mirror of
https://github.com/crawlab-team/crawlab.git
synced 2026-01-30 18:00:56 +01:00
updated docs
This commit is contained in:
9
gitbook/Usage/Node/Edit.md
Normal file
9
gitbook/Usage/Node/Edit.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## 修改节点信息
|
||||
|
||||
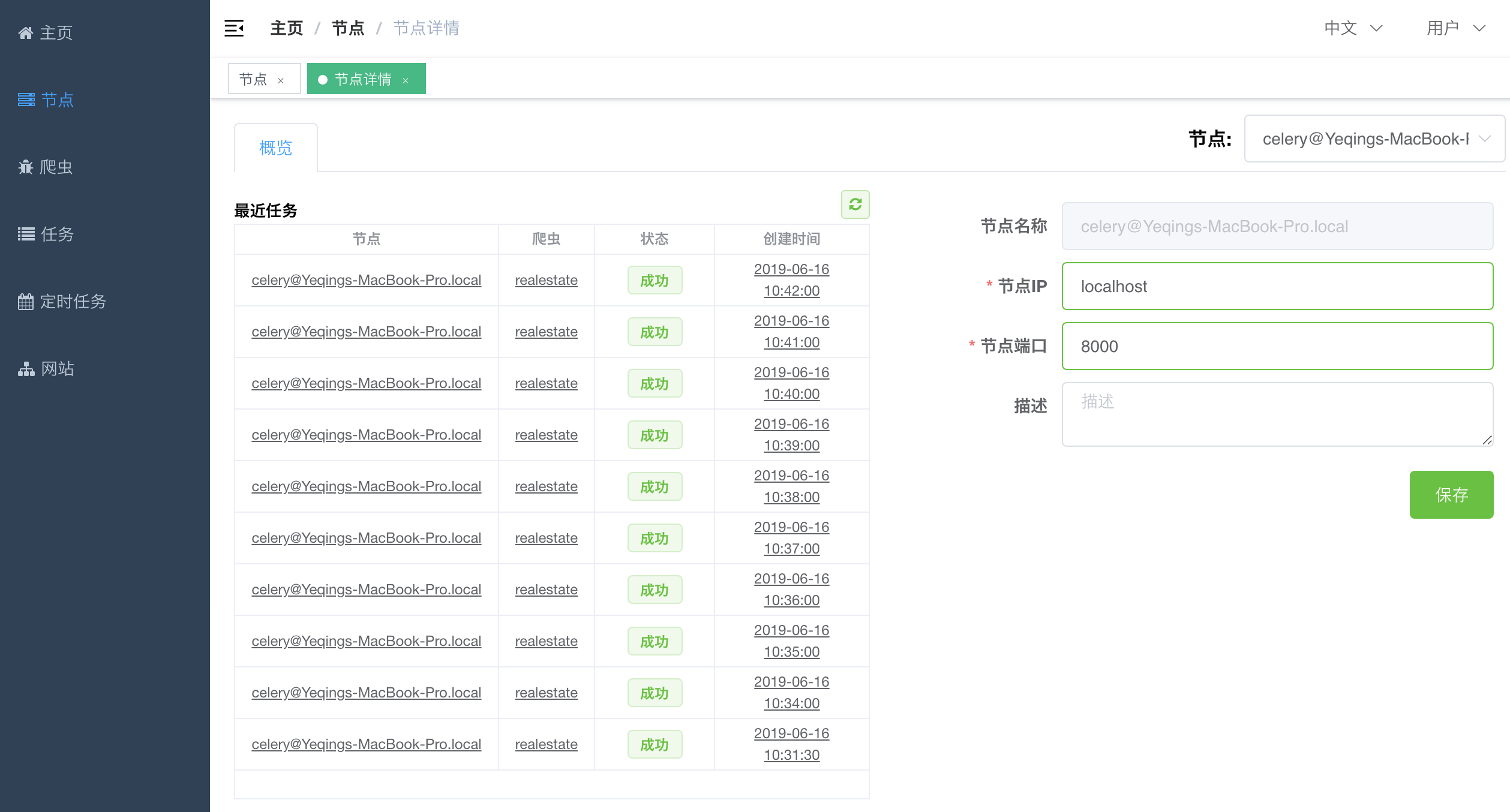
后面我们需要让爬虫运行在各个节点上,需要让主机与节点进行通信,因此需要知道节点的IP地址和端口。我们需要手动配置一下节点的IP和端口。在`节点列表`中点击`操作`列里的蓝色查看按钮进入到节点详情。节点详情样子如下。
|
||||
|
||||
|
||||
|
||||
在右侧分别输入该节点对应的`节点IP`和`节点端口`,然后点击`保存`按钮,保存该节点信息。
|
||||
|
||||
这样,我们就完成了节点的配置工作。
|
||||
6
gitbook/Usage/Node/README.md
Normal file
6
gitbook/Usage/Node/README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
## 节点
|
||||
|
||||
节点其实就是Celery中的Worker。一个节点运行时会连接到一个任务队列(例如Redis)来接收和运行任务。所有爬虫需要在运行时被部署到节点上,用户在部署前需要定义节点的IP地址和端口(默认为`localhost:8000`)。
|
||||
|
||||
1. [查看节点](/Usage/Node/View.md)
|
||||
2. [修改节点信息](/Usage/Node/Edit.md)
|
||||
5
gitbook/Usage/Node/View.md
Normal file
5
gitbook/Usage/Node/View.md
Normal file
@@ -0,0 +1,5 @@
|
||||
## 查看节点列表
|
||||
|
||||
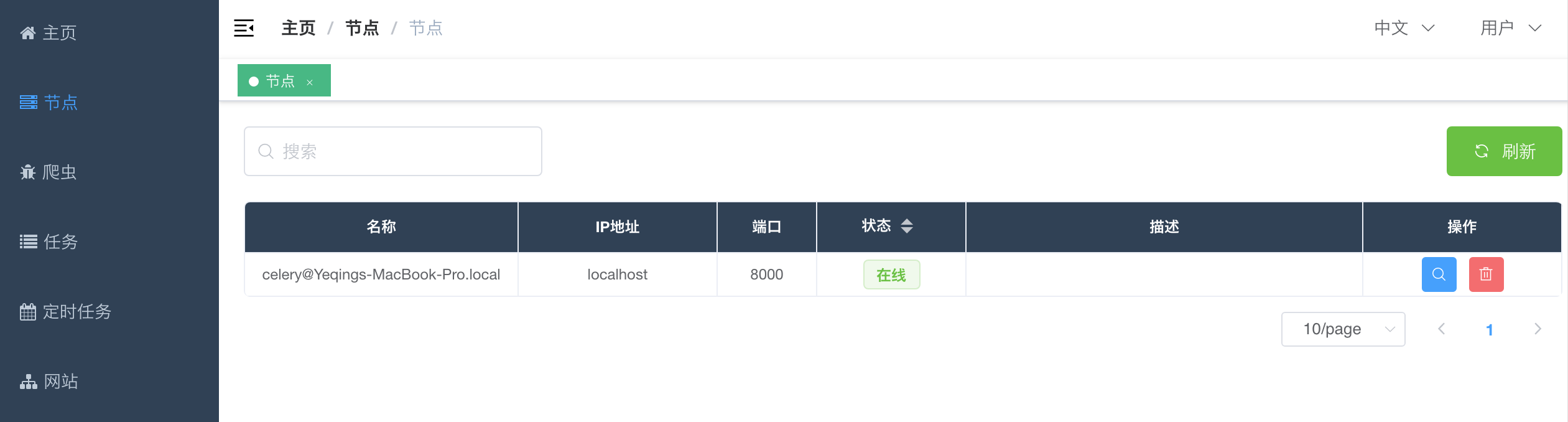
