mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-21 17:21:09 +01:00
updated dockerfile
This commit is contained in:
128
README.md
128
README.md
@@ -45,18 +45,18 @@ Three methods:
|
||||
- Docker Compose 1.24+ (optional but recommended)
|
||||
|
||||
### Pre-requisite (Direct Deploy)
|
||||
- Go 1.12+
|
||||
- Go 1.15+
|
||||
- Node 8.12+
|
||||
- MongoDB 3.6+
|
||||
- SeaweedFS
|
||||
- [SeaweedFS](https://github.com/chrislusf/seaweedfs) 2.59+
|
||||
|
||||
## Quick Start
|
||||
|
||||
Please open the command line prompt and execute the command below. Make sure you have installed `docker-compose` in advance.
|
||||
|
||||
```bash
|
||||
git clone https://github.com/crawlab-team/crawlab
|
||||
cd crawlab
|
||||
git clone https://github.com/crawlab-team/examples
|
||||
cd examples/docker/basic
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
@@ -72,34 +72,51 @@ Please use `docker-compose` to one-click to start up. By doing so, you don't eve
|
||||
```yaml
|
||||
version: '3.3'
|
||||
services:
|
||||
master:
|
||||
image: tikazyq/crawlab:latest
|
||||
container_name: master
|
||||
master:
|
||||
image: crawlabteam/crawlab:latest
|
||||
container_name: crawlab_example_master
|
||||
environment:
|
||||
CRAWLAB_SERVER_MASTER: "Y"
|
||||
CRAWLAB_MONGO_HOST: "mongo"
|
||||
CRAWLAB_REDIS_ADDRESS: "redis"
|
||||
ports:
|
||||
volumes:
|
||||
- "./.crawlab/master:/root/.crawlab"
|
||||
ports:
|
||||
- "8080:8080"
|
||||
depends_on:
|
||||
- mongo
|
||||
- redis
|
||||
|
||||
worker01:
|
||||
image: crawlabteam/crawlab:latest
|
||||
container_name: crawlab_example_worker01
|
||||
environment:
|
||||
CRAWLAB_SERVER_MASTER: "N"
|
||||
CRAWLAB_GRPC_ADDRESS: "master"
|
||||
volumes:
|
||||
- "./.crawlab/worker01:/root/.crawlab"
|
||||
depends_on:
|
||||
- master
|
||||
|
||||
worker02:
|
||||
image: crawlabteam/crawlab:latest
|
||||
container_name: crawlab_example_worker02
|
||||
environment:
|
||||
CRAWLAB_SERVER_MASTER: "N"
|
||||
CRAWLAB_GRPC_ADDRESS: "master"
|
||||
volumes:
|
||||
- "./.crawlab/worker02:/root/.crawlab"
|
||||
depends_on:
|
||||
- master
|
||||
|
||||
mongo:
|
||||
image: mongo:latest
|
||||
container_name: crawlab_example_mongo
|
||||
restart: always
|
||||
ports:
|
||||
- "27017:27017"
|
||||
redis:
|
||||
image: redis:latest
|
||||
restart: always
|
||||
ports:
|
||||
- "6379:6379"
|
||||
```
|
||||
|
||||
Then execute the command below, and Crawlab Master Node + MongoDB + Redis will start up. Open the browser and enter `http://localhost:8080` to see the UI interface.
|
||||
|
||||
```bash
|
||||
docker-compose up
|
||||
docker-compose up -d
|
||||
```
|
||||
|
||||
For Docker Deployment details, please refer to [relevant documentation](https://tikazyq.github.io/crawlab-docs/Installation/Docker.html).
