disable it by calling this function :
+``` go
+req.EnableCookie(false)
+```
+and you can set cookie in request just using `*http.Cookie`
+``` go
+cookie := new(http.Cookie)
+// ......
+req.Get(url, cookie)
+```
+
+## Set Timeout
+``` go
+req.SetTimeout(50 * time.Second)
+```
+
+## Set Proxy
+By default, req use proxy from system environment if `http_proxy` or `https_proxy` is specified, you can set a custom proxy or disable it by set `nil`
+``` go
+req.SetProxy(func(r *http.Request) (*url.URL, error) {
+ if strings.Contains(r.URL.Hostname(), "google") {
+ return url.Parse("http://my.vpn.com:23456")
+ }
+ return nil, nil
+})
+```
+Set a simple proxy (use fixed proxy url for every request)
+``` go
+req.SetProxyUrl("http://my.proxy.com:23456")
+```
+
+## Customize Client
+Use `SetClient` to change the default underlying `*http.Client`
+``` go
+req.SetClient(client)
+```
+Specify independent http client for some requests
+``` go
+client := &http.Client{Timeout: 30 * time.Second}
+req.Get(url, client)
+```
+Change some properties of default client you want
+``` go
+req.Client().Jar, _ = cookiejar.New(nil)
+trans, _ := req.Client().Transport.(*http.Transport)
+trans.MaxIdleConns = 20
+trans.TLSHandshakeTimeout = 20 * time.Second
+trans.DisableKeepAlives = true
+trans.TLSClientConfig = &tls.Config{InsecureSkipVerify: true}
+```
diff --git a/backend/vendor/github.com/imroc/req/dump.go b/backend/vendor/github.com/imroc/req/dump.go
new file mode 100644
index 00000000..ce6d3a5b
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/dump.go
@@ -0,0 +1,216 @@
+package req
+
+import (
+ "bufio"
+ "bytes"
+ "fmt"
+ "io"
+ "io/ioutil"
+ "net"
+ "net/http"
+ "net/http/httputil"
+ "net/url"
+ "strings"
+ "time"
+)
+
+// Debug enable debug mode if set to true
+var Debug bool
+
+// dumpConn is a net.Conn which writes to Writer and reads from Reader
+type dumpConn struct {
+ io.Writer
+ io.Reader
+}
+
+func (c *dumpConn) Close() error { return nil }
+func (c *dumpConn) LocalAddr() net.Addr { return nil }
+func (c *dumpConn) RemoteAddr() net.Addr { return nil }
+func (c *dumpConn) SetDeadline(t time.Time) error { return nil }
+func (c *dumpConn) SetReadDeadline(t time.Time) error { return nil }
+func (c *dumpConn) SetWriteDeadline(t time.Time) error { return nil }
+
+// delegateReader is a reader that delegates to another reader,
+// once it arrives on a channel.
+type delegateReader struct {
+ c chan io.Reader
+ r io.Reader // nil until received from c
+}
+
+func (r *delegateReader) Read(p []byte) (int, error) {
+ if r.r == nil {
+ r.r = <-r.c
+ }
+ return r.r.Read(p)
+}
+
+type dummyBody struct {
+ N int
+ off int
+}
+
+func (d *dummyBody) Read(p []byte) (n int, err error) {
+ if d.N <= 0 {
+ err = io.EOF
+ return
+ }
+ left := d.N - d.off
+ if left <= 0 {
+ err = io.EOF
+ return
+ }
+
+ if l := len(p); l > 0 {
+ if l >= left {
+ n = left
+ err = io.EOF
+ } else {
+ n = l
+ }
+ d.off += n
+ for i := 0; i < n; i++ {
+ p[i] = '*'
+ }
+ }
+
+ return
+}
+
+func (d *dummyBody) Close() error {
+ return nil
+}
+
+type dumpBuffer struct {
+ bytes.Buffer
+}
+
+func (b *dumpBuffer) Write(p []byte) {
+ if b.Len() > 0 {
+ b.Buffer.WriteString("\r\n\r\n")
+ }
+ b.Buffer.Write(p)
+}
+
+func (b *dumpBuffer) WriteString(s string) {
+ b.Write([]byte(s))
+}
+
+func (r *Resp) dumpRequest(dump *dumpBuffer) {
+ head := r.r.flag&LreqHead != 0
+ body := r.r.flag&LreqBody != 0
+
+ if head {
+ r.dumpReqHead(dump)
+ }
+ if body {
+ if r.multipartHelper != nil {
+ dump.Write(r.multipartHelper.Dump())
+ } else if len(r.reqBody) > 0 {
+ dump.Write(r.reqBody)
+ }
+ }
+}
+
+func (r *Resp) dumpReqHead(dump *dumpBuffer) {
+ reqSend := new(http.Request)
+ *reqSend = *r.req
+ if reqSend.URL.Scheme == "https" {
+ reqSend.URL = new(url.URL)
+ *reqSend.URL = *r.req.URL
+ reqSend.URL.Scheme = "http"
+ }
+
+ if reqSend.ContentLength > 0 {
+ reqSend.Body = &dummyBody{N: int(reqSend.ContentLength)}
+ } else {
+ reqSend.Body = &dummyBody{N: 1}
+ }
+
+ // Use the actual Transport code to record what we would send
+ // on the wire, but not using TCP. Use a Transport with a
+ // custom dialer that returns a fake net.Conn that waits
+ // for the full input (and recording it), and then responds
+ // with a dummy response.
+ var buf bytes.Buffer // records the output
+ pr, pw := io.Pipe()
+ defer pw.Close()
+ dr := &delegateReader{c: make(chan io.Reader)}
+
+ t := &http.Transport{
+ Dial: func(net, addr string) (net.Conn, error) {
+ return &dumpConn{io.MultiWriter(&buf, pw), dr}, nil
+ },
+ }
+ defer t.CloseIdleConnections()
+
+ client := new(http.Client)
+ *client = *r.client
+ client.Transport = t
+
+ // Wait for the request before replying with a dummy response:
+ go func() {
+ req, err := http.ReadRequest(bufio.NewReader(pr))
+ if err == nil {
+ // Ensure all the body is read; otherwise
+ // we'll get a partial dump.
+ io.Copy(ioutil.Discard, req.Body)
+ req.Body.Close()
+ }
+
+ dr.c <- strings.NewReader("HTTP/1.1 204 No Content\r\nConnection: close\r\n\r\n")
+ pr.Close()
+ }()
+
+ _, err := client.Do(reqSend)
+ if err != nil {
+ dump.WriteString(err.Error())
+ } else {
+ reqDump := buf.Bytes()
+ if i := bytes.Index(reqDump, []byte("\r\n\r\n")); i >= 0 {
+ reqDump = reqDump[:i]
+ }
+ dump.Write(reqDump)
+ }
+}
+
+func (r *Resp) dumpResponse(dump *dumpBuffer) {
+ head := r.r.flag&LrespHead != 0
+ body := r.r.flag&LrespBody != 0
+ if head {
+ respDump, err := httputil.DumpResponse(r.resp, false)
+ if err != nil {
+ dump.WriteString(err.Error())
+ } else {
+ if i := bytes.Index(respDump, []byte("\r\n\r\n")); i >= 0 {
+ respDump = respDump[:i]
+ }
+ dump.Write(respDump)
+ }
+ }
+ if body && len(r.Bytes()) > 0 {
+ dump.Write(r.Bytes())
+ }
+}
+
+// Cost return the time cost of the request
+func (r *Resp) Cost() time.Duration {
+ return r.cost
+}
+
+// Dump dump the request
+func (r *Resp) Dump() string {
+ dump := new(dumpBuffer)
+ if r.r.flag&Lcost != 0 {
+ dump.WriteString(fmt.Sprint(r.cost))
+ }
+ r.dumpRequest(dump)
+ l := dump.Len()
+ if l > 0 {
+ dump.WriteString("=================================")
+ l = dump.Len()
+ }
+
+ r.dumpResponse(dump)
+
+ return dump.String()
+}
diff --git a/backend/vendor/github.com/imroc/req/req.go b/backend/vendor/github.com/imroc/req/req.go
new file mode 100644
index 00000000..d1b3e712
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/req.go
@@ -0,0 +1,688 @@
+package req
+
+import (
+ "bytes"
+ "compress/gzip"
+ "context"
+ "encoding/json"
+ "encoding/xml"
+ "errors"
+ "fmt"
+ "io"
+ "io/ioutil"
+ "mime/multipart"
+ "net/http"
+ "net/textproto"
+ "net/url"
+ "os"
+ "path/filepath"
+ "strconv"
+ "strings"
+ "time"
+)
+
+// default *Req
+var std = New()
+
+// flags to decide which part can be outputed
+const (
+ LreqHead = 1 << iota // output request head (request line and request header)
+ LreqBody // output request body
+ LrespHead // output response head (response line and response header)
+ LrespBody // output response body
+ Lcost // output time costed by the request
+ LstdFlags = LreqHead | LreqBody | LrespHead | LrespBody
+)
+
+// Header represents http request header
+type Header map[string]string
+
+func (h Header) Clone() Header {
+ if h == nil {
+ return nil
+ }
+ hh := Header{}
+ for k, v := range h {
+ hh[k] = v
+ }
+ return hh
+}
+
+// Param represents http request param
+type Param map[string]interface{}
+
+// QueryParam is used to force append http request param to the uri
+type QueryParam map[string]interface{}
+
+// Host is used for set request's Host
+type Host string
+
+// FileUpload represents a file to upload
+type FileUpload struct {
+ // filename in multipart form.
+ FileName string
+ // form field name
+ FieldName string
+ // file to uplaod, required
+ File io.ReadCloser
+}
+
+type DownloadProgress func(current, total int64)
+
+type UploadProgress func(current, total int64)
+
+// File upload files matching the name pattern such as
+// /usr/*/bin/go* (assuming the Separator is '/')
+func File(patterns ...string) interface{} {
+ matches := []string{}
+ for _, pattern := range patterns {
+ m, err := filepath.Glob(pattern)
+ if err != nil {
+ return err
+ }
+ matches = append(matches, m...)
+ }
+ if len(matches) == 0 {
+ return errors.New("req: no file have been matched")
+ }
+ uploads := []FileUpload{}
+ for _, match := range matches {
+ if s, e := os.Stat(match); e != nil || s.IsDir() {
+ continue
+ }
+ file, _ := os.Open(match)
+ uploads = append(uploads, FileUpload{
+ File: file,
+ FileName: filepath.Base(match),
+ FieldName: "media",
+ })
+ }
+
+ return uploads
+}
+
+type bodyJson struct {
+ v interface{}
+}
+
+type bodyXml struct {
+ v interface{}
+}
+
+// BodyJSON make the object be encoded in json format and set it to the request body
+func BodyJSON(v interface{}) *bodyJson {
+ return &bodyJson{v: v}
+}
+
+// BodyXML make the object be encoded in xml format and set it to the request body
+func BodyXML(v interface{}) *bodyXml {
+ return &bodyXml{v: v}
+}
+
+// Req is a convenient client for initiating requests
+type Req struct {
+ client *http.Client
+ jsonEncOpts *jsonEncOpts
+ xmlEncOpts *xmlEncOpts
+ flag int
+}
+
+// New create a new *Req
+func New() *Req {
+ return &Req{flag: LstdFlags}
+}
+
+type param struct {
+ url.Values
+}
+
+func (p *param) getValues() url.Values {
+ if p.Values == nil {
+ p.Values = make(url.Values)
+ }
+ return p.Values
+}
+
+func (p *param) Copy(pp param) {
+ if pp.Values == nil {
+ return
+ }
+ vs := p.getValues()
+ for key, values := range pp.Values {
+ for _, value := range values {
+ vs.Add(key, value)
+ }
+ }
+}
+func (p *param) Adds(m map[string]interface{}) {
+ if len(m) == 0 {
+ return
+ }
+ vs := p.getValues()
+ for k, v := range m {
+ vs.Add(k, fmt.Sprint(v))
+ }
+}
+
+func (p *param) Empty() bool {
+ return p.Values == nil
+}
+
+// Do execute a http request with sepecify method and url,
+// and it can also have some optional params, depending on your needs.
+func (r *Req) Do(method, rawurl string, vs ...interface{}) (resp *Resp, err error) {
+ if rawurl == "" {
+ return nil, errors.New("req: url not specified")
+ }
+ req := &http.Request{
+ Method: method,
+ Header: make(http.Header),
+ Proto: "HTTP/1.1",
+ ProtoMajor: 1,
+ ProtoMinor: 1,
+ }
+ resp = &Resp{req: req, r: r}
+
+ var queryParam param
+ var formParam param
+ var uploads []FileUpload
+ var uploadProgress UploadProgress
+ var progress func(int64, int64)
+ var delayedFunc []func()
+ var lastFunc []func()
+
+ for _, v := range vs {
+ switch vv := v.(type) {
+ case Header:
+ for key, value := range vv {
+ req.Header.Add(key, value)
+ }
+ case http.Header:
+ for key, values := range vv {
+ for _, value := range values {
+ req.Header.Add(key, value)
+ }
+ }
+ case *bodyJson:
+ fn, err := setBodyJson(req, resp, r.jsonEncOpts, vv.v)
+ if err != nil {
+ return nil, err
+ }
+ delayedFunc = append(delayedFunc, fn)
+ case *bodyXml:
+ fn, err := setBodyXml(req, resp, r.xmlEncOpts, vv.v)
+ if err != nil {
+ return nil, err
+ }
+ delayedFunc = append(delayedFunc, fn)
+ case url.Values:
+ p := param{vv}
+ if method == "GET" || method == "HEAD" {
+ queryParam.Copy(p)
+ } else {
+ formParam.Copy(p)
+ }
+ case Param:
+ if method == "GET" || method == "HEAD" {
+ queryParam.Adds(vv)
+ } else {
+ formParam.Adds(vv)
+ }
+ case QueryParam:
+ queryParam.Adds(vv)
+ case string:
+ setBodyBytes(req, resp, []byte(vv))
+ case []byte:
+ setBodyBytes(req, resp, vv)
+ case bytes.Buffer:
+ setBodyBytes(req, resp, vv.Bytes())
+ case *http.Client:
+ resp.client = vv
+ case FileUpload:
+ uploads = append(uploads, vv)
+ case []FileUpload:
+ uploads = append(uploads, vv...)
+ case *http.Cookie:
+ req.AddCookie(vv)
+ case Host:
+ req.Host = string(vv)
+ case io.Reader:
+ fn := setBodyReader(req, resp, vv)
+ lastFunc = append(lastFunc, fn)
+ case UploadProgress:
+ uploadProgress = vv
+ case DownloadProgress:
+ resp.downloadProgress = vv
+ case func(int64, int64):
+ progress = vv
+ case context.Context:
+ req = req.WithContext(vv)
+ resp.req = req
+ case error:
+ return nil, vv
+ }
+ }
+
+ if length := req.Header.Get("Content-Length"); length != "" {
+ if l, err := strconv.ParseInt(length, 10, 64); err == nil {
+ req.ContentLength = l
+ }
+ }
+
+ if len(uploads) > 0 && (req.Method == "POST" || req.Method == "PUT") { // multipart
+ var up UploadProgress
+ if uploadProgress != nil {
+ up = uploadProgress
+ } else if progress != nil {
+ up = UploadProgress(progress)
+ }
+ multipartHelper := &multipartHelper{
+ form: formParam.Values,
+ uploads: uploads,
+ uploadProgress: up,
+ }
+ multipartHelper.Upload(req)
+ resp.multipartHelper = multipartHelper
+ } else {
+ if progress != nil {
+ resp.downloadProgress = DownloadProgress(progress)
+ }
+ if !formParam.Empty() {
+ if req.Body != nil {
+ queryParam.Copy(formParam)
+ } else {
+ setBodyBytes(req, resp, []byte(formParam.Encode()))
+ setContentType(req, "application/x-www-form-urlencoded; charset=UTF-8")
+ }
+ }
+ }
+
+ if !queryParam.Empty() {
+ paramStr := queryParam.Encode()
+ if strings.IndexByte(rawurl, '?') == -1 {
+ rawurl = rawurl + "?" + paramStr
+ } else {
+ rawurl = rawurl + "&" + paramStr
+ }
+ }
+
+ u, err := url.Parse(rawurl)
+ if err != nil {
+ return nil, err
+ }
+ req.URL = u
+
+ if host := req.Header.Get("Host"); host != "" {
+ req.Host = host
+ }
+
+ for _, fn := range delayedFunc {
+ fn()
+ }
+
+ if resp.client == nil {
+ resp.client = r.Client()
+ }
+
+ var response *http.Response
+ if r.flag&Lcost != 0 {
+ before := time.Now()
+ response, err = resp.client.Do(req)
+ after := time.Now()
+ resp.cost = after.Sub(before)
+ } else {
+ response, err = resp.client.Do(req)
+ }
+ if err != nil {
+ return nil, err
+ }
+
+ for _, fn := range lastFunc {
+ fn()
+ }
+
+ resp.resp = response
+
+ if _, ok := resp.client.Transport.(*http.Transport); ok && response.Header.Get("Content-Encoding") == "gzip" && req.Header.Get("Accept-Encoding") != "" {
+ body, err := gzip.NewReader(response.Body)
+ if err != nil {
+ return nil, err
+ }
+ response.Body = body
+ }
+
+ // output detail if Debug is enabled
+ if Debug {
+ fmt.Println(resp.Dump())
+ }
+ return
+}
+
+func setBodyBytes(req *http.Request, resp *Resp, data []byte) {
+ resp.reqBody = data
+ req.Body = ioutil.NopCloser(bytes.NewReader(data))
+ req.ContentLength = int64(len(data))
+}
+
+func setBodyJson(req *http.Request, resp *Resp, opts *jsonEncOpts, v interface{}) (func(), error) {
+ var data []byte
+ switch vv := v.(type) {
+ case string:
+ data = []byte(vv)
+ case []byte:
+ data = vv
+ case *bytes.Buffer:
+ data = vv.Bytes()
+ default:
+ if opts != nil {
+ var buf bytes.Buffer
+ enc := json.NewEncoder(&buf)
+ enc.SetIndent(opts.indentPrefix, opts.indentValue)
+ enc.SetEscapeHTML(opts.escapeHTML)
+ err := enc.Encode(v)
+ if err != nil {
+ return nil, err
+ }
+ data = buf.Bytes()
+ } else {
+ var err error
+ data, err = json.Marshal(v)
+ if err != nil {
+ return nil, err
+ }
+ }
+ }
+ setBodyBytes(req, resp, data)
+ delayedFunc := func() {
+ setContentType(req, "application/json; charset=UTF-8")
+ }
+ return delayedFunc, nil
+}
+
+func setBodyXml(req *http.Request, resp *Resp, opts *xmlEncOpts, v interface{}) (func(), error) {
+ var data []byte
+ switch vv := v.(type) {
+ case string:
+ data = []byte(vv)
+ case []byte:
+ data = vv
+ case *bytes.Buffer:
+ data = vv.Bytes()
+ default:
+ if opts != nil {
+ var buf bytes.Buffer
+ enc := xml.NewEncoder(&buf)
+ enc.Indent(opts.prefix, opts.indent)
+ err := enc.Encode(v)
+ if err != nil {
+ return nil, err
+ }
+ data = buf.Bytes()
+ } else {
+ var err error
+ data, err = xml.Marshal(v)
+ if err != nil {
+ return nil, err
+ }
+ }
+ }
+ setBodyBytes(req, resp, data)
+ delayedFunc := func() {
+ setContentType(req, "application/xml; charset=UTF-8")
+ }
+ return delayedFunc, nil
+}
+
+func setContentType(req *http.Request, contentType string) {
+ if req.Header.Get("Content-Type") == "" {
+ req.Header.Set("Content-Type", contentType)
+ }
+}
+
+func setBodyReader(req *http.Request, resp *Resp, rd io.Reader) func() {
+ var rc io.ReadCloser
+ switch r := rd.(type) {
+ case *os.File:
+ stat, err := r.Stat()
+ if err == nil {
+ req.ContentLength = stat.Size()
+ }
+ rc = r
+
+ case io.ReadCloser:
+ rc = r
+ default:
+ rc = ioutil.NopCloser(rd)
+ }
+ bw := &bodyWrapper{
+ ReadCloser: rc,
+ limit: 102400,
+ }
+ req.Body = bw
+ lastFunc := func() {
+ resp.reqBody = bw.buf.Bytes()
+ }
+ return lastFunc
+}
+
+type bodyWrapper struct {
+ io.ReadCloser
+ buf bytes.Buffer
+ limit int
+}
+
+func (b *bodyWrapper) Read(p []byte) (n int, err error) {
+ n, err = b.ReadCloser.Read(p)
+ if left := b.limit - b.buf.Len(); left > 0 && n > 0 {
+ if n <= left {
+ b.buf.Write(p[:n])
+ } else {
+ b.buf.Write(p[:left])
+ }
+ }
+ return
+}
+
+type multipartHelper struct {
+ form url.Values
+ uploads []FileUpload
+ dump []byte
+ uploadProgress UploadProgress
+}
+
+func (m *multipartHelper) Upload(req *http.Request) {
+ pr, pw := io.Pipe()
+ bodyWriter := multipart.NewWriter(pw)
+ go func() {
+ for key, values := range m.form {
+ for _, value := range values {
+ bodyWriter.WriteField(key, value)
+ }
+ }
+ var upload func(io.Writer, io.Reader) error
+ if m.uploadProgress != nil {
+ var total int64
+ for _, up := range m.uploads {
+ if file, ok := up.File.(*os.File); ok {
+ stat, err := file.Stat()
+ if err != nil {
+ continue
+ }
+ total += stat.Size()
+ }
+ }
+ var current int64
+ buf := make([]byte, 1024)
+ var lastTime time.Time
+ upload = func(w io.Writer, r io.Reader) error {
+ for {
+ n, err := r.Read(buf)
+ if n > 0 {
+ _, _err := w.Write(buf[:n])
+ if _err != nil {
+ return _err
+ }
+ current += int64(n)
+ if now := time.Now(); now.Sub(lastTime) > 200*time.Millisecond {
+ lastTime = now
+ m.uploadProgress(current, total)
+ }
+ }
+ if err == io.EOF {
+ return nil
+ }
+ if err != nil {
+ return err
+ }
+ }
+ }
+ }
+
+ i := 0
+ for _, up := range m.uploads {
+ if up.FieldName == "" {
+ i++
+ up.FieldName = "file" + strconv.Itoa(i)
+ }
+ fileWriter, err := bodyWriter.CreateFormFile(up.FieldName, up.FileName)
+ if err != nil {
+ continue
+ }
+ //iocopy
+ if upload == nil {
+ io.Copy(fileWriter, up.File)
+ } else {
+ if _, ok := up.File.(*os.File); ok {
+ upload(fileWriter, up.File)
+ } else {
+ io.Copy(fileWriter, up.File)
+ }
+ }
+ up.File.Close()
+ }
+ bodyWriter.Close()
+ pw.Close()
+ }()
+ req.Header.Set("Content-Type", bodyWriter.FormDataContentType())
+ req.Body = ioutil.NopCloser(pr)
+}
+
+func (m *multipartHelper) Dump() []byte {
+ if m.dump != nil {
+ return m.dump
+ }
+ var buf bytes.Buffer
+ bodyWriter := multipart.NewWriter(&buf)
+ for key, values := range m.form {
+ for _, value := range values {
+ m.writeField(bodyWriter, key, value)
+ }
+ }
+ for _, up := range m.uploads {
+ m.writeFile(bodyWriter, up.FieldName, up.FileName)
+ }
+ bodyWriter.Close()
+ m.dump = buf.Bytes()
+ return m.dump
+}
+
+func (m *multipartHelper) writeField(w *multipart.Writer, fieldname, value string) error {
+ h := make(textproto.MIMEHeader)
+ h.Set("Content-Disposition",
+ fmt.Sprintf(`form-data; name="%s"`, fieldname))
+ p, err := w.CreatePart(h)
+ if err != nil {
+ return err
+ }
+ _, err = p.Write([]byte(value))
+ return err
+}
+
+func (m *multipartHelper) writeFile(w *multipart.Writer, fieldname, filename string) error {
+ h := make(textproto.MIMEHeader)
+ h.Set("Content-Disposition",
+ fmt.Sprintf(`form-data; name="%s"; filename="%s"`,
+ fieldname, filename))
+ h.Set("Content-Type", "application/octet-stream")
+ p, err := w.CreatePart(h)
+ if err != nil {
+ return err
+ }
+ _, err = p.Write([]byte("******"))
+ return err
+}
+
+// Get execute a http GET request
+func (r *Req) Get(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("GET", url, v...)
+}
+
+// Post execute a http POST request
+func (r *Req) Post(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("POST", url, v...)
+}
+
+// Put execute a http PUT request
+func (r *Req) Put(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("PUT", url, v...)
+}
+
+// Patch execute a http PATCH request
+func (r *Req) Patch(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("PATCH", url, v...)
+}
+
+// Delete execute a http DELETE request
+func (r *Req) Delete(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("DELETE", url, v...)
+}
+
+// Head execute a http HEAD request
+func (r *Req) Head(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("HEAD", url, v...)
+}
+
+// Options execute a http OPTIONS request
+func (r *Req) Options(url string, v ...interface{}) (*Resp, error) {
+ return r.Do("OPTIONS", url, v...)
+}
+
+// Get execute a http GET request
+func Get(url string, v ...interface{}) (*Resp, error) {
+ return std.Get(url, v...)
+}
+
+// Post execute a http POST request
+func Post(url string, v ...interface{}) (*Resp, error) {
+ return std.Post(url, v...)
+}
+
+// Put execute a http PUT request
+func Put(url string, v ...interface{}) (*Resp, error) {
+ return std.Put(url, v...)
+}
+
+// Head execute a http HEAD request
+func Head(url string, v ...interface{}) (*Resp, error) {
+ return std.Head(url, v...)
+}
+
+// Options execute a http OPTIONS request
+func Options(url string, v ...interface{}) (*Resp, error) {
+ return std.Options(url, v...)
+}
+
+// Delete execute a http DELETE request
+func Delete(url string, v ...interface{}) (*Resp, error) {
+ return std.Delete(url, v...)
+}
+
+// Patch execute a http PATCH request
+func Patch(url string, v ...interface{}) (*Resp, error) {
+ return std.Patch(url, v...)
+}
+
+// Do execute request.
+func Do(method, url string, v ...interface{}) (*Resp, error) {
+ return std.Do(method, url, v...)
+}
diff --git a/backend/vendor/github.com/imroc/req/resp.go b/backend/vendor/github.com/imroc/req/resp.go
new file mode 100644
index 00000000..eb56b1bd
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/resp.go
@@ -0,0 +1,215 @@
+package req
+
+import (
+ "encoding/json"
+ "encoding/xml"
+ "fmt"
+ "io"
+ "io/ioutil"
+ "net/http"
+ "os"
+ "regexp"
+ "time"
+)
+
+// Resp represents a request with it's response
+type Resp struct {
+ r *Req
+ req *http.Request
+ resp *http.Response
+ client *http.Client
+ cost time.Duration
+ *multipartHelper
+ reqBody []byte
+ respBody []byte
+ downloadProgress DownloadProgress
+ err error // delayed error
+}
+
+// Request returns *http.Request
+func (r *Resp) Request() *http.Request {
+ return r.req
+}
+
+// Response returns *http.Response
+func (r *Resp) Response() *http.Response {
+ return r.resp
+}
+
+// Bytes returns response body as []byte
+func (r *Resp) Bytes() []byte {
+ data, _ := r.ToBytes()
+ return data
+}
+
+// ToBytes returns response body as []byte,
+// return error if error happend when reading
+// the response body
+func (r *Resp) ToBytes() ([]byte, error) {
+ if r.err != nil {
+ return nil, r.err
+ }
+ if r.respBody != nil {
+ return r.respBody, nil
+ }
+ defer r.resp.Body.Close()
+ respBody, err := ioutil.ReadAll(r.resp.Body)
+ if err != nil {
+ r.err = err
+ return nil, err
+ }
+ r.respBody = respBody
+ return r.respBody, nil
+}
+
+// String returns response body as string
+func (r *Resp) String() string {
+ data, _ := r.ToBytes()
+ return string(data)
+}
+
+// ToString returns response body as string,
+// return error if error happend when reading
+// the response body
+func (r *Resp) ToString() (string, error) {
+ data, err := r.ToBytes()
+ return string(data), err
+}
+
+// ToJSON convert json response body to struct or map
+func (r *Resp) ToJSON(v interface{}) error {
+ data, err := r.ToBytes()
+ if err != nil {
+ return err
+ }
+ return json.Unmarshal(data, v)
+}
+
+// ToXML convert xml response body to struct or map
+func (r *Resp) ToXML(v interface{}) error {
+ data, err := r.ToBytes()
+ if err != nil {
+ return err
+ }
+ return xml.Unmarshal(data, v)
+}
+
+// ToFile download the response body to file with optional download callback
+func (r *Resp) ToFile(name string) error {
+ //TODO set name to the suffix of url path if name == ""
+ file, err := os.Create(name)
+ if err != nil {
+ return err
+ }
+ defer file.Close()
+
+ if r.respBody != nil {
+ _, err = file.Write(r.respBody)
+ return err
+ }
+
+ if r.downloadProgress != nil && r.resp.ContentLength > 0 {
+ return r.download(file)
+ }
+
+ defer r.resp.Body.Close()
+ _, err = io.Copy(file, r.resp.Body)
+ return err
+}
+
+func (r *Resp) download(file *os.File) error {
+ p := make([]byte, 1024)
+ b := r.resp.Body
+ defer b.Close()
+ total := r.resp.ContentLength
+ var current int64
+ var lastTime time.Time
+ for {
+ l, err := b.Read(p)
+ if l > 0 {
+ _, _err := file.Write(p[:l])
+ if _err != nil {
+ return _err
+ }
+ current += int64(l)
+ if now := time.Now(); now.Sub(lastTime) > 200*time.Millisecond {
+ lastTime = now
+ r.downloadProgress(current, total)
+ }
+ }
+ if err != nil {
+ if err == io.EOF {
+ return nil
+ }
+ return err
+ }
+ }
+}
+
+var regNewline = regexp.MustCompile(`\n|\r`)
+
+func (r *Resp) autoFormat(s fmt.State) {
+ req := r.req
+ if r.r.flag&Lcost != 0 {
+ fmt.Fprint(s, req.Method, " ", req.URL.String(), " ", r.cost)
+ } else {
+ fmt.Fprint(s, req.Method, " ", req.URL.String())
+ }
+
+ // test if it is should be outputed pretty
+ var pretty bool
+ var parts []string
+ addPart := func(part string) {
+ if part == "" {
+ return
+ }
+ parts = append(parts, part)
+ if !pretty && regNewline.MatchString(part) {
+ pretty = true
+ }
+ }
+ if r.r.flag&LreqBody != 0 { // request body
+ addPart(string(r.reqBody))
+ }
+ if r.r.flag&LrespBody != 0 { // response body
+ addPart(r.String())
+ }
+
+ for _, part := range parts {
+ if pretty {
+ fmt.Fprint(s, "\n")
+ }
+ fmt.Fprint(s, " ", part)
+ }
+}
+
+func (r *Resp) miniFormat(s fmt.State) {
+ req := r.req
+ if r.r.flag&Lcost != 0 {
+ fmt.Fprint(s, req.Method, " ", req.URL.String(), " ", r.cost)
+ } else {
+ fmt.Fprint(s, req.Method, " ", req.URL.String())
+ }
+ if r.r.flag&LreqBody != 0 && len(r.reqBody) > 0 { // request body
+ str := regNewline.ReplaceAllString(string(r.reqBody), " ")
+ fmt.Fprint(s, " ", str)
+ }
+ if r.r.flag&LrespBody != 0 && r.String() != "" { // response body
+ str := regNewline.ReplaceAllString(r.String(), " ")
+ fmt.Fprint(s, " ", str)
+ }
+}
+
+// Format fort the response
+func (r *Resp) Format(s fmt.State, verb rune) {
+ if r == nil || r.req == nil {
+ return
+ }
+ if s.Flag('+') { // include header and format pretty.
+ fmt.Fprint(s, r.Dump())
+ } else if s.Flag('-') { // keep all informations in one line.
+ r.miniFormat(s)
+ } else { // auto
+ r.autoFormat(s)
+ }
+}
diff --git a/backend/vendor/github.com/imroc/req/setting.go b/backend/vendor/github.com/imroc/req/setting.go
new file mode 100644
index 00000000..74235f37
--- /dev/null
+++ b/backend/vendor/github.com/imroc/req/setting.go
@@ -0,0 +1,236 @@
+package req
+
+import (
+ "crypto/tls"
+ "errors"
+ "net"
+ "net/http"
+ "net/http/cookiejar"
+ "net/url"
+ "time"
+)
+
+// create a default client
+func newClient() *http.Client {
+ jar, _ := cookiejar.New(nil)
+ transport := &http.Transport{
+ Proxy: http.ProxyFromEnvironment,
+ DialContext: (&net.Dialer{
+ Timeout: 30 * time.Second,
+ KeepAlive: 30 * time.Second,
+ DualStack: true,
+ }).DialContext,
+ MaxIdleConns: 100,
+ IdleConnTimeout: 90 * time.Second,
+ TLSHandshakeTimeout: 10 * time.Second,
+ ExpectContinueTimeout: 1 * time.Second,
+ }
+ return &http.Client{
+ Jar: jar,
+ Transport: transport,
+ Timeout: 2 * time.Minute,
+ }
+}
+
+// Client return the default underlying http client
+func (r *Req) Client() *http.Client {
+ if r.client == nil {
+ r.client = newClient()
+ }
+ return r.client
+}
+
+// Client return the default underlying http client
+func Client() *http.Client {
+ return std.Client()
+}
+
+// SetClient sets the underlying http.Client.
+func (r *Req) SetClient(client *http.Client) {
+ r.client = client // use default if client == nil
+}
+
+// SetClient sets the default http.Client for requests.
+func SetClient(client *http.Client) {
+ std.SetClient(client)
+}
+
+// SetFlags control display format of *Resp
+func (r *Req) SetFlags(flags int) {
+ r.flag = flags
+}
+
+// SetFlags control display format of *Resp
+func SetFlags(flags int) {
+ std.SetFlags(flags)
+}
+
+// Flags return output format for the *Resp
+func (r *Req) Flags() int {
+ return r.flag
+}
+
+// Flags return output format for the *Resp
+func Flags() int {
+ return std.Flags()
+}
+
+func (r *Req) getTransport() *http.Transport {
+ trans, _ := r.Client().Transport.(*http.Transport)
+ return trans
+}
+
+// EnableInsecureTLS allows insecure https
+func (r *Req) EnableInsecureTLS(enable bool) {
+ trans := r.getTransport()
+ if trans == nil {
+ return
+ }
+ if trans.TLSClientConfig == nil {
+ trans.TLSClientConfig = &tls.Config{}
+ }
+ trans.TLSClientConfig.InsecureSkipVerify = enable
+}
+
+func EnableInsecureTLS(enable bool) {
+ std.EnableInsecureTLS(enable)
+}
+
+// EnableCookieenable or disable cookie manager
+func (r *Req) EnableCookie(enable bool) {
+ if enable {
+ jar, _ := cookiejar.New(nil)
+ r.Client().Jar = jar
+ } else {
+ r.Client().Jar = nil
+ }
+}
+
+// EnableCookieenable or disable cookie manager
+func EnableCookie(enable bool) {
+ std.EnableCookie(enable)
+}
+
+// SetTimeout sets the timeout for every request
+func (r *Req) SetTimeout(d time.Duration) {
+ r.Client().Timeout = d
+}
+
+// SetTimeout sets the timeout for every request
+func SetTimeout(d time.Duration) {
+ std.SetTimeout(d)
+}
+
+// SetProxyUrl set the simple proxy with fixed proxy url
+func (r *Req) SetProxyUrl(rawurl string) error {
+ trans := r.getTransport()
+ if trans == nil {
+ return errors.New("req: no transport")
+ }
+ u, err := url.Parse(rawurl)
+ if err != nil {
+ return err
+ }
+ trans.Proxy = http.ProxyURL(u)
+ return nil
+}
+
+// SetProxyUrl set the simple proxy with fixed proxy url
+func SetProxyUrl(rawurl string) error {
+ return std.SetProxyUrl(rawurl)
+}
+
+// SetProxy sets the proxy for every request
+func (r *Req) SetProxy(proxy func(*http.Request) (*url.URL, error)) error {
+ trans := r.getTransport()
+ if trans == nil {
+ return errors.New("req: no transport")
+ }
+ trans.Proxy = proxy
+ return nil
+}
+
+// SetProxy sets the proxy for every request
+func SetProxy(proxy func(*http.Request) (*url.URL, error)) error {
+ return std.SetProxy(proxy)
+}
+
+type jsonEncOpts struct {
+ indentPrefix string
+ indentValue string
+ escapeHTML bool
+}
+
+func (r *Req) getJSONEncOpts() *jsonEncOpts {
+ if r.jsonEncOpts == nil {
+ r.jsonEncOpts = &jsonEncOpts{escapeHTML: true}
+ }
+ return r.jsonEncOpts
+}
+
+// SetJSONEscapeHTML specifies whether problematic HTML characters
+// should be escaped inside JSON quoted strings.
+// The default behavior is to escape &, <, and > to \u0026, \u003c, and \u003e
+// to avoid certain safety problems that can arise when embedding JSON in HTML.
+//
+// In non-HTML settings where the escaping interferes with the readability
+// of the output, SetEscapeHTML(false) disables this behavior.
+func (r *Req) SetJSONEscapeHTML(escape bool) {
+ opts := r.getJSONEncOpts()
+ opts.escapeHTML = escape
+}
+
+// SetJSONEscapeHTML specifies whether problematic HTML characters
+// should be escaped inside JSON quoted strings.
+// The default behavior is to escape &, <, and > to \u0026, \u003c, and \u003e
+// to avoid certain safety problems that can arise when embedding JSON in HTML.