点击`侧边栏`的`节点`导航至`节点列表`,可以看到已上线的节点。这里的节点其实就是已经运行起来的`celery worker`,他们通过连接到配置好的`broker`(通常是`redis`)来进行与主机的通信。
|
||||
|
||||
|
||||
6
gitbook/Usage/README.md
Normal file
6
gitbook/Usage/README.md
Normal file
@@ -0,0 +1,6 @@
|
||||
本小节将介绍如何使用Crawlab,包括如下内容:
|
||||
|
||||
1. [节点](/Usage/Node/README.md)
|
||||
2. [爬虫](/Usage/Spider/README.md)
|
||||
3. [任务](/Usage/Task/README.md)
|
||||
4. [定时任务](/Usage/Schedule/README.md)
|
||||
0
gitbook/Usage/Schedule/README.md
Normal file
0
gitbook/Usage/Schedule/README.md
Normal file
0
gitbook/Usage/Site/README.md
Normal file
0
gitbook/Usage/Site/README.md
Normal file
7
gitbook/Usage/Spider/Analytics.md
Normal file
7
gitbook/Usage/Spider/Analytics.md
Normal file
@@ -0,0 +1,7 @@
|
||||
## 统计数据
|
||||
|
||||
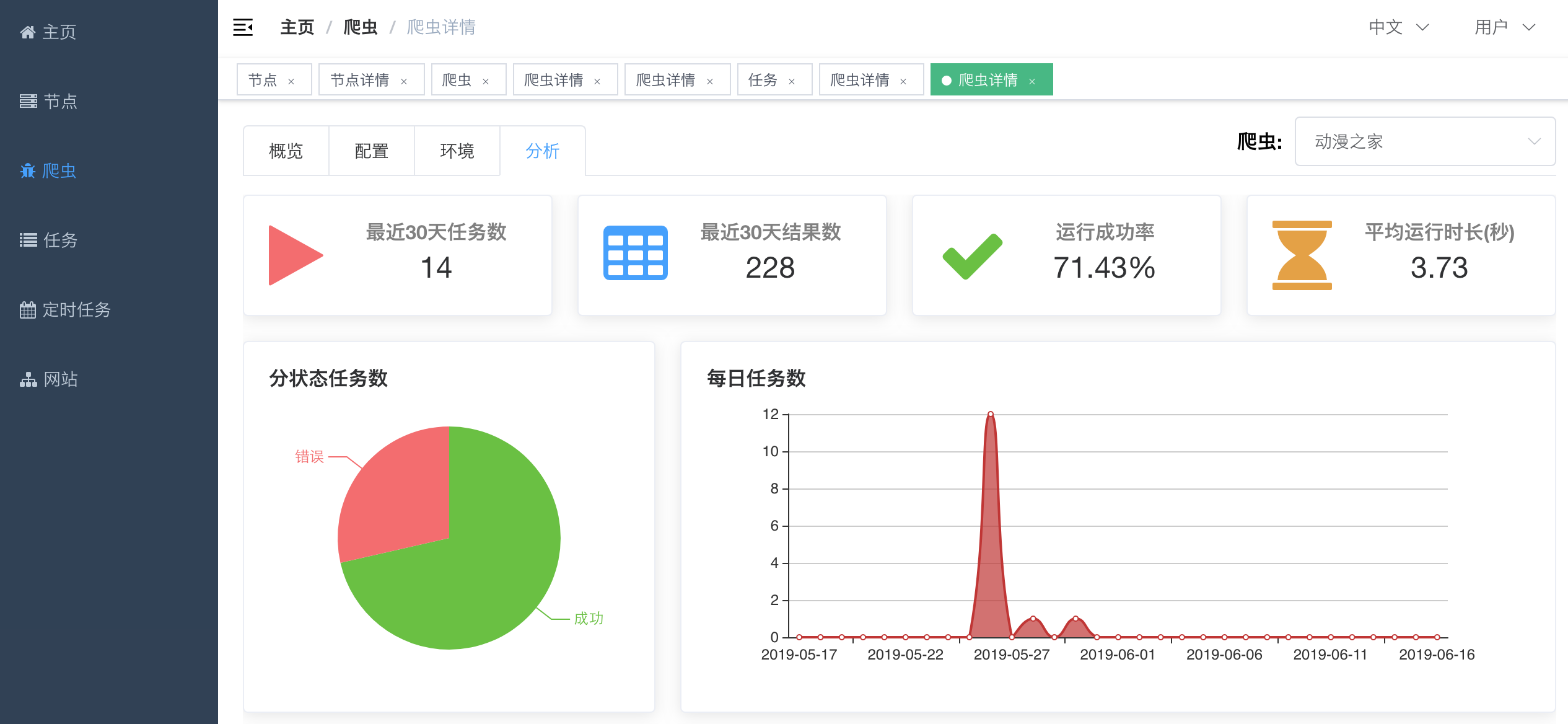
在运行了一段时间之后,爬虫会积累一些统计数据,例如`运行成功率`、`任务数`、`运行时长`等指标。Crawlab将这些指标汇总并呈现给开发者。
|
||||
|
||||
要查看统计数据的话,只需要在`爬虫详情`中,点击`分析`标签,就可以看到爬虫的统计数据了。
|
||||
|
||||
|
||||
64
gitbook/Usage/Spider/ConfigurableSpider.md
Normal file
64
gitbook/Usage/Spider/ConfigurableSpider.md
Normal file
@@ -0,0 +1,64 @@
|
||||
## 可配置爬虫
|
||||
|
||||