|
||||
@@ -109,115 +126,92 @@ For Docker Deployment details, please refer to [relevant documentation](https://
|
||||
|
||||
#### Login
|
||||
|
||||
|
||||

|
||||
|
||||
#### Home Page
|
||||
|
||||
|
||||
|
||||
|
||||
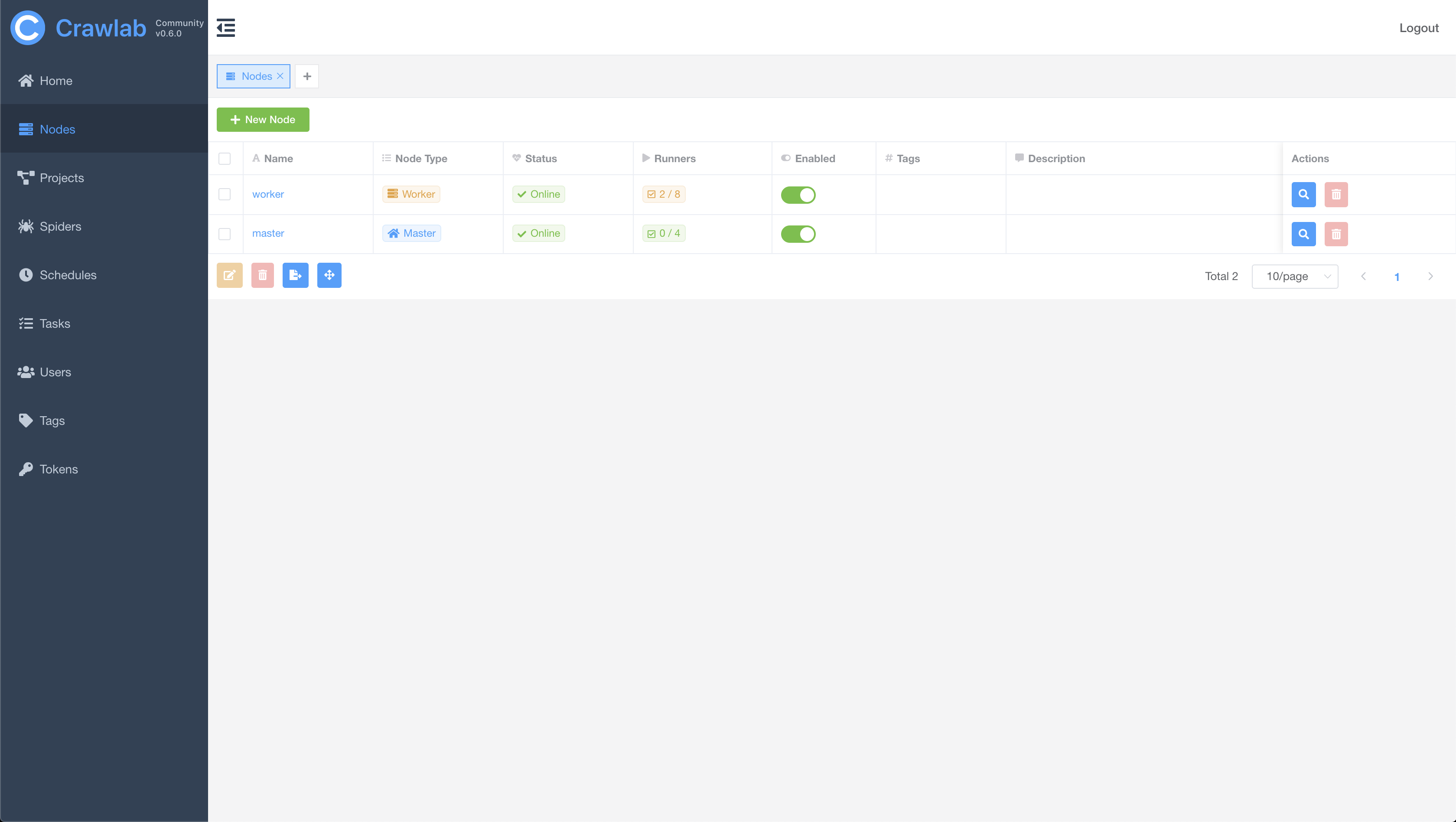
#### Node List
|
||||
|
||||
|
||||
|
||||
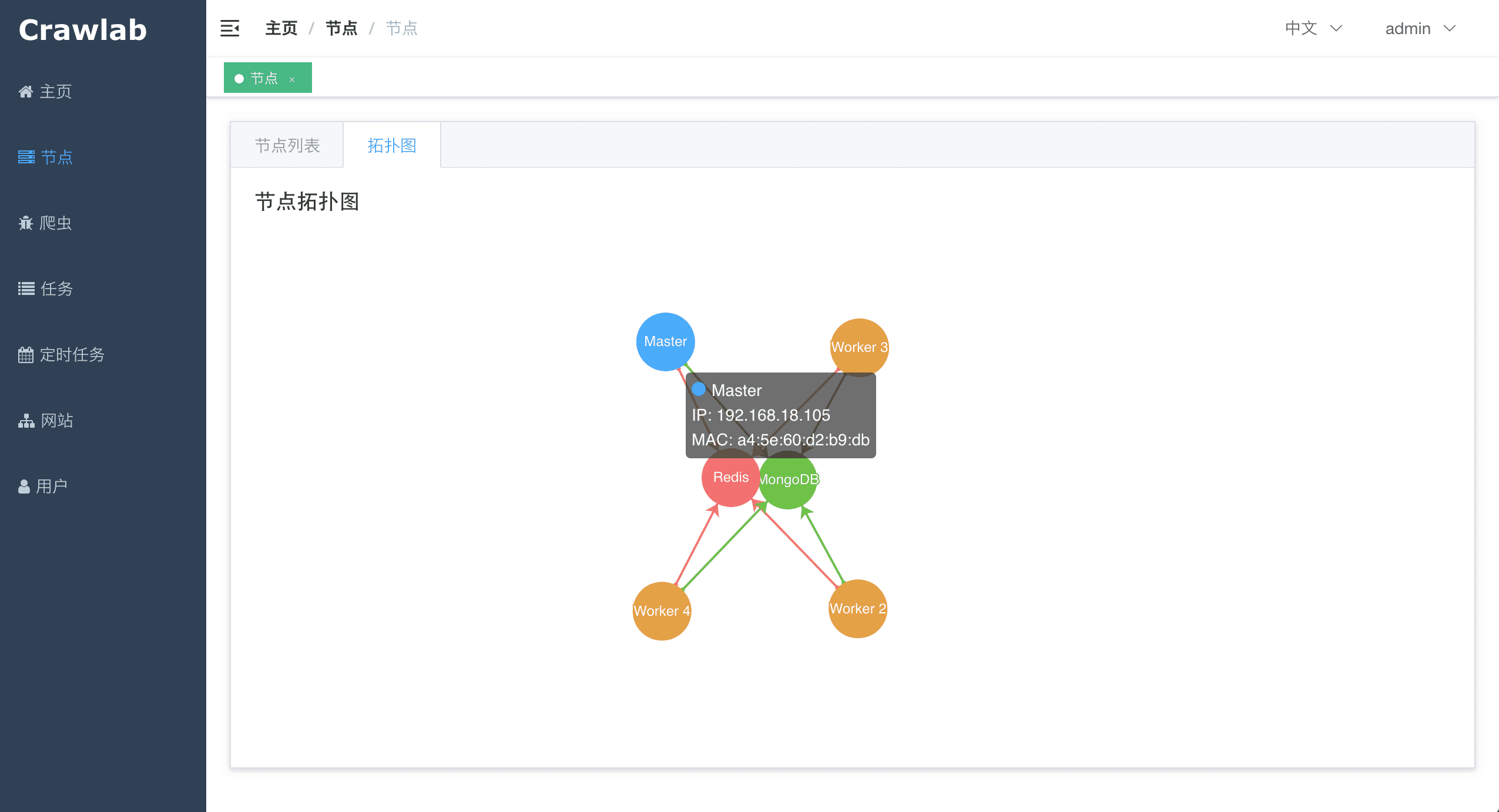
#### Node Network
|
||||
|
||||
|
||||
|
||||
|
||||
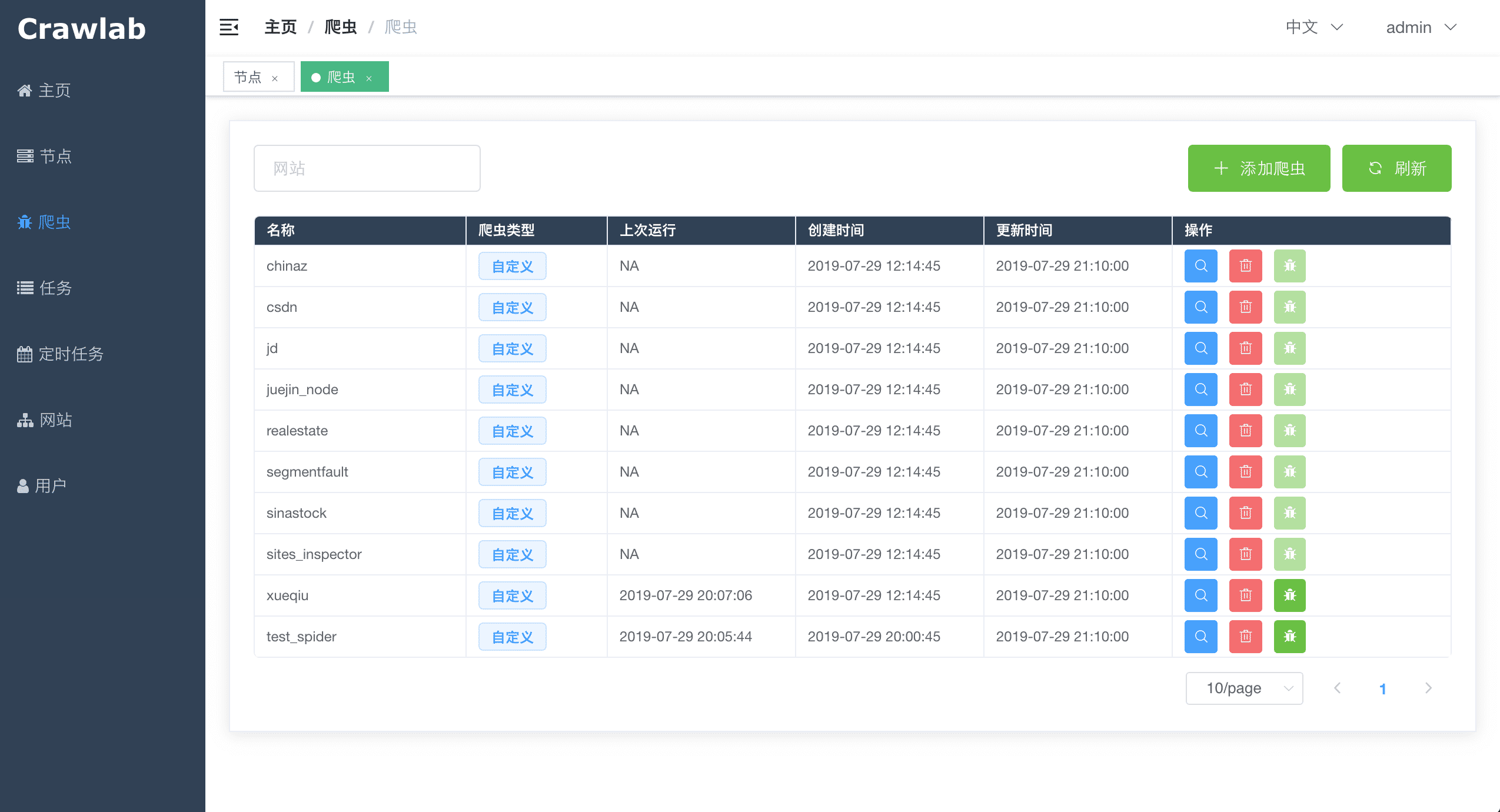
#### Spider List
|
||||
|
||||
|
||||

|
||||
|
||||
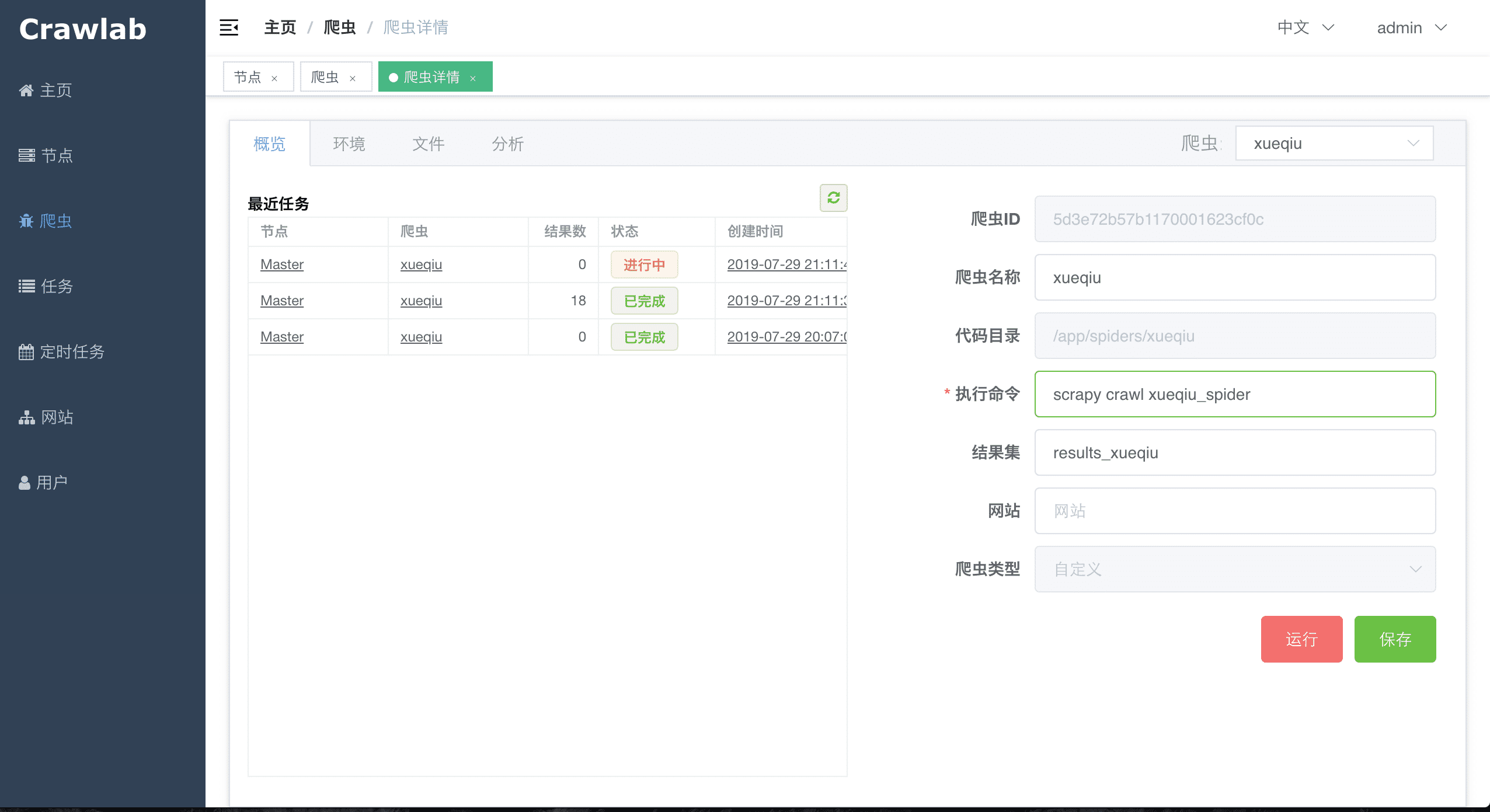
#### Spider Overview
|
||||
|
||||
|
||||

|
||||
|
||||
#### Spider Analytics
|