+//
+// In non-HTML settings where the escaping interferes with the readability
+// of the output, SetEscapeHTML(false) disables this behavior.
+func SetJSONEscapeHTML(escape bool) {
+ std.SetJSONEscapeHTML(escape)
+}
+
+// SetJSONIndent instructs the encoder to format each subsequent encoded
+// value as if indented by the package-level function Indent(dst, src, prefix, indent).
+// Calling SetIndent("", "") disables indentation.
+func (r *Req) SetJSONIndent(prefix, indent string) {
+ opts := r.getJSONEncOpts()
+ opts.indentPrefix = prefix
+ opts.indentValue = indent
+}
+
+// SetJSONIndent instructs the encoder to format each subsequent encoded
+// value as if indented by the package-level function Indent(dst, src, prefix, indent).
+// Calling SetIndent("", "") disables indentation.
+func SetJSONIndent(prefix, indent string) {
+ std.SetJSONIndent(prefix, indent)
+}
+
+type xmlEncOpts struct {
+ prefix string
+ indent string
+}
+
+func (r *Req) getXMLEncOpts() *xmlEncOpts {
+ if r.xmlEncOpts == nil {
+ r.xmlEncOpts = &xmlEncOpts{}
+ }
+ return r.xmlEncOpts
+}
+
+// SetXMLIndent sets the encoder to generate XML in which each element
+// begins on a new indented line that starts with prefix and is followed by
+// one or more copies of indent according to the nesting depth.
+func (r *Req) SetXMLIndent(prefix, indent string) {
+ opts := r.getXMLEncOpts()
+ opts.prefix = prefix
+ opts.indent = indent
+}
+
+// SetXMLIndent sets the encoder to generate XML in which each element
+// begins on a new indented line that starts with prefix and is followed by
+// one or more copies of indent according to the nesting depth.
+func SetXMLIndent(prefix, indent string) {
+ std.SetXMLIndent(prefix, indent)
+}
diff --git a/backend/vendor/github.com/jaytaylor/html2text/.gitignore b/backend/vendor/github.com/jaytaylor/html2text/.gitignore
new file mode 100644
index 00000000..daf913b1
--- /dev/null
+++ b/backend/vendor/github.com/jaytaylor/html2text/.gitignore
@@ -0,0 +1,24 @@
+# Compiled Object files, Static and Dynamic libs (Shared Objects)
+*.o
+*.a
+*.so
+
+# Folders
+_obj
+_test
+
+# Architecture specific extensions/prefixes
+*.[568vq]
+[568vq].out
+
+*.cgo1.go
+*.cgo2.c
+_cgo_defun.c
+_cgo_gotypes.go
+_cgo_export.*
+
+_testmain.go
+
+*.exe
+*.test
+*.prof
diff --git a/backend/vendor/github.com/jaytaylor/html2text/.travis.yml b/backend/vendor/github.com/jaytaylor/html2text/.travis.yml
new file mode 100644
index 00000000..6c7f48ef
--- /dev/null
+++ b/backend/vendor/github.com/jaytaylor/html2text/.travis.yml
@@ -0,0 +1,14 @@
+language: go
+go:
+ - tip
+ - 1.8
+ - 1.7
+ - 1.6
+ - 1.5
+ - 1.4
+ - 1.3
+ - 1.2
+notifications:
+ email:
+ on_success: change
+ on_failure: always
diff --git a/backend/vendor/github.com/jaytaylor/html2text/LICENSE b/backend/vendor/github.com/jaytaylor/html2text/LICENSE
new file mode 100644
index 00000000..24dc4abe
--- /dev/null
+++ b/backend/vendor/github.com/jaytaylor/html2text/LICENSE
@@ -0,0 +1,22 @@
+The MIT License (MIT)
+
+Copyright (c) 2015 Jay Taylor
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
+
diff --git a/backend/vendor/github.com/jaytaylor/html2text/README.md b/backend/vendor/github.com/jaytaylor/html2text/README.md
new file mode 100644
index 00000000..6b2494ee
--- /dev/null
+++ b/backend/vendor/github.com/jaytaylor/html2text/README.md
@@ -0,0 +1,137 @@
+# html2text
+
+[](https://godoc.org/github.com/jaytaylor/html2text)
+[](https://travis-ci.org/jaytaylor/html2text)
+[](https://goreportcard.com/report/github.com/jaytaylor/html2text)
+
+### Converts HTML into text of the markdown-flavored variety
+
+
+## Introduction
+
+Ensure your emails are readable by all!
+
+Turns HTML into raw text, useful for sending fancy HTML emails with an equivalently nicely formatted TXT document as a fallback (e.g. for people who don't allow HTML emails or have other display issues).
+
+html2text is a simple golang package for rendering HTML into plaintext.
+
+There are still lots of improvements to be had, but FWIW this has worked fine for my [basic] HTML-2-text needs.
+
+It requires go 1.x or newer ;)
+
+
+## Download the package
+
+```bash
+go get jaytaylor.com/html2text
+```
+
+## Example usage
+
+```go
+package main
+
+import (
+ "fmt"
+
+ "jaytaylor.com/html2text"
+)
+
+func main() {
+ inputHTML := `
+
+
+ + Here is some more information: + +
| Header 1 | Header 2 |
|---|---|
| Footer 1 | Footer 2 |
| Row 1 Col 1 | Row 1 Col 2 |
| Row 2 Col 1 | Row 2 Col 2 |
{{ $line }}
+ {{ end }} + {{ end }} +{{ end }} +``` + +## Dictionary Injection + +The following will inject a `
+
|
+ |||
{{ $action.Instructions }}
+| + + | +
|
+ {{$.Hermes.Product.TroubleText | replace "{ACTION}" $action.Button.Text}} + + |
+ {{ end }}
+
{{ $line }}
+ {{ end }} + {{ end }} +{{ end }} +``` + +## Signature Injection + +The following will inject the signature phrase (e.g. Yours truly) along with the product name into the e-mail: + +```html +{{.Email.Body.Signature}}, +

 +
+# Usage
+
+First install the package:
+
+```
+go get -u github.com/matcornic/hermes
+```
+
+Then, start using the package by importing and configuring it:
+
+```go
+// Configure hermes by setting a theme and your product info
+h := hermes.Hermes{
+ // Optional Theme
+ // Theme: new(Default)
+ Product: hermes.Product{
+ // Appears in header & footer of e-mails
+ Name: "Hermes",
+ Link: "https://example-hermes.com/",
+ // Optional product logo
+ Logo: "http://www.duchess-france.org/wp-content/uploads/2016/01/gopher.png",
+ },
+}
+```
+
+Next, generate an e-mail using the following code:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Name: "Jon Snow",
+ Intros: []string{
+ "Welcome to Hermes! We're very excited to have you on board.",
+ },
+ Actions: []hermes.Action{
+ {
+ Instructions: "To get started with Hermes, please click here:",
+ Button: hermes.Button{
+ Color: "#22BC66", // Optional action button color
+ Text: "Confirm your account",
+ Link: "https://hermes-example.com/confirm?token=d9729feb74992cc3482b350163a1a010",
+ },
+ },
+ },
+ Outros: []string{
+ "Need help, or have questions? Just reply to this email, we'd love to help.",
+ },
+ },
+}
+
+// Generate an HTML email with the provided contents (for modern clients)
+emailBody, err := h.GenerateHTML(email)
+if err != nil {
+ panic(err) // Tip: Handle error with something else than a panic ;)
+}
+
+// Generate the plaintext version of the e-mail (for clients that do not support xHTML)
+emailText, err := h.GeneratePlainText(email)
+if err != nil {
+ panic(err) // Tip: Handle error with something else than a panic ;)
+}
+
+// Optionally, preview the generated HTML e-mail by writing it to a local file
+err = ioutil.WriteFile("preview.html", []byte(emailBody), 0644)
+if err != nil {
+ panic(err) // Tip: Handle error with something else than a panic ;)
+}
+```
+
+This code would output the following HTML template:
+
+
+
+# Usage
+
+First install the package:
+
+```
+go get -u github.com/matcornic/hermes
+```
+
+Then, start using the package by importing and configuring it:
+
+```go
+// Configure hermes by setting a theme and your product info
+h := hermes.Hermes{
+ // Optional Theme
+ // Theme: new(Default)
+ Product: hermes.Product{
+ // Appears in header & footer of e-mails
+ Name: "Hermes",
+ Link: "https://example-hermes.com/",
+ // Optional product logo
+ Logo: "http://www.duchess-france.org/wp-content/uploads/2016/01/gopher.png",
+ },
+}
+```
+
+Next, generate an e-mail using the following code:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Name: "Jon Snow",
+ Intros: []string{
+ "Welcome to Hermes! We're very excited to have you on board.",
+ },
+ Actions: []hermes.Action{
+ {
+ Instructions: "To get started with Hermes, please click here:",
+ Button: hermes.Button{
+ Color: "#22BC66", // Optional action button color
+ Text: "Confirm your account",
+ Link: "https://hermes-example.com/confirm?token=d9729feb74992cc3482b350163a1a010",
+ },
+ },
+ },
+ Outros: []string{
+ "Need help, or have questions? Just reply to this email, we'd love to help.",
+ },
+ },
+}
+
+// Generate an HTML email with the provided contents (for modern clients)
+emailBody, err := h.GenerateHTML(email)
+if err != nil {
+ panic(err) // Tip: Handle error with something else than a panic ;)
+}
+
+// Generate the plaintext version of the e-mail (for clients that do not support xHTML)
+emailText, err := h.GeneratePlainText(email)
+if err != nil {
+ panic(err) // Tip: Handle error with something else than a panic ;)
+}
+
+// Optionally, preview the generated HTML e-mail by writing it to a local file
+err = ioutil.WriteFile("preview.html", []byte(emailBody), 0644)
+if err != nil {
+ panic(err) // Tip: Handle error with something else than a panic ;)
+}
+```
+
+This code would output the following HTML template:
+
+ +
+And the following plain text:
+
+```
+------------
+Hi Jon Snow,
+------------
+
+Welcome to Hermes! We're very excited to have you on board.
+
+To get started with Hermes, please click here: https://hermes-example.com/confirm?token=d9729feb74992cc3482b350163a1a010
+
+Need help, or have questions? Just reply to this email, we'd love to help.
+
+Yours truly,
+Hermes - https://example-hermes.com/
+
+Copyright © 2017 Hermes. All rights reserved.
+```
+
+> Theme templates will be embedded in your application binary. If you want to use external templates (for configuration), use your own theme by implementing `hermes.Theme` interface with code searching for your files.
+
+## More Examples
+
+* [Welcome](examples/welcome.go)
+* [Receipt](examples/receipt.go)
+* [Password Reset](examples/reset.go)
+* [Maintenance](examples/maintenance.go)
+
+To run the examples, go to `examples` folder, then run `go run *.go`. HTML and Plaintext example should be created in given theme folders.
+
+## Plaintext E-mails
+
+To generate a [plaintext version of the e-mail](https://litmus.com/blog/best-practices-for-plain-text-emails-a-look-at-why-theyre-important), simply call `GeneratePlainText` function:
+
+```go
+// Generate plaintext email using hermes
+emailText, err := h.GeneratePlainText(email)
+if err != nil {
+ panic(err) // Tip: Handle error with something else than a panic ;)
+}
+```
+
+## Supported Themes
+
+The following open-source themes are bundled with this package:
+
+* `default` by [Postmark Transactional Email Templates](https://github.com/wildbit/postmark-templates)
+
+
+
+* `flat`, slightly modified from [Postmark Transactional Email Templates](https://github.com/wildbit/postmark-templates)
+
+
+
+And the following plain text:
+
+```
+------------
+Hi Jon Snow,
+------------
+
+Welcome to Hermes! We're very excited to have you on board.
+
+To get started with Hermes, please click here: https://hermes-example.com/confirm?token=d9729feb74992cc3482b350163a1a010
+
+Need help, or have questions? Just reply to this email, we'd love to help.
+
+Yours truly,
+Hermes - https://example-hermes.com/
+
+Copyright © 2017 Hermes. All rights reserved.
+```
+
+> Theme templates will be embedded in your application binary. If you want to use external templates (for configuration), use your own theme by implementing `hermes.Theme` interface with code searching for your files.
+
+## More Examples
+
+* [Welcome](examples/welcome.go)
+* [Receipt](examples/receipt.go)
+* [Password Reset](examples/reset.go)
+* [Maintenance](examples/maintenance.go)
+
+To run the examples, go to `examples` folder, then run `go run *.go`. HTML and Plaintext example should be created in given theme folders.
+
+## Plaintext E-mails
+
+To generate a [plaintext version of the e-mail](https://litmus.com/blog/best-practices-for-plain-text-emails-a-look-at-why-theyre-important), simply call `GeneratePlainText` function:
+
+```go
+// Generate plaintext email using hermes
+emailText, err := h.GeneratePlainText(email)
+if err != nil {
+ panic(err) // Tip: Handle error with something else than a panic ;)
+}
+```
+
+## Supported Themes
+
+The following open-source themes are bundled with this package:
+
+* `default` by [Postmark Transactional Email Templates](https://github.com/wildbit/postmark-templates)
+
+
+
+* `flat`, slightly modified from [Postmark Transactional Email Templates](https://github.com/wildbit/postmark-templates)
+
+

 +
+## RTL Support
+
+To change the default text direction (left-to-right), simply override it as follows:
+
+```go
+// Configure hermes by setting a theme and your product info
+h := hermes.Hermes {
+ // Custom text direction
+ TextDirection: hermes.TDRightToLeft,
+}
+```
+
+## Language Customizations
+
+To customize the e-mail's greeting ("Hi") or signature ("Yours truly"), supply custom strings within the e-mail's `Body`:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Greeting: "Dear",
+ Signature: "Sincerely",
+ },
+}
+```
+
+To use a custom title string rather than a greeting/name introduction, provide it instead of `Name`:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ // Title will override `Name`
+ Title: "Welcome to Hermes",
+ },
+}
+```
+
+To customize the `Copyright`, override it when initializing `Hermes` within your `Product` as follows:
+
+```go
+// Configure hermes by setting a theme and your product info
+h := hermes.Hermes{
+ // Optional Theme
+ // Theme: new(Default)
+ Product: hermes.Product{
+ // Appears in header & footer of e-mails
+ Name: "Hermes",
+ Link: "https://example-hermes.com/",
+ // Custom copyright notice
+ Copyright: "Copyright © 2017 Dharma Initiative. All rights reserved."
+ },
+}
+```
+
+To use a custom fallback text at the end of the email, change the `TroubleText` field of the `hermes.Product` struct. The default value is `If you’re having trouble with the button '{ACTION}', copy and paste the URL below into your web browser.`. The `{ACTION}` placeholder will be replaced with the corresponding text of the supplied action button:
+
+```go
+// Configure hermes by setting a theme and your product info
+h := hermes.Hermes{
+ // Optional Theme
+ // Theme: new(Default)
+ Product: hermes.Product{
+ // Custom trouble text
+ TroubleText: "If the {ACTION}-button is not working for you, just copy and paste the URL below into your web browser."
+ },
+}
+```
+
+## Elements
+
+Hermes supports injecting custom elements such as dictionaries, tables and action buttons into e-mails.
+
+### Action
+
+To inject an action button in to the e-mail, supply the `Actions` object as follows:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Actions: []hermes.Action{
+ {
+ Instructions: "To get started with Hermes, please click here:",
+ Button: hermes.Button{
+ Color: "#22BC66", // Optional action button color
+ Text: "Confirm your account",
+ Link: "https://hermes-example.com/confirm?token=d9729feb74992cc3482b350163a1a010",
+ },
+ },
+ },
+ },
+}
+```
+
+To inject multiple action buttons in to the e-mail, supply another struct in Actions slice `Action`.
+
+### Table
+
+To inject a table into the e-mail, supply the `Table` object as follows:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Table: hermes.Table{
+ Data: [][]hermes.Entry{
+ // List of rows
+ {
+ // Key is the column name, Value is the cell value
+ // First object defines what columns will be displayed
+ {Key: "Item", Value: "Golang"},
+ {Key: "Description", Value: "Open source programming language that makes it easy to build simple, reliable, and efficient software"},
+ {Key: "Price", Value: "$10.99"},
+ },
+ {
+ {Key: "Item", Value: "Hermes"},
+ {Key: "Description", Value: "Programmatically create beautiful e-mails using Golang."},
+ {Key: "Price", Value: "$1.99"},
+ },
+ },
+ Columns: hermes.Columns{
+ // Custom style for each rows
+ CustomWidth: map[string]string{
+ "Item": "20%",
+ "Price": "15%",
+ },
+ CustomAlignment: map[string]string{
+ "Price": "right",
+ },
+ },
+ },
+ },
+}
+```
+
+### Dictionary
+
+To inject key-value pairs of data into the e-mail, supply the `Dictionary` object as follows:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Dictionary: []hermes.Entry{
+ {Key: "Date", Value: "20 November 1887"},
+ {Key: "Address", Value: "221B Baker Street, London"},
+ },
+ },
+}
+```
+
+### Free Markdown
+
+If you need more flexibility in the content of your generated e-mail, while keeping the same format than any other e-mail, use Markdown content. Supply the `FreeMarkdown` object as follows:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ FreeMarkdown: `
+> _Hermes_ service will shutdown the **1st August 2017** for maintenance operations.
+
+Services will be unavailable based on the following schedule:
+
+| Services | Downtime |
+| :------:| :-----------: |
+| Service A | 2AM to 3AM |
+| Service B | 4AM to 5AM |
+| Service C | 5AM to 6AM |
+
+---
+
+Feel free to contact us for any question regarding this matter at [support@hermes-example.com](mailto:support@hermes-example.com) or in our [Gitter](https://gitter.im/)
+
+`,
+ },
+ }
+}
+```
+
+This code would output the following HTML template:
+
+
+
+## RTL Support
+
+To change the default text direction (left-to-right), simply override it as follows:
+
+```go
+// Configure hermes by setting a theme and your product info
+h := hermes.Hermes {
+ // Custom text direction
+ TextDirection: hermes.TDRightToLeft,
+}
+```
+
+## Language Customizations
+
+To customize the e-mail's greeting ("Hi") or signature ("Yours truly"), supply custom strings within the e-mail's `Body`:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Greeting: "Dear",
+ Signature: "Sincerely",
+ },
+}
+```
+
+To use a custom title string rather than a greeting/name introduction, provide it instead of `Name`:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ // Title will override `Name`
+ Title: "Welcome to Hermes",
+ },
+}
+```
+
+To customize the `Copyright`, override it when initializing `Hermes` within your `Product` as follows:
+
+```go
+// Configure hermes by setting a theme and your product info
+h := hermes.Hermes{
+ // Optional Theme
+ // Theme: new(Default)
+ Product: hermes.Product{
+ // Appears in header & footer of e-mails
+ Name: "Hermes",
+ Link: "https://example-hermes.com/",
+ // Custom copyright notice
+ Copyright: "Copyright © 2017 Dharma Initiative. All rights reserved."
+ },
+}
+```
+
+To use a custom fallback text at the end of the email, change the `TroubleText` field of the `hermes.Product` struct. The default value is `If you’re having trouble with the button '{ACTION}', copy and paste the URL below into your web browser.`. The `{ACTION}` placeholder will be replaced with the corresponding text of the supplied action button:
+
+```go
+// Configure hermes by setting a theme and your product info
+h := hermes.Hermes{
+ // Optional Theme
+ // Theme: new(Default)
+ Product: hermes.Product{
+ // Custom trouble text
+ TroubleText: "If the {ACTION}-button is not working for you, just copy and paste the URL below into your web browser."
+ },
+}
+```
+
+## Elements
+
+Hermes supports injecting custom elements such as dictionaries, tables and action buttons into e-mails.
+
+### Action
+
+To inject an action button in to the e-mail, supply the `Actions` object as follows:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Actions: []hermes.Action{
+ {
+ Instructions: "To get started with Hermes, please click here:",
+ Button: hermes.Button{
+ Color: "#22BC66", // Optional action button color
+ Text: "Confirm your account",
+ Link: "https://hermes-example.com/confirm?token=d9729feb74992cc3482b350163a1a010",
+ },
+ },
+ },
+ },
+}
+```
+
+To inject multiple action buttons in to the e-mail, supply another struct in Actions slice `Action`.
+
+### Table
+
+To inject a table into the e-mail, supply the `Table` object as follows:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Table: hermes.Table{
+ Data: [][]hermes.Entry{
+ // List of rows
+ {
+ // Key is the column name, Value is the cell value
+ // First object defines what columns will be displayed
+ {Key: "Item", Value: "Golang"},
+ {Key: "Description", Value: "Open source programming language that makes it easy to build simple, reliable, and efficient software"},
+ {Key: "Price", Value: "$10.99"},
+ },
+ {
+ {Key: "Item", Value: "Hermes"},
+ {Key: "Description", Value: "Programmatically create beautiful e-mails using Golang."},
+ {Key: "Price", Value: "$1.99"},
+ },
+ },
+ Columns: hermes.Columns{
+ // Custom style for each rows
+ CustomWidth: map[string]string{
+ "Item": "20%",
+ "Price": "15%",
+ },
+ CustomAlignment: map[string]string{
+ "Price": "right",
+ },
+ },
+ },
+ },
+}
+```
+
+### Dictionary
+
+To inject key-value pairs of data into the e-mail, supply the `Dictionary` object as follows:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ Dictionary: []hermes.Entry{
+ {Key: "Date", Value: "20 November 1887"},
+ {Key: "Address", Value: "221B Baker Street, London"},
+ },
+ },
+}
+```
+
+### Free Markdown
+
+If you need more flexibility in the content of your generated e-mail, while keeping the same format than any other e-mail, use Markdown content. Supply the `FreeMarkdown` object as follows:
+
+```go
+email := hermes.Email{
+ Body: hermes.Body{
+ FreeMarkdown: `
+> _Hermes_ service will shutdown the **1st August 2017** for maintenance operations.
+
+Services will be unavailable based on the following schedule:
+
+| Services | Downtime |
+| :------:| :-----------: |
+| Service A | 2AM to 3AM |
+| Service B | 4AM to 5AM |
+| Service C | 5AM to 6AM |
+
+---
+
+Feel free to contact us for any question regarding this matter at [support@hermes-example.com](mailto:support@hermes-example.com) or in our [Gitter](https://gitter.im/)
+
+`,
+ },
+ }
+}
+```
+
+This code would output the following HTML template:
+
+ +
+And the following plaintext:
+
+```
+------------
+Hi Jon Snow,
+------------
+
+>
+>
+>
+> Hermes service will shutdown the *1st August 2017* for maintenance
+> operations.
+>
+>
+
+Services will be unavailable based on the following schedule:
+
++-----------+------------+
+| SERVICES | DOWNTIME |
++-----------+------------+
+| Service A | 2AM to 3AM |
+| Service B | 4AM to 5AM |
+| Service C | 5AM to 6AM |
++-----------+------------+
+
+Feel free to contact us for any question regarding this matter at support@hermes-example.com ( support@hermes-example.com ) or in our Gitter ( https://gitter.im/ )
+
+Yours truly,
+Hermes - https://example-hermes.com/
+
+Copyright © 2017 Hermes. All rights reserved.
+```
+
+Be aware that this content will replace existing tables, dictionary and actions. Only intros, outros, header and footer will be kept.
+
+This is helpful when your application needs sending e-mails, wrote on-the-fly by adminstrators.
+
+> Markdown is rendered with [Blackfriday](https://github.com/russross/blackfriday), so every thing Blackfriday can do, Hermes can do it as well.
+
+## Troubleshooting
+
+1. After sending multiple e-mails to the same Gmail / Inbox address, they become grouped and truncated since they contain similar text, breaking the responsive e-mail layout.
+
+> Simply sending the `X-Entity-Ref-ID` header with your e-mails will prevent grouping / truncation.
+
+## Contributing
+
+See [CONTRIBUTING.md](CONTRIBUTING.md)
+
+## License
+
+Apache 2.0
+
diff --git a/backend/vendor/github.com/matcornic/hermes/default.go b/backend/vendor/github.com/matcornic/hermes/default.go
new file mode 100644
index 00000000..b8e2e941
--- /dev/null
+++ b/backend/vendor/github.com/matcornic/hermes/default.go
@@ -0,0 +1,495 @@
+package hermes
+
+// Default is the theme by default
+type Default struct{}
+
+// Name returns the name of the default theme
+func (dt *Default) Name() string {
+ return "default"
+}
+
+// HTMLTemplate returns a Golang template that will generate an HTML email.
+func (dt *Default) HTMLTemplate() string {
+ return `
+
+
+
+
+
+
+
+
+
+
+And the following plaintext:
+
+```
+------------
+Hi Jon Snow,
+------------
+
+>
+>
+>
+> Hermes service will shutdown the *1st August 2017* for maintenance
+> operations.
+>
+>
+
+Services will be unavailable based on the following schedule:
+
++-----------+------------+
+| SERVICES | DOWNTIME |
++-----------+------------+
+| Service A | 2AM to 3AM |
+| Service B | 4AM to 5AM |
+| Service C | 5AM to 6AM |
++-----------+------------+
+
+Feel free to contact us for any question regarding this matter at support@hermes-example.com ( support@hermes-example.com ) or in our Gitter ( https://gitter.im/ )
+
+Yours truly,
+Hermes - https://example-hermes.com/
+
+Copyright © 2017 Hermes. All rights reserved.
+```
+
+Be aware that this content will replace existing tables, dictionary and actions. Only intros, outros, header and footer will be kept.
+
+This is helpful when your application needs sending e-mails, wrote on-the-fly by adminstrators.
+
+> Markdown is rendered with [Blackfriday](https://github.com/russross/blackfriday), so every thing Blackfriday can do, Hermes can do it as well.
+
+## Troubleshooting
+
+1. After sending multiple e-mails to the same Gmail / Inbox address, they become grouped and truncated since they contain similar text, breaking the responsive e-mail layout.
+
+> Simply sending the `X-Entity-Ref-ID` header with your e-mails will prevent grouping / truncation.
+
+## Contributing
+
+See [CONTRIBUTING.md](CONTRIBUTING.md)
+
+## License
+
+Apache 2.0
+
diff --git a/backend/vendor/github.com/matcornic/hermes/default.go b/backend/vendor/github.com/matcornic/hermes/default.go
new file mode 100644
index 00000000..b8e2e941
--- /dev/null
+++ b/backend/vendor/github.com/matcornic/hermes/default.go
@@ -0,0 +1,495 @@
+package hermes
+
+// Default is the theme by default
+type Default struct{}
+
+// Name returns the name of the default theme
+func (dt *Default) Name() string {
+ return "default"
+}
+
+// HTMLTemplate returns a Golang template that will generate an HTML email.