可配置爬虫是版本[v0.2.1](https://github.com/tikazyq/crawlab/releases/tag/v0.2.1)开发的功能。目的是将具有相似网站结构的爬虫项目可配置化,将开发爬虫的过程流程化,大大提高爬虫开发效率。
|
||||
|
||||
Crawlab的可配置爬虫是基于Scrapy的,因此天生支持并发。而且,可配置爬虫完全支持[自定义爬虫](/Usage/Spider/CustomizedSpider)的一般功能,因此也支持任务调度、任务监控、日志监控、数据分析。
|
||||
|
||||
### 添加爬虫
|
||||
|
||||
在`侧边栏`点击`爬虫`导航至`爬虫列表`,点击**添加爬虫**按钮。
|
||||
|
||||

|
||||
|
||||
点击**可配置爬虫**。
|
||||
|
||||

|
||||
|
||||
输入完基本信息,点击**添加**。
|
||||
|
||||

|
||||
|
||||
### 配置爬虫
|
||||
|
||||
添加完成后,可以看到刚刚添加的可配置爬虫出现了在最下方,点击**查看**进入到**爬虫详情**。
|
||||
|
||||

|
||||
|
||||
点击**配置**标签进入到配置页面。接下来,我们需要对爬虫规则进行配置。
|
||||
|
||||

|
||||
|
||||
这里已经有一些配置好的初始输入项。我们简单介绍一下各自的含义。
|
||||
|
||||
#### 抓取类别
|
||||
|
||||
这也是爬虫抓取采用的策略,也就是爬虫遍历网页是如何进行的。作为第一个版本,我们有**仅列表**、**仅详情页**、**列表+详情页**。
|
||||
- 仅列表页。这也是最简单的形式,爬虫遍历列表上的列表项,将数据抓取下来。
|
||||
- 仅详情页。爬虫只抓取详情页。
|
||||
- 列表+详情页。爬虫先遍历列表页,将列表项中的详情页地址提取出来并跟进抓取详情页。
|
||||
|
||||
这里我们选择**列表+详情页**。
|
||||
|
||||
#### 列表项选择器 & 分页选择器
|
||||
|
||||
列表项的匹和分页按钮的匹配查询,由CSS或XPath来进行匹配。
|
||||
|
||||
#### 开始URL
|
||||
|
||||
爬虫最开始遍历的网址。
|
||||
|
||||
#### 遵守Robots协议
|
||||
|
||||