||||
#### Spider Files
|
||||
|
||||
|
||||
|
||||
#### Spider File Edit
|
||||
|
||||

|
||||
|
||||
|
||||
#### Task Log
|
||||
|
||||

|
||||
|
||||
|
||||
#### Task Results
|
||||
|
||||
|
||||
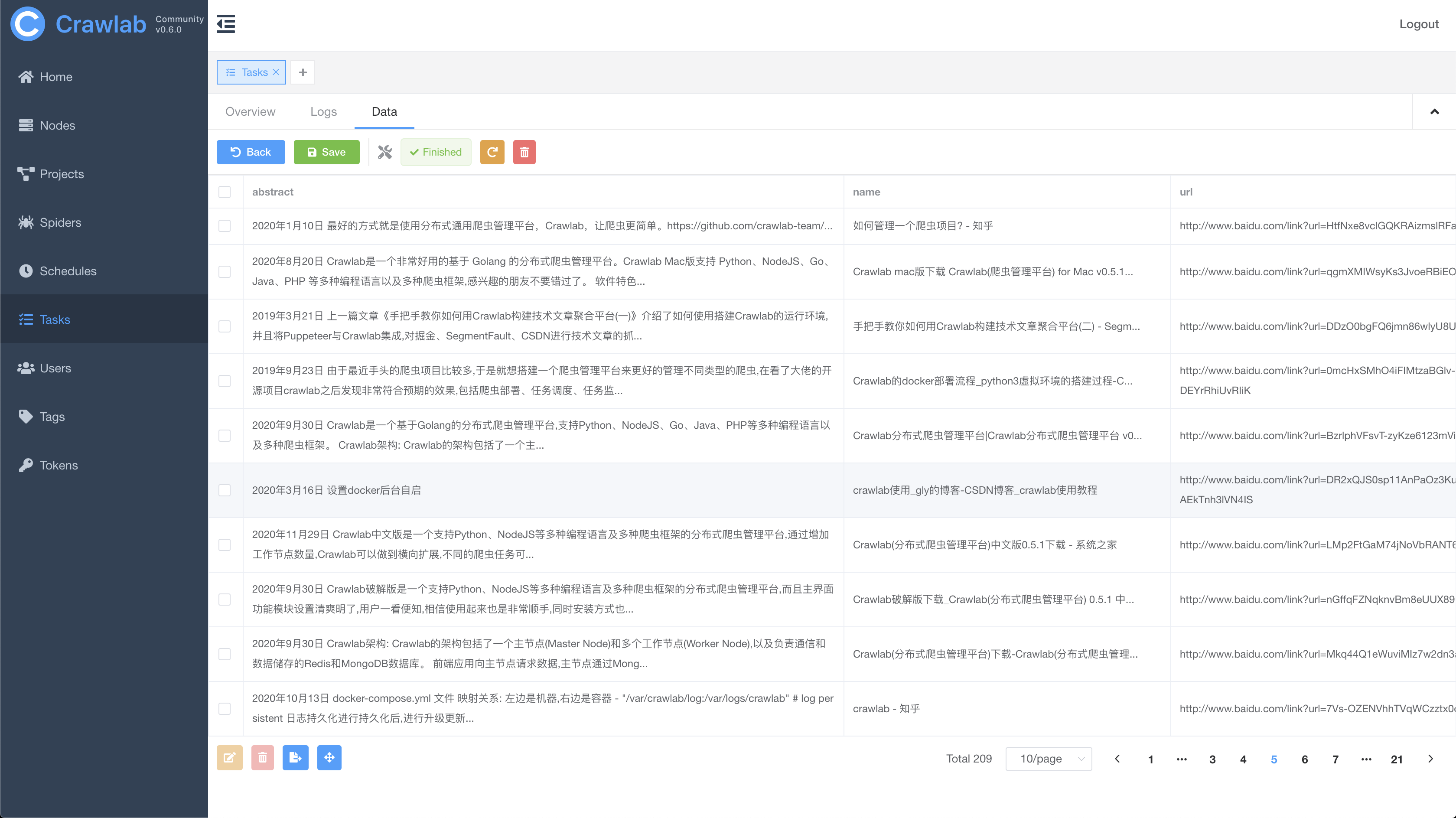
|
||||
|
||||
#### Cron Job
|
||||
|
||||

|
||||
|
||||
#### Language Installation
|
||||
|
||||

|
||||
|
||||
#### Dependency Installation
|
||||
|
||||

|
||||
|
||||
#### Notifications
|
||||
|
||||
<img src="http://static-docs.crawlab.cn/notification-mobile.jpeg" height="480px">
|
||||
|
||||
|
||||
## Architecture
|
||||
|
||||
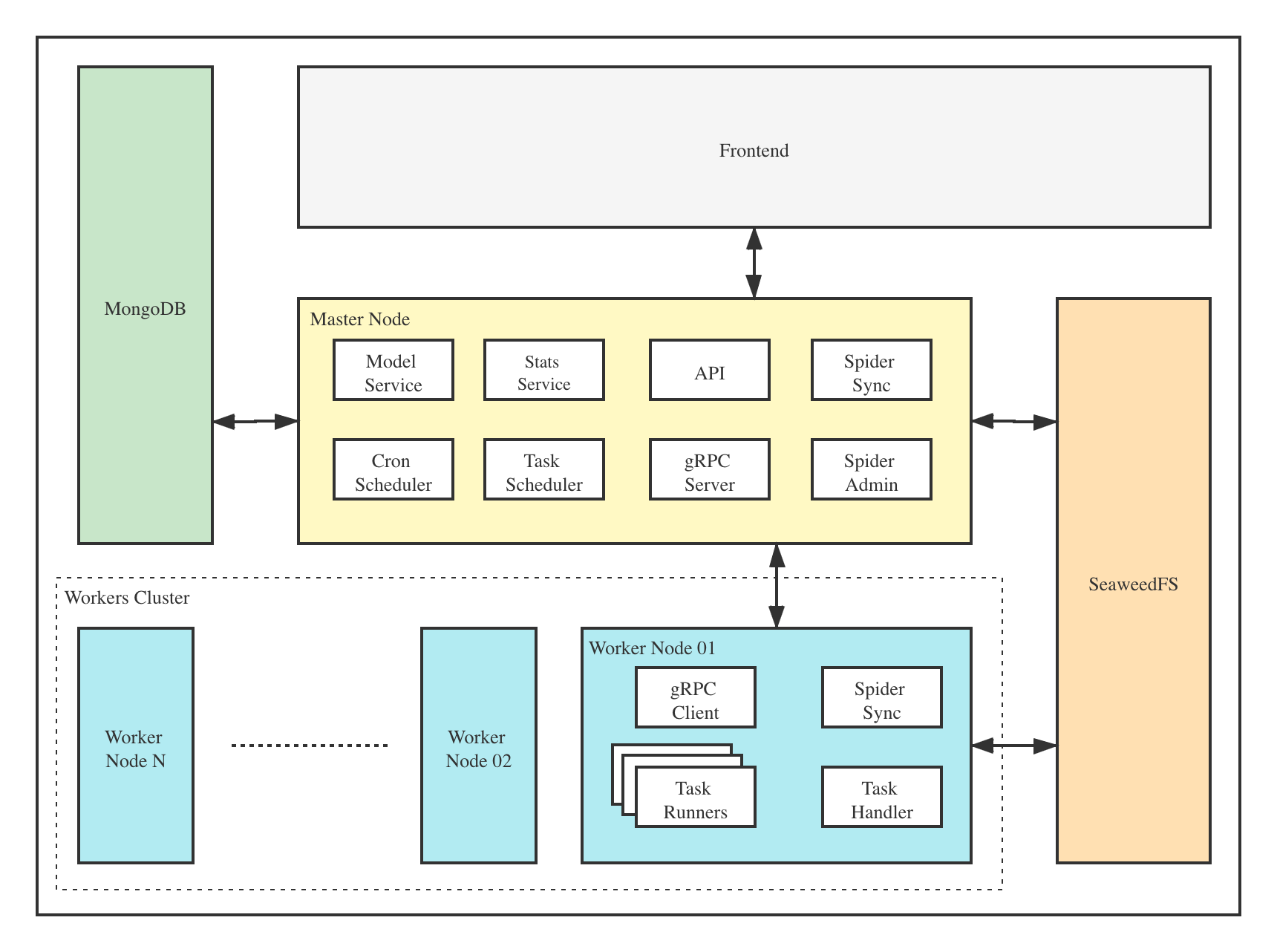