+func (dt *Default) HTMLTemplate() string {
+ return `
+
+
+
+
+
+
+
+
+
+
|
+ |||||||||||
{{ $line }}
+ {{ end }} +{{ end }} +{{ if (ne .Email.Body.FreeMarkdown "") }} + {{ .Email.Body.FreeMarkdown.ToHTML }} +{{ else }} + {{ with .Email.Body.Dictionary }} +| {{ $entry.Key }} | + {{ end }} +
|---|
| + {{ $cell.Value }} + | + {{ end }} +
{{ $action.Instructions }} {{ $action.Button.Link }}
+ {{ end }} + {{ end }} +{{ end }} +{{ with .Email.Body.Outros }} + {{ range $line := . }} +{{ $line }}
+ {{ end }} +{{ end }} +
{{.Email.Body.Signature}},
{{.Hermes.Product.Name}} - {{.Hermes.Product.Link}}
{{.Hermes.Product.Copyright}}
+` +} diff --git a/backend/vendor/github.com/matcornic/hermes/flat.go b/backend/vendor/github.com/matcornic/hermes/flat.go new file mode 100644 index 00000000..955a5686 --- /dev/null +++ b/backend/vendor/github.com/matcornic/hermes/flat.go @@ -0,0 +1,495 @@ +package hermes + +// Flat is a theme +type Flat struct{} + +// Name returns the name of the flat theme +func (dt *Flat) Name() string { + return "flat" +} + +// HTMLTemplate returns a Golang template that will generate an HTML email. +func (dt *Flat) HTMLTemplate() string { + return ` + + + + + + + + +
+
|
+ |||||||||||
{{ $line }}
+ {{ end }} +{{ end }} +{{ if (ne .Email.Body.FreeMarkdown "") }} + {{ .Email.Body.FreeMarkdown.ToHTML }} +{{ else }} + {{ with .Email.Body.Dictionary }} +| {{ $entry.Key }} | + {{ end }} +
|---|
| + {{ $cell.Value }} + | + {{ end }} +
{{ $action.Instructions }} {{ $action.Button.Link }}
+ {{ end }} + {{ end }} +{{ end }} +{{ with .Email.Body.Outros }} + {{ range $line := . }} +{{ $line }}
+ {{ end }} +{{ end }} +
{{.Email.Body.Signature}},
{{.Hermes.Product.Name}} - {{.Hermes.Product.Link}}
{{.Hermes.Product.Copyright}}
+` +} diff --git a/backend/vendor/github.com/matcornic/hermes/gometalinter.json b/backend/vendor/github.com/matcornic/hermes/gometalinter.json new file mode 100644 index 00000000..80d6aaf2 --- /dev/null +++ b/backend/vendor/github.com/matcornic/hermes/gometalinter.json @@ -0,0 +1,17 @@ +{ + "DisableAll": true, + "Enable": [ + "unused", + "vet", + "vetshadow", + "deadcode", + "gofmt", + "golint", + "ineffassign", + "goconst", + "gosimple", + "staticcheck", + "misspell" + ], + "Test": true +} \ No newline at end of file diff --git a/backend/vendor/github.com/matcornic/hermes/hermes.go b/backend/vendor/github.com/matcornic/hermes/hermes.go new file mode 100644 index 00000000..6848ef49 --- /dev/null +++ b/backend/vendor/github.com/matcornic/hermes/hermes.go @@ -0,0 +1,200 @@ +package hermes + +import ( + "bytes" + "github.com/Masterminds/sprig" + "github.com/imdario/mergo" + "github.com/jaytaylor/html2text" + "gopkg.in/russross/blackfriday.v2" + "html/template" +) + +// Hermes is an instance of the hermes email generator +type Hermes struct { + Theme Theme + TextDirection TextDirection + Product Product +} + +// Theme is an interface to implement when creating a new theme +type Theme interface { + Name() string // The name of the theme + HTMLTemplate() string // The golang template for HTML emails + PlainTextTemplate() string // The golang templte for plain text emails (can be basic HTML) +} + +// TextDirection of the text in HTML email +type TextDirection string + +var templateFuncs = template.FuncMap{ + "url": func(s string) template.URL { + return template.URL(s) + }, +} + +// TDLeftToRight is the text direction from left to right (default) +const TDLeftToRight TextDirection = "ltr" + +// TDRightToLeft is the text direction from right to left +const TDRightToLeft TextDirection = "rtl" + +// Product represents your company product (brand) +// Appears in header & footer of e-mails +type Product struct { + Name string + Link string // e.g. https://matcornic.github.io + Logo string // e.g. https://matcornic.github.io/img/logo.png + Copyright string // Copyright © 2017 Hermes. All rights reserved. + TroubleText string // TroubleText is the sentence at the end of the email for users having trouble with the button (default to `If you’re having trouble with the button '{ACTION}', copy and paste the URL below into your web browser.`) +} + +// Email is the email containing a body +type Email struct { + Body Body +} + +// Markdown is a HTML template (a string) representing Markdown content +// https://en.wikipedia.org/wiki/Markdown +type Markdown template.HTML + +// Body is the body of the email, containing all interesting data +type Body struct { + Name string // The name of the contacted person + Intros []string // Intro sentences, first displayed in the email + Dictionary []Entry // A list of key+value (useful for displaying parameters/settings/personal info) + Table Table // Table is an table where you can put data (pricing grid, a bill, and so on) + Actions []Action // Actions are a list of actions that the user will be able to execute via a button click + Outros []string // Outro sentences, last displayed in the email + Greeting string // Greeting for the contacted person (default to 'Hi') + Signature string // Signature for the contacted person (default to 'Yours truly') + Title string // Title replaces the greeting+name when set + FreeMarkdown Markdown // Free markdown content that replaces all content other than header and footer +} + +// ToHTML converts Markdown to HTML +func (c Markdown) ToHTML() template.HTML { + return template.HTML(blackfriday.Run([]byte(string(c)))) +} + +// Entry is a simple entry of a map +// Allows using a slice of entries instead of a map +// Because Golang maps are not ordered +type Entry struct { + Key string + Value string +} + +// Table is an table where you can put data (pricing grid, a bill, and so on) +type Table struct { + Data [][]Entry // Contains data + Columns Columns // Contains meta-data for display purpose (width, alignement) +} + +// Columns contains meta-data for the different columns +type Columns struct { + CustomWidth map[string]string + CustomAlignment map[string]string +} + +// Action is an action the user can do on the email (click on a button) +type Action struct { + Instructions string + Button Button +} + +// Button defines an action to launch +type Button struct { + Color string + TextColor string + Text string + Link string +} + +// Template is the struct given to Golang templating +// Root object in a template is this struct +type Template struct { + Hermes Hermes + Email Email +} + +func setDefaultEmailValues(e *Email) error { + // Default values of an email + defaultEmail := Email{ + Body: Body{ + Intros: []string{}, + Dictionary: []Entry{}, + Outros: []string{}, + Signature: "Yours truly", + Greeting: "Hi", + }, + } + // Merge the given email with default one + // Default one overrides all zero values + return mergo.Merge(e, defaultEmail) +} + +// default values of the engine +func setDefaultHermesValues(h *Hermes) error { + defaultTextDirection := TDLeftToRight + defaultHermes := Hermes{ + Theme: new(Default), + TextDirection: defaultTextDirection, + Product: Product{ + Name: "Hermes", + Copyright: "Copyright © 2017 Hermes. All rights reserved.", + TroubleText: "If you’re having trouble with the button '{ACTION}', copy and paste the URL below into your web browser.", + }, + } + // Merge the given hermes engine configuration with default one + // Default one overrides all zero values + err := mergo.Merge(h, defaultHermes) + if err != nil { + return err + } + if h.TextDirection != TDLeftToRight && h.TextDirection != TDRightToLeft { + h.TextDirection = defaultTextDirection + } + return nil +} + +// GenerateHTML generates the email body from data to an HTML Reader +// This is for modern email clients +func (h *Hermes) GenerateHTML(email Email) (string, error) { + err := setDefaultHermesValues(h) + if err != nil { + return "", err + } + return h.generateTemplate(email, h.Theme.HTMLTemplate()) +} + +// GeneratePlainText generates the email body from data +// This is for old email clients +func (h *Hermes) GeneratePlainText(email Email) (string, error) { + err := setDefaultHermesValues(h) + if err != nil { + return "", err + } + template, err := h.generateTemplate(email, h.Theme.PlainTextTemplate()) + if err != nil { + return "", err + } + return html2text.FromString(template, html2text.Options{PrettyTables: true}) +} + +func (h *Hermes) generateTemplate(email Email, tplt string) (string, error) { + + err := setDefaultEmailValues(&email) + if err != nil { + return "", err + } + + // Generate the email from Golang template + // Allow usage of simple function from sprig : https://github.com/Masterminds/sprig + t, err := template.New("hermes").Funcs(sprig.FuncMap()).Funcs(templateFuncs).Parse(tplt) + if err != nil { + return "", err + } + var b bytes.Buffer + t.Execute(&b, Template{*h, email}) + return b.String(), nil +} diff --git a/backend/vendor/github.com/mattn/go-runewidth/.travis.yml b/backend/vendor/github.com/mattn/go-runewidth/.travis.yml new file mode 100644 index 00000000..5c9c2a30 --- /dev/null +++ b/backend/vendor/github.com/mattn/go-runewidth/.travis.yml @@ -0,0 +1,8 @@ +language: go +go: + - tip +before_install: + - go get github.com/mattn/goveralls + - go get golang.org/x/tools/cmd/cover +script: + - $HOME/gopath/bin/goveralls -repotoken lAKAWPzcGsD3A8yBX3BGGtRUdJ6CaGERL diff --git a/backend/vendor/github.com/mattn/go-runewidth/LICENSE b/backend/vendor/github.com/mattn/go-runewidth/LICENSE new file mode 100644 index 00000000..91b5cef3 --- /dev/null +++ b/backend/vendor/github.com/mattn/go-runewidth/LICENSE @@ -0,0 +1,21 @@ +The MIT License (MIT) + +Copyright (c) 2016 Yasuhiro Matsumoto + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. diff --git a/backend/vendor/github.com/mattn/go-runewidth/README.mkd b/backend/vendor/github.com/mattn/go-runewidth/README.mkd new file mode 100644 index 00000000..66663a94 --- /dev/null +++ b/backend/vendor/github.com/mattn/go-runewidth/README.mkd @@ -0,0 +1,27 @@ +go-runewidth +============ + +[](https://travis-ci.org/mattn/go-runewidth) +[](https://coveralls.io/r/mattn/go-runewidth?branch=HEAD) +[](http://godoc.org/github.com/mattn/go-runewidth) +[](https://goreportcard.com/report/github.com/mattn/go-runewidth) + +Provides functions to get fixed width of the character or string. + +Usage +----- + +```go +runewidth.StringWidth("つのだ☆HIRO") == 12 +``` + + +Author +------ + +Yasuhiro Matsumoto + +License +------- + +under the MIT License: http://mattn.mit-license.org/2013 diff --git a/backend/vendor/github.com/mattn/go-runewidth/runewidth.go b/backend/vendor/github.com/mattn/go-runewidth/runewidth.go new file mode 100644 index 00000000..82568a1b --- /dev/null +++ b/backend/vendor/github.com/mattn/go-runewidth/runewidth.go @@ -0,0 +1,1235 @@ +package runewidth + +import "os" + +var ( + // EastAsianWidth will be set true if the current locale is CJK + EastAsianWidth bool + + // DefaultCondition is a condition in current locale + DefaultCondition = &Condition{EastAsianWidth} +) + +func init() { + env := os.Getenv("RUNEWIDTH_EASTASIAN") + if env == "" { + EastAsianWidth = IsEastAsian() + } else { + EastAsianWidth = env == "1" + } +} + +type interval struct { + first rune + last rune +} + +type table []interval + +func inTables(r rune, ts ...table) bool { + for _, t := range ts { + if inTable(r, t) { + return true + } + } + return false +} + +func inTable(r rune, t table) bool { + // func (t table) IncludesRune(r rune) bool { + if r < t[0].first { + return false + } + + bot := 0 + top := len(t) - 1 + for top >= bot { + mid := (bot + top) / 2 + + switch { + case t[mid].last < r: + bot = mid + 1 + case t[mid].first > r: + top = mid - 1 + default: + return true + } + } + + return false +} + +var private = table{ + {0x00E000, 0x00F8FF}, {0x0F0000, 0x0FFFFD}, {0x100000, 0x10FFFD}, +} + +var nonprint = table{ + {0x0000, 0x001F}, {0x007F, 0x009F}, {0x00AD, 0x00AD}, + {0x070F, 0x070F}, {0x180B, 0x180E}, {0x200B, 0x200F}, + {0x2028, 0x2029}, + {0x202A, 0x202E}, {0x206A, 0x206F}, {0xD800, 0xDFFF}, + {0xFEFF, 0xFEFF}, {0xFFF9, 0xFFFB}, {0xFFFE, 0xFFFF}, +} + +var combining = table{ + {0x0300, 0x036F}, {0x0483, 0x0489}, {0x0591, 0x05BD}, + {0x05BF, 0x05BF}, {0x05C1, 0x05C2}, {0x05C4, 0x05C5}, + {0x05C7, 0x05C7}, {0x0610, 0x061A}, {0x064B, 0x065F}, + {0x0670, 0x0670}, {0x06D6, 0x06DC}, {0x06DF, 0x06E4}, + {0x06E7, 0x06E8}, {0x06EA, 0x06ED}, {0x0711, 0x0711}, + {0x0730, 0x074A}, {0x07A6, 0x07B0}, {0x07EB, 0x07F3}, + {0x0816, 0x0819}, {0x081B, 0x0823}, {0x0825, 0x0827}, + {0x0829, 0x082D}, {0x0859, 0x085B}, {0x08D4, 0x08E1}, + {0x08E3, 0x0903}, {0x093A, 0x093C}, {0x093E, 0x094F}, + {0x0951, 0x0957}, {0x0962, 0x0963}, {0x0981, 0x0983}, + {0x09BC, 0x09BC}, {0x09BE, 0x09C4}, {0x09C7, 0x09C8}, + {0x09CB, 0x09CD}, {0x09D7, 0x09D7}, {0x09E2, 0x09E3}, + {0x0A01, 0x0A03}, {0x0A3C, 0x0A3C}, {0x0A3E, 0x0A42}, + {0x0A47, 0x0A48}, {0x0A4B, 0x0A4D}, {0x0A51, 0x0A51}, + {0x0A70, 0x0A71}, {0x0A75, 0x0A75}, {0x0A81, 0x0A83}, + {0x0ABC, 0x0ABC}, {0x0ABE, 0x0AC5}, {0x0AC7, 0x0AC9}, + {0x0ACB, 0x0ACD}, {0x0AE2, 0x0AE3}, {0x0B01, 0x0B03}, + {0x0B3C, 0x0B3C}, {0x0B3E, 0x0B44}, {0x0B47, 0x0B48}, + {0x0B4B, 0x0B4D}, {0x0B56, 0x0B57}, {0x0B62, 0x0B63}, + {0x0B82, 0x0B82}, {0x0BBE, 0x0BC2}, {0x0BC6, 0x0BC8}, + {0x0BCA, 0x0BCD}, {0x0BD7, 0x0BD7}, {0x0C00, 0x0C03}, + {0x0C3E, 0x0C44}, {0x0C46, 0x0C48}, {0x0C4A, 0x0C4D}, + {0x0C55, 0x0C56}, {0x0C62, 0x0C63}, {0x0C81, 0x0C83}, + {0x0CBC, 0x0CBC}, {0x0CBE, 0x0CC4}, {0x0CC6, 0x0CC8}, + {0x0CCA, 0x0CCD}, {0x0CD5, 0x0CD6}, {0x0CE2, 0x0CE3}, + {0x0D01, 0x0D03}, {0x0D3E, 0x0D44}, {0x0D46, 0x0D48}, + {0x0D4A, 0x0D4D}, {0x0D57, 0x0D57}, {0x0D62, 0x0D63}, + {0x0D82, 0x0D83}, {0x0DCA, 0x0DCA}, {0x0DCF, 0x0DD4}, + {0x0DD6, 0x0DD6}, {0x0DD8, 0x0DDF}, {0x0DF2, 0x0DF3}, + {0x0E31, 0x0E31}, {0x0E34, 0x0E3A}, {0x0E47, 0x0E4E}, + {0x0EB1, 0x0EB1}, {0x0EB4, 0x0EB9}, {0x0EBB, 0x0EBC}, + {0x0EC8, 0x0ECD}, {0x0F18, 0x0F19}, {0x0F35, 0x0F35}, + {0x0F37, 0x0F37}, {0x0F39, 0x0F39}, {0x0F3E, 0x0F3F}, + {0x0F71, 0x0F84}, {0x0F86, 0x0F87}, {0x0F8D, 0x0F97}, + {0x0F99, 0x0FBC}, {0x0FC6, 0x0FC6}, {0x102B, 0x103E}, + {0x1056, 0x1059}, {0x105E, 0x1060}, {0x1062, 0x1064}, + {0x1067, 0x106D}, {0x1071, 0x1074}, {0x1082, 0x108D}, + {0x108F, 0x108F}, {0x109A, 0x109D}, {0x135D, 0x135F}, + {0x1712, 0x1714}, {0x1732, 0x1734}, {0x1752, 0x1753}, + {0x1772, 0x1773}, {0x17B4, 0x17D3}, {0x17DD, 0x17DD}, + {0x180B, 0x180D}, {0x1885, 0x1886}, {0x18A9, 0x18A9}, + {0x1920, 0x192B}, {0x1930, 0x193B}, {0x1A17, 0x1A1B}, + {0x1A55, 0x1A5E}, {0x1A60, 0x1A7C}, {0x1A7F, 0x1A7F}, + {0x1AB0, 0x1ABE}, {0x1B00, 0x1B04}, {0x1B34, 0x1B44}, + {0x1B6B, 0x1B73}, {0x1B80, 0x1B82}, {0x1BA1, 0x1BAD}, + {0x1BE6, 0x1BF3}, {0x1C24, 0x1C37}, {0x1CD0, 0x1CD2}, + {0x1CD4, 0x1CE8}, {0x1CED, 0x1CED}, {0x1CF2, 0x1CF4}, + {0x1CF8, 0x1CF9}, {0x1DC0, 0x1DF5}, {0x1DFB, 0x1DFF}, + {0x20D0, 0x20F0}, {0x2CEF, 0x2CF1}, {0x2D7F, 0x2D7F}, + {0x2DE0, 0x2DFF}, {0x302A, 0x302F}, {0x3099, 0x309A}, + {0xA66F, 0xA672}, {0xA674, 0xA67D}, {0xA69E, 0xA69F}, + {0xA6F0, 0xA6F1}, {0xA802, 0xA802}, {0xA806, 0xA806}, + {0xA80B, 0xA80B}, {0xA823, 0xA827}, {0xA880, 0xA881}, + {0xA8B4, 0xA8C5}, {0xA8E0, 0xA8F1}, {0xA926, 0xA92D}, + {0xA947, 0xA953}, {0xA980, 0xA983}, {0xA9B3, 0xA9C0}, + {0xA9E5, 0xA9E5}, {0xAA29, 0xAA36}, {0xAA43, 0xAA43}, + {0xAA4C, 0xAA4D}, {0xAA7B, 0xAA7D}, {0xAAB0, 0xAAB0}, + {0xAAB2, 0xAAB4}, {0xAAB7, 0xAAB8}, {0xAABE, 0xAABF}, + {0xAAC1, 0xAAC1}, {0xAAEB, 0xAAEF}, {0xAAF5, 0xAAF6}, + {0xABE3, 0xABEA}, {0xABEC, 0xABED}, {0xFB1E, 0xFB1E}, + {0xFE00, 0xFE0F}, {0xFE20, 0xFE2F}, {0x101FD, 0x101FD}, + {0x102E0, 0x102E0}, {0x10376, 0x1037A}, {0x10A01, 0x10A03}, + {0x10A05, 0x10A06}, {0x10A0C, 0x10A0F}, {0x10A38, 0x10A3A}, + {0x10A3F, 0x10A3F}, {0x10AE5, 0x10AE6}, {0x11000, 0x11002}, + {0x11038, 0x11046}, {0x1107F, 0x11082}, {0x110B0, 0x110BA}, + {0x11100, 0x11102}, {0x11127, 0x11134}, {0x11173, 0x11173}, + {0x11180, 0x11182}, {0x111B3, 0x111C0}, {0x111CA, 0x111CC}, + {0x1122C, 0x11237}, {0x1123E, 0x1123E}, {0x112DF, 0x112EA}, + {0x11300, 0x11303}, {0x1133C, 0x1133C}, {0x1133E, 0x11344}, + {0x11347, 0x11348}, {0x1134B, 0x1134D}, {0x11357, 0x11357}, + {0x11362, 0x11363}, {0x11366, 0x1136C}, {0x11370, 0x11374}, + {0x11435, 0x11446}, {0x114B0, 0x114C3}, {0x115AF, 0x115B5}, + {0x115B8, 0x115C0}, {0x115DC, 0x115DD}, {0x11630, 0x11640}, + {0x116AB, 0x116B7}, {0x1171D, 0x1172B}, {0x11C2F, 0x11C36}, + {0x11C38, 0x11C3F}, {0x11C92, 0x11CA7}, {0x11CA9, 0x11CB6}, + {0x16AF0, 0x16AF4}, {0x16B30, 0x16B36}, {0x16F51, 0x16F7E}, + {0x16F8F, 0x16F92}, {0x1BC9D, 0x1BC9E}, {0x1D165, 0x1D169}, + {0x1D16D, 0x1D172}, {0x1D17B, 0x1D182}, {0x1D185, 0x1D18B}, + {0x1D1AA, 0x1D1AD}, {0x1D242, 0x1D244}, {0x1DA00, 0x1DA36}, + {0x1DA3B, 0x1DA6C}, {0x1DA75, 0x1DA75}, {0x1DA84, 0x1DA84}, + {0x1DA9B, 0x1DA9F}, {0x1DAA1, 0x1DAAF}, {0x1E000, 0x1E006}, + {0x1E008, 0x1E018}, {0x1E01B, 0x1E021}, {0x1E023, 0x1E024}, + {0x1E026, 0x1E02A}, {0x1E8D0, 0x1E8D6}, {0x1E944, 0x1E94A}, + {0xE0100, 0xE01EF}, +} + +var doublewidth = table{ + {0x1100, 0x115F}, {0x231A, 0x231B}, {0x2329, 0x232A}, + {0x23E9, 0x23EC}, {0x23F0, 0x23F0}, {0x23F3, 0x23F3}, + {0x25FD, 0x25FE}, {0x2614, 0x2615}, {0x2648, 0x2653}, + {0x267F, 0x267F}, {0x2693, 0x2693}, {0x26A1, 0x26A1}, + {0x26AA, 0x26AB}, {0x26BD, 0x26BE}, {0x26C4, 0x26C5}, + {0x26CE, 0x26CE}, {0x26D4, 0x26D4}, {0x26EA, 0x26EA}, + {0x26F2, 0x26F3}, {0x26F5, 0x26F5}, {0x26FA, 0x26FA}, + {0x26FD, 0x26FD}, {0x2705, 0x2705}, {0x270A, 0x270B}, + {0x2728, 0x2728}, {0x274C, 0x274C}, {0x274E, 0x274E}, + {0x2753, 0x2755}, {0x2757, 0x2757}, {0x2795, 0x2797}, + {0x27B0, 0x27B0}, {0x27BF, 0x27BF}, {0x2B1B, 0x2B1C}, + {0x2B50, 0x2B50}, {0x2B55, 0x2B55}, {0x2E80, 0x2E99}, + {0x2E9B, 0x2EF3}, {0x2F00, 0x2FD5}, {0x2FF0, 0x2FFB}, + {0x3000, 0x303E}, {0x3041, 0x3096}, {0x3099, 0x30FF}, + {0x3105, 0x312D}, {0x3131, 0x318E}, {0x3190, 0x31BA}, + {0x31C0, 0x31E3}, {0x31F0, 0x321E}, {0x3220, 0x3247}, + {0x3250, 0x32FE}, {0x3300, 0x4DBF}, {0x4E00, 0xA48C}, + {0xA490, 0xA4C6}, {0xA960, 0xA97C}, {0xAC00, 0xD7A3}, + {0xF900, 0xFAFF}, {0xFE10, 0xFE19}, {0xFE30, 0xFE52}, + {0xFE54, 0xFE66}, {0xFE68, 0xFE6B}, {0xFF01, 0xFF60}, + {0xFFE0, 0xFFE6}, {0x16FE0, 0x16FE0}, {0x17000, 0x187EC}, + {0x18800, 0x18AF2}, {0x1B000, 0x1B001}, {0x1F004, 0x1F004}, + {0x1F0CF, 0x1F0CF}, {0x1F18E, 0x1F18E}, {0x1F191, 0x1F19A}, + {0x1F200, 0x1F202}, {0x1F210, 0x1F23B}, {0x1F240, 0x1F248}, + {0x1F250, 0x1F251}, {0x1F300, 0x1F320}, {0x1F32D, 0x1F335}, + {0x1F337, 0x1F37C}, {0x1F37E, 0x1F393}, {0x1F3A0, 0x1F3CA}, + {0x1F3CF, 0x1F3D3}, {0x1F3E0, 0x1F3F0}, {0x1F3F4, 0x1F3F4}, + {0x1F3F8, 0x1F43E}, {0x1F440, 0x1F440}, {0x1F442, 0x1F4FC}, + {0x1F4FF, 0x1F53D}, {0x1F54B, 0x1F54E}, {0x1F550, 0x1F567}, + {0x1F57A, 0x1F57A}, {0x1F595, 0x1F596}, {0x1F5A4, 0x1F5A4}, + {0x1F5FB, 0x1F64F}, {0x1F680, 0x1F6C5}, {0x1F6CC, 0x1F6CC}, + {0x1F6D0, 0x1F6D2}, {0x1F6EB, 0x1F6EC}, {0x1F6F4, 0x1F6F6}, + {0x1F910, 0x1F91E}, {0x1F920, 0x1F927}, {0x1F930, 0x1F930}, + {0x1F933, 0x1F93E}, {0x1F940, 0x1F94B}, {0x1F950, 0x1F95E}, + {0x1F980, 0x1F991}, {0x1F9C0, 0x1F9C0}, {0x20000, 0x2FFFD}, + {0x30000, 0x3FFFD}, +} + +var ambiguous = table{ + {0x00A1, 0x00A1}, {0x00A4, 0x00A4}, {0x00A7, 0x00A8}, + {0x00AA, 0x00AA}, {0x00AD, 0x00AE}, {0x00B0, 0x00B4}, + {0x00B6, 0x00BA}, {0x00BC, 0x00BF}, {0x00C6, 0x00C6}, + {0x00D0, 0x00D0}, {0x00D7, 0x00D8}, {0x00DE, 0x00E1}, + {0x00E6, 0x00E6}, {0x00E8, 0x00EA}, {0x00EC, 0x00ED}, + {0x00F0, 0x00F0}, {0x00F2, 0x00F3}, {0x00F7, 0x00FA}, + {0x00FC, 0x00FC}, {0x00FE, 0x00FE}, {0x0101, 0x0101}, + {0x0111, 0x0111}, {0x0113, 0x0113}, {0x011B, 0x011B}, + {0x0126, 0x0127}, {0x012B, 0x012B}, {0x0131, 0x0133}, + {0x0138, 0x0138}, {0x013F, 0x0142}, {0x0144, 0x0144}, + {0x0148, 0x014B}, {0x014D, 0x014D}, {0x0152, 0x0153}, + {0x0166, 0x0167}, {0x016B, 0x016B}, {0x01CE, 0x01CE}, + {0x01D0, 0x01D0}, {0x01D2, 0x01D2}, {0x01D4, 0x01D4}, + {0x01D6, 0x01D6}, {0x01D8, 0x01D8}, {0x01DA, 0x01DA}, + {0x01DC, 0x01DC}, {0x0251, 0x0251}, {0x0261, 0x0261}, + {0x02C4, 0x02C4}, {0x02C7, 0x02C7}, {0x02C9, 0x02CB}, + {0x02CD, 0x02CD}, {0x02D0, 0x02D0}, {0x02D8, 0x02DB}, + {0x02DD, 0x02DD}, {0x02DF, 0x02DF}, {0x0300, 0x036F}, + {0x0391, 0x03A1}, {0x03A3, 0x03A9}, {0x03B1, 0x03C1}, + {0x03C3, 0x03C9}, {0x0401, 0x0401}, {0x0410, 0x044F}, + {0x0451, 0x0451}, {0x2010, 0x2010}, {0x2013, 0x2016}, + {0x2018, 0x2019}, {0x201C, 0x201D}, {0x2020, 0x2022}, + {0x2024, 0x2027}, {0x2030, 0x2030}, {0x2032, 0x2033}, + {0x2035, 0x2035}, {0x203B, 0x203B}, {0x203E, 0x203E}, + {0x2074, 0x2074}, {0x207F, 0x207F}, {0x2081, 0x2084}, + {0x20AC, 0x20AC}, {0x2103, 0x2103}, {0x2105, 0x2105}, + {0x2109, 0x2109}, {0x2113, 0x2113}, {0x2116, 0x2116}, + {0x2121, 0x2122}, {0x2126, 0x2126}, {0x212B, 0x212B}, + {0x2153, 0x2154}, {0x215B, 0x215E}, {0x2160, 0x216B}, + {0x2170, 0x2179}, {0x2189, 0x2189}, {0x2190, 0x2199}, + {0x21B8, 0x21B9}, {0x21D2, 0x21D2}, {0x21D4, 0x21D4}, + {0x21E7, 0x21E7}, {0x2200, 0x2200}, {0x2202, 0x2203}, + {0x2207, 0x2208}, {0x220B, 0x220B}, {0x220F, 0x220F}, + {0x2211, 0x2211}, {0x2215, 0x2215}, {0x221A, 0x221A}, + {0x221D, 0x2220}, {0x2223, 0x2223}, {0x2225, 0x2225}, + {0x2227, 0x222C}, {0x222E, 0x222E}, {0x2234, 0x2237}, + {0x223C, 0x223D}, {0x2248, 0x2248}, {0x224C, 0x224C}, + {0x2252, 0x2252}, {0x2260, 0x2261}, {0x2264, 0x2267}, + {0x226A, 0x226B}, {0x226E, 0x226F}, {0x2282, 0x2283}, + {0x2286, 0x2287}, {0x2295, 0x2295}, {0x2299, 0x2299}, + {0x22A5, 0x22A5}, {0x22BF, 0x22BF}, {0x2312, 0x2312}, + {0x2460, 0x24E9}, {0x24EB, 0x254B}, {0x2550, 0x2573}, + {0x2580, 0x258F}, {0x2592, 0x2595}, {0x25A0, 0x25A1}, + {0x25A3, 0x25A9}, {0x25B2, 0x25B3}, {0x25B6, 0x25B7}, + {0x25BC, 0x25BD}, {0x25C0, 0x25C1}, {0x25C6, 0x25C8}, + {0x25CB, 0x25CB}, {0x25CE, 0x25D1}, {0x25E2, 0x25E5}, + {0x25EF, 0x25EF}, {0x2605, 0x2606}, {0x2609, 0x2609}, + {0x260E, 0x260F}, {0x261C, 0x261C}, {0x261E, 0x261E}, + {0x2640, 0x2640}, {0x2642, 0x2642}, {0x2660, 0x2661}, + {0x2663, 0x2665}, {0x2667, 0x266A}, {0x266C, 0x266D}, + {0x266F, 0x266F}, {0x269E, 0x269F}, {0x26BF, 0x26BF}, + {0x26C6, 0x26CD}, {0x26CF, 0x26D3}, {0x26D5, 0x26E1}, + {0x26E3, 0x26E3}, {0x26E8, 0x26E9}, {0x26EB, 0x26F1}, + {0x26F4, 0x26F4}, {0x26F6, 0x26F9}, {0x26FB, 0x26FC}, + {0x26FE, 0x26FF}, {0x273D, 0x273D}, {0x2776, 0x277F}, + {0x2B56, 0x2B59}, {0x3248, 0x324F}, {0xE000, 0xF8FF}, + {0xFE00, 0xFE0F}, {0xFFFD, 0xFFFD}, {0x1F100, 0x1F10A}, + {0x1F110, 0x1F12D}, {0x1F130, 0x1F169}, {0x1F170, 0x1F18D}, + {0x1F18F, 0x1F190}, {0x1F19B, 0x1F1AC}, {0xE0100, 0xE01EF}, + {0xF0000, 0xFFFFD}, {0x100000, 0x10FFFD}, +} + +var emoji = table{ + {0x1F1E6, 0x1F1FF}, {0x1F321, 0x1F321}, {0x1F324, 0x1F32C}, + {0x1F336, 0x1F336}, {0x1F37D, 0x1F37D}, {0x1F396, 0x1F397}, + {0x1F399, 0x1F39B}, {0x1F39E, 0x1F39F}, {0x1F3CB, 0x1F3CE}, + {0x1F3D4, 0x1F3DF}, {0x1F3F3, 0x1F3F5}, {0x1F3F7, 0x1F3F7}, + {0x1F43F, 0x1F43F}, {0x1F441, 0x1F441}, {0x1F4FD, 0x1F4FD}, + {0x1F549, 0x1F54A}, {0x1F56F, 0x1F570}, {0x1F573, 0x1F579}, + {0x1F587, 0x1F587}, {0x1F58A, 0x1F58D}, {0x1F590, 0x1F590}, + {0x1F5A5, 0x1F5A5}, {0x1F5A8, 0x1F5A8}, {0x1F5B1, 0x1F5B2}, + {0x1F5BC, 0x1F5BC}, {0x1F5C2, 0x1F5C4}, {0x1F5D1, 0x1F5D3}, + {0x1F5DC, 0x1F5DE}, {0x1F5E1, 0x1F5E1}, {0x1F5E3, 0x1F5E3}, + {0x1F5E8, 0x1F5E8}, {0x1F5EF, 0x1F5EF}, {0x1F5F3, 0x1F5F3}, + {0x1F5FA, 0x1F5FA}, {0x1F6CB, 0x1F6CF}, {0x1F6E0, 0x1F6E5}, + {0x1F6E9, 0x1F6E9}, {0x1F6F0, 0x1F6F0}, {0x1F6F3, 0x1F6F3}, +} + +var notassigned = table{ + {0x0378, 0x0379}, {0x0380, 0x0383}, {0x038B, 0x038B}, + {0x038D, 0x038D}, {0x03A2, 0x03A2}, {0x0530, 0x0530}, + {0x0557, 0x0558}, {0x0560, 0x0560}, {0x0588, 0x0588}, + {0x058B, 0x058C}, {0x0590, 0x0590}, {0x05C8, 0x05CF}, + {0x05EB, 0x05EF}, {0x05F5, 0x05FF}, {0x061D, 0x061D}, + {0x070E, 0x070E}, {0x074B, 0x074C}, {0x07B2, 0x07BF}, + {0x07FB, 0x07FF}, {0x082E, 0x082F}, {0x083F, 0x083F}, + {0x085C, 0x085D}, {0x085F, 0x089F}, {0x08B5, 0x08B5}, + {0x08BE, 0x08D3}, {0x0984, 0x0984}, {0x098D, 0x098E}, + {0x0991, 0x0992}, {0x09A9, 0x09A9}, {0x09B1, 0x09B1}, + {0x09B3, 0x09B5}, {0x09BA, 0x09BB}, {0x09C5, 0x09C6}, + {0x09C9, 0x09CA}, {0x09CF, 0x09D6}, {0x09D8, 0x09DB}, + {0x09DE, 0x09DE}, {0x09E4, 0x09E5}, {0x09FC, 0x0A00}, + {0x0A04, 0x0A04}, {0x0A0B, 0x0A0E}, {0x0A11, 0x0A12}, + {0x0A29, 0x0A29}, {0x0A31, 0x0A31}, {0x0A34, 0x0A34}, + {0x0A37, 0x0A37}, {0x0A3A, 0x0A3B}, {0x0A3D, 0x0A3D}, + {0x0A43, 0x0A46}, {0x0A49, 0x0A4A}, {0x0A4E, 0x0A50}, + {0x0A52, 0x0A58}, {0x0A5D, 0x0A5D}, {0x0A5F, 0x0A65}, + {0x0A76, 0x0A80}, {0x0A84, 0x0A84}, {0x0A8E, 0x0A8E}, + {0x0A92, 0x0A92}, {0x0AA9, 0x0AA9}, {0x0AB1, 0x0AB1}, + {0x0AB4, 0x0AB4}, {0x0ABA, 0x0ABB}, {0x0AC6, 0x0AC6}, + {0x0ACA, 0x0ACA}, {0x0ACE, 0x0ACF}, {0x0AD1, 0x0ADF}, + {0x0AE4, 0x0AE5}, {0x0AF2, 0x0AF8}, {0x0AFA, 0x0B00}, + {0x0B04, 0x0B04}, {0x0B0D, 0x0B0E}, {0x0B11, 0x0B12}, + {0x0B29, 0x0B29}, {0x0B31, 0x0B31}, {0x0B34, 0x0B34}, + {0x0B3A, 0x0B3B}, {0x0B45, 0x0B46}, {0x0B49, 0x0B4A}, + {0x0B4E, 0x0B55}, {0x0B58, 0x0B5B}, {0x0B5E, 0x0B5E}, + {0x0B64, 0x0B65}, {0x0B78, 0x0B81}, {0x0B84, 0x0B84}, + {0x0B8B, 0x0B8D}, {0x0B91, 0x0B91}, {0x0B96, 0x0B98}, + {0x0B9B, 0x0B9B}, {0x0B9D, 0x0B9D}, {0x0BA0, 0x0BA2}, + {0x0BA5, 0x0BA7}, {0x0BAB, 0x0BAD}, {0x0BBA, 0x0BBD}, + {0x0BC3, 0x0BC5}, {0x0BC9, 0x0BC9}, {0x0BCE, 0x0BCF}, + {0x0BD1, 0x0BD6}, {0x0BD8, 0x0BE5}, {0x0BFB, 0x0BFF}, + {0x0C04, 0x0C04}, {0x0C0D, 0x0C0D}, {0x0C11, 0x0C11}, + {0x0C29, 0x0C29}, {0x0C3A, 0x0C3C}, {0x0C45, 0x0C45}, + {0x0C49, 0x0C49}, {0x0C4E, 0x0C54}, {0x0C57, 0x0C57}, + {0x0C5B, 0x0C5F}, {0x0C64, 0x0C65}, {0x0C70, 0x0C77}, + {0x0C84, 0x0C84}, {0x0C8D, 0x0C8D}, {0x0C91, 0x0C91}, + {0x0CA9, 0x0CA9}, {0x0CB4, 0x0CB4}, {0x0CBA, 0x0CBB}, + {0x0CC5, 0x0CC5}, {0x0CC9, 0x0CC9}, {0x0CCE, 0x0CD4}, + {0x0CD7, 0x0CDD}, {0x0CDF, 0x0CDF}, {0x0CE4, 0x0CE5}, + {0x0CF0, 0x0CF0}, {0x0CF3, 0x0D00}, {0x0D04, 0x0D04}, + {0x0D0D, 0x0D0D}, {0x0D11, 0x0D11}, {0x0D3B, 0x0D3C}, + {0x0D45, 0x0D45}, {0x0D49, 0x0D49}, {0x0D50, 0x0D53}, + {0x0D64, 0x0D65}, {0x0D80, 0x0D81}, {0x0D84, 0x0D84}, + {0x0D97, 0x0D99}, {0x0DB2, 0x0DB2}, {0x0DBC, 0x0DBC}, + {0x0DBE, 0x0DBF}, {0x0DC7, 0x0DC9}, {0x0DCB, 0x0DCE}, + {0x0DD5, 0x0DD5}, {0x0DD7, 0x0DD7}, {0x0DE0, 0x0DE5}, + {0x0DF0, 0x0DF1}, {0x0DF5, 0x0E00}, {0x0E3B, 0x0E3E}, + {0x0E5C, 0x0E80}, {0x0E83, 0x0E83}, {0x0E85, 0x0E86}, + {0x0E89, 0x0E89}, {0x0E8B, 0x0E8C}, {0x0E8E, 0x0E93}, + {0x0E98, 0x0E98}, {0x0EA0, 0x0EA0}, {0x0EA4, 0x0EA4}, + {0x0EA6, 0x0EA6}, {0x0EA8, 0x0EA9}, {0x0EAC, 0x0EAC}, + {0x0EBA, 0x0EBA}, {0x0EBE, 0x0EBF}, {0x0EC5, 0x0EC5}, + {0x0EC7, 0x0EC7}, {0x0ECE, 0x0ECF}, {0x0EDA, 0x0EDB}, + {0x0EE0, 0x0EFF}, {0x0F48, 0x0F48}, {0x0F6D, 0x0F70}, + {0x0F98, 0x0F98}, {0x0FBD, 0x0FBD}, {0x0FCD, 0x0FCD}, + {0x0FDB, 0x0FFF}, {0x10C6, 0x10C6}, {0x10C8, 0x10CC}, + {0x10CE, 0x10CF}, {0x1249, 0x1249}, {0x124E, 0x124F}, + {0x1257, 0x1257}, {0x1259, 0x1259}, {0x125E, 0x125F}, + {0x1289, 0x1289}, {0x128E, 0x128F}, {0x12B1, 0x12B1}, + {0x12B6, 0x12B7}, {0x12BF, 0x12BF}, {0x12C1, 0x12C1}, + {0x12C6, 0x12C7}, {0x12D7, 0x12D7}, {0x1311, 0x1311}, + {0x1316, 0x1317}, {0x135B, 0x135C}, {0x137D, 0x137F}, + {0x139A, 0x139F}, {0x13F6, 0x13F7}, {0x13FE, 0x13FF}, + {0x169D, 0x169F}, {0x16F9, 0x16FF}, {0x170D, 0x170D}, + {0x1715, 0x171F}, {0x1737, 0x173F}, {0x1754, 0x175F}, + {0x176D, 0x176D}, {0x1771, 0x1771}, {0x1774, 0x177F}, + {0x17DE, 0x17DF}, {0x17EA, 0x17EF}, {0x17FA, 0x17FF}, + {0x180F, 0x180F}, {0x181A, 0x181F}, {0x1878, 0x187F}, + {0x18AB, 0x18AF}, {0x18F6, 0x18FF}, {0x191F, 0x191F}, + {0x192C, 0x192F}, {0x193C, 0x193F}, {0x1941, 0x1943}, + {0x196E, 0x196F}, {0x1975, 0x197F}, {0x19AC, 0x19AF}, + {0x19CA, 0x19CF}, {0x19DB, 0x19DD}, {0x1A1C, 0x1A1D}, + {0x1A5F, 0x1A5F}, {0x1A7D, 0x1A7E}, {0x1A8A, 0x1A8F}, + {0x1A9A, 0x1A9F}, {0x1AAE, 0x1AAF}, {0x1ABF, 0x1AFF}, + {0x1B4C, 0x1B4F}, {0x1B7D, 0x1B7F}, {0x1BF4, 0x1BFB}, + {0x1C38, 0x1C3A}, {0x1C4A, 0x1C4C}, {0x1C89, 0x1CBF}, + {0x1CC8, 0x1CCF}, {0x1CF7, 0x1CF7}, {0x1CFA, 0x1CFF}, + {0x1DF6, 0x1DFA}, {0x1F16, 0x1F17}, {0x1F1E, 0x1F1F}, + {0x1F46, 0x1F47}, {0x1F4E, 0x1F4F}, {0x1F58, 0x1F58}, + {0x1F5A, 0x1F5A}, {0x1F5C, 0x1F5C}, {0x1F5E, 0x1F5E}, + {0x1F7E, 0x1F7F}, {0x1FB5, 0x1FB5}, {0x1FC5, 0x1FC5}, + {0x1FD4, 0x1FD5}, {0x1FDC, 0x1FDC}, {0x1FF0, 0x1FF1}, + {0x1FF5, 0x1FF5}, {0x1FFF, 0x1FFF}, {0x2065, 0x2065}, + {0x2072, 0x2073}, {0x208F, 0x208F}, {0x209D, 0x209F}, + {0x20BF, 0x20CF}, {0x20F1, 0x20FF}, {0x218C, 0x218F}, + {0x23FF, 0x23FF}, {0x2427, 0x243F}, {0x244B, 0x245F}, + {0x2B74, 0x2B75}, {0x2B96, 0x2B97}, {0x2BBA, 0x2BBC}, + {0x2BC9, 0x2BC9}, {0x2BD2, 0x2BEB}, {0x2BF0, 0x2BFF}, + {0x2C2F, 0x2C2F}, {0x2C5F, 0x2C5F}, {0x2CF4, 0x2CF8}, + {0x2D26, 0x2D26}, {0x2D28, 0x2D2C}, {0x2D2E, 0x2D2F}, + {0x2D68, 0x2D6E}, {0x2D71, 0x2D7E}, {0x2D97, 0x2D9F}, + {0x2DA7, 0x2DA7}, {0x2DAF, 0x2DAF}, {0x2DB7, 0x2DB7}, + {0x2DBF, 0x2DBF}, {0x2DC7, 0x2DC7}, {0x2DCF, 0x2DCF}, + {0x2DD7, 0x2DD7}, {0x2DDF, 0x2DDF}, {0x2E45, 0x2E7F}, + {0x2E9A, 0x2E9A}, {0x2EF4, 0x2EFF}, {0x2FD6, 0x2FEF}, + {0x2FFC, 0x2FFF}, {0x3040, 0x3040}, {0x3097, 0x3098}, + {0x3100, 0x3104}, {0x312E, 0x3130}, {0x318F, 0x318F}, + {0x31BB, 0x31BF}, {0x31E4, 0x31EF}, {0x321F, 0x321F}, + {0x32FF, 0x32FF}, {0x4DB6, 0x4DBF}, {0x9FD6, 0x9FFF}, + {0xA48D, 0xA48F}, {0xA4C7, 0xA4CF}, {0xA62C, 0xA63F}, + {0xA6F8, 0xA6FF}, {0xA7AF, 0xA7AF}, {0xA7B8, 0xA7F6}, + {0xA82C, 0xA82F}, {0xA83A, 0xA83F}, {0xA878, 0xA87F}, + {0xA8C6, 0xA8CD}, {0xA8DA, 0xA8DF}, {0xA8FE, 0xA8FF}, + {0xA954, 0xA95E}, {0xA97D, 0xA97F}, {0xA9CE, 0xA9CE}, + {0xA9DA, 0xA9DD}, {0xA9FF, 0xA9FF}, {0xAA37, 0xAA3F}, + {0xAA4E, 0xAA4F}, {0xAA5A, 0xAA5B}, {0xAAC3, 0xAADA}, + {0xAAF7, 0xAB00}, {0xAB07, 0xAB08}, {0xAB0F, 0xAB10}, + {0xAB17, 0xAB1F}, {0xAB27, 0xAB27}, {0xAB2F, 0xAB2F}, + {0xAB66, 0xAB6F}, {0xABEE, 0xABEF}, {0xABFA, 0xABFF}, + {0xD7A4, 0xD7AF}, {0xD7C7, 0xD7CA}, {0xD7FC, 0xD7FF}, + {0xFA6E, 0xFA6F}, {0xFADA, 0xFAFF}, {0xFB07, 0xFB12}, + {0xFB18, 0xFB1C}, {0xFB37, 0xFB37}, {0xFB3D, 0xFB3D}, + {0xFB3F, 0xFB3F}, {0xFB42, 0xFB42}, {0xFB45, 0xFB45}, + {0xFBC2, 0xFBD2}, {0xFD40, 0xFD4F}, {0xFD90, 0xFD91}, + {0xFDC8, 0xFDEF}, {0xFDFE, 0xFDFF}, {0xFE1A, 0xFE1F}, + {0xFE53, 0xFE53}, {0xFE67, 0xFE67}, {0xFE6C, 0xFE6F}, + {0xFE75, 0xFE75}, {0xFEFD, 0xFEFE}, {0xFF00, 0xFF00}, + {0xFFBF, 0xFFC1}, {0xFFC8, 0xFFC9}, {0xFFD0, 0xFFD1}, + {0xFFD8, 0xFFD9}, {0xFFDD, 0xFFDF}, {0xFFE7, 0xFFE7}, + {0xFFEF, 0xFFF8}, {0xFFFE, 0xFFFF}, {0x1000C, 0x1000C}, + {0x10027, 0x10027}, {0x1003B, 0x1003B}, {0x1003E, 0x1003E}, + {0x1004E, 0x1004F}, {0x1005E, 0x1007F}, {0x100FB, 0x100FF}, + {0x10103, 0x10106}, {0x10134, 0x10136}, {0x1018F, 0x1018F}, + {0x1019C, 0x1019F}, {0x101A1, 0x101CF}, {0x101FE, 0x1027F}, + {0x1029D, 0x1029F}, {0x102D1, 0x102DF}, {0x102FC, 0x102FF}, + {0x10324, 0x1032F}, {0x1034B, 0x1034F}, {0x1037B, 0x1037F}, + {0x1039E, 