这个默认是开启的。如果开启,爬虫将先抓取网站的robots.txt并判断页面是否可抓;否则,不会对此进行验证。用户可以选择将其关闭。请注意,任何无视Robots协议的行为都有法律风险。
|
||||
|
||||
#### 列表页字段 & 详情页字段
|
||||
|
||||
这些都是再列表页或详情页中需要提取的字段。字段由CSS选择器或者XPath来匹配提取。可以选择文本或者属性。
|
||||
|
||||
在检查完目标网页的元素CSS选择器之后,我们输入列表项选择器、开始URL、列表页/详情页等信息。注意勾选url为详情页URL。
|
||||
|
||||

|
||||
|
||||
点击保存、预览,查看预览内容。
|
||||
|
||||

|
||||
7
gitbook/Usage/Spider/Create.md
Normal file
7
gitbook/Usage/Spider/Create.md
Normal file
@@ -0,0 +1,7 @@
|
||||
## 创建爬虫
|
||||
|
||||
Crawlab允许用户创建两种爬虫:
|
||||
1. [自定义爬虫](/Usage/Spider/CustomizedSpider.md)
|
||||
2. [可配置爬虫](/Usage/Spider/ConfigurableSpider.md)
|
||||
|
||||
前者可以通过Web界面和创建项目目录的方式来添加,后者由于没有源代码,只能通过Web界面来添加。
|
||||
31
gitbook/Usage/Spider/CustomizedSpider.md
Normal file
31
gitbook/Usage/Spider/CustomizedSpider.md
Normal file
@@ -0,0 +1,31 @@
|
||||
## 自定义爬虫
|
||||
|
||||
自定义爬虫是指用户可以添加的任何语言任何框架的爬虫,高度自定义化。当用户添加好自定义爬虫之后,Crawlab就可以将其集成到爬虫管理的系统中来。
|
||||
|
||||
自定义爬虫的添加有两种方式:
|
||||
1. 通过Web界面上传爬虫
|
||||
2. 通过创建项目目录
|
||||
|
||||
### 通过Web界面上传
|
||||
|
||||
在通过Web界面上传之前,需要将爬虫项目文件打包成`zip`格式。
|
||||
|
||||
|
||||
|
||||
然后,在`侧边栏`点击`爬虫`导航至`爬虫列表`,点击`添加爬虫`按钮,选择`自定义爬虫`,点击`上传`按钮,选择刚刚打包好的`zip`文件。上传成功后,`爬虫列表`中会出现新添加的自定义爬虫。这样就算添加好了。