The architecture of Crawlab is consisted of the Master Node and multiple Worker Nodes, and Redis and MongoDB databases which are mainly for nodes communication and data storage.
|
||||
The architecture of Crawlab is consisted of a master node, worker nodes, [SeaweeFS](https://github.com/chrislusf/seaweedfs) (a distributed file system) and MongoDB database.
|
||||
|
||||

|
||||
|
||||
|
||||
The frontend app makes requests to the Master Node, which assigns tasks and deploys spiders through MongoDB and Redis. When a Worker Node receives a task, it begins to execute the crawling task, and stores the results to MongoDB. The architecture is much more concise compared with versions before `v0.3.0`. It has removed unnecessary Flower module which offers node monitoring services. They are now done by Redis.
|
||||
The frontend app interacts with the master node, which communicates with other components such as MongoDB, SeaweedFS and worker nodes. Master node and worker nodes communicate with each other via [gRPC](https://grpc.io) (a RPC framework). Tasks are scheduled by the task scheduler module in the master node, and received by the task handler module in worker nodes, which executes these tasks in task runners. Task runners are actually processes running spider or crawler programs, and can also send data through gRPC (integrated in SDK) to other data sources, e.g. MongoDB.
|
||||
|
||||
### Master Node
|
||||
|
||||
The Master Node is the core of the Crawlab architecture. It is the center control system of Crawlab.
|
||||
|
||||
The Master Node offers below services:
|
||||
1. Crawling Task Coordination;
|
||||
The Master Node provides below services:
|
||||
1. Task Coordination;
|
||||
2. Worker Node Management and Communication;
|
||||
3. Spider Deployment;
|
||||
4. Frontend and API Services;
|
||||
5. Task Execution (one can regard the Master Node as a Worker Node)
|
||||
5. Task Execution (you can regard the Master Node as a Worker Node)
|
||||
|
||||
The Master Node communicates with the frontend app, and send crawling tasks to Worker Nodes. In the mean time, the Master Node synchronizes (deploys) spiders to Worker Nodes, via Redis and MongoDB GridFS.
|
||||
The Master Node communicates with the frontend app, and send crawling tasks to Worker Nodes. In the mean time, the Master Node uploads (deploys) spiders to the distributed file system SeaweedFS, for synchronization by worker nodes.