0x1039E}, {0x103C4, 0x103C7}, {0x103D6, 0x103FF}, + {0x1049E, 0x1049F}, {0x104AA, 0x104AF}, {0x104D4, 0x104D7}, + {0x104FC, 0x104FF}, {0x10528, 0x1052F}, {0x10564, 0x1056E}, + {0x10570, 0x105FF}, {0x10737, 0x1073F}, {0x10756, 0x1075F}, + {0x10768, 0x107FF}, {0x10806, 0x10807}, {0x10809, 0x10809}, + {0x10836, 0x10836}, {0x10839, 0x1083B}, {0x1083D, 0x1083E}, + {0x10856, 0x10856}, {0x1089F, 0x108A6}, {0x108B0, 0x108DF}, + {0x108F3, 0x108F3}, {0x108F6, 0x108FA}, {0x1091C, 0x1091E}, + {0x1093A, 0x1093E}, {0x10940, 0x1097F}, {0x109B8, 0x109BB}, + {0x109D0, 0x109D1}, {0x10A04, 0x10A04}, {0x10A07, 0x10A0B}, + {0x10A14, 0x10A14}, {0x10A18, 0x10A18}, {0x10A34, 0x10A37}, + {0x10A3B, 0x10A3E}, {0x10A48, 0x10A4F}, {0x10A59, 0x10A5F}, + {0x10AA0, 0x10ABF}, {0x10AE7, 0x10AEA}, {0x10AF7, 0x10AFF}, + {0x10B36, 0x10B38}, {0x10B56, 0x10B57}, {0x10B73, 0x10B77}, + {0x10B92, 0x10B98}, {0x10B9D, 0x10BA8}, {0x10BB0, 0x10BFF}, + {0x10C49, 0x10C7F}, {0x10CB3, 0x10CBF}, {0x10CF3, 0x10CF9}, + {0x10D00, 0x10E5F}, {0x10E7F, 0x10FFF}, {0x1104E, 0x11051}, + {0x11070, 0x1107E}, {0x110C2, 0x110CF}, {0x110E9, 0x110EF}, + {0x110FA, 0x110FF}, {0x11135, 0x11135}, {0x11144, 0x1114F}, + {0x11177, 0x1117F}, {0x111CE, 0x111CF}, {0x111E0, 0x111E0}, + {0x111F5, 0x111FF}, {0x11212, 0x11212}, {0x1123F, 0x1127F}, + {0x11287, 0x11287}, {0x11289, 0x11289}, {0x1128E, 0x1128E}, + {0x1129E, 0x1129E}, {0x112AA, 0x112AF}, {0x112EB, 0x112EF}, + {0x112FA, 0x112FF}, {0x11304, 0x11304}, {0x1130D, 0x1130E}, + {0x11311, 0x11312}, {0x11329, 0x11329}, {0x11331, 0x11331}, + {0x11334, 0x11334}, {0x1133A, 0x1133B}, {0x11345, 0x11346}, + {0x11349, 0x1134A}, {0x1134E, 0x1134F}, {0x11351, 0x11356}, + {0x11358, 0x1135C}, {0x11364, 0x11365}, {0x1136D, 0x1136F}, + {0x11375, 0x113FF}, {0x1145A, 0x1145A}, {0x1145C, 0x1145C}, + {0x1145E, 0x1147F}, {0x114C8, 0x114CF}, {0x114DA, 0x1157F}, + {0x115B6, 0x115B7}, {0x115DE, 0x115FF}, {0x11645, 0x1164F}, + {0x1165A, 0x1165F}, {0x1166D, 0x1167F}, {0x116B8, 0x116BF}, + {0x116CA, 0x116FF}, {0x1171A, 0x1171C}, {0x1172C, 0x1172F}, + {0x11740, 0x1189F}, {0x118F3, 0x118FE}, {0x11900, 0x11ABF}, + {0x11AF9, 0x11BFF}, {0x11C09, 0x11C09}, {0x11C37, 0x11C37}, + {0x11C46, 0x11C4F}, {0x11C6D, 0x11C6F}, {0x11C90, 0x11C91}, + {0x11CA8, 0x11CA8}, {0x11CB7, 0x11FFF}, {0x1239A, 0x123FF}, + {0x1246F, 0x1246F}, {0x12475, 0x1247F}, {0x12544, 0x12FFF}, + {0x1342F, 0x143FF}, {0x14647, 0x167FF}, {0x16A39, 0x16A3F}, + {0x16A5F, 0x16A5F}, {0x16A6A, 0x16A6D}, {0x16A70, 0x16ACF}, + {0x16AEE, 0x16AEF}, {0x16AF6, 0x16AFF}, {0x16B46, 0x16B4F}, + {0x16B5A, 0x16B5A}, {0x16B62, 0x16B62}, {0x16B78, 0x16B7C}, + {0x16B90, 0x16EFF}, {0x16F45, 0x16F4F}, {0x16F7F, 0x16F8E}, + {0x16FA0, 0x16FDF}, {0x16FE1, 0x16FFF}, {0x187ED, 0x187FF}, + {0x18AF3, 0x1AFFF}, {0x1B002, 0x1BBFF}, {0x1BC6B, 0x1BC6F}, + {0x1BC7D, 0x1BC7F}, {0x1BC89, 0x1BC8F}, {0x1BC9A, 0x1BC9B}, + {0x1BCA4, 0x1CFFF}, {0x1D0F6, 0x1D0FF}, {0x1D127, 0x1D128}, + {0x1D1E9, 0x1D1FF}, {0x1D246, 0x1D2FF}, {0x1D357, 0x1D35F}, + {0x1D372, 0x1D3FF}, {0x1D455, 0x1D455}, {0x1D49D, 0x1D49D}, + {0x1D4A0, 0x1D4A1}, {0x1D4A3, 0x1D4A4}, {0x1D4A7, 0x1D4A8}, + {0x1D4AD, 0x1D4AD}, {0x1D4BA, 0x1D4BA}, {0x1D4BC, 0x1D4BC}, + {0x1D4C4, 0x1D4C4}, {0x1D506, 0x1D506}, {0x1D50B, 0x1D50C}, + {0x1D515, 0x1D515}, {0x1D51D, 0x1D51D}, {0x1D53A, 0x1D53A}, + {0x1D53F, 0x1D53F}, {0x1D545, 0x1D545}, {0x1D547, 0x1D549}, + {0x1D551, 0x1D551}, {0x1D6A6, 0x1D6A7}, {0x1D7CC, 0x1D7CD}, + {0x1DA8C, 0x1DA9A}, {0x1DAA0, 0x1DAA0}, {0x1DAB0, 0x1DFFF}, + {0x1E007, 0x1E007}, {0x1E019, 0x1E01A}, {0x1E022, 0x1E022}, + {0x1E025, 0x1E025}, {0x1E02B, 0x1E7FF}, {0x1E8C5, 0x1E8C6}, + {0x1E8D7, 0x1E8FF}, {0x1E94B, 0x1E94F}, {0x1E95A, 0x1E95D}, + {0x1E960, 0x1EDFF}, {0x1EE04, 0x1EE04}, {0x1EE20, 0x1EE20}, + {0x1EE23, 0x1EE23}, {0x1EE25, 0x1EE26}, {0x1EE28, 0x1EE28}, + {0x1EE33, 0x1EE33}, {0x1EE38, 0x1EE38}, {0x1EE3A, 0x1EE3A}, + {0x1EE3C, 0x1EE41}, {0x1EE43, 0x1EE46}, {0x1EE48, 0x1EE48}, + {0x1EE4A, 0x1EE4A}, {0x1EE4C, 0x1EE4C}, {0x1EE50, 0x1EE50}, + {0x1EE53, 0x1EE53}, {0x1EE55, 0x1EE56}, {0x1EE58, 0x1EE58}, + {0x1EE5A, 0x1EE5A}, {0x1EE5C, 0x1EE5C}, {0x1EE5E, 0x1EE5E}, + {0x1EE60, 0x1EE60}, {0x1EE63, 0x1EE63}, {0x1EE65, 0x1EE66}, + {0x1EE6B, 0x1EE6B}, {0x1EE73, 0x1EE73}, {0x1EE78, 0x1EE78}, + {0x1EE7D, 0x1EE7D}, {0x1EE7F, 0x1EE7F}, {0x1EE8A, 0x1EE8A}, + {0x1EE9C, 0x1EEA0}, {0x1EEA4, 0x1EEA4}, {0x1EEAA, 0x1EEAA}, + {0x1EEBC, 0x1EEEF}, {0x1EEF2, 0x1EFFF}, {0x1F02C, 0x1F02F}, + {0x1F094, 0x1F09F}, {0x1F0AF, 0x1F0B0}, {0x1F0C0, 0x1F0C0}, + {0x1F0D0, 0x1F0D0}, {0x1F0F6, 0x1F0FF}, {0x1F10D, 0x1F10F}, + {0x1F12F, 0x1F12F}, {0x1F16C, 0x1F16F}, {0x1F1AD, 0x1F1E5}, + {0x1F203, 0x1F20F}, {0x1F23C, 0x1F23F}, {0x1F249, 0x1F24F}, + {0x1F252, 0x1F2FF}, {0x1F6D3, 0x1F6DF}, {0x1F6ED, 0x1F6EF}, + {0x1F6F7, 0x1F6FF}, {0x1F774, 0x1F77F}, {0x1F7D5, 0x1F7FF}, + {0x1F80C, 0x1F80F}, {0x1F848, 0x1F84F}, {0x1F85A, 0x1F85F}, + {0x1F888, 0x1F88F}, {0x1F8AE, 0x1F90F}, {0x1F91F, 0x1F91F}, + {0x1F928, 0x1F92F}, {0x1F931, 0x1F932}, {0x1F93F, 0x1F93F}, + {0x1F94C, 0x1F94F}, {0x1F95F, 0x1F97F}, {0x1F992, 0x1F9BF}, + {0x1F9C1, 0x1FFFF}, {0x2A6D7, 0x2A6FF}, {0x2B735, 0x2B73F}, + {0x2B81E, 0x2B81F}, {0x2CEA2, 0x2F7FF}, {0x2FA1E, 0xE0000}, + {0xE0002, 0xE001F}, {0xE0080, 0xE00FF}, {0xE01F0, 0xEFFFF}, + {0xFFFFE, 0xFFFFF}, +} + +var neutral = table{ + {0x0000, 0x001F}, {0x007F, 0x007F}, {0x0080, 0x009F}, + {0x00A0, 0x00A0}, {0x00A9, 0x00A9}, {0x00AB, 0x00AB}, + {0x00B5, 0x00B5}, {0x00BB, 0x00BB}, {0x00C0, 0x00C5}, + {0x00C7, 0x00CF}, {0x00D1, 0x00D6}, {0x00D9, 0x00DD}, + {0x00E2, 0x00E5}, {0x00E7, 0x00E7}, {0x00EB, 0x00EB}, + {0x00EE, 0x00EF}, {0x00F1, 0x00F1}, {0x00F4, 0x00F6}, + {0x00FB, 0x00FB}, {0x00FD, 0x00FD}, {0x00FF, 0x00FF}, + {0x0100, 0x0100}, {0x0102, 0x0110}, {0x0112, 0x0112}, + {0x0114, 0x011A}, {0x011C, 0x0125}, {0x0128, 0x012A}, + {0x012C, 0x0130}, {0x0134, 0x0137}, {0x0139, 0x013E}, + {0x0143, 0x0143}, {0x0145, 0x0147}, {0x014C, 0x014C}, + {0x014E, 0x0151}, {0x0154, 0x0165}, {0x0168, 0x016A}, + {0x016C, 0x017F}, {0x0180, 0x01BA}, {0x01BB, 0x01BB}, + {0x01BC, 0x01BF}, {0x01C0, 0x01C3}, {0x01C4, 0x01CD}, + {0x01CF, 0x01CF}, {0x01D1, 0x01D1}, {0x01D3, 0x01D3}, + {0x01D5, 0x01D5}, {0x01D7, 0x01D7}, {0x01D9, 0x01D9}, + {0x01DB, 0x01DB}, {0x01DD, 0x024F}, {0x0250, 0x0250}, + {0x0252, 0x0260}, {0x0262, 0x0293}, {0x0294, 0x0294}, + {0x0295, 0x02AF}, {0x02B0, 0x02C1}, {0x02C2, 0x02C3}, + {0x02C5, 0x02C5}, {0x02C6, 0x02C6}, {0x02C8, 0x02C8}, + {0x02CC, 0x02CC}, {0x02CE, 0x02CF}, {0x02D1, 0x02D1}, + {0x02D2, 0x02D7}, {0x02DC, 0x02DC}, {0x02DE, 0x02DE}, + {0x02E0, 0x02E4}, {0x02E5, 0x02EB}, {0x02EC, 0x02EC}, + {0x02ED, 0x02ED}, {0x02EE, 0x02EE}, {0x02EF, 0x02FF}, + {0x0370, 0x0373}, {0x0374, 0x0374}, {0x0375, 0x0375}, + {0x0376, 0x0377}, {0x037A, 0x037A}, {0x037B, 0x037D}, + {0x037E, 0x037E}, {0x037F, 0x037F}, {0x0384, 0x0385}, + {0x0386, 0x0386}, {0x0387, 0x0387}, {0x0388, 0x038A}, + {0x038C, 0x038C}, {0x038E, 0x0390}, {0x03AA, 0x03B0}, + {0x03C2, 0x03C2}, {0x03CA, 0x03F5}, {0x03F6, 0x03F6}, + {0x03F7, 0x03FF}, {0x0400, 0x0400}, {0x0402, 0x040F}, + {0x0450, 0x0450}, {0x0452, 0x0481}, {0x0482, 0x0482}, + {0x0483, 0x0487}, {0x0488, 0x0489}, {0x048A, 0x04FF}, + {0x0500, 0x052F}, {0x0531, 0x0556}, {0x0559, 0x0559}, + {0x055A, 0x055F}, {0x0561, 0x0587}, {0x0589, 0x0589}, + {0x058A, 0x058A}, {0x058D, 0x058E}, {0x058F, 0x058F}, + {0x0591, 0x05BD}, {0x05BE, 0x05BE}, {0x05BF, 0x05BF}, + {0x05C0, 0x05C0}, {0x05C1, 0x05C2}, {0x05C3, 0x05C3}, + {0x05C4, 0x05C5}, {0x05C6, 0x05C6}, {0x05C7, 0x05C7}, + {0x05D0, 0x05EA}, {0x05F0, 0x05F2}, {0x05F3, 0x05F4}, + {0x0600, 0x0605}, {0x0606, 0x0608}, {0x0609, 0x060A}, + {0x060B, 0x060B}, {0x060C, 0x060D}, {0x060E, 0x060F}, + {0x0610, 0x061A}, {0x061B, 0x061B}, {0x061C, 0x061C}, + {0x061E, 0x061F}, {0x0620, 0x063F}, {0x0640, 0x0640}, + {0x0641, 0x064A}, {0x064B, 0x065F}, {0x0660, 0x0669}, + {0x066A, 0x066D}, {0x066E, 0x066F}, {0x0670, 0x0670}, + {0x0671, 0x06D3}, {0x06D4, 0x06D4}, {0x06D5, 0x06D5}, + {0x06D6, 0x06DC}, {0x06DD, 0x06DD}, {0x06DE, 0x06DE}, + {0x06DF, 0x06E4}, {0x06E5, 0x06E6}, {0x06E7, 0x06E8}, + {0x06E9, 0x06E9}, {0x06EA, 0x06ED}, {0x06EE, 0x06EF}, + {0x06F0, 0x06F9}, {0x06FA, 0x06FC}, {0x06FD, 0x06FE}, + {0x06FF, 0x06FF}, {0x0700, 0x070D}, {0x070F, 0x070F}, + {0x0710, 0x0710}, {0x0711, 0x0711}, {0x0712, 0x072F}, + {0x0730, 0x074A}, {0x074D, 0x074F}, {0x0750, 0x077F}, + {0x0780, 0x07A5}, {0x07A6, 0x07B0}, {0x07B1, 0x07B1}, + {0x07C0, 0x07C9}, {0x07CA, 0x07EA}, {0x07EB, 0x07F3}, + {0x07F4, 0x07F5}, {0x07F6, 0x07F6}, {0x07F7, 0x07F9}, + {0x07FA, 0x07FA}, {0x0800, 0x0815}, {0x0816, 0x0819}, + {0x081A, 0x081A}, {0x081B, 0x0823}, {0x0824, 0x0824}, + {0x0825, 0x0827}, {0x0828, 0x0828}, {0x0829, 0x082D}, + {0x0830, 0x083E}, {0x0840, 0x0858}, {0x0859, 0x085B}, + {0x085E, 0x085E}, {0x08A0, 0x08B4}, {0x08B6, 0x08BD}, + {0x08D4, 0x08E1}, {0x08E2, 0x08E2}, {0x08E3, 0x08FF}, + {0x0900, 0x0902}, {0x0903, 0x0903}, {0x0904, 0x0939}, + {0x093A, 0x093A}, {0x093B, 0x093B}, {0x093C, 0x093C}, + {0x093D, 0x093D}, {0x093E, 0x0940}, {0x0941, 0x0948}, + {0x0949, 0x094C}, {0x094D, 0x094D}, {0x094E, 0x094F}, + {0x0950, 0x0950}, {0x0951, 0x0957}, {0x0958, 0x0961}, + {0x0962, 0x0963}, {0x0964, 0x0965}, {0x0966, 0x096F}, + {0x0970, 0x0970}, {0x0971, 0x0971}, {0x0972, 0x097F}, + {0x0980, 0x0980}, {0x0981, 0x0981}, {0x0982, 0x0983}, + {0x0985, 0x098C}, {0x098F, 0x0990}, {0x0993, 0x09A8}, + {0x09AA, 0x09B0}, {0x09B2, 0x09B2}, {0x09B6, 0x09B9}, + {0x09BC, 0x09BC}, {0x09BD, 0x09BD}, {0x09BE, 0x09C0}, + {0x09C1, 0x09C4}, {0x09C7, 0x09C8}, {0x09CB, 0x09CC}, + {0x09CD, 0x09CD}, {0x09CE, 0x09CE}, {0x09D7, 0x09D7}, + {0x09DC, 0x09DD}, {0x09DF, 0x09E1}, {0x09E2, 0x09E3}, + {0x09E6, 0x09EF}, {0x09F0, 0x09F1}, {0x09F2, 0x09F3}, + {0x09F4, 0x09F9}, {0x09FA, 0x09FA}, {0x09FB, 0x09FB}, + {0x0A01, 0x0A02}, {0x0A03, 0x0A03}, {0x0A05, 0x0A0A}, + {0x0A0F, 0x0A10}, {0x0A13, 0x0A28}, {0x0A2A, 0x0A30}, + {0x0A32, 0x0A33}, {0x0A35, 0x0A36}, {0x0A38, 0x0A39}, + {0x0A3C, 0x0A3C}, {0x0A3E, 0x0A40}, {0x0A41, 0x0A42}, + {0x0A47, 0x0A48}, {0x0A4B, 0x0A4D}, {0x0A51, 0x0A51}, + {0x0A59, 0x0A5C}, {0x0A5E, 0x0A5E}, {0x0A66, 0x0A6F}, + {0x0A70, 0x0A71}, {0x0A72, 0x0A74}, {0x0A75, 0x0A75}, + {0x0A81, 0x0A82}, {0x0A83, 0x0A83}, {0x0A85, 0x0A8D}, + {0x0A8F, 0x0A91}, {0x0A93, 0x0AA8}, {0x0AAA, 0x0AB0}, + {0x0AB2, 0x0AB3}, {0x0AB5, 0x0AB9}, {0x0ABC, 0x0ABC}, + {0x0ABD, 0x0ABD}, {0x0ABE, 0x0AC0}, {0x0AC1, 0x0AC5}, + {0x0AC7, 0x0AC8}, {0x0AC9, 0x0AC9}, {0x0ACB, 0x0ACC}, + {0x0ACD, 0x0ACD}, {0x0AD0, 0x0AD0}, {0x0AE0, 0x0AE1}, + {0x0AE2, 0x0AE3}, {0x0AE6, 0x0AEF}, {0x0AF0, 0x0AF0}, + {0x0AF1, 0x0AF1}, {0x0AF9, 0x0AF9}, {0x0B01, 0x0B01}, + {0x0B02, 0x0B03}, {0x0B05, 0x0B0C}, {0x0B0F, 0x0B10}, + {0x0B13, 0x0B28}, {0x0B2A, 0x0B30}, {0x0B32, 0x0B33}, + {0x0B35, 0x0B39}, {0x0B3C, 0x0B3C}, {0x0B3D, 0x0B3D}, + {0x0B3E, 0x0B3E}, {0x0B3F, 0x0B3F}, {0x0B40, 0x0B40}, + {0x0B41, 0x0B44}, {0x0B47, 0x0B48}, {0x0B4B, 0x0B4C}, + {0x0B4D, 0x0B4D}, {0x0B56, 0x0B56}, {0x0B57, 0x0B57}, + {0x0B5C, 0x0B5D}, {0x0B5F, 0x0B61}, {0x0B62, 0x0B63}, + {0x0B66, 0x0B6F}, {0x0B70, 0x0B70}, {0x0B71, 0x0B71}, + {0x0B72, 0x0B77}, {0x0B82, 0x0B82}, {0x0B83, 0x0B83}, + {0x0B85, 0x0B8A}, {0x0B8E, 0x0B90}, {0x0B92, 0x0B95}, + {0x0B99, 0x0B9A}, {0x0B9C, 0x0B9C}, {0x0B9E, 0x0B9F}, + {0x0BA3, 0x0BA4}, {0x0BA8, 0x0BAA}, {0x0BAE, 0x0BB9}, + {0x0BBE, 0x0BBF}, {0x0BC0, 0x0BC0}, {0x0BC1, 0x0BC2}, + {0x0BC6, 0x0BC8}, {0x0BCA, 0x0BCC}, {0x0BCD, 0x0BCD}, + {0x0BD0, 0x0BD0}, {0x0BD7, 0x0BD7}, {0x0BE6, 0x0BEF}, + {0x0BF0, 0x0BF2}, {0x0BF3, 0x0BF8}, {0x0BF9, 0x0BF9}, + {0x0BFA, 0x0BFA}, {0x0C00, 0x0C00}, {0x0C01, 0x0C03}, + {0x0C05, 0x0C0C}, {0x0C0E, 0x0C10}, {0x0C12, 0x0C28}, + {0x0C2A, 0x0C39}, {0x0C3D, 0x0C3D}, {0x0C3E, 0x0C40}, + {0x0C41, 0x0C44}, {0x0C46, 0x0C48}, {0x0C4A, 0x0C4D}, + {0x0C55, 0x0C56}, {0x0C58, 0x0C5A}, {0x0C60, 0x0C61}, + {0x0C62, 0x0C63}, {0x0C66, 0x0C6F}, {0x0C78, 0x0C7E}, + {0x0C7F, 0x0C7F}, {0x0C80, 0x0C80}, {0x0C81, 0x0C81}, + {0x0C82, 0x0C83}, {0x0C85, 0x0C8C}, {0x0C8E, 0x0C90}, + {0x0C92, 0x0CA8}, {0x0CAA, 0x0CB3}, {0x0CB5, 0x0CB9}, + {0x0CBC, 0x0CBC}, {0x0CBD, 0x0CBD}, {0x0CBE, 0x0CBE}, + {0x0CBF, 0x0CBF}, {0x0CC0, 0x0CC4}, {0x0CC6, 0x0CC6}, + {0x0CC7, 0x0CC8}, {0x0CCA, 0x0CCB}, {0x0CCC, 0x0CCD}, + {0x0CD5, 0x0CD6}, {0x0CDE, 0x0CDE}, {0x0CE0, 0x0CE1}, + {0x0CE2, 0x0CE3}, {0x0CE6, 0x0CEF}, {0x0CF1, 0x0CF2}, + {0x0D01, 0x0D01}, {0x0D02, 0x0D03}, {0x0D05, 0x0D0C}, + {0x0D0E, 0x0D10}, {0x0D12, 0x0D3A}, {0x0D3D, 0x0D3D}, + {0x0D3E, 0x0D40}, {0x0D41, 0x0D44}, {0x0D46, 0x0D48}, + {0x0D4A, 0x0D4C}, {0x0D4D, 0x0D4D}, {0x0D4E, 0x0D4E}, + {0x0D4F, 0x0D4F}, {0x0D54, 0x0D56}, {0x0D57, 0x0D57}, + {0x0D58, 0x0D5E}, {0x0D5F, 0x0D61}, {0x0D62, 0x0D63}, + {0x0D66, 0x0D6F}, {0x0D70, 0x0D78}, {0x0D79, 0x0D79}, + {0x0D7A, 0x0D7F}, {0x0D82, 0x0D83}, {0x0D85, 0x0D96}, + {0x0D9A, 0x0DB1}, {0x0DB3, 0x0DBB}, {0x0DBD, 0x0DBD}, + {0x0DC0, 0x0DC6}, {0x0DCA, 0x0DCA}, {0x0DCF, 0x0DD1}, + {0x0DD2, 0x0DD4}, {0x0DD6, 0x0DD6}, {0x0DD8, 0x0DDF}, + {0x0DE6, 0x0DEF}, {0x0DF2, 0x0DF3}, {0x0DF4, 0x0DF4}, + {0x0E01, 0x0E30}, {0x0E31, 0x0E31}, {0x0E32, 0x0E33}, + {0x0E34, 0x0E3A}, {0x0E3F, 0x0E3F}, {0x0E40, 0x0E45}, + {0x0E46, 0x0E46}, {0x0E47, 0x0E4E}, {0x0E4F, 0x0E4F}, + {0x0E50, 0x0E59}, {0x0E5A, 0x0E5B}, {0x0E81, 0x0E82}, + {0x0E84, 0x0E84}, {0x0E87, 0x0E88}, {0x0E8A, 0x0E8A}, + {0x0E8D, 0x0E8D}, {0x0E94, 0x0E97}, {0x0E99, 0x0E9F}, + {0x0EA1, 0x0EA3}, {0x0EA5, 0x0EA5}, {0x0EA7, 0x0EA7}, + {0x0EAA, 0x0EAB}, {0x0EAD, 0x0EB0}, {0x0EB1, 0x0EB1}, + {0x0EB2, 0x0EB3}, {0x0EB4, 0x0EB9}, {0x0EBB, 0x0EBC}, + {0x0EBD, 0x0EBD}, {0x0EC0, 0x0EC4}, {0x0EC6, 0x0EC6}, + {0x0EC8, 0x0ECD}, {0x0ED0, 0x0ED9}, {0x0EDC, 0x0EDF}, + {0x0F00, 0x0F00}, {0x0F01, 0x0F03}, {0x0F04, 0x0F12}, + {0x0F13, 0x0F13}, {0x0F14, 0x0F14}, {0x0F15, 0x0F17}, + {0x0F18, 0x0F19}, {0x0F1A, 0x0F1F}, {0x0F20, 0x0F29}, + {0x0F2A, 0x0F33}, {0x0F34, 0x0F34}, {0x0F35, 0x0F35}, + {0x0F36, 0x0F36}, {0x0F37, 0x0F37}, {0x0F38, 0x0F38}, + {0x0F39, 0x0F39}, {0x0F3A, 0x0F3A}, {0x0F3B, 0x0F3B}, + {0x0F3C, 0x0F3C}, {0x0F3D, 0x0F3D}, {0x0F3E, 0x0F3F}, + {0x0F40, 0x0F47}, {0x0F49, 0x0F6C}, {0x0F71, 0x0F7E}, + {0x0F7F, 0x0F7F}, {0x0F80, 0x0F84}, {0x0F85, 0x0F85}, + {0x0F86, 0x0F87}, {0x0F88, 0x0F8C}, {0x0F8D, 0x0F97}, + {0x0F99, 0x0FBC}, {0x0FBE, 0x0FC5}, {0x0FC6, 0x0FC6}, + {0x0FC7, 0x0FCC}, {0x0FCE, 0x0FCF}, {0x0FD0, 0x0FD4}, + {0x0FD5, 0x0FD8}, {0x0FD9, 0x0FDA}, {0x1000, 0x102A}, + {0x102B, 0x102C}, {0x102D, 0x1030}, {0x1031, 0x1031}, + {0x1032, 0x1037}, {0x1038, 0x1038}, {0x1039, 0x103A}, + {0x103B, 0x103C}, {0x103D, 0x103E}, {0x103F, 0x103F}, + {0x1040, 0x1049}, {0x104A, 0x104F}, {0x1050, 0x1055}, + {0x1056, 0x1057}, {0x1058, 0x1059}, {0x105A, 0x105D}, + {0x105E, 0x1060}, {0x1061, 0x1061}, {0x1062, 0x1064}, + {0x1065, 0x1066}, {0x1067, 0x106D}, {0x106E, 0x1070}, + {0x1071, 0x1074}, {0x1075, 0x1081}, {0x1082, 0x1082}, + {0x1083, 0x1084}, {0x1085, 0x1086}, {0x1087, 0x108C}, + {0x108D, 0x108D}, {0x108E, 0x108E}, {0x108F, 0x108F}, + {0x1090, 0x1099}, {0x109A, 0x109C}, {0x109D, 0x109D}, + {0x109E, 0x109F}, {0x10A0, 0x10C5}, {0x10C7, 0x10C7}, + {0x10CD, 0x10CD}, {0x10D0, 0x10FA}, {0x10FB, 0x10FB}, + {0x10FC, 0x10FC}, {0x10FD, 0x10FF}, {0x1160, 0x11FF}, + {0x1200, 0x1248}, {0x124A, 0x124D}, {0x1250, 0x1256}, + {0x1258, 0x1258}, {0x125A, 0x125D}, {0x1260, 0x1288}, + {0x128A, 0x128D}, {0x1290, 0x12B0}, {0x12B2, 0x12B5}, + {0x12B8, 0x12BE}, {0x12C0, 0x12C0}, {0x12C2, 0x12C5}, + {0x12C8, 0x12D6}, {0x12D8, 0x1310}, {0x1312, 0x1315}, + {0x1318, 0x135A}, {0x135D, 0x135F}, {0x1360, 0x1368}, + {0x1369, 0x137C}, {0x1380, 0x138F}, {0x1390, 0x1399}, + {0x13A0, 0x13F5}, {0x13F8, 0x13FD}, {0x1400, 0x1400}, + {0x1401, 0x166C}, {0x166D, 0x166E}, {0x166F, 0x167F}, + {0x1680, 0x1680}, {0x1681, 0x169A}, {0x169B, 0x169B}, + {0x169C, 0x169C}, {0x16A0, 0x16EA}, {0x16EB, 0x16ED}, + {0x16EE, 0x16F0}, {0x16F1, 0x16F8}, {0x1700, 0x170C}, + {0x170E, 0x1711}, {0x1712, 0x1714}, {0x1720, 0x1731}, + {0x1732, 0x1734}, {0x1735, 0x1736}, {0x1740, 0x1751}, + {0x1752, 0x1753}, {0x1760, 0x176C}, {0x176E, 0x1770}, + {0x1772, 0x1773}, {0x1780, 0x17B3}, {0x17B4, 0x17B5}, + {0x17B6, 0x17B6}, {0x17B7, 0x17BD}, {0x17BE, 0x17C5}, + {0x17C6, 0x17C6}, {0x17C7, 0x17C8}, {0x17C9, 0x17D3}, + {0x17D4, 0x17D6}, {0x17D7, 0x17D7}, {0x17D8, 0x17DA}, + {0x17DB, 0x17DB}, {0x17DC, 0x17DC}, {0x17DD, 0x17DD}, + {0x17E0, 0x17E9}, {0x17F0, 0x17F9}, {0x1800, 0x1805}, + {0x1806, 0x1806}, {0x1807, 0x180A}, {0x180B, 0x180D}, + {0x180E, 0x180E}, {0x1810, 0x1819}, {0x1820, 0x1842}, + {0x1843, 0x1843}, {0x1844, 0x1877}, {0x1880, 0x1884}, + {0x1885, 0x1886}, {0x1887, 0x18A8}, {0x18A9, 0x18A9}, + {0x18AA, 0x18AA}, {0x18B0, 0x18F5}, {0x1900, 0x191E}, + {0x1920, 0x1922}, {0x1923, 0x1926}, {0x1927, 0x1928}, + {0x1929, 0x192B}, {0x1930, 0x1931}, {0x1932, 0x1932}, + {0x1933, 0x1938}, {0x1939, 0x193B}, {0x1940, 0x1940}, + {0x1944, 0x1945}, {0x1946, 0x194F}, {0x1950, 0x196D}, + {0x1970, 0x1974}, {0x1980, 0x19AB}, {0x19B0, 0x19C9}, + {0x19D0, 0x19D9}, {0x19DA, 0x19DA}, {0x19DE, 0x19DF}, + {0x19E0, 0x19FF}, {0x1A00, 0x1A16}, {0x1A17, 0x1A18}, + {0x1A19, 0x1A1A}, {0x1A1B, 0x1A1B}, {0x1A1E, 0x1A1F}, + {0x1A20, 0x1A54}, {0x1A55, 0x1A55}, {0x1A56, 0x1A56}, + {0x1A57, 0x1A57}, {0x1A58, 0x1A5E}, {0x1A60, 0x1A60}, + {0x1A61, 0x1A61}, {0x1A62, 0x1A62}, {0x1A63, 0x1A64}, + {0x1A65, 0x1A6C}, {0x1A6D, 0x1A72}, {0x1A73, 0x1A7C}, + {0x1A7F, 0x1A7F}, {0x1A80, 0x1A89}, {0x1A90, 0x1A99}, + {0x1AA0, 0x1AA6}, {0x1AA7, 0x1AA7}, {0x1AA8, 0x1AAD}, + {0x1AB0, 0x1ABD}, {0x1ABE, 0x1ABE}, {0x1B00, 0x1B03}, + {0x1B04, 0x1B04}, {0x1B05, 0x1B33}, {0x1B34, 0x1B34}, + {0x1B35, 0x1B35}, {0x1B36, 0x1B3A}, {0x1B3B, 0x1B3B}, + {0x1B3C, 0x1B3C}, {0x1B3D, 0x1B41}, {0x1B42, 0x1B42}, + {0x1B43, 0x1B44}, {0x1B45, 0x1B4B}, {0x1B50, 0x1B59}, + {0x1B5A, 0x1B60}, {0x1B61, 0x1B6A}, {0x1B6B, 0x1B73}, + {0x1B74, 0x1B7C}, {0x1B80, 0x1B81}, {0x1B82, 0x1B82}, + {0x1B83, 0x1BA0}, {0x1BA1, 0x1BA1}, {0x1BA2, 0x1BA5}, + {0x1BA6, 0x1BA7}, {0x1BA8, 0x1BA9}, {0x1BAA, 0x1BAA}, + {0x1BAB, 0x1BAD}, {0x1BAE, 0x1BAF}, {0x1BB0, 0x1BB9}, + {0x1BBA, 0x1BBF}, {0x1BC0, 0x1BE5}, {0x1BE6, 0x1BE6}, + {0x1BE7, 0x1BE7}, {0x1BE8, 0x1BE9}, {0x1BEA, 0x1BEC}, + {0x1BED, 0x1BED}, {0x1BEE, 0x1BEE}, {0x1BEF, 0x1BF1}, + {0x1BF2, 0x1BF3}, {0x1BFC, 0x1BFF}, {0x1C00, 0x1C23}, + {0x1C24, 0x1C2B}, {0x1C2C, 0x1C33}, {0x1C34, 0x1C35}, + {0x1C36, 0x1C37}, {0x1C3B, 0x1C3F}, {0x1C40, 0x1C49}, + {0x1C4D, 0x1C4F}, {0x1C50, 0x1C59}, {0x1C5A, 0x1C77}, + {0x1C78, 0x1C7D}, {0x1C7E, 0x1C7F}, {0x1C80, 0x1C88}, + {0x1CC0, 0x1CC7}, {0x1CD0, 0x1CD2}, {0x1CD3, 0x1CD3}, + {0x1CD4, 0x1CE0}, {0x1CE1, 0x1CE1}, {0x1CE2, 0x1CE8}, + {0x1CE9, 0x1CEC}, {0x1CED, 0x1CED}, {0x1CEE, 0x1CF1}, + {0x1CF2, 0x1CF3}, {0x1CF4, 0x1CF4}, {0x1CF5, 0x1CF6}, + {0x1CF8, 0x1CF9}, {0x1D00, 0x1D2B}, {0x1D2C, 0x1D6A}, + {0x1D6B, 0x1D77}, {0x1D78, 0x1D78}, {0x1D79, 0x1D7F}, + {0x1D80, 0x1D9A}, {0x1D9B, 0x1DBF}, {0x1DC0, 0x1DF5}, + {0x1DFB, 0x1DFF}, {0x1E00, 0x1EFF}, {0x1F00, 0x1F15}, + {0x1F18, 0x1F1D}, {0x1F20, 0x1F45}, {0x1F48, 0x1F4D}, + {0x1F50, 0x1F57}, {0x1F59, 0x1F59}, {0x1F5B, 0x1F5B}, + {0x1F5D, 0x1F5D}, {0x1F5F, 0x1F7D}, {0x1F80, 0x1FB4}, + {0x1FB6, 0x1FBC}, {0x1FBD, 0x1FBD}, {0x1FBE, 0x1FBE}, + {0x1FBF, 0x1FC1}, {0x1FC2, 0x1FC4}, {0x1FC6, 0x1FCC}, + {0x1FCD, 0x1FCF}, {0x1FD0, 0x1FD3}, {0x1FD6, 0x1FDB}, + {0x1FDD, 0x1FDF}, {0x1FE0, 0x1FEC}, {0x1FED, 0x1FEF}, + {0x1FF2, 0x1FF4}, {0x1FF6, 0x1FFC}, {0x1FFD, 0x1FFE}, + {0x2000, 0x200A}, {0x200B, 0x200F}, {0x2011, 0x2012}, + {0x2017, 0x2017}, {0x201A, 0x201A}, {0x201B, 0x201B}, + {0x201E, 0x201E}, {0x201F, 0x201F}, {0x2023, 0x2023}, + {0x2028, 0x2028}, {0x2029, 0x2029}, {0x202A, 0x202E}, + {0x202F, 0x202F}, {0x2031, 0x2031}, {0x2034, 0x2034}, + {0x2036, 0x2038}, {0x2039, 0x2039}, {0x203A, 0x203A}, + {0x203C, 0x203D}, {0x203F, 0x2040}, {0x2041, 0x2043}, + {0x2044, 0x2044}, {0x2045, 0x2045}, {0x2046, 0x2046}, + {0x2047, 0x2051}, {0x2052, 0x2052}, {0x2053, 0x2053}, + {0x2054, 0x2054}, {0x2055, 0x205E}, {0x205F, 0x205F}, + {0x2060, 0x2064}, {0x2066, 0x206F}, {0x2070, 0x2070}, + {0x2071, 0x2071}, {0x2075, 0x2079}, {0x207A, 0x207C}, + {0x207D, 0x207D}, {0x207E, 0x207E}, {0x2080, 0x2080}, + {0x2085, 0x2089}, {0x208A, 0x208C}, {0x208D, 0x208D}, + {0x208E, 0x208E}, {0x2090, 0x209C}, {0x20A0, 0x20A8}, + {0x20AA, 0x20AB}, {0x20AD, 0x20BE}, {0x20D0, 0x20DC}, + {0x20DD, 0x20E0}, {0x20E1, 0x20E1}, {0x20E2, 0x20E4}, + {0x20E5, 0x20F0}, {0x2100, 0x2101}, {0x2102, 0x2102}, + {0x2104, 0x2104}, {0x2106, 0x2106}, {0x2107, 0x2107}, + {0x2108, 0x2108}, {0x210A, 0x2112}, {0x2114, 0x2114}, + {0x2115, 0x2115}, {0x2117, 0x2117}, {0x2118, 0x2118}, + {0x2119, 0x211D}, {0x211E, 0x2120}, {0x2123, 0x2123}, + {0x2124, 0x2124}, {0x2125, 0x2125}, {0x2127, 0x2127}, + {0x2128, 0x2128}, {0x2129, 0x2129}, {0x212A, 0x212A}, + {0x212C, 0x212D}, {0x212E, 0x212E}, {0x212F, 0x2134}, + {0x2135, 0x2138}, {0x2139, 0x2139}, {0x213A, 0x213B}, + {0x213C, 0x213F}, {0x2140, 0x2144}, {0x2145, 0x2149}, + {0x214A, 0x214A}, {0x214B, 0x214B}, {0x214C, 0x214D}, + {0x214E, 0x214E}, {0x214F, 0x214F}, {0x2150, 0x2152}, + {0x2155, 0x215A}, {0x215F, 0x215F}, {0x216C, 0x216F}, + {0x217A, 0x2182}, {0x2183, 0x2184}, {0x2185, 0x2188}, + {0x218A, 0x218B}, {0x219A, 0x219B}, {0x219C, 0x219F}, + {0x21A0, 0x21A0}, {0x21A1, 0x21A2}, {0x21A3, 0x21A3}, + {0x21A4, 0x21A5}, {0x21A6, 0x21A6}, {0x21A7, 0x21AD}, + {0x21AE, 0x21AE}, {0x21AF, 0x21B7}, {0x21BA, 0x21CD}, + {0x21CE, 0x21CF}, {0x21D0, 0x21D1}, {0x21D3, 0x21D3}, + {0x21D5, 0x21E6}, {0x21E8, 0x21F3}, {0x21F4, 0x21FF}, + {0x2201, 0x2201}, {0x2204, 0x2206}, {0x2209, 0x220A}, + {0x220C, 0x220E}, {0x2210, 0x2210}, {0x2212, 0x2214}, + {0x2216, 0x2219}, {0x221B, 0x221C}, {0x2221, 0x2222}, + {0x2224, 0x2224}, {0x2226, 0x2226}, {0x222D, 0x222D}, + {0x222F, 0x2233}, {0x2238, 0x223B}, {0x223E, 0x2247}, + {0x2249, 0x224B}, {0x224D, 0x2251}, {0x2253, 0x225F}, + {0x2262, 0x2263}, {0x2268, 0x2269}, {0x226C, 0x226D}, + {0x2270, 0x2281}, {0x2284, 0x2285}, {0x2288, 0x2294}, + {0x2296, 0x2298}, {0x229A, 0x22A4}, {0x22A6, 0x22BE}, + {0x22C0, 0x22FF}, {0x2300, 0x2307}, {0x2308, 0x2308}, + {0x2309, 0x2309}, {0x230A, 0x230A}, {0x230B, 0x230B}, + {0x230C, 0x2311}, {0x2313, 0x2319}, {0x231C, 0x231F}, + {0x2320, 0x2321}, {0x2322, 0x2328}, {0x232B, 0x237B}, + {0x237C, 0x237C}, {0x237D, 0x239A}, {0x239B, 0x23B3}, + {0x23B4, 0x23DB}, {0x23DC, 0x23E1}, {0x23E2, 0x23E8}, + {0x23ED, 0x23EF}, {0x23F1, 0x23F2}, {0x23F4, 0x23FE}, + {0x2400, 0x2426}, {0x2440, 0x244A}, {0x24EA, 0x24EA}, + {0x254C, 0x254F}, {0x2574, 0x257F}, {0x2590, 0x2591}, + {0x2596, 0x259F}, {0x25A2, 0x25A2}, {0x25AA, 0x25B1}, + {0x25B4, 0x25B5}, {0x25B8, 0x25BB}, {0x25BE, 0x25BF}, + {0x25C2, 0x25C5}, {0x25C9, 0x25CA}, {0x25CC, 0x25CD}, + {0x25D2, 0x25E1}, {0x25E6, 0x25EE}, {0x25F0, 0x25F7}, + {0x25F8, 0x25FC}, {0x25FF, 0x25FF}, {0x2600, 0x2604}, + {0x2607, 0x2608}, {0x260A, 0x260D}, {0x2610, 0x2613}, + {0x2616, 0x261B}, {0x261D, 0x261D}, {0x261F, 0x263F}, + {0x2641, 0x2641}, {0x2643, 0x2647}, {0x2654, 0x265F}, + {0x2662, 0x2662}, {0x2666, 0x2666}, {0x266B, 0x266B}, + {0x266E, 0x266E}, {0x2670, 0x267E}, {0x2680, 0x2692}, + {0x2694, 0x269D}, {0x26A0, 0x26A0}, {0x26A2, 0x26A9}, + {0x26AC, 0x26BC}, {0x26C0, 0x26C3}, {0x26E2, 0x26E2}, + {0x26E4, 0x26E7}, {0x2700, 0x2704}, {0x2706, 0x2709}, + {0x270C, 0x2727}, {0x2729, 0x273C}, {0x273E, 0x274B}, + {0x274D, 0x274D}, {0x274F, 0x2752}, {0x2756, 0x2756}, + {0x2758, 0x2767}, {0x2768, 0x2768}, {0x2769, 0x2769}, + {0x276A, 0x276A}, {0x276B, 0x276B}, {0x276C, 0x276C}, + {0x276D, 0x276D}, {0x276E, 0x276E}, {0x276F, 0x276F}, + {0x2770, 0x2770}, {0x2771, 0x2771}, {0x2772, 0x2772}, + {0x2773, 0x2773}, {0x2774, 0x2774}, {0x2775, 0x2775}, + {0x2780, 0x2793}, {0x2794, 0x2794}, {0x2798, 0x27AF}, + {0x27B1, 0x27BE}, {0x27C0, 0x27C4}, {0x27C5, 0x27C5}, + {0x27C6, 0x27C6}, {0x27C7, 0x27E5}, {0x27EE, 0x27EE}, + {0x27EF, 0x27EF}, {0x27F0, 0x27FF}, {0x2800, 0x28FF}, + {0x2900, 0x297F}, {0x2980, 0x2982}, {0x2983, 0x2983}, + {0x2984, 0x2984}, {0x2987, 0x2987}, {0x2988, 0x2988}, + {0x2989, 0x2989}, {0x298A, 0x298A}, {0x298B, 0x298B}, + {0x298C, 0x298C}, {0x298D, 0x298D}, {0x298E, 0x298E}, + {0x298F, 0x298F}, {0x2990, 0x2990}, {0x2991, 0x2991}, + {0x2992, 0x2992}, {0x2993, 0x2993}, {0x2994, 0x2994}, + {0x2995, 0x2995}, {0x2996, 0x2996}, {0x2997, 0x2997}, + {0x2998, 0x2998}, {0x2999, 0x29D7}, {0x29D8, 0x29D8}, + {0x29D9, 0x29D9}, {0x29DA, 0x29DA}, {0x29DB, 0x29DB}, + {0x29DC, 0x29FB}, {0x29FC, 0x29FC}, {0x29FD, 0x29FD}, + {0x29FE, 0x29FF}, {0x2A00, 0x2AFF}, {0x2B00, 0x2B1A}, + {0x2B1D, 0x2B2F}, {0x2B30, 0x2B44}, {0x2B45, 0x2B46}, + {0x2B47, 0x2B4C}, {0x2B4D, 0x2B4F}, {0x2B51, 0x2B54}, + {0x2B5A, 0x2B73}, {0x2B76, 0x2B95}, {0x2B98, 0x2BB9}, + {0x2BBD, 0x2BC8}, {0x2BCA, 0x2BD1}, {0x2BEC, 0x2BEF}, + {0x2C00, 0x2C2E}, {0x2C30, 0x2C5E}, {0x2C60, 0x2C7B}, + {0x2C7C, 0x2C7D}, {0x2C7E, 0x2C7F}, {0x2C80, 0x2CE4}, + {0x2CE5, 0x2CEA}, {0x2CEB, 0x2CEE}, {0x2CEF, 0x2CF1}, + {0x2CF2, 0x2CF3}, {0x2CF9, 0x2CFC}, {0x2CFD, 0x2CFD}, + {0x2CFE, 0x2CFF}, {0x2D00, 0x2D25}, {0x2D27, 0x2D27}, + {0x2D2D, 0x2D2D}, {0x2D30, 0x2D67}, {0x2D6F, 0x2D6F}, + {0x2D70, 0x2D70}, {0x2D7F, 0x2D7F}, {0x2D80, 0x2D96}, + {0x2DA0, 0x2DA6}, {0x2DA8, 0x2DAE}, {0x2DB0, 0x2DB6}, + {0x2DB8, 0x2DBE}, {0x2DC0, 0x2DC6}, {0x2DC8, 0x2DCE}, + {0x2DD0, 0x2DD6}, {0x2DD8, 0x2DDE}, {0x2DE0, 0x2DFF}, + {0x2E00, 0x2E01}, {0x2E02, 0x2E02}, {0x2E03, 0x2E03}, + {0x2E04, 0x2E04}, {0x2E05, 0x2E05}, {0x2E06, 0x2E08}, + {0x2E09, 0x2E09}, {0x2E0A, 0x2E0A}, {0x2E0B, 0x2E0B}, + {0x2E0C, 0x2E0C}, {0x2E0D, 0x2E0D}, {0x2E0E, 0x2E16}, + {0x2E17, 0x2E17}, {0x2E18, 0x2E19}, {0x2E1A, 0x2E1A}, + {0x2E1B, 0x2E1B}, {0x2E1C, 0x2E1C}, {0x2E1D, 0x2E1D}, + {0x2E1E, 0x2E1F}, {0x2E20, 0x2E20}, {0x2E21, 0x2E21}, + {0x2E22, 0x2E22}, {0x2E23, 0x2E23}, {0x2E24, 0x2E24}, + {0x2E25, 0x2E25}, {0x2E26, 0x2E26}, {0x2E27, 0x2E27}, + {0x2E28, 0x2E28}, {0x2E29, 0x2E29}, {0x2E2A, 0x2E2E}, + {0x2E2F, 0x2E2F}, {0x2E30, 0x2E39}, {0x2E3A, 0x2E3B}, + {0x2E3C, 0x2E3F}, {0x2E40, 0x2E40}, {0x2E41, 0x2E41}, + {0x2E42, 0x2E42}, {0x2E43, 0x2E44}, {0x303F, 0x303F}, + {0x4DC0, 0x4DFF}, {0xA4D0, 0xA4F7}, {0xA4F8, 0xA4FD}, + {0xA4FE, 0xA4FF}, {0xA500, 0xA60B}, {0xA60C, 0xA60C}, + {0xA60D, 0xA60F}, {0xA610, 0xA61F}, {0xA620, 0xA629}, + {0xA62A, 0xA62B}, {0xA640, 0xA66D}, {0xA66E, 0xA66E}, + {0xA66F, 0xA66F}, {0xA670, 0xA672}, {0xA673, 0xA673}, + {0xA674, 0xA67D}, {0xA67E, 0xA67E}, {0xA67F, 0xA67F}, + {0xA680, 0xA69B}, {0xA69C, 0xA69D}, {0xA69E, 0xA69F}, + {0xA6A0, 0xA6E5}, {0xA6E6, 0xA6EF}, {0xA6F0, 0xA6F1}, + {0xA6F2, 0xA6F7}, {0xA700, 0xA716}, {0xA717, 0xA71F}, + {0xA720, 0xA721}, {0xA722, 0xA76F}, {0xA770, 0xA770}, + {0xA771, 0xA787}, {0xA788, 0xA788}, {0xA789, 0xA78A}, + {0xA78B, 0xA78E}, {0xA78F, 0xA78F}, {0xA790, 0xA7AE}, + {0xA7B0, 0xA7B7}, {0xA7F7, 0xA7F7}, {0xA7F8, 0xA7F9}, + {0xA7FA, 0xA7FA}, {0xA7FB, 0xA7FF}, {0xA800, 0xA801}, + {0xA802, 0xA802}, {0xA803, 0xA805}, {0xA806, 0xA806}, + {0xA807, 0xA80A}, {0xA80B, 0xA80B}, {0xA80C, 0xA822}, + {0xA823, 0xA824}, {0xA825, 0xA826}, {0xA827, 0xA827}, + {0xA828, 0xA82B}, {0xA830, 0xA835}, {0xA836, 0xA837}, + {0xA838, 0xA838}, {0xA839, 0xA839}, {0xA840, 0xA873}, + {0xA874, 0xA877}, {0xA880, 0xA881}, {0xA882, 0xA8B3}, + {0xA8B4, 0xA8C3}, {0xA8C4, 0xA8C5}, {0xA8CE, 0xA8CF}, + {0xA8D0, 0xA8D9}, {0xA8E0, 0xA8F1}, {0xA8F2, 0xA8F7}, + {0xA8F8, 0xA8FA}, {0xA8FB, 0xA8FB}, {0xA8FC, 0xA8FC}, + {0xA8FD, 0xA8FD}, {0xA900, 0xA909}, {0xA90A, 0xA925}, + {0xA926, 0xA92D}, {0xA92E, 0xA92F}, {0xA930, 0xA946}, + {0xA947, 0xA951}, {0xA952, 0xA953}, {0xA95F, 0xA95F}, + {0xA980, 0xA982}, {0xA983, 0xA983}, {0xA984, 0xA9B2}, + {0xA9B3, 0xA9B3}, {0xA9B4, 0xA9B5}, {0xA9B6, 0xA9B9}, + {0xA9BA, 0xA9BB}, {0xA9BC, 0xA9BC}, {0xA9BD, 0xA9C0}, + {0xA9C1, 0xA9CD}, {0xA9CF, 0xA9CF}, {0xA9D0, 0xA9D9}, + {0xA9DE, 0xA9DF}, {0xA9E0, 0xA9E4}, {0xA9E5, 0xA9E5}, + {0xA9E6, 0xA9E6}, {0xA9E7, 0xA9EF}, {0xA9F0, 0xA9F9}, + {0xA9FA, 0xA9FE}, {0xAA00, 0xAA28}, {0xAA29, 0xAA2E}, + {0xAA2F, 0xAA30}, {0xAA31, 0xAA32}, {0xAA33, 0xAA34}, + {0xAA35, 0xAA36}, {0xAA40, 0xAA42}, {0xAA43, 0xAA43}, + {0xAA44, 0xAA4B}, {0xAA4C, 0xAA4C}, {0xAA4D, 0xAA4D}, + {0xAA50, 0xAA59}, {0xAA5C, 0xAA5F}, {0xAA60, 0xAA6F}, + {0xAA70, 0xAA70}, {0xAA71, 0xAA76}, {0xAA77, 0xAA79}, + {0xAA7A, 0xAA7A}, {0xAA7B, 0xAA7B}, {0xAA7C, 0xAA7C}, + {0xAA7D, 0xAA7D}, {0xAA7E, 0xAA7F}, {0xAA80, 0xAAAF}, + {0xAAB0, 0xAAB0}, {0xAAB1, 0xAAB1}, {0xAAB2, 0xAAB4}, + {0xAAB5, 0xAAB6}, {0xAAB7, 0xAAB8}, {0xAAB9, 0xAABD}, + {0xAABE, 0xAABF}, {0xAAC0, 0xAAC0}, {0xAAC1, 0xAAC1}, + {0xAAC2, 0xAAC2}, {0xAADB, 0xAADC}, {0xAADD, 0xAADD}, + {0xAADE, 0xAADF}, {0xAAE0, 0xAAEA}, {0xAAEB, 0xAAEB}, + {0xAAEC, 0xAAED}, {0xAAEE, 0xAAEF}, {0xAAF0, 0xAAF1}, + {0xAAF2, 0xAAF2}, {0xAAF3, 0xAAF4}, {0xAAF5, 0xAAF5}, + {0xAAF6, 0xAAF6}, {0xAB01, 0xAB06}, {0xAB09, 0xAB0E}, + {0xAB11, 0xAB16}, {0xAB20, 0xAB26}, {0xAB28, 0xAB2E}, + {0xAB30, 0xAB5A}, {0xAB5B, 0xAB5B}, {0xAB5C, 0xAB5F}, + {0xAB60, 0xAB65}, {0xAB70, 0xABBF}, {0xABC0, 0xABE2}, + {0xABE3, 0xABE4}, {0xABE5, 0xABE5}, {0xABE6, 0xABE7}, + {0xABE8, 0xABE8}, {0xABE9, 0xABEA}, {0xABEB, 0xABEB}, + {0xABEC, 0xABEC}, {0xABED, 0xABED}, {0xABF0, 0xABF9}, + {0xD7B0, 0xD7C6}, {0xD7CB, 0xD7FB}, {0xD800, 0xDB7F}, + {0xDB80, 0xDBFF}, {0xDC00, 0xDFFF}, {0xFB00, 0xFB06}, + {0xFB13, 0xFB17}, {0xFB1D, 0xFB1D}, {0xFB1E, 0xFB1E}, + {0xFB1F, 0xFB28}, {0xFB29, 0xFB29}, {0xFB2A, 0xFB36}, + {0xFB38, 0xFB3C}, {0xFB3E, 0xFB3E}, {0xFB40, 0xFB41}, + {0xFB43, 0xFB44}, {0xFB46, 0xFB4F}, {0xFB50, 0xFBB1}, + {0xFBB2, 0xFBC1}, {0xFBD3, 0xFD3D}, {0xFD3E, 0xFD3E}, + {0xFD3F, 0xFD3F}, {0xFD50, 0xFD8F}, {0xFD92, 0xFDC7}, + {0xFDF0, 0xFDFB}, {0xFDFC, 0xFDFC}, {0xFDFD, 0xFDFD}, + {0xFE20, 0xFE2F}, {0xFE70, 0xFE74}, {0xFE76, 0xFEFC}, + {0xFEFF, 0xFEFF}, {0xFFF9, 0xFFFB}, {0xFFFC, 0xFFFC}, + {0x10000, 0x1000B}, {0x1000D, 0x10026}, {0x10028, 0x1003A}, + {0x1003C, 0x1003D}, {0x1003F, 0x1004D}, {0x10050, 0x1005D}, + {0x10080, 0x100FA}, {0x10100, 0x10102}, {0x10107, 0x10133}, + {0x10137, 0x1013F}, {0x10140, 0x10174}, {0x10175, 0x10178}, + {0x10179, 0x10189}, {0x1018A, 0x1018B}, {0x1018C, 0x1018E}, + {0x10190, 0x1019B}, {0x101A0, 0x101A0}, {0x101D0, 0x101FC}, + {0x101FD, 0x101FD}, {0x10280, 0x1029C}, {0x102A0, 0x102D0}, + {0x102E0, 0x102E0}, {0x102E1, 0x102FB}, {0x10300, 0x1031F}, + {0x10320, 0x10323}, {0x10330, 0x10340}, {0x10341, 0x10341}, + {0x10342, 0x10349}, {0x1034A, 0x1034A}, {0x10350, 0x10375}, + {0x10376, 0x1037A}, {0x10380, 0x1039D}, {0x1039F, 0x1039F}, + {0x103A0, 0x103C3}, {0x103C8, 0x103CF}, {0x103D0, 0x103D0}, + {0x103D1, 0x103D5}, {0x10400, 0x1044F}, {0x10450, 0x1047F}, + {0x10480, 0x1049D}, {0x104A0, 0x104A9}, {0x104B0, 0x104D3}, + {0x104D8, 0x104FB}, {0x10500, 0x10527}, {0x10530, 0x10563}, + {0x1056F, 0x1056F}, {0x10600, 0x10736}, {0x10740, 0x10755}, + {0x10760, 0x10767}, {0x10800, 0x10805}, {0x10808, 0x10808}, + {0x1080A, 