|
||||
|
||||
这个方式稍微有些繁琐,但是对于无法轻松获取服务器的读写权限时是非常有用的,适合在生产环境上使用。
|
||||
|
||||
### 通过添加项目目录
|
||||
|
||||
Crawlab会自动发现`PROJECT_SOURCE_FILE_FOLDER`目录下的所有爬虫目录,并将这些目录生成自定义爬虫并集成到Crawlab中。因此,将爬虫项目目录拷贝到`PROJECT_SOURCE_FILE_FOLDER`目录下,就可以添加一个爬虫了。
|
||||
|
||||
这种方式非常方便,但是需要获得主机服务器的读写权限,因而比较适合在开发环境上采用。
|
||||
|
||||
### 配置爬虫
|
||||
|
||||
在定义爬虫中,我们需要配置一下`执行命令`(运行爬虫时后台执行的`shell`命令)和`结果集`(通过`CRAWLAB_COLLECTION`传递给爬虫程序,爬虫程序存储结果的地方),然后点击`保存`按钮保存爬虫信息。
|
||||
|
||||
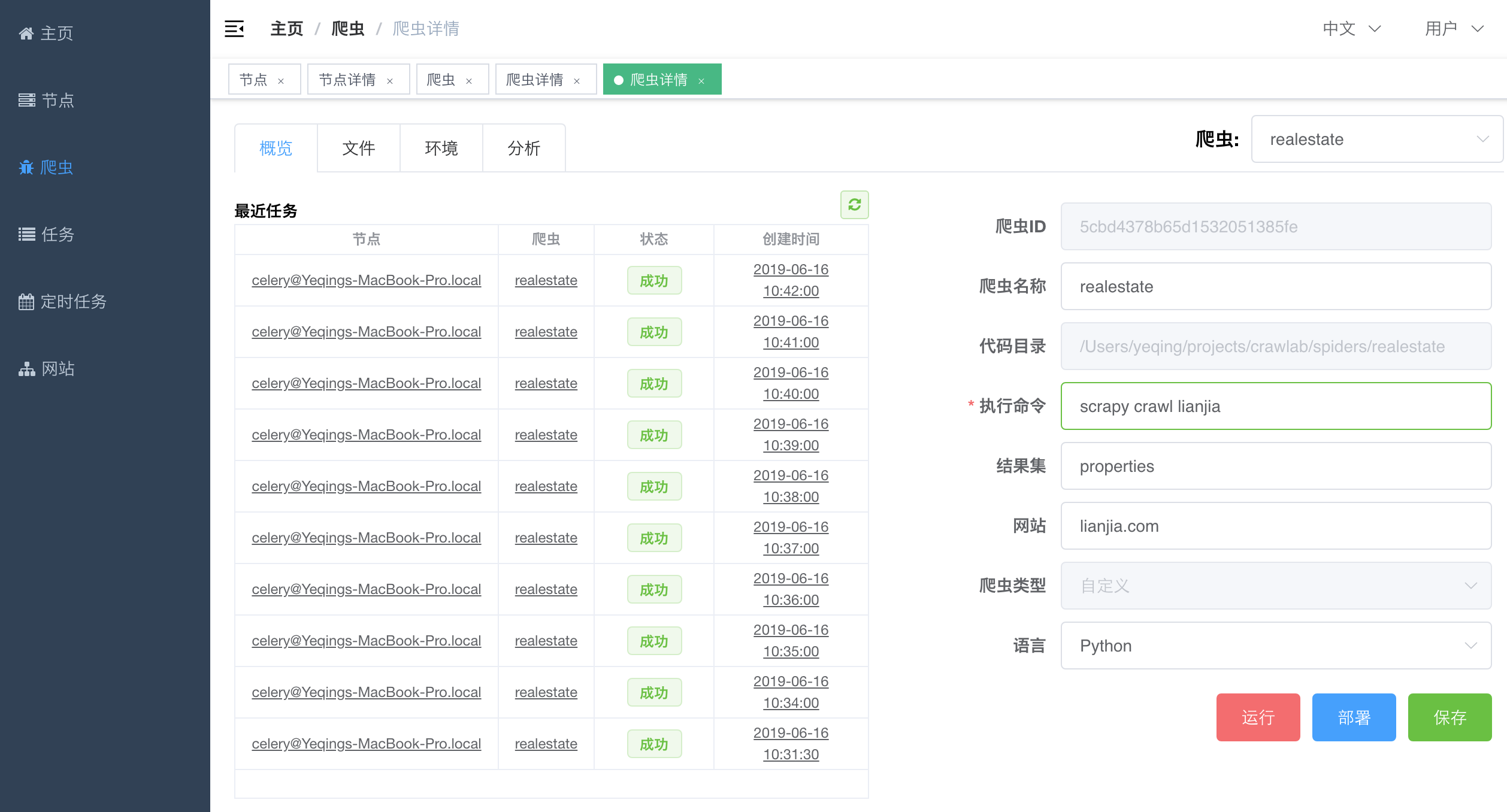
|
||||
|
||||
接下来,我们就可以部署、运行自定义爬虫了。
|
||||
10
gitbook/Usage/Spider/Deploy.md
Normal file
10
gitbook/Usage/Spider/Deploy.md
Normal file
@@ -0,0 +1,10 @@
|
||||
## 部署爬虫
|
||||
|
||||
这里的爬虫部署是指[自定义爬虫](/Usage/Spider/CustomizedSpider)的部署,因为[可配置爬虫](/Usage/Spider/ConfigurableSpider)已经内嵌到Crawlab中了,所有节点都可以使用,不需要额外部署。简单来说,就是将主机上的爬虫源代码通过`HTTP`的方式打包传输至`worker`节点上,因此节点就可以运行传输过来的爬虫了。
|
||||
|
||||
部署爬虫很简单,有三种方式:
|
||||
1. 在`爬虫列表`中点击`部署所有爬虫`,将所有爬虫部署到所有在线节点中;
|
||||
2. 在`爬虫列表`中点击`操作`列的`部署`按钮,将指定爬虫部署到所有在线节点中;
|
||||
3. 在`爬虫详情`的`概览`标签中,点击`部署`按钮,将指定爬虫部署到所有在线节点中。