|
||||
|
||||
### Worker Node
|
||||
|
||||
The main functionality of the Worker Nodes is to execute crawling tasks and store results and logs, and communicate with the Master Node through Redis `PubSub`. By increasing the number of Worker Nodes, Crawlab can scale horizontally, and different crawling tasks can be assigned to different nodes to execute.
|
||||
The main functionality of the Worker Nodes is to execute crawling tasks and store results and logs, and communicate with the Master Node through gRPC. By increasing the number of Worker Nodes, Crawlab can scale horizontally, and different crawling tasks can be assigned to different nodes to execute.
|
||||
|
||||
### MongoDB
|
||||
|
||||
MongoDB is the operational database of Crawlab. It stores data of nodes, spiders, tasks, schedules, etc. The MongoDB GridFS file system is the medium for the Master Node to store spider files and synchronize to the Worker Nodes.
|
||||
MongoDB is the operational database of Crawlab. It stores data of nodes, spiders, tasks, schedules, etc. Task queue is also stored in MongoDB.
|
||||
|
||||
### Redis
|
||||
### SeaweedFS
|
||||
|
||||
Redis is a very popular Key-Value database. It offers node communication services in Crawlab. For example, nodes will execute `HSET` to set their info into a hash list named `nodes` in Redis, and the Master Node will identify online nodes according to the hash list.
|
||||
SeaweedFS is an open source distributed file system authored by [Chris Lu](https://github.com/chrislusf). It can robustly store and share files across a distributed system. In Crawlab, SeaweedFS mainly plays the role as file synchronization system and the place where task log files are stored.
|
||||
|
||||
### Frontend
|
||||
|
||||
Frontend is a SPA based on
|
||||
[Vue-Element-Admin](https://github.com/PanJiaChen/vue-element-admin). It has re-used many Element-UI components to support corresponding display.
|
||||
Frontend app is built upon [Element-Plus](https://github.com/element-plus/element-plus), a popular [Vue 3](https://github.com/vuejs/vue-next)-based UI framework. It interacts with API hosted on the Master Node, and indirectly controls Worker Nodes.
|
||||
|
||||
## Integration with Other Frameworks
|
||||
|
||||
[Crawlab SDK](https://github.com/crawlab-team/crawlab-sdk) provides some `helper` methods to make it easier for you to integrate your spiders into Crawlab, e.g. saving results.
|
||||
|
||||
⚠️Note: make sure you have already installed `crawlab-sdk` using pip.
|
||||
|
||||
### Scrapy
|
||||
|
||||
In `settings.py` in your Scrapy project, find the variable named `ITEM_PIPELINES` (a `dict` variable). Add content below.
|
||||
|
||||
```python
|
||||
ITEM_PIPELINES = {
|
||||
'crawlab.pipelines.CrawlabMongoPipeline': 888,
|
||||
'crawlab.scrapy.pipelines.CrawlabPipeline': 888,
|
||||
}
|
||||
```
|
||||
|
||||
Then, start the Scrapy spider. After it's done, you should be able to see scraped results in **Task Detail -> Result**
|
||||
Then, start the Scrapy spider. After it's done, you should be able to see scraped results in **Task Detail -> Data**
|
||||
|
||||
### General Python Spider
|
||||
|
||||
@@ -234,11 +228,11 @@ result = {'name': 'crawlab'}
|
||||
save_item(result)
|
||||
```
|
||||
|
||||
Then, start the spider. After it's done, you should be able to see scraped results in **Task Detail -> Result**
|
||||
Then, start the spider. After it's done, you should be able to see scraped results in **Task Detail -> Data**
|
||||
|
||||
### Other Frameworks / Languages
|
||||
|
||||
A crawling task is actually executed through a shell command. The Task ID will be passed to the crawling task process in the form of environment variable named `CRAWLAB_TASK_ID`. By doing so, the data can be related to a task. Also, another environment variable `CRAWLAB_COLLECTION` is passed by Crawlab as the name of the collection to store results data.
|
||||
A crawling task is actually executed through a shell command. The Task ID will be passed to the crawling task process in the form of environment variable named `CRAWLAB_TASK_ID`. By doing so, the data can be related to a task.
|
||||
|
||||
## Comparison with Other Frameworks
|
||||
|
||||
|
||||
Reference in New Issue
Block a user