0x10835}, {0x10837, 0x10838}, {0x1083C, 0x1083C}, + {0x1083F, 0x1083F}, {0x10840, 0x10855}, {0x10857, 0x10857}, + {0x10858, 0x1085F}, {0x10860, 0x10876}, {0x10877, 0x10878}, + {0x10879, 0x1087F}, {0x10880, 0x1089E}, {0x108A7, 0x108AF}, + {0x108E0, 0x108F2}, {0x108F4, 0x108F5}, {0x108FB, 0x108FF}, + {0x10900, 0x10915}, {0x10916, 0x1091B}, {0x1091F, 0x1091F}, + {0x10920, 0x10939}, {0x1093F, 0x1093F}, {0x10980, 0x1099F}, + {0x109A0, 0x109B7}, {0x109BC, 0x109BD}, {0x109BE, 0x109BF}, + {0x109C0, 0x109CF}, {0x109D2, 0x109FF}, {0x10A00, 0x10A00}, + {0x10A01, 0x10A03}, {0x10A05, 0x10A06}, {0x10A0C, 0x10A0F}, + {0x10A10, 0x10A13}, {0x10A15, 0x10A17}, {0x10A19, 0x10A33}, + {0x10A38, 0x10A3A}, {0x10A3F, 0x10A3F}, {0x10A40, 0x10A47}, + {0x10A50, 0x10A58}, {0x10A60, 0x10A7C}, {0x10A7D, 0x10A7E}, + {0x10A7F, 0x10A7F}, {0x10A80, 0x10A9C}, {0x10A9D, 0x10A9F}, + {0x10AC0, 0x10AC7}, {0x10AC8, 0x10AC8}, {0x10AC9, 0x10AE4}, + {0x10AE5, 0x10AE6}, {0x10AEB, 0x10AEF}, {0x10AF0, 0x10AF6}, + {0x10B00, 0x10B35}, {0x10B39, 0x10B3F}, {0x10B40, 0x10B55}, + {0x10B58, 0x10B5F}, {0x10B60, 0x10B72}, {0x10B78, 0x10B7F}, + {0x10B80, 0x10B91}, {0x10B99, 0x10B9C}, {0x10BA9, 0x10BAF}, + {0x10C00, 0x10C48}, {0x10C80, 0x10CB2}, {0x10CC0, 0x10CF2}, + {0x10CFA, 0x10CFF}, {0x10E60, 0x10E7E}, {0x11000, 0x11000}, + {0x11001, 0x11001}, {0x11002, 0x11002}, {0x11003, 0x11037}, + {0x11038, 0x11046}, {0x11047, 0x1104D}, {0x11052, 0x11065}, + {0x11066, 0x1106F}, {0x1107F, 0x1107F}, {0x11080, 0x11081}, + {0x11082, 0x11082}, {0x11083, 0x110AF}, {0x110B0, 0x110B2}, + {0x110B3, 0x110B6}, {0x110B7, 0x110B8}, {0x110B9, 0x110BA}, + {0x110BB, 0x110BC}, {0x110BD, 0x110BD}, {0x110BE, 0x110C1}, + {0x110D0, 0x110E8}, {0x110F0, 0x110F9}, {0x11100, 0x11102}, + {0x11103, 0x11126}, {0x11127, 0x1112B}, {0x1112C, 0x1112C}, + {0x1112D, 0x11134}, {0x11136, 0x1113F}, {0x11140, 0x11143}, + {0x11150, 0x11172}, {0x11173, 0x11173}, {0x11174, 0x11175}, + {0x11176, 0x11176}, {0x11180, 0x11181}, {0x11182, 0x11182}, + {0x11183, 0x111B2}, {0x111B3, 0x111B5}, {0x111B6, 0x111BE}, + {0x111BF, 0x111C0}, {0x111C1, 0x111C4}, {0x111C5, 0x111C9}, + {0x111CA, 0x111CC}, {0x111CD, 0x111CD}, {0x111D0, 0x111D9}, + {0x111DA, 0x111DA}, {0x111DB, 0x111DB}, {0x111DC, 0x111DC}, + {0x111DD, 0x111DF}, {0x111E1, 0x111F4}, {0x11200, 0x11211}, + {0x11213, 0x1122B}, {0x1122C, 0x1122E}, {0x1122F, 0x11231}, + {0x11232, 0x11233}, {0x11234, 0x11234}, {0x11235, 0x11235}, + {0x11236, 0x11237}, {0x11238, 0x1123D}, {0x1123E, 0x1123E}, + {0x11280, 0x11286}, {0x11288, 0x11288}, {0x1128A, 0x1128D}, + {0x1128F, 0x1129D}, {0x1129F, 0x112A8}, {0x112A9, 0x112A9}, + {0x112B0, 0x112DE}, {0x112DF, 0x112DF}, {0x112E0, 0x112E2}, + {0x112E3, 0x112EA}, {0x112F0, 0x112F9}, {0x11300, 0x11301}, + {0x11302, 0x11303}, {0x11305, 0x1130C}, {0x1130F, 0x11310}, + {0x11313, 0x11328}, {0x1132A, 0x11330}, {0x11332, 0x11333}, + {0x11335, 0x11339}, {0x1133C, 0x1133C}, {0x1133D, 0x1133D}, + {0x1133E, 0x1133F}, {0x11340, 0x11340}, {0x11341, 0x11344}, + {0x11347, 0x11348}, {0x1134B, 0x1134D}, {0x11350, 0x11350}, + {0x11357, 0x11357}, {0x1135D, 0x11361}, {0x11362, 0x11363}, + {0x11366, 0x1136C}, {0x11370, 0x11374}, {0x11400, 0x11434}, + {0x11435, 0x11437}, {0x11438, 0x1143F}, {0x11440, 0x11441}, + {0x11442, 0x11444}, {0x11445, 0x11445}, {0x11446, 0x11446}, + {0x11447, 0x1144A}, {0x1144B, 0x1144F}, {0x11450, 0x11459}, + {0x1145B, 0x1145B}, {0x1145D, 0x1145D}, {0x11480, 0x114AF}, + {0x114B0, 0x114B2}, {0x114B3, 0x114B8}, {0x114B9, 0x114B9}, + {0x114BA, 0x114BA}, {0x114BB, 0x114BE}, {0x114BF, 0x114C0}, + {0x114C1, 0x114C1}, {0x114C2, 0x114C3}, {0x114C4, 0x114C5}, + {0x114C6, 0x114C6}, {0x114C7, 0x114C7}, {0x114D0, 0x114D9}, + {0x11580, 0x115AE}, {0x115AF, 0x115B1}, {0x115B2, 0x115B5}, + {0x115B8, 0x115BB}, {0x115BC, 0x115BD}, {0x115BE, 0x115BE}, + {0x115BF, 0x115C0}, {0x115C1, 0x115D7}, {0x115D8, 0x115DB}, + {0x115DC, 0x115DD}, {0x11600, 0x1162F}, {0x11630, 0x11632}, + {0x11633, 0x1163A}, {0x1163B, 0x1163C}, {0x1163D, 0x1163D}, + {0x1163E, 0x1163E}, {0x1163F, 0x11640}, {0x11641, 0x11643}, + {0x11644, 0x11644}, {0x11650, 0x11659}, {0x11660, 0x1166C}, + {0x11680, 0x116AA}, {0x116AB, 0x116AB}, {0x116AC, 0x116AC}, + {0x116AD, 0x116AD}, {0x116AE, 0x116AF}, {0x116B0, 0x116B5}, + {0x116B6, 0x116B6}, {0x116B7, 0x116B7}, {0x116C0, 0x116C9}, + {0x11700, 0x11719}, {0x1171D, 0x1171F}, {0x11720, 0x11721}, + {0x11722, 0x11725}, {0x11726, 0x11726}, {0x11727, 0x1172B}, + {0x11730, 0x11739}, {0x1173A, 0x1173B}, {0x1173C, 0x1173E}, + {0x1173F, 0x1173F}, {0x118A0, 0x118DF}, {0x118E0, 0x118E9}, + {0x118EA, 0x118F2}, {0x118FF, 0x118FF}, {0x11AC0, 0x11AF8}, + {0x11C00, 0x11C08}, {0x11C0A, 0x11C2E}, {0x11C2F, 0x11C2F}, + {0x11C30, 0x11C36}, {0x11C38, 0x11C3D}, {0x11C3E, 0x11C3E}, + {0x11C3F, 0x11C3F}, {0x11C40, 0x11C40}, {0x11C41, 0x11C45}, + {0x11C50, 0x11C59}, {0x11C5A, 0x11C6C}, {0x11C70, 0x11C71}, + {0x11C72, 0x11C8F}, {0x11C92, 0x11CA7}, {0x11CA9, 0x11CA9}, + {0x11CAA, 0x11CB0}, {0x11CB1, 0x11CB1}, {0x11CB2, 0x11CB3}, + {0x11CB4, 0x11CB4}, {0x11CB5, 0x11CB6}, {0x12000, 0x12399}, + {0x12400, 0x1246E}, {0x12470, 0x12474}, {0x12480, 0x12543}, + {0x13000, 0x1342E}, {0x14400, 0x14646}, {0x16800, 0x16A38}, + {0x16A40, 0x16A5E}, {0x16A60, 0x16A69}, {0x16A6E, 0x16A6F}, + {0x16AD0, 0x16AED}, {0x16AF0, 0x16AF4}, {0x16AF5, 0x16AF5}, + {0x16B00, 0x16B2F}, {0x16B30, 0x16B36}, {0x16B37, 0x16B3B}, + {0x16B3C, 0x16B3F}, {0x16B40, 0x16B43}, {0x16B44, 0x16B44}, + {0x16B45, 0x16B45}, {0x16B50, 0x16B59}, {0x16B5B, 0x16B61}, + {0x16B63, 0x16B77}, {0x16B7D, 0x16B8F}, {0x16F00, 0x16F44}, + {0x16F50, 0x16F50}, {0x16F51, 0x16F7E}, {0x16F8F, 0x16F92}, + {0x16F93, 0x16F9F}, {0x1BC00, 0x1BC6A}, {0x1BC70, 0x1BC7C}, + {0x1BC80, 0x1BC88}, {0x1BC90, 0x1BC99}, {0x1BC9C, 0x1BC9C}, + {0x1BC9D, 0x1BC9E}, {0x1BC9F, 0x1BC9F}, {0x1BCA0, 0x1BCA3}, + {0x1D000, 0x1D0F5}, {0x1D100, 0x1D126}, {0x1D129, 0x1D164}, + {0x1D165, 0x1D166}, {0x1D167, 0x1D169}, {0x1D16A, 0x1D16C}, + {0x1D16D, 0x1D172}, {0x1D173, 0x1D17A}, {0x1D17B, 0x1D182}, + {0x1D183, 0x1D184}, {0x1D185, 0x1D18B}, {0x1D18C, 0x1D1A9}, + {0x1D1AA, 0x1D1AD}, {0x1D1AE, 0x1D1E8}, {0x1D200, 0x1D241}, + {0x1D242, 0x1D244}, {0x1D245, 0x1D245}, {0x1D300, 0x1D356}, + {0x1D360, 0x1D371}, {0x1D400, 0x1D454}, {0x1D456, 0x1D49C}, + {0x1D49E, 0x1D49F}, {0x1D4A2, 0x1D4A2}, {0x1D4A5, 0x1D4A6}, + {0x1D4A9, 0x1D4AC}, {0x1D4AE, 0x1D4B9}, {0x1D4BB, 0x1D4BB}, + {0x1D4BD, 0x1D4C3}, {0x1D4C5, 0x1D505}, {0x1D507, 0x1D50A}, + {0x1D50D, 0x1D514}, {0x1D516, 0x1D51C}, {0x1D51E, 0x1D539}, + {0x1D53B, 0x1D53E}, {0x1D540, 0x1D544}, {0x1D546, 0x1D546}, + {0x1D54A, 0x1D550}, {0x1D552, 0x1D6A5}, {0x1D6A8, 0x1D6C0}, + {0x1D6C1, 0x1D6C1}, {0x1D6C2, 0x1D6DA}, {0x1D6DB, 0x1D6DB}, + {0x1D6DC, 0x1D6FA}, {0x1D6FB, 0x1D6FB}, {0x1D6FC, 0x1D714}, + {0x1D715, 0x1D715}, {0x1D716, 0x1D734}, {0x1D735, 0x1D735}, + {0x1D736, 0x1D74E}, {0x1D74F, 0x1D74F}, {0x1D750, 0x1D76E}, + {0x1D76F, 0x1D76F}, {0x1D770, 0x1D788}, {0x1D789, 0x1D789}, + {0x1D78A, 0x1D7A8}, {0x1D7A9, 0x1D7A9}, {0x1D7AA, 0x1D7C2}, + {0x1D7C3, 0x1D7C3}, {0x1D7C4, 0x1D7CB}, {0x1D7CE, 0x1D7FF}, + {0x1D800, 0x1D9FF}, {0x1DA00, 0x1DA36}, {0x1DA37, 0x1DA3A}, + {0x1DA3B, 0x1DA6C}, {0x1DA6D, 0x1DA74}, {0x1DA75, 0x1DA75}, + {0x1DA76, 0x1DA83}, {0x1DA84, 0x1DA84}, {0x1DA85, 0x1DA86}, + {0x1DA87, 0x1DA8B}, {0x1DA9B, 0x1DA9F}, {0x1DAA1, 0x1DAAF}, + {0x1E000, 0x1E006}, {0x1E008, 0x1E018}, {0x1E01B, 0x1E021}, + {0x1E023, 0x1E024}, {0x1E026, 0x1E02A}, {0x1E800, 0x1E8C4}, + {0x1E8C7, 0x1E8CF}, {0x1E8D0, 0x1E8D6}, {0x1E900, 0x1E943}, + {0x1E944, 0x1E94A}, {0x1E950, 0x1E959}, {0x1E95E, 0x1E95F}, + {0x1EE00, 0x1EE03}, {0x1EE05, 0x1EE1F}, {0x1EE21, 0x1EE22}, + {0x1EE24, 0x1EE24}, {0x1EE27, 0x1EE27}, {0x1EE29, 0x1EE32}, + {0x1EE34, 0x1EE37}, {0x1EE39, 0x1EE39}, {0x1EE3B, 0x1EE3B}, + {0x1EE42, 0x1EE42}, {0x1EE47, 0x1EE47}, {0x1EE49, 0x1EE49}, + {0x1EE4B, 0x1EE4B}, {0x1EE4D, 0x1EE4F}, {0x1EE51, 0x1EE52}, + {0x1EE54, 0x1EE54}, {0x1EE57, 0x1EE57}, {0x1EE59, 0x1EE59}, + {0x1EE5B, 0x1EE5B}, {0x1EE5D, 0x1EE5D}, {0x1EE5F, 0x1EE5F}, + {0x1EE61, 0x1EE62}, {0x1EE64, 0x1EE64}, {0x1EE67, 0x1EE6A}, + {0x1EE6C, 0x1EE72}, {0x1EE74, 0x1EE77}, {0x1EE79, 0x1EE7C}, + {0x1EE7E, 0x1EE7E}, {0x1EE80, 0x1EE89}, {0x1EE8B, 0x1EE9B}, + {0x1EEA1, 0x1EEA3}, {0x1EEA5, 0x1EEA9}, {0x1EEAB, 0x1EEBB}, + {0x1EEF0, 0x1EEF1}, {0x1F000, 0x1F003}, {0x1F005, 0x1F02B}, + {0x1F030, 0x1F093}, {0x1F0A0, 0x1F0AE}, {0x1F0B1, 0x1F0BF}, + {0x1F0C1, 0x1F0CE}, {0x1F0D1, 0x1F0F5}, {0x1F10B, 0x1F10C}, + {0x1F12E, 0x1F12E}, {0x1F16A, 0x1F16B}, {0x1F1E6, 0x1F1FF}, + {0x1F321, 0x1F32C}, {0x1F336, 0x1F336}, {0x1F37D, 0x1F37D}, + {0x1F394, 0x1F39F}, {0x1F3CB, 0x1F3CE}, {0x1F3D4, 0x1F3DF}, + {0x1F3F1, 0x1F3F3}, {0x1F3F5, 0x1F3F7}, {0x1F43F, 0x1F43F}, + {0x1F441, 0x1F441}, {0x1F4FD, 0x1F4FE}, {0x1F53E, 0x1F54A}, + {0x1F54F, 0x1F54F}, {0x1F568, 0x1F579}, {0x1F57B, 0x1F594}, + {0x1F597, 0x1F5A3}, {0x1F5A5, 0x1F5FA}, {0x1F650, 0x1F67F}, + {0x1F6C6, 0x1F6CB}, {0x1F6CD, 0x1F6CF}, {0x1F6E0, 0x1F6EA}, + {0x1F6F0, 0x1F6F3}, {0x1F700, 0x1F773}, {0x1F780, 0x1F7D4}, + {0x1F800, 0x1F80B}, {0x1F810, 0x1F847}, {0x1F850, 0x1F859}, + {0x1F860, 0x1F887}, {0x1F890, 0x1F8AD}, {0xE0001, 0xE0001}, + {0xE0020, 0xE007F}, +} + +// Condition have flag EastAsianWidth whether the current locale is CJK or not. +type Condition struct { + EastAsianWidth bool +} + +// NewCondition return new instance of Condition which is current locale. +func NewCondition() *Condition { + return &Condition{EastAsianWidth} +} + +// RuneWidth returns the number of cells in r. +// See http://www.unicode.org/reports/tr11/ +func (c *Condition) RuneWidth(r rune) int { + switch { + case r < 0 || r > 0x10FFFF || + inTables(r, nonprint, combining, notassigned): + return 0 + case (c.EastAsianWidth && IsAmbiguousWidth(r)) || + inTables(r, doublewidth, emoji): + return 2 + default: + return 1 + } +} + +// StringWidth return width as you can see +func (c *Condition) StringWidth(s string) (width int) { + for _, r := range []rune(s) { + width += c.RuneWidth(r) + } + return width +} + +// Truncate return string truncated with w cells +func (c *Condition) Truncate(s string, w int, tail string) string { + if c.StringWidth(s) <= w { + return s + } + r := []rune(s) + tw := c.StringWidth(tail) + w -= tw + width := 0 + i := 0 + for ; i < len(r); i++ { + cw := c.RuneWidth(r[i]) + if width+cw > w { + break + } + width += cw + } + return string(r[0:i]) + tail +} + +// Wrap return string wrapped with w cells +func (c *Condition) Wrap(s string, w int) string { + width := 0 + out := "" + for _, r := range []rune(s) { + cw := RuneWidth(r) + if r == '\n' { + out += string(r) + width = 0 + continue + } else if width+cw > w { + out += "\n" + width = 0 + out += string(r) + width += cw + continue + } + out += string(r) + width += cw + } + return out +} + +// FillLeft return string filled in left by spaces in w cells +func (c *Condition) FillLeft(s string, w int) string { + width := c.StringWidth(s) + count := w - width + if count > 0 { + b := make([]byte, count) + for i := range b { + b[i] = ' ' + } + return string(b) + s + } + return s +} + +// FillRight return string filled in left by spaces in w cells +func (c *Condition) FillRight(s string, w int) string { + width := c.StringWidth(s) + count := w - width + if count > 0 { + b := make([]byte, count) + for i := range b { + b[i] = ' ' + } + return s + string(b) + } + return s +} + +// RuneWidth returns the number of cells in r. +// See http://www.unicode.org/reports/tr11/ +func RuneWidth(r rune) int { + return DefaultCondition.RuneWidth(r) +} + +// IsAmbiguousWidth returns whether is ambiguous width or not. +func IsAmbiguousWidth(r rune) bool { + return inTables(r, private, ambiguous) +} + +// IsNeutralWidth returns whether is neutral width or not. +func IsNeutralWidth(r rune) bool { + return inTable(r, neutral) +} + +// StringWidth return width as you can see +func StringWidth(s string) (width int) { + return DefaultCondition.StringWidth(s) +} + +// Truncate return string truncated with w cells +func Truncate(s string, w int, tail string) string { + return DefaultCondition.Truncate(s, w, tail) +} + +// Wrap return string wrapped with w cells +func Wrap(s string, w int) string { + return DefaultCondition.Wrap(s, w) +} + +// FillLeft return string filled in left by spaces in w cells +func FillLeft(s string, w int) string { + return DefaultCondition.FillLeft(s, w) +} + +// FillRight return string filled in left by spaces in w cells +func FillRight(s string, w int) string { + return DefaultCondition.FillRight(s, w) +} diff --git a/backend/vendor/github.com/mattn/go-runewidth/runewidth_js.go b/backend/vendor/github.com/mattn/go-runewidth/runewidth_js.go new file mode 100644 index 00000000..0ce32c5e --- /dev/null +++ b/backend/vendor/github.com/mattn/go-runewidth/runewidth_js.go @@ -0,0 +1,8 @@ +// +build js + +package runewidth + +func IsEastAsian() bool { + // TODO: Implement this for the web. Detect east asian in a compatible way, and return true. + return false +} diff --git a/backend/vendor/github.com/mattn/go-runewidth/runewidth_posix.go b/backend/vendor/github.com/mattn/go-runewidth/runewidth_posix.go new file mode 100644 index 00000000..c579e9a3 --- /dev/null +++ b/backend/vendor/github.com/mattn/go-runewidth/runewidth_posix.go @@ -0,0 +1,77 @@ +// +build !windows,!js + +package runewidth + +import ( + "os" + "regexp" + "strings" +) + +var reLoc = regexp.MustCompile(`^[a-z][a-z][a-z]?(?:_[A-Z][A-Z])?\.(.+)`) + +var mblenTable = map[string]int{ + "utf-8": 6, + "utf8": 6, + "jis": 8, + "eucjp": 3, + "euckr": 2, + "euccn": 2, + "sjis": 2, + "cp932": 2, + "cp51932": 2, + "cp936": 2, + "cp949": 2, + "cp950": 2, + "big5": 2, + "gbk": 2, + "gb2312": 2, +} + +func isEastAsian(locale string) bool { + charset := strings.ToLower(locale) + r := reLoc.FindStringSubmatch(locale) + if len(r) == 2 { + charset = strings.ToLower(r[1]) + } + + if strings.HasSuffix(charset, "@cjk_narrow") { + return false + } + + for pos, b := range []byte(charset) { + if b == '@' { + charset = charset[:pos] + break + } + } + max := 1 + if m, ok := mblenTable[charset]; ok { + max = m + } + if max > 1 && (charset[0] != 'u' || + strings.HasPrefix(locale, "ja") || + strings.HasPrefix(locale, "ko") || + strings.HasPrefix(locale, "zh")) { + return true + } + return false +} + +// IsEastAsian return true if the current locale is CJK +func IsEastAsian() bool { + locale := os.Getenv("LC_CTYPE") + if locale == "" { + locale = os.Getenv("LANG") + } + + // ignore C locale + if locale == "POSIX" || locale == "C" { + return false + } + if len(locale) > 1 && locale[0] == 'C' && (locale[1] == '.' || locale[1] == '-') { + return false + } + + return isEastAsian(locale) +} diff --git a/backend/vendor/github.com/mattn/go-runewidth/runewidth_windows.go b/backend/vendor/github.com/mattn/go-runewidth/runewidth_windows.go new file mode 100644 index 00000000..0258876b --- /dev/null +++ b/backend/vendor/github.com/mattn/go-runewidth/runewidth_windows.go @@ -0,0 +1,25 @@ +package runewidth + +import ( + "syscall" +) + +var ( + kernel32 = syscall.NewLazyDLL("kernel32") + procGetConsoleOutputCP = kernel32.NewProc("GetConsoleOutputCP") +) + +// IsEastAsian return true if the current locale is CJK +func IsEastAsian() bool { + r1, _, _ := procGetConsoleOutputCP.Call() + if r1 == 0 { + return false + } + + switch int(r1) { + case 932, 51932, 936, 949, 950: + return true + } + + return false +} diff --git a/backend/vendor/github.com/modern-go/reflect2/Gopkg.lock b/backend/vendor/github.com/modern-go/reflect2/Gopkg.lock deleted file mode 100644 index 2a3a6989..00000000 --- a/backend/vendor/github.com/modern-go/reflect2/Gopkg.lock +++ /dev/null @@ -1,15 +0,0 @@ -# This file is autogenerated, do not edit; changes may be undone by the next 'dep ensure'. - - -[[projects]] - name = "github.com/modern-go/concurrent" - packages = ["."] - revision = "e0a39a4cb4216ea8db28e22a69f4ec25610d513a" - version = "1.0.0" - -[solve-meta] - analyzer-name = "dep" - analyzer-version = 1 - inputs-digest = "daee8a88b3498b61c5640056665b8b9eea062006f5e596bbb6a3ed9119a11ec7" - solver-name = "gps-cdcl" - solver-version = 1 diff --git a/backend/vendor/github.com/olekukonko/tablewriter/.gitignore b/backend/vendor/github.com/olekukonko/tablewriter/.gitignore new file mode 100644 index 00000000..b66cec63 --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/.gitignore @@ -0,0 +1,15 @@ +# Created by .ignore support plugin (hsz.mobi) +### Go template +# Binaries for programs and plugins +*.exe +*.exe~ +*.dll +*.so +*.dylib + +# Test binary, build with `go test -c` +*.test + +# Output of the go coverage tool, specifically when used with LiteIDE +*.out + diff --git a/backend/vendor/github.com/olekukonko/tablewriter/.travis.yml b/backend/vendor/github.com/olekukonko/tablewriter/.travis.yml new file mode 100644 index 00000000..9c64270e --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/.travis.yml @@ -0,0 +1,14 @@ +language: go + +go: + - 1.1 + - 1.2 + - 1.3 + - 1.4 + - 1.5 + - 1.6 + - 1.7 + - 1.8 + - 1.9 + - "1.10" + - tip diff --git a/backend/vendor/github.com/olekukonko/tablewriter/LICENSE.md b/backend/vendor/github.com/olekukonko/tablewriter/LICENSE.md new file mode 100644 index 00000000..a0769b5c --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/LICENSE.md @@ -0,0 +1,19 @@ +Copyright (C) 2014 by Oleku Konko + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in +all copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN +THE SOFTWARE. diff --git a/backend/vendor/github.com/olekukonko/tablewriter/README.md b/backend/vendor/github.com/olekukonko/tablewriter/README.md new file mode 100644 index 00000000..9c2b139b --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/README.md @@ -0,0 +1,277 @@ +ASCII Table Writer +========= + +[](https://travis-ci.org/olekukonko/tablewriter) +[](https://sourcegraph.com/github.com/olekukonko/tablewriter) +[](https://godoc.org/github.com/olekukonko/tablewriter) + +Generate ASCII table on the fly ... Installation is simple as + + go get github.com/olekukonko/tablewriter + + +#### Features +- Automatic Padding +- Support Multiple Lines +- Supports Alignment +- Support Custom Separators +- Automatic Alignment of numbers & percentage +- Write directly to http , file etc via `io.Writer` +- Read directly from CSV file +- Optional row line via `SetRowLine` +- Normalise table header +- Make CSV Headers optional +- Enable or disable table border +- Set custom footer support +- Optional identical cells merging +- Set custom caption +- Optional reflowing of paragrpahs in multi-line cells. + +#### Example 1 - Basic +```go +data := [][]string{ + []string{"A", "The Good", "500"}, + []string{"B", "The Very very Bad Man", "288"}, + []string{"C", "The Ugly", "120"}, + []string{"D", "The Gopher", "800"}, +} + +table := tablewriter.NewWriter(os.Stdout) +table.SetHeader([]string{"Name", "Sign", "Rating"}) + +for _, v := range data { + table.Append(v) +} +table.Render() // Send output +``` + +##### Output 1 +``` ++------+-----------------------+--------+ +| NAME | SIGN | RATING | ++------+-----------------------+--------+ +| A | The Good | 500 | +| B | The Very very Bad Man | 288 | +| C | The Ugly | 120 | +| D | The Gopher | 800 | ++------+-----------------------+--------+ +``` + +#### Example 2 - Without Border / Footer / Bulk Append +```go +data := [][]string{ + []string{"1/1/2014", "Domain name", "2233", "$10.98"}, + []string{"1/1/2014", "January Hosting", "2233", "$54.95"}, + []string{"1/4/2014", "February Hosting", "2233", "$51.00"}, + []string{"1/4/2014", "February Extra Bandwidth", "2233", "$30.00"}, +} + +table := tablewriter.NewWriter(os.Stdout) +table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) +table.SetFooter([]string{"", "", "Total", "$146.93"}) // Add Footer +table.SetBorder(false) // Set Border to false +table.AppendBulk(data) // Add Bulk Data +table.Render() +``` + +##### Output 2 +``` + + DATE | DESCRIPTION | CV2 | AMOUNT ++----------+--------------------------+-------+---------+ + 1/1/2014 | Domain name | 2233 | $10.98 + 1/1/2014 | January Hosting | 2233 | $54.95 + 1/4/2014 | February Hosting | 2233 | $51.00 + 1/4/2014 | February Extra Bandwidth | 2233 | $30.00 ++----------+--------------------------+-------+---------+ + TOTAL | $146 93 + +-------+---------+ + +``` + + +#### Example 3 - CSV +```go +table, _ := tablewriter.NewCSV(os.Stdout, "testdata/test_info.csv", true) +table.SetAlignment(tablewriter.ALIGN_LEFT) // Set Alignment +table.Render() +``` + +##### Output 3 +``` ++----------+--------------+------+-----+---------+----------------+ +| FIELD | TYPE | NULL | KEY | DEFAULT | EXTRA | ++----------+--------------+------+-----+---------+----------------+ +| user_id | smallint(5) | NO | PRI | NULL | auto_increment | +| username | varchar(10) | NO | | NULL | | +| password | varchar(100) | NO | | NULL | | ++----------+--------------+------+-----+---------+----------------+ +``` + +#### Example 4 - Custom Separator +```go +table, _ := tablewriter.NewCSV(os.Stdout, "testdata/test.csv", true) +table.SetRowLine(true) // Enable row line + +// Change table lines +table.SetCenterSeparator("*") +table.SetColumnSeparator("╪") +table.SetRowSeparator("-") + +table.SetAlignment(tablewriter.ALIGN_LEFT) +table.Render() +``` + +##### Output 4 +``` +*------------*-----------*---------* +╪ FIRST NAME ╪ LAST NAME ╪ SSN ╪ +*------------*-----------*---------* +╪ John ╪ Barry ╪ 123456 ╪ +*------------*-----------*---------* +╪ Kathy ╪ Smith ╪ 687987 ╪ +*------------*-----------*---------* +╪ Bob ╪ McCornick ╪ 3979870 ╪ +*------------*-----------*---------* +``` + +#### Example 5 - Markdown Format +```go +data := [][]string{ + []string{"1/1/2014", "Domain name", "2233", "$10.98"}, + []string{"1/1/2014", "January Hosting", "2233", "$54.95"}, + []string{"1/4/2014", "February Hosting", "2233", "$51.00"}, + []string{"1/4/2014", "February Extra Bandwidth", "2233", "$30.00"}, +} + +table := tablewriter.NewWriter(os.Stdout) +table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) +table.SetBorders(tablewriter.Border{Left: true, Top: false, Right: true, Bottom: false}) +table.SetCenterSeparator("|") +table.AppendBulk(data) // Add Bulk Data +table.Render() +``` + +##### Output 5 +``` +| DATE | DESCRIPTION | CV2 | AMOUNT | +|----------|--------------------------|------|--------| +| 1/1/2014 | Domain name | 2233 | $10.98 | +| 1/1/2014 | January Hosting | 2233 | $54.95 | +| 1/4/2014 | February Hosting | 2233 | $51.00 | +| 1/4/2014 | February Extra Bandwidth | 2233 | $30.00 | +``` + +#### Example 6 - Identical cells merging +```go +data := [][]string{ + []string{"1/1/2014", "Domain name", "1234", "$10.98"}, + []string{"1/1/2014", "January Hosting", "2345", "$54.95"}, + []string{"1/4/2014", "February Hosting", "3456", "$51.00"}, + []string{"1/4/2014", "February Extra Bandwidth", "4567", "$30.00"}, +} + +table := tablewriter.NewWriter(os.Stdout) +table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) +table.SetFooter([]string{"", "", "Total", "$146.93"}) +table.SetAutoMergeCells(true) +table.SetRowLine(true) +table.AppendBulk(data) +table.Render() +``` + +##### Output 6 +``` ++----------+--------------------------+-------+---------+ +| DATE | DESCRIPTION | CV2 | AMOUNT | ++----------+--------------------------+-------+---------+ +| 1/1/2014 | Domain name | 1234 | $10.98 | ++ +--------------------------+-------+---------+ +| | January Hosting | 2345 | $54.95 | ++----------+--------------------------+-------+---------+ +| 1/4/2014 | February Hosting | 3456 | $51.00 | ++ +--------------------------+-------+---------+ +| | February Extra Bandwidth | 4567 | $30.00 | ++----------+--------------------------+-------+---------+ +| TOTAL | $146 93 | ++----------+--------------------------+-------+---------+ +``` + + +#### Table with color +```go +data := [][]string{ + []string{"1/1/2014", "Domain name", "2233", "$10.98"}, + []string{"1/1/2014", "January Hosting", "2233", "$54.95"}, + []string{"1/4/2014", "February Hosting", "2233", "$51.00"}, + []string{"1/4/2014", "February Extra Bandwidth", "2233", "$30.00"}, +} + +table := tablewriter.NewWriter(os.Stdout) +table.SetHeader([]string{"Date", "Description", "CV2", "Amount"}) +table.SetFooter([]string{"", "", "Total", "$146.93"}) // Add Footer +table.SetBorder(false) // Set Border to false + +table.SetHeaderColor(tablewriter.Colors{tablewriter.Bold, tablewriter.BgGreenColor}, + tablewriter.Colors{tablewriter.FgHiRedColor, tablewriter.Bold, tablewriter.BgBlackColor}, + tablewriter.Colors{tablewriter.BgRedColor, tablewriter.FgWhiteColor}, + tablewriter.Colors{tablewriter.BgCyanColor, tablewriter.FgWhiteColor}) + +table.SetColumnColor(tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiBlackColor}, + tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiRedColor}, + tablewriter.Colors{tablewriter.Bold, tablewriter.FgHiBlackColor}, + tablewriter.Colors{tablewriter.Bold, tablewriter.FgBlackColor}) + +table.SetFooterColor(tablewriter.Colors{}, tablewriter.Colors{}, + tablewriter.Colors{tablewriter.Bold}, + tablewriter.Colors{tablewriter.FgHiRedColor}) + +table.AppendBulk(data) +table.Render() +``` + +#### Table with color Output + + +#### Example 6 - Set table caption +```go +data := [][]string{ + []string{"A", "The Good", "500"}, + []string{"B", "The Very very Bad Man", "288"}, + []string{"C", "The Ugly", "120"}, + []string{"D", "The Gopher", "800"}, +} + +table := tablewriter.NewWriter(os.Stdout) +table.SetHeader([]string{"Name", "Sign", "Rating"}) +table.SetCaption(true, "Movie ratings.") + +for _, v := range data { + table.Append(v) +} +table.Render() // Send output +``` + +Note: Caption text will wrap with total width of rendered table. + +##### Output 6 +``` ++------+-----------------------+--------+ +| NAME | SIGN | RATING | ++------+-----------------------+--------+ +| A | The Good | 500 | +| B | The Very very Bad Man | 288 | +| C | The Ugly | 120 | +| D | The Gopher | 800 | ++------+-----------------------+--------+ +Movie ratings. +``` + +#### TODO +- ~~Import Directly from CSV~~ - `done` +- ~~Support for `SetFooter`~~ - `done` +- ~~Support for `SetBorder`~~ - `done` +- ~~Support table with uneven rows~~ - `done` +- ~~Support custom alignment~~ +- General Improvement & Optimisation +- `NewHTML` Parse table from HTML diff --git a/backend/vendor/github.com/olekukonko/tablewriter/csv.go b/backend/vendor/github.com/olekukonko/tablewriter/csv.go new file mode 100644 index 00000000..98878303 --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/csv.go @@ -0,0 +1,52 @@ +// Copyright 2014 Oleku Konko All rights reserved. +// Use of this source code is governed by a MIT +// license that can be found in the LICENSE file. + +// This module is a Table Writer API for the Go Programming Language. +// The protocols were written in pure Go and works on windows and unix systems + +package tablewriter + +import ( + "encoding/csv" + "io" + "os" +) + +// Start A new table by importing from a CSV file +// Takes io.Writer and csv File name +func NewCSV(writer io.Writer, fileName string, hasHeader bool) (*Table, error) { + file, err := os.Open(fileName) + if err != nil { + return &Table{}, err + } + defer file.Close() + csvReader := csv.NewReader(file) + t, err := NewCSVReader(writer, csvReader, hasHeader) + return t, err +} + +// Start a New Table Writer with csv.Reader +// This enables customisation such as reader.Comma = ';' +// See http://golang.org/src/pkg/encoding/csv/reader.go?s=3213:3671#L94 +func NewCSVReader(writer io.Writer, csvReader *csv.Reader, hasHeader bool) (*Table, error) { + t := NewWriter(writer) + if hasHeader { + // Read the first row + headers, err := csvReader.Read() + if err != nil { + return &Table{}, err + } + t.SetHeader(headers) + } + for { + record, err := csvReader.Read() + if err == io.EOF { + break + } else if err != nil { + return &Table{}, err + } + t.Append(record) + } + return t, nil +} diff --git a/backend/vendor/github.com/olekukonko/tablewriter/table.go b/backend/vendor/github.com/olekukonko/tablewriter/table.go new file mode 100644 index 00000000..dec0385f --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/table.go @@ -0,0 +1,839 @@ +// Copyright 2014 Oleku Konko All rights reserved. +// Use of this source code is governed by a MIT +// license that can be found in the LICENSE file. + +// This module is a Table Writer API for the Go Programming Language. +// The protocols were written in pure Go and works on windows and unix systems + +// Create & Generate text based table +package tablewriter + +import ( + "bytes" + "fmt" + "io" + "regexp" + "strings" +) + +const ( + MAX_ROW_WIDTH = 30 +) + +const ( + CENTER = "+" + ROW = "-" + COLUMN = "|" + SPACE = " " + NEWLINE = "\n" +) + +const ( + ALIGN_DEFAULT = iota + ALIGN_CENTER + ALIGN_RIGHT + ALIGN_LEFT +) + +var ( + decimal = regexp.MustCompile(`^-?(?:\d{1,3}(?:,\d{3})*|\d+)(?:\.\d+)?$`) + percent = regexp.MustCompile(`^-?\d+\.?\d*$%$`) +) + +type Border struct { + Left bool + Right bool + Top bool + Bottom bool +} + +type Table struct { + out io.Writer + rows [][]string + lines [][][]string + cs map[int]int + rs map[int]int + headers [][]string + footers [][]string + caption bool + captionText string + autoFmt bool + autoWrap bool + reflowText bool + mW int + pCenter string + pRow string + pColumn string + tColumn int + tRow int + hAlign int + fAlign int + align int + newLine string + rowLine bool + autoMergeCells bool + hdrLine bool + borders Border + colSize int + headerParams []string + columnsParams []string + footerParams []string + columnsAlign []int +} + +// Start New Table +// Take io.Writer Directly +func NewWriter(writer io.Writer) *Table { + t := &Table{ + out: writer, + rows: [][]string{}, + lines: [][][]string{}, + cs: make(map[int]int), + rs: make(map[int]int), + headers: [][]string{}, + footers: [][]string{}, + caption: false, + captionText: "Table caption.", + autoFmt: true, + autoWrap: true, + reflowText: true, + mW: MAX_ROW_WIDTH, + pCenter: CENTER, + pRow: ROW, + pColumn: COLUMN, + tColumn: -1, + tRow: -1, + hAlign: ALIGN_DEFAULT, + fAlign: ALIGN_DEFAULT, + align: ALIGN_DEFAULT, + newLine: NEWLINE, + rowLine: false, + hdrLine: true, + borders: Border{Left: true, Right: true, Bottom: true, Top: true}, + colSize: -1, + headerParams: []string{}, + columnsParams: []string{}, + footerParams: []string{}, + columnsAlign: []int{}} + return t +} + +// Render table output +func (t *Table) Render() { + if t.borders.Top { + t.printLine(true) + } + t.printHeading() + if t.autoMergeCells { + t.printRowsMergeCells() + } else { + t.printRows() + } + if !t.rowLine && t.borders.Bottom { + t.printLine(true) + } + t.printFooter() + + if t.caption { + t.printCaption() + } +} + +const ( + headerRowIdx = -1 + footerRowIdx = -2 +) + +// Set table header +func (t *Table) SetHeader(keys []string) { + t.colSize = len(keys) + for i, v := range keys { + lines := t.parseDimension(v, i, headerRowIdx) + t.headers = append(t.headers, lines) + } +} + +// Set table Footer +func (t *Table) SetFooter(keys []string) { + //t.colSize = len(keys) + for i, v := range keys { + lines := t.parseDimension(v, i, footerRowIdx) + t.footers = append(t.footers, lines) + } +} + +// Set table Caption +func (t *Table) SetCaption(caption bool, captionText ...string) { + t.caption = caption + if len(captionText) == 1 { + t.captionText = captionText[0] + } +} + +// Turn header autoformatting on/off. Default is on (true). +func (t *Table) SetAutoFormatHeaders(auto bool) { + t.autoFmt = auto +} + +// Turn automatic multiline text adjustment on/off. Default is on (true). +func (t *Table) SetAutoWrapText(auto bool) { + t.autoWrap = auto +} + +// Turn automatic reflowing of multiline text when rewrapping. Default is on (true). +func (t *Table) SetReflowDuringAutoWrap(auto bool) { + t.reflowText = auto +} + +// Set the Default column width +func (t *Table) SetColWidth(width int) { + t.mW = width +} + +// Set the minimal width for a column +func (t *Table) SetColMinWidth(column int, width int) { + t.cs[column] = width +} + +// Set the Column Separator +func (t *Table) SetColumnSeparator(sep string) { + t.pColumn = sep +} + +// Set the Row Separator +func (t *Table) SetRowSeparator(sep string) { + t.pRow = sep +} + +// Set the center Separator +func (t *Table) SetCenterSeparator(sep string) { + t.pCenter = sep +} + +// Set Header Alignment +func (t *Table) SetHeaderAlignment(hAlign int) { + t.hAlign = hAlign +} + +// Set Footer Alignment +func (t *Table) SetFooterAlignment(fAlign int) { + t.fAlign = fAlign +} + +// Set Table Alignment +func (t *Table) SetAlignment(align int) { + t.align = align +} + +func (t *Table) SetColumnAlignment(keys []int) { + for _, v := range keys { + switch v { + case ALIGN_CENTER: + break + case ALIGN_LEFT: + break + case ALIGN_RIGHT: + break + default: + v = ALIGN_DEFAULT + } + t.columnsAlign = append(t.columnsAlign, v) + } +} + +// Set New Line +func (t *Table) SetNewLine(nl string) { + t.newLine = nl +} + +// Set Header Line +// This would enable / disable a line after the header +func (t *Table) SetHeaderLine(line bool) { + t.hdrLine = line +} + +// Set Row Line +// This would enable / disable a line on each row of the table +func (t *Table) SetRowLine(line bool) { + t.rowLine = line +} + +// Set Auto Merge Cells +// This would enable / disable the merge of cells with identical values +func (t *Table) SetAutoMergeCells(auto bool) { + t.autoMergeCells = auto +} + +// Set Table Border +// This would enable / disable line around the table +func (t *Table) SetBorder(border bool) { + t.SetBorders(Border{border, border, border, border}) +} + +func (t *Table) SetBorders(border Border) { + t.borders = border +} + +// Append row to table +func (t *Table) Append(row []string) { + rowSize := len(t.headers) + if rowSize > t.colSize { + t.colSize = rowSize + } + + n := len(t.lines) + line := [][]string{} + for i, v := range row { + + // Detect string width + // Detect String height + // Break strings into words + out := t.parseDimension(v, i, n) + + // Append broken words + line = append(line, out) + } + t.lines = append(t.lines, line) +} + +// Allow Support for Bulk Append +// Eliminates repeated for loops +func (t *Table) AppendBulk(rows [][]string) { + for _, row := range rows { + t.Append(row) + } +} + +// NumLines to get the number of lines +func (t *Table) NumLines() int { + return len(t.lines) +} + +// Clear rows +func (t *Table) ClearRows() { + t.lines = [][][]string{} +} + +// Clear footer +func (t *Table) ClearFooter() { + t.footers = [][]string{} +} + +// Print line based on row width +func (t *Table) printLine(nl bool) { + fmt.Fprint(t.out, t.pCenter) + for i := 0; i < len(t.cs); i++ { + v := t.cs[i] + fmt.Fprintf(t.out, "%s%s%s%s", + t.pRow, + strings.Repeat(string(t.pRow), v), + t.pRow, + t.pCenter) + } + if nl { + fmt.Fprint(t.out, t.newLine) + } +} + +// Print line based on row width with our without cell separator +func (t *Table) printLineOptionalCellSeparators(nl bool, displayCellSeparator []bool) { + fmt.Fprint(t.out, t.pCenter) + for i := 0; i < len(t.cs); i++ { + v := t.cs[i] + if i > len(displayCellSeparator) || displayCellSeparator[i] { + // Display the cell separator + fmt.Fprintf(t.out, "%s%s%s%s", + t.pRow, + strings.Repeat(string(t.pRow), v), + t.pRow, + t.pCenter) + } else { + // Don't display the cell separator for this cell + fmt.Fprintf(t.out, "%s%s", + strings.Repeat(" ", v+2), + t.pCenter) + } + } + if nl { + fmt.Fprint(t.out, t.newLine) + } +} + +// Return the PadRight function if align is left, PadLeft if align is right, +// and Pad by default +func pad(align int) func(string, string, int) string { + padFunc := Pad + switch align { + case ALIGN_LEFT: + padFunc = PadRight + case ALIGN_RIGHT: + padFunc = PadLeft + } + return padFunc +} + +// Print heading information +func (t *Table) printHeading() { + // Check if headers is available + if len(t.headers) < 1 { + return + } + + // Identify last column + end := len(t.cs) - 1 + + // Get pad function + padFunc := pad(t.hAlign) + + // Checking for ANSI escape sequences for header + is_esc_seq := false + if len(t.headerParams) > 0 { + is_esc_seq = true + } + + // Maximum height. + max := t.rs[headerRowIdx] + + // Print Heading + for x := 0; x < max; x++ { + // Check if border is set + // Replace with space if not set + fmt.Fprint(t.out, ConditionString(t.borders.Left, t.pColumn, SPACE)) + + for y := 0; y <= end; y++ { + v := t.cs[y] + h := "" + if y < len(t.headers) && x < len(t.headers[y]) { + h = t.headers[y][x] + } + if t.autoFmt { + h = Title(h) + } + pad := ConditionString((y == end && !t.borders.Left), SPACE, t.pColumn) + + if is_esc_seq { + fmt.Fprintf(t.out, " %s %s", + format(padFunc(h, SPACE, v), + t.headerParams[y]), pad) + } else { + fmt.Fprintf(t.out, " %s %s", + padFunc(h, SPACE, v), + pad) + } + } + // Next line + fmt.Fprint(t.out, t.newLine) + } + if t.hdrLine { + t.printLine(true) + } +} + +// Print heading information +func (t *Table) printFooter() { + // Check if headers is available + if len(t.footers) < 1 { + return + } + + // Only print line if border is not set + if !t.borders.Bottom { + t.printLine(true) + } + + // Identify last column + end := len(t.cs) - 1 + + // Get pad function + padFunc := pad(t.fAlign) + + // Checking for ANSI escape sequences for header + is_esc_seq := false + if len(t.footerParams) > 0 { + is_esc_seq = true + } + + // Maximum height. + max := t.rs[footerRowIdx] + + // Print Footer + erasePad := make([]bool, len(t.footers)) + for x := 0; x < max; x++ { + // Check if border is set + // Replace with space if not set + fmt.Fprint(t.out, ConditionString(t.borders.Bottom, t.pColumn, SPACE)) + + for y := 0; y <= end; y++ { + v := t.cs[y] + f := "" + if y < len(t.footers) && x < len(t.footers[y]) { + f = t.footers[y][x] + } + if t.autoFmt { + f = Title(f) + } + pad := ConditionString((y == end && !t.borders.Top), SPACE, t.pColumn) + + if erasePad[y] || (x == 0 && len(f) == 0) { + pad = SPACE + erasePad[y] = true + } + + if is_esc_seq { + fmt.Fprintf(t.out, " %s %s", + format(padFunc(f, SPACE, v), + t.footerParams[y]), pad) + } else { + fmt.Fprintf(t.out, " %s %s", + padFunc(f, SPACE, v), + pad) + } + + //fmt.Fprintf(t.out, " %s %s", + // padFunc(f, SPACE, v), + // pad) + } + // Next line + fmt.Fprint(t.out, t.newLine) + //t.printLine(true) + } + + hasPrinted := false + + for i := 0; i <= end; i++ { + v := t.cs[i] + pad := t.pRow + center := t.pCenter + length := len(t.footers[i][0]) + + if length > 0 { + hasPrinted = true + } + + // Set center to be space if length is 0 + if length == 0 && !t.borders.Right { + center = SPACE + } + + // Print first junction + if i == 0 { + fmt.Fprint(t.out, center) + } + + // Pad With space of length is 0 + if length == 0 { + pad = SPACE + } + // Ignore left space of it has printed before + if hasPrinted || t.borders.Left { + pad = t.pRow + center = t.pCenter + } + + // Change Center start position + if center == SPACE { + if i < end && len(t.footers[i+1][0]) != 0 { + center = t.pCenter + } + } + + // Print the footer + fmt.Fprintf(t.out, "%s%s%s%s", + pad, + strings.Repeat(string(pad), v), + pad, + center) + + } + + fmt.Fprint(t.out, t.newLine) +} + +// Print caption text +func (t Table) printCaption() { + width := t.getTableWidth() + paragraph, _ := WrapString(t.captionText, width) + for linecount := 0; linecount < len(paragraph); linecount++ { + fmt.Fprintln(t.out, paragraph[linecount]) + } +} + +// Calculate the total number of characters in a row +func (t Table) getTableWidth() int { + var chars int + for _, v := range t.cs { + chars += v + } + + // Add chars, spaces, seperators to calculate the total width of the table. + // ncols := t.colSize + // spaces := ncols * 2 + // seps := ncols + 1 + + return (chars + (3 * t.colSize) + 2) +} + +func (t Table) printRows() { + for i, lines := range t.lines { + t.printRow(lines, i) + } +} + +func (t *Table) fillAlignment(num int) { + if len(t.columnsAlign) < num { + t.columnsAlign = make([]int, num) + for i := range t.columnsAlign { + t.columnsAlign[i] = t.align + } + } +} + +// Print Row Information +// Adjust column alignment based on type + +func (t *Table) printRow(columns [][]string, rowIdx int) { + // Get Maximum Height + max := t.rs[rowIdx] + total := len(columns) + + // TODO Fix uneven col size + // if total < t.colSize { + // for n := t.colSize - total; n < t.colSize ; n++ { + // columns = append(columns, []string{SPACE}) + // t.cs[n] = t.mW + // } + //} + + // Pad Each Height + pads := []int{} + + // Checking for ANSI escape sequences for columns + is_esc_seq := false + if len(t.columnsParams) > 0 { + is_esc_seq = true + } + t.fillAlignment(total) + + for i, line := range columns { + length := len(line) + pad := max - length + pads = append(pads, pad) + for n := 0; n < pad; n++ { + columns[i] = append(columns[i], " ") + } + } + //fmt.Println(max, "\n") + for x := 0; x < max; x++ { + for y := 0; y < total; y++ { + + // Check if border is set + fmt.Fprint(t.out, ConditionString((!t.borders.Left && y == 0), SPACE, t.pColumn)) + + fmt.Fprintf(t.out, SPACE) + str := columns[y][x] + + // Embedding escape sequence with column value + if is_esc_seq { + str = format(str, t.columnsParams[y]) + } + + // This would print alignment + // Default alignment would use multiple configuration + switch t.columnsAlign[y] { + case ALIGN_CENTER: // + fmt.Fprintf(t.out, "%s", Pad(str, SPACE, t.cs[y])) + case ALIGN_RIGHT: + fmt.Fprintf(t.out, "%s", PadLeft(str, SPACE, t.cs[y])) + case ALIGN_LEFT: + fmt.Fprintf(t.out, "%s", PadRight(str, SPACE, t.cs[y])) + default: + if decimal.MatchString(strings.TrimSpace(str)) || percent.MatchString(strings.TrimSpace(str)) { + fmt.Fprintf(t.out, "%s", PadLeft(str, SPACE, t.cs[y])) + } else { + fmt.Fprintf(t.out, "%s", PadRight(str, SPACE, t.cs[y])) + + // TODO Custom alignment per column + //if max == 1 || pads[y] > 0 { + // fmt.Fprintf(t.out, "%s", Pad(str, SPACE, t.cs[y])) + //} else { + // fmt.Fprintf(t.out, "%s", PadRight(str, SPACE, t.cs[y])) + //} + + } + } + fmt.Fprintf(t.out, SPACE) + } + // Check if border is set + // Replace with space if not set + fmt.Fprint(t.out, ConditionString(t.borders.Left, t.pColumn, SPACE)) + fmt.Fprint(t.out, t.newLine) + } + + if t.rowLine { + t.printLine(true) + } +} + +// Print the rows of the table and merge the cells that are identical +func (t *Table) printRowsMergeCells() { + var previousLine []string + var displayCellBorder []bool + var tmpWriter bytes.Buffer + for i, lines := range t.lines { + // We store the display of the current line in a tmp writer, as we need to know which border needs to be print above + previousLine, displayCellBorder = t.printRowMergeCells(&tmpWriter, lines, i, previousLine) + if i > 0 { //We don't need to print borders above first line + if t.rowLine { + t.printLineOptionalCellSeparators(true, displayCellBorder) + } + } + tmpWriter.WriteTo(t.out) + } + //Print the end of the table + if t.rowLine { + t.printLine(true) + } +} + +// Print Row Information to a writer and merge identical cells. +// Adjust column alignment based on type + +func (t *Table) printRowMergeCells(writer io.Writer, columns [][]string, rowIdx int, previousLine []string) ([]string, []bool) { + // Get Maximum Height + max := t.rs[rowIdx] + total := len(columns) + + // Pad Each Height + pads := []int{} + + for i, line := range columns { + length := len(line) + pad := max - length + pads = append(pads, pad) + for n := 0; n < pad; n++ { + columns[i] = append(columns[i], " ") + } + } + + var displayCellBorder []bool + t.fillAlignment(total) + for x := 0; x < max; x++ { + for y := 0; y < total; y++ { + + // Check if border is set + fmt.Fprint(writer, ConditionString((!t.borders.Left && y == 0), SPACE, t.pColumn)) + + fmt.Fprintf(writer, SPACE) + + str := columns[y][x] + + if t.autoMergeCells { + //Store the full line to merge mutli-lines cells + fullLine := strings.Join(columns[y], " ") + if len(previousLine) > y && fullLine == previousLine[y] && fullLine != "" { + // If this cell is identical to the one above but not empty, we don't display the border and keep the cell empty. + displayCellBorder = append(displayCellBorder, false) + str = "" + } else { + // First line or different content, keep the content and print the cell border + displayCellBorder = append(displayCellBorder, true) + } + } + + // This would print alignment + // Default alignment would use multiple configuration + switch t.columnsAlign[y] { + case ALIGN_CENTER: // + fmt.Fprintf(writer, "%s", Pad(str, SPACE, t.cs[y])) + case ALIGN_RIGHT: + fmt.Fprintf(writer, "%s", PadLeft(str, SPACE, t.cs[y])) + case ALIGN_LEFT: + fmt.Fprintf(writer, "%s", PadRight(str, SPACE, t.cs[y])) + default: + if decimal.MatchString(strings.TrimSpace(str)) || percent.MatchString(strings.TrimSpace(str)) { + fmt.Fprintf(writer, "%s", PadLeft(str, SPACE, t.cs[y])) + } else { + fmt.Fprintf(writer, "%s", PadRight(str, SPACE, t.cs[y])) + } + } + fmt.Fprintf(writer, SPACE) + } + // Check if border is set + // Replace with space if not set + fmt.Fprint(writer, ConditionString(t.borders.Left, t.pColumn, SPACE)) + fmt.Fprint(writer, t.newLine) + } + + //The new previous line is the current one + previousLine = make([]string, total) + for y := 0; y < total; y++ { + previousLine[y] = strings.Join(columns[y], " ") //Store the full line for multi-lines cells + } + //Returns the newly added line and wether or not a border should be displayed above. + return previousLine, displayCellBorder +} + +func (t *Table) parseDimension(str string, colKey, rowKey int) []string { + var ( + raw []string + maxWidth int + ) + + raw = getLines(str) + maxWidth = 0 + for _, line := range raw { + if w := DisplayWidth(line); w > maxWidth { + maxWidth = w + } + } + + // If wrapping, ensure that all paragraphs in the cell fit in the + // specified width. + if t.autoWrap { + // If there's a maximum allowed width for wrapping, use that. + if maxWidth > t.mW { + maxWidth = t.mW + } + + // In the process of doing so, we need to recompute maxWidth. This + // is because perhaps a word in the cell is longer than the + // allowed maximum width in t.mW. + newMaxWidth := maxWidth + newRaw := make([]string, 0, len(raw)) + + if t.reflowText { + // Make a single paragraph of everything. + raw = []string{strings.Join(raw, " ")} + } + for i, para := range raw { + paraLines, _ := WrapString(para, maxWidth) + for _, line := range paraLines { + if w := DisplayWidth(line); w > newMaxWidth { + newMaxWidth = w + } + } + if i > 0 { + newRaw = append(newRaw, " ") + } + newRaw = append(newRaw, paraLines...) + } + raw = newRaw + maxWidth = newMaxWidth + } + + // Store the new known maximum width. + v, ok := t.cs[colKey] + if !ok || v < maxWidth || v == 0 { + t.cs[colKey] = maxWidth + } + + // Remember the number of lines for the row printer. + h := len(raw) + v, ok = t.rs[rowKey] + + if !ok || v < h || v == 0 { + t.rs[rowKey] = h + } + //fmt.Printf("Raw %+v %d\n", raw, len(raw)) + return raw +} diff --git a/backend/vendor/github.com/olekukonko/tablewriter/table_with_color.go b/backend/vendor/github.com/olekukonko/tablewriter/table_with_color.go new file mode 100644 index 00000000..5a4a53ec --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/table_with_color.go @@ -0,0 +1,134 @@ +package tablewriter + +import ( + "fmt" + "strconv" + "strings" +) + +const ESC = "\033" +const SEP = ";" + +const ( + BgBlackColor int = iota + 40 + BgRedColor + BgGreenColor + BgYellowColor + BgBlueColor + BgMagentaColor + BgCyanColor + BgWhiteColor +) + +const ( + FgBlackColor int = iota + 30 + FgRedColor + FgGreenColor + FgYellowColor + FgBlueColor + FgMagentaColor + FgCyanColor + FgWhiteColor +) + +const ( + BgHiBlackColor int = iota + 100 + BgHiRedColor + BgHiGreenColor + BgHiYellowColor + BgHiBlueColor + BgHiMagentaColor + BgHiCyanColor + BgHiWhiteColor +) + +const ( + FgHiBlackColor int = iota + 90 + FgHiRedColor + FgHiGreenColor + FgHiYellowColor + FgHiBlueColor + FgHiMagentaColor + FgHiCyanColor + FgHiWhiteColor +) + +const ( + Normal = 0 + Bold = 1 + UnderlineSingle = 4 + Italic +) + +type Colors []int + +func startFormat(seq string) string { + return fmt.Sprintf("%s[%sm", ESC, seq) +} + +func stopFormat() string { + return fmt.Sprintf("%s[%dm", ESC, Normal) +} + +// Making the SGR (Select Graphic Rendition) sequence. +func makeSequence(codes []int) string { + codesInString := []string{} + for _, code := range codes { + codesInString = append(codesInString, strconv.Itoa(code)) + } + return strings.Join(codesInString, SEP) +} + +// Adding ANSI escape sequences before and after string +func format(s string, codes interface{}) string { + var seq string + + switch v := codes.(type) { + + case string: + seq = v + case []int: + seq = makeSequence(v) + default: + return s + } + + if len(seq) == 0 { + return s + } + return startFormat(seq) + s + stopFormat() +} + +// Adding header colors (ANSI codes) +func (t *Table) SetHeaderColor(colors ...Colors) { + if t.colSize != len(colors) { + panic("Number of header colors must be equal to number of headers.") + } + for i := 0; i < len(colors); i++ { + t.headerParams = append(t.headerParams, makeSequence(colors[i])) + } +} + +// Adding column colors (ANSI codes) +func (t *Table) SetColumnColor(colors ...Colors) { + if t.colSize != len(colors) { + panic("Number of column colors must be equal to number of headers.") + } + for i := 0; i < len(colors); i++ { + t.columnsParams = append(t.columnsParams, makeSequence(colors[i])) + } +} + +// Adding column colors (ANSI codes) +func (t *Table) SetFooterColor(colors ...Colors) { + if len(t.footers) != len(colors) { + panic("Number of footer colors must be equal to number of footer.") + } + for i := 0; i < len(colors); i++ { + t.footerParams = append(t.footerParams, makeSequence(colors[i])) + } +} + +func Color(colors ...int) []int { + return colors +} diff --git a/backend/vendor/github.com/olekukonko/tablewriter/util.go b/backend/vendor/github.com/olekukonko/tablewriter/util.go new file mode 100644 index 00000000..9e8f0cbb --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/util.go @@ -0,0 +1,93 @@ +// Copyright 2014 Oleku Konko All rights reserved. +// Use of this source code is governed by a MIT +// license that can be found in the LICENSE file. + +// This module is a Table Writer API for the Go Programming Language. +// The protocols were written in pure Go and works on windows and unix systems + +package tablewriter + +import ( + "math" + "regexp" + "strings" + + "github.com/mattn/go-runewidth" +) + +var ansi = regexp.MustCompile("\033\\[(?:[0-9]{1,3}(?:;[0-9]{1,3})*)?[m|K]") + +func DisplayWidth(str string) int { + return runewidth.StringWidth(ansi.ReplaceAllLiteralString(str, "")) +} + +// Simple Condition for string +// Returns value based on condition +func ConditionString(cond bool, valid, inValid string) string { + if cond { + return valid + } + return inValid +} + +func isNumOrSpace(r rune) bool { + return ('0' <= r && r <= '9') || r == ' ' +} + +// Format Table Header +// Replace _ , . and spaces +func Title(name string) string { + origLen := len(name) + rs := []rune(name) + for i, r := range rs { + switch r { + case '_': + rs[i] = ' ' + case '.': + // ignore floating number 0.0 + if (i != 0 && !isNumOrSpace(rs[i-1])) || (i != len(rs)-1 && !isNumOrSpace(rs[i+1])) { + rs[i] = ' ' + } + } + } + name = string(rs) + name = strings.TrimSpace(name) + if len(name) == 0 && origLen > 0 { + // Keep at least one character. This is important to preserve + // empty lines in multi-line headers/footers. + name = " " + } + return strings.ToUpper(name) +} + +// Pad String +// Attempts to play string in the center +func Pad(s, pad string, width int) string { + gap := width - DisplayWidth(s) + if gap > 0 { + gapLeft := int(math.Ceil(float64(gap / 2))) + gapRight := gap - gapLeft + return strings.Repeat(string(pad), gapLeft) + s + strings.Repeat(string(pad), gapRight) + } + return s +} + +// Pad String Right position +// This would pace string at the left side fo the screen +func PadRight(s, pad string, width int) string { + gap := width - DisplayWidth(s) + if gap > 0 { + return s + strings.Repeat(string(pad), gap) + } + return s +} + +// Pad String Left position +// This would pace string at the right side fo the screen +func PadLeft(s, pad string, width int) string { + gap := width - DisplayWidth(s) + if gap > 0 { + return strings.Repeat(string(pad), gap) + s + } + return s +} diff --git a/backend/vendor/github.com/olekukonko/tablewriter/wrap.go b/backend/vendor/github.com/olekukonko/tablewriter/wrap.go new file mode 100644 index 00000000..a092ee1f --- /dev/null +++ b/backend/vendor/github.com/olekukonko/tablewriter/wrap.go @@ -0,0 +1,99 @@ +// Copyright 2014 Oleku Konko All rights reserved. +// Use of this source code is governed by a MIT +// license that can be found in the LICENSE file. + +// This module is a Table Writer API for the Go Programming Language. +// The protocols were written in pure Go and works on windows and unix systems + +package tablewriter + +import ( + "math" + "strings" + + "github.com/mattn/go-runewidth" +) + +var ( + nl = "\n" + sp = " " +) + +const defaultPenalty = 1e5 + +// Wrap wraps s into a paragraph of lines of length lim, with minimal +// raggedness. +func WrapString(s string, lim int) ([]string, int) { + words := strings.Split(strings.Replace(s, nl, sp, -1), sp) + var lines []string + max := 0 + for _, v := range words { + max = runewidth.StringWidth(v) + if max > lim { + lim = max + } + } + for _, line := range WrapWords(words, 1, lim, defaultPenalty) { + lines = append(lines, strings.Join(line, sp)) + } + return lines, lim +} + +// WrapWords is the low-level line-breaking algorithm, useful if you need more +// control over the details of the text wrapping process. For most uses, +// WrapString will be sufficient and more convenient. +// +// WrapWords splits a list of words into lines with minimal "raggedness", +// treating each rune as one unit, accounting for spc units between adjacent +// words on each line, and attempting to limit lines to lim units. Raggedness +// is the total error over all lines, where error is the square of the +// difference of the length of the line and lim. Too-long lines (which only +// happen when a single word is longer than lim units) have pen penalty units +// added to the error. +func WrapWords(words []string, spc, lim, pen int) [][]string { + n := len(words) + + length := make([][]int, n) + for i := 0; i < n; i++ { + length[i] = make([]int, n) + length[i][i] = runewidth.StringWidth(words[i]) + for j := i + 1; j < n; j++ { + length[i][j] = length[i][j-1] + spc + runewidth.StringWidth(words[j]) + } + } + nbrk := make([]int, n) + cost := make([]int, n) + for i := range cost { + cost[i] = math.MaxInt32 + } + for i := n - 1; i >= 0; i-- { + if length[i][n-1] <= lim { + cost[i] = 0 + nbrk[i] = n + } else { + for j := i + 1; j < n; j++ { + d := lim - length[i][j-1] + c := d*d + cost[j] + if length[i][j-1] > lim { + c += pen // too-long lines get a worse penalty + } + if c < cost[i] { + cost[i] = c + nbrk[i] = j + } + } + } + } + var lines [][]string + i := 0 + for i < n { + lines = append(lines, words[i:nbrk[i]]) + i = nbrk[i] + } + return lines +} + +// getLines decomposes a multiline string into a slice of strings. +func getLines(s string) []string { + return strings.Split(s, nl) +} diff --git a/backend/vendor/github.com/royeo/dingrobot/LICENSE b/backend/vendor/github.com/royeo/dingrobot/LICENSE new file mode 100644 index 00000000..e2c20381 --- /dev/null +++ b/backend/vendor/github.com/royeo/dingrobot/LICENSE @@ -0,0 +1,21 @@ +MIT License + +Copyright (c) 2018 Royeo + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. \ No newline at end of file diff --git a/backend/vendor/github.com/royeo/dingrobot/README.md b/backend/vendor/github.com/royeo/dingrobot/README.md new file mode 100644 index 00000000..c76c6313 --- /dev/null +++ b/backend/vendor/github.com/royeo/dingrobot/README.md @@ -0,0 +1,110 @@ +# Dingrobot + +钉钉自定义机器人 Golang API. + +支持的消息类型: +- 文本类型 +- link 类型 +- markdown 类型 +- 整体跳转 ActionCard 类型 + +## Installation + +Install: + +```sh +go get -u github.com/royeo/dingrobot +``` + +Import: + +```go +import "github.com/royeo/dingrobot" +``` + +## Quick start + +发送文本类型的消息: + +```go +func main() { + // You should replace the webhook here with your own. + webhook := "https://oapi.dingtalk.com/robot/send?access_token=xxx" + robot := dingrobot.NewRobot(webhook) + + content := "我就是我, @1825718XXXX 是不一样的烟火" + atMobiles := []string{"1825718XXXX"} + isAtAll := false + + err := robot.SendText(content, atMobiles, isAtAll) + if err != nil { + log.Fatal(err) + } +} +``` + +发送 link 类型的消息: + +```go +func main() { + // You should replace the webhook here with your own. + webhook := "https://oapi.dingtalk.com/robot/send?access_token=xxx" + robot := dingrobot.NewRobot(webhook) + + title := "自定义机器人协议" + text := "群机器人是钉钉群的高级扩展功能。群机器人可以将第三方服务的信息聚合到群聊中,实现自动化的信息同步。例如:通过聚合GitHub,GitLab等源码管理服务,实现源码更新同步;通过聚合Trello,JIRA等项目协调服务,实现项目信息同步。不仅如此,群机器人支持Webhook协议的自定义接入,支持更多可能性,例如:你可将运维报警提醒通过自定义机器人聚合到钉钉群。" + messageUrl := "https://open-doc.dingtalk.com/docs/doc.htm?spm=a219a.7629140.0.0.Rqyvqo&treeId=257&articleId=105735&docType=1" + picUrl := "" + + err := robot.SendLink(title, text, messageUrl, picUrl) + if err != nil { + log.Fatal(err) + } +} +``` + +发送 markdown 类型的消息: + +```go +func main() { + // You should replace the webhook here with your own. + webhook := "https://oapi.dingtalk.com/robot/send?access_token=xxx" + robot := dingrobot.NewRobot(webhook) + + title := "杭州天气" + text := "#### 杭州天气 \n > 9度,@1825718XXXX 西北风1级,空气良89,相对温度73%\n\n > \n > ###### 10点20分发布 [天气](http://www.thinkpage.cn/) " + atMobiles := []string{"1825718XXXX"} + isAtAll := false + + err := robot.SendMarkdown(title, text, atMobiles, isAtAll) + if err != nil { + log.Fatal(err) + } +} +``` + +发送整体跳转 ActionCard 类型的消息: + +```go +func main() { + // You should replace the webhook here with your own. + webhook := "https://oapi.dingtalk.com/robot/send?access_token=xxx" + robot := dingrobot.NewRobot(webhook) + + title := "乔布斯 20 年前想打造一间苹果咖啡厅,而它正是 Apple Store 的前身" + text := " \n #### 乔布斯 20 年前想打造的苹果咖啡厅 \n\n Apple Store 的设计正从原来满满的科技感走向生活化,而其生活化的走向其实可以追溯到 20 年前苹果一个建立咖啡馆的计划" + singleTitle := "阅读全文" + singleURL := "https://www.dingtalk.com/" + btnOrientation := "0" + hideAvatar := "0" + + err := robot.SendActionCard(title, text, singleTitle, singleURL, btnOrientation, hideAvatar) + if err != nil { + log.Fatal(err) + } +} +``` + +## License + +MIT Copyright (c) 2018 Royeo diff --git a/backend/vendor/github.com/royeo/dingrobot/dingrobot.go b/backend/vendor/github.com/royeo/dingrobot/dingrobot.go new file mode 100644 index 00000000..cd5b65b0 --- /dev/null +++ b/backend/vendor/github.com/royeo/dingrobot/dingrobot.go @@ -0,0 +1,118 @@ +package dingrobot + +import ( + "bytes" + "encoding/json" + "fmt" + "io/ioutil" + "net/http" +) + +// Roboter is the interface implemented by Robot that can send multiple types of messages. +type Roboter interface { + SendText(content string, atMobiles []string, isAtAll bool) error + SendLink(title, text, messageURL, picURL string) error + SendMarkdown(title, text string, atMobiles []string, isAtAll bool) error + SendActionCard(title, text, singleTitle, singleURL, btnOrientation, hideAvatar string) error +} + +// Robot represents a dingtalk custom robot that can send messages to groups. +type Robot struct { + Webhook string +} + +// NewRobot returns a roboter that can send messages. +func NewRobot(webhook string) Roboter { + return Robot{Webhook: webhook} +} + +// SendText send a text type message. +func (r Robot) SendText(content string, atMobiles []string, isAtAll bool) error { + return r.send(&textMessage{ + MsgType: msgTypeText, + Text: textParams{ + Content: content, + }, + At: atParams{ + AtMobiles: atMobiles, + IsAtAll: isAtAll, + }, + }) +} + +// SendLink send a link type message. +func (r Robot) SendLink(title, text, messageURL, picURL string) error { + return r.send(&linkMessage{ + MsgType: msgTypeLink, + Link: linkParams{ + Title: title, + Text: text, + MessageURL: messageURL, + PicURL: picURL, + }, + }) +} + +// SendMarkdown send a markdown type message. +func (r Robot) SendMarkdown(title, text string, atMobiles []string, isAtAll bool) error { + return r.send(&markdownMessage{ + MsgType: msgTypeMarkdown, + Markdown: markdownParams{ + Title: title, + Text: text, + }, + At: atParams{ + AtMobiles: atMobiles, + IsAtAll: isAtAll, + }, + }) +} + +// SendActionCard send a action card type message. +func (r Robot) SendActionCard(title, text, singleTitle, singleURL, btnOrientation, hideAvatar string) error { + return r.send(&actionCardMessage{ + MsgType: msgTypeActionCard, + ActionCard: actionCardParams{ + Title: title, + Text: text, + SingleTitle: singleTitle, + SingleURL: singleURL, + BtnOrientation: btnOrientation, + HideAvatar: hideAvatar, + }, + }) +} + +type dingResponse struct { + Errcode int + Errmsg string +} + +func (r Robot) send(msg interface{}) error { + m, err := json.Marshal(msg) + if err != nil { + return err + } + + resp, err := http.Post(r.Webhook, "application/json", bytes.NewReader(m)) + if err != nil { + return err + } + defer resp.Body.Close() + + data, err := ioutil.ReadAll(resp.Body) + if err != nil { + return err + } + + var dr dingResponse + err = json.Unmarshal(data, &dr) + if err != nil { + return err + } + if dr.Errcode != 0 { + return fmt.Errorf("dingrobot send failed: %v", dr.Errmsg) + } + + return nil +} diff --git a/backend/vendor/github.com/royeo/dingrobot/message.go b/backend/vendor/github.com/royeo/dingrobot/message.go new file mode 100644 index 00000000..82f286f8 --- /dev/null +++ b/backend/vendor/github.com/royeo/dingrobot/message.go @@ -0,0 +1,60 @@ +package dingrobot + +const ( + msgTypeText = "text" + msgTypeLink = "link" + msgTypeMarkdown = "markdown" + msgTypeActionCard = "actionCard" +) + +type textMessage struct { + MsgType string `json:"msgtype"` + Text textParams `json:"text"` + At atParams `json:"at"` +} + +type textParams struct { + Content string `json:"content"` +} + +type atParams struct { + AtMobiles []string `json:"atMobiles,omitempty"` + IsAtAll bool `json:"isAtAll,omitempty"` +} + +type linkMessage struct { + MsgType string `json:"msgtype"` + Link linkParams `json:"link"` +} + +type linkParams struct { + Title string `json:"title"` + Text string `json:"text"` + MessageURL string `json:"messageUrl"` + PicURL string `json:"picUrl,omitempty"` +} + +type markdownMessage struct { + MsgType string `json:"msgtype"` + Markdown markdownParams `json:"markdown"` + At atParams `json:"at"` +} + +type markdownParams struct { + Title string `json:"title"` + Text string `json:"text"` +} + +type actionCardMessage struct { + MsgType string `json:"msgtype"` + ActionCard actionCardParams `json:"actionCard"` +} + +type actionCardParams struct { + Title string `json:"title"` + Text string `json:"text"` + SingleTitle string `json:"singleTitle"` + SingleURL string `json:"singleURL"` + BtnOrientation string `json:"btnOrientation,omitempty"` + HideAvatar string `json:"hideAvatar,omitempty"` +} diff --git a/backend/vendor/github.com/shurcooL/sanitized_anchor_name/.travis.yml b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/.travis.yml new file mode 100644 index 00000000..93b1fcdb --- /dev/null +++ b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/.travis.yml @@ -0,0 +1,16 @@ +sudo: false +language: go +go: + - 1.x + - master +matrix: + allow_failures: + - go: master + fast_finish: true +install: + - # Do nothing. This is needed to prevent default install action "go get -t -v ./..." from happening here (we want it to happen inside script step). +script: + - go get -t -v ./... + - diff -u <(echo -n) <(gofmt -d -s .) + - go tool vet . + - go test -v -race ./... diff --git a/backend/vendor/github.com/shurcooL/sanitized_anchor_name/LICENSE b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/LICENSE new file mode 100644 index 00000000..c35c17af --- /dev/null +++ b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/LICENSE @@ -0,0 +1,21 @@ +MIT License + +Copyright (c) 2015 Dmitri Shuralyov + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. diff --git a/backend/vendor/github.com/shurcooL/sanitized_anchor_name/README.md b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/README.md new file mode 100644 index 00000000..670bf0fe --- /dev/null +++ b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/README.md @@ -0,0 +1,36 @@ +sanitized_anchor_name +===================== + +[](https://travis-ci.org/shurcooL/sanitized_anchor_name) [](https://godoc.org/github.com/shurcooL/sanitized_anchor_name) + +Package sanitized_anchor_name provides a func to create sanitized anchor names. + +Its logic can be reused by multiple packages to create interoperable anchor names +and links to those anchors. + +At this time, it does not try to ensure that generated anchor names +are unique, that responsibility falls on the caller. + +Installation +------------ + +```bash +go get -u github.com/shurcooL/sanitized_anchor_name +``` + +Example +------- + +```Go +anchorName := sanitized_anchor_name.Create("This is a header") + +fmt.Println(anchorName) + +// Output: +// this-is-a-header +``` + +License +------- + +- [MIT License](LICENSE) diff --git a/backend/vendor/github.com/shurcooL/sanitized_anchor_name/go.mod b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/go.mod new file mode 100644 index 00000000..1e255347 --- /dev/null +++ b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/go.mod @@ -0,0 +1 @@ +module github.com/shurcooL/sanitized_anchor_name diff --git a/backend/vendor/github.com/shurcooL/sanitized_anchor_name/main.go b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/main.go new file mode 100644 index 00000000..6a77d124 --- /dev/null +++ b/backend/vendor/github.com/shurcooL/sanitized_anchor_name/main.go @@ -0,0 +1,29 @@ +// Package sanitized_anchor_name provides a func to create sanitized anchor names. +// +// Its logic can be reused by multiple packages to create interoperable anchor names +// and links to those anchors. +// +// At this time, it does not try to ensure that generated anchor names +// are unique, that responsibility falls on the caller. +package sanitized_anchor_name // import "github.com/shurcooL/sanitized_anchor_name" + +import "unicode" + +// Create returns a sanitized anchor name for the given text. +func Create(text string) string { + var anchorName []rune + var futureDash = false + for _, r := range text { + switch { + case unicode.IsLetter(r) || unicode.IsNumber(r): + if futureDash && len(anchorName) > 0 { + anchorName = append(anchorName, '-') + } + futureDash = false + anchorName = append(anchorName, unicode.ToLower(r)) + default: + futureDash = true + } + } + return string(anchorName) +} diff --git a/backend/vendor/github.com/smartystreets/assertions/.gitignore b/backend/vendor/github.com/smartystreets/assertions/.gitignore new file mode 100644 index 00000000..07d3c71c --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/.gitignore @@ -0,0 +1,5 @@ +.DS_Store +Thumbs.db +*.iml +/.idea +coverage.out diff --git a/backend/vendor/github.com/smartystreets/assertions/.travis.yml b/backend/vendor/github.com/smartystreets/assertions/.travis.yml new file mode 100644 index 00000000..72df752f --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/.travis.yml @@ -0,0 +1,11 @@ +language: go + +go: + - 1.x + +install: + - go get -t ./... + +script: go test ./... -v + +sudo: false diff --git a/backend/vendor/github.com/smartystreets/assertions/CONTRIBUTING.md b/backend/vendor/github.com/smartystreets/assertions/CONTRIBUTING.md new file mode 100644 index 00000000..1820ecb3 --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/CONTRIBUTING.md @@ -0,0 +1,12 @@ +# Contributing + +In general, the code posted to the [SmartyStreets github organization](https://github.com/smartystreets) is created to solve specific problems at SmartyStreets that are ancillary to our core products in the address verification industry and may or may not be useful to other organizations or developers. Our reason for posting said code isn't necessarily to solicit feedback or contributions from the community but more as a showcase of some of the approaches to solving problems we have adopted. + +Having stated that, we do consider issues raised by other githubbers as well as contributions submitted via pull requests. When submitting such a pull request, please follow these guidelines: + +- _Look before you leap:_ If the changes you plan to make are significant, it's in everyone's best interest for you to discuss them with a SmartyStreets team member prior to opening a pull request. +- _License and ownership:_ If modifying the `LICENSE.md` file, limit your changes to fixing typographical mistakes. Do NOT modify the actual terms in the license or the copyright by **SmartyStreets, LLC**. Code submitted to SmartyStreets projects becomes property of SmartyStreets and must be compatible with the associated license. +- _Testing:_ If the code you are submitting resides in packages/modules covered by automated tests, be sure to add passing tests that cover your changes and assert expected behavior and state. Submit the additional test cases as part of your change set. +- _Style:_ Match your approach to **naming** and **formatting** with the surrounding code. Basically, the code you submit shouldn't stand out. + - "Naming" refers to such constructs as variables, methods, functions, classes, structs, interfaces, packages, modules, directories, files, etc... + - "Formatting" refers to such constructs as whitespace, horizontal line length, vertical function length, vertical file length, indentation, curly braces, etc... diff --git a/backend/vendor/github.com/smartystreets/assertions/LICENSE.md b/backend/vendor/github.com/smartystreets/assertions/LICENSE.md new file mode 100644 index 00000000..8ea6f945 --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/LICENSE.md @@ -0,0 +1,23 @@ +Copyright (c) 2016 SmartyStreets, LLC + +Permission is hereby granted, free of charge, to any person obtaining a copy +of this software and associated documentation files (the "Software"), to deal +in the Software without restriction, including without limitation the rights +to use, copy, modify, merge, publish, distribute, sublicense, and/or sell +copies of the Software, and to permit persons to whom the Software is +furnished to do so, subject to the following conditions: + +The above copyright notice and this permission notice shall be included in all +copies or substantial portions of the Software. + +THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR +IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, +FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE +AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER +LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, +OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE +SOFTWARE. + +NOTE: Various optional and subordinate components carry their own licensing +requirements and restrictions. Use of those components is subject to the terms +and conditions outlined the respective license of each component. diff --git a/backend/vendor/github.com/smartystreets/assertions/README.md b/backend/vendor/github.com/smartystreets/assertions/README.md new file mode 100644 index 00000000..208a4040 --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/README.md @@ -0,0 +1,619 @@ +# assertions +-- + import "github.com/smartystreets/assertions" + +Package assertions contains the implementations for all assertions which are +referenced in goconvey's `convey` package +(github.com/smartystreets/goconvey/convey) and gunit +(github.com/smartystreets/gunit) for use with the So(...) method. They can also +be used in traditional Go test functions and even in applications. + +https://smartystreets.com + +Many of the assertions lean heavily on work done by Aaron Jacobs in his +excellent oglematchers library. (https://github.com/jacobsa/oglematchers) The +ShouldResemble assertion leans heavily on work done by Daniel Jacques in his +very helpful go-render library. (https://github.com/luci/go-render) + +## Usage + +#### func GoConveyMode + +```go +func GoConveyMode(yes bool) +``` +GoConveyMode provides control over JSON serialization of failures. When using +the assertions in this package from the convey package JSON results are very +helpful and can be rendered in a DIFF view. In that case, this function will be +called with a true value to enable the JSON serialization. By default, the +assertions in this package will not serializer a JSON result, making standalone +usage more convenient. + +#### func ShouldAlmostEqual + +```go +func ShouldAlmostEqual(actual interface{}, expected ...interface{}) string +``` +ShouldAlmostEqual makes sure that two parameters are close enough to being +equal. The acceptable delta may be specified with a third argument, or a very +small default delta will be used. + +#### func ShouldBeBetween + +```go +func ShouldBeBetween(actual interface{}, expected ...interface{}) string +``` +ShouldBeBetween receives exactly three parameters: an actual value, a lower +bound, and an upper bound. It ensures that the actual value is between both +bounds (but not equal to either of them). + +#### func ShouldBeBetweenOrEqual + +```go +func ShouldBeBetweenOrEqual(actual interface{}, expected ...interface{}) string +``` +ShouldBeBetweenOrEqual receives exactly three parameters: an actual value, a +lower bound, and an upper bound. It ensures that the actual value is between +both bounds or equal to one of them. + +#### func ShouldBeBlank + +```go +func ShouldBeBlank(actual interface{}, expected ...interface{}) string +``` +ShouldBeBlank receives exactly 1 string parameter and ensures that it is equal +to "". + +#### func ShouldBeChronological + +```go +func ShouldBeChronological(actual interface{}, expected ...interface{}) string +``` +ShouldBeChronological receives a []time.Time slice and asserts that they are in +chronological order starting with the first time.Time as the earliest. + +#### func ShouldBeEmpty + +```go +func ShouldBeEmpty(actual interface{}, expected ...interface{}) string +``` +ShouldBeEmpty receives a single parameter (actual) and determines whether or not +calling len(actual) would return `0`. It obeys the rules specified by the len +function for determining length: http://golang.org/pkg/builtin/#len + +#### func ShouldBeError + +```go +func ShouldBeError(actual interface{}, expected ...interface{}) string +``` +ShouldBeError asserts that the first argument implements the error interface. It +also compares the first argument against the second argument if provided (which +must be an error message string or another error value). + +#### func ShouldBeFalse + +```go +func ShouldBeFalse(actual interface{}, expected ...interface{}) string +``` +ShouldBeFalse receives a single parameter and ensures that it is false. + +#### func ShouldBeGreaterThan + +```go +func ShouldBeGreaterThan(actual interface{}, expected ...interface{}) string +``` +ShouldBeGreaterThan receives exactly two parameters and ensures that the first +is greater than the second. + +#### func ShouldBeGreaterThanOrEqualTo + +```go +func ShouldBeGreaterThanOrEqualTo(actual interface{}, expected ...interface{}) string +``` +ShouldBeGreaterThanOrEqualTo receives exactly two parameters and ensures that +the first is greater than or equal to the second. + +#### func ShouldBeIn + +```go +func ShouldBeIn(actual interface{}, expected ...interface{}) string +``` +ShouldBeIn receives at least 2 parameters. The first is a proposed member of the +collection that is passed in either as the second parameter, or of the +collection that is comprised of all the remaining parameters. This assertion +ensures that the proposed member is in the collection (using ShouldEqual). + +#### func ShouldBeLessThan + +```go +func ShouldBeLessThan(actual interface{}, expected ...interface{}) string +``` +ShouldBeLessThan receives exactly two parameters and ensures that the first is +less than the second. + +#### func ShouldBeLessThanOrEqualTo + +```go +func ShouldBeLessThanOrEqualTo(actual interface{}, expected ...interface{}) string +``` +ShouldBeLessThan receives exactly two parameters and ensures that the first is +less than or equal to the second. + +#### func ShouldBeNil + +```go +func ShouldBeNil(actual interface{}, expected ...interface{}) string +``` +ShouldBeNil receives a single parameter and ensures that it is nil. + +#### func ShouldBeTrue + +```go +func ShouldBeTrue(actual interface{}, expected ...interface{}) string +``` +ShouldBeTrue receives a single parameter and ensures that it is true. + +#### func ShouldBeZeroValue + +```go +func ShouldBeZeroValue(actual interface{}, expected ...interface{}) string +``` +ShouldBeZeroValue receives a single parameter and ensures that it is the Go +equivalent of the default value, or "zero" value. + +#### func ShouldContain + +```go +func ShouldContain(actual interface{}, expected ...interface{}) string +``` +ShouldContain receives exactly two parameters. The first is a slice and the +second is a proposed member. Membership is determined using ShouldEqual. + +#### func ShouldContainKey + +```go +func ShouldContainKey(actual interface{}, expected ...interface{}) string +``` +ShouldContainKey receives exactly two parameters. The first is a map and the +second is a proposed key. Keys are compared with a simple '=='. + +#### func ShouldContainSubstring + +```go +func ShouldContainSubstring(actual interface{}, expected ...interface{}) string +``` +ShouldContainSubstring receives exactly 2 string parameters and ensures that the +first contains the second as a substring. + +#### func ShouldEndWith + +```go +func ShouldEndWith(actual interface{}, expected ...interface{}) string +``` +ShouldEndWith receives exactly 2 string parameters and ensures that the first +ends with the second. + +#### func ShouldEqual + +```go +func ShouldEqual(actual interface{}, expected ...interface{}) string +``` +ShouldEqual receives exactly two parameters and does an equality check using the +following semantics: 1. If the expected and actual values implement an Equal +method in the form `func (this T) Equal(that T) bool` then call the method. If +true, they are equal. 2. The expected and actual values are judged equal or not +by oglematchers.Equals. + +#### func ShouldEqualJSON + +```go +func ShouldEqualJSON(actual interface{}, expected ...interface{}) string +``` +ShouldEqualJSON receives exactly two parameters and does an equality check by +marshalling to JSON + +#### func ShouldEqualTrimSpace + +```go +func ShouldEqualTrimSpace(actual interface{}, expected ...interface{}) string +``` +ShouldEqualTrimSpace receives exactly 2 string parameters and ensures that the +first is equal to the second after removing all leading and trailing whitespace +using strings.TrimSpace(first). + +#### func ShouldEqualWithout + +```go +func ShouldEqualWithout(actual interface{}, expected ...interface{}) string +``` +ShouldEqualWithout receives exactly 3 string parameters and ensures that the +first is equal to the second after removing all instances of the third from the +first using strings.Replace(first, third, "", -1). + +#### func ShouldHappenAfter + +```go +func ShouldHappenAfter(actual interface{}, expected ...interface{}) string +``` +ShouldHappenAfter receives exactly 2 time.Time arguments and asserts that the +first happens after the second. + +#### func ShouldHappenBefore + +```go +func ShouldHappenBefore(actual interface{}, expected ...interface{}) string +``` +ShouldHappenBefore receives exactly 2 time.Time arguments and asserts that the +first happens before the second. + +#### func ShouldHappenBetween + +```go +func ShouldHappenBetween(actual interface{}, expected ...interface{}) string +``` +ShouldHappenBetween receives exactly 3 time.Time arguments and asserts that the +first happens between (not on) the second and third. + +#### func ShouldHappenOnOrAfter + +```go +func ShouldHappenOnOrAfter(actual interface{}, expected ...interface{}) string +``` +ShouldHappenOnOrAfter receives exactly 2 time.Time arguments and asserts that +the first happens on or after the second. + +#### func ShouldHappenOnOrBefore + +```go +func ShouldHappenOnOrBefore(actual interface{}, expected ...interface{}) string +``` +ShouldHappenOnOrBefore receives exactly 2 time.Time arguments and asserts that +the first happens on or before the second. + +#### func ShouldHappenOnOrBetween + +```go +func ShouldHappenOnOrBetween(actual interface{}, expected ...interface{}) string +``` +ShouldHappenOnOrBetween receives exactly 3 time.Time arguments and asserts that +the first happens between or on the second and third. + +#### func ShouldHappenWithin + +```go +func ShouldHappenWithin(actual interface{}, expected ...interface{}) string +``` +ShouldHappenWithin receives a time.Time, a time.Duration, and a time.Time (3 +arguments) and asserts that the first time.Time happens within or on the +duration specified relative to the other time.Time. + +#### func ShouldHaveLength + +```go +func ShouldHaveLength(actual interface{}, expected ...interface{}) string +``` +ShouldHaveLength receives 2 parameters. The first is a collection to check the +length of, the second being the expected length. It obeys the rules specified by +the len function for determining length: http://golang.org/pkg/builtin/#len + +#### func ShouldHaveSameTypeAs + +```go +func ShouldHaveSameTypeAs(actual interface{}, expected ...interface{}) string +``` +ShouldHaveSameTypeAs receives exactly two parameters and compares their +underlying types for equality. + +#### func ShouldImplement + +```go +func ShouldImplement(actual interface{}, expectedList ...interface{}) string +``` +ShouldImplement receives exactly two parameters and ensures that the first +implements the interface type of the second. + +#### func ShouldNotAlmostEqual + +```go +func ShouldNotAlmostEqual(actual interface{}, expected ...interface{}) string +``` +ShouldNotAlmostEqual is the inverse of ShouldAlmostEqual + +#### func ShouldNotBeBetween + +```go +func ShouldNotBeBetween(actual interface{}, expected ...interface{}) string +``` +ShouldNotBeBetween receives exactly three parameters: an actual value, a lower +bound, and an upper bound. It ensures that the actual value is NOT between both +bounds. + +#### func ShouldNotBeBetweenOrEqual + +```go +func ShouldNotBeBetweenOrEqual(actual interface{}, expected ...interface{}) string +``` +ShouldNotBeBetweenOrEqual receives exactly three parameters: an actual value, a +lower bound, and an upper bound. It ensures that the actual value is nopt +between the bounds nor equal to either of them. + +#### func ShouldNotBeBlank + +```go +func ShouldNotBeBlank(actual interface{}, expected ...interface{}) string +``` +ShouldNotBeBlank receives exactly 1 string parameter and ensures that it is +equal to "". + +#### func ShouldNotBeChronological + +```go +func ShouldNotBeChronological(actual interface{}, expected ...interface{}) string +``` +ShouldNotBeChronological receives a []time.Time slice and asserts that they are +NOT in chronological order. + +#### func ShouldNotBeEmpty + +```go +func ShouldNotBeEmpty(actual interface{}, expected ...interface{}) string +``` +ShouldNotBeEmpty receives a single parameter (actual) and determines whether or +not calling len(actual) would return a value greater than zero. It obeys the +rules specified by the `len` function for determining length: +http://golang.org/pkg/builtin/#len + +#### func ShouldNotBeIn + +```go +func ShouldNotBeIn(actual interface{}, expected ...interface{}) string +``` +ShouldNotBeIn receives at least 2 parameters. The first is a proposed member of +the collection that is passed in either as the second parameter, or of the +collection that is comprised of all the remaining parameters. This assertion +ensures that the proposed member is NOT in the collection (using ShouldEqual). + +#### func ShouldNotBeNil + +```go +func ShouldNotBeNil(actual interface{}, expected ...interface{}) string +``` +ShouldNotBeNil receives a single parameter and ensures that it is not nil. + +#### func ShouldNotBeZeroValue + +```go +func ShouldNotBeZeroValue(actual interface{}, expected ...interface{}) string +``` +ShouldBeZeroValue receives a single parameter and ensures that it is NOT the Go +equivalent of the default value, or "zero" value. + +#### func ShouldNotContain + +```go +func ShouldNotContain(actual interface{}, expected ...interface{}) string +``` +ShouldNotContain receives exactly two parameters. The first is a slice and the +second is a proposed member. Membership is determinied using ShouldEqual. + +#### func ShouldNotContainKey + +```go +func ShouldNotContainKey(actual interface{}, expected ...interface{}) string +``` +ShouldNotContainKey receives exactly two parameters. The first is a map and the +second is a proposed absent key. Keys are compared with a simple '=='. + +#### func ShouldNotContainSubstring + +```go +func ShouldNotContainSubstring(actual interface{}, expected ...interface{}) string +``` +ShouldNotContainSubstring receives exactly 2 string parameters and ensures that +the first does NOT contain the second as a substring. + +#### func ShouldNotEndWith + +```go +func ShouldNotEndWith(actual interface{}, expected ...interface{}) string +``` +ShouldEndWith receives exactly 2 string parameters and ensures that the first +does not end with the second. + +#### func ShouldNotEqual + +```go +func ShouldNotEqual(actual interface{}, expected ...interface{}) string +``` +ShouldNotEqual receives exactly two parameters and does an inequality check. See +ShouldEqual for details on how equality is determined. + +#### func ShouldNotHappenOnOrBetween + +```go +func ShouldNotHappenOnOrBetween(actual interface{}, expected ...interface{}) string +``` +ShouldNotHappenOnOrBetween receives exactly 3 time.Time arguments and asserts +that the first does NOT happen between or on the second or third. + +#### func ShouldNotHappenWithin + +```go +func ShouldNotHappenWithin(actual interface{}, expected ...interface{}) string +``` +ShouldNotHappenWithin receives a time.Time, a time.Duration, and a time.Time (3 +arguments) and asserts that the first time.Time does NOT happen within or on the +duration specified relative to the other time.Time. + +#### func ShouldNotHaveSameTypeAs + +```go +func ShouldNotHaveSameTypeAs(actual interface{}, expected ...interface{}) string +``` +ShouldNotHaveSameTypeAs receives exactly two parameters and compares their +underlying types for inequality. + +#### func ShouldNotImplement + +```go +func ShouldNotImplement(actual interface{}, expectedList ...interface{}) string +``` +ShouldNotImplement receives exactly two parameters and ensures that the first +does NOT implement the interface type of the second. + +#### func ShouldNotPanic + +```go +func ShouldNotPanic(actual interface{}, expected ...interface{}) (message string) +``` +ShouldNotPanic receives a void, niladic function and expects to execute the +function without any panic. + +#### func ShouldNotPanicWith + +```go +func ShouldNotPanicWith(actual interface{}, expected ...interface{}) (message string) +``` +ShouldNotPanicWith receives a void, niladic function and expects to recover a +panic whose content differs from the second argument. + +#### func ShouldNotPointTo + +```go +func ShouldNotPointTo(actual interface{}, expected ...interface{}) string +``` +ShouldNotPointTo receives exactly two parameters and checks to see that they +point to different addresess. + +#### func ShouldNotResemble + +```go +func ShouldNotResemble(actual interface{}, expected ...interface{}) string +``` +ShouldNotResemble receives exactly two parameters and does an inverse deep equal +check (see reflect.DeepEqual) + +#### func ShouldNotStartWith + +```go +func ShouldNotStartWith(actual interface{}, expected ...interface{}) string +``` +ShouldNotStartWith receives exactly 2 string parameters and ensures that the +first does not start with the second. + +#### func ShouldPanic + +```go +func ShouldPanic(actual interface{}, expected ...interface{}) (message string) +``` +ShouldPanic receives a void, niladic function and expects to recover a panic. + +#### func ShouldPanicWith + +```go +func ShouldPanicWith(actual interface{}, expected ...interface{}) (message string) +``` +ShouldPanicWith receives a void, niladic function and expects to recover a panic +with the second argument as the content. + +#### func ShouldPointTo + +```go +func ShouldPointTo(actual interface{}, expected ...interface{}) string +``` +ShouldPointTo receives exactly two parameters and checks to see that they point +to the same address. + +#### func ShouldResemble + +```go +func ShouldResemble(actual interface{}, expected ...interface{}) string +``` +ShouldResemble receives exactly two parameters and does a deep equal check (see +reflect.DeepEqual) + +#### func ShouldStartWith + +```go +func ShouldStartWith(actual interface{}, expected ...interface{}) string +``` +ShouldStartWith receives exactly 2 string parameters and ensures that the first +starts with the second. + +#### func So + +```go +func So(actual interface{}, assert assertion, expected ...interface{}) (bool, string) +``` +So is a convenience function (as opposed to an inconvenience function?) for +running assertions on arbitrary arguments in any context, be it for testing or +even application logging. It allows you to perform assertion-like behavior (and +get nicely formatted messages detailing discrepancies) but without the program +blowing up or panicking. All that is required is to import this package and call +`So` with one of the assertions exported by this package as the second +parameter. The first return parameter is a boolean indicating if the assertion +was true. The second return parameter is the well-formatted message showing why +an assertion was incorrect, or blank if the assertion was correct. + +Example: + + if ok, message := So(x, ShouldBeGreaterThan, y); !ok { + log.Println(message) + } + +For an alternative implementation of So (that provides more flexible return +options) see the `So` function in the package at +github.com/smartystreets/assertions/assert. + +#### type Assertion + +```go +type Assertion struct { +} +``` + + +#### func New + +```go +func New(t testingT) *Assertion +``` +New swallows the *testing.T struct and prints failed assertions using t.Error. +Example: assertions.New(t).So(1, should.Equal, 1) + +#### func (*Assertion) Failed + +```go +func (this *Assertion) Failed() bool +``` +Failed reports whether any calls to So (on this Assertion instance) have failed. + +#### func (*Assertion) So + +```go +func (this *Assertion) So(actual interface{}, assert assertion, expected ...interface{}) bool +``` +So calls the standalone So function and additionally, calls t.Error in failure +scenarios. + +#### type FailureView + +```go +type FailureView struct { + Message string `json:"Message"` + Expected string `json:"Expected"` + Actual string `json:"Actual"` +} +``` + +This struct is also declared in +github.com/smartystreets/goconvey/convey/reporting. The json struct tags should +be equal in both declarations. + +#### type Serializer + +```go +type Serializer interface { + // contains filtered or unexported methods +} +``` diff --git a/backend/vendor/github.com/smartystreets/assertions/collections.go b/backend/vendor/github.com/smartystreets/assertions/collections.go new file mode 100644 index 00000000..b534d4ba --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/collections.go @@ -0,0 +1,244 @@ +package assertions + +import ( + "fmt" + "reflect" + + "github.com/smartystreets/assertions/internal/oglematchers" +) + +// ShouldContain receives exactly two parameters. The first is a slice and the +// second is a proposed member. Membership is determined using ShouldEqual. +func ShouldContain(actual interface{}, expected ...interface{}) string { + if fail := need(1, expected); fail != success { + return fail + } + + if matchError := oglematchers.Contains(expected[0]).Matches(actual); matchError != nil { + typeName := reflect.TypeOf(actual) + + if fmt.Sprintf("%v", matchError) == "which is not a slice or array" { + return fmt.Sprintf(shouldHaveBeenAValidCollection, typeName) + } + return fmt.Sprintf(shouldHaveContained, typeName, expected[0]) + } + return success +} + +// ShouldNotContain receives exactly two parameters. The first is a slice and the +// second is a proposed member. Membership is determinied using ShouldEqual. +func ShouldNotContain(actual interface{}, expected ...interface{}) string { + if fail := need(1, expected); fail != success { + return fail + } + typeName := reflect.TypeOf(actual) + + if matchError := oglematchers.Contains(expected[0]).Matches(actual); matchError != nil { + if fmt.Sprintf("%v", matchError) == "which is not a slice or array" { + return fmt.Sprintf(shouldHaveBeenAValidCollection, typeName) + } + return success + } + return fmt.Sprintf(shouldNotHaveContained, typeName, expected[0]) +} + +// ShouldContainKey receives exactly two parameters. The first is a map and the +// second is a proposed key. Keys are compared with a simple '=='. +func ShouldContainKey(actual interface{}, expected ...interface{}) string { + if fail := need(1, expected); fail != success { + return fail + } + + keys, isMap := mapKeys(actual) + if !isMap { + return fmt.Sprintf(shouldHaveBeenAValidMap, reflect.TypeOf(actual)) + } + + if !keyFound(keys, expected[0]) { + return fmt.Sprintf(shouldHaveContainedKey, reflect.TypeOf(actual), expected) + } + + return "" +} + +// ShouldNotContainKey receives exactly two parameters. The first is a map and the +// second is a proposed absent key. Keys are compared with a simple '=='. +func ShouldNotContainKey(actual interface{}, expected ...interface{}) string { + if fail := need(1, expected); fail != success { + return fail + } + + keys, isMap := mapKeys(actual) + if !isMap { + return fmt.Sprintf(shouldHaveBeenAValidMap, reflect.TypeOf(actual)) + } + + if keyFound(keys, expected[0]) { + return fmt.Sprintf(shouldNotHaveContainedKey, reflect.TypeOf(actual), expected) + } + + return "" +} + +func mapKeys(m interface{}) ([]reflect.Value, bool) { + value := reflect.ValueOf(m) + if value.Kind() != reflect.Map { + return nil, false + } + return value.MapKeys(), true +} +func keyFound(keys []reflect.Value, expectedKey interface{}) bool { + found := false + for _, key := range keys { + if key.Interface() == expectedKey { + found = true + } + } + return found +} + +// ShouldBeIn receives at least 2 parameters. The first is a proposed member of the collection +// that is passed in either as the second parameter, or of the collection that is comprised +// of all the remaining parameters. This assertion ensures that the proposed member is in +// the collection (using ShouldEqual). +func ShouldBeIn(actual interface{}, expected ...interface{}) string { + if fail := atLeast(1, expected); fail != success { + return fail + } + + if len(expected) == 1 { + return shouldBeIn(actual, expected[0]) + } + return shouldBeIn(actual, expected) +} +func shouldBeIn(actual interface{}, expected interface{}) string { + if matchError := oglematchers.Contains(actual).Matches(expected); matchError != nil { + return fmt.Sprintf(shouldHaveBeenIn, actual, reflect.TypeOf(expected)) + } + return success +} + +// ShouldNotBeIn receives at least 2 parameters. The first is a proposed member of the collection +// that is passed in either as the second parameter, or of the collection that is comprised +// of all the remaining parameters. This assertion ensures that the proposed member is NOT in +// the collection (using ShouldEqual). +func ShouldNotBeIn(actual interface{}, expected ...interface{}) string { + if fail := atLeast(1, expected); fail != success { + return fail + } + + if len(expected) == 1 { + return shouldNotBeIn(actual, expected[0]) + } + return shouldNotBeIn(actual, expected) +} +func shouldNotBeIn(actual interface{}, expected interface{}) string { + if matchError := oglematchers.Contains(actual).Matches(expected); matchError == nil { + return fmt.Sprintf(shouldNotHaveBeenIn, actual, reflect.TypeOf(expected)) + } + return success +} + +// ShouldBeEmpty receives a single parameter (actual) and determines whether or not +// calling len(actual) would return `0`. It obeys the rules specified by the len +// function for determining length: http://golang.org/pkg/builtin/#len +func ShouldBeEmpty(actual interface{}, expected ...interface{}) string { + if fail := need(0, expected); fail != success { + return fail + } + + if actual == nil { + return success + } + + value := reflect.ValueOf(actual) + switch value.Kind() { + case reflect.Slice: + if value.Len() == 0 { + return success + } + case reflect.Chan: + if value.Len() == 0 { + return success + } + case reflect.Map: + if value.Len() == 0 { + return success + } + case reflect.String: + if value.Len() == 0 { + return success + } + case reflect.Ptr: + elem := value.Elem() + kind := elem.Kind() + if (kind == reflect.Slice || kind == reflect.Array) && elem.Len() == 0 { + return success + } + } + + return fmt.Sprintf(shouldHaveBeenEmpty, actual) +} + +// ShouldNotBeEmpty receives a single parameter (actual) and determines whether or not +// calling len(actual) would return a value greater than zero. It obeys the rules +// specified by the `len` function for determining length: http://golang.org/pkg/builtin/#len +func ShouldNotBeEmpty(actual interface{}, expected ...interface{}) string { + if fail := need(0, expected); fail != success { + return fail + } + + if empty := ShouldBeEmpty(actual, expected...); empty != success { + return success + } + return fmt.Sprintf(shouldNotHaveBeenEmpty, actual) +} + +// ShouldHaveLength receives 2 parameters. The first is a collection to check +// the length of, the second being the expected length. It obeys the rules +// specified by the len function for determining length: +// http://golang.org/pkg/builtin/#len +func ShouldHaveLength(actual interface{}, expected ...interface{}) string { + if fail := need(1, expected); fail != success { + return fail + } + + var expectedLen int64 + lenValue := reflect.ValueOf(expected[0]) + switch lenValue.Kind() { + case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64: + expectedLen = lenValue.Int() + case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64: + expectedLen = int64(lenValue.Uint()) + default: + return fmt.Sprintf(shouldHaveBeenAValidInteger, reflect.TypeOf(expected[0])) + } + + if expectedLen < 0 { + return fmt.Sprintf(shouldHaveBeenAValidLength, expected[0]) + } + + value := reflect.ValueOf(actual) + switch value.Kind() { + case reflect.Slice, + reflect.Chan, + reflect.Map, + reflect.String: + if int64(value.Len()) == expectedLen { + return success + } else { + return fmt.Sprintf(shouldHaveHadLength, expectedLen, value.Len(), actual) + } + case reflect.Ptr: + elem := value.Elem() + kind := elem.Kind() + if kind == reflect.Slice || kind == reflect.Array { + if int64(elem.Len()) == expectedLen { + return success + } else { + return fmt.Sprintf(shouldHaveHadLength, expectedLen, elem.Len(), actual) + } + } + } + return fmt.Sprintf(shouldHaveBeenAValidCollection, reflect.TypeOf(actual)) +} diff --git a/backend/vendor/github.com/smartystreets/assertions/doc.go b/backend/vendor/github.com/smartystreets/assertions/doc.go new file mode 100644 index 00000000..ba30a926 --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/doc.go @@ -0,0 +1,109 @@ +// Package assertions contains the implementations for all assertions which +// are referenced in goconvey's `convey` package +// (github.com/smartystreets/goconvey/convey) and gunit (github.com/smartystreets/gunit) +// for use with the So(...) method. +// They can also be used in traditional Go test functions and even in +// applications. +// +// https://smartystreets.com +// +// Many of the assertions lean heavily on work done by Aaron Jacobs in his excellent oglematchers library. +// (https://github.com/jacobsa/oglematchers) +// The ShouldResemble assertion leans heavily on work done by Daniel Jacques in his very helpful go-render library. +// (https://github.com/luci/go-render) +package assertions + +import ( + "fmt" + "runtime" +) + +// By default we use a no-op serializer. The actual Serializer provides a JSON +// representation of failure results on selected assertions so the goconvey +// web UI can display a convenient diff. +var serializer Serializer = new(noopSerializer) + +// GoConveyMode provides control over JSON serialization of failures. When +// using the assertions in this package from the convey package JSON results +// are very helpful and can be rendered in a DIFF view. In that case, this function +// will be called with a true value to enable the JSON serialization. By default, +// the assertions in this package will not serializer a JSON result, making +// standalone usage more convenient. +func GoConveyMode(yes bool) { + if yes { + serializer = newSerializer() + } else { + serializer = new(noopSerializer) + } +} + +type testingT interface { + Error(args ...interface{}) +} + +type Assertion struct { + t testingT + failed bool +} + +// New swallows the *testing.T struct and prints failed assertions using t.Error. +// Example: assertions.New(t).So(1, should.Equal, 1) +func New(t testingT) *Assertion { + return &Assertion{t: t} +} + +// Failed reports whether any calls to So (on this Assertion instance) have failed. +func (this *Assertion) Failed() bool { + return this.failed +} + +// So calls the standalone So function and additionally, calls t.Error in failure scenarios. +func (this *Assertion) So(actual interface{}, assert assertion, expected ...interface{}) bool { + ok, result := So(actual, assert, expected...) + if !ok { + this.failed = true + _, file, line, _ := runtime.Caller(1) + this.t.Error(fmt.Sprintf("\n%s:%d\n%s", file, line, result)) + } + return ok +} + +// So is a convenience function (as opposed to an inconvenience function?) +// for running assertions on arbitrary arguments in any context, be it for testing or even +// application logging. It allows you to perform assertion-like behavior (and get nicely +// formatted messages detailing discrepancies) but without the program blowing up or panicking. +// All that is required is to import this package and call `So` with one of the assertions +// exported by this package as the second parameter. +// The first return parameter is a boolean indicating if the assertion was true. The second +// return parameter is the well-formatted message showing why an assertion was incorrect, or +// blank if the assertion was correct. +// +// Example: +// +// if ok, message := So(x, ShouldBeGreaterThan, y); !ok { +// log.Println(message) +// } +// +// For an alternative implementation of So (that provides more flexible return options) +// see the `So` function in the package at github.com/smartystreets/assertions/assert. +func So(actual interface{}, assert assertion, expected ...interface{}) (bool, string) { + if result := so(actual, assert, expected...); len(result) == 0 { + return true, result + } else { + return false, result + } +} + +// so is like So, except that it only returns the string message, which is blank if the +// assertion passed. Used to facilitate testing. +func so(actual interface{}, assert func(interface{}, ...interface{}) string, expected ...interface{}) string { + return assert(actual, expected...) +} + +// assertion is an alias for a function with a signature that the So() +// function can handle. Any future or custom assertions should conform to this +// method signature. The return value should be an empty string if the assertion +// passes and a well-formed failure message if not. +type assertion func(actual interface{}, expected ...interface{}) string + +//////////////////////////////////////////////////////////////////////////// diff --git a/backend/vendor/github.com/smartystreets/assertions/equal_method.go b/backend/vendor/github.com/smartystreets/assertions/equal_method.go new file mode 100644 index 00000000..c4fc38fa --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/equal_method.go @@ -0,0 +1,75 @@ +package assertions + +import "reflect" + +type equalityMethodSpecification struct { + a interface{} + b interface{} + + aType reflect.Type + bType reflect.Type + + equalMethod reflect.Value +} + +func newEqualityMethodSpecification(a, b interface{}) *equalityMethodSpecification { + return &equalityMethodSpecification{ + a: a, + b: b, + } +} + +func (this *equalityMethodSpecification) IsSatisfied() bool { + if !this.bothAreSameType() { + return false + } + if !this.typeHasEqualMethod() { + return false + } + if !this.equalMethodReceivesSameTypeForComparison() { + return false + } + if !this.equalMethodReturnsBool() { + return false + } + return true +} + +func (this *equalityMethodSpecification) bothAreSameType() bool { + this.aType = reflect.TypeOf(this.a) + if this.aType == nil { + return false + } + if this.aType.Kind() == reflect.Ptr { + this.aType = this.aType.Elem() + } + this.bType = reflect.TypeOf(this.b) + return this.aType == this.bType +} +func (this *equalityMethodSpecification) typeHasEqualMethod() bool { + aInstance := reflect.ValueOf(this.a) + this.equalMethod = aInstance.MethodByName("Equal") + return this.equalMethod != reflect.Value{} +} + +func (this *equalityMethodSpecification) equalMethodReceivesSameTypeForComparison() bool { + signature := this.equalMethod.Type() + return signature.NumIn() == 1 && signature.In(0) == this.aType +} + +func (this *equalityMethodSpecification) equalMethodReturnsBool() bool { + signature := this.equalMethod.Type() + return signature.NumOut() == 1 && signature.Out(0) == reflect.TypeOf(true) +} + +func (this *equalityMethodSpecification) AreEqual() bool { + a := reflect.ValueOf(this.a) + b := reflect.ValueOf(this.b) + return areEqual(a, b) && areEqual(b, a) +} +func areEqual(receiver reflect.Value, argument reflect.Value) bool { + equalMethod := receiver.MethodByName("Equal") + argumentList := []reflect.Value{argument} + result := equalMethod.Call(argumentList) + return result[0].Bool() +} diff --git a/backend/vendor/github.com/smartystreets/assertions/equality.go b/backend/vendor/github.com/smartystreets/assertions/equality.go new file mode 100644 index 00000000..37a49f4e --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/equality.go @@ -0,0 +1,331 @@ +package assertions + +import ( + "encoding/json" + "errors" + "fmt" + "math" + "reflect" + "strings" + + "github.com/smartystreets/assertions/internal/go-render/render" + "github.com/smartystreets/assertions/internal/oglematchers" +) + +// ShouldEqual receives exactly two parameters and does an equality check +// using the following semantics: +// 1. If the expected and actual values implement an Equal method in the form +// `func (this T) Equal(that T) bool` then call the method. If true, they are equal. +// 2. The expected and actual values are judged equal or not by oglematchers.Equals. +func ShouldEqual(actual interface{}, expected ...interface{}) string { + if message := need(1, expected); message != success { + return message + } + return shouldEqual(actual, expected[0]) +} +func shouldEqual(actual, expected interface{}) (message string) { + defer func() { + if r := recover(); r != nil { + message = serializer.serialize(expected, actual, composeEqualityMismatchMessage(expected, actual)) + } + }() + + if spec := newEqualityMethodSpecification(expected, actual); spec.IsSatisfied() && spec.AreEqual() { + return success + } else if matchError := oglematchers.Equals(expected).Matches(actual); matchError == nil { + return success + } + + return serializer.serialize(expected, actual, composeEqualityMismatchMessage(expected, actual)) +} +func composeEqualityMismatchMessage(expected, actual interface{}) string { + var ( + renderedExpected = fmt.Sprintf("%v", expected) + renderedActual = fmt.Sprintf("%v", actual) + ) + + if renderedExpected != renderedActual { + return fmt.Sprintf(shouldHaveBeenEqual+composePrettyDiff(renderedExpected, renderedActual), expected, actual) + } else if reflect.TypeOf(expected) != reflect.TypeOf(actual) { + return fmt.Sprintf(shouldHaveBeenEqualTypeMismatch, expected, expected, actual, actual) + } else { + return fmt.Sprintf(shouldHaveBeenEqualNoResemblance, renderedExpected) + } +} + +// ShouldNotEqual receives exactly two parameters and does an inequality check. +// See ShouldEqual for details on how equality is determined. +func ShouldNotEqual(actual interface{}, expected ...interface{}) string { + if fail := need(1, expected); fail != success { + return fail + } else if ShouldEqual(actual, expected[0]) == success { + return fmt.Sprintf(shouldNotHaveBeenEqual, actual, expected[0]) + } + return success +} + +// ShouldAlmostEqual makes sure that two parameters are close enough to being equal. +// The acceptable delta may be specified with a third argument, +// or a very small default delta will be used. +func ShouldAlmostEqual(actual interface{}, expected ...interface{}) string { + actualFloat, expectedFloat, deltaFloat, err := cleanAlmostEqualInput(actual, expected...) + + if err != "" { + return err + } + + if math.Abs(actualFloat-expectedFloat) <= deltaFloat { + return success + } else { + return fmt.Sprintf(shouldHaveBeenAlmostEqual, actualFloat, expectedFloat) + } +} + +// ShouldNotAlmostEqual is the inverse of ShouldAlmostEqual +func ShouldNotAlmostEqual(actual interface{}, expected ...interface{}) string { + actualFloat, expectedFloat, deltaFloat, err := cleanAlmostEqualInput(actual, expected...) + + if err != "" { + return err + } + + if math.Abs(actualFloat-expectedFloat) > deltaFloat { + return success + } else { + return fmt.Sprintf(shouldHaveNotBeenAlmostEqual, actualFloat, expectedFloat) + } +} + +func cleanAlmostEqualInput(actual interface{}, expected ...interface{}) (float64, float64, float64, string) { + deltaFloat := 0.0000000001 + + if len(expected) == 0 { + return 0.0, 0.0, 0.0, "This assertion requires exactly one comparison value and an optional delta (you provided neither)" + } else if len(expected) == 2 { + delta, err := getFloat(expected[1]) + + if err != nil { + return 0.0, 0.0, 0.0, "The delta value " + err.Error() + } + + deltaFloat = delta + } else if len(expected) > 2 { + return 0.0, 0.0, 0.0, "This assertion requires exactly one comparison value and an optional delta (you provided more values)" + } + + actualFloat, err := getFloat(actual) + if err != nil { + return 0.0, 0.0, 0.0, "The actual value " + err.Error() + } + + expectedFloat, err := getFloat(expected[0]) + if err != nil { + return 0.0, 0.0, 0.0, "The comparison value " + err.Error() + } + + return actualFloat, expectedFloat, deltaFloat, "" +} + +// returns the float value of any real number, or error if it is not a numerical type +func getFloat(num interface{}) (float64, error) { + numValue := reflect.ValueOf(num) + numKind := numValue.Kind() + + if numKind == reflect.Int || + numKind == reflect.Int8 || + numKind == reflect.Int16 || + numKind == reflect.Int32 || + numKind == reflect.Int64 { + return float64(numValue.Int()), nil + } else if numKind == reflect.Uint || + numKind == reflect.Uint8 || + numKind == reflect.Uint16 || + numKind == reflect.Uint32 || + numKind == reflect.Uint64 { + return float64(numValue.Uint()), nil + } else if numKind == reflect.Float32 || + numKind == reflect.Float64 { + return numValue.Float(), nil + } else { + return 0.0, errors.New("must be a numerical type, but was: " + numKind.String()) + } +} + +// ShouldEqualJSON receives exactly two parameters and does an equality check by marshalling to JSON +func ShouldEqualJSON(actual interface{}, expected ...interface{}) string { + if message := need(1, expected); message != success { + return message + } + + expectedString, expectedErr := remarshal(expected[0].(string)) + if expectedErr != nil { + return "Expected value not valid JSON: " + expectedErr.Error() + } + + actualString, actualErr := remarshal(actual.(string)) + if actualErr != nil { + return "Actual value not valid JSON: " + actualErr.Error() + } + + return ShouldEqual(actualString, expectedString) +} +func remarshal(value string) (string, error) { + var structured interface{} + err := json.Unmarshal([]byte(value), &structured) + if err != nil { + return "", err + } + canonical, _ := json.Marshal(structured) + return string(canonical), nil +} + +// ShouldResemble receives exactly two parameters and does a deep equal check (see reflect.DeepEqual) +func ShouldResemble(actual interface{}, expected ...interface{}) string { + if message := need(1, expected); message != success { + return message + } + + if matchError := oglematchers.DeepEquals(expected[0]).Matches(actual); matchError != nil { + renderedExpected, renderedActual := render.Render(expected[0]), render.Render(actual) + message := fmt.Sprintf(shouldHaveResembled, renderedExpected, renderedActual) + + composePrettyDiff(renderedExpected, renderedActual) + return serializer.serializeDetailed(expected[0], actual, message) + } + + return success +} + +// ShouldNotResemble receives exactly two parameters and does an inverse deep equal check (see reflect.DeepEqual) +func ShouldNotResemble(actual interface{}, expected ...interface{}) string { + if message := need(1, expected); message != success { + return message + } else if ShouldResemble(actual, expected[0]) == success { + return fmt.Sprintf(shouldNotHaveResembled, render.Render(actual), render.Render(expected[0])) + } + return success +} + +// ShouldPointTo receives exactly two parameters and checks to see that they point to the same address. +func ShouldPointTo(actual interface{}, expected ...interface{}) string { + if message := need(1, expected); message != success { + return message + } + return shouldPointTo(actual, expected[0]) + +} +func shouldPointTo(actual, expected interface{}) string { + actualValue := reflect.ValueOf(actual) + expectedValue := reflect.ValueOf(expected) + + if ShouldNotBeNil(actual) != success { + return fmt.Sprintf(shouldHaveBeenNonNilPointer, "first", "nil") + } else if ShouldNotBeNil(expected) != success { + return fmt.Sprintf(shouldHaveBeenNonNilPointer, "second", "nil") + } else if actualValue.Kind() != reflect.Ptr { + return fmt.Sprintf(shouldHaveBeenNonNilPointer, "first", "not") + } else if expectedValue.Kind() != reflect.Ptr { + return fmt.Sprintf(shouldHaveBeenNonNilPointer, "second", "not") + } else if ShouldEqual(actualValue.Pointer(), expectedValue.Pointer()) != success { + actualAddress := reflect.ValueOf(actual).Pointer() + expectedAddress := reflect.ValueOf(expected).Pointer() + return serializer.serialize(expectedAddress, actualAddress, fmt.Sprintf(shouldHavePointedTo, + actual, actualAddress, + expected, expectedAddress)) + } + return success +} + +// ShouldNotPointTo receives exactly two parameters and checks to see that they point to different addresess. +func ShouldNotPointTo(actual interface{}, expected ...interface{}) string { + if message := need(1, expected); message != success { + return message + } + compare := ShouldPointTo(actual, expected[0]) + if strings.HasPrefix(compare, shouldBePointers) { + return compare + } else if compare == success { + return fmt.Sprintf(shouldNotHavePointedTo, actual, expected[0], reflect.ValueOf(actual).Pointer()) + } + return success +} + +// ShouldBeNil receives a single parameter and ensures that it is nil. +func ShouldBeNil(actual interface{}, expected ...interface{}) string { + if fail := need(0, expected); fail != success { + return fail + } else if actual == nil { + return success + } else if interfaceHasNilValue(actual) { + return success + } + return fmt.Sprintf(shouldHaveBeenNil, actual) +} +func interfaceHasNilValue(actual interface{}) bool { + value := reflect.ValueOf(actual) + kind := value.Kind() + nilable := kind == reflect.Slice || + kind == reflect.Chan || + kind == reflect.Func || + kind == reflect.Ptr || + kind == reflect.Map + + // Careful: reflect.Value.IsNil() will panic unless it's an interface, chan, map, func, slice, or ptr + // Reference: http://golang.org/pkg/reflect/#Value.IsNil + return nilable && value.IsNil() +} + +// ShouldNotBeNil receives a single parameter and ensures that it is not nil. +func ShouldNotBeNil(actual interface{}, expected ...interface{}) string { + if fail := need(0, expected); fail != success { + return fail + } else if ShouldBeNil(actual) == success { + return fmt.Sprintf(shouldNotHaveBeenNil, actual) + } + return success +} + +// ShouldBeTrue receives a single parameter and ensures that it is true. +func ShouldBeTrue(actual interface{}, expected ...interface{}) string { + if fail := need(0, expected); fail != success { + return fail + } else if actual != true { + return fmt.Sprintf(shouldHaveBeenTrue, actual) + } + return success +} + +// ShouldBeFalse receives a single parameter and ensures that it is false. +func ShouldBeFalse(actual interface{}, expected ...interface{}) string { + if fail := need(0, expected); fail != success { + return fail + } else if actual != false { + return fmt.Sprintf(shouldHaveBeenFalse, actual) + } + return success +} + +// ShouldBeZeroValue receives a single parameter and ensures that it is +// the Go equivalent of the default value, or "zero" value. +func ShouldBeZeroValue(actual interface{}, expected ...interface{}) string { + if fail := need(0, expected); fail != success { + return fail + } + zeroVal := reflect.Zero(reflect.TypeOf(actual)).Interface() + if !reflect.DeepEqual(zeroVal, actual) { + return serializer.serialize(zeroVal, actual, fmt.Sprintf(shouldHaveBeenZeroValue, actual)) + } + return success +} + +// ShouldBeZeroValue receives a single parameter and ensures that it is NOT +// the Go equivalent of the default value, or "zero" value. +func ShouldNotBeZeroValue(actual interface{}, expected ...interface{}) string { + if fail := need(0, expected); fail != success { + return fail + } + zeroVal := reflect.Zero(reflect.TypeOf(actual)).Interface() + if reflect.DeepEqual(zeroVal, actual) { + return serializer.serialize(zeroVal, actual, fmt.Sprintf(shouldNotHaveBeenZeroValue, actual)) + } + return success +} diff --git a/backend/vendor/github.com/smartystreets/assertions/equality_diff.go b/backend/vendor/github.com/smartystreets/assertions/equality_diff.go new file mode 100644 index 00000000..bd698ff6 --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/equality_diff.go @@ -0,0 +1,37 @@ +package assertions + +import ( + "fmt" + + "github.com/smartystreets/assertions/internal/go-diff/diffmatchpatch" +) + +func composePrettyDiff(expected, actual string) string { + diff := diffmatchpatch.New() + diffs := diff.DiffMain(expected, actual, false) + if prettyDiffIsLikelyToBeHelpful(diffs) { + return fmt.Sprintf("\nDiff: '%s'", diff.DiffPrettyText(diffs)) + } + return "" +} + +// prettyDiffIsLikelyToBeHelpful returns true if the diff listing contains +// more 'equal' segments than 'deleted'/'inserted' segments. +func prettyDiffIsLikelyToBeHelpful(diffs []diffmatchpatch.Diff) bool { + equal, deleted, inserted := measureDiffTypeLengths(diffs) + return equal > deleted && equal > inserted +} + +func measureDiffTypeLengths(diffs []diffmatchpatch.Diff) (equal, deleted, inserted int) { + for _, segment := range diffs { + switch segment.Type { + case diffmatchpatch.DiffEqual: + equal += len(segment.Text) + case diffmatchpatch.DiffDelete: + deleted += len(segment.Text) + case diffmatchpatch.DiffInsert: + inserted += len(segment.Text) + } + } + return equal, deleted, inserted +} diff --git a/backend/vendor/github.com/smartystreets/assertions/filter.go b/backend/vendor/github.com/smartystreets/assertions/filter.go new file mode 100644 index 00000000..cbf75667 --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/filter.go @@ -0,0 +1,31 @@ +package assertions + +import "fmt" + +const ( + success = "" + needExactValues = "This assertion requires exactly %d comparison values (you provided %d)." + needNonEmptyCollection = "This assertion requires at least 1 comparison value (you provided 0)." + needFewerValues = "This assertion allows %d or fewer comparison values (you provided %d)." +) + +func need(needed int, expected []interface{}) string { + if len(expected) != needed { + return fmt.Sprintf(needExactValues, needed, len(expected)) + } + return success +} + +func atLeast(minimum int, expected []interface{}) string { + if len(expected) < minimum { + return needNonEmptyCollection + } + return success +} + +func atMost(max int, expected []interface{}) string { + if len(expected) > max { + return fmt.Sprintf(needFewerValues, max, len(expected)) + } + return success +} diff --git a/backend/vendor/github.com/smartystreets/assertions/go.mod b/backend/vendor/github.com/smartystreets/assertions/go.mod new file mode 100644 index 00000000..c0daaa3d --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/go.mod @@ -0,0 +1,3 @@ +module github.com/smartystreets/assertions + +go 1.12 diff --git a/backend/vendor/github.com/smartystreets/assertions/internal/go-diff/AUTHORS b/backend/vendor/github.com/smartystreets/assertions/internal/go-diff/AUTHORS new file mode 100644 index 00000000..2d7bb2bf --- /dev/null +++ b/backend/vendor/github.com/smartystreets/assertions/internal/go-diff/AUTHORS @@ -0,0 +1,25 @@ +# This is the official list of go-diff authors for copyright purposes. +# This file is distinct from the CONTRIBUTORS files. +# See the latter for an explanation. + +# Names should be added to this file as +# Name or Organization