|
||||
|
||||
部署好之后,我们就可以运行爬虫了。
|
||||
9
gitbook/Usage/Spider/README.md
Normal file
9
gitbook/Usage/Spider/README.md
Normal file
@@ -0,0 +1,9 @@
|
||||
## 爬虫
|
||||
|
||||
爬虫就是我们通常说的网络爬虫了,本小节将介绍如下内容:
|
||||
|
||||
1. [创建爬虫](/Usage/Spider/Create.md)
|
||||
2. [部署爬虫](/Usage/Spider/Deploy.md)
|
||||
3. [运行爬虫](/Usage/Spider/Run.md)
|
||||
4. [可配置爬虫](/Usage/Spider/ConfigurableSpider.md)
|
||||
5. [统计数据](/Usage/Spider/Analytics.md)
|
||||
17
gitbook/Usage/Spider/Run.md
Normal file
17
gitbook/Usage/Spider/Run.md
Normal file
@@ -0,0 +1,17 @@
|
||||
## 运行爬虫
|
||||
|
||||
我们有两种运行爬虫的方式:
|
||||
1. 手动触发
|
||||
2. 定时任务触发
|
||||
|
||||
### 手动触发
|
||||
|
||||
1. 在`爬虫列表`中`操作`列点击`运行`按钮,或者
|
||||
2. 在`爬虫详情`中`概览`标签下点击`运行`按钮,或者
|
||||
3. 对于`自定义爬虫`,可以在`配置`标签下点击`运行`按钮
|
||||
|
||||
然后,Crawlab会提示任务已经派发到队列中去了,然后你可以在`爬虫详情`左侧看到新创建的任务。点击`创建时间`可以导航至`任务详情`。
|
||||
|
||||
### 定时任务触发
|
||||
|
||||
`定时任务触发`是比较常用的功能,对于`增量抓取`或对实时性有要求的任务很重要。这在[定时任务](/Usage/Schedule/README.md)中会详细介绍。
|
||||
0
gitbook/Usage/Task/README.md
Normal file
0
gitbook/Usage/Task/README.md
Normal file
Reference in New Issue
